LSTM(Long Short-Term Memory)
- LSTM은 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정한다.
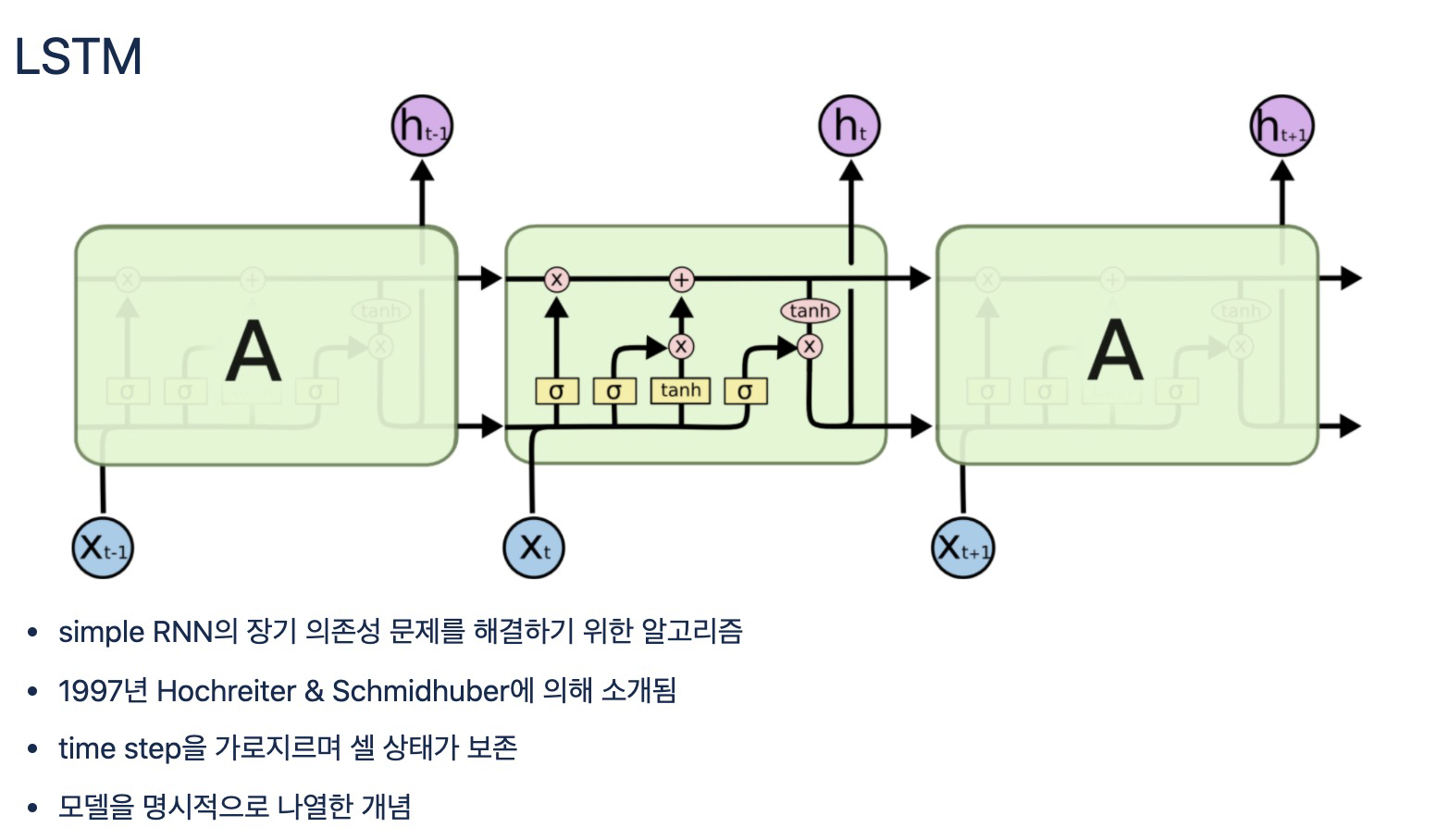
cell state
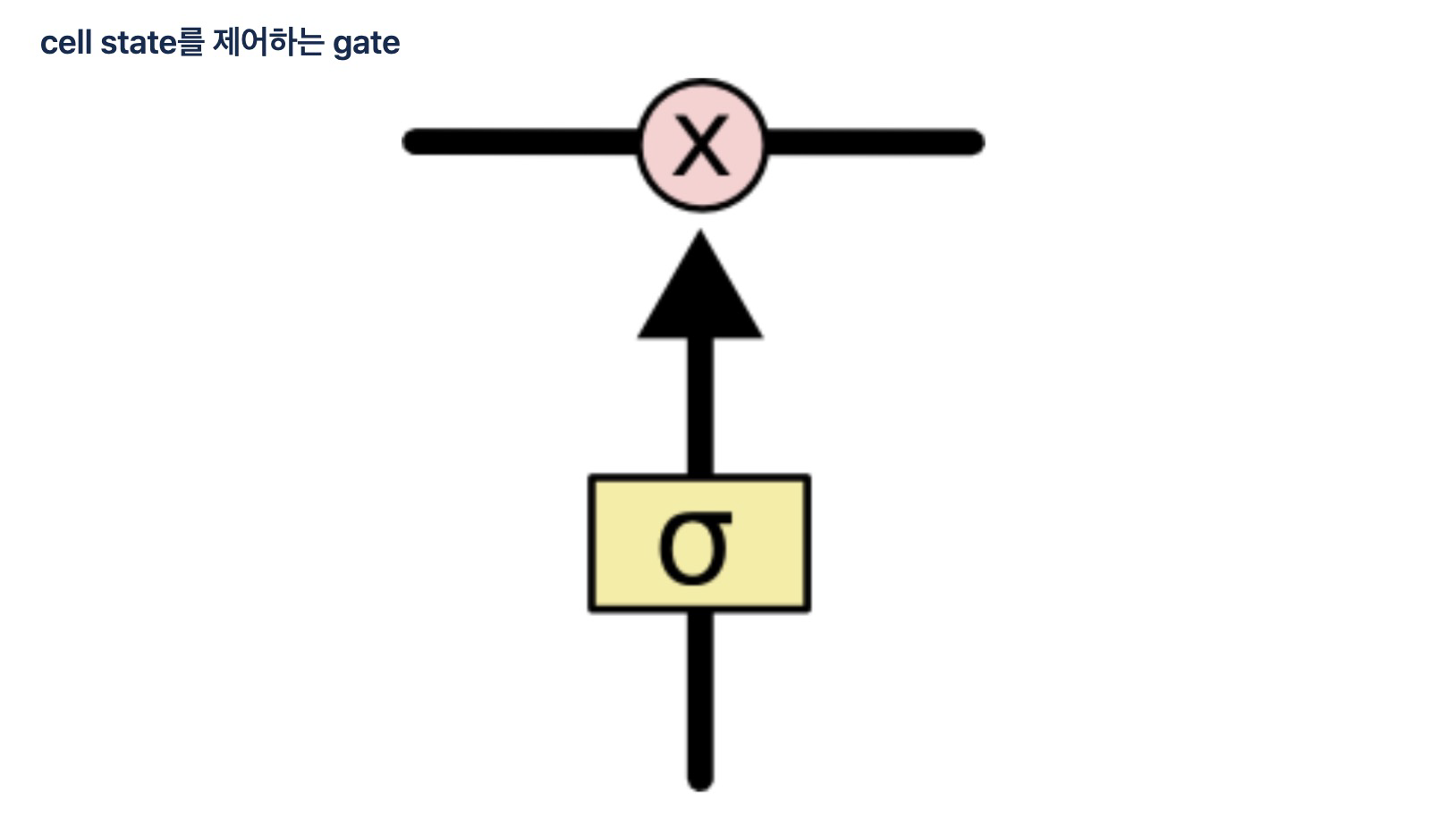
gate
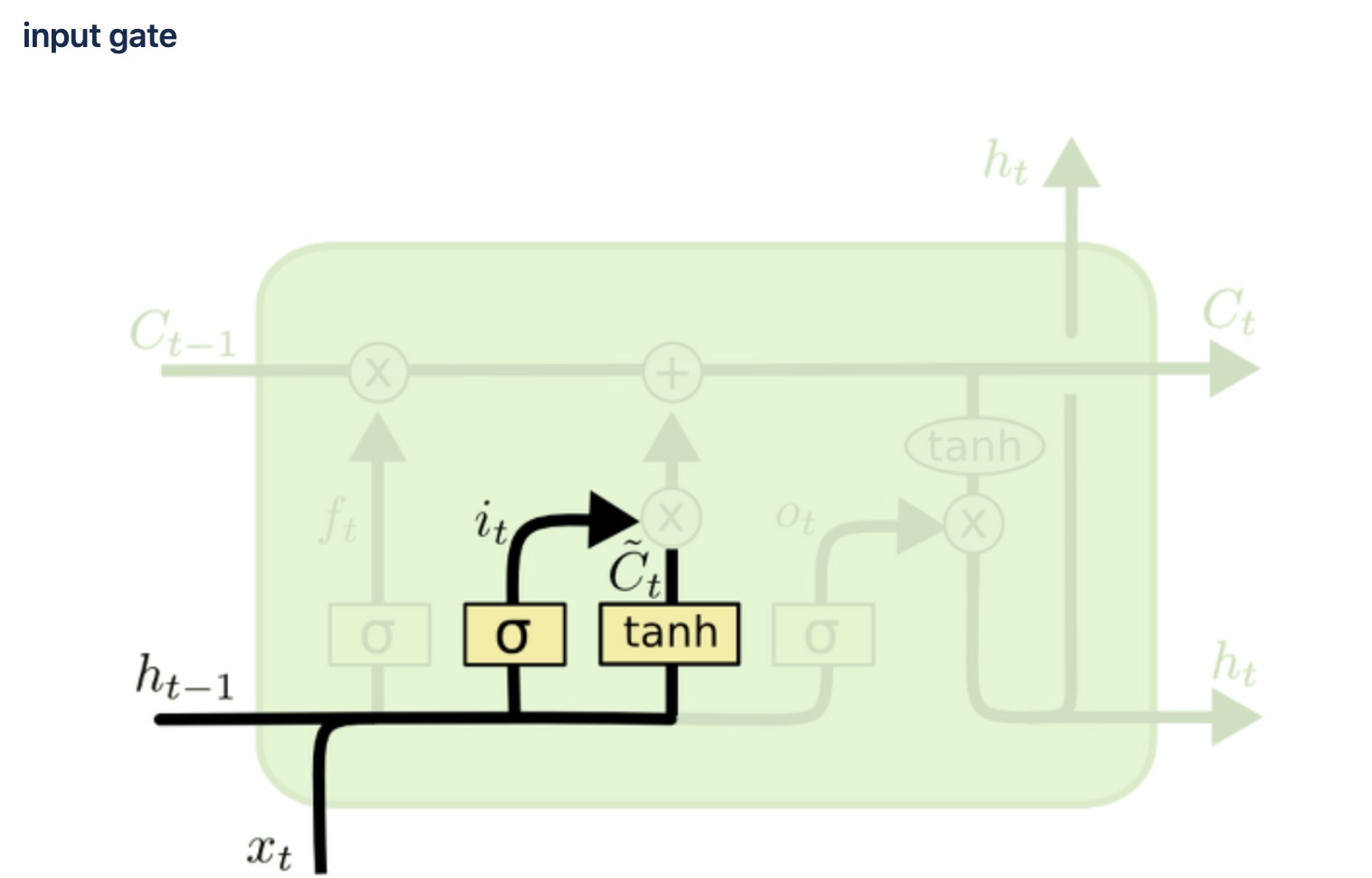
1) input gate
- 현재 정보를 기억하기 위한 게이트
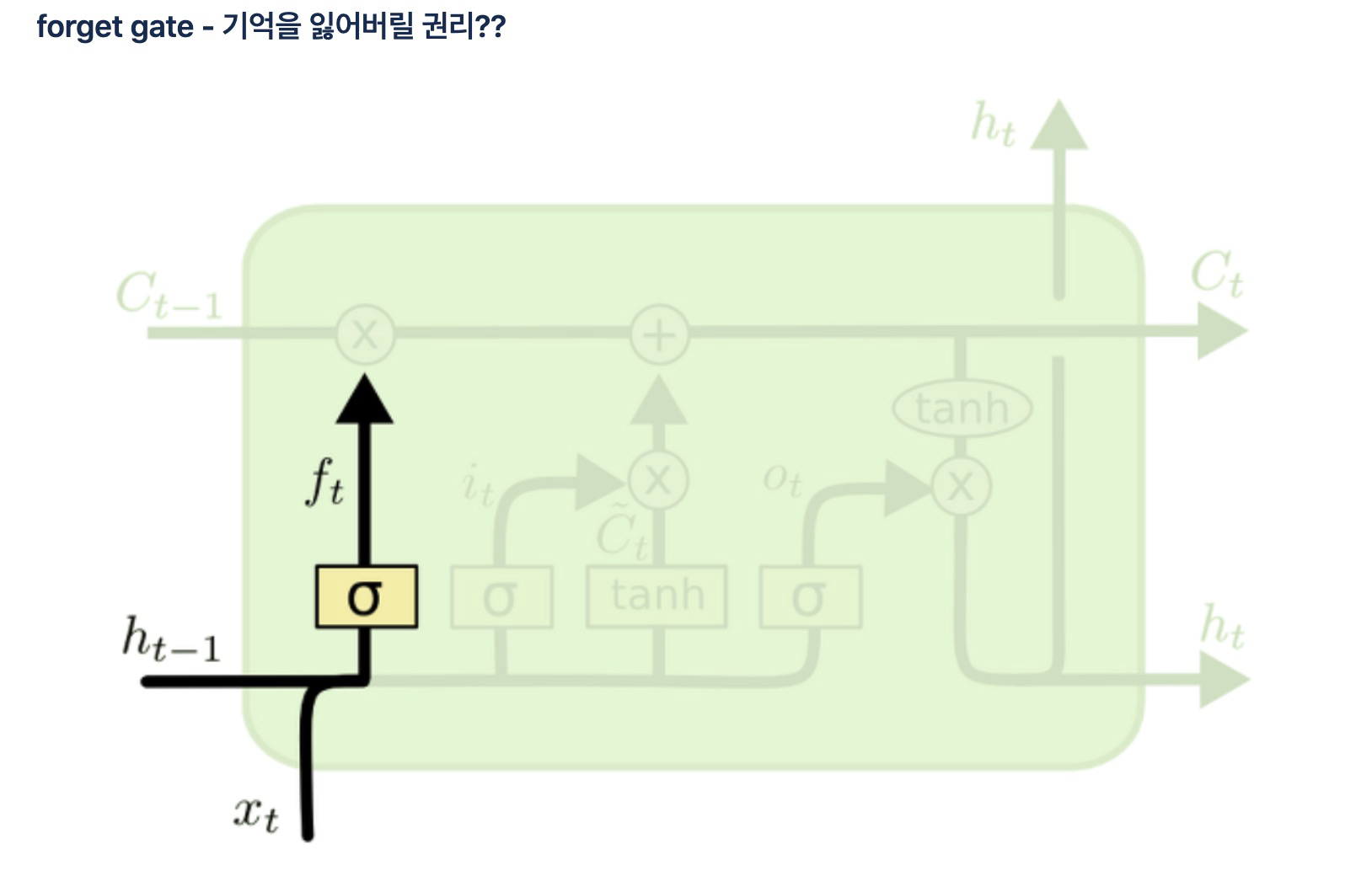
2) forget gate
- 기억을 삭제하기 위한 게이트
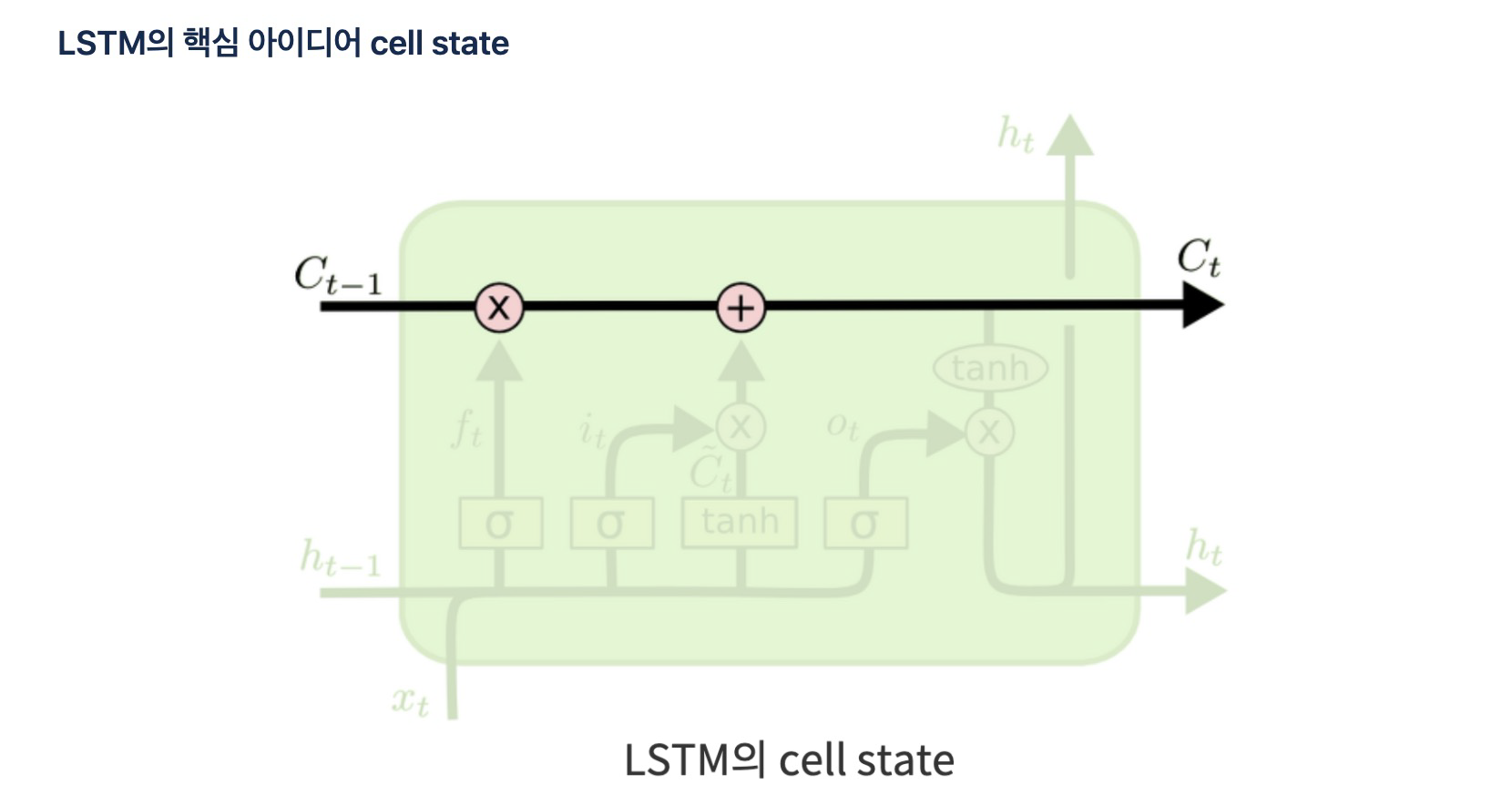
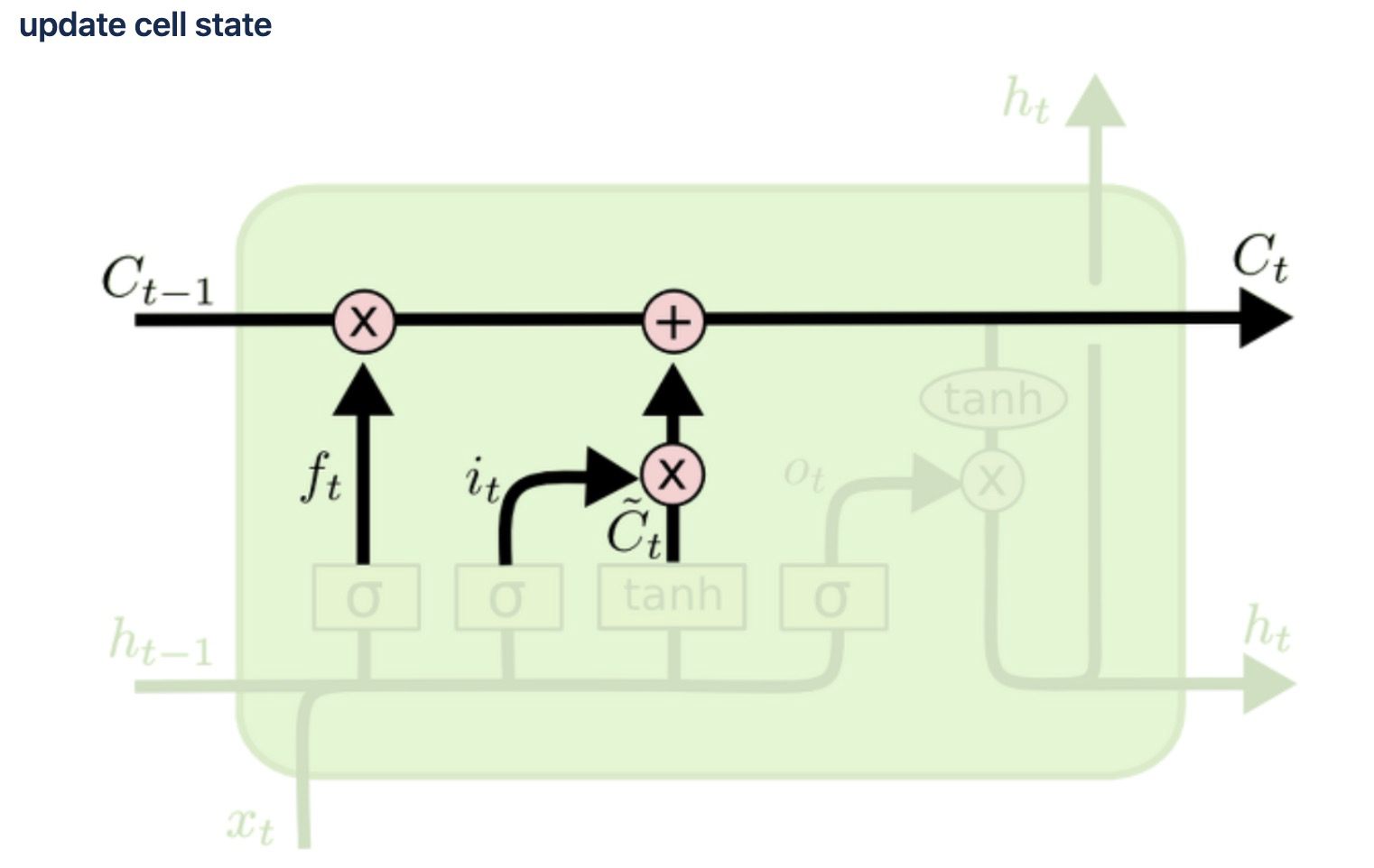
3) update cell state
- cell state(장기상태)
- t의 셀 상태 : 입력 게이트에서 구한 iₜ, gₜ 이 두 개의 값에 대해서 원소별 곱(이번에 선택된 기억할 값) + 삭제 게이트의 결과값 → t+1 시점의 LSTM 셀로 넘겨짐
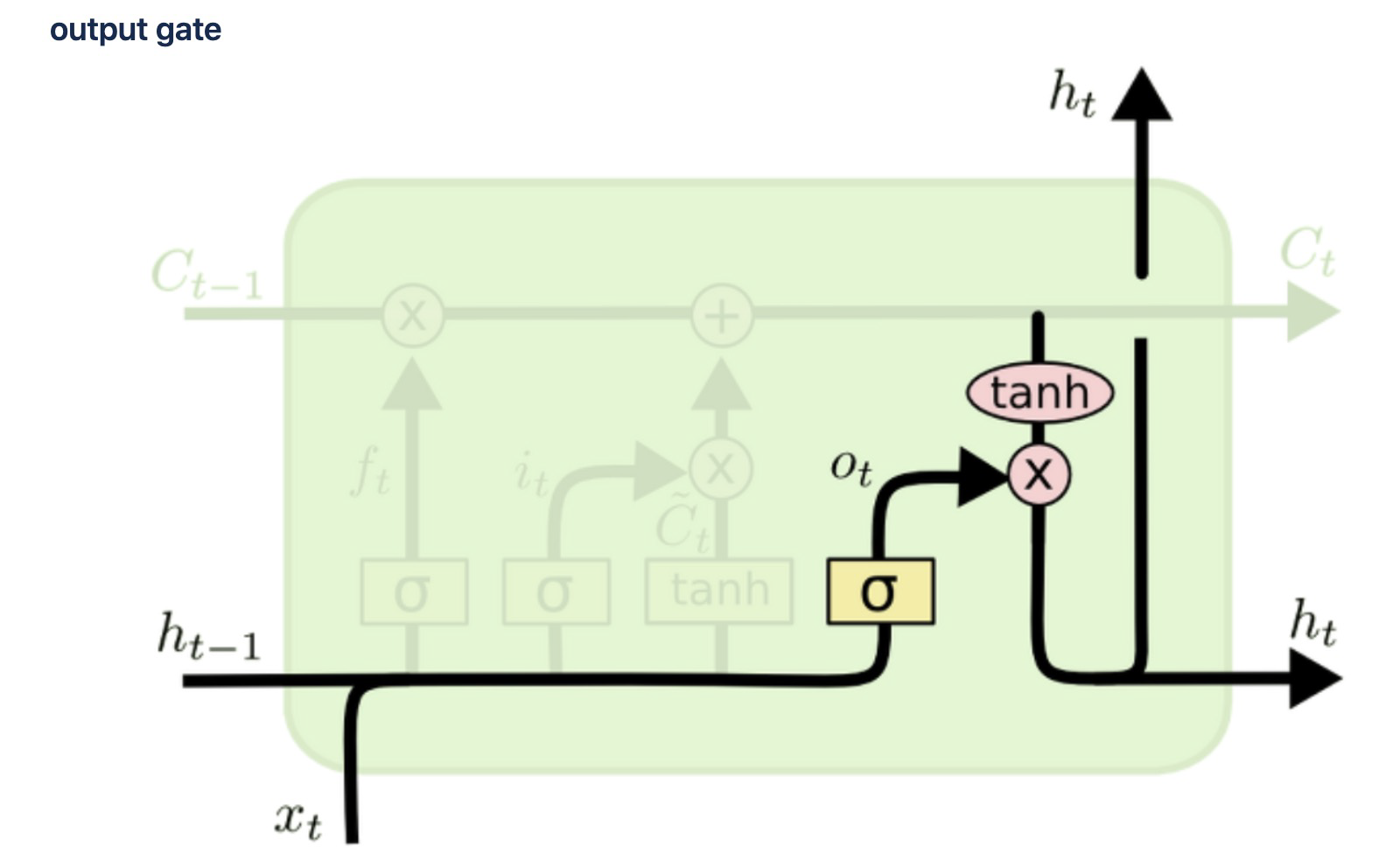
4) output gate
- 출력 게이트 & 은닉 상태(단기 상태)
- 현재 시점 t의 x값과 이전 시점 t-1의 은닉 상태가 시그모이드 함수를 지난 값이다. 해당 값은 현재 시점 t의 은닉 상태를 결정하는 일에 쓰이게 된다.
- 은닉 상태는 장기 상태의 값이 하이퍼볼릭탄젠트 함수를 지나 -1과 1사이의 값이다. 해당 값은 출력 게이트의 값과 연산되면서, 값이 걸러지는 효과가 발생한다. 단기 상태의 값은 또한 출력층으로도 향한다.
실습
1. 데이터
X = []
Y = []
for i in range(3000):
lst = np.random.rand(100)
idx = np.random.choice(100,2, replace=False)
zeros = np.zeros(100)
zeros[idx] = 1
X.append(np.array(list(zip(zeros, lst))))
Y.append(np.prod(lst[idx]))
print(X[0], Y[0])
'''
[[1. 0.30630322]
[0. 0.14278013]
[0. 0.96178476]
[0. 0.02242287]
[0. 0.34139033]
[0. 0.54767334]
[0. 0.58360337]
[0. 0.75452914]
.
.
.
'''2. RNN부터 확인
model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(units=30, return_sequences=True, input_shape=[100, 2]),
tf.keras.layers.SimpleRNN(units=30),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mse')
model.summary()
# 데이터 준비
X = np.array(X)
Y = np.array(Y)
# 학습
history = model.fit(X[:2500], Y[:2500], epochs=100, validation_split=0.2)
# 시각화
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(history.history['loss'], 'b--', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('Epoch')
plt.legend()
plt.show()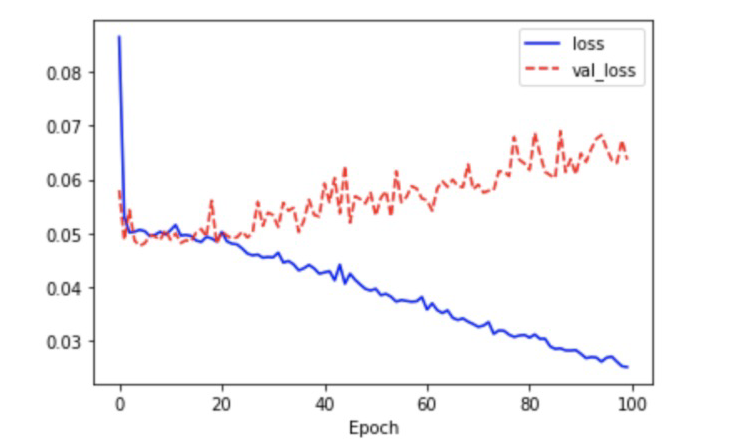
3. LSTM
- 조건은 동일
# 모델
model = tf.keras.Sequential([
tf.keras.layers.LSTM(units=30, return_sequences=True, input_shape=[100, 2]),
tf.keras.layers.LSTM(units=30),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mse')
model.summary()
X = np.array(X)
Y = np.array(Y)
# 학습
history = model.fit(X[:2500], Y[:2500], epochs=100, validation_split=0.2)
# 시각화
plt.plot(history.history['loss'], 'b--', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('Epoch')
plt.legend()
plt.show()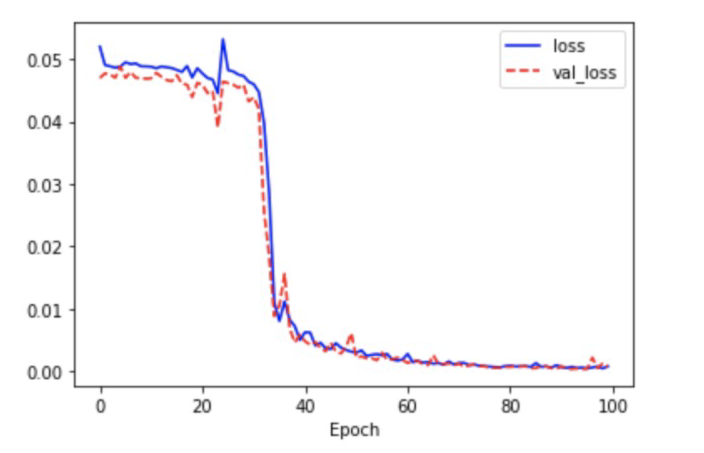
Reference
1) 제로베이스 데이터스쿨 강의자료
2) https://omicro03.medium.com/%EC%9E%90%EC%97%B0%EC%96%B4%EC%B2%98%EB%A6%AC-nlp-12%EC%9D%BC%EC%B0%A8-ltsm-81c9751afafb

데이터 사이언스 / just do it