딥러닝-Tensorflow
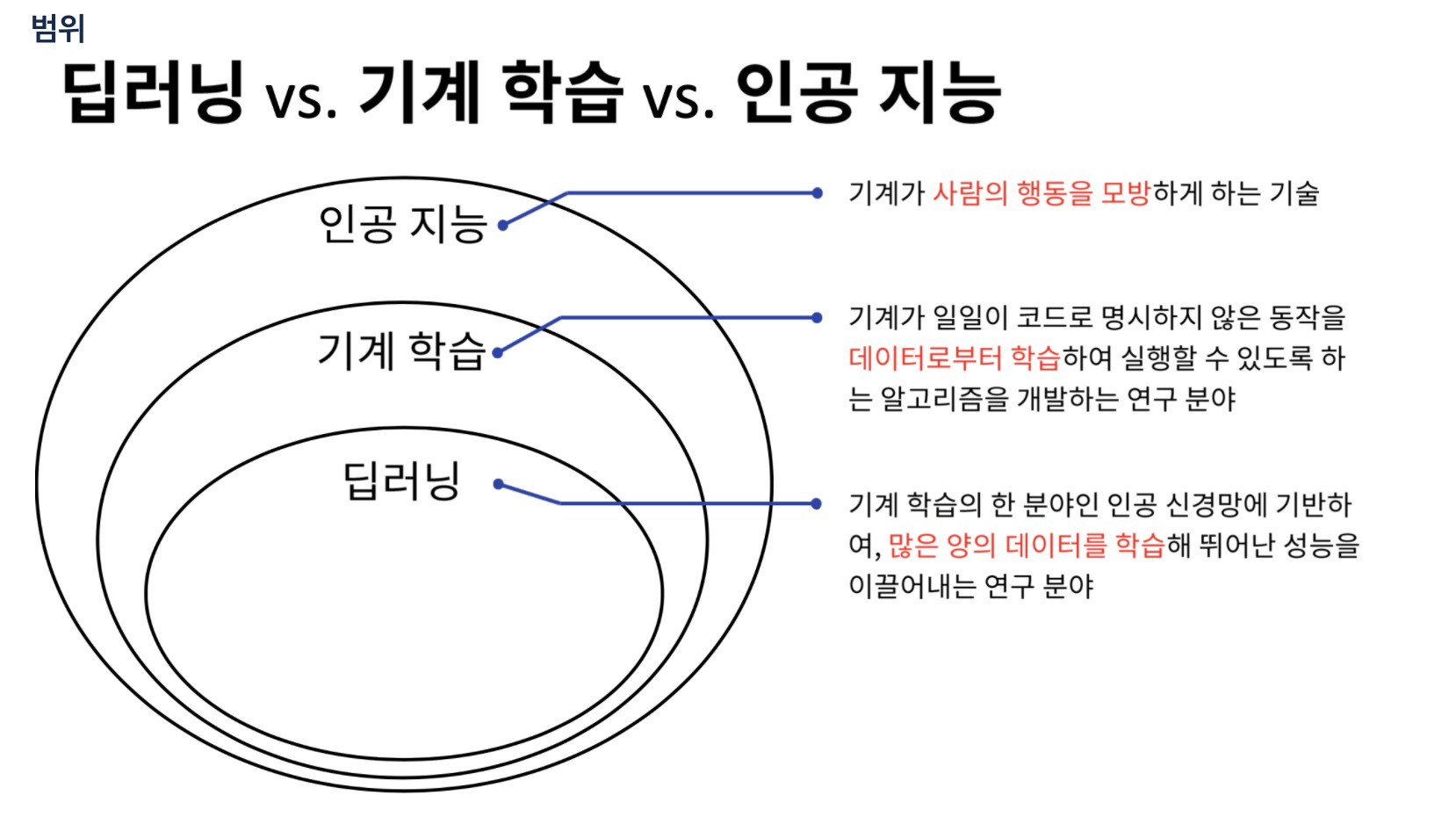
1.딥러닝 기초
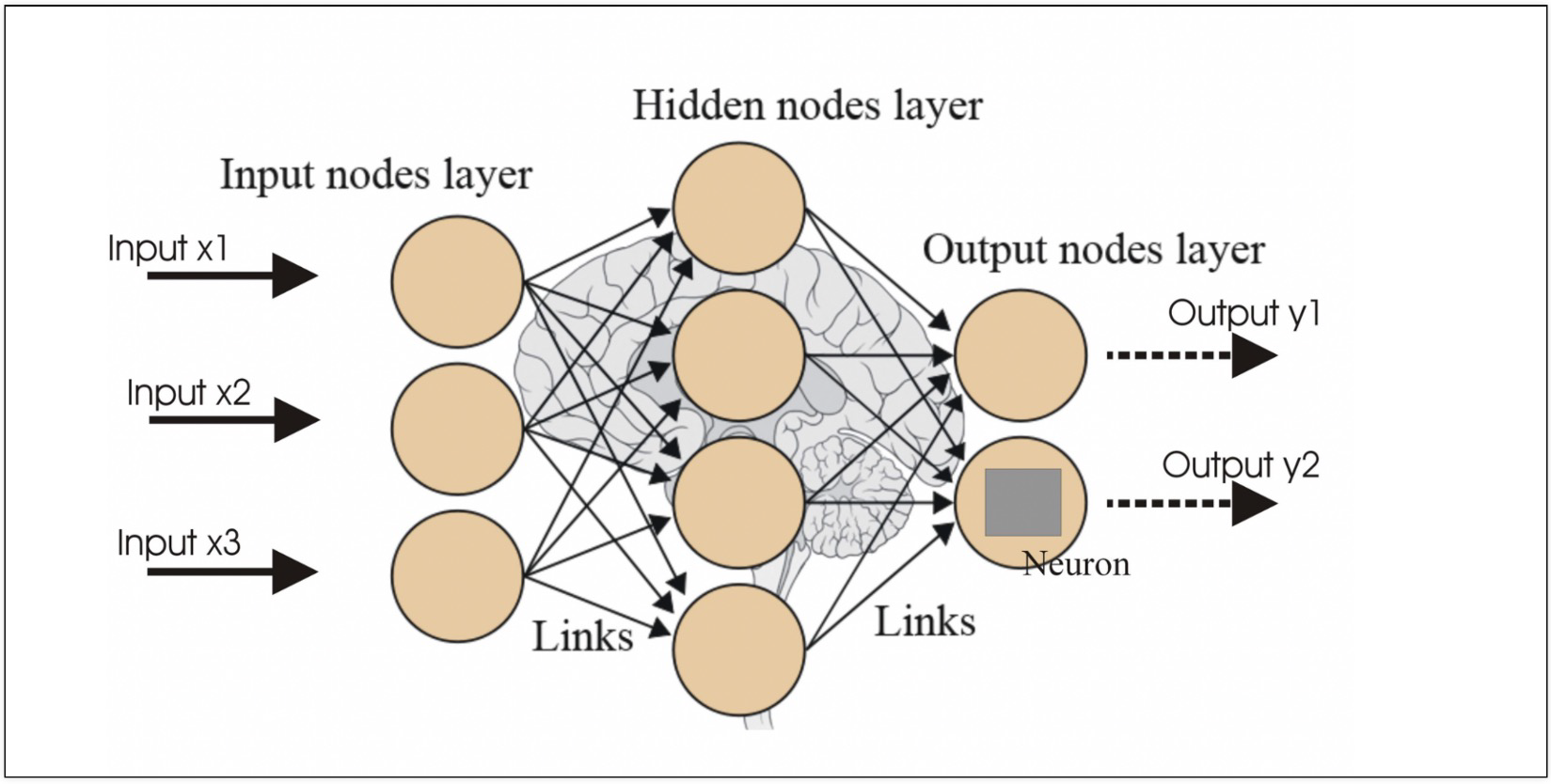
뉴런은 입력, 가중치, 활성화함수, 출력으로 구성뉴런에서 학습할 때 변하는 것은 가중치. 처음에는 초기화를 통해 랜덤값을 넣고, 학습과정에서 일정한 값으로 수렴모델 선택, 모델의 각 activation function 선택, 전체 layer 에러를 잡는 loss fun
2.딥러닝 기초 실습
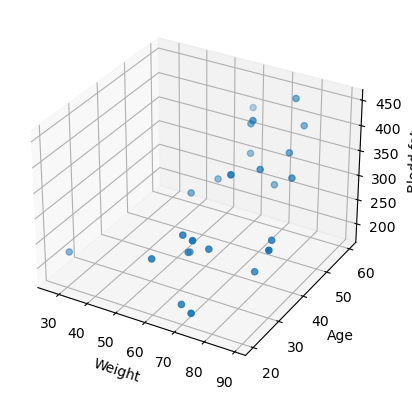
목적: input - age & weight / output - blood fatLinear Regression (y = Wx + b)뉴런 하나만 사용X: age, weight 데이터만 선택 행렬 (25, 2) & W (2, 1) → (25, 1)y: blood fat
3.XOR
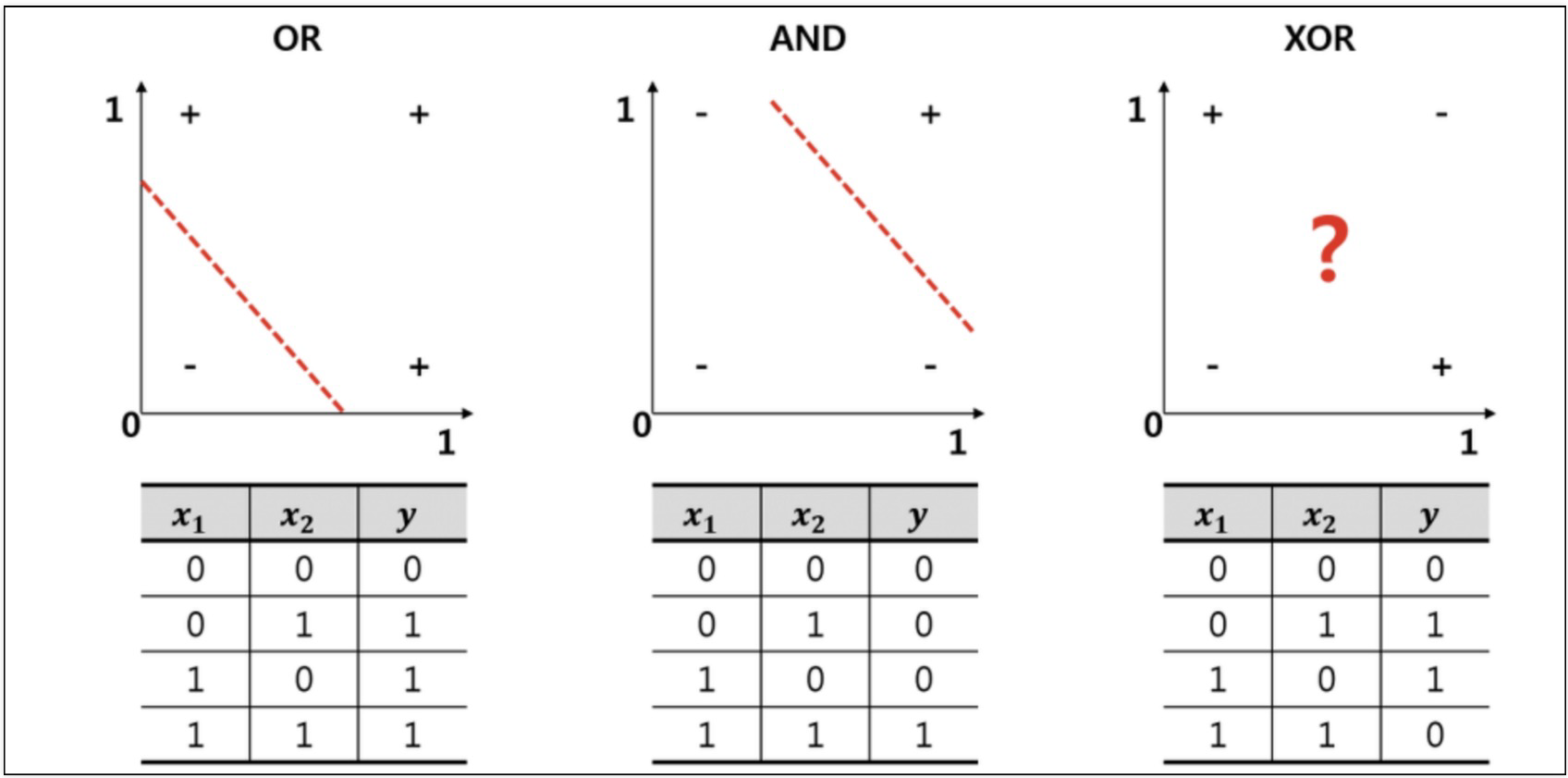
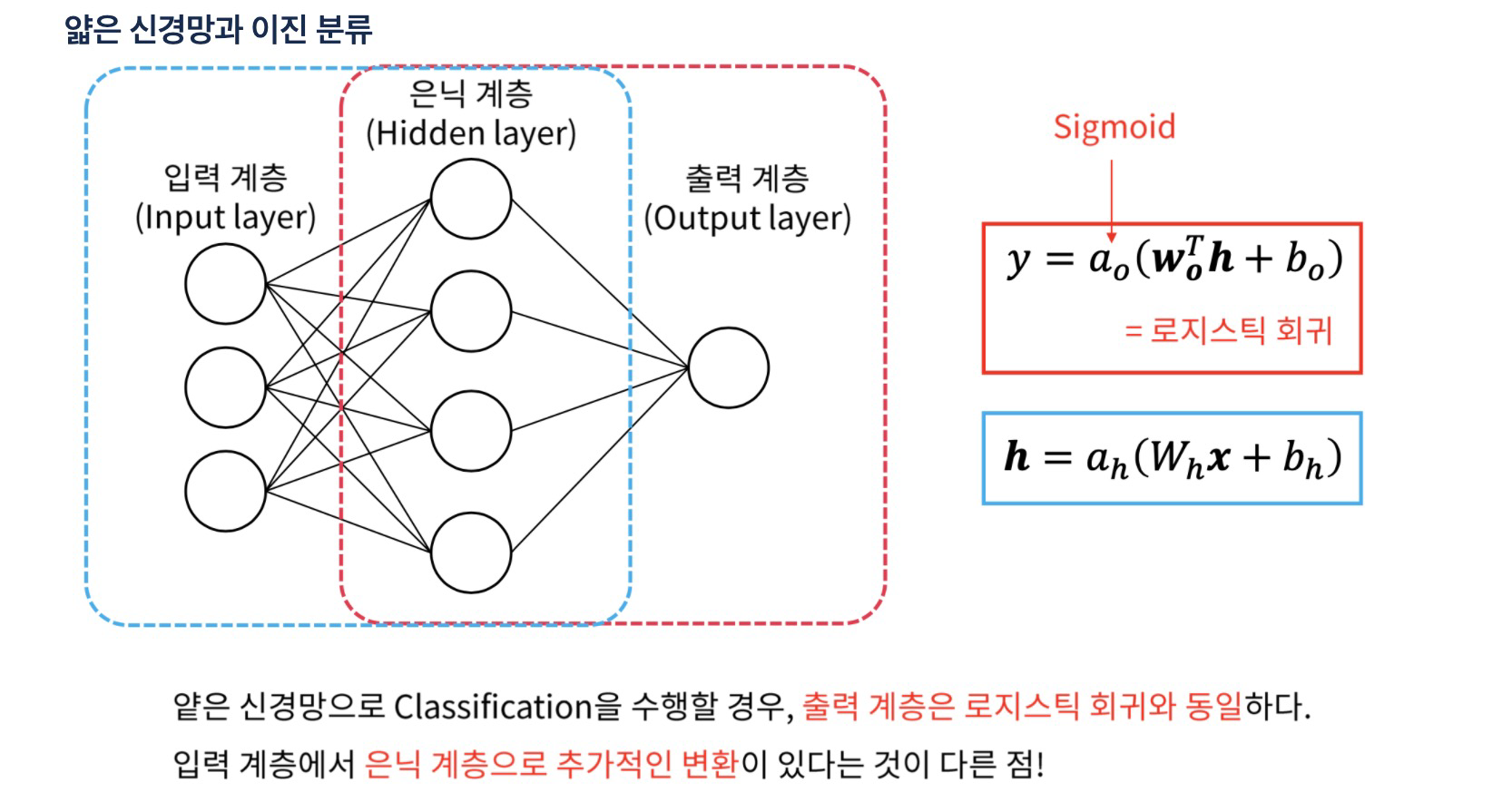
OR : 둘 중에 하나라도 1이면 1AND : 둘 다 1이면 1XOR : 둘이 다를 때만 1 → 직선으로 해결할 수 없다. 즉, 뉴런 2개 필요찾아야할 미지수 9개activation : 활성화함수를 설정linear : 디폴트 값으로 입력값과 가중치로 계산된 결과 값이
4.Activation
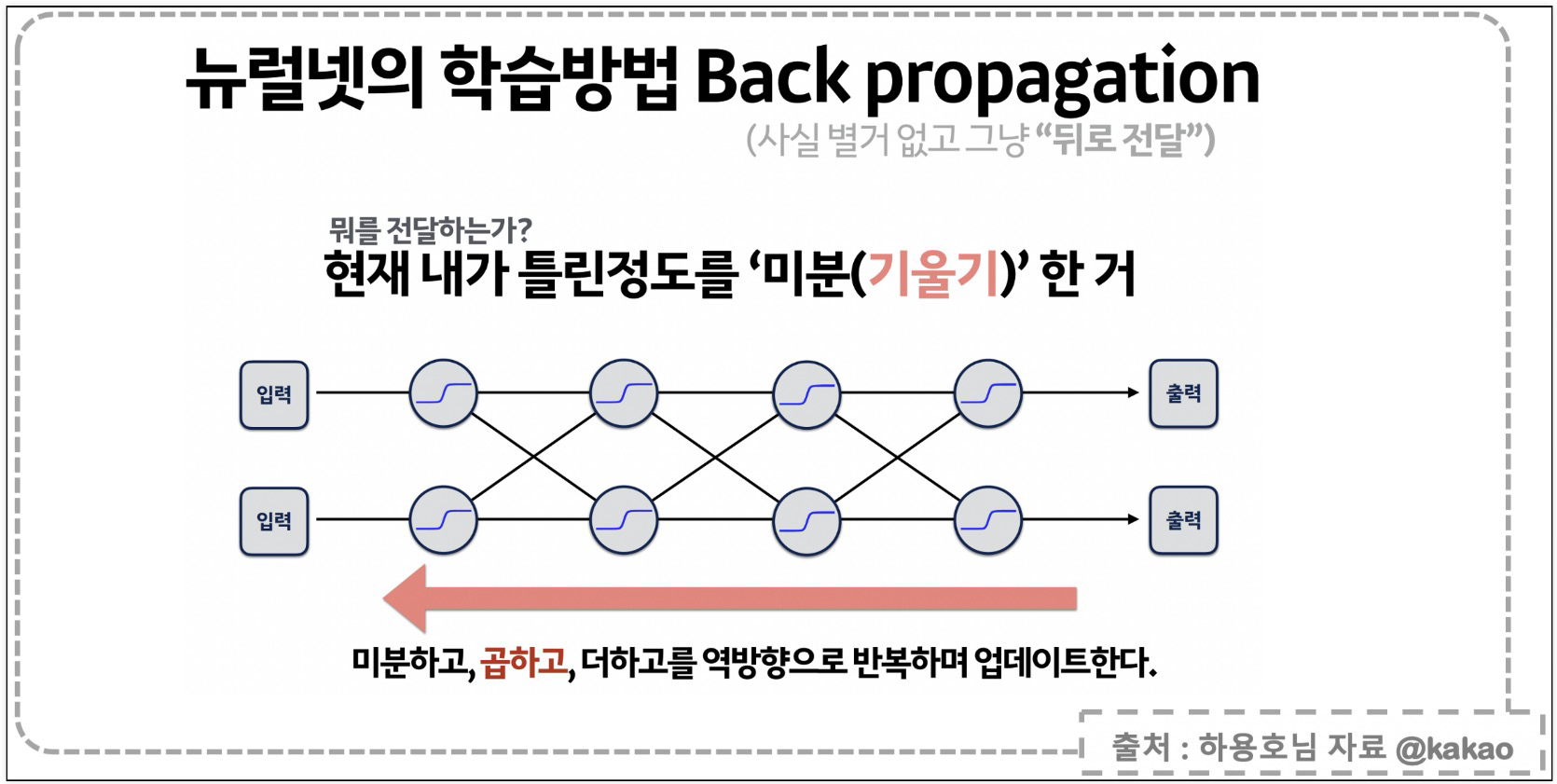
오차를 뒤로 전달해서 사이에서 알 수 없었던 오차 값을 주는 것$\\sum n개 출력값의 확률 = 1$ , 이중 가장 높은 값을 정답이라고 한다Reference1) 제로베이스 데이터스쿨 강의자료2) https://steadiness-193.tistory.com
5.Optimizer

데이터가 복잡할 때는 일단 AdamReference1) 제로베이스 데이터스쿨 강의자료2) https://steadiness-193.tistory.com/244
6.딥러닝 기초2
현업에서 점차 분리되고 있는 분위기이나, 일단 정의된 내용이다.빅데이터: 데이터 베이스 관리, 데이터 저장/ 유통, 데이터 수집, 데이터 신뢰성 확보, 데이터 시각화, 데이터 통계 분석, 데이터 마이닝DL - 분류, 회귀, 물체검출, 영상분할, 영상 초해상도, 예술 창
7.딥러닝 수학적 표현
내적: 같은 위치에 있는 요소끼리 곱한 값들의 합모델별로 상대적으로 작아지는 것을 선택하는 것이 중요변수가 하나 추가될 때마다 차원이 하나씩 추가 (직선 → 평면 → 초평면)은닉층의 효과: 선형적으로 분포되지 않는 입력이 선형적으로 분포하는 은닉계층(특징)을 만나면 선
8.딥러닝 numpy로 계산
입력을 주고 출력을 관찰하는 것이 추론, 순방향 연산1) 임의의 데이터 2) 가중치를 랜덤하게 선택\-1 ~ 1 사이의 랜덤한 실수 값을 가지는 1x3 크기의 가중치 배열3) 활성화 함수 - sigmoid 함수4) 추론 결과1) 지도학습을 위해 정답을 줌2) 모델의 출
9.iris 분류 딥러닝
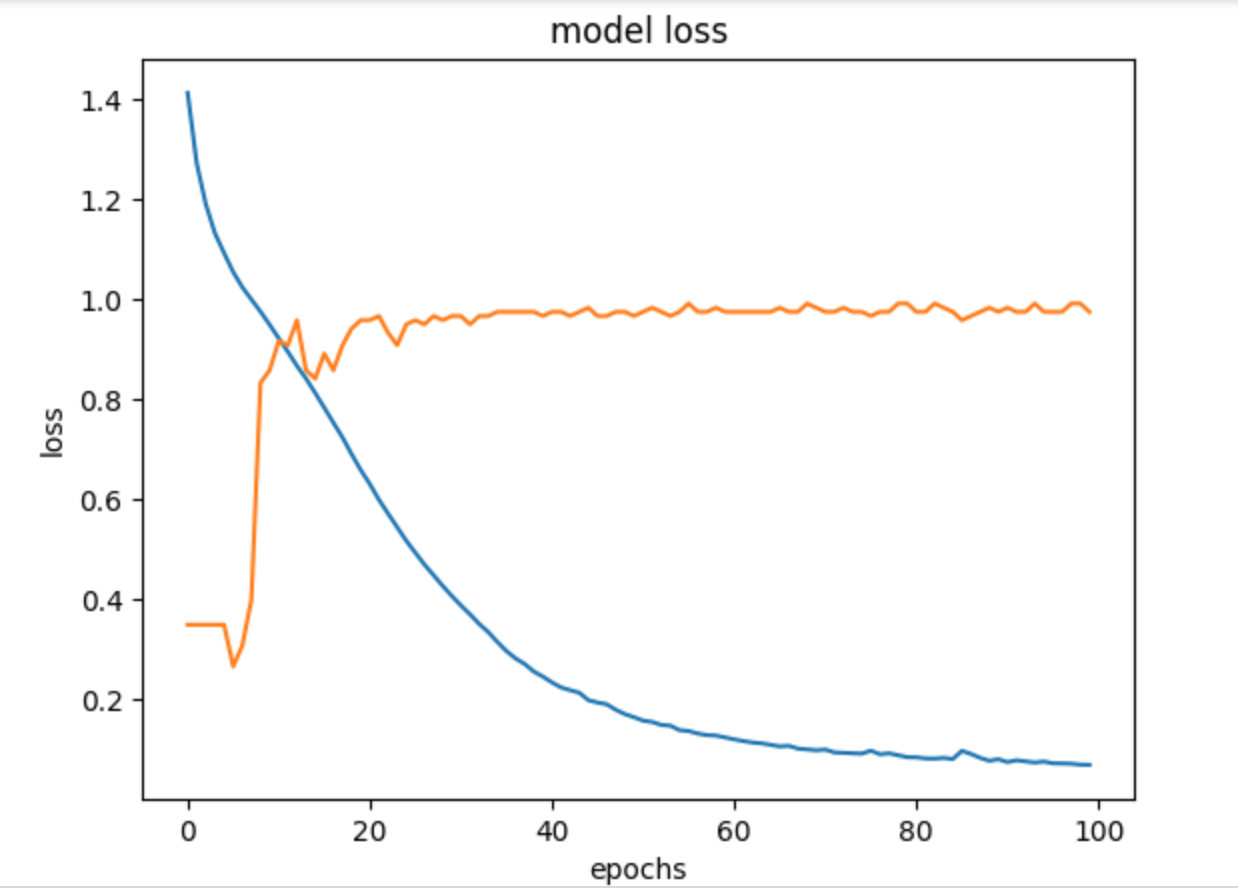
y 값 그대로 사용하면 error 값이 y값에 영향을 받아서 편향된 결과를 가져올 수 있다. 이것을 막기위해 OneHotEncoder 을 사용OneHotEncoder :n개의 범주형 데이터를 n개의 비트(0, 1) 벡터로 표현주의:1) 판다스의 시리즈가 아닌 numpy
10.MNIST 딥러닝
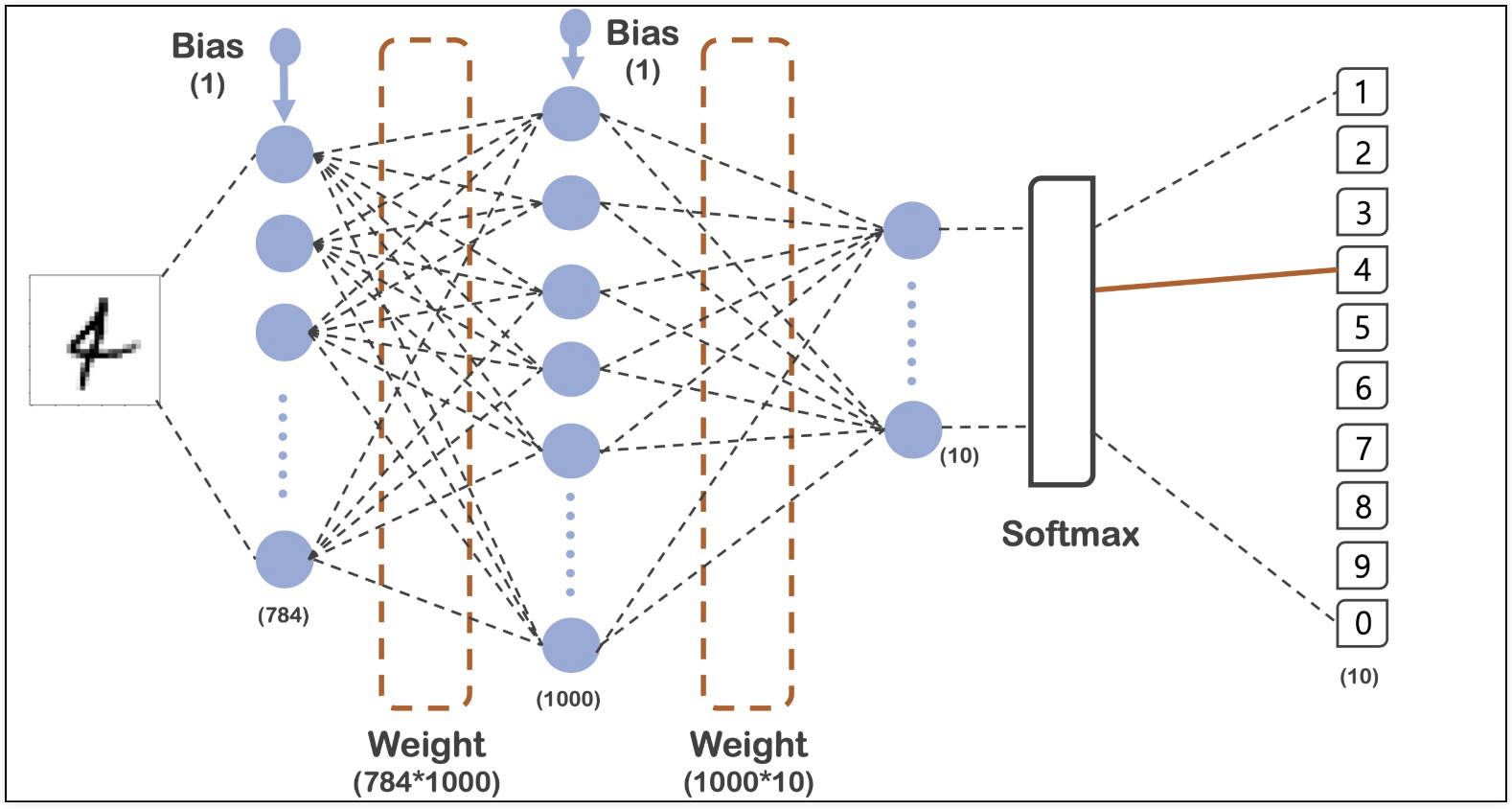
각 픽셀이 255값이 최댓값이어서 0~1사이의 값으로 조정 (일종의 min max scaler)one-hot-encoding → loss='sparse_categorical_crossentropy' 같은 효과머신러닝에서 93%쯤 나왔던 결과대비 5%쯤 향상되었다숫자로
11.CNN
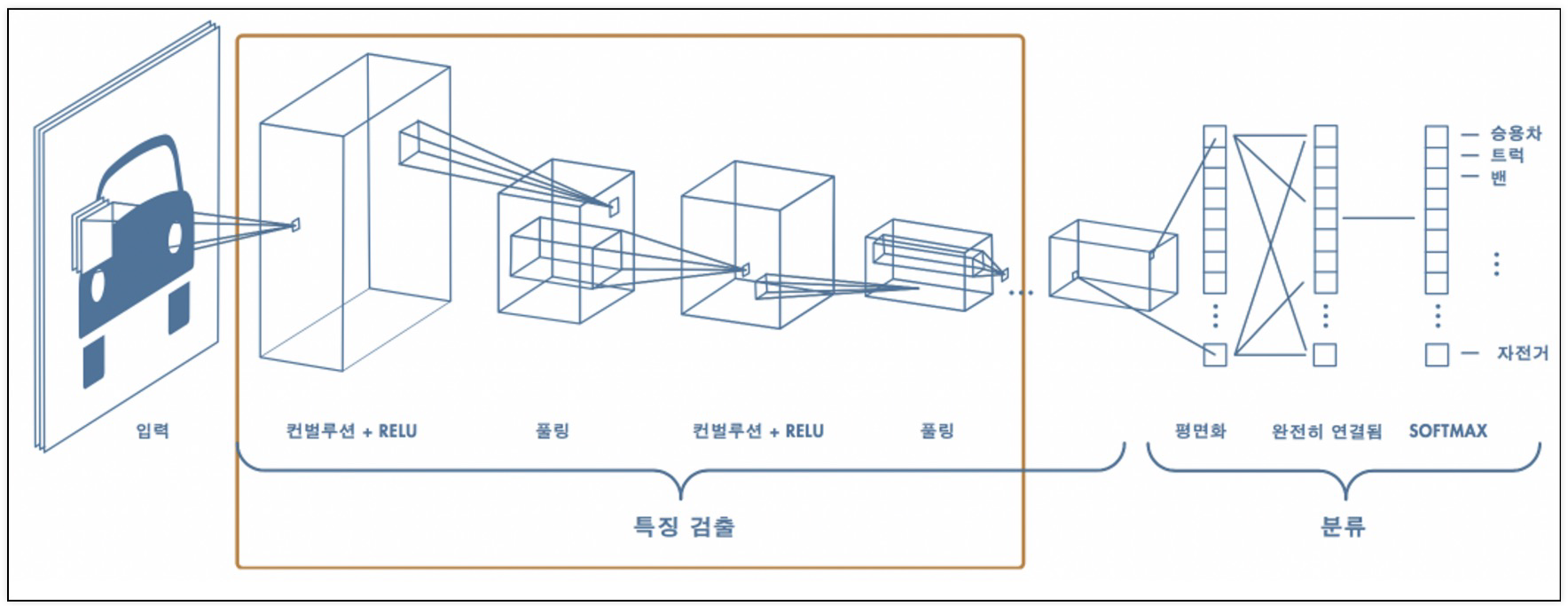
특징 검출학습을 통해 필터까지 구할 수도 있다예시Convolution: 특정 패턴이 있는지 박스로 훓으며 마킹위아래선 필터, 좌우선 필터, 대각선 필터,등등 여러가지 '조각'필터로 해당 패턴이 그림 위에 있는지 확인한다.Convolution 박스로 밀고나면, 숫자가 나
12.CNN(MNIST 데이터 실습)
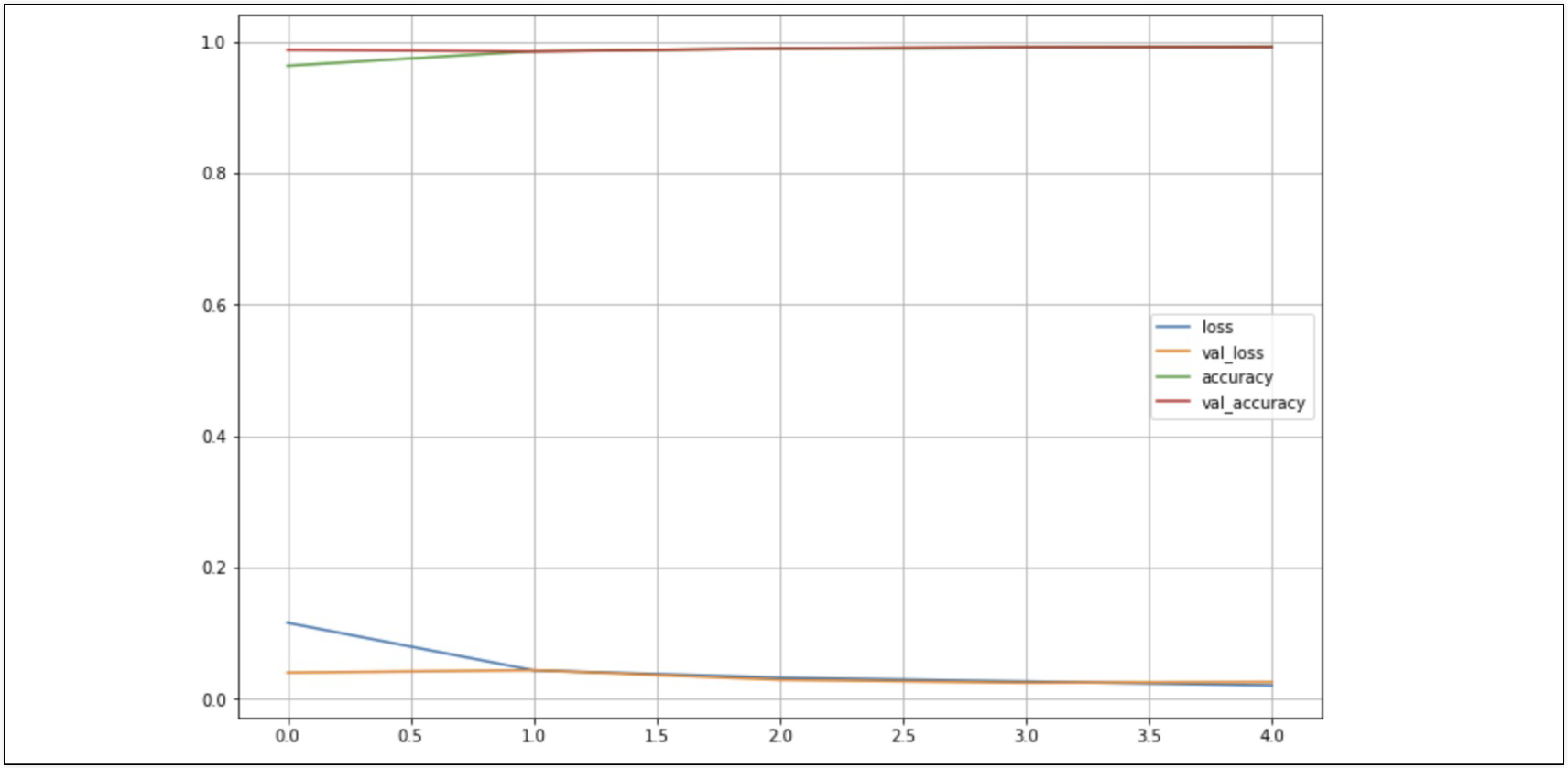
결과가 좋다Reference1) 제로베이스 데이터스쿨 강의자료
13.CNN(MNIST데이터 conv filter)
Reference1) 제로베이스 데이터스쿨 강의자료
14.LeNET(Mask 데이터 실습)

캐글: https://www.kaggle.com/ashishjangra27/face-mask-12k-images-datasetReference1) 제로베이스 데이터스쿨 강의자료
15.오토인코더
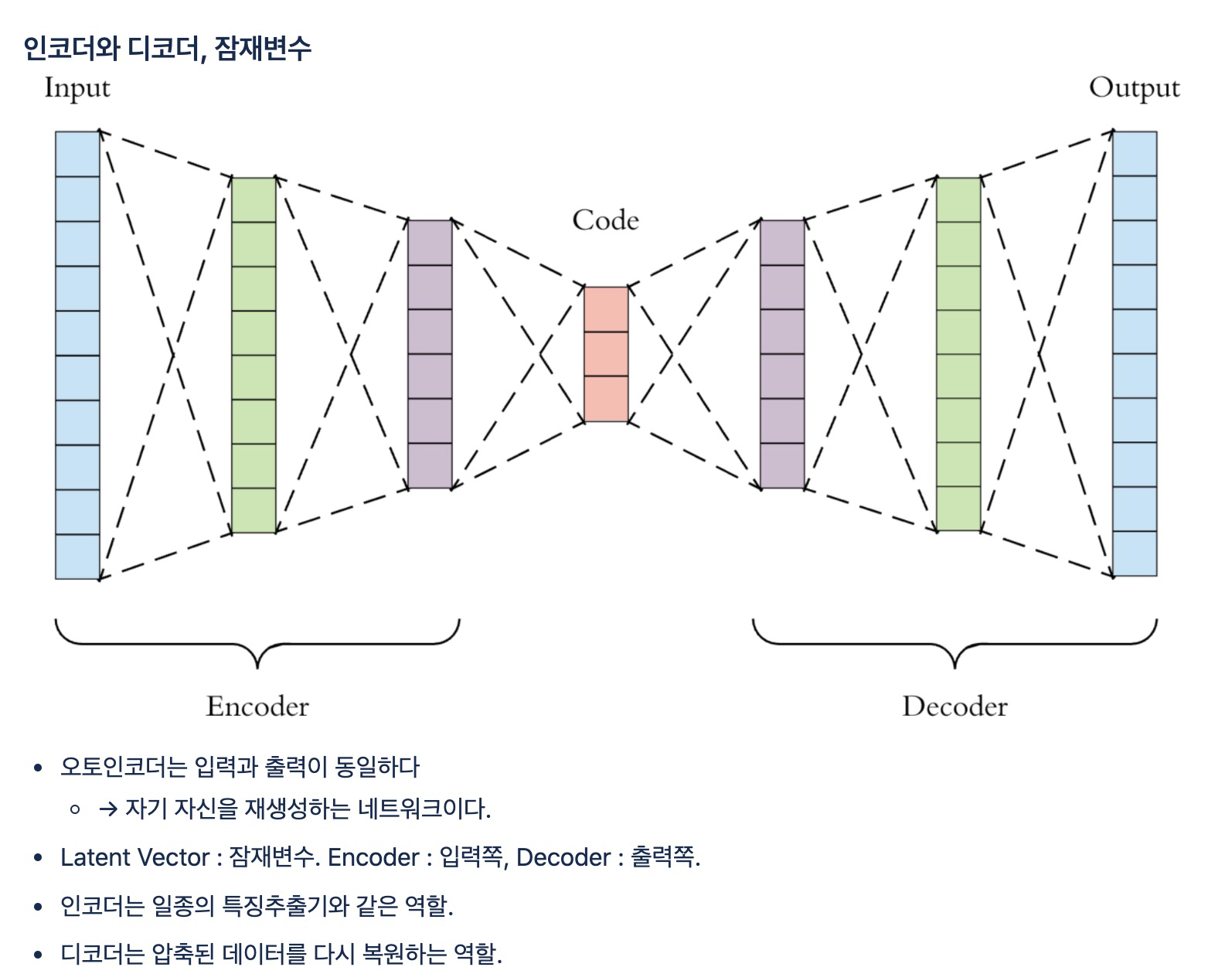
labels\_ : 각 데이터가 0부터 9사이의 어떤 클러스터에 속하는지에 대한 정보가 저장cluster_cetners\_ : 각 클러스터의 중심 좌표가 저장되고, 잠재변수와 마찬가지로 64차원이기 때문에 이 좌표가 각각 무엇을 의미지하는지 직관적으로 알기 어렵다.km
16.RNN
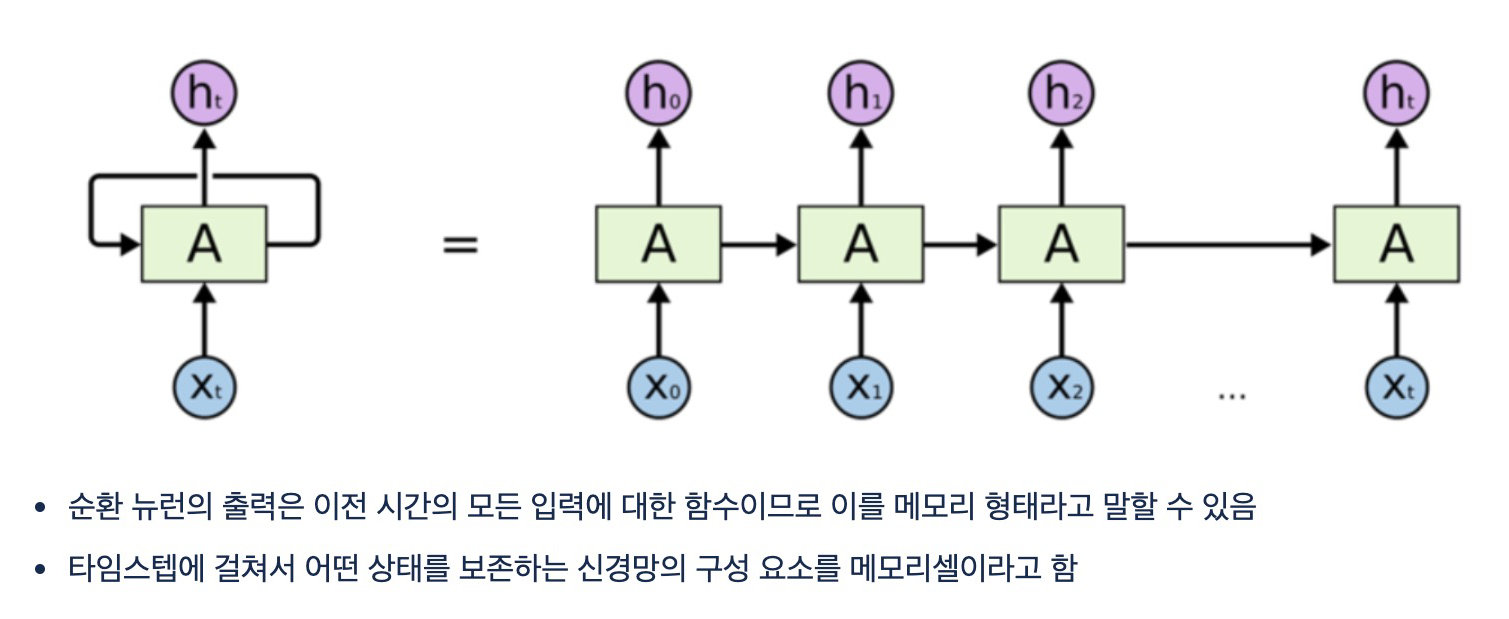
활성화 신호가 입력에서 출력으로 한 방향으로 흐르는 피드포워드 신경망순환 신경망은 뒤쪽으로 연결하는 순환연결이 있음순서가 있는 데이터를 입력 받고 변화하는 입력에 대한 출력을 얻음1) sequence-to-sequence 형태주식가격과 같은 시계열 데이터 예측에 사용최
17.LSTM
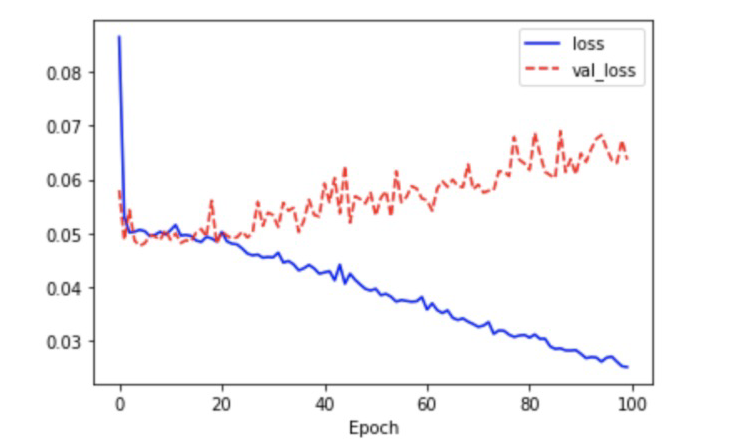
LSTM은 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정한다.현재 정보를 기억하기 위한 게이트기억을 삭제하기 위한 게이트$$Ct = f_t\*C{t-1} + i_t\*g_t$$cell state(
18.감성분석
입력된 자연어 안의 주관적 의견, 감정 등을 찾아내는 문제이중 문장의 긍정/부정 등을 구분하는 경우가 많다데이터의 각 행은 탭 문자(\\t)로 구분각 데이터의 고유한 iddocument는 실제 리뷰 내용label은 긍정/부정을 나타내는 값으로, 0은 부정, 1은 긍정1