감성분석
- 입력된 자연어 안의 주관적 의견, 감정 등을 찾아내는 문제
- 이중 문장의 긍정/부정 등을 구분하는 경우가 많다
1. 데이터 읽기
- 데이터의 각 행은 탭 문자(\t)로 구분
- 각 데이터의 고유한 id
- document는 실제 리뷰 내용
- label은 긍정/부정을 나타내는 값으로, 0은 부정, 1은 긍정
import tensorflow as tf
import numpy as np
import pandas as pd
path_to_train_file = tf.keras.utils.get_file('train.txt', 'https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt')
path_to_test_file = tf.keras.utils.get_file('test.txt', 'https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt')
train_text = open(path_to_train_file, 'rb').read().decode(encoding='utf-8')
test_text = open(path_to_test_file, 'rb').read().decode(encoding='utf-8')
# 텍스트가 총 몇 자인지 확인
print('Length of text: {} characters'.format(len(train_text)))
print('Length of text: {} characters'.format(len(test_text)))
# 처음 300자를 확인
print(train_text[:300])
'''
Length of text: 6937271 characters
Length of text: 2318260 characters
id document label
9976970 아 더빙.. 진짜 짜증나네요 목소리 0
3819312 흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나 1
10265843 너무재밓었다그래서보는것을추천한다 0
9045019 교도소 이야기구먼 ..솔직히 재미는 없다..평점 조정 0
6483659 사이몬페그의 익살스런 연기가 돋보였던 영화!스파이더맨에서 늙어보이기만 했던 커스틴 던스트가 너무나도 이뻐보였다 1
5403919 막 걸음마 뗀 3세부터 초등학교 1학년생인 8살용영화.ㅋㅋㅋ...별반개도 아까움. 0
7797314 원작의
'''2. 학습을 위한 정답 데이터(Y) 만들기
1) 각 텍스트를 개행 문자(\n)로 분리한 다음
2) 헤더에 해당하는 부분(id document label)을 제외한 나머지([1:])에 대해 각 행을 처리
3) 각 행은 탭 문자(\t)로 나눠진 후에 2번째 원소를 정수(integer)로 변환해서 저장
4) np.array로 결과 리스트를 감싸서 네트워크에 입력하기 쉽게 만들기
train_Y = np.array([[int(row.split('\t')[2])]
for row in train_text.split('\n')[1:] if row.count('\t') > 0])
test_Y = np.array([[int(row.split('\t')[2])]
for row in test_text.split('\n')[1:] if row.count('\t') > 0])
print(train_Y.shape, test_Y.shape)
print(train_Y[:5])
'''
(150000, 1) (50000, 1)
[[0]
[1]
[0]
[0]
[1]]
'''3. Cleaning 함수
- tokenization: 자연어를 처리 가능한 최소의 단위로 나누는 것
- cleaning 불필요한 기호를 제거
# train 데이터의 입력(X)에 대한 정제(Cleaning)
import re
# From https://github.com/yoonkim/CNN_sentence/blob/master/process_data.py
def clean_str(string):
string = re.sub(r"[^가-힣A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string)
string = re.sub(r"\'ve", " \'ve", string)
string = re.sub(r"n\'t", " n\'t", string)
string = re.sub(r"\'re", " \'re", string)
string = re.sub(r"\'d", " \'d", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
string = re.sub(r"\'{2,}", "\'", string)
string = re.sub(r"\'", "", string)
return string.lower()4.훈련용 데이터 확보
train_text_X = [row.split('\t')[1] for row in train_text.split('\n')[1:] if row.count('\t') > 0]
train_text_X = [clean_str(sentence) for sentence in train_text_X]
# 문장을 띄어쓰기 단위로 단어 분리
sentences = [sentence.split(' ') for sentence in train_text_X]5. 문장 길이 확인해보기
import matplotlib.pyplot as plt
sentence_len = [len(sentence) for sentence in sentences]
sentence_len.sort()
plt.plot(sentence_len)
plt.show()
print(sum([int(l<=25) for l in sentence_len]))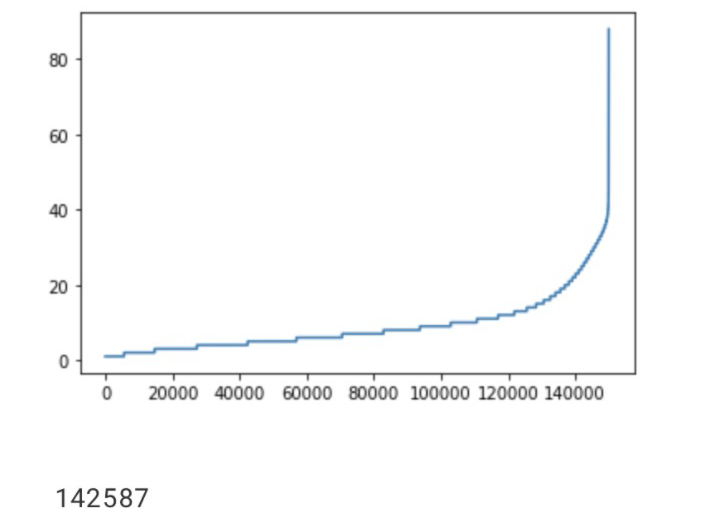
6. 단어의 정제 및 문장 전처리
- 데이터 크기 맞추기: 학습을 위해 네트워크에 입력을 넣을 때 입력 데이터는 그 크기가 같아야 한다. 입력 벡터의 크기를 맞춰야 함
- 긴 문장을 줄이고, 짧은 문장은 공백을 채우기
- 15만개의 문장 중에서 대부분 40단어 이하
sentence_new = []
for sentence in sentences:
sentence_new.append([word[:5] for word in sentence][:25])
sentences = sentence_new
for i in range(5):
print(sentences[i])
'''
['아', '더빙', '진짜', '짜증나네요', '목소리']
['흠', '포스터보고', '초딩영화줄', '오버연기조', '가볍지', '않구나']
['너무재밓었']
['교도소', '이야기구먼', '솔직히', '재미는', '없다', '평점', '조정']
['사이몬페그', '익살스런', '연기가', '돋보였던', '영화', '!', '스파이더맨', '늙어보이기', '했던', '커스틴', '던스트가', '너무나도', '이뻐보였다']
'''7. tokenization
Tokenizer는 데이터에 출현하는 모든 단어의 개수를 세고 빈도 수로 정렬해서num_words에 지정된 만큼만 숫자로 반환하고 나머지는 0으로 반환합니다.tokenizer.fit_on_texts(sentences)는Tokenizer에 데이터를 실제로 입력합니다.tokenizer.texts_to_sequences(sentence)는 문장을 입력받아 숫자를 반환합니다.pad_sequences()는 입력된 데이터에 패딩을 더합니다.
pad_sequences()의 인수에는 pre & post가 있는데,pre는 문장의 앞에 패딩을 넣고,post는 문장의 뒤에 패딩을 넣습니다. 여기에서는 post를 사용합니다.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(num_words=2000)
tokenizer.fit_on_texts(sentences)
train_X = tokenizer.texts_to_sequences(sentences)
train_X = pad_sequences(train_X, padding='post')
print(train_X[:5])
'''
[[ 25 884 8 1111 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0]
[ 588 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0]
[ 71 346 31 35 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0]
[ 106 4 2 869 573 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0]]
'''8. 모델
임베딩 레이어
- Embedding Layer: 자연어를 수치화된 정보로 바꾸기 위한 레이어
- 자연어는 시간의 흐름에 따라 정보가 연속적으로 이어지는 시퀀스 데이터
- 영어는 문자 단위, 한글은 문자를 넘어 자소단위로도 쪼개기도 함. 혹은 띄어쓰기나 형태소로 나누기도 함.
- 여러 단어로 묶어서 사용하는 n-gram 방식도 있음
- 여기서는 원핫인코딩까지 포함
model = tf.keras.Sequential([
tf.keras.layers.Embedding(20000, 300, input_length=25),
tf.keras.layers.LSTM(units=50),
tf.keras.layers.Dense(2, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()9. 학습 & 테스트
history = model.fit(train_X, train_Y, epochs=5, batch_size=128, validation_split=0.2)
# 테스트
test_sentence = '재미있을 줄 알았는데 완전 실망했다. 너무 졸리고 돈이 아까웠다.'
test_sentence = test_sentence.split(' ')
test_sentences = []
now_sentence = []
for word in test_sentence:
now_sentence.append(word)
test_sentences.append(now_sentence[:])
test_X_1 = tokenizer.texts_to_sequences(test_sentences)
test_X_1 = pad_sequences(test_X_1, padding='post', maxlen=25)
prediction = model.predict(test_X_1)
for idx, sentence in enumerate(test_sentences):
print(sentence)
print(prediction[idx])
'''
['재미있을']
[0.5503682 0.44963175]
['재미있을', '줄']
[0.5536265 0.44637352]
['재미있을', '줄', '알았는데']
[0.5636333 0.43636665]
['재미있을', '줄', '알았는데', '완전']
[0.5324937 0.46750632]
['재미있을', '줄', '알았는데', '완전', '실망했다.']
[0.5324937 0.46750632]
['재미있을', '줄', '알았는데', '완전', '실망했다.', '너무']
[0.5381458 0.46185422]
['재미있을', '줄', '알았는데', '완전', '실망했다.', '너무', '졸리고']
[0.5381458 0.46185422]
['재미있을', '줄', '알았는데', '완전', '실망했다.', '너무', '졸리고', '돈이']
[0.9767985 0.02320149]
['재미있을', '줄', '알았는데', '완전', '실망했다.', '너무', '졸리고', '돈이', '아까웠다.']
[0.97679853 0.0232015 ]
'''Reference
1) 제로베이스 데이터스쿨 강의자료
2)
https://dschloe.github.io/python/tensorflow2.0/ch7_3_sentimentanalysis/

데이터 사이언스 / just do it