PIMA 인디언 당뇨병 예측
상관관계 및 Outcome과 다른 특성과의 관계 확인
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.figure(figsize=(12,10))
sns.heatmap(PIMA.corr(), cmap='YlGnBu')
plt.show()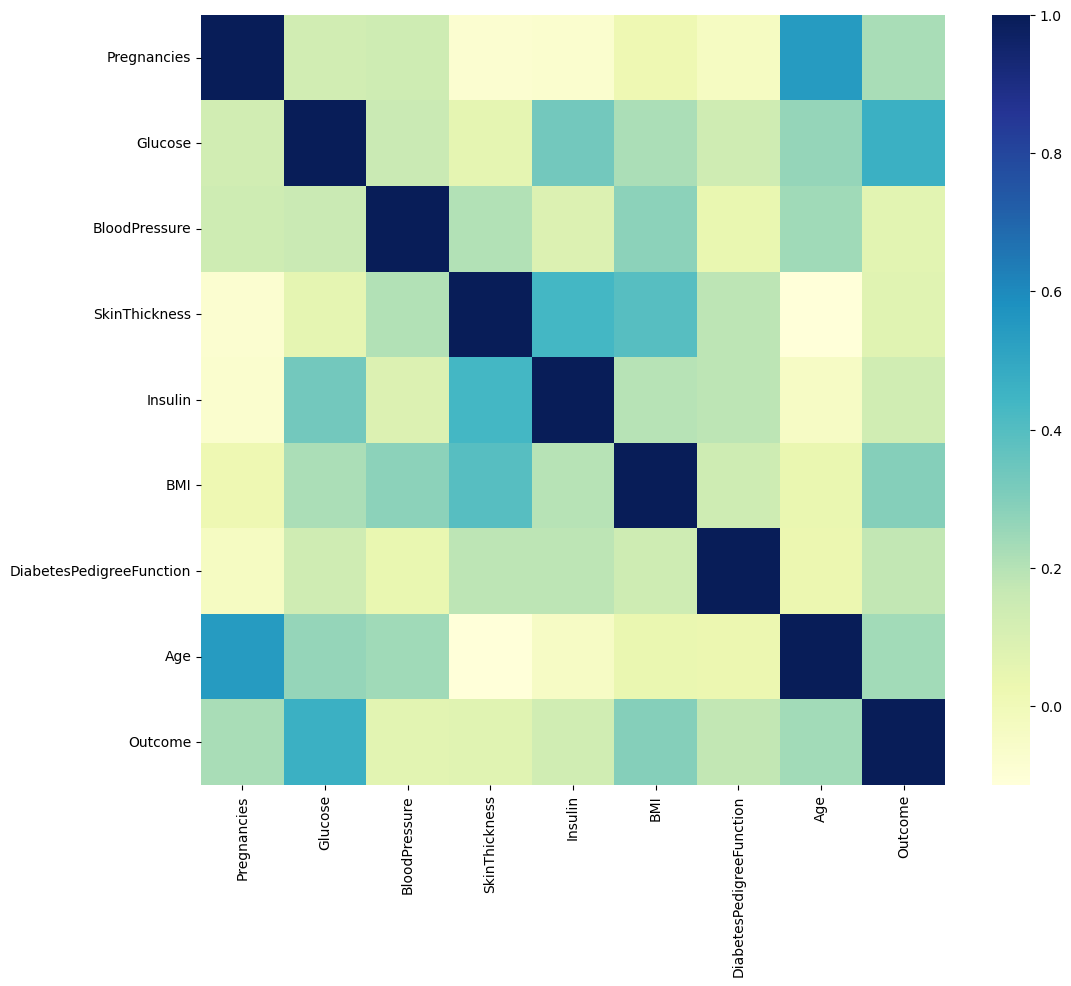
결측치 처리
- null은 아니지만 0인값이 존재한다. 논리적 이상치 존재.
- 시간의 경우 연속된 값으로 앞의 값으로 대체하겠지만 여기서는 평균값으로 대체 → 다양한 방식과 검증이 존재
(PIMA==0).astype(int).sum()
zero_features = ['Glucose', 'BloodPressure', 'SkinThickness', 'BMI']
PIMA[zero_features] = PIMA[zero_features].replace(0, PIMA[zero_features].mean())
(PIMA==0).astype(int).sum()데이터 분리, pipeline 여러 수치
- 현재 수치들은 상대적 의미를 가질 수 없어서 이 수치 자체를 평가할 수는 없다.
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (accuracy_score, recall_score, precision_score, roc_auc_score, f1_score)
X = PIMA.drop(['Outcome'], axis=1)
y = PIMA['Outcome']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13, stratify=y)
estimators = [('scaler', StandardScaler()), ('clf', LogisticRegression(solver='liblinear', random_state=13))]
pipe = Pipeline(estimators)
pipe.fit(X_train, y_train)
pred = pipe.predict(X_test)
print('Accuracy: ', accuracy_score(y_test, pred))
print('Recall: ', recall_score(y_test, pred))
print('Precision: ', precision_score(y_test, pred))
print('AUC score: ', roc_auc_score(y_test, pred))
print('f1 score: ', f1_score(y_test, pred))
'''
Accuracy: 0.7727272727272727
Recall: 0.6111111111111112
Precision: 0.7021276595744681
AUC score: 0.7355555555555556
f1 score: 0.6534653465346535
'''중요 feature 그래프
- 포도당, BMI 등은 당뇨에 영향을 미치는 정도가 높다.
- 혈압은 예측에 부정적 영향을 준다.
- 연령이 BMI보다 츨력 변수와 더 관련되어 있었지만, 모델은 BMI와 Glucose에 더 의존한다.
# 다변수 방정식의 각 계수 값
coeff = list(pipe['clf'].coef_[0])
labels = list(X_train.columns)
features = pd.DataFrame({'Features': labels, 'importance': coeff})
features.sort_values(by=['importance'], inplace=True)
features['positive'] = features['importance'] > 0
features.set_index('Features', inplace=True)
features['importance'].plot(kind='barh', figsize=(11,6), color=features['positive'].map({True:'blue', False:'red'}))
plt.xlabel('Importance')
plt.show()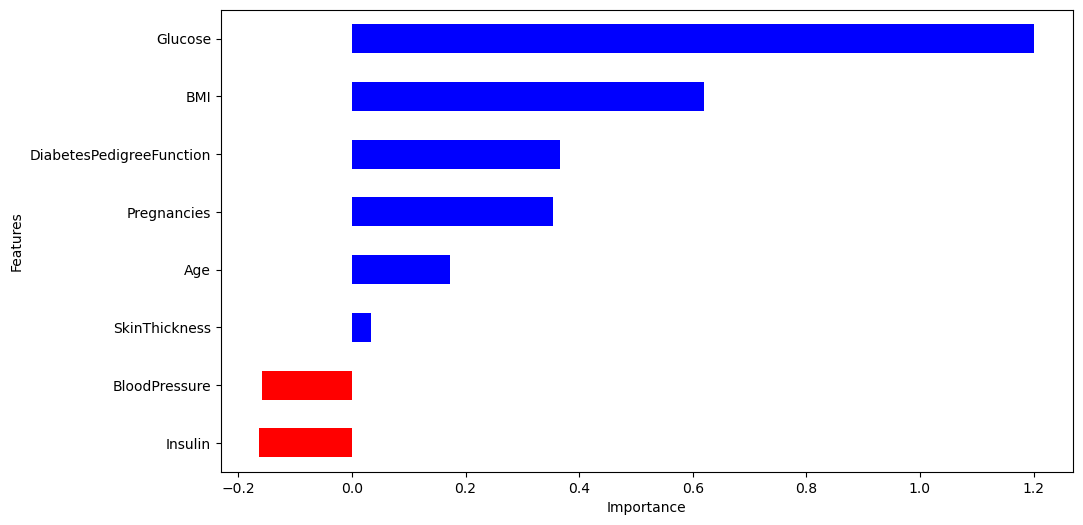
Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it