LogisticRegression
와인 모델 정밀도
- 모델에게 큰 의미가 없어 정밀도를 강제로 조정하지는 않는다.
# 데이터 분리, 간단 로지스틱 회귀 테스트
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 데이터
wine = pd.read_csv(wine_url, index_col=0)
wine['taste'] = [ 1. if grade > 5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
# LogisticRegression
lr = LogisticRegression(solver='liblinear', random_state=13)
lr.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
print('Train Acc: ', accuracy_score(y_train, y_pred_tr))
print('Test Acc: ', accuracy_score(y_test, y_pred_test))classification_report
- weighted avg: 0.58*(477/1300) + 0.84(823/1300) 클래스별 분포를 반영
from sklearn.metrics import classification_report
print(classification_report(y_test, lr.predict(X_test)))
'''
precision recall f1-score support
0.0 0.68 0.58 0.62 477
1.0 0.77 0.84 0.81 823
accuracy 0.74 1300
macro avg 0.73 0.71 0.71 1300
weighted avg 0.74 0.74 0.74 1300
'''confusion_matrix
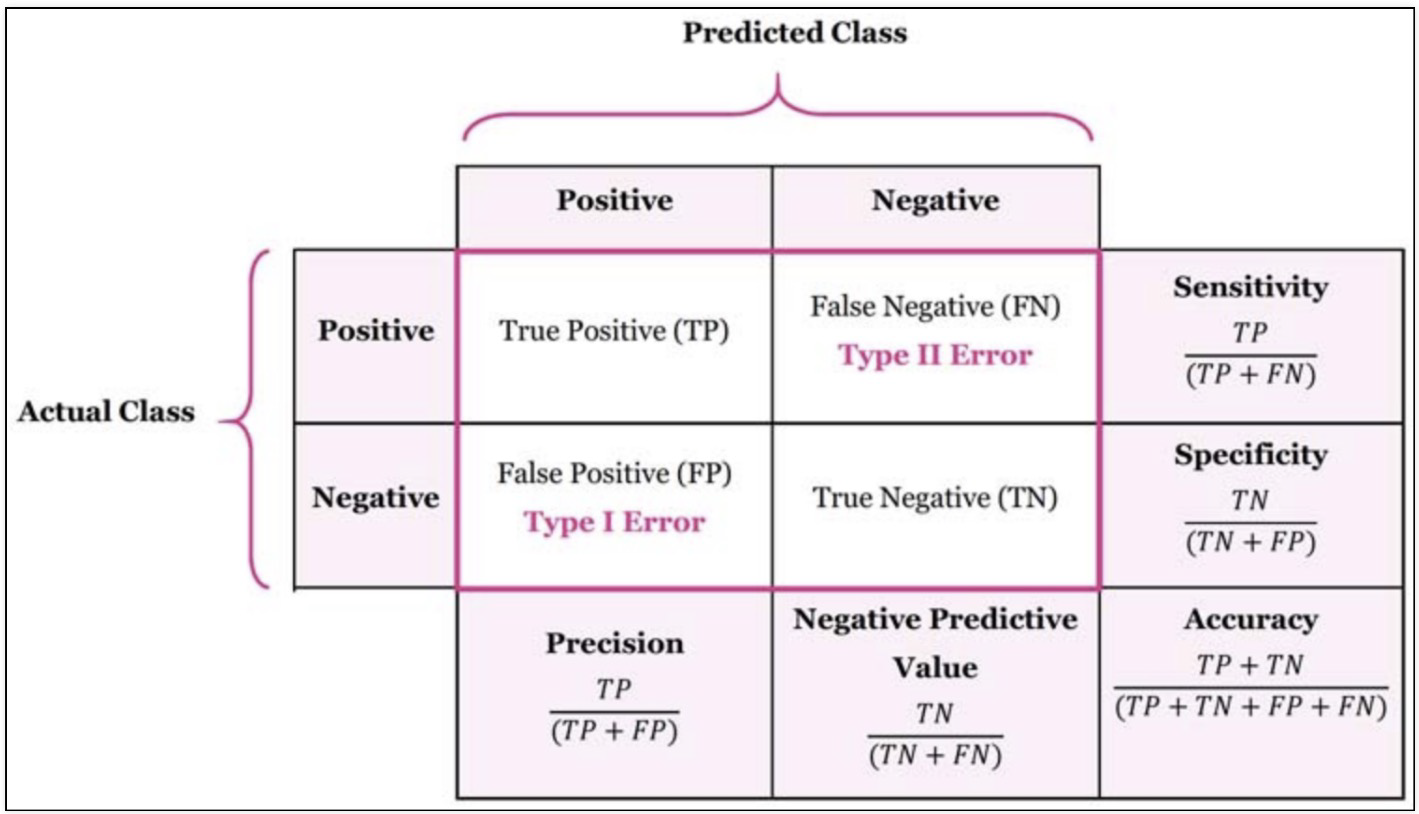
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, lr.predict(X_test)))
'''
[[275 202] TP FN
[131 692]] FP TN
'''precision_recall_curve
from sklearn.metrics import precision_recall_curve
plt.figure(figsize=(10, 8))
pred = lr.predict_proba(X_test)[:, 1] # 1일 확률
precisions, recalls, thresholds = precision_recall_curve(y_test, pred)
plt.plot(thresholds, precisions[:len(thresholds)], label="precision")
plt.plot(thresholds, recalls[:len(thresholds)], label="recall")
plt.grid(); plt.legend(); plt.show()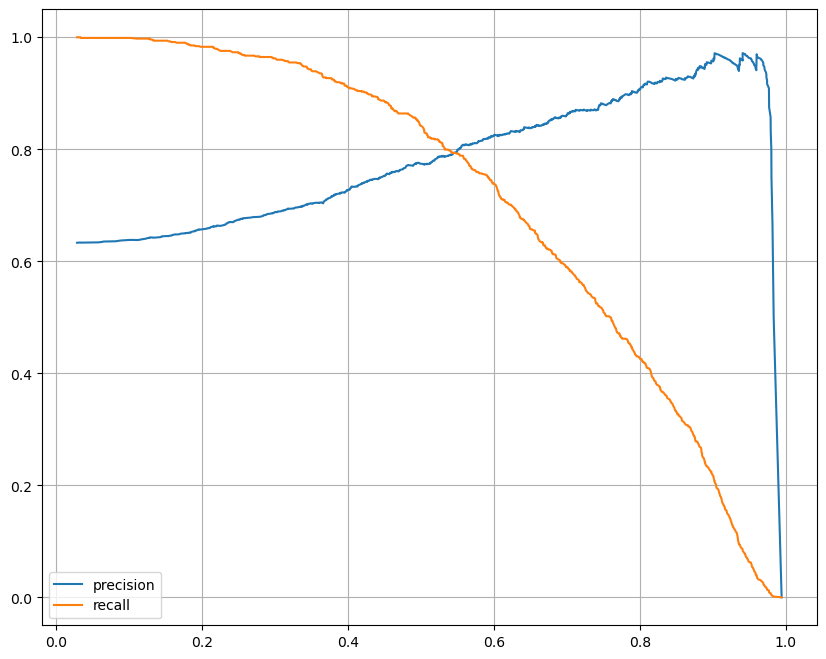
- threshold 바꿔 보기 - Binarizer
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold=0.6).fit(pred_proba)
pred_bin = binarizer.transform(pred_proba)[:, 1]
print(classification_report(y_test, pred_bin))
'''
precision recall f1-score support
0.0 0.62 0.73 0.67 477
1.0 0.82 0.74 0.78 823
accuracy 0.73 1300
macro avg 0.72 0.73 0.72 1300
weighted avg 0.75 0.73 0.74 1300
'''Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it