1. 데이터 준비
1) 이름 분리해서 title
2) title로 귀족과 평민 등급을 구별
3) gender, grade 컬럼 생성 → 머신러닝을 위해 sex, title 숫자로 표현
4) 결측치 제거
import pandas as pd
titanic = pd.read_excel(titanic_url)
# 이름 분리해서 title
import re
title = []
for idx, dataset in titanic.iterrows():
title.append(re.search('\,\s\w+(\s\w+)?\.', dataset['name']).group()[2:-1])
titanic['title'] = title
# 귀족과 평민 등급을 구별
titanic['title'] = titanic['title'].replace('Mlle', 'Miss')
titanic['title'] = titanic['title'].replace('Ms', 'Miss')
titanic['title'] = titanic['title'].replace('Mme', 'Mrs')
Rare_f = ['Dona', 'Dr', 'Lady', 'the Countess']
Rare_m = ['Capt', 'Col', 'Don', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Master']
for each in Rare_f:
titanic['title'] = titanic['title'].replace(each, 'Rare_f')
for each in Rare_m:
titanic['title'] = titanic['title'].replace(each, 'Rare_m')
# gender,grade 컬럼 -> 머신러닝을 위해 숫자로
from sklearn.preprocessing import LabelEncoder
le_gender = LabelEncoder()
le_gender.fit(titanic['sex'])
titanic['gender'] = le_gender.transform(titanic['sex'])
le_grade = LabelEncoder()
le_grade.fit(titanic['title'])
titanic['grade'] = le_grade.transform(titanic['title'])
# null이 아닌 데이터만
titanic = titanic[titanic['age'].notnull()]
titanic = titanic[titanic['fare'].notnull()]2. 데이터 분리 & PCA 입력 출력 함수
import numpy as np
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
X = titanic[['pclass', 'age', 'sibsp', 'parch', 'fare', 'gender', 'grade']].astype(float)
y = titanic['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
def get_pca_data(ss_data, n_components=2):
pca = PCA(n_components=n_components)
pca.fit(ss_data)
return pca.transform(ss_data), pca
def get_pd_from_pca(pca_data, col_num):
cols = ['pca_' + str(n+1) for n in range(col_num)]
return pd.DataFrame(pca_data, columns=cols)
def print_variance_ratio(pca, only_sum=False):
if only_sum == False:
print('variance_ration: ', pca.explained_variance_ratio_)
print('sum of variance_ration: ', np.sum(pca.explained_variance_ratio_))3. 함수 적용
- 2개 축으로 변환
pca_data, pca = get_pca_data(X_train, n_components=2)
print_variance_ratio(pca)
# variance_ration: [0.93577394 0.06326916]
# sum of variance_ration: 0.99904310095112754. 그래프
- 구분 안됨
import seaborn as sns
pca_pd = get_pd_from_pca(pca_data, 2)
pca_pd['survived'] = y_train
sns.pairplot(pca_pd, hue='survived', height=5, x_vars=['pca_1'], y_vars=['pca_2']) 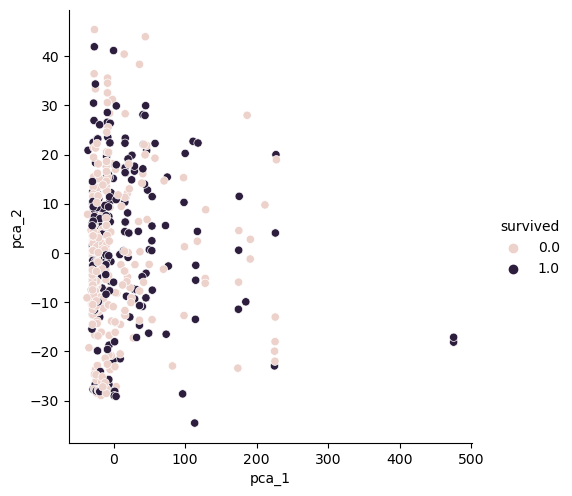
5. 함수 다시 적용
- 3개 축으로 변환
pca_data, pca = get_pca_data(X_train, n_components=3)
print_variance_ratio(pca)
# variance_ration: [9.35773938e-01 6.32691630e-02 4.00903990e-04]
# sum of variance_ration: 0.99944400494135476. pipline 구축
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('pca', PCA(n_components=3)),
('clf', KNeighborsClassifier(n_neighbors=20))
]
pipe = Pipeline(estimators)
pipe.fit(X_train, y_train)
pred = pipe.predict(X_test)
print(accuracy_score(y_test, pred)) # 0.77511961722488047. 디카프리오, 윈슬리 예측
# [['pclass', 'age', 'sibsp', 'parch', 'fare', 'gender', 'grade']]
dicaprio = np.array([[3, 18, 0, 0, 5, 1, 1]])
print('dicaprio: ', pipe.predict_proba(dicaprio)[0, 1]) # 0.1
winslet = np.array([[1, 16, 1, 1, 100, 0, 3]])
print('winslet: ', pipe.predict_proba(winslet)[0, 1]) # 0.85Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it