pandas란
- python에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서서는 최대 효율
- 코딩이 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 누군가 스테로이드를 맞은 엑셀로 표현함
Series
- Pandas의 데이터형을 구성하는 기본
- index & vaule로 이루어져 있다.
- 한 가지 데이터 타입만 가질 수 있다.
- pandas는 통상 pd
- numpy는 통상 np(수치적 해석 함수가 많음)
- pd.date_range(문자열 날짜, 원하는 기간) → 날짜 형성
import pandas as pd
import numpy as np
#Series int
pd.Series([1, 2, 3, 4])
0 1
1 2
2 3
3 4
dtype: int64
#Series 연산
data % 2
0 1
1 0
2 1
3 0
dtype: int64
#Series float -> pandas 기본 문법 참고해서 np를 삽입
pd.Series([1, 2, 3, 4], dtype=np.float64)
0 1.0
1 2.0
2 3.0
3 4.0
dtype: float64
#Series str -> pandas에서는 object
pd.Series([1, 2, 3, 4], dtype=str)
0 1
1 2
2 3
3 4
dtype: object
#Series np.array
pd.Series(np.array([1, 2, 3]))
0 1
1 2
2 3
dtype: int64
#Series dictionary
pd.Series({"key": "value"})
key value
dtype: object
#dtype 섞이면 한 타입으로만 나옴 -> objcet때문에 연산 안 됨
data = pd.Series([1, 2, 3, 4, "S"])
data
0 1
1 2
2 3
3 4
4 S
dtype: object
#date_range
dtype='datetime64[ns]'
dates = pd.date_range("20230501", periods=6)
dates
DatetimeIndex(['2023-05-01', '2023-05-02', '2023-05-03', '2023-05-04',
'2023-05-05', '2023-05-06'],
dtype='datetime64[ns]', freq='D')DataFrame
- pd.DataFrame(): index, vaule, column
#표준정규분포에서 샘플링한 난수 생성
data = np.random.randn(6, 4)
data
df = pd.DataFrame(data, index=dates, columns=["A", "B", "C", "D"])
df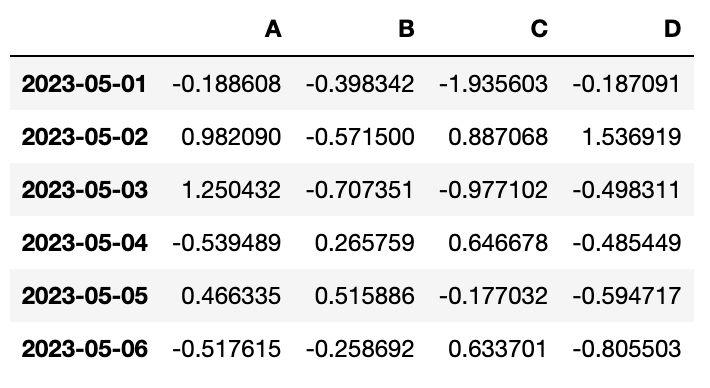
데이터 프레임 검색
#pandas 객체 매소드, 상단 데이터 5개, 숫자를 넣어서 변경가능
df.head()
#하단 데이터 5개, 상단과 합해서 데이터 개수 파악 가능
df.tail()
#pandas 객체 안 변수 & 리스트로 표현
df.index
df.columns
df.values
#데이터 프레임의 기본 정보 확인(class name, DatetimeIndex, Freq, columns, dtype 등)
df.info()
#데이터 프레임의 기술통계 정보 확인(count, mean, std, min, max 등)
df.describe()
데이터 정렬
- sort_values()
- 특정 컬럼(열)을 기준으로 데이터를 정렬
#기준, 오름차순=True or 내림차순=False
df.sort_values(by="B", ascending=False)
#inplace -> 원본 데이터도 정렬
df.sort_values(by="B", ascending=False, inplace=True)데이터 선택
# 한 개 컬럼 선택 -> type: Series
df["A"]
type(df["A"])
#컬럼이 문자이면 문자로만으로도 부를 수 있다. "2"는 안된다
df.A
# 두 개 이상 컬럼 선택
df[["A", "B"]]offset index
[n:m]
- [n:m]: n부터 m-1까지
- 인덱스나 컬럼의 이름으로 slice하는 경우는 끝을 포함한다.
df[0:3]
#문자는 끝까지 slice가 된다(하지만, 정렬되지 않은 상태에서 나누면 끊어져서 나올 수 있다.)
df["20230501":"20230503"] loc
- loc: location
- index 이름으로 특정 행, 열을 선택
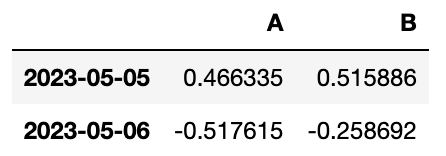
#인덱스는 전부, 컬럼 A, B
df.loc[:, ["A", "B"]]
df.loc["20230505":"20230506", ["A","B"]]
#아래 첫 번째 이미지
df.loc["20230505":"20230506", "A":"D"]
#아래 두 번째 이미지
df.loc["20230505", ["A", "D"]]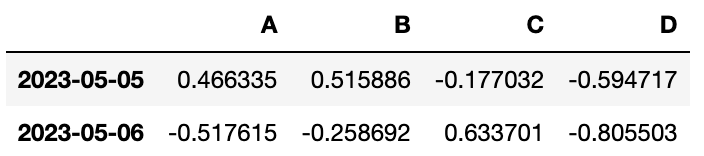
iloc
- iloc: inter location → 컴퓨터가 인식하는 인덱스 값으로 선택
df.iloc[3]
#행, 열(index 기준)
df.iloc[3, 2]
df.iloc[3:5, 0:2]
df.iloc[[1,2,4], [0,2]]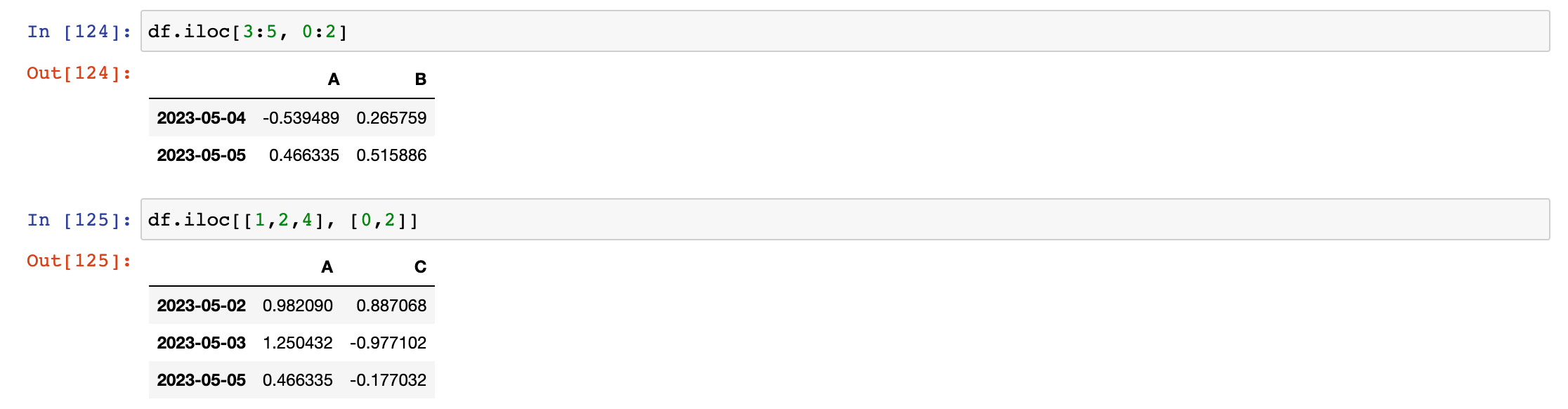
condition
- NaN : Not a Number -> 데이터가 없다
# A컬럼에서 0보다 큰 숫자(양수 선택)
df["A"] > 0
2023-05-01 False
2023-05-02 True
2023-05-03 True
2023-05-04 False
2023-05-05 True
2023-05-06 False
Freq: D, Name: A, dtype: bool
df[df["A"] > 0]
df[df>0]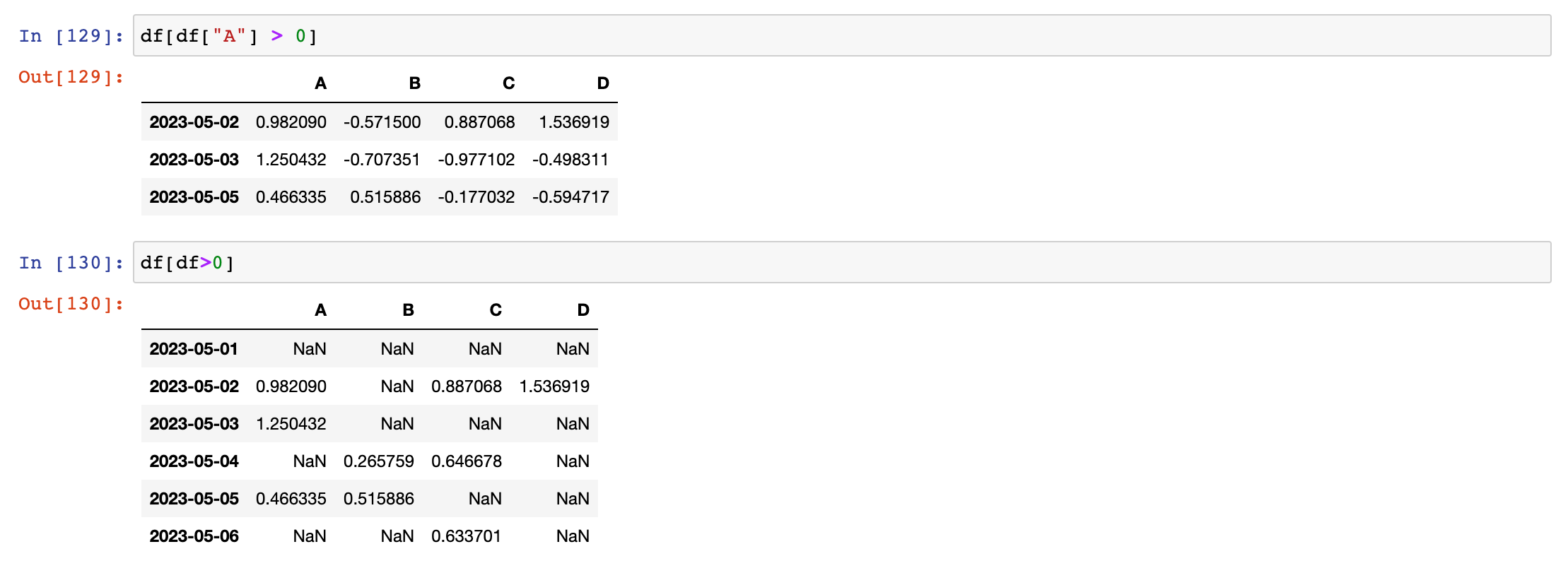
데이터 세기
- count(): 데이터 프레임, 시리즈 둘 다 가능 -> NaN 제외 값
- size: NaN 포함한 값
- value_counts(): 각 종류별로 몇 개의 데이터가 있는지 세기, 데이터 프레임에는 안 되고 특정 칼럼
- unique(): 해당 컬럼에 어떤 종류의 데이터가 있는지 출력, NaN이 포함된 유일값들이 array로 반환
컬럼
컬럼 추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
df["E"] = ["one", "two", "three", "four", "five", "six"]
df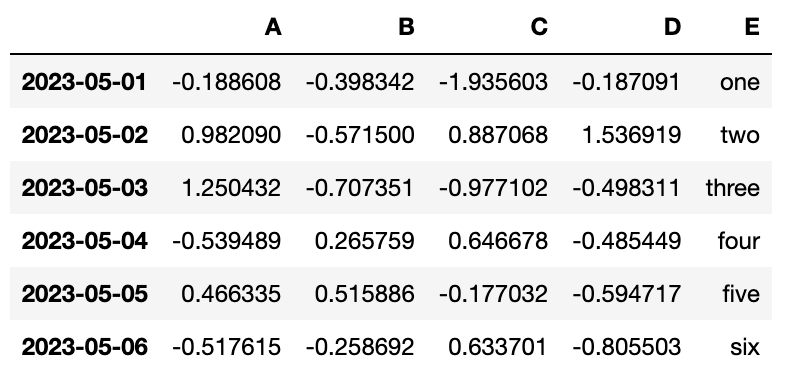
특정 컬럼 제거
- del
- drop
del df["E"]
df
#axis=0 가로, axis=1 세로
df.drop(["D"], axis=1)
df.drop(["20230505"])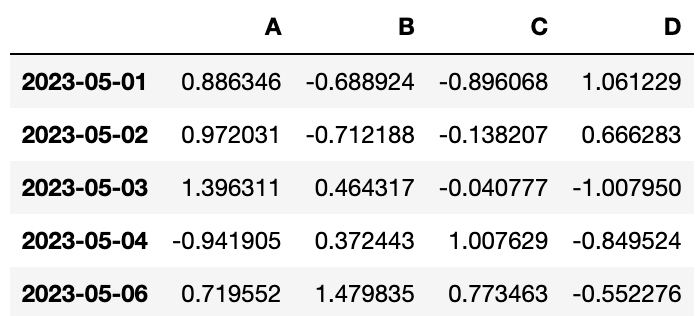
확인
- isin()
- 특정요소가 있는지 확인
df["E"].isin(["two", "five", "three"])
2023-05-01 False
2023-05-02 True
2023-05-03 True
2023-05-04 False
2023-05-05 False
2023-05-06 False
Freq: D, Name: E, dtype: bool
#데이터 프레임으로 출력
df[df["E"].isin(["two", "five", "three"])]apply
#합
df["A"].apply("sum")
#평균
df["A"].apply("mean")
#최소, 최대
df["A"].apply("min"), df["A"].apply("max")
#두 열의 각각 합
df[["A", "D"]].apply("sum")
A 2.094290
D 0.957431
dtype: float64
#pandas는 np를 바탕으로 만든 것이라 np를 주로 사용
df["A"].apply(np.sum)
2023-05-01 0.886346
2023-05-02 0.972031
2023-05-03 1.396311
2023-05-04 -0.941905
2023-05-05 -0.938045
2023-05-06 0.719552
Freq: D, Name: A, dtype: float64
df["A"].apply(np.mean)
df["A"].apply(np.std)
#사용자 함수 apply
def plusminus(num):
return "plus" if num > 0 else "minus"
df["A"].apply(plusminus)
df["A"].apply(lambda num: "plus" if num > 0 else "minus")pandas DataFrame 병합
- 자세한 예시 링크 참고
- pd.concat()
- pd.merge()
- pd.join()
- groupby(): 데이터를 그룹별로 분할하여 독립된 그룹에 대하여 별도로 데이터를 처리하거나 그룹별 통계량을 확인하고자 할 때 유용한 함수(링크 참고)
#딕셔너리 안의 리스트 형태 ->컬럼기준
left = pd.DataFrame({
"key": ["K0", "K4", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"]
})
left
#리스트 안의 딕셔너리 형태 -> 행 기준
right = pd.DataFrame([
{"key":"K0","C":"C0","D":"D0"},
{"key":"K1","C":"C1","D":"D1"},
{"key":"K2","C":"C2","D":"D2"},
{"key":"K3","C":"C3","D":"D3"}
])
rightpd.merge()
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 한다
- 기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야 한다
#key라는 컬럼을 기준으로 잡겠다 -> 교집합 기본
pd.merge(left, right, on="key")
#교집합
pd.merge(left, right, how="inner", on="key")
#합집합
pd.merge(left, right, how="outer", on="key")
#왼쪽에 있는 key라는 컬럼을 기준 -> K4 C, D에는 없어서 NaN값으로 나옴
pd.merge(left, right, how="left", on="key")
#오른쪽에 있는 key라는 컬럼을 기준 -> K1 A, B없어서 Na
pd.merge(left, right, how="right", on="key")pandas pivot
- index, columns, values, aggfunc
- aggfunc: np.mean, np.sum 등(기본 mean값)
- fill_value: NaN 값 설정
- DatFrame.pivot_table(index, value, aggfunc) → 버전에 따라 index와 value 값을 설정하지 않으면 경고문이 뜰 수 있다.
[row data]
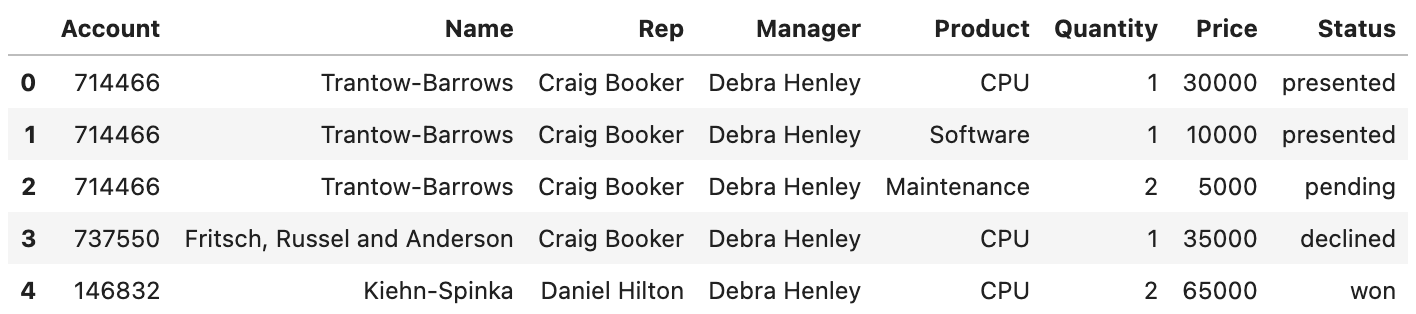
# xlsx가 안 읽혀지면 install 필요
!pip install openpyxl
df = pd.read_excel("../data/02. sales-funnel.xlsx")
# price 컬럼 sum 연산 작용
df.pivot_table(index=["Rep", "Manager"], values="Price", aggfunc=np.sum)
# fill_value
df.pivot_table(index=["Rep", "Manager"], values="Price", columns="Product", aggfunc=np.sum, fill_value=0)
#2개 이상 index, value
df.pivot_table(
index=["Manager", "Rep", "Product"],
values=["Price", "Quantity"],
aggfunc=np.sum,
fill_value=0
)
#aggfunc 2개이상
df.pivot_table(
index=["Manager", "Rep", "Product"],
values=["Price", "Quantity"],
aggfunc=[np.sum, np.mean],
fill_value=0,
margins=True #총계 추가
)[pivot data]
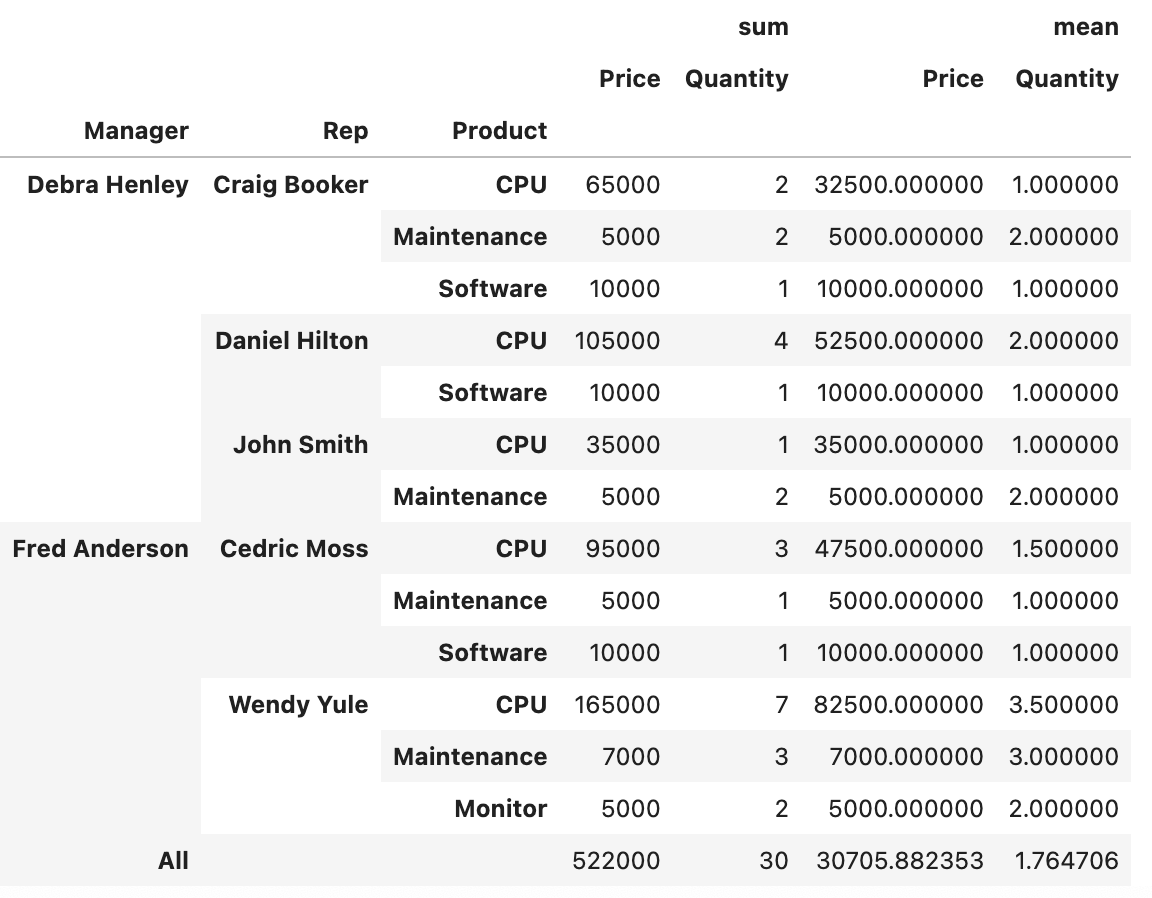
Refrence
1) 제로베이스 데이터스쿨
2) https://yganalyst.github.io/data_handling/Pd_12/
3) https://bigdaheta.tistory.com/46
4) https://teddylee777.github.io/pandas/pandas-groupby/

데이터 사이언스 / just do it