딥러닝
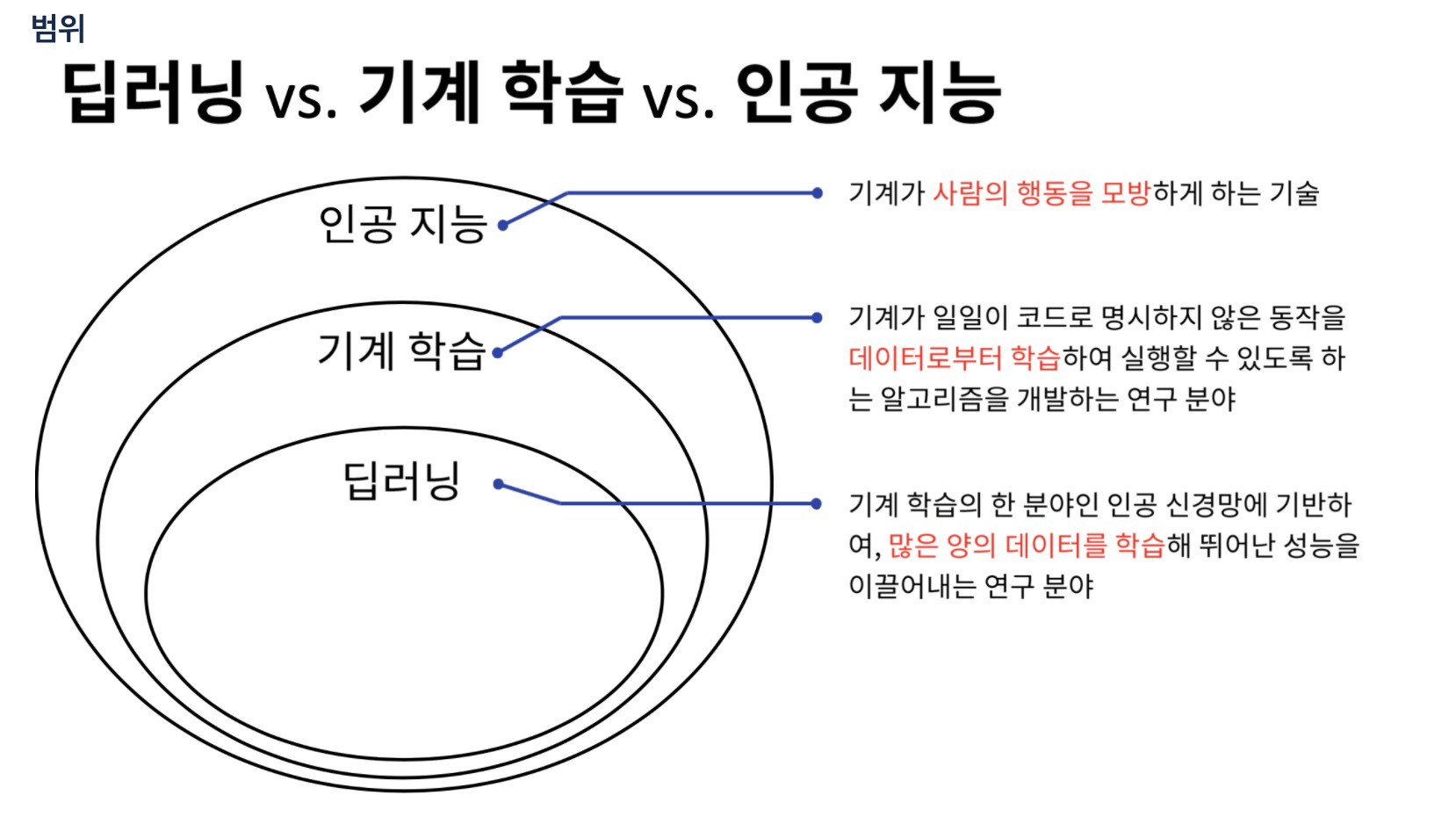
1. 범위
- 현업에서 점차 분리되고 있는 분위기이나, 일단 정의된 내용이다.
- 빅데이터: 데이터 베이스 관리, 데이터 저장/ 유통, 데이터 수집, 데이터 신뢰성 확보, 데이터 시각화, 데이터 통계 분석, 데이터 마이닝
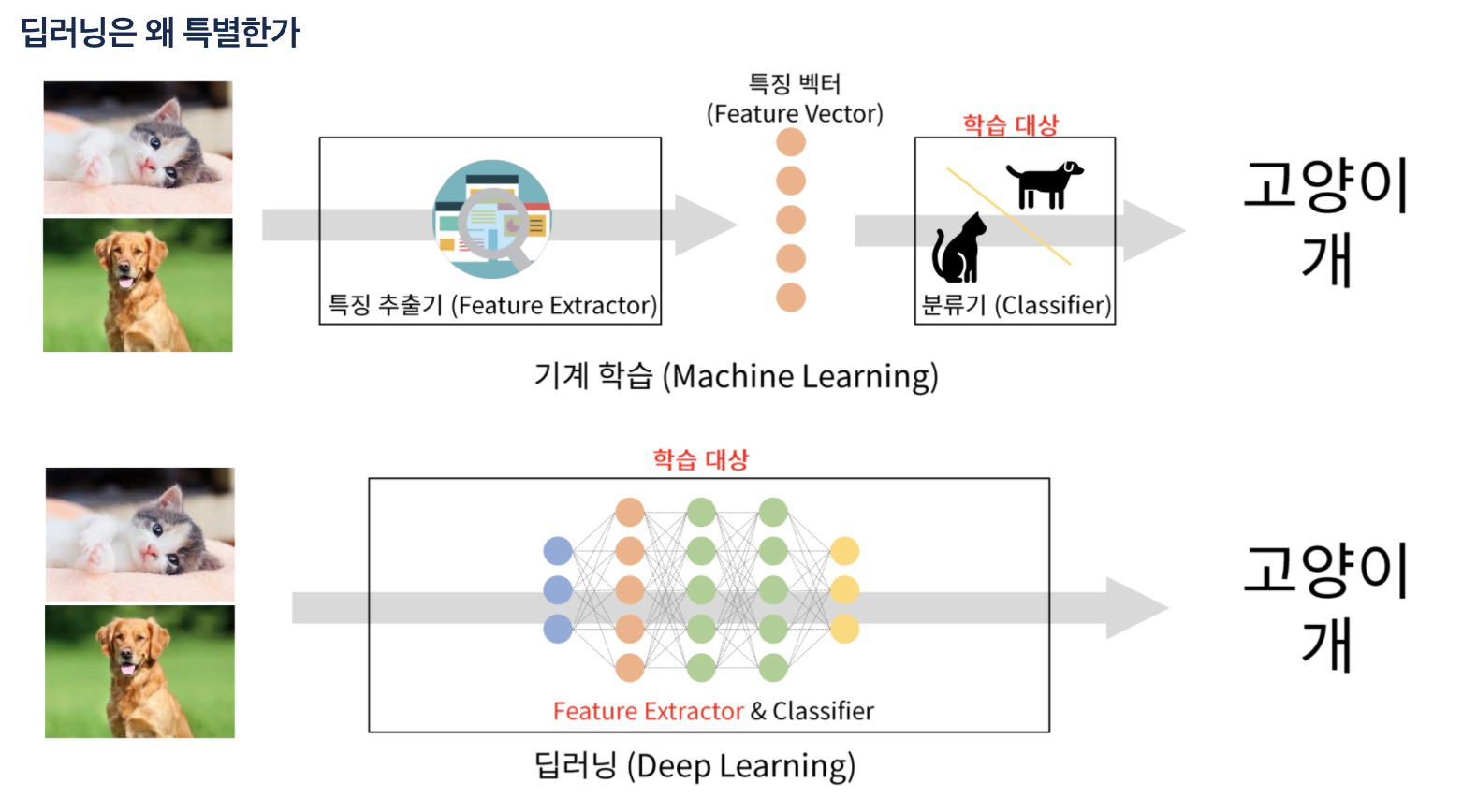
2. ML vs DL
- DL - 분류, 회귀, 물체검출, 영상분할, 영상 초해상도, 예술 창조물, 강화학습
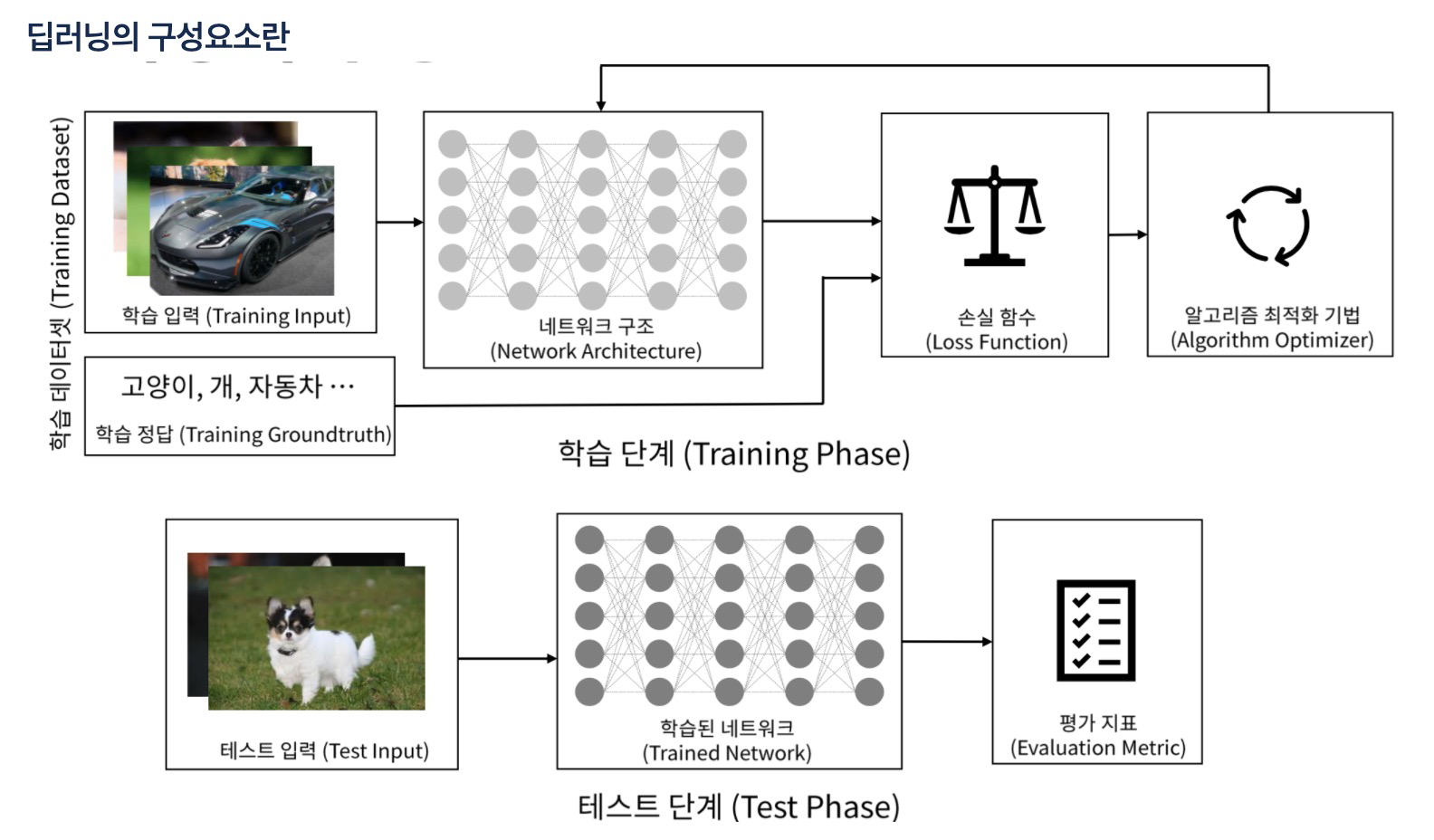
3. 딥러닝 구성요소
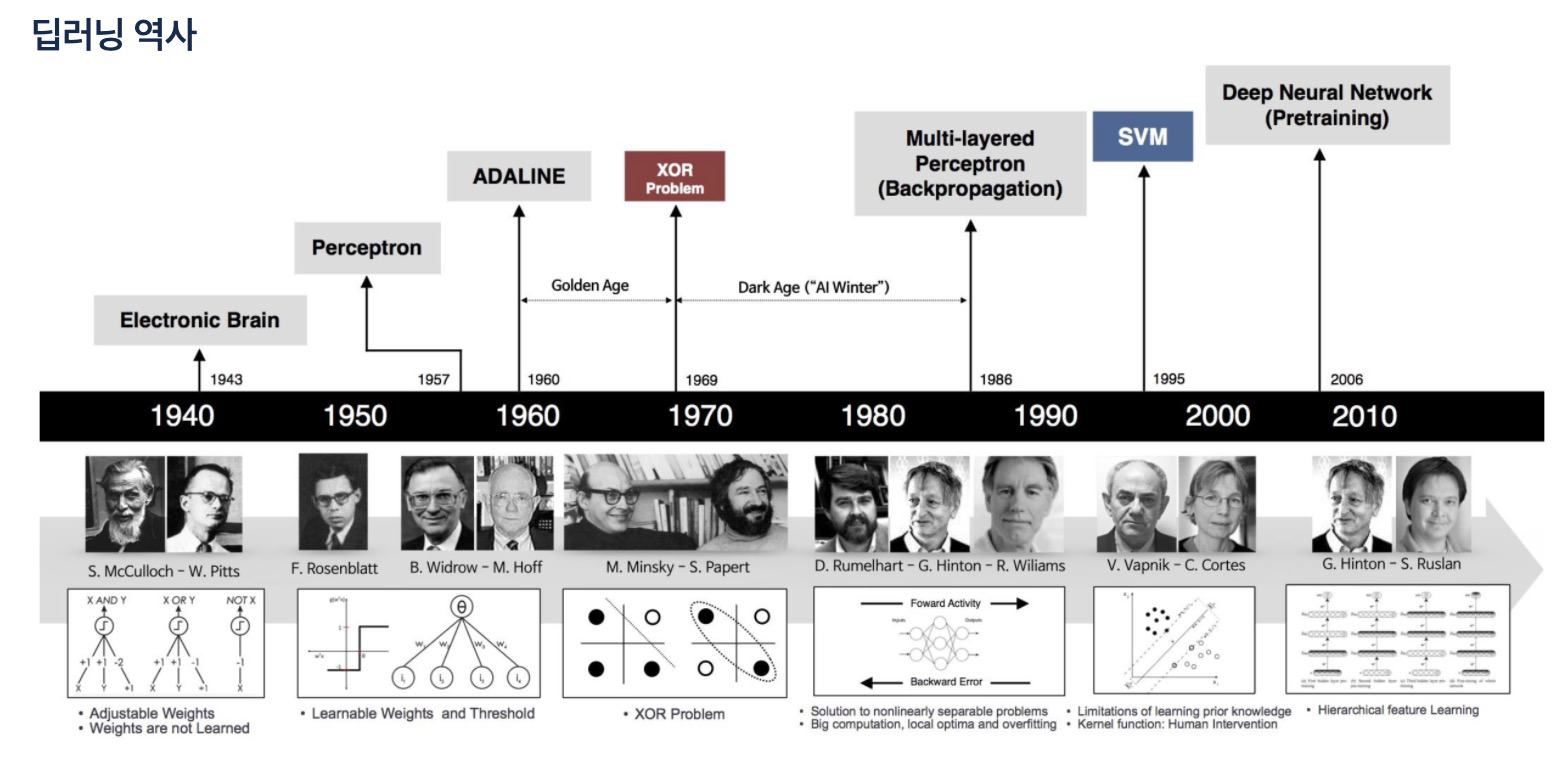
4. 딥러닝 역사
- 딥러닝 시조: 최초의 인공 신경망, 퍼셉트론 구조
- XOR 문제: 다층 퍼셉트론 Multi-Layered Perceptrons;MLP로 해결
- 오류 역전파 알고리즘 Backpropagation Algorithm;BP
- MLP & BP → 필기 숫자 인식
- 계층이 깊어질 수록 학습이 어려운 기울기 소실(vanishing Gradient)문제
- Fei-Fei Li 교수의 ILSVRC우승과 함께 딥러닝 부상 → AlexNet(GPU를 병렬)
- Framework 등장
- 학계에 대중으로 알려진 첫 프레임워크 Caffe.MATLAB 환경에 익숙한 연구원들을 위함 MatConvNet
- Tensorflow(다양한 플랫폼으로 확장), Pytorch(진입 장벽이 낮고 속도 빠름)
- Cloud 플랫폼의 대중화 - AWS, GCP, Azure
- 하드웨어의 대중화
뉴런
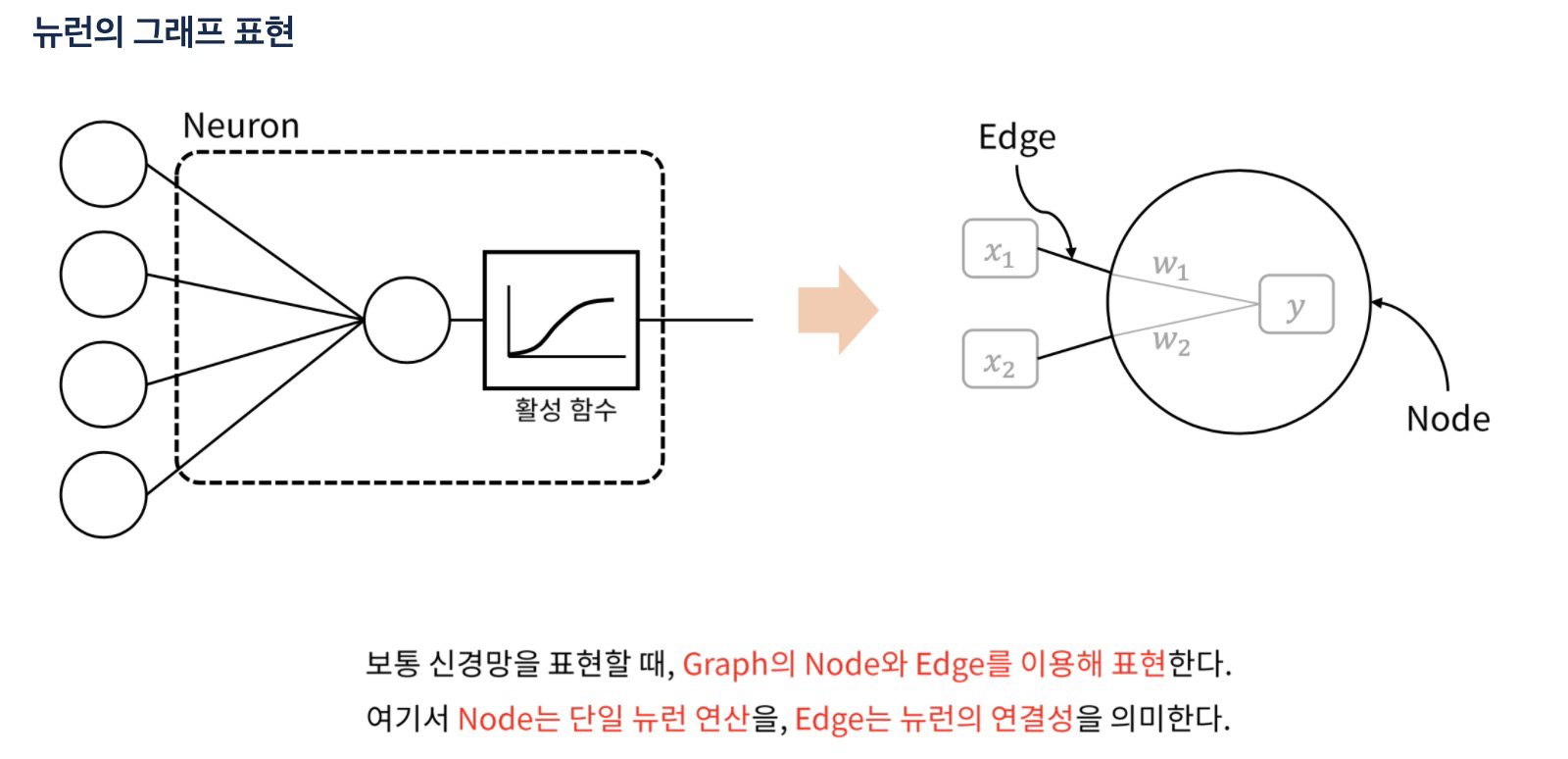
1. 뉴런의 그래프 표현
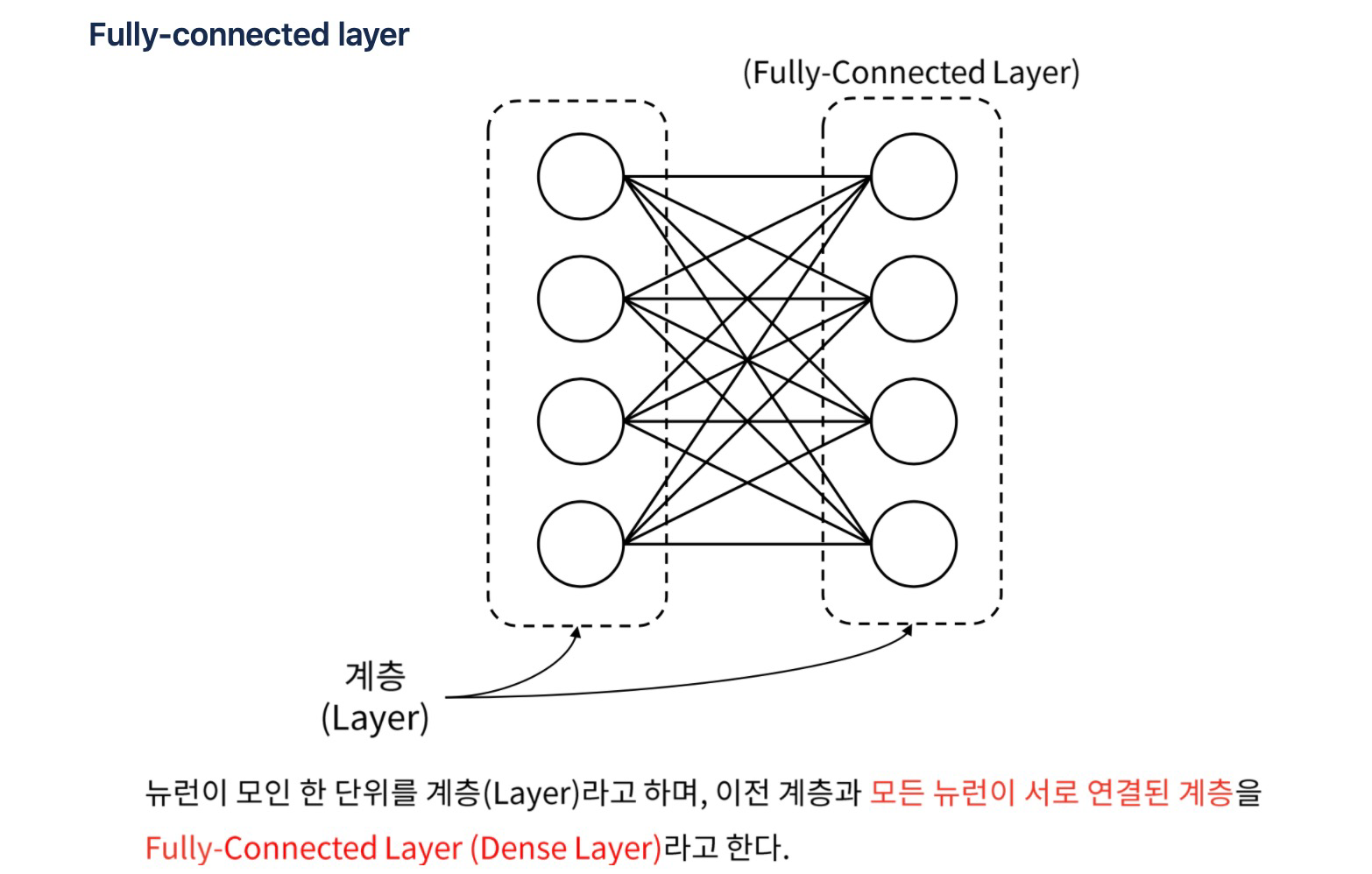
3. Fully-connected layer
- 이전 layer node와 다음 layer node가 모두 연결 됨
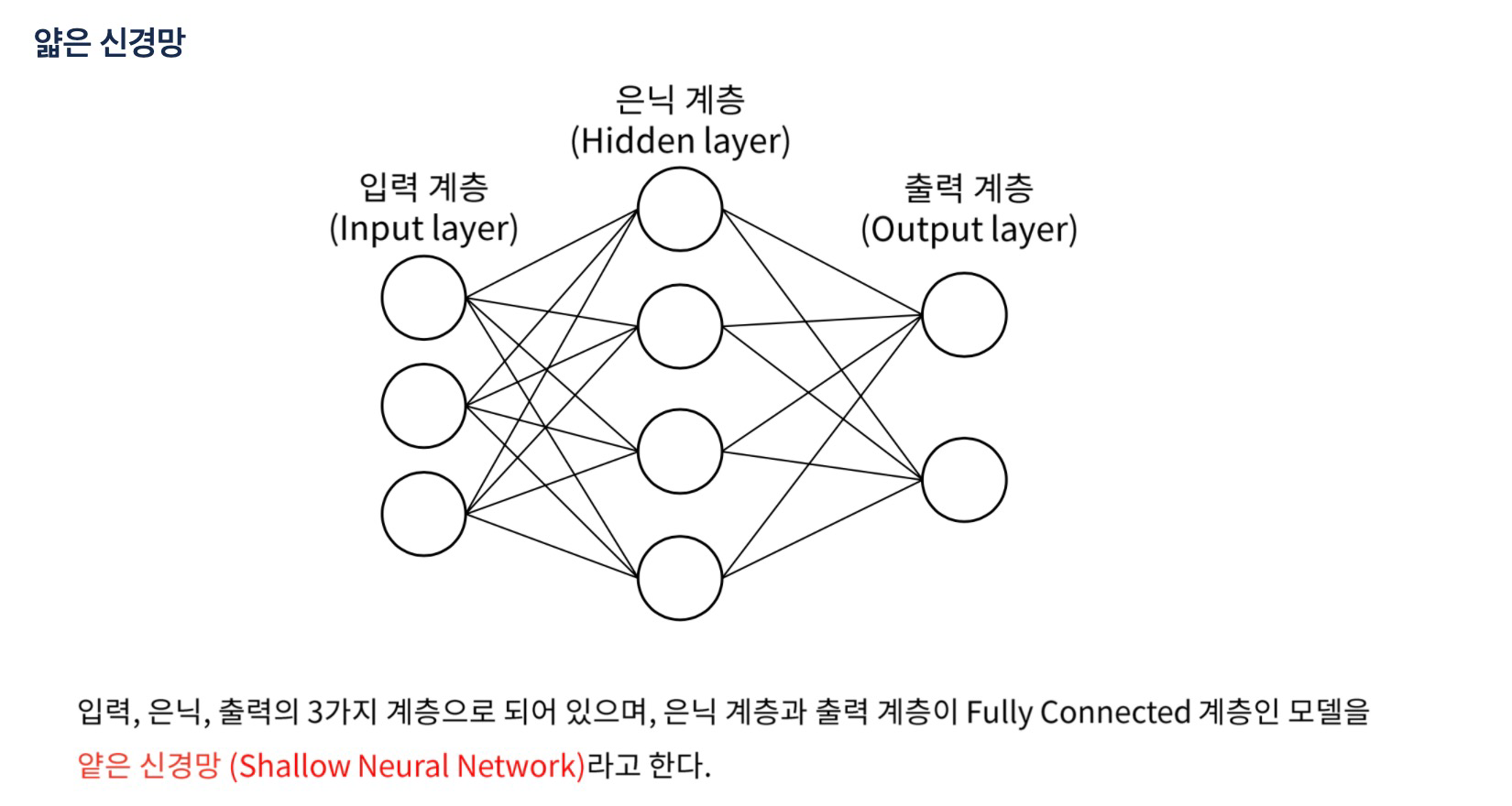
3. 얇은 신경망
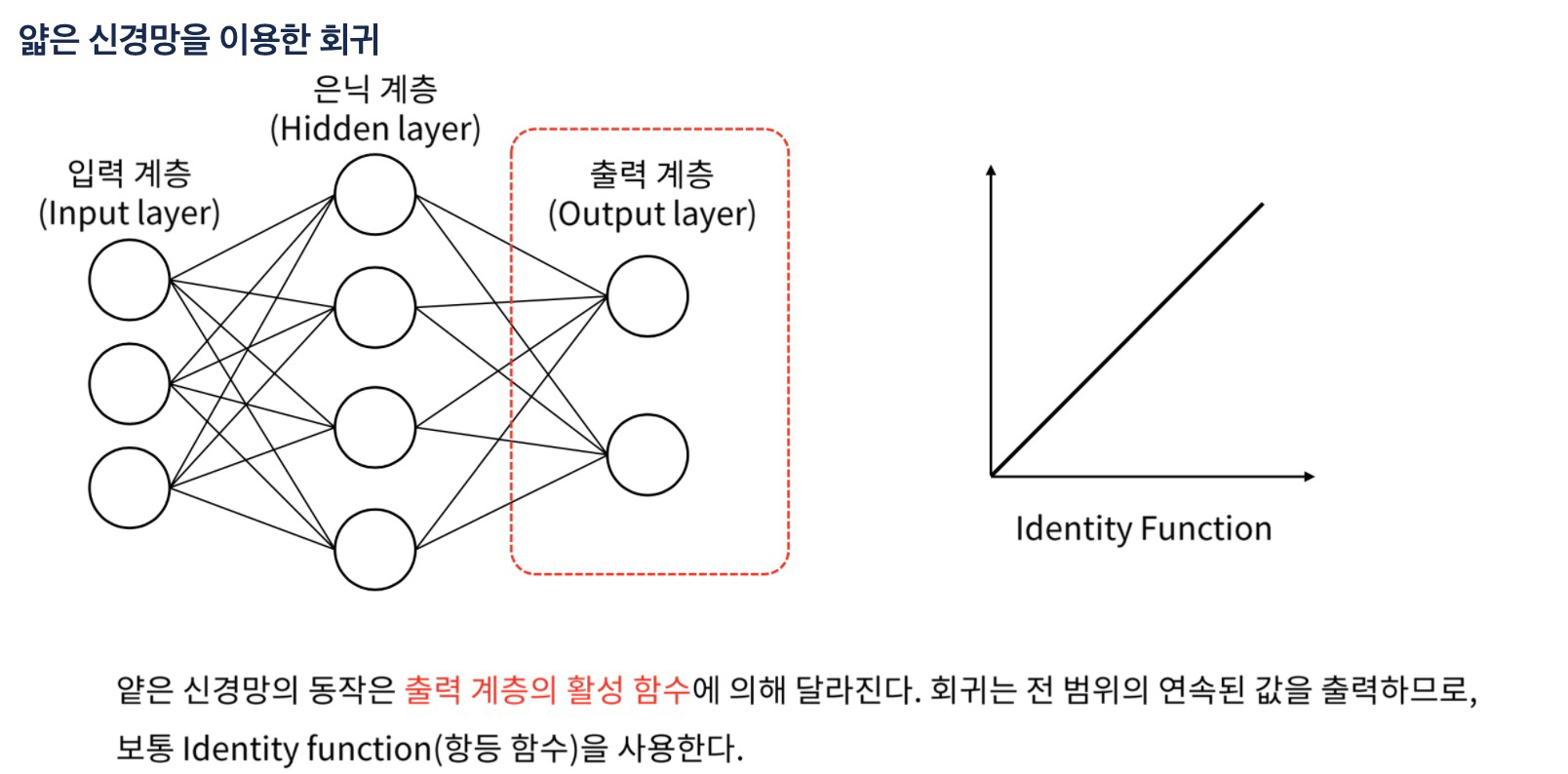
회귀
- 잡음이 있는 학습 샘플로부터 규칙을 찾아 연속된 값의 출력을 추정하는 것
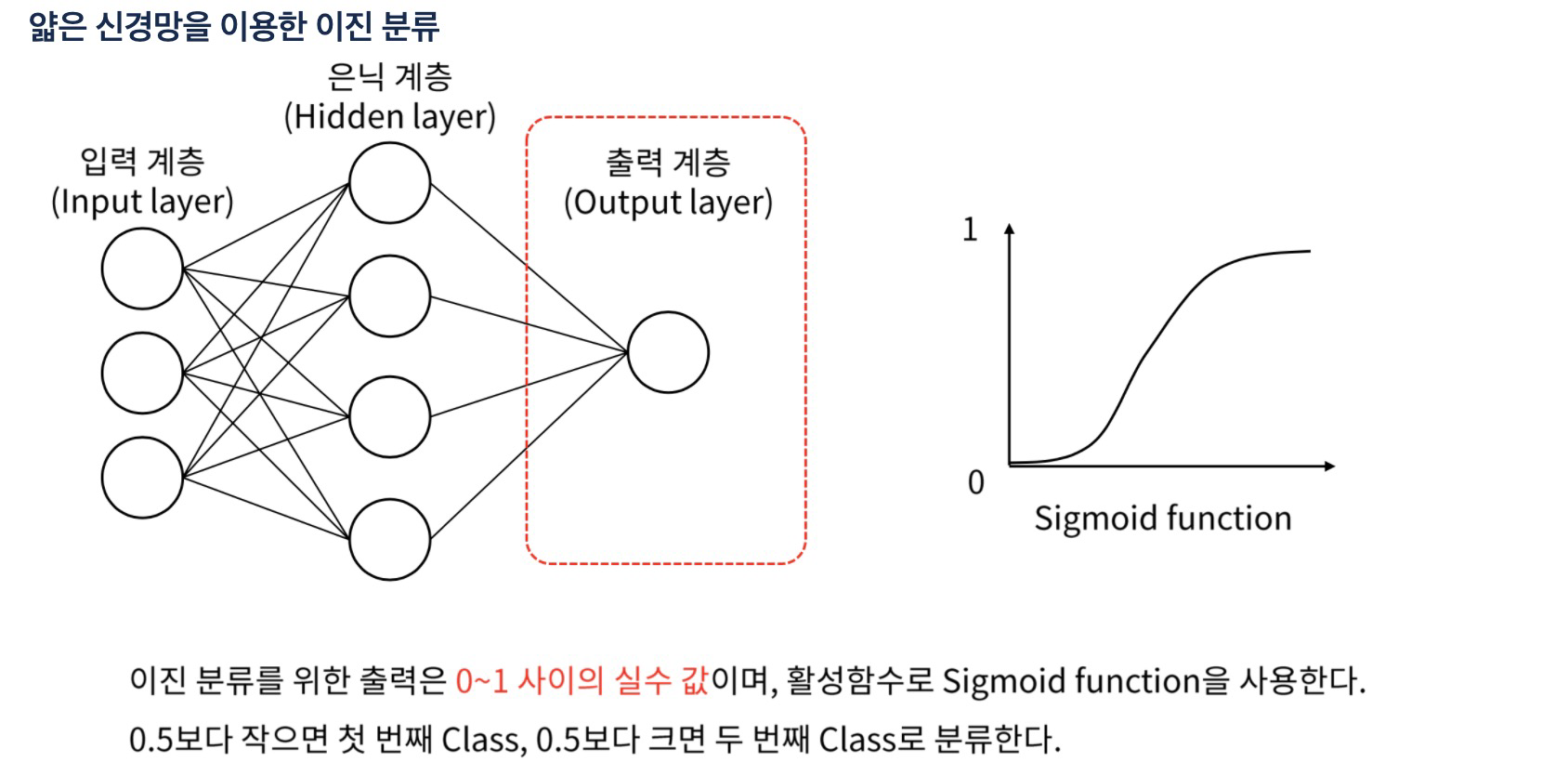
분류
- 입력 값을 분석해 특정 범주(category)로 구분하는 작업(이진 분류, 다중 분류)
- 다중 분류
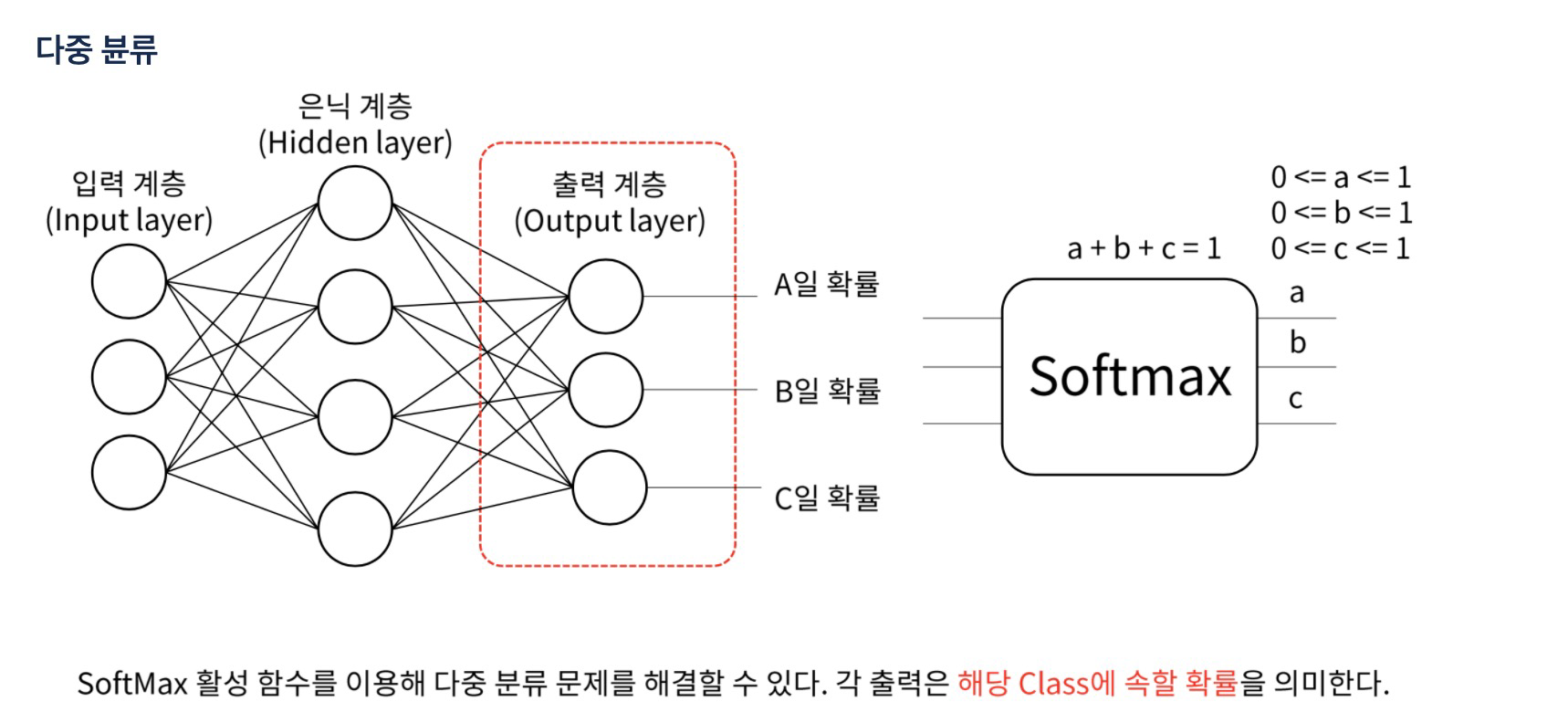
클래스
- 다중 분류에서는 '어떤 물체'인지 표현해야 한다.
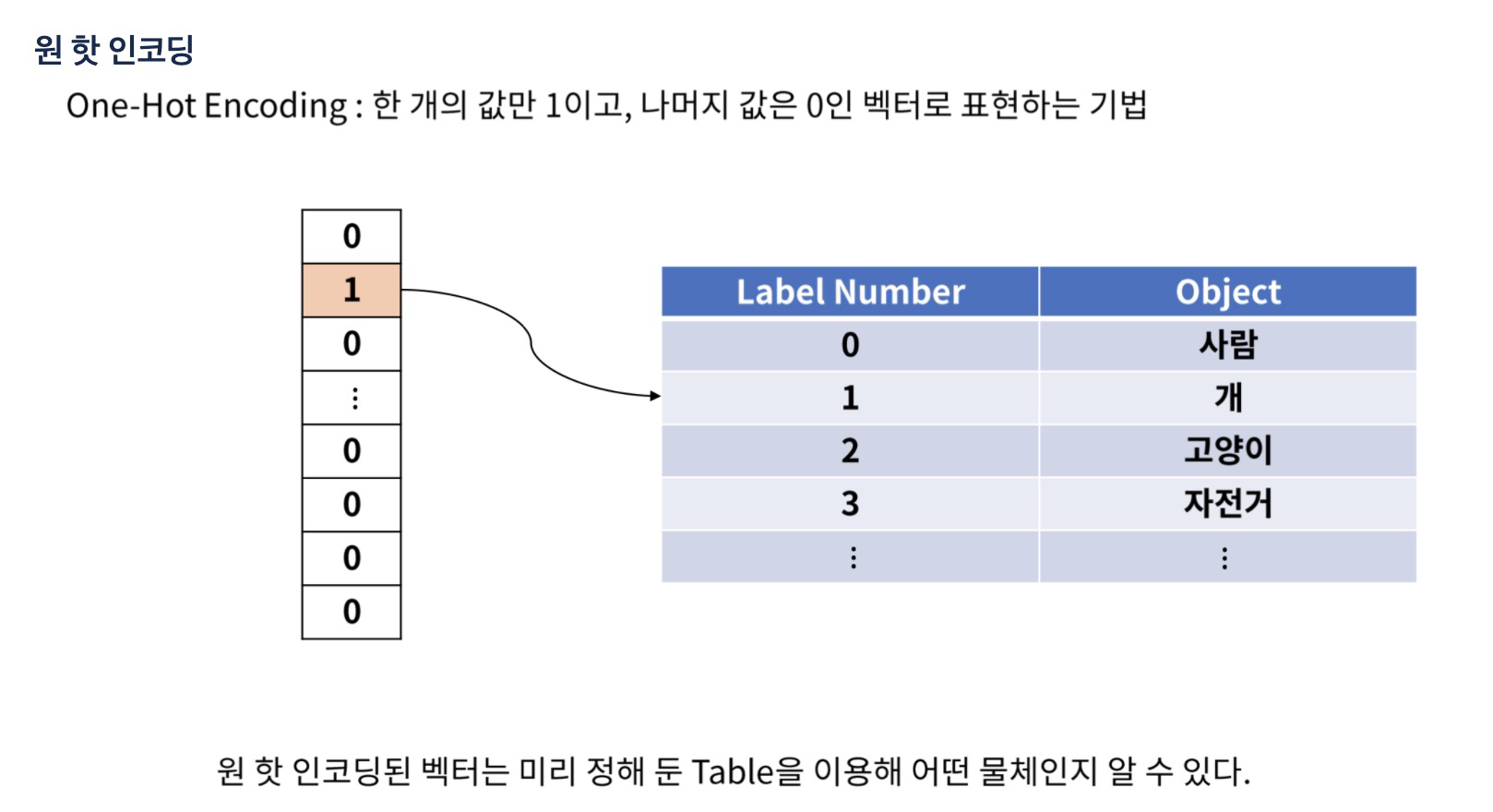
1. One-Hot Encoding
- 편향된 결과를 방지
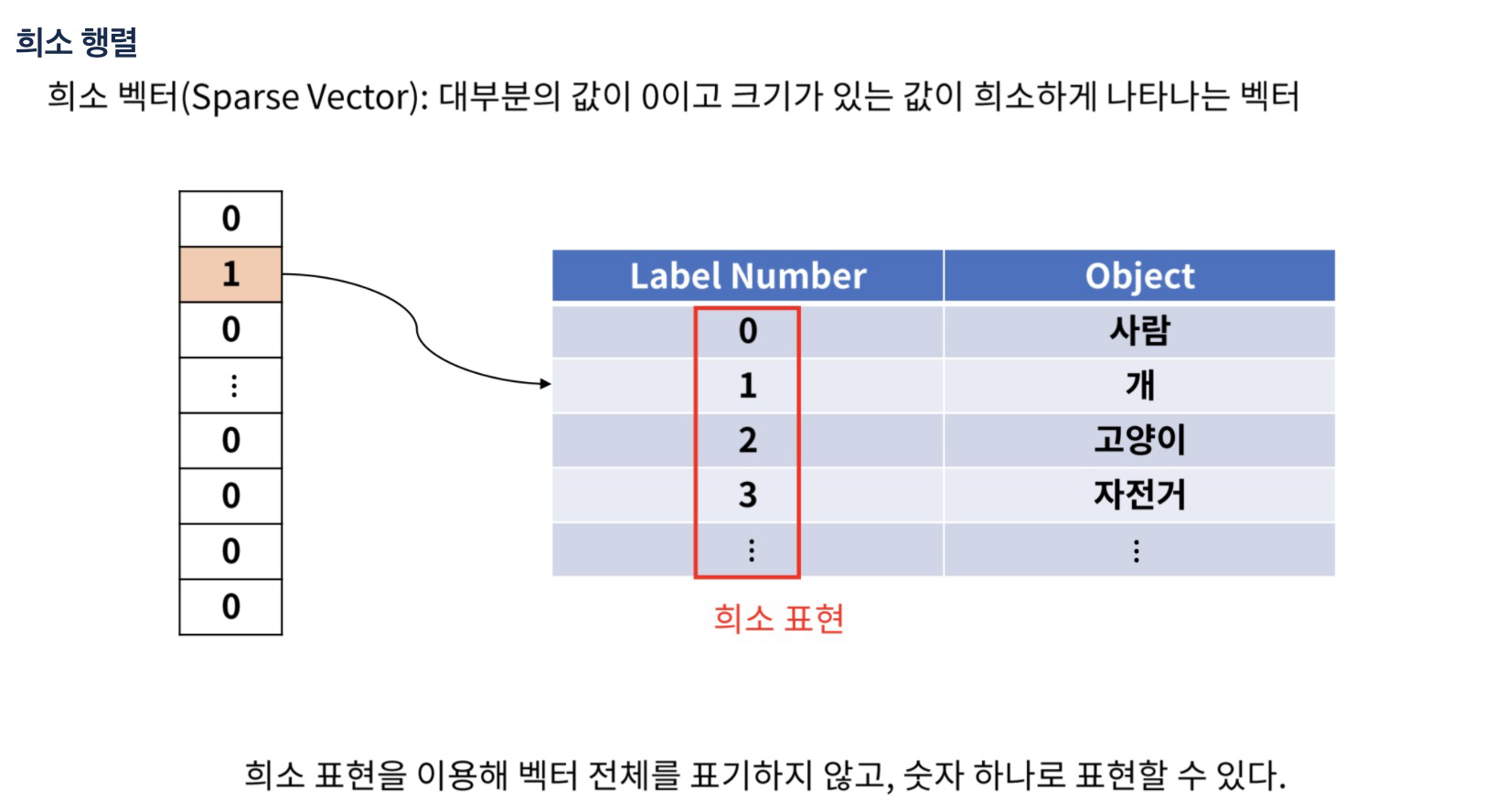
2. 희소 행렬
- 메모리 차지때문에 계산 전까지 숨기기, 위치와 값을 알려줘서 표기
3. 다중 클래스
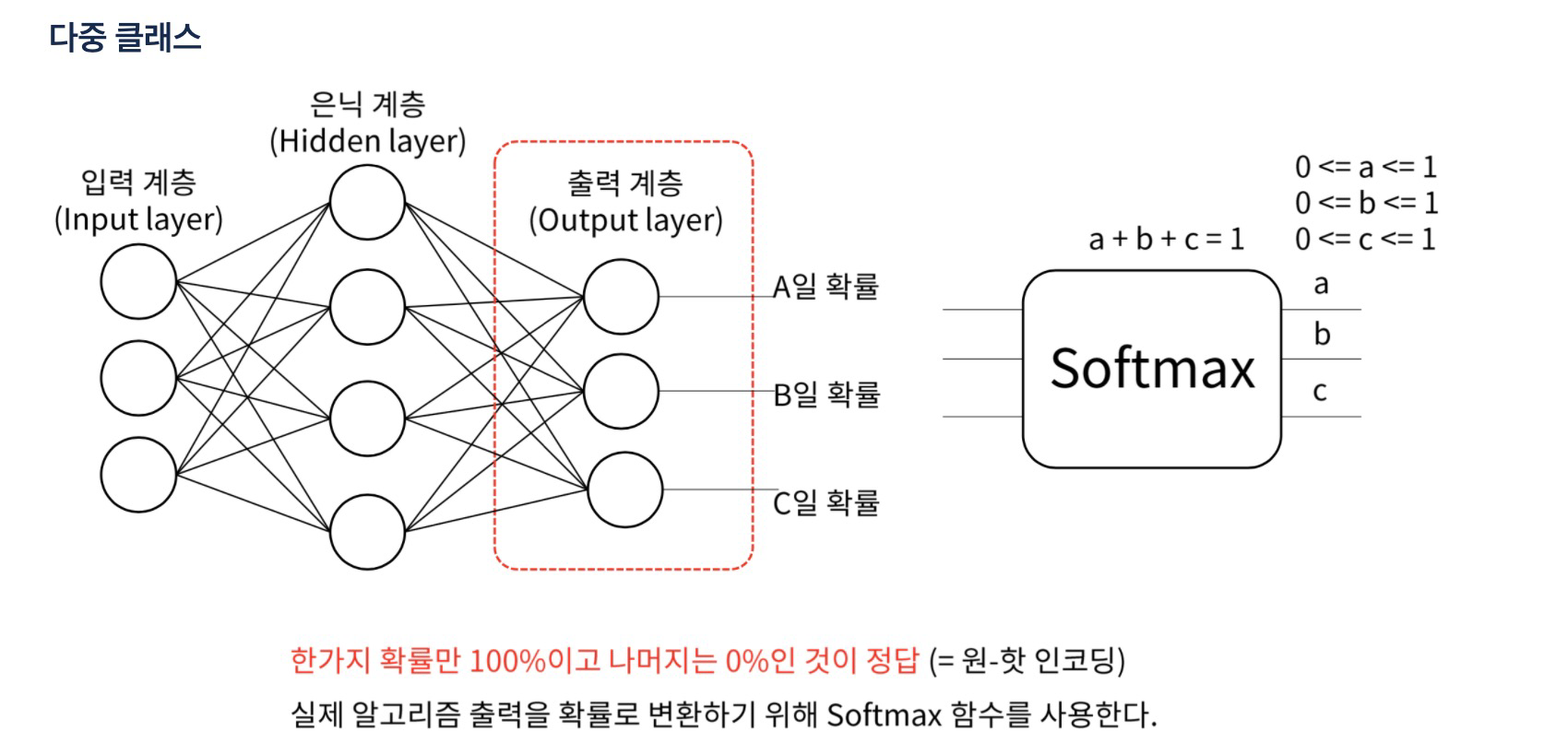
softmax
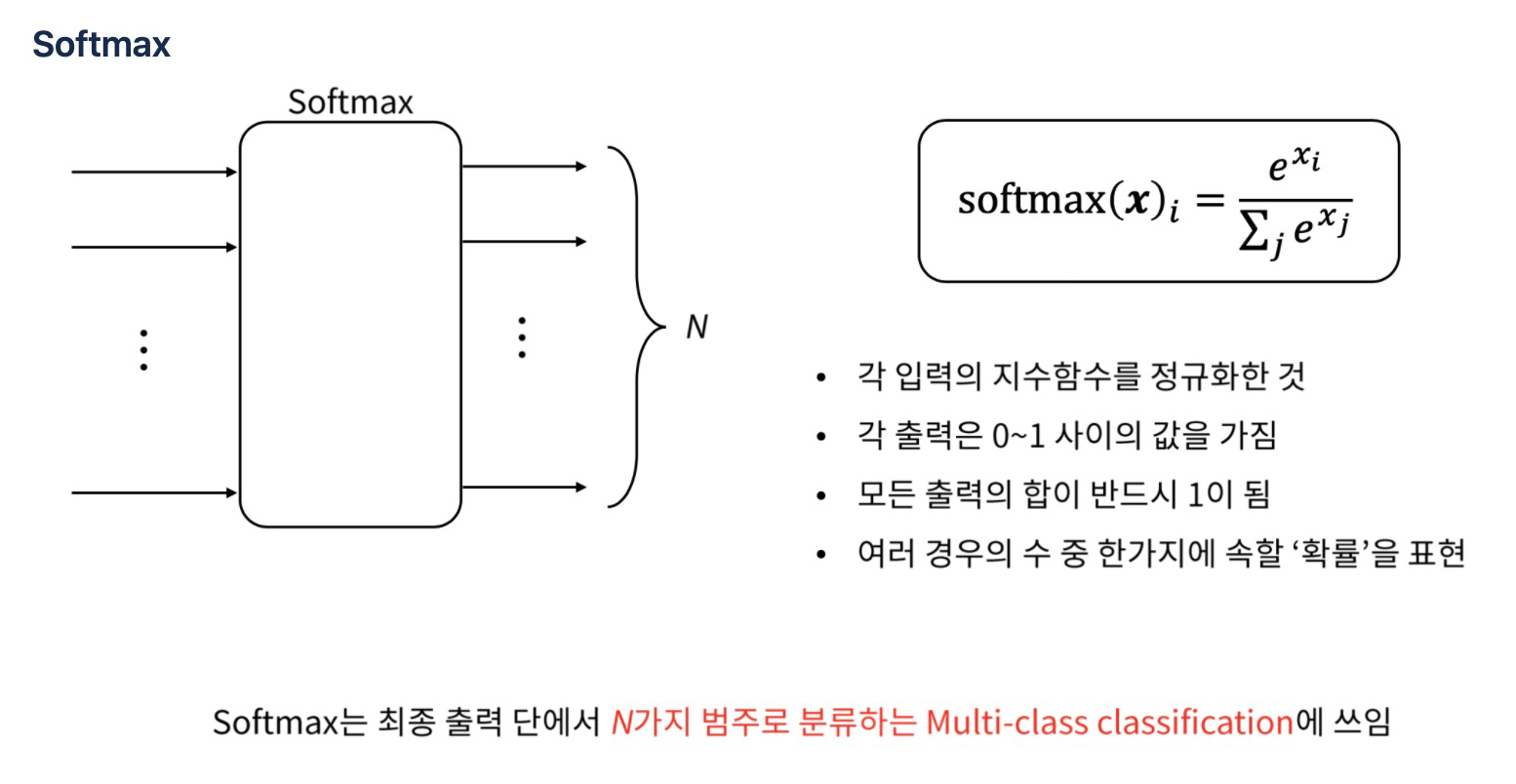
softmax vs sigmoid

One-Hot Encoding & Cross Entropy
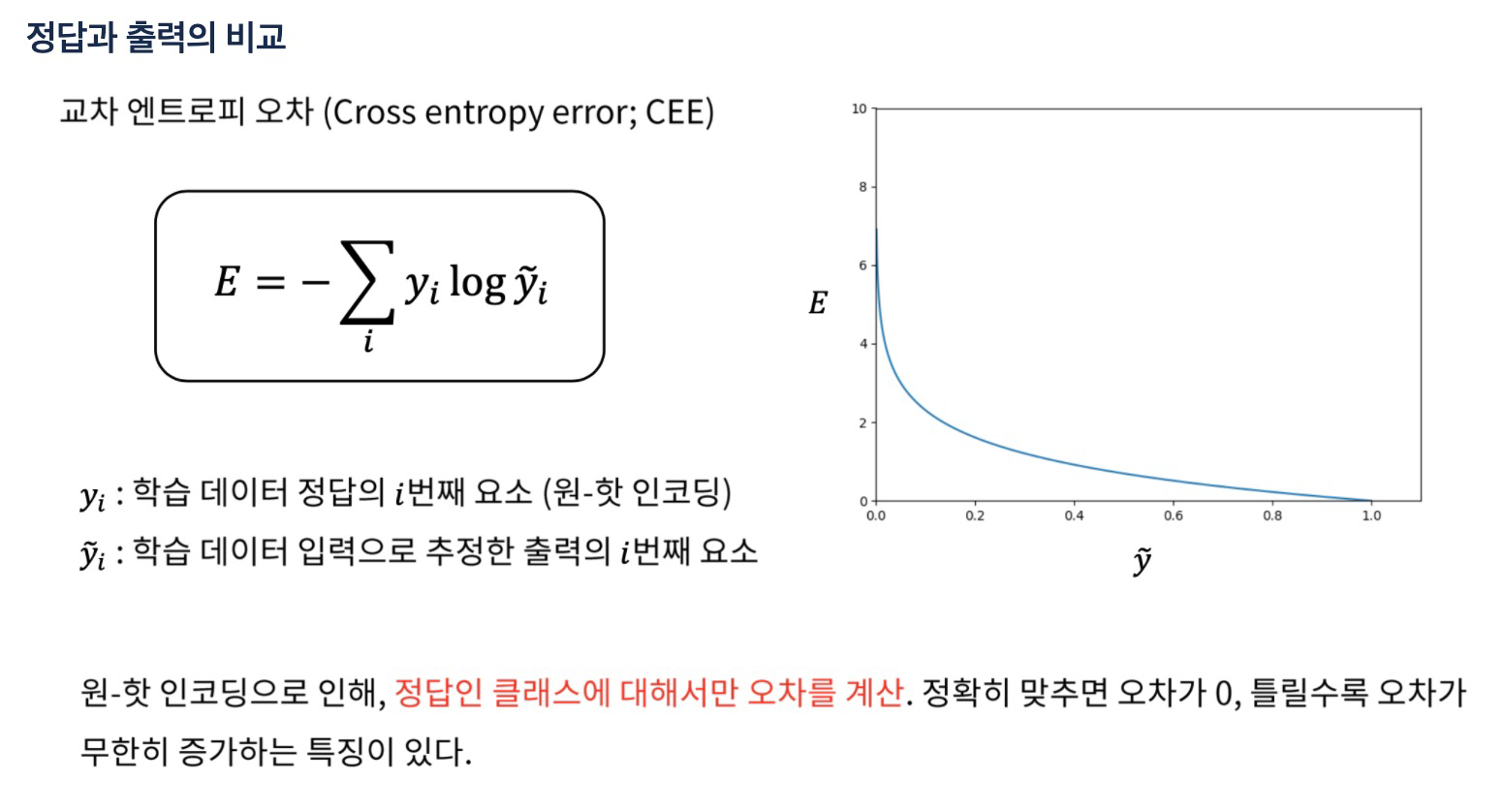
Cross Entropy Error
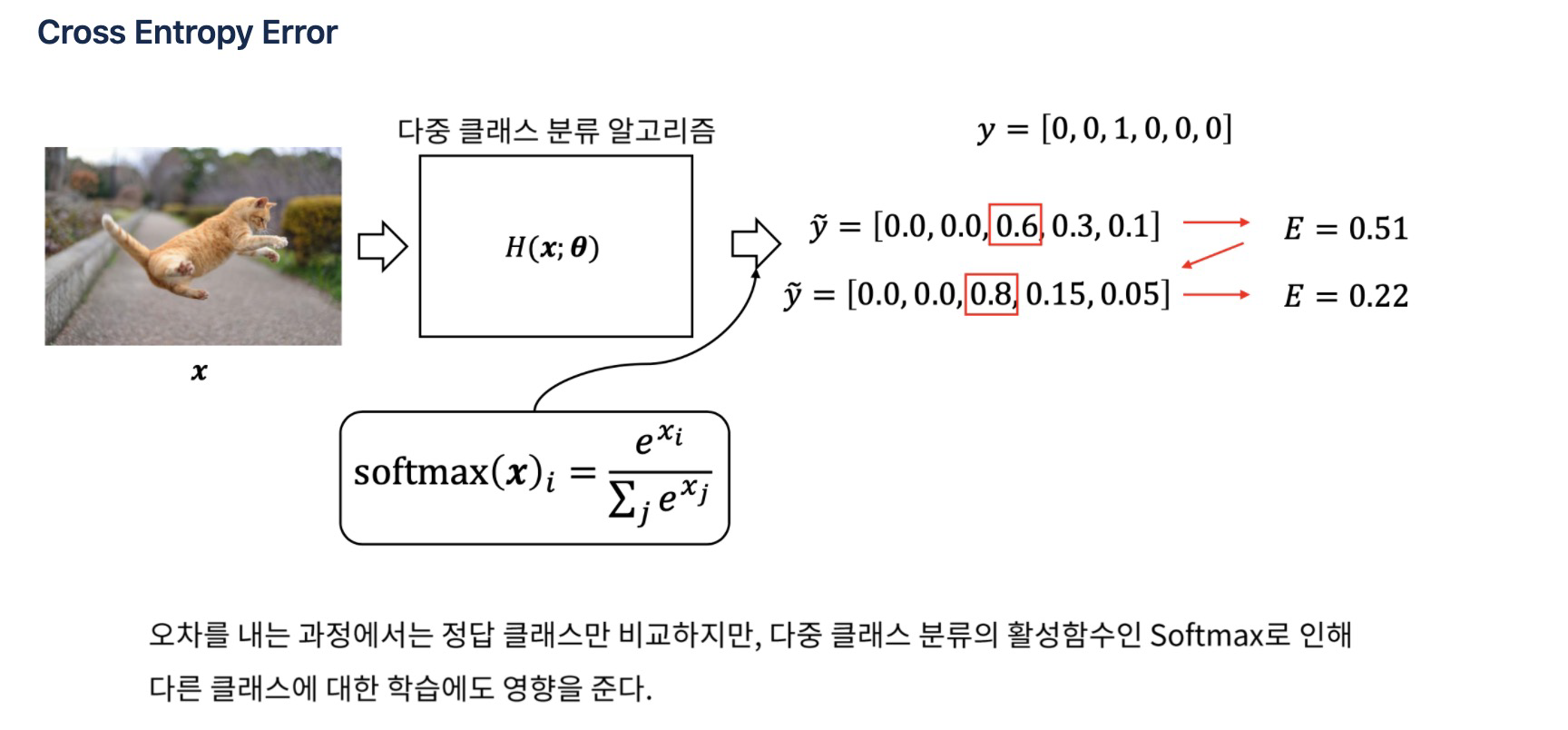
CNN 계열의 네트워크
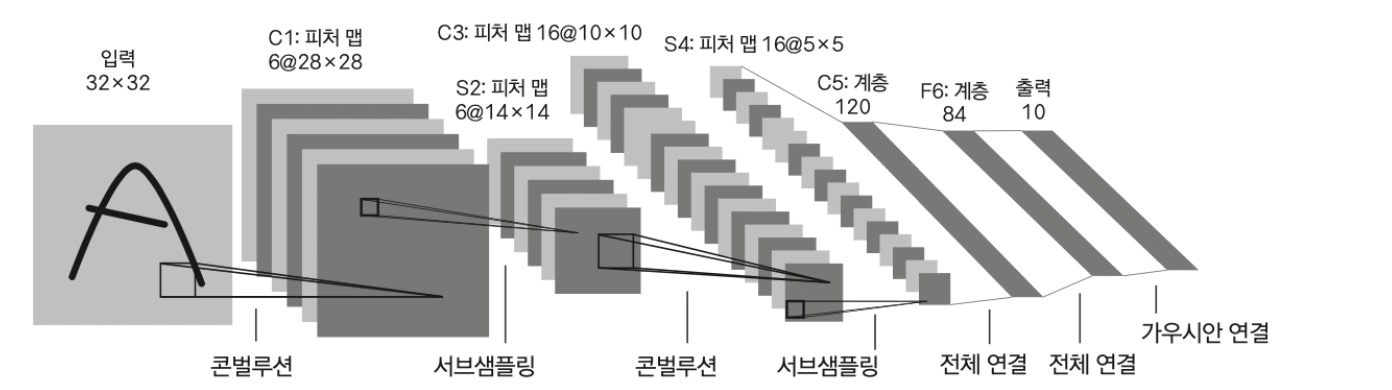
1. LeNET-5
- 얀 르쿤이 1998년 우편물에 필기체 인식을 위해 개발
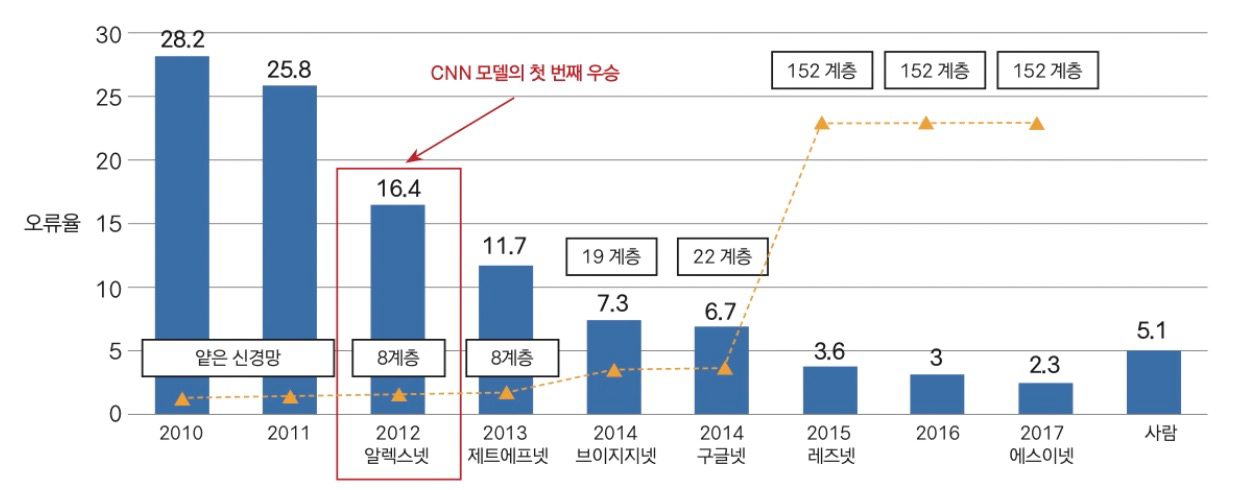
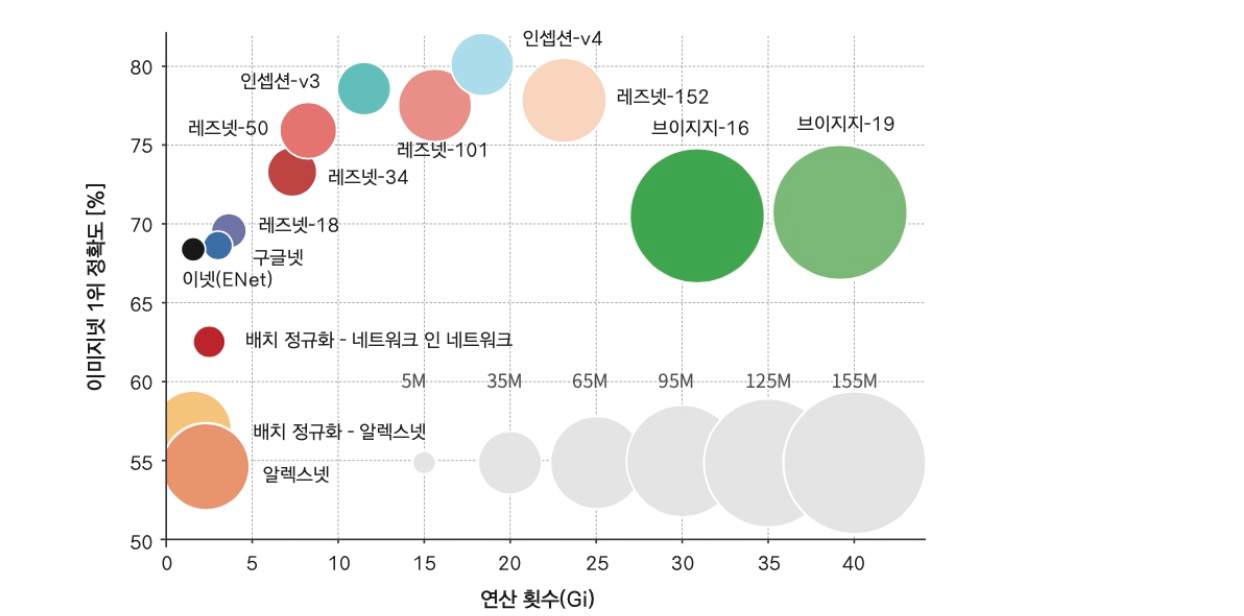
2. ImageNet
- 이미지넷은 1,400만개의 이미지 데이터와 1000개의 클래스의 데이터
- 2010년부터 대회개최
- CNN 계열의 최초 우승이 2012년 알렉스넷
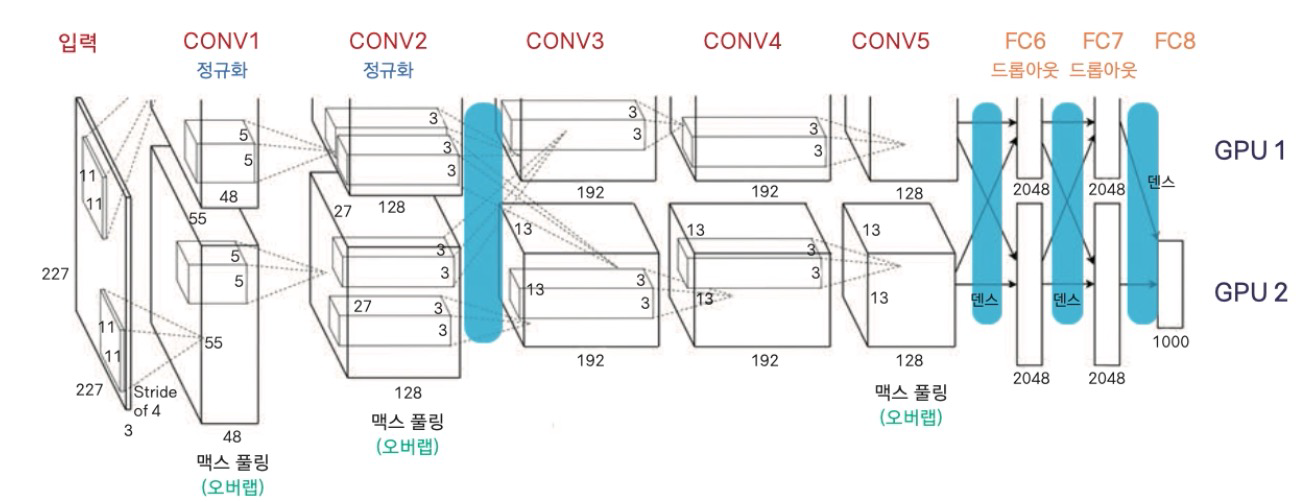
3. AlexNet
- 힌튼 교수 연구팀에서 창안
- 2개의 GPU에서 실행 (GTX580)
- 두 개의 conv 넷을 구성하고 하나씩 GPU를 할당하고 중간에 정보 교환
- 이미지넷 데이터를 5~6일 정도 학습
4. ZFNet
- 2013 ILSVRC 우승.
- 알렉스넷의 문제점을 시각화를 통해 확인 후 해당부분을 개선
- GTX580으로 12일 학습
- 의의는 모델 튜닝만으로도 좋은 결과를 얻을 수 있다는 사례를 남김

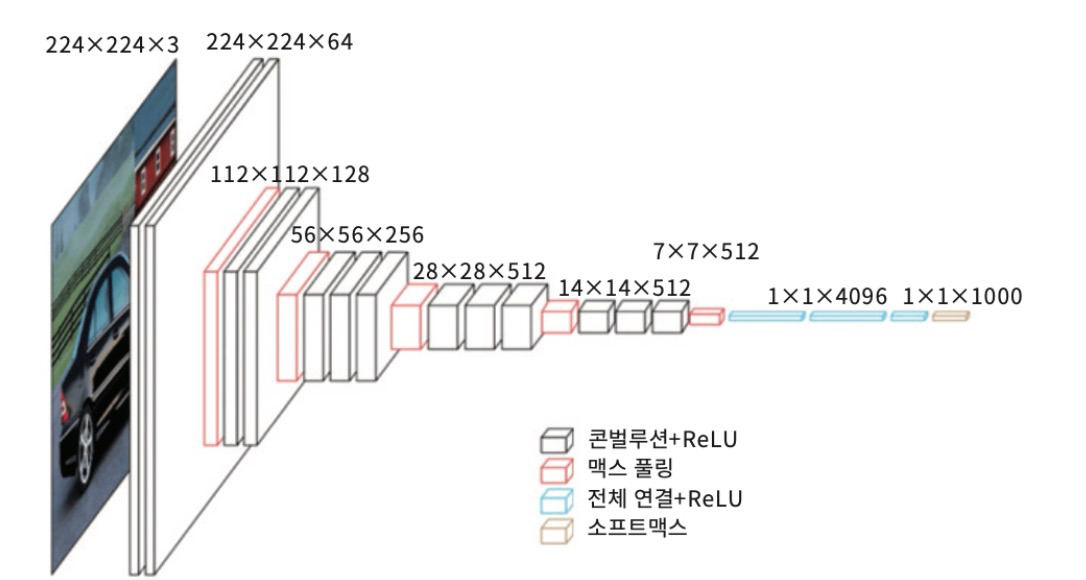
5. VGGNet
- 2014 ILSVRC 준우승.
- 깊은 신경망. 3x3 컨블루션 필터만을 사용. 매우 단순한 구조
- 작은 필터로 깊은 네트워크를 형성하는 것이 유리함을 보여줌
- VGG는 이미지의 특징을 추출할 때 많이 사용
- 일부 계층의 특징으로 스타일을 생성
6. GoogLeNet
- 2014 ILSVRC 우승.
- 이후 InceptionV4로 발전했기 때문에 GoogLeNet을 인셉션v1이라고도 함
- 기존의 방식과 달리 네트워크 속에 네트워크를 두는
방식으로 구성 - 왼쪽에서 빨간색 박스가 인셉션 모듈
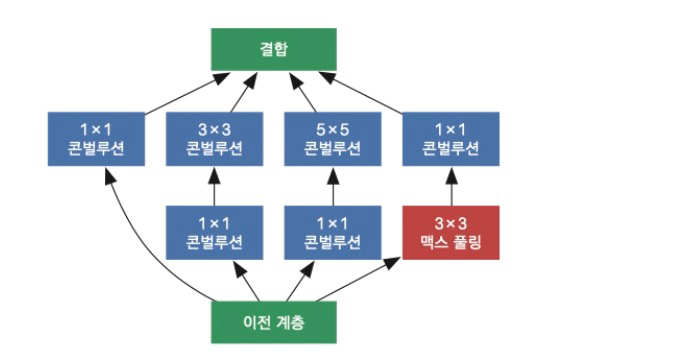
GoogLeNet – 인셉션 모듈
- 1x1, 3x3, 5x5, 맥스풀링으로 구성
- 1x1은 채널의 특성을 인식
- 3x3과 5x5는 서로 다른 크기의 영역에서 공간의 특징과 채널의 특징을 인식
- 맥스 풀링은 가장 두드러진 특징을 인식
GoogLeNet – 구조
- 스템 : 도입부에는 일반적인 구조로 진행 (Conv – Pool –Conv - Pool)
- 몸체 : 인셉션 모듈 9개
- 최종 분류기 : FC 대선 mean pooling을 통해 파리미터 수를 줄임
- 보조 분류기 : 하위 계층에 그레디언트를 원할히 전달 (훈련때만 사용)
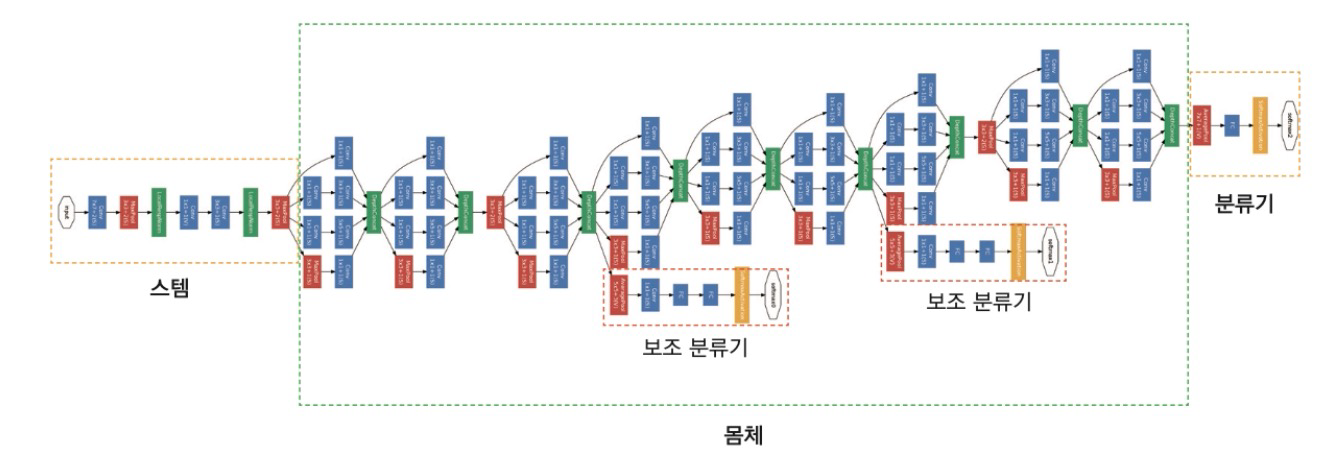
7. ResNet
- 최초로 사람의 인지능력(5%대)보다 좋은 성능
- 152계층의 엄청난 깊이를 가짐
- Residual connection의 구조를 가짐

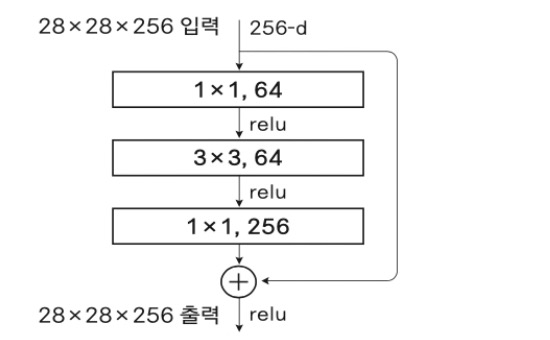
ResNet – Bottlnet
- 3x3 Conv 앞뒤에 1x1 Conv를 배치
- 1x1 Conv로 채널을 줄였다가 다시 확대
Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it