시작하기전
1) searborn
목표
- 데이터 과학의 목적: 가정 혹은 ‘인식’을 검증하고 표현하는 것
- '서울 강남 3구' 체감 안전도가 높다는 뉴스 → 사실인지 검증
1. 데이터 읽기
- thousands="," → 콤마를 문자로 인식하지 않게 구분을 없애고 불러오기
- 읽는 데이터의 숫자에 세자리수를 구분하기 위한 콤마(,)가 사용됨을 지정
- thousands 옵션을 사용한 후에는 콤마가 있는 숫자로 보이는 문자열 데이터가 숫자형 데이터로 자동으로 변환됨
- 문자로 구성된 데이터에는 해당사항이 없음
- info(): 데이터 개요 확인하기 → 불필요한 데이터가 있는지 확인
- 특정 컬럼에서 unique 조사
- crime_raw_data["죄종"].isnull() → nan값을 확인
import numpy as np
import pandas as pd
#thousands
crime_raw_data = pd.read_csv("../data/02. crime_in_Seoul.csv", thousands=",", encoding="euc-kr")
crime_raw_data.head()
crime_raw_data.info()
crime_raw_data["죄종"].unique()
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()]2. 서울시 범죄 현황 데이터 정리
- pivot_table 이용
- MultiIndex 정리(다중 컬럼에서 특정 컬럼 제거) → columns.droplevel()
- 현재 index는 경찰서 이름
crime_station = crime_raw_data.pivot_table(
crime_raw_data,
index="구분",
columns=["죄종", "발생검거"],
aggfunc=[np.sum]) #sum이라는 column 나오려면 []필요
#MultiIndex
crime_station.columns
'''
MultiIndex([('sum', '건수', '강간', '검거'),
('sum', '건수', '강간', '발생'),
('sum', '건수', '강도', '검거'),
('sum', '건수', '강도', '발생'),
('sum', '건수', '살인', '검거'),
('sum', '건수', '살인', '발생'),
('sum', '건수', '절도', '검거'),
('sum', '건수', '절도', '발생'),
('sum', '건수', '폭력', '검거'),
('sum', '건수', '폭력', '발생')],
names=[None, None, '죄종', '발생검거'])
'''
#다중 컬럼에서 특정 컬럼 제거
crime_station.columns = crime_station.columns.droplevel([0, 1])
crime_station.head()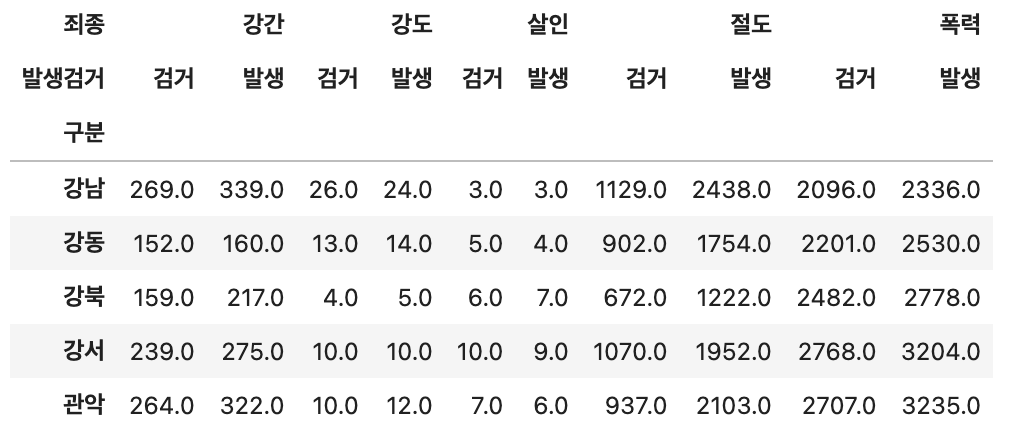
3. Google Maps를 이용한 데이터 정리
Pandas에 잘 맞춰진 반복문용 명령 iterrows()
- Pandas 데이터 프레임은 대부분은 2차원
- for문을 사용하면 n번째라는 지정을 반복해서 가독률이 떨어짐
- Pandas 데이터 프레임으로 반복문을 만들때 iterrows()라는 옵션을 사용
- 받을 때, 인덱스와 내용으로 나누어 받는 것만 주의
데이터 정리 순서
- 경찰서 이름에서 소속한 '구'이름 얻기
- 구이름, 위도, 경도 정보를 저장할 준비
- iterrow() 반복문을 이용해서 표의 NaN을 모두 채워줌
- get_level_values와 for문을 이용해서 죄종, 발생검거로 나누어진 컬럼을 합치기
- 데이터 저장
import googlemaps
gmaps_key="API key"
gmaps=googlemaps.Client(key=gmaps_key)
gmaps.geocode("서울영등포경찰서", language="ko") #단순 테스트 코드
tmp = gmaps.geocode("서울영등포경찰서", language="ko")
#len(tmp)=1 → index=0, dict이라서 이렇게 접근(lat 위도, lng 경도)
print(tmp[0].get("geometry")["location"]["lat"])
print(tmp[0].get("geometry")["location"]["lng"])
#주소 값을 띄어쓰기로 나누고 '구'에 해당하는 index
tmp[0].get("formatted_address").split()[2]
#NaN을 넣어 저장할 준비
crime_station["구별"] = np.nan
crime_station["lat"] = np.nan
crime_station["lng"] = np.nan
#idx -> 현재 '구분'
#iterrow(), NaN
for idx, rows in crime_station.iterrows():
station_name = "서울" + str(idx) + "경찰서"
tmp = gmaps.geocode(station_name, language="ko")
tmmp_gu = tmp[0].get("formatted_address").split()[2]
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
crime_station.loc[idx, "lat"] = lat
crime_station.loc[idx, "lng"] = lng
crime_station.loc[idx, "구별"] = tmmp_gu
# 컬럼 합치기
tmp = [
crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n]
for n in range(0, len(crime_station.columns.get_level_values(0)))
]
'''
tmp = ['강간검거', '강간발생', '강도검거','강도발생', '살인검거', '살인발생', '절도검거', '절도발생', '폭력검거', '폭력발생', '구별', 'lat', 'lng']
'''
crime_station.columns = tmp
crime_station.head()
# 데이터 저장
crime_station.to_csv("../data/02. crime_station_raw.csv", sep=",", encoding="utf-8")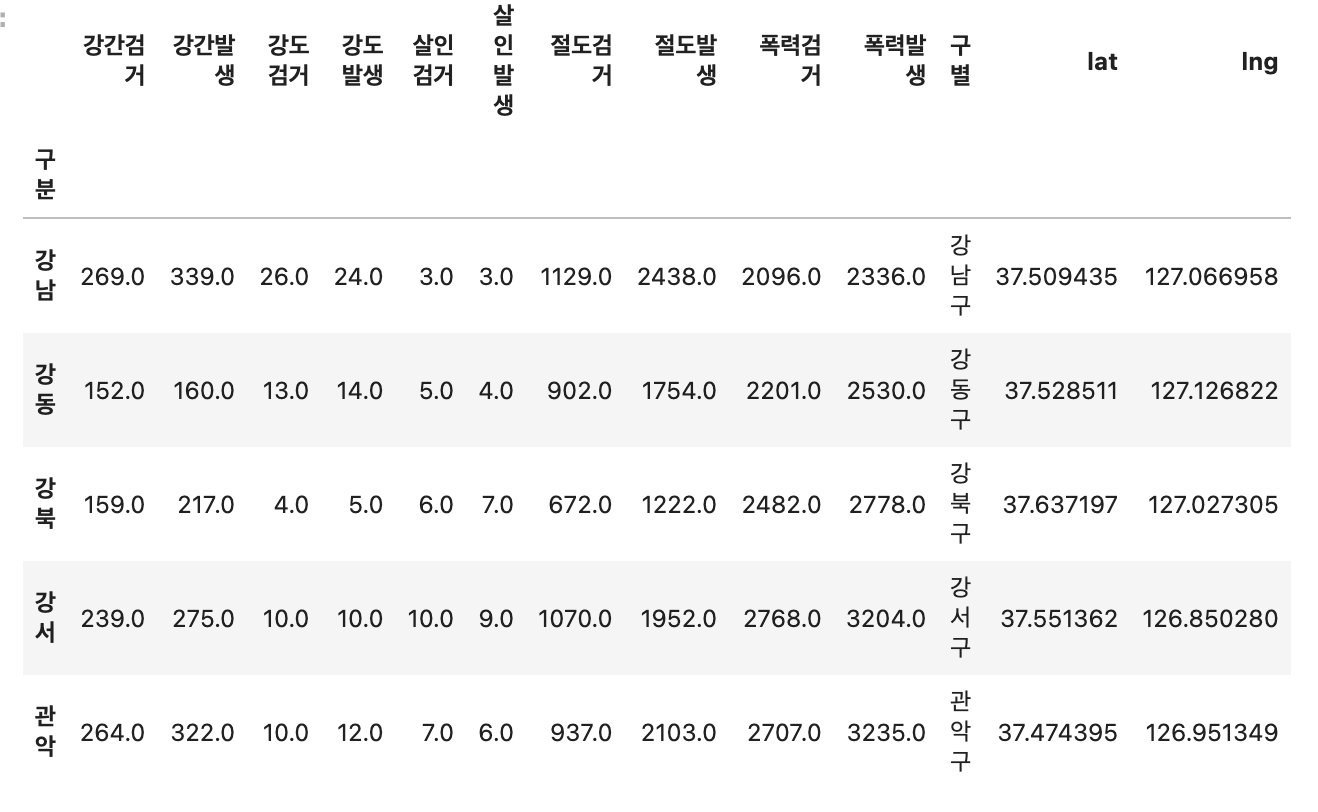
4. 구별 데이터로 정리
- index_col 이용해서 '구분'을 인덱스 칼럼으로 지정
- '구별' pivot_table 생성하고 불필요 column 삭제
- 검거율 생성
- heatmap을 위해서 검거율 100보다 큰 숫다 찾아서 바꾸기
#index_col '구분'을 인덱스 칼럼으로 적용
crime_anal_station = pd.read_csv("../data/02. crime_station_raw.csv", index_col=0, encoding="utf-8")
#pivot_table, column 삭제
crime_anal_gu = pd.pivot_table(crime_anal_station, index="구별", aggfunc=np.sum)
del crime_anal_gu["lat"]
crime_anal_gu.drop("lng", axis=1, inplace=True)
#검거율 생성
target = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"]
den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"]
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100
#필요 없는 컬럼 제거
del crime_anal_gu["강간검거"]
del crime_anal_gu["강도검거"]
del crime_anal_gu["살인검거"]
crime_anal_gu.drop(["절도검거", "폭력검거"], axis=1, inplace=True)
# 100보다 큰 숫다 찾아서 바꾸기
crime_anal_gu[crime_anal_gu[target] > 100] = 100
#컬럼 이름 변경
crime_anal_gu.rename(columns={"강간발생":"강간", "강도발생":"강도", "살인발생":"살인", "절도발생":"절도", "폭력발생":"폭력"}, inplace=True)
crime_anal_gu.head()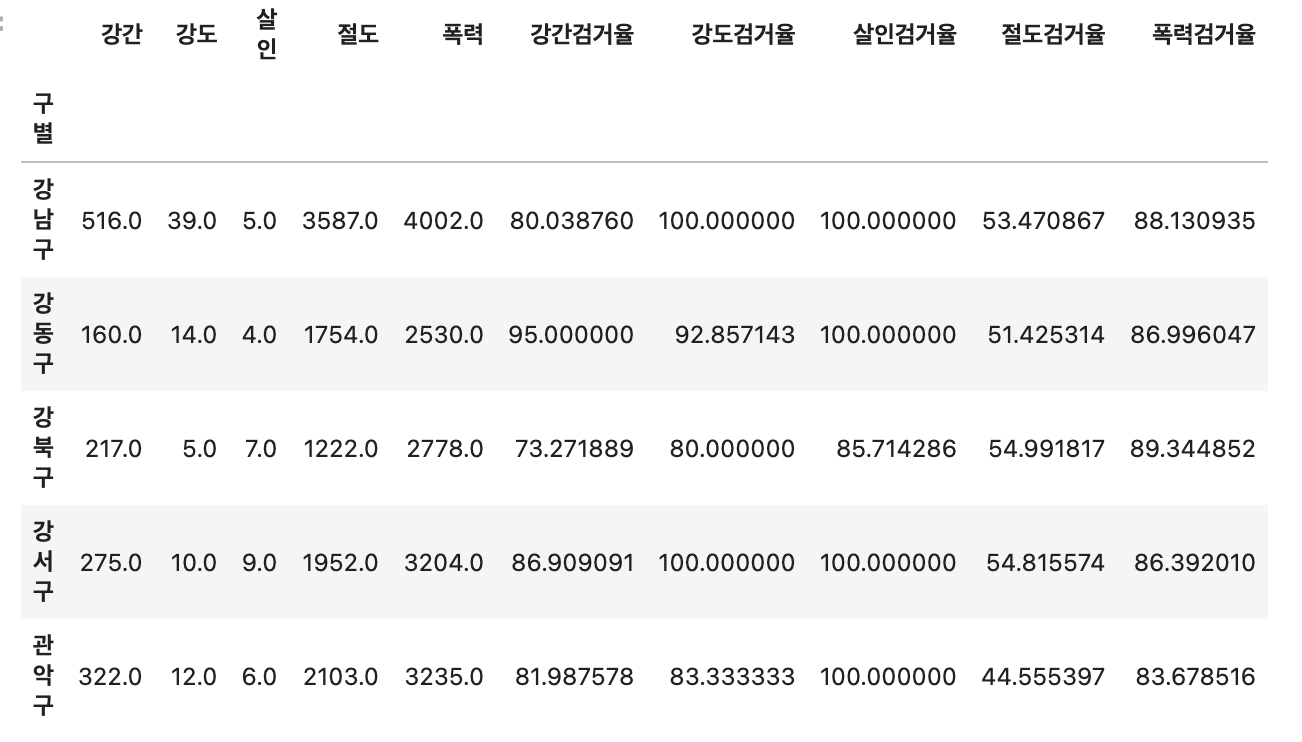
5. 범죄 데이터 정렬를 위한 데이터 정리
- 정규화하여 비교(최고:1 , 최소:0)
- CCTV 연관성을 찾기 위해 CCTV자료 추가
- 정규화된 범죄발생건수의 전체 평균을 구해서 '범죄' 칼럼 대표값으로 사용
- 검거율의 평균을 구해서 '검거' 컬럼의 대표값으로 사용
- numpy: axis=1 행, axis=0 열 <-> pandas: axis=1 열, axis=0 행
# 정규화 범죄발생수
col = ["강간", "강도", "살인", "절도", "폭력"]
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()
# 검거율 추가
col2 = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_anal_norm[col2] = crime_anal_gu[col2]
# CCTV
result_CCTV = pd.read_csv("../data/01. CCTV_reulst.csv", index_col="구별", encoding="utf-8")
crime_anal_norm[["인구수", "CCTV"]] = result_CCTV[["인구수", "소계"]]
#'범죄' 칼럼
col = ["강간", "강도", "살인", "절도", "폭력"]
crime_anal_norm["범죄"]=np.mean(crime_anal_norm[col], axis=1)
# '검거' 컬럼
col = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율"]
crime_anal_norm["검거"] = np.mean(crime_anal_norm[col], axis=1)
crime_anal_norm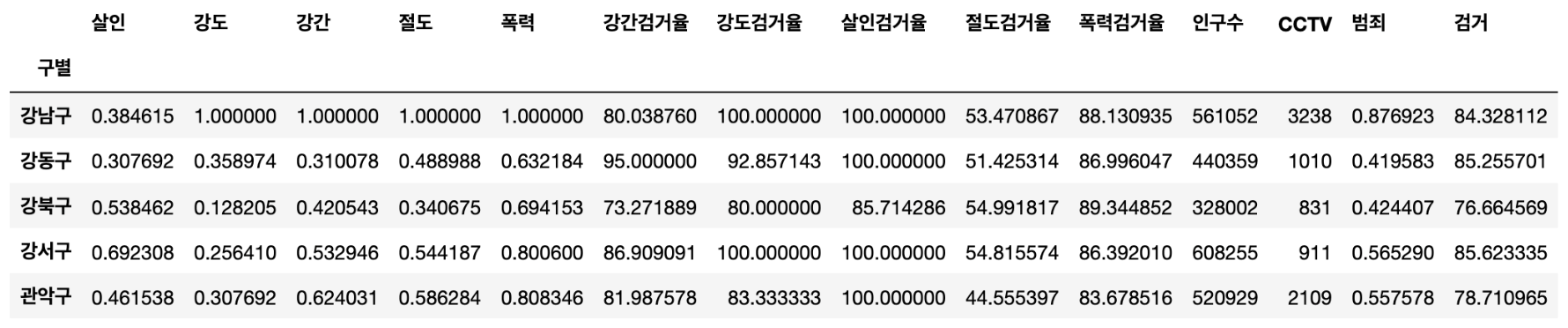
6. 서울시 범죄현황 데이터 시각화
pairplot
강도, 살인, 폭력
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
plt.rcParams["axes.unicode_minus"]=False
get_ipython().run_line_magic("matplotlib", "inline")
rc("font", family="Arial Unicode MS")
# kind : {'scatter', 'kde', 'hist', 'reg'}
sns.pairplot(data=crime_anal_norm, vars=["살인", "강도", "폭력"], kind="reg", height=4)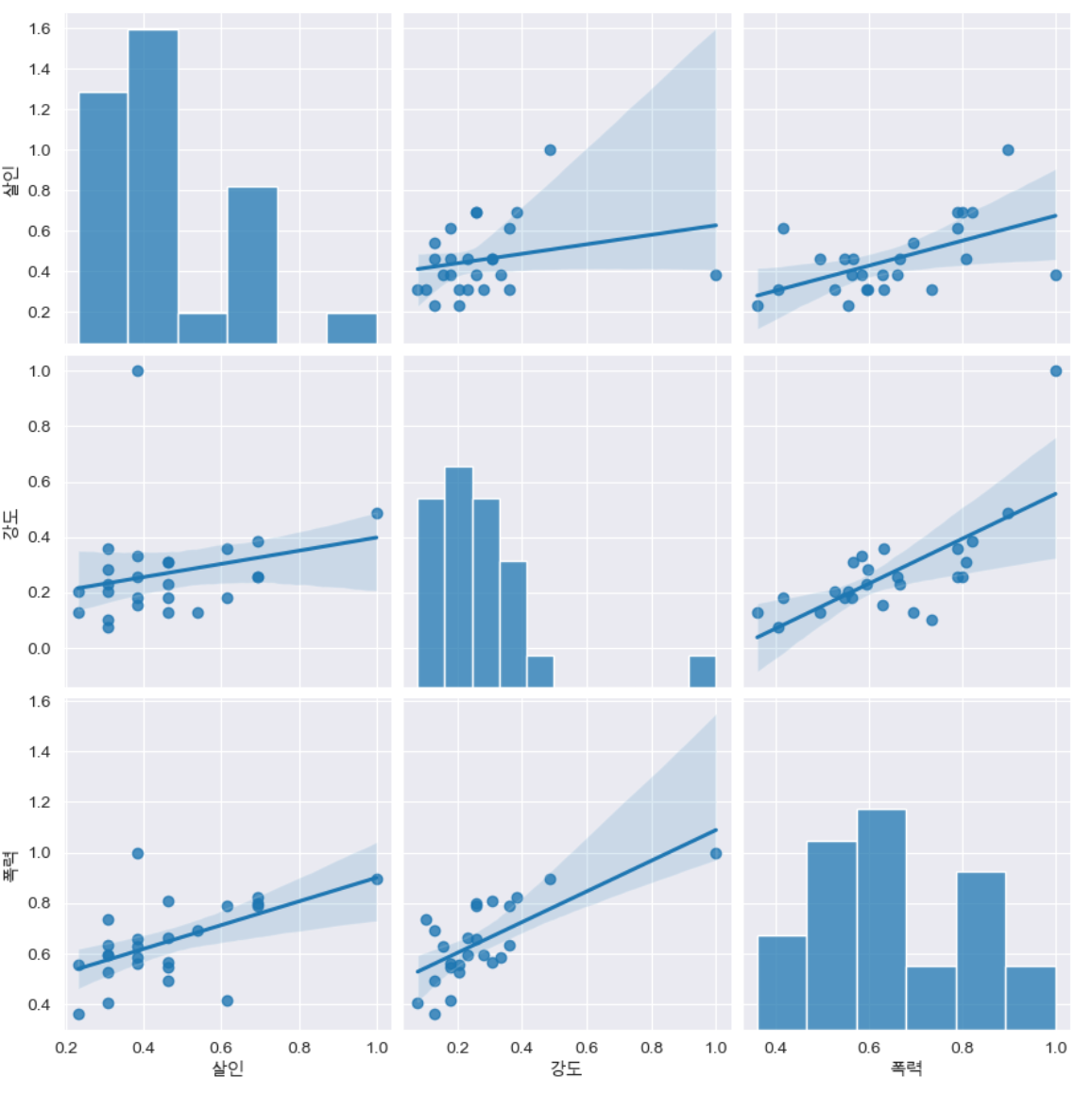
인구수, cctv & 살인, 강도
def drawGraph():
sns.pairplot(
data=crime_anal_norm,
x_vars=["인구수", "CCTV"],
y_vars=["살인", "강도"],
kind="reg",
height=4
)
plt.show()
drawGraph()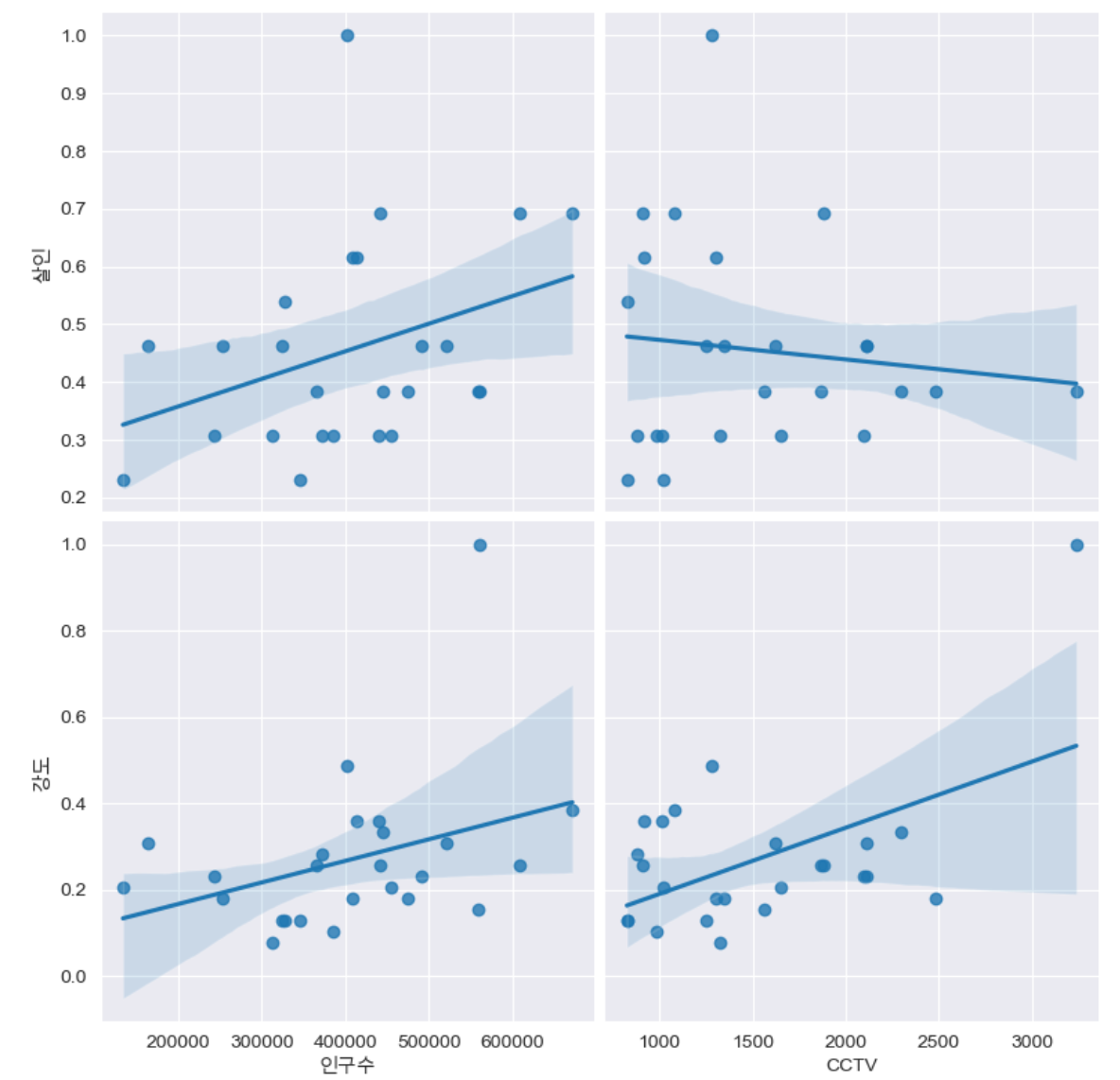
인구수, cctv & 살인검거율, 폭력검거율
def drawGraph():
sns.pairplot(
data=crime_anal_norm,
x_vars=["인구수", "CCTV"],
y_vars=["살인검거율", "폭력검거율"],
kind="reg",
height=4
)
plt.show()
drawGraph()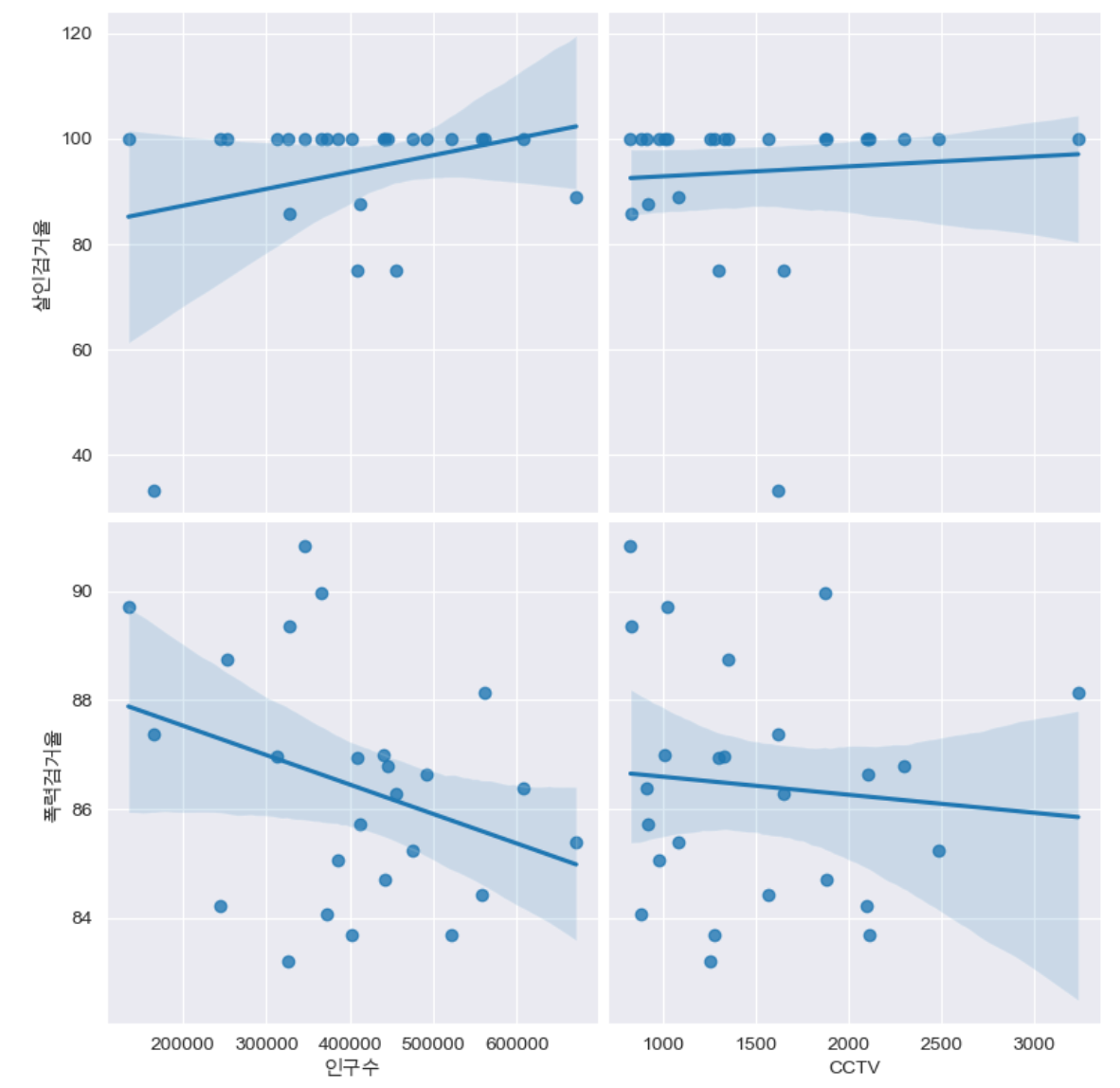
인구수, cctv & 절도검거율, 강도검거율
def drawGraph():
sns.pairplot(
data=crime_anal_norm,
x_vars=["인구수", "CCTV"],
y_vars=["절도검거율", "강도검거율"],
kind="reg",
height=4
)
plt.show()
drawGraph()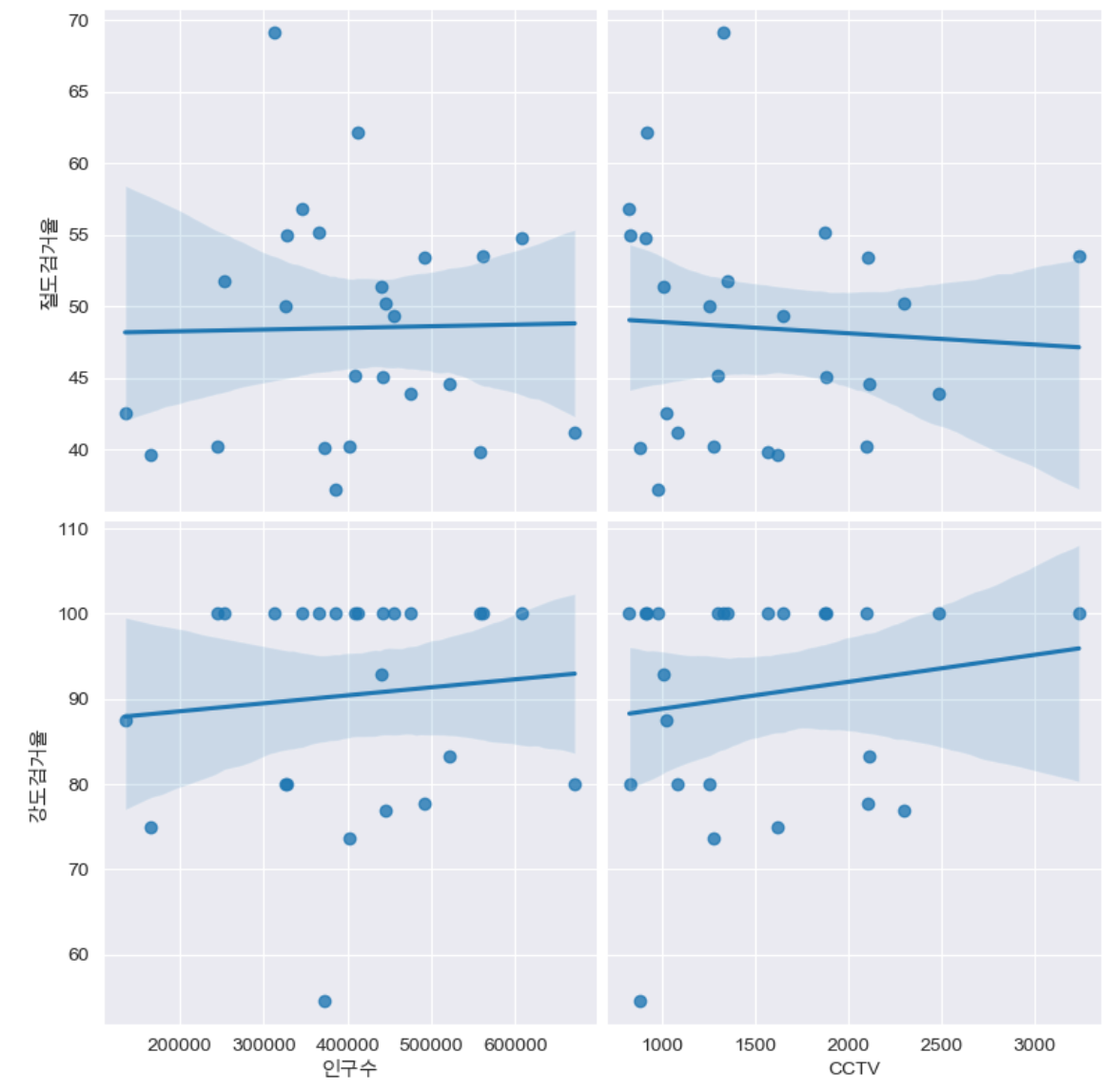
heatmap
검거율
- "검거"평균 기준으로 정렬
- 데이터 프레임 생성
- 그래프 설정
#"검거"평균 기준으로 정렬
def drawGraph():
#데이터 프레임 생성
target_col=["살인검거율", "강도검거율", "절도검거율", "폭력검거율", "강간검거율", "검거"]
crime_anal_norm_sort= crime_anal_norm.sort_values(by="검거", ascending=False)#내림차순
#그래프 설정
plt.figure(figsize=(10, 10))
sns.heatmap(
data=crime_anal_norm_sort[target_col],
annot=True,
fmt='f', #실수
linewidths=0.5, #간격설정
cmap="RdPu"
)
plt.title("범죄 검거 비율(정규화된 검거의 합으로 정렬)")
plt.show()
drawGraph()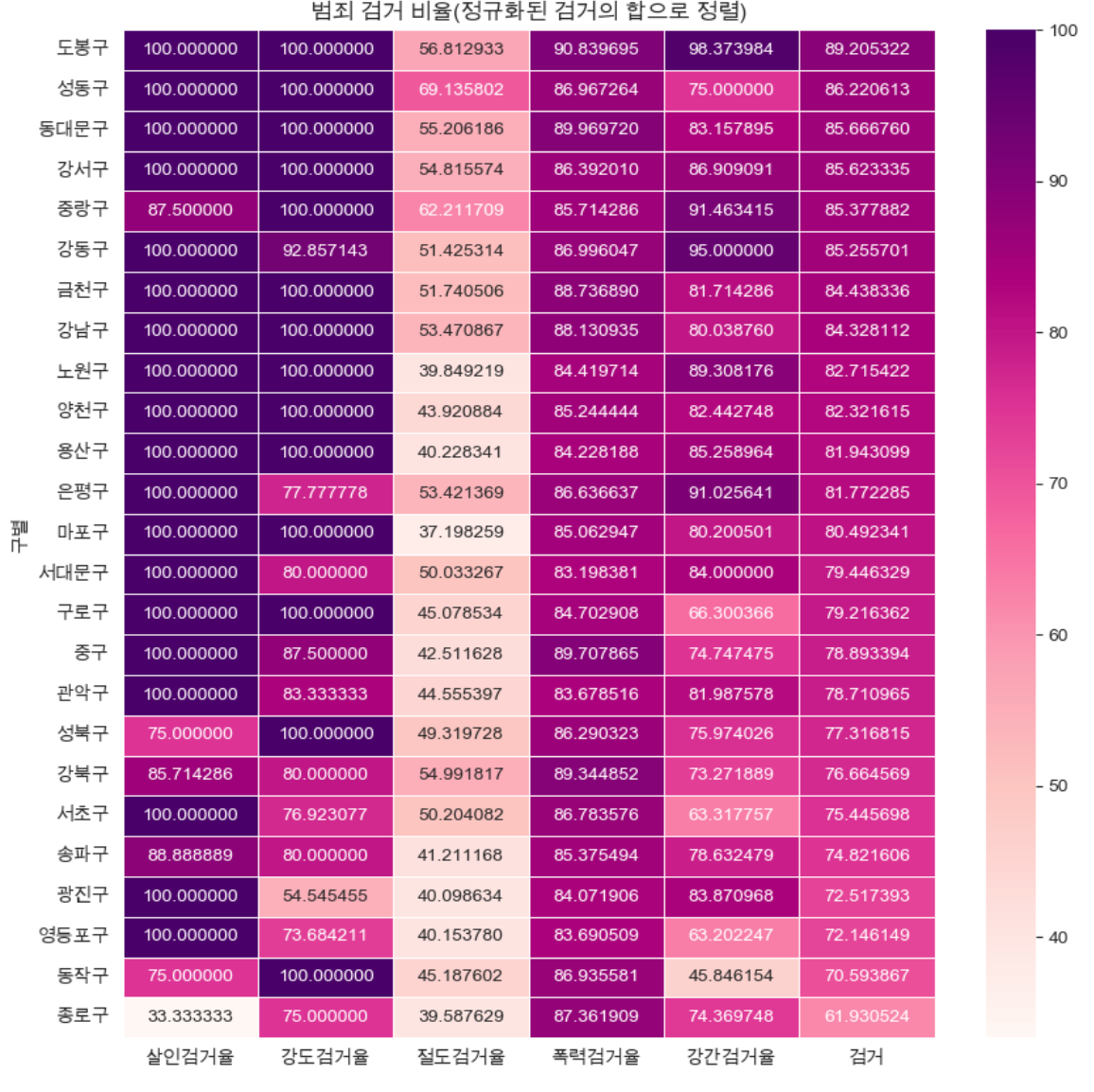
범죄건수
- "범죄"평균 기준으로 정렬
- 데이터 프레임 생성
- 그래프 설정
#"범죄"평균 기준으로 정렬
def drawGraph():
#데이터 프레임 생성
target_col=["살인", "강도", "절도", "폭력", "강간", "범죄"]
crime_anal_norm_sort= crime_anal_norm.sort_values(by="범죄", ascending=False)#내림차순
#그래프 설정
plt.figure(figsize=(10, 10))
sns.heatmap(
data=crime_anal_norm_sort[target_col],
annot=True,
fmt='f', #실수
linewidths=0.5, #간격설정
cmap="RdPu"
)
plt.title("범죄 비율(정규화된 발생 건수로 정렬)")
plt.show()
drawGraph()
#데이터 저장
crime_anal_norm.to_csv("../data/02. crime_in_Seoul_final.csv", sep=",", encoding="utf-8")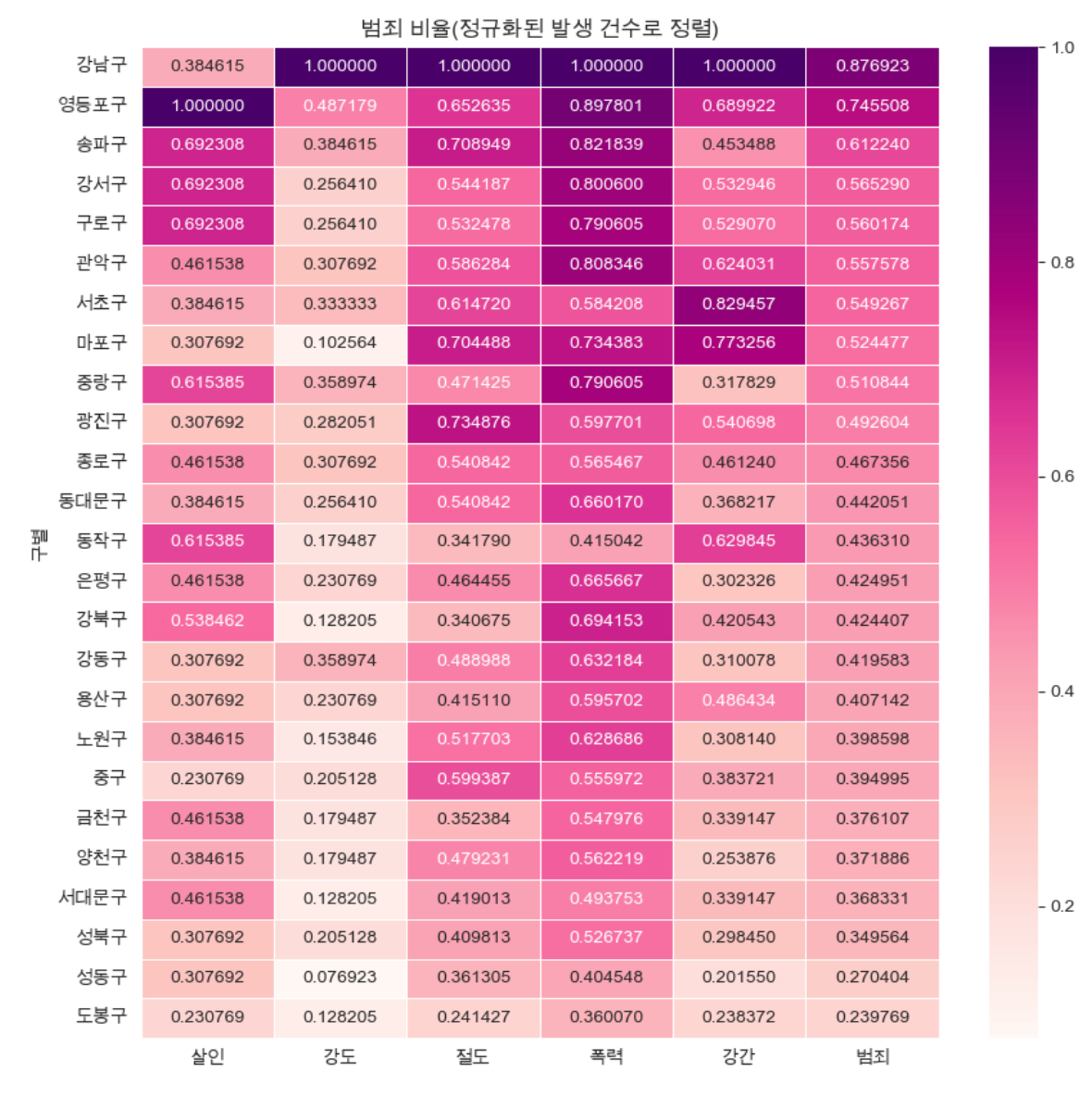
Reference
1) 제로베이스 데이터스쿨 강의자료
2) 정규화 이유
3) Pandas DataFrame 반복
- 컬럼을 컬럼으로 나누는 방법 추가 설명
#하나의 컬럼을 다른 컬럼으로 나누기
crime_anal_gu["강도검거"]/crime_anal_gu["강도발생"]
#다수의 컬럼을 다른 칼럼으로 나누기
crime_anal_gu[["강도검거", "살인검거"]].div(crime_anal_gu["강도발생"], axis=0).head()
#다수의 컬럼을 다수의 컬럼으로 나누기
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"]
den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"]
crime_anal_gu[num].div(crime_anal_gu[den].values).head()
데이터 사이언스 / just do it