
1. 데이터 읽기
- load_boston이 이제 지원이 안돼서 이 방식으로 진행해야 함!
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
# 데이터 파악을 위해 pandas로 정리
boston =pd.DataFrame(data, columns=['CRIM','ZN','INDUS','CHAS', 'NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT'])
boston['PRICE'] = target
2. 집값 히스토그램
import plotly_express as px
# import plotly.express as px
# 집값에 대한 히스토그램
fig = px.histogram(boston, x='PRICE')
fig.show()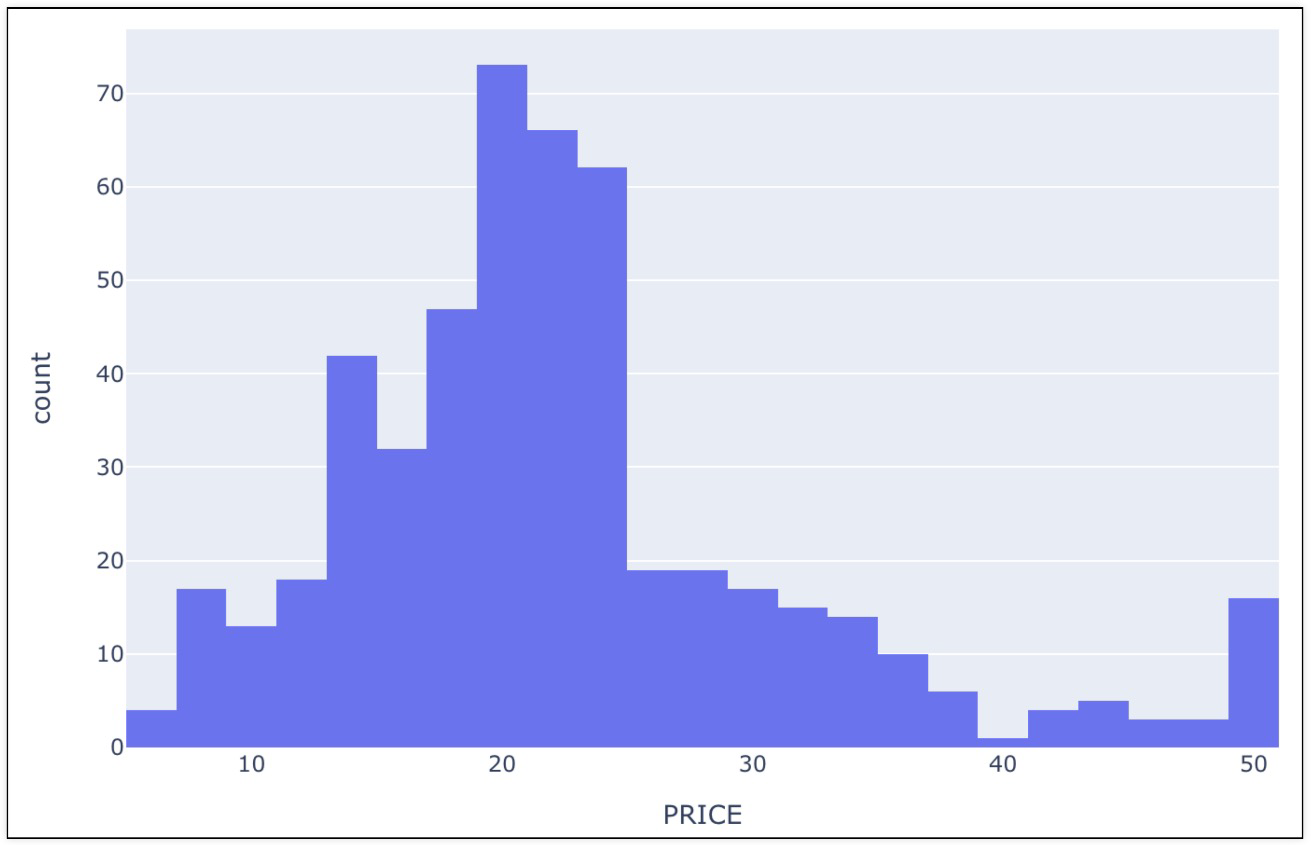
3. 각 특성별 상관계수 확인
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
corr_mat = boston.corr().round(1)
sns.set(rc={'figure.figsize':(10,8)})
sns.heatmap(data=corr_mat, annot=True, cmap='bwr')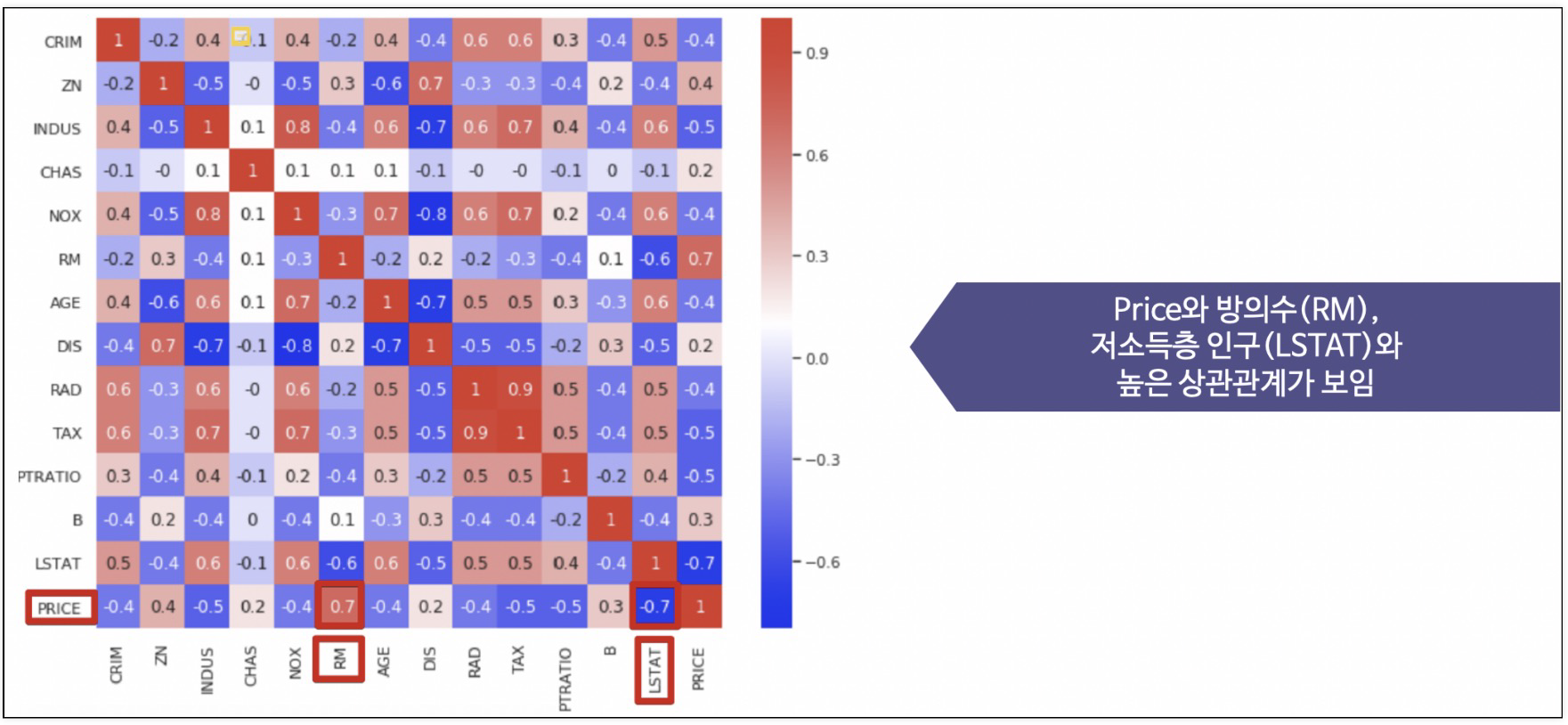
4. RM,LSTAT,PRICE 관계 관찰
- 저소득층 인구가 낮을 수록, 방의 개수가 많을 수록 집 값이 높아진다?
sns.set_style('darkgrid')
sns.set(rc={'figure.figsize':(12,6)})
fig, ax = plt.subplots(ncols=2)
sns.regplot(x='RM', y='PRICE', data=boston, ax=ax[0])
sns.regplot(x='LSTAT', y='PRICE', data=boston, ax=ax[1])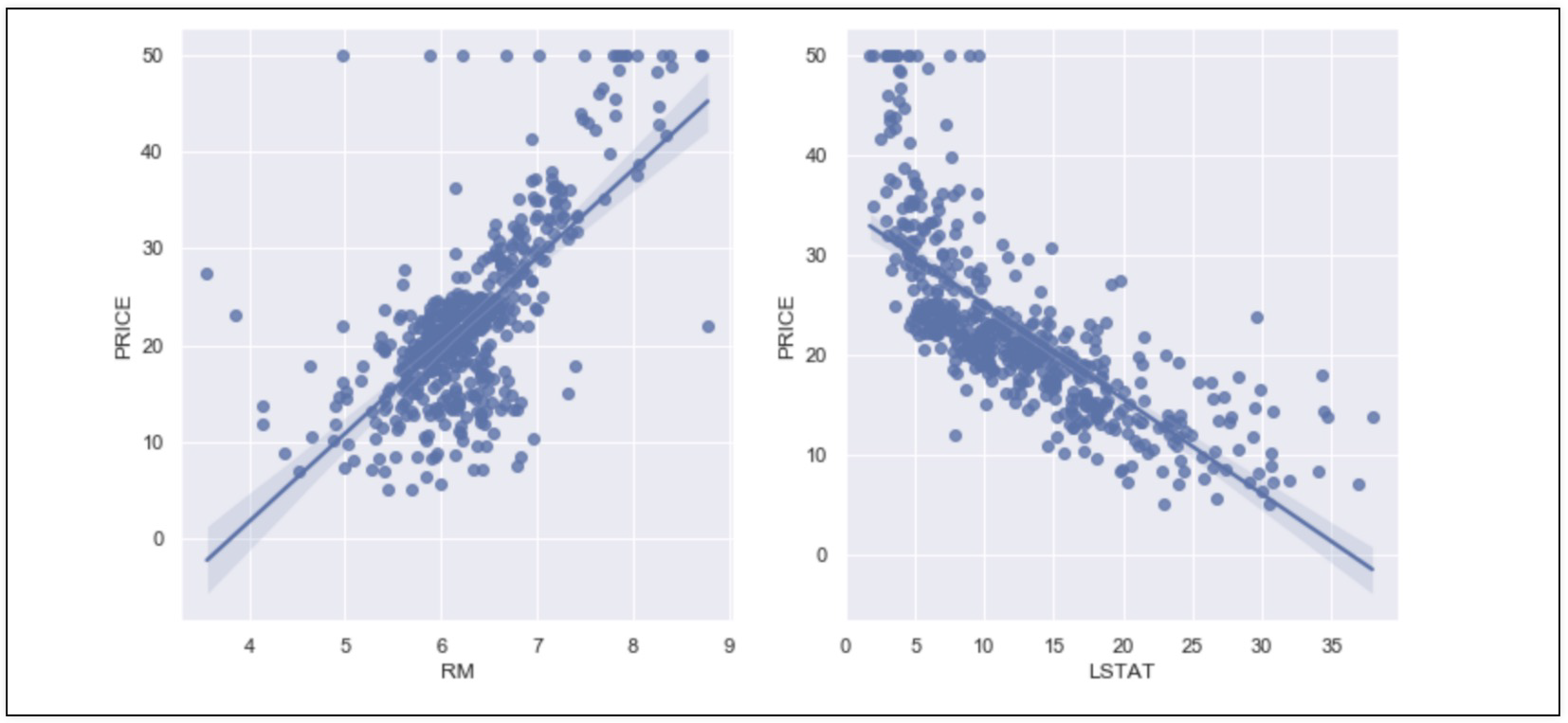
5. 데이터 분리
from sklearn.model_selection import train_test_split
X = boston.drop('PRICE', axis=1)
y = boston['PRICE']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)6. 선형회귀
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train, y_train)7. 모델 평가
- RMSE(Root Mean Squared Error)
import numpy as np
from sklearn.metrics import mean_squared_error
pred_tr = reg.predict(X_train)
pred_test = reg.predict(X_test)
rmse_tr = (np.sqrt(mean_squared_error(y_train, pred_tr)))
rmse_test = (np.sqrt(mean_squared_error(y_test, pred_test)))
print('RMSE of Train Data: ', rmse_tr) # RMSE of Train Data: 4.642806069019824
print('RMSE of Test Data: ', rmse_test) # RMSE of Test Data: 4.9313525841467078. 성능확인
plt.scatter(y_test, pred_test)
plt.xlabel('Actaul House Pirces ($1000)')
plt.ylabel('Predicted Prices')
plt.title('Real vs Predicted')
plt.plot([0,48], [0,48], 'r')
plt.show()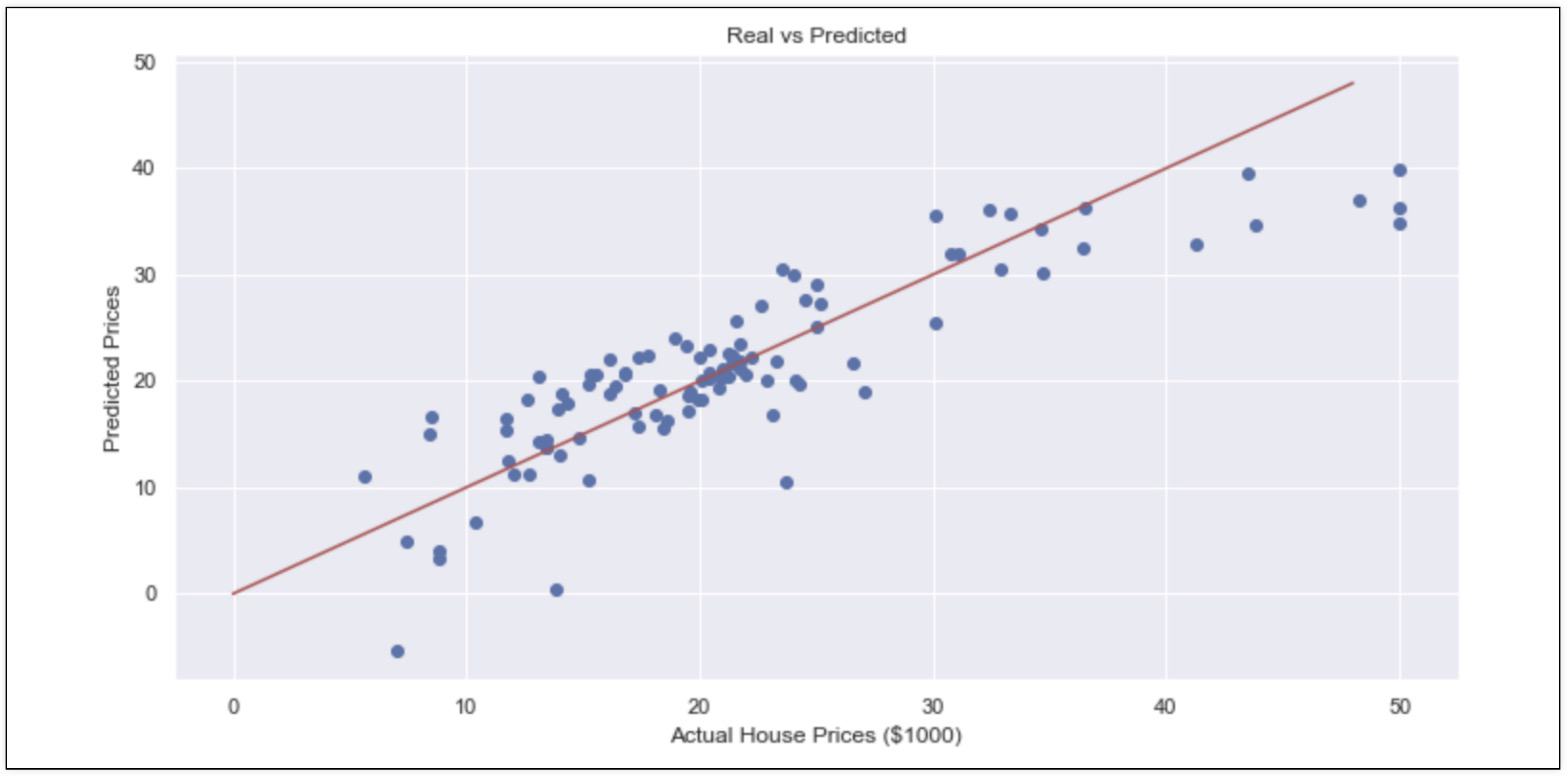
9. LSTAT 데이터 사용에 대한 타당성 확인
- 성능 나빠는 것으로 보아 빼지 않는 것이 옳은가? 이것을 결정하는 역할이 중요
X = boston.drop(['PRICE', 'LSTAT'], axis=1)
y = boston['PRICE']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
reg = LinearRegression()
reg.fit(X_train, y_train)
pred_tr = reg.predict(X_train)
pred_test = reg.predict(X_test)
rmse_tr = (np.sqrt(mean_squared_error(y_train, pred_tr)))
rmse_test = (np.sqrt(mean_squared_error(y_test, pred_test)))
print('RMSE of Train Data: ', rmse_tr)
print('RMSE of Test Data: ', rmse_test)
'''
RMSE of Train Data: 5.165137874244864
RMSE of Test Data: 5.295595032597149
'''10. 성능확인
plt.scatter(y_test, pred_test)
plt.xlabel('Actaul House Pirces ($1000)')
plt.ylabel('Predicted Prices')
plt.title('Real vs Predicted')
plt.plot([0,48], [0,48], 'r')
plt.show()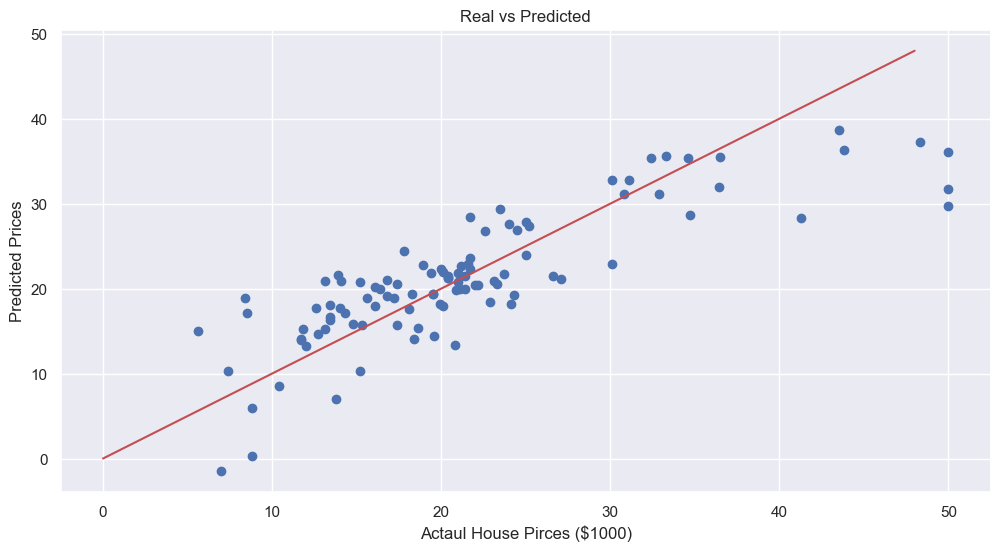
Reference
1) 제로베이스 데이터스쿨 강의자료
2) https://velog.io/@hyesoup/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%ED%9A%8C%EA%B7%80-%EB%AA%A8%EB%8D%B8%EC%9D%98-%EC%84%B1%EB%8A%A5-%ED%8F%89%EA%B0%80-%EC%A7%80%ED%91%9C-MAE-MSE-RMSE-R-squred

데이터 사이언스 / just do it