
📖 수업내용
# 데이터베이스
1) 데이터베이스란?
-
다양한 카테고리의 정보를 저장할 수 있는 구조로 되어 있으며, 여러 사람에 의해 공유되어 사용될 목적으로 통합하여 관리되는 데이터의 집합이다.
-
데이터베이스를 사용하는 이유는 파일 단위로 저장할 때, 데이터 종속성 및 중복성, 데이터 무결성 문제가 존재하기 때문이다.
- 데이터 독립성 : 데이터베이스 사이즈를 늘리거나 성능 향상을 위해 데이터 파일을 늘리거나 새롭게 추가하더라도 관련된 응용 프로그램을 수정할 필요가 없다.
- 데이터 중복 최소화 : 데이터베이스는 데이터를 통해해서 관리함으로써 파일 시스템의 단점 중 하나인 자료의 중복과 데이터의 중복성 문제를 해결할 수 있다.
- 데이터 무결성 : 여러 경로를 통해 잘못된 데이터가 발생하는 경우의 수를 방지하는 기능으로 데이터의 유효성 검사를 통해 데이터의 무결성을 구현하게 된다.
🤷🏻♀️ file system 이란?
: 데이터베이스를 사용하기 전 데이터의 저장을 위해 이용했던 시스템이다.
-> 데이터를 기록하고 여러 사람이 공유하여 사용할 수 있다. (예: 엑셀 프로그램으로 데이터 관리)
# DBMS
: DataBase Management System
- 파일 시스템이 가진 문제를 해결하기 위해 만들어진 것이며, 데이터베이스에 접근하고 이를 관리하기 위해 존재한다.
- 사용자와 데이터베이스를 연결시켜주는 소프트웨어이며, 데이터베이스 사용자가 데이터베이스를 생성, 공유, 관리할 수 있도록 하는 역할을 한다.
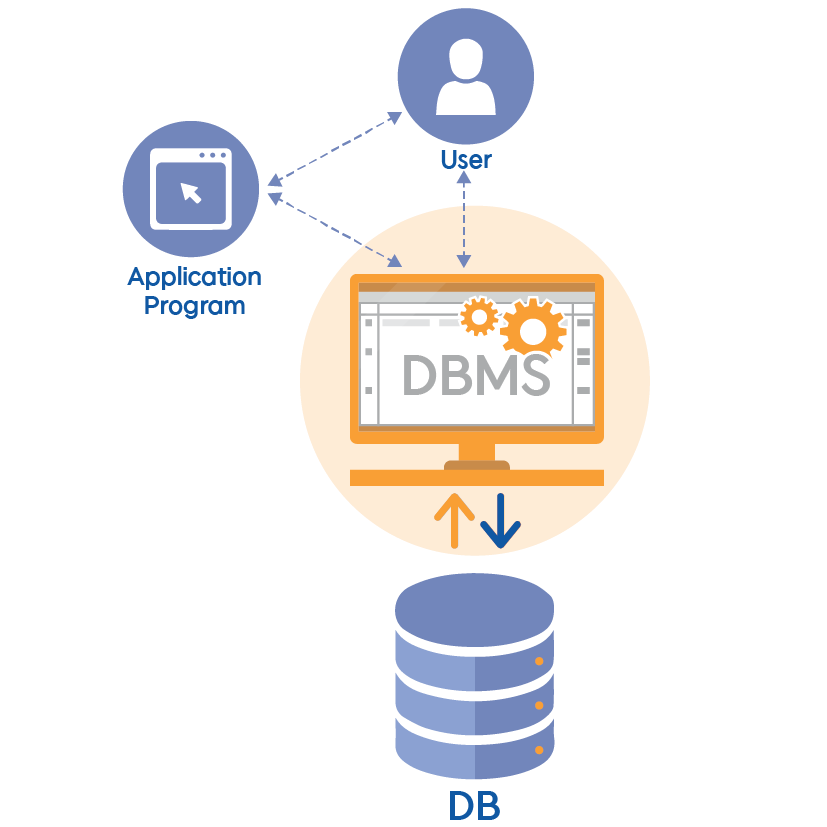
🤷🏻♀️ RDBMS 이란?
: DBMS + relational
예: Oracle, SQL Server, DB2, MySQL, PostgreSQL, SQLite 등
2) 데이터베이스 용어
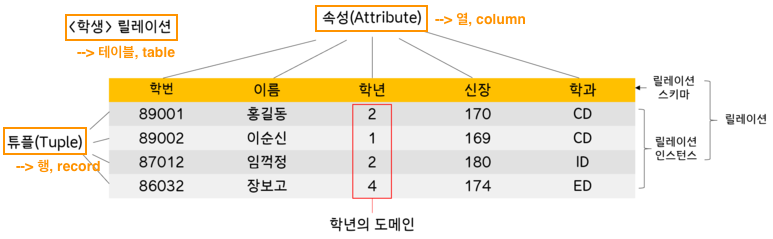
# 키 (key)
: 데이터베이스에서 특정 튜플을 식별하거나 순서대로 정렬할 때 구분하고 정렬의 기준이 되는 속성이다. 테이블 간 관계를 맺는 데도 사용한다.
① 기본키(PK, Primary Key)
- 메인 키로 한 테이블에서 특정 튜플(행)을 유일하게 구별할 수 있는 속성이다. -> Null 값과 중복 불가
NULL이란?- 데이터에 값이 존재하지 않음을 나타낸다.
- 테이블당 오직 하나의 필드에만 설정이 가능하다.
② 외래키(FK, Foreign Key)
- 다른 테이블의 기본키를 참조하는 속성이다.
- 참조하고(외래키) 참조되는(기본키) 양쪽 테이블 도메인(속성이 가질 수 있는 값의 집합)은 서로 같아야 한다. -> 속성은 달라도 되는데, 그 안의 값은 같아야 한다.
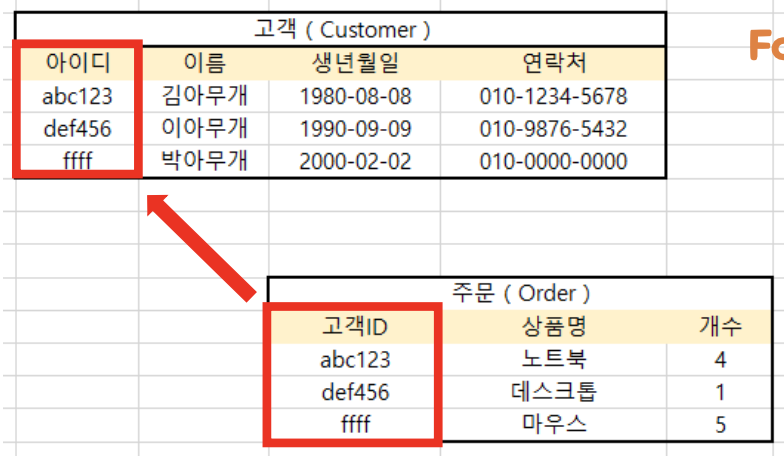
이미지 참고: 포스코x코딩온 강의 자료(1013데이터베이스1_MySQL소개.pdf)
- 참조되는(기본키) 값이 변경되면 참조하는(외래키) 값도 변경된다.
- NULL 값과 중복 값 등을 허용하며, 자기 자신의 기본키를 참조하는 외래키도 가능하다.
# MySQL
- 가장 널리 사용되고 있는 관계형 데이터베이스 관리 시스템(RDBMS)이다.(오픈 소스)
# MySQL 설치하기
① 사이트에 접속해서 운영체제에 맞게 설치한다.
② MySQL 실행하기 (MacOS)
# 1. mysql 설치된 경로로 이동
cd /usr/local/mysql/bin
# 2. 사용자명 root, 비밀번호 사용해 mysql 접속
./mysql -u root -p
# 3. mysql 종료 (-> 다시 콘솔로 돌아가기)
quit
# exit 로도 가능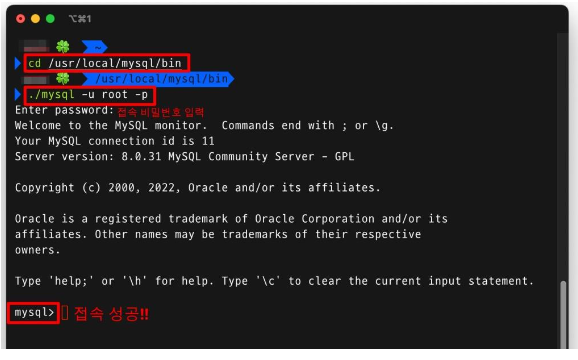
이미지 참고: 포스코x코딩온 강의 자료(1013데이터베이스1_MySQL소개.pdf)
+) MySQL Wokbench
- 데이터를 시작적으로 확인하기 편리하다.
MySQL Wokbench 설치
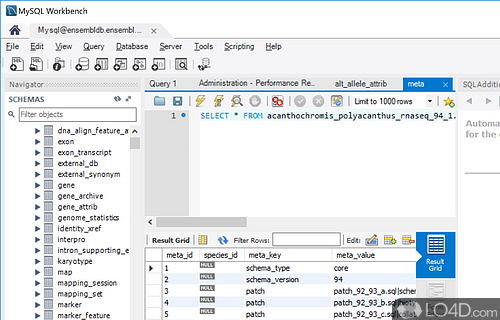
# SQL문
: Structured Query Language / 구조적 쿼리 언어
-> 관계형 데이터베이스를 제어하고 관리할 수 있는 목적의 프로그래밍 언어이다.
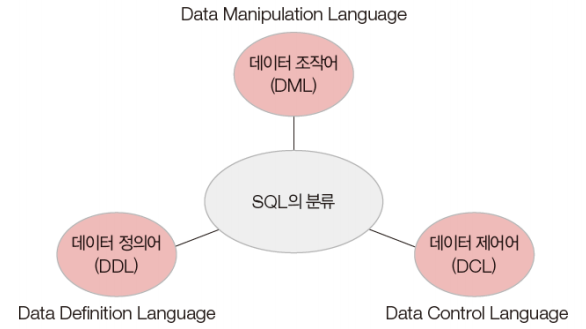
-> 기능에 따라서 DDL, DML, DCL로 분류할 수 있다.
+) SQL 공통
# 데이터베이스 목록 보기
SHOW DATABASES;
# 데이터베이스 이용하기
USE 데이터베이스명;
# 테이블 목록 보기
SHOW TABLES;
# 테이블 구조 보기
DESC 테이블명;1) DDL (Data Definition Language)
: 데이터베이스 혹은 테이블을 정의하는 언어이다.
① CREATE
: 데이터베이스, 테이블 등을 생성하는 역할을 한다.
# 1. 데이터베이스 만들기
CREATE DATABASE 이름 DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
# 테이블 생성시, 기본 인코딩을 UTF8로 설정 -> 프로그래밍 언어는 영어 기반이므로 한글을 사용할 수 있도록 하기 위함이다.
# 2. 테이블 만들기
CREATE TABLE tableName (
### 필드1 값형식,
id VARCHAR(10) NOT NULL PRIMARY KEY,
name VARCHAR(10) NOT NULL,
birthday DATE NOT NULL
);* 문자형 데이터 형식
| 데이터 타입 | 바이트 수 | 설명 |
|---|---|---|
| CHAR(n) | 1 ~ 255 byte | 고정 길이 데이터 타입 -> 지정된 길이보다 짧은 데이터 입력될 시 나머지 공간 공백으로 채워진다. |
| VARCHAR(n) | 1 ~ 65535 byte | 가변 길이 데이터 타입 -> 지정된 길이보다 짧은 데이터 입력될 시 나머지 공간은 채우지 않는다. |
| TINYTEXT(n) | 1 ~ 255 byte | 문자열 데이터 타입 |
| TEXT(n) | 1 ~ 65535 byte | 문자열 데이터 타입 |
| MEDIUMTEXT(n) | 1 ~ 16777215 byte | 문자열 데이터 타입 |
| LONGTEXT(n) | 1 ~ 4294967295 byte | 문자열 데이터 타입 |
* 숫자형 데이터 형식
| 데이터 타입 | 바이트 수 | 설명 |
|---|---|---|
| TINYINT(n) | 1 byte | 정수형 데이터 타입이며, "-128 ~ +127" 또는 "0 ~ 255" 표현 가능하다. |
| SMALLINT(n) | 2 byte | 정수형 데이터 타입이며, "-32768 ~ +32767" 또는 "0 ~ 65536" 표현 가능하다. |
| MEDIUMINT(n) | 3 byte | 정수형 데이터 타입이며, "-8388608 ~ 8388607" 또는 "0 ~ 16777215" 표현 가능하다. |
| INT(n) | 4 byte | 정수형 데이터 타입이며, "-2147483648 ~ +2147863647" 또는 "0 ~ 4294967295" 표현 가능하다. |
| BIGINT(n) | 8 byte | 정수형 데이터 타입이며, 무제한으로 표현 가능하다. |
| FLOAT(길이, 소수) | 4 byte | 부동 소수형 데이터 타입이며, 고정 소수점을 사용하는 형태이다. |
| DECIMAL(길이, 소수) | 길이 + 1 byte | 고정 소수형 데이터 타입이며, 전체 자릿수(길이)와 소수점 이하 자리수를 가진 숫자형이다. |
| DOUBLE(길이, 소수) | 8 byte | 부동 소수형 데이터 타입이며, DOUBLE을 문자열로 저장한다. |
* 날짜형 데이터 형식
| 데이터 타입 | 바이트 수 | 설명 |
|---|---|---|
| DATE | 3 byte | 날짜(년, 월, 일) 형태의 기간 표현 데이터 타입이다. |
| TIME | 3 byte | 시간(시, 분, 초) 형태의 기간 표현 데이터 타입이다. |
| DATETIME | 8 byte | 날짜와 시간 형태의 기간 표현 데이터 타입이다. |
| TIMESTAMP | 4 byte | 날짜와 시간 형태의 기간 표현 데이터 타입이며, 시스템 변경 시 자동으로 그 날짜와 시간이 저장된다. |
| YEAR | 1 byte | 년도 표현 데이터 타입이다. |
② ALTER
: 테이블의 특정 컬럼을 추가, 변경 그리고 삭제할 때 사용한다.
# 1. 컬럼 추가
ALTER TABLE 테이블명 ADD COLUMN 컬럼명 타입;
# 2. 컬럼 속성 변경
ALTER TABLE 테이블명 MODIFY COLUMN 컬럼명 타입;
# 3. 컬럼 삭제
ALTER TABLE 테이블명 DROP COLUMN 컬럼명;③ DROP
: 데이터베이스, 테이블을 삭제하는 역할을 한다.
DROP TABLE 테이블명;④ TRUNCATE
: 테이블을 초기화시키는 역할을 한다.(-> 테이블의 모든 행을 삭제)
TRUNCATE TABLE 테이블명;
이미지 참고: 포스코x코딩온 강의 자료(1013데이터베이스1_MySQL소개.pdf)
2) DML (Data Manipulation Language)
: 데이터베이스의 내부 데이터를 관리하기 위한 언어이다.
① INSERT
: 테이블에 데이터를 추가하는 역할을 한다. -> Create(생성)
# 방법 1
INSERT INTO 테이블명 (필드1, 필드2, 필드3) VALUES (값1, 값2, 값3)
# 방법 2 (테이블의 모든 컬럼에 값을 추가할 때만 사용 가능)
INSERT INTO 테이블명 VALUES (값1, 값2, 값3)② SELECT
: 데이터베이스에서 데이터를 검색(조회)하는 역할을 한다. -> Read(읽기)
- query(질의어)라고도 부르며, SQL문 중에서 가장 많이 사용된다.
# 기본 작성법
SELECT 속성 이름,... FROM 테이블명 [WHERE 검색조건]
# [] 안의 값은 생략 가능
# 예시
# 테이블 전체 조회
SELECT * FROM 테이블명;
# 테이블에서 필드1 = 조건값1인 행 조회
SELECT * FROM 테이블명 WHERE 필드1 = 조건값1;
# 테이블에서 필드1 = 조건값1을 찾아서 오름차순으로 정렬
SELECT * FROM 테이블명 WHERE 필드1 = 조건값1 ORDER BY 필드1 ASC;
# 테이블에서 필드1 = 조건값1을 찾아서 내림차순으로 정렬 하는데 필드1, 필드2 값만 보여줌
SELECT 필드1, 필드2 FROM 테이블명 WHERE 필드1 = 조건값1 ORDER BY 필드1 DESC;
# 테이블에서 필드1 = 조건값1을 찾아서 내림차순으로 정렬한 후에 위에서부터 제한된 개수 만큼만 필드1, 필드2 값을 보여줌
SELECT 필드1, 필드2 FROM 테이블명 WHERE 필드1 = 조건값1 ORDER BY 필드1 DESC LIMIT 개수; ②-1) WHERE 절
* 부정 연산자
| 연산자 | 설명 |
|---|---|
| != | 같지 않다. |
| ^= | 같지 않다. |
| <> | 같지 않다. |
| NOT 칼럼명 = | ~와 같지 않다. |
* 범위, 집합, 패턴, NULL
| 연산자 | 설명 |
|---|---|
| BETWEEN a AND b | a와 b의 값 사이에 있으면 참이다. (a, b 포함) |
| IN(list) | 리스트에 있는 값 중에서 어느 하나라도 일치하면 참 |
| LIKE '비교문자열' | 비교문자열과 형태가 일치하면 사용한다. (% : 0개 이상의 어떤 문자 / _ : 1개의 단일 문자) |
| IS NULL | NULL 값인 경우 true |
* 논리 연산자
| 연산자 | 설명 |
|---|---|
| AND | 앞에 있는 조건과 뒤에 오는 조건이 참이면 결과도 참이다. |
| OR | 앞에 있는 조건과 뒤에 오는 조건 중 하나라도 참이면 결과는 참이다. |
| NOT | 뒤에 오는 조건과 반대되는 결과를 돌려준다. |
②-2) ORDER BY
- 결과가 출력되는 순서를 조절하며,
where절과 함께 사용 가능하다. (단,where절 뒤에 나와야 함!)
| 속성이름 | 설명 |
|---|---|
| ASC | Ascending, 오름차순(기본값) |
| DESC | Descending, 내림차순 |
②-3) DISTINCT
- 중복된 데이터를 제거한다.
SELECT [DISTINCT] 속성이름, ...
FROM 테이블명
[WHERE 검색 조건]
[ORDER BY 속성이름] ②-4) LIMIT
- 출력 개수를 제한한다.
SELECT [DISTINCT] 속성이름, ...
FROM 테이블명
[WHERE 검색 조건]
[ORDER BY 속성이름]
[LIMIT 개수] ②-5) 집계 함수
| 속성이름 | 설명 |
|---|---|
| SUM() | 합계 |
| AVG() | 평균 |
| MAX() | 최대값 |
| MIN() | 최소값 |
| COUNT() | 행 개수 |
| COUNT(DISTINCT) | 중복 제외한 행 개수 |
# 테이블에서 필드1 모든 행의 값의 총합 검색
select sum(필드1) from 테이블명;
# 테이블에서 필드1 모든 행의 값의 총합 검색 + 의미 있는 열 이름으로 변경
select sum(필드1) as '의미 있는 열 이름' from 테이블명; ②-6) GROUP BY
| 속성이름 | 설명 |
|---|---|
| GROUP BY | 속성 이름끼리 그룹으로 묶는 역할이다. |
| HAVING | group by절의 결과를 나타내는 그룹의 조건을 설정한다. |
③ UPDATE
: 테이블에서 데이터를 수정하는 역할을 한다. -> Update(갱신)
UPDATE 테이블명 SET 필드1=값1 WHERE 필드2=조건2;
# 테이블에서 필드2=조건2을 찾아서 필드1의 값을 값1로 변경한다.④ DELETE
: 테이블에서 데이터를 삭제하는 역할을 한다. -> Delete(삭제)
DELETE FROM 테이블명 WHERE 필드1=값1;
# 테이블에서 필드1=값1을 찾아서 삭제한다.❗️ SQL 문 실행 순서
이미지 참고: 포스코x코딩온 강의 자료(1013데이터베이스1_MySQL소개.pdf)

3) DCL (Data Control Language)
: 데이터 저어어이며, 데이터베이스에 접근해 읽거나 쓰는 것을 제한할 수 있는 권한을 부여하거나 박탈한다.
① GRANT
: 특정 데이터베이스 사용자에게 특정 작업에 대한 수행 권한을 부여한다.
GRANT permission_type ON db_name.table_name TO username@host INDETIFIED BY 'pw' [WITH GRANT OPTION];② REVOKE
: 특정 데이터베이스 사용자에게 특정 작업에 대한 권한을 박탈한다.
REVOKE permission_type ON db_name.table_name FROM 'username'@'host';+)
JOIN
: 두 테이블을 묶어서 하나의 테이블을 만든다.SELECT 속성이름, ... FROM 테이블A, 테이블B WHERE 조인조건 AND 검색조건;①
Inner JoinSELECT 속성이름, ... FROM 테이블A INNER JOIN 테이블B ON 조인조건 WHERE 검색조건;②
Outer Join# outer join 은 inner join과 다르게 공통되지 않은 row도 유지한다. # Left Outer Join SELECT 속성이름, ... FROM 테이블A LEFT JOIN 테이블B ON 조인조건; # Right Outer Join SELECT 속성이름, ... FROM 테이블A RIGHT JOIN 테이블B ON 조인조건;
참고: 포스코x코딩온 강의 자료(1013데이터베이스1_MySQL소개.pdf)
👩🏻💻 학습
# 실습 1
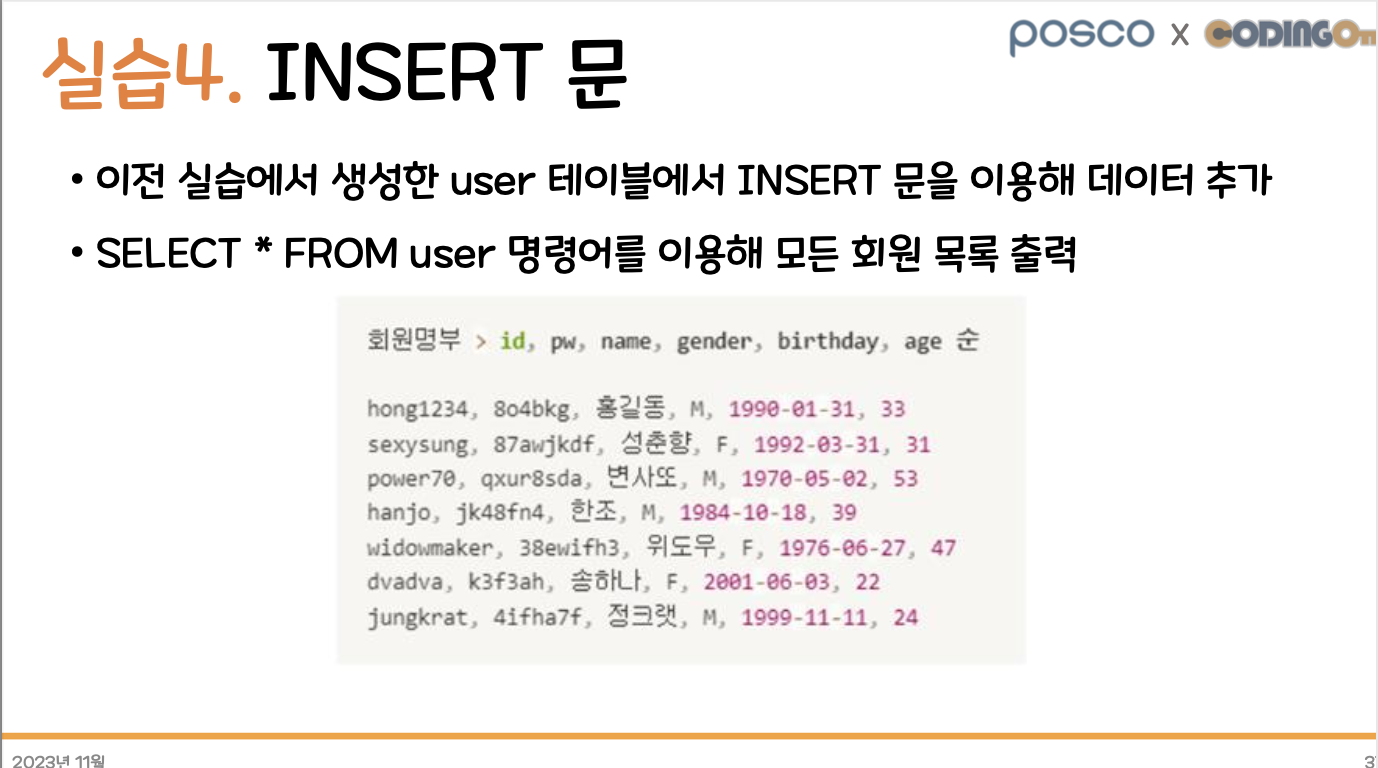
〉 작성 코드
create table user (
id varchar(10) not null primary key,
pw varchar(20) not null,
name varchar(5) not null,
gender enum('F', 'M', '') default '',
birthday date not null,
age int(3) not null default 0
);
desc user;
INSERT INTO user VALUES('hong1234', '8o4bkg', '홍길동', 'M', '1990-01-31', 33);
INSERT INTO user VALUES('sexysung', '87awjkdf', '성춘향', 'F', '1992-03-03', 31);
INSERT INTO user VALUES('power70', 'qxur8sda', '변사또', 'M', '1970-05-02', 53);
INSERT INTO user VALUES('hanjo', 'jk48fn4', '한조', 'M', '1984-10-18', 39);
INSERT INTO user VALUES('widowmaker', '38ewifh3', '위도우', 'F', '1976-06-27', 47);
INSERT INTO user VALUES('dvadva', 'k3f3ah', '송하나', 'F', '2001-06-03', 22);
INSERT INTO user VALUES('jungkrat', '4ifha7f', '정크랫', 'M', '1999-11-11', 24);# 실습 2
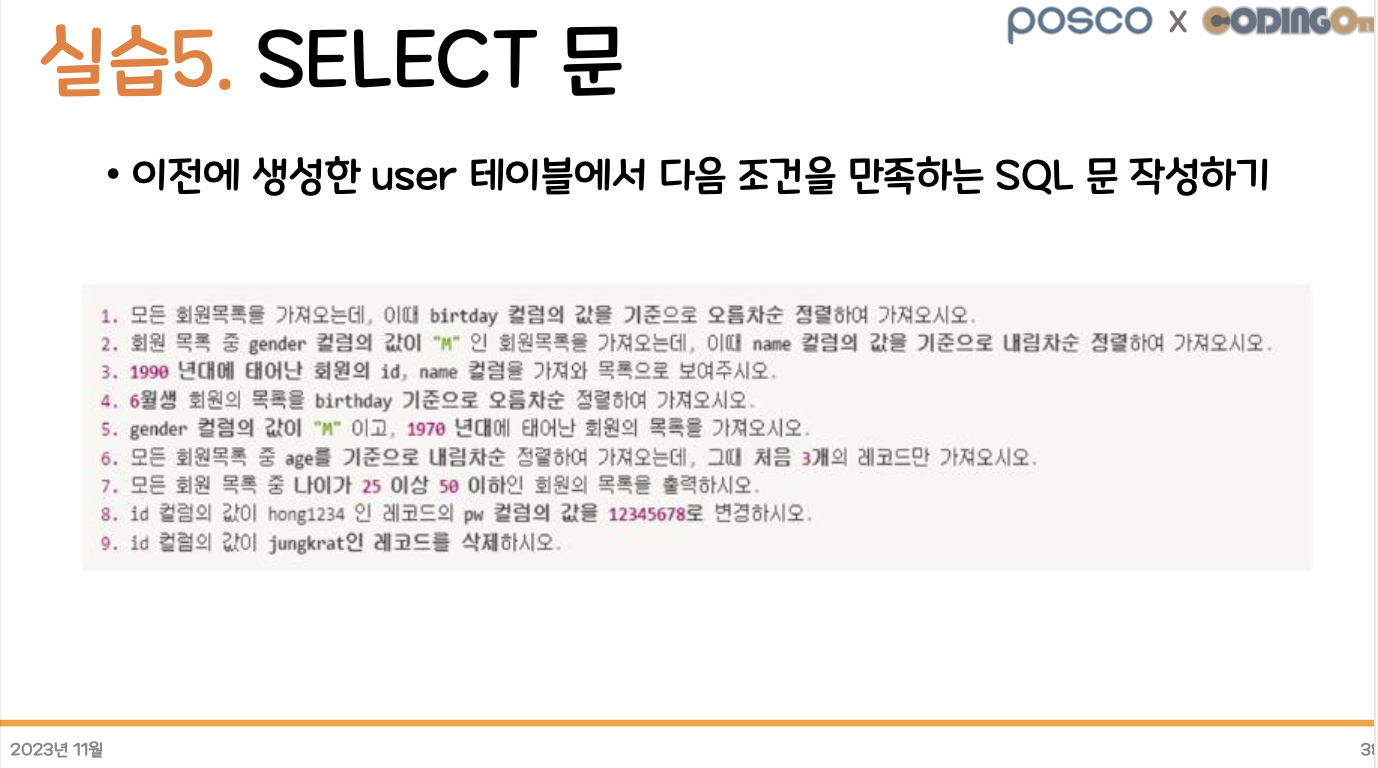
〉 작성 코드
-- 1. 모든 회원 목록을 가져오는데, 이때 birthday 컬럼의 값을 기준으로 오름차순 정렬
select * from user order by birthday;
-- 2. 회원 목록 중 gender 컬럼의 값이 'M'인 회원목록을 가져오는데, 이 때 name 컬럼의 값을 기준으로 내림차순 정렬
select * from user where gender = 'M' order by name desc;
-- 3. 1990년대에 태어난 회원의 id, name 컬럼 가져오기
select id, name from user where birthday >= '1990-01-01' and birthday < '2000-01-01';
-- 4. 6월 생 회원의 목록을 birthday 기준으로 오름차순 정렬
select * from user where birthday like '%-06-%' order by birthday;
-- 5. gender 컬럼의 값이 'M'이고, 1970년대에 태어난 회원의 목록 가져오기
select * from user where gender = 'M' and birthday >= '1970-01-01' and birthday < '1980-01-01';
-- 6. 모든 회원목록 중 age를 기준으로 내림차순 정렬하는데, 그 때 처음 3개의 레코드만 가져오기
select * from user order by age desc limit 3;
-- 7. 모든 회원 목록 중 나이가 25 이상 50 이하인 회원의 목록 가져오기
select * from user where age >= '25' and age <= '50';
-- 8. id 컬럼의 값이 honng1234인 레코드의 pw 컬럼의 값을 12345678로 변경하기
update user set pw = '12345678' where id = 'hong1234';
select * from user;
-- 9. id 컬럼의 값이 jungkrat인 레코드를 삭제하기
delete from user where id = 'jungkrat';이미지 참고: 포스코x코딩온 강의 자료(1013데이터베이스1_MySQL소개.pdf)
