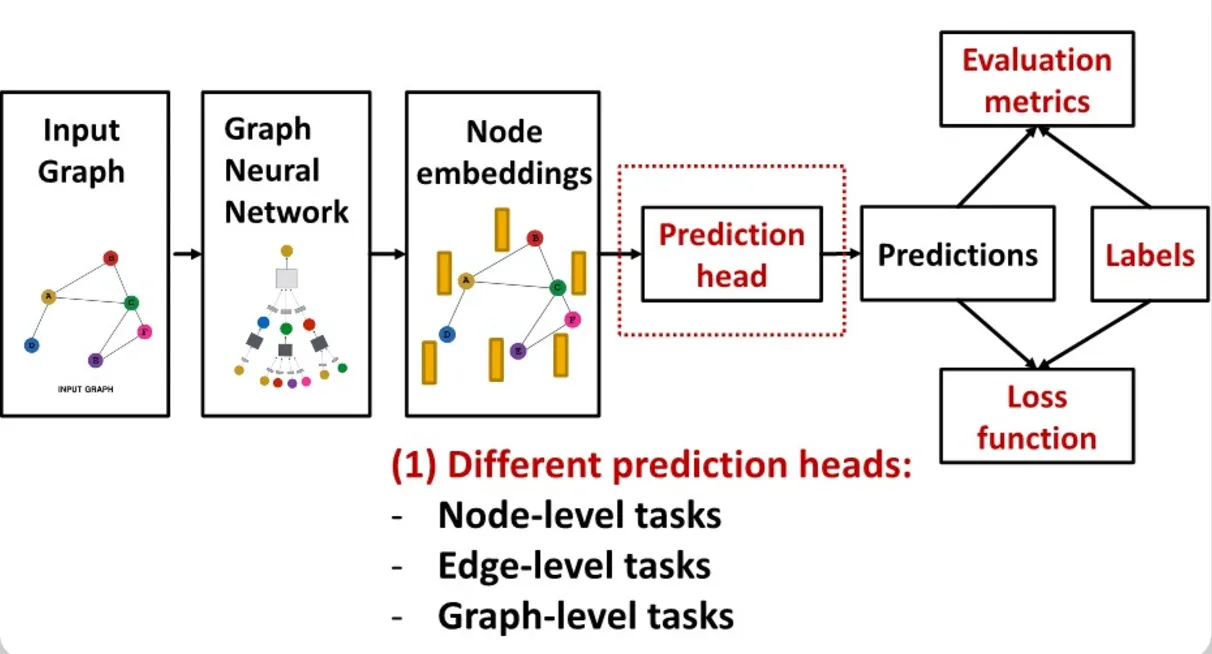
GNN 학습 파이프라인
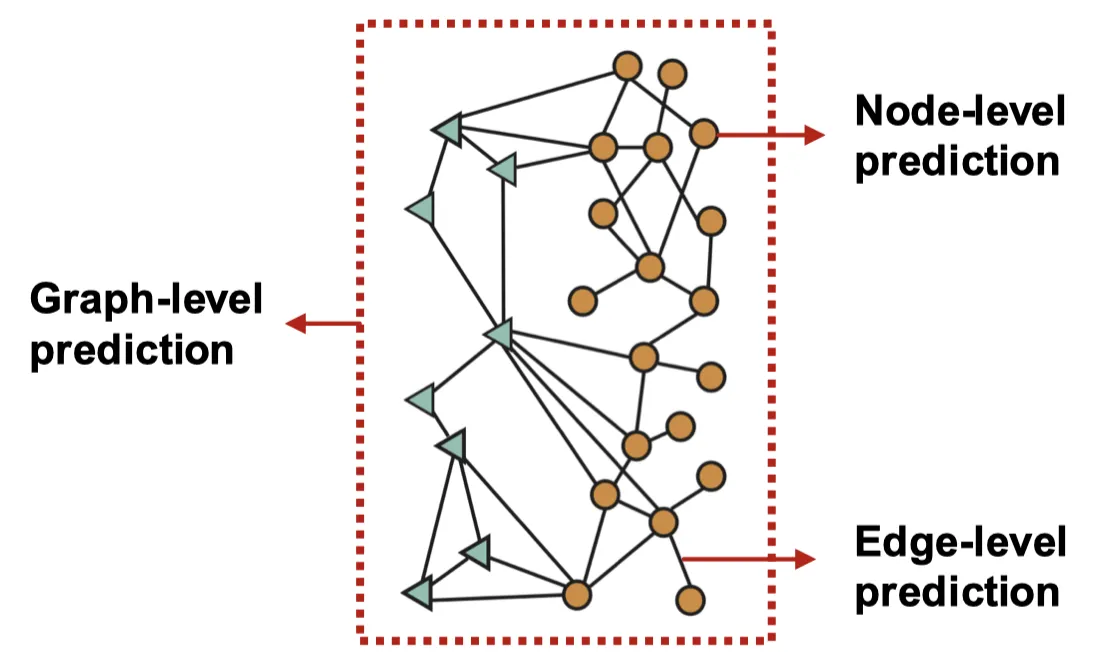
그래프에는 노드 레벨, 엣지 레벨, 그래프 레벨에서 다양한 태스크가 있는데, 각 레벨에 따라 다른 예측 헤드를 갖게 된다.
1. Node level
노드 레벨의 예측은 노드 임베딩을 이용해서 바로 예측을 생성할 수 있다. GNN 계산 이후 d차원의 노드 임베딩을 갖게 된다.
식 설명
- : 노드 표현
- 노드 표현, 그래프 신경망의 L번째 레이어에서 노드 의 특징 벡터
- 각 노드가 GNN을 통해 학습한 최종 임베딩 벡터를 의미
- 학습한 벡터 은 그래프의 구조와 이웃 노드들로부터 얻서
- : 임베딩 공간
- 노드의 표현 벡터는 d차원 실수 벡터 공간에 위치함
- 여기서 d는 GNN에서 설정한 히든 레이어의 차원 or 임베딩 차원, 모델의 출력 크기를 말함.
- 그래프 G 내의 모든 노드 에 대해 이 식이 적용됨.
- 그래프의 각 노드 마다 학습된 벡터 을 갖게 됨.
-way prediction을 한다고 가정하면, 분류 문제에서 k개의 카테고리 중 하나를 예측해야 하고, 회귀 문제라면 k개의 타켓을 예측해야 한다. 해당 태스크를 노드 임베딩을 포함하여 수식으로 나타내면 다음과 같다.
- : d 차원의 노드 임베딩을 k 차원의 target에 매핑
2. Edge level
엣지 레벨의 예측은 두 노드의 임베딩 쌍을 활용해 생성한다. k-way prediction일 때, 예측값은 다음과 같다.
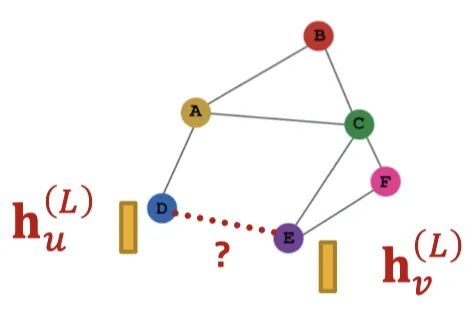
식 설명
- 두 노드 u, v 사이의 엣지에 대한 예측 값
- 두 노드 간의 관계를 예측하기 위한 함수 또는 모델
- Neural Network, Simple MLP 등 사용
- 두 노드의 임베딩 벡터를 입력으로 받아 엣지 값 출력
- 노드 u, v의 최종 임베딩 벡터
- GNN의 L번째 (마지막) 레이어를 통과한 후 각 노드가 학습한 d차원 벡터
- 각 노드의 특징 및 이웃 노드의와의 관계 정보 포함
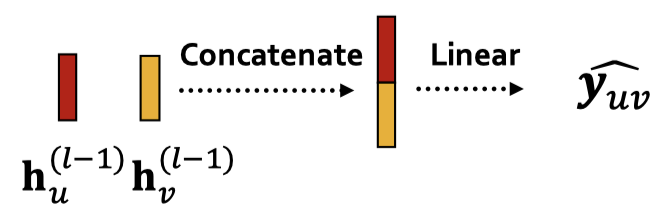
이때, 로 사용할 만한 방법은 첫째, 두 노드 임베딩을 붙인 다음, 선형 레이어를 태우는 방법이다.
여기서 선형 레이어는 두 노드 임베딩을 붙인 2d차원의 임베딩을 k차원 임베딩으로 매핑한다.
두 번째 방법은 내적을 사용한다.
이 방법으로 두 노드 간의 엣지의 존재를 예측하는 등의 1-way prediction만 가능하다. 만약 k-way prediction에 내적을 적용하려면, 멀티 헤드 어텐션과 같은 유사한 방법을 사용해야 한다.
3. Graph level
그래프 레벨의 예측은 그래프 내에 있는 모든 노드의 임베딩을 사용한다. 동일하게 k-way prediction에서 예측값은 다음과 같다.
여기서 은 GNN 레이어에서 집계 함수와 비슷한 역할을 한다. 그래서 3개의 함수를 많이 사용한다.
- Global mean pooling
- Global max pooling
- Global sum pooling
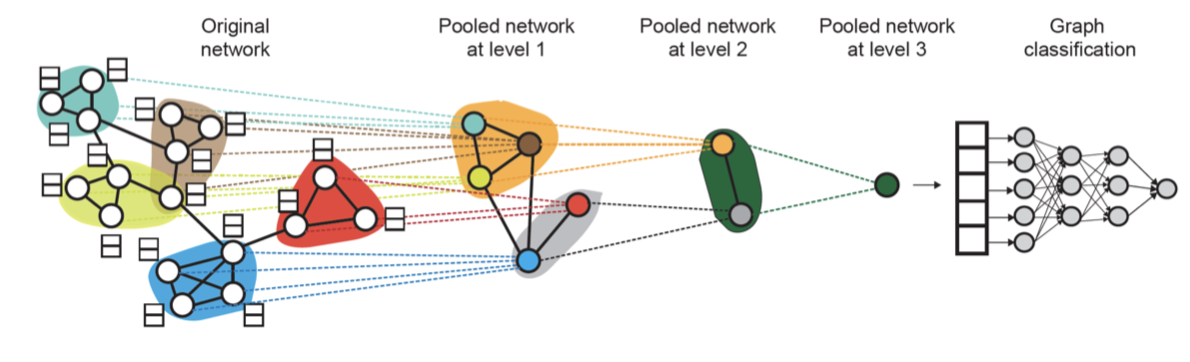
다만, 위의 함수들은 규모가 작은 그래프에서만 잘 작동한다. 큰 그래프에서는 풀링 함수들이 오히려 정보 손실을 야기하기 때문.. 그래서 큰 그래프에 대해서는 계층적 풀링(Hierarchical Pooling)을 사용한다.
위 이미지의 계층적 풀링은 여러 단계에 걸쳐 진행된다. 우선 GNN 레이어 2개를 각각 GNN-A, GNN-B라고 한다. GNN-A는 노드 임베딩을 계산하고, GNN-B는 각 노드들이 속할 군집을 정한다. 이 두 레이어는 병렬적으로 시행가능하다는 특징이 있다.
각 풀링 레이어에서는 GNN-B에 배정한 군집마다 GNN-A에서 계산한 노드 임베딩을 집계한다. 그 다음 각 군집에 대해 하나의 새 노드를 생성하고, 군집 간의 엣지를 유추해 새로 풀링된 네트워크를 생성한다.
Training Graph Neural Network
지도 학습, 비지도 학습
지도 학습에서 라벨은 특정 상황에서 비롯된다. 노드 라벨의 경우 인용 네트워크에서 노드가 속한 주제 영역이 무엇인지로 정할 수 있다. 엣지 라벨의 경우는 트랜잭션 네트워크에서 어떤 엣지가 사기와 관련된 엣지인지 정할 수 있다. 그래프 라벨의 경우 분자 그래프에서 그래프의 약물 유사성이 될 수 있다.
항상 라벨은 작업하기 쉬운 노드/엣지/그래프 라벨로 만들어야 한다.
그렇지만, 대부분의 경우 그래프 구조는 있지만 ,별도의 라벨이 없는 경우가 많다. 그렇기에, Semi-supervised Learning을 고려해야 한다.
노드 라벨의 경우는 군집 계수나 PageRank같은 노드 통계량을, 엣지 라벨의 경우는 두 노드의 엣지를 숨기고 실제 그 엣지의 예측 여부로 사용할 수 있다. 그래프 레벨은 두 그래프가 같은 구조인지 같은 통계량을 사용할 수 있다.
Loss function
- Classification Loss : Cross Entropy
보통은 Cross entropy를 사용한다. k-way prediction에서 i번째 데이터 포인트에 대한 Cross entropy는 다음과 같다.
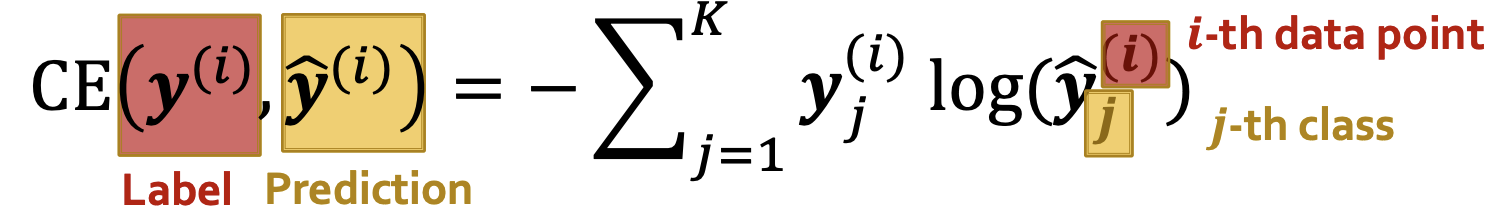
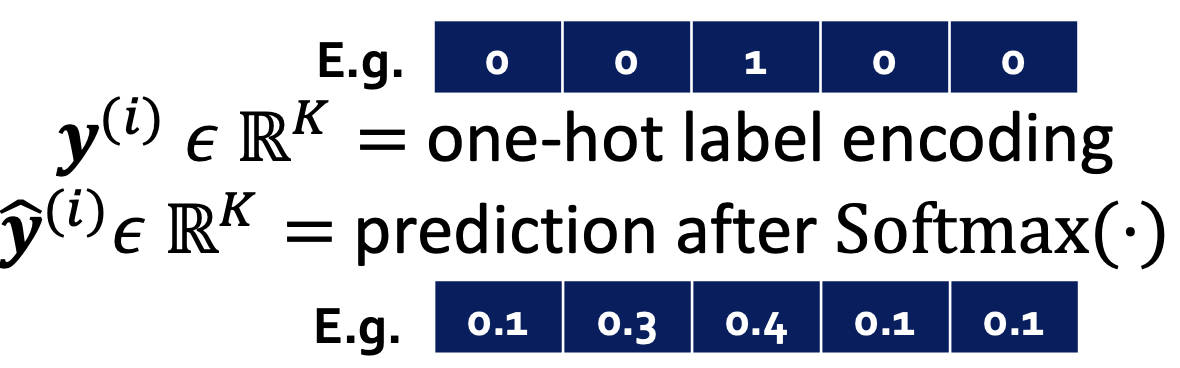
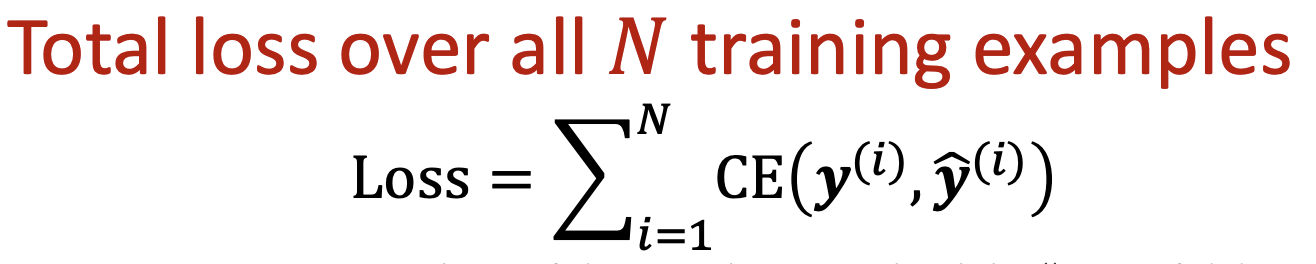
정답이면 1, 정답이 아니면 0을 라벨로 주고, Loss를 최소화하는 것이 목표이다.
- Regression Loss : MSE

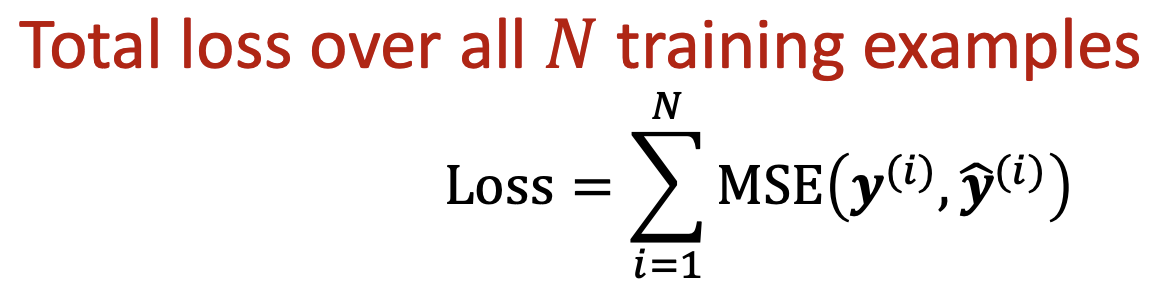
예측 값과 Ground Truth 간의 벡터 사이 거리를 최소화하는 방향으로 학습을 진행한다.
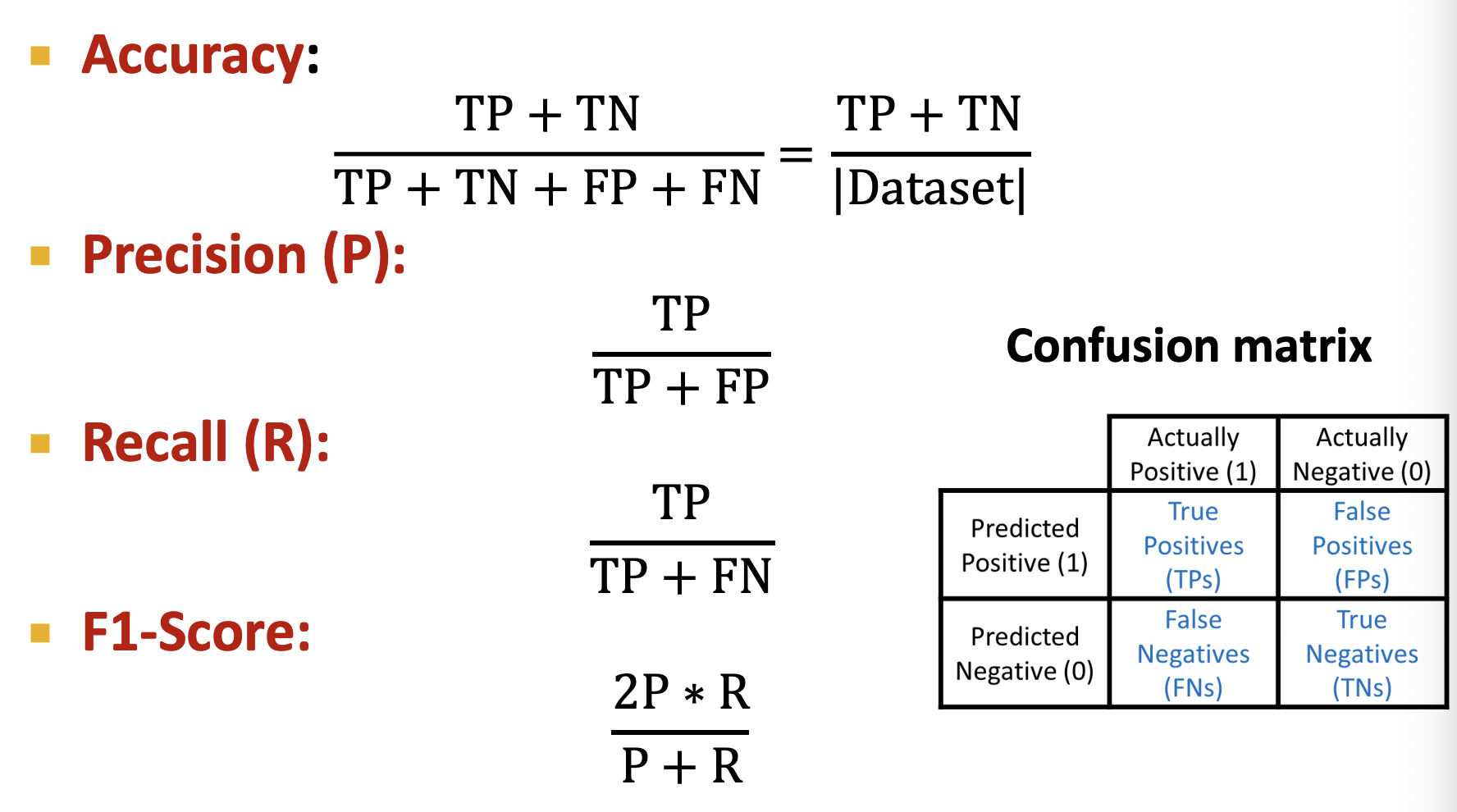
Evaluation Metric
-
Classification
-
Multi-Class Classification : Accuracy(Acc)
-
Binary Classification : Acc, Precision / Recall, ROC-AUC
💡ROC AUC
- 위 plot의 curve 아래에 있는 면적, 클 수록 좋음.
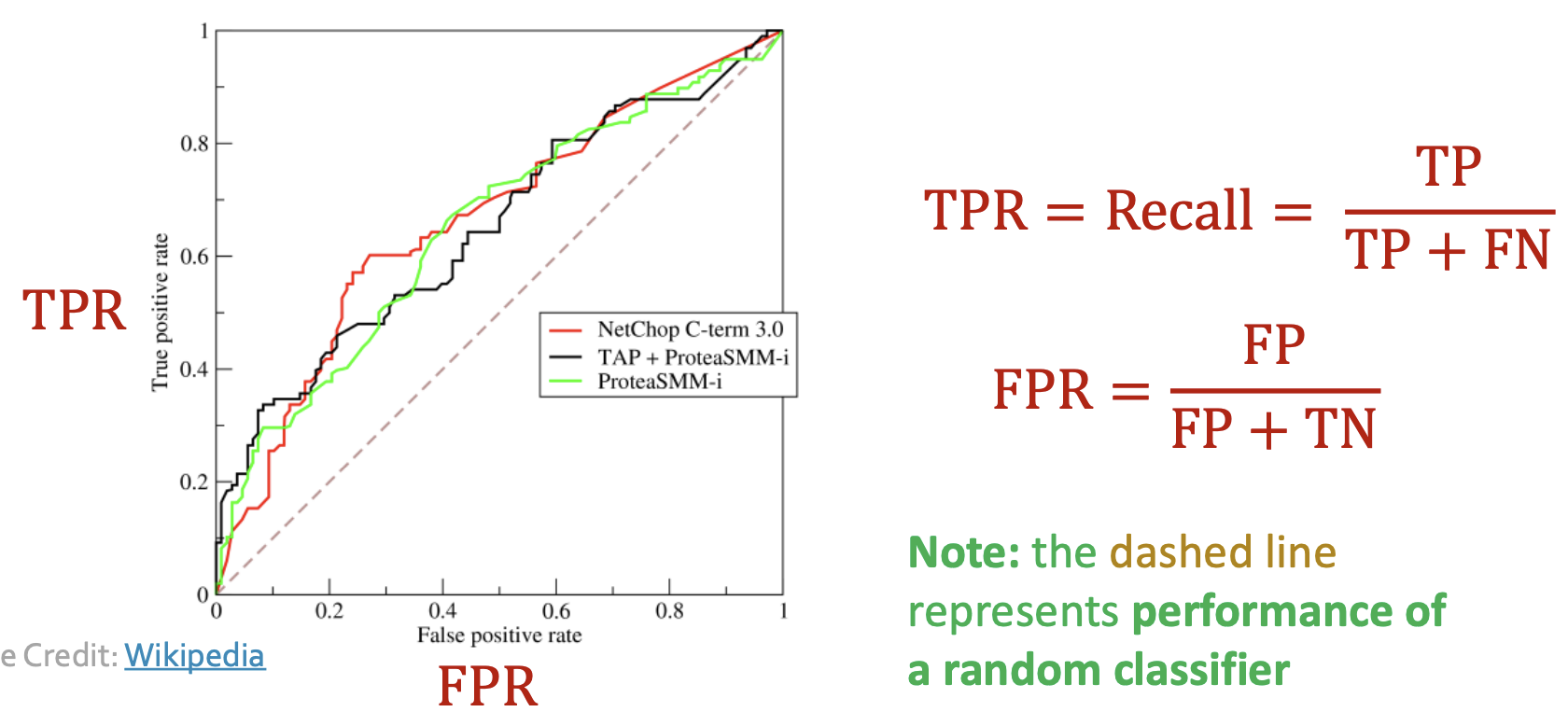
- 위 plot의 curve 아래에 있는 면적, 클 수록 좋음.
-
- Regression
- RMSE, MAE를 사용한다.

GNN Prediction Task 설정
Fixed split의 경우, 데이터셋을 한번만 나눈다.
- Train Data : GNN 파라미터 최적화 용도
- Valid Data : 모델과 하이퍼파라미터 튜닝
- Test Data : 최종 성능 확인할 때까지 보류
테스트 데이터는 실제로 있을지 보장하기 힘들기에, Random split을 통해 Train, Valid, Test 데이터를 모두 나눈다. 그리고 여러 랜덤 시드 값에 대해 평균 성능을 계산한다.
일반적인 데이터는 데이터 셋은 서로에게 영향을 주지 않지만, 그래프 데이터셋의 경우 한 노드가 다른 노드에게 영향을 줄 수 있다. 각 노드가 메시지 전달에 참여하기 때문이다.
그렇기에, 어떤 노드가 없다면, 다른 노드의 임베딩은 변화한다.
그래프 데이터를 나눌 때에는 2가지 방법이 있다.
- 전이적 설정(transductive setting)
- 귀납적 설정(inductive setting)
전이적 설정 (transductive)
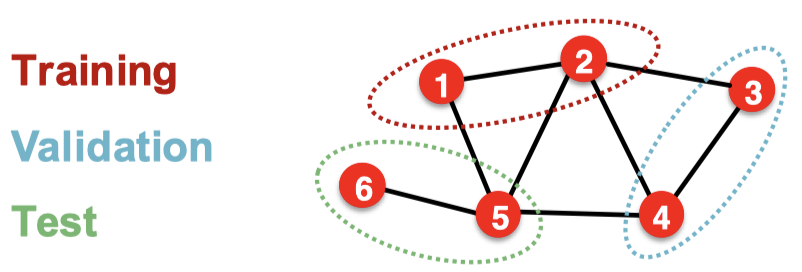
- Train/Valid/Test set이 모두 같은 그래프에 존재하고, Dataset이 하나의 그래프만 가진다.
- 이 하나의 그래프를 3개로 나눠서 분할을 진행한다.
- Node, Edge level task에만 사용이 가능하다.
귀납적 설정 (inductive)
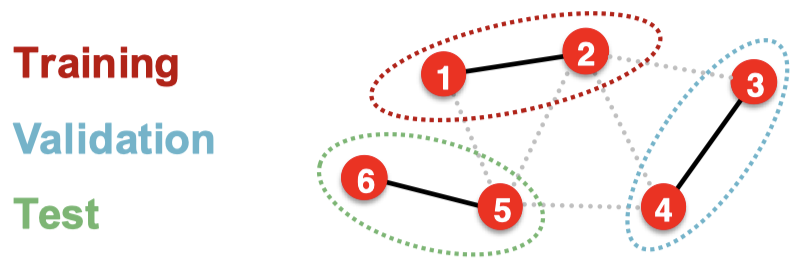
- 데이터셋을 여러 독립적인 그래프로 분할한다. (전체 데이터셋이 여러 그래프를 가진다.)
- Train/Valid/Test set이 모두 다른 그래프를 가진다.
- 학습 시에도 노드 1, 노드 2에 대한 임베딩만 계산하고, 노드 1, 노드 2에 대한 라벨만 사용한다.
- Node, Edge, Graph level Tasks에 모두 이용가능하다.
Task Example
Node Classification
- Transductive (전이적)
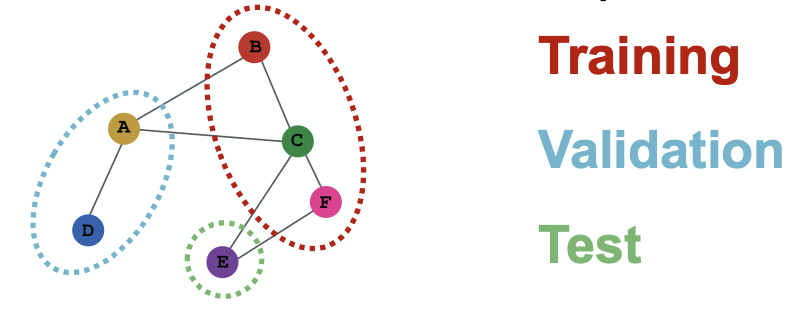
- 전체 그래프 구조를 모든 데이터 분할에서 관찰할 수 있다.
- 각 데이터 분할에서는 자신의 노드 라벨만 사용
- Inductive (귀납적)
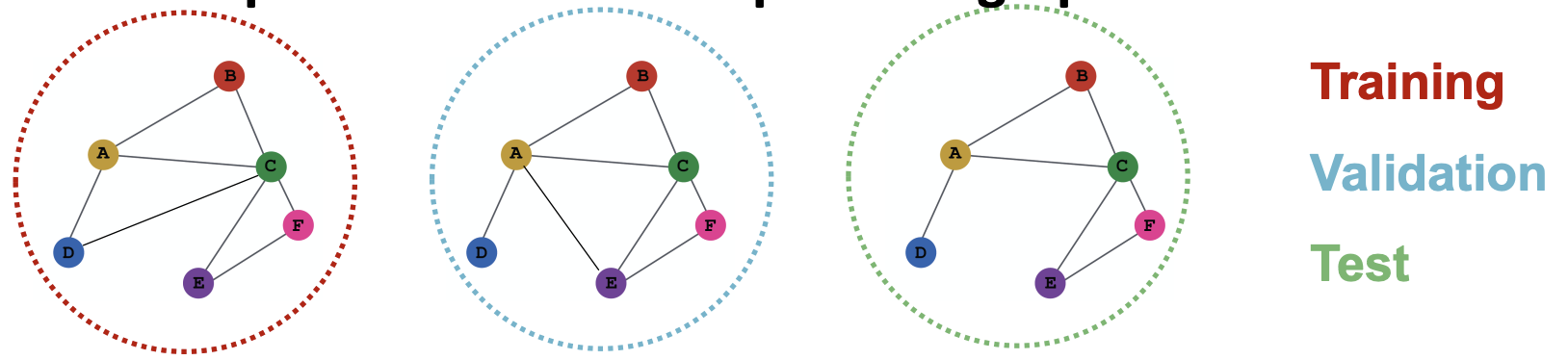
- 3개의 데이터 셋이 있다고 가정하고
- 각각 독립적인 그래프로 분할한다.
Graph Classification
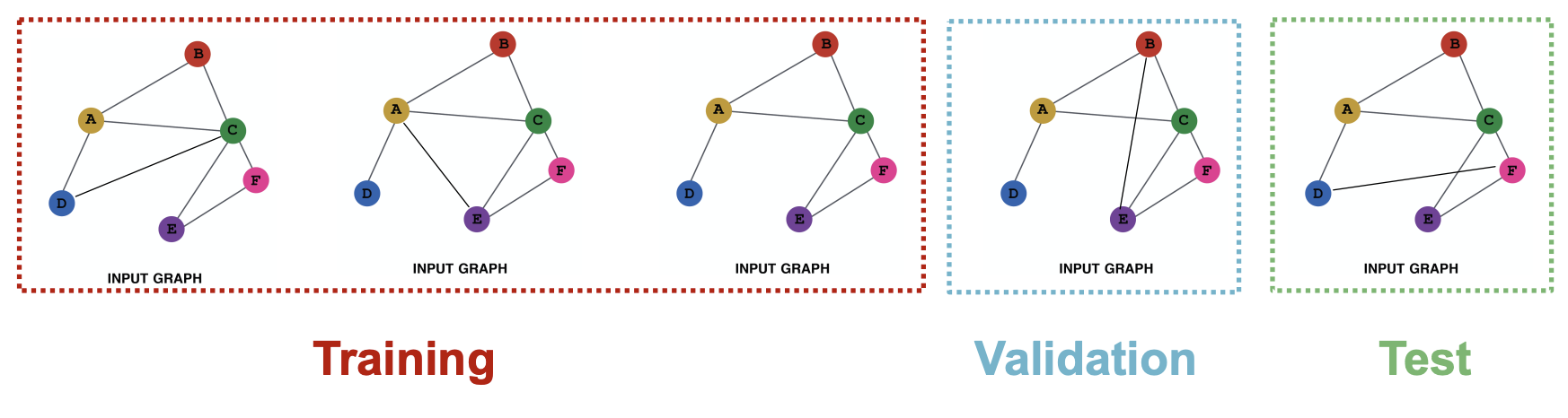
- Inductive setting에서만 가능하다. (학습하지 않은 그래프에 대해 테스트해야 하기 때문에)
Link Prediction
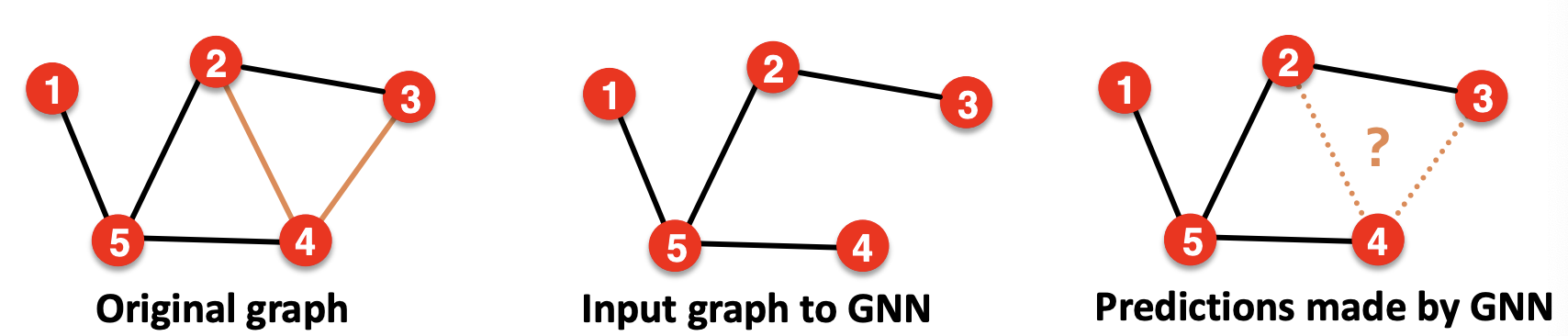
- 사라진 Edge를 예측하는 것이 목표
Link Prediction을 설정하는 것은 까다로운데, 우선 이는 Unsupervised / self-supervised task이다. 그렇기에, 라벨을 만들고, 데이터셋을 분할하는 것이 필요하다. 그렇기에, 일부 에지를 숨기고 에지가 존재하는지 GNN이 예측하도록 해야한다.
과정 1 : Link Prediction Setting
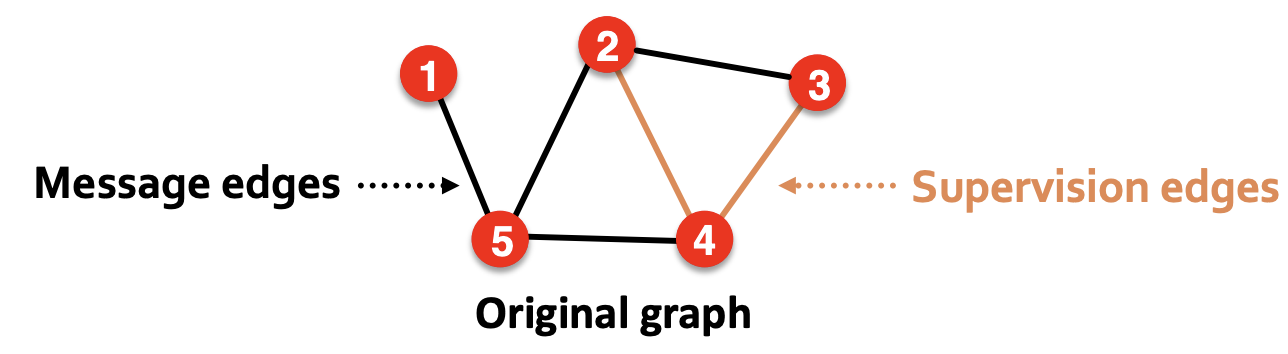
이 과정에서는 엣지를 두번 분할한다.
- 기존 그래프의 엣지를 2가지 유형으로 분할한다.
- Message Edges
- GNN의 Message 전달에 사용된다.
- Supervision Edges
- 목표를 계산하는 것에 사용
- Message Edges
- 1번 과정 이후, 그래프에는 메시지 엣지만 남게 된다.
→ Supervision Edges는 모델이 예측한 엣지에 대한 정답으로 사용되며, GNN에 입력되지 않는다.
과정 2 : Split edges into train/valid/test sets
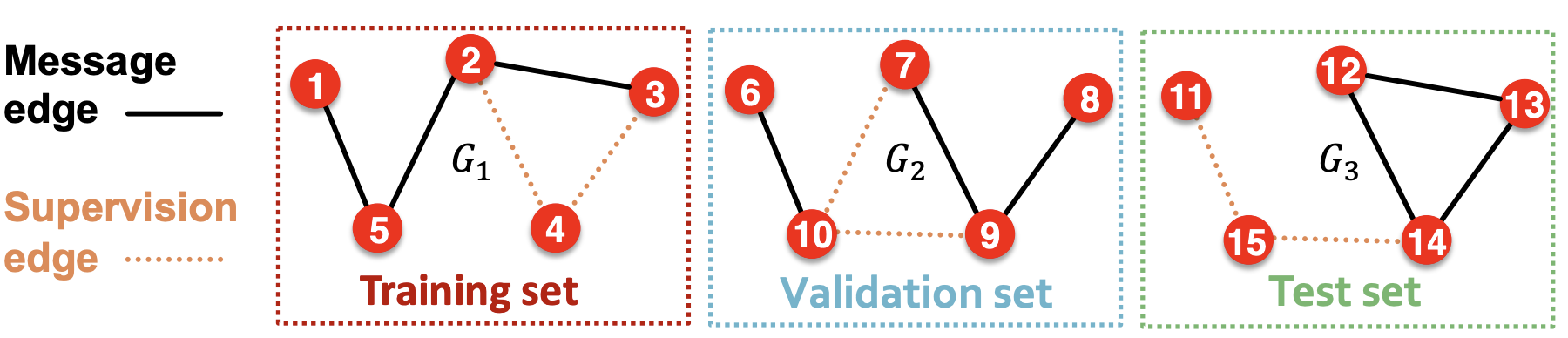
-
Option 1 : 귀납적 Link prediction split
- 3개의 그래프 데이터셋을 가지고 있다고 가정하면, 각 귀납적 분할은 독립적인 그래프로 구성된다.
- train/val/test 데이터셋은 모두 학습에 사용되는 Message, 예측에 사용되는Supervision edge를 포함한다.
-
Option 2 : 전이적 link prediction split
- 하나의 큰 그래프에서 train/valid/test를 나눈다. (train set에 대한 supervision edge를 유지해야 한다.)
- 보통의 link prediction에서 많이 사용되는 방법으로, 하나의 큰 그래프에서 data를 나누는 방법
- Training시에는 message, supervision edge를 통해 학습, 예측을 수행한다. validation에서는 training set에서 message edge, supervision에 edge를 validation step의 입력으로 사용해 validation edge를 예측하는데 쓴다. Test할 때는, training할 때와 validation할 때 모두 사용된 edge를 입력으로 test edg를 맞춘다.

참조
https://otzslayer.github.io/cs224w/2023/06/18/cs224w-06.html
https://meaningful96.github.io/graph/Graph2/#d-gnn-prediction-task
