Abstract
- 기존 NLP 연구에서 특정 작업에 대해 fine-tuning하는 방법으로 성과를 달성했으나, task에 따라 매번 데이터를 모으고 fine-tuning하는 한계가 존재합니다.
- 이러한 성격의 유형을 Task-agnostic model이라고 합니다.
- 즉, 좋은 성능을 내기 위해서는 매번 Fine-tuning이 필수입니다.
- 그렇지만, Few-show learning으로 이를 돌파했습니다.
- GPT-3는 대규모 학습 데이터를 필요로 하는 Fine-tuning에서 벗어나, 간단한 지침으로 다양한 작업을 수행할 수 있는 가능성을 보여줍니다.
- 또한, 175B(175억개)파라미터로 다수의 작업에서 우수한 성능을 보여줬습니다.
- 이전보다 뛰어난 성능을 보였지만, 아직은 한계가 있습니다. 단, GPT-3가 생성한 텍스트가 인간이 작성한 텍스트와 이제는 구별되지 않을 정도로 자연스러워졌기에, 사회적, 윤리적 이슈 역시 존재합니다.
💡 Few-Shot learning
- 몇 개의 예제를 제공하고, 이를 통해서 간단한 지시만으로 태스크에 적용하여 문제를 해결하는 것을 말합니다.
1. Introduction
- GPT-3 이전의 NLP 연구는 Pre-trained RNN or Transformer 모델을 사용하는 등, 작업에 구애받지 않는 구조로 발전되었습니다.
- 그렇지만, 새로운 작업마다 작업별 데이터와 Fine-tuning이 필요하다는 한계가 존재했습니다.
- 이 점을 극복하기 위해서는 다음 3가지 관점이 있습니다.
-
새로운 작업마다, 대규모 라벨링된 데이터가 필요하지 않다면, 언어 모델의 적용 가능성을 넓힐 것입니다.
-
Fine-tuning 과정에서 훈련 분포에 과도하게 특화될 위험성을 낮추고 일반화 성능을 높이는 것이 핵심입니다.
- 모델은 사전 학습 과정에서 대량의 지식을, 소수의 task에 대해 Fine-tuning을 진행합니다. 그렇기에, Out-of-Distribution 문제를 일반화하지 못하는 경우도 있습니다.
-
사람은 대부분의 언어 task를 하기 위해 예제가 많이 필요하지 않습니다.
즉, 간단한 지시 사항만으로 해결할 수 있다는 것이죠.
이러한 문제를 해결하기 위한 방법은 “Meta-Learning”입니다.
💡 Meta Learning
- 언어모델의 문맥에서 모델이 학습하는 동안 여러 기술과 패턴 인식 능력을 키우고, 추론 시간에는 이를 원하는 task에 빠르게 적용시키거나 인식시키는 방법입니다
- Train 과정에서 다양한 기술이나 패턴을 인식하는 방법을 배우고, Inference에서 Downstream task에 대해 빠르게 적응하도록 하는 것이죠.
- 간단하게 말하면, 학습하는 방법을 배우는 것입니다.
- Unsupervised Pre-training에서는 언어 모델이 여러 기술들과 패턴인식 능력을 키워 추론에 이용합니다.
- GPT-2에서는 각 Sequence에 대해 forward-pass 안에서 일어나는 내부 과정인 In-context Learning(문맥 내 학습) 방식으로 진행했습니다.
→ 그렇지만, 이 방법들은 몇몇 task에서 Fine-tuning에 비해 아쉬운 성능을 보였습니다.
- 또다른 NLP 연구의 트렌드는 모델의 크기를 키우는 것인데, Transformer를 이용해서 모델 사이즈를 크게 늘릴 수 있고, 파라미터 수까지 늘어나 Downstream task에서 강력한 성능을 보였습니다.
💡 Transformer의 경우 Self-Attention을 사용해 모든 위치 간의 관계를 동시에 학습할 수 있습니다. 그렇기에, 장기 의존성 문제를 극복하고, 더 효과적인 표현을 학습할 수 있습니다.
또한, Residual Connection을 사용하기에, Gradient Vanish, Explode를 완화하고 복잡한 패턴을 학습가능합니다.
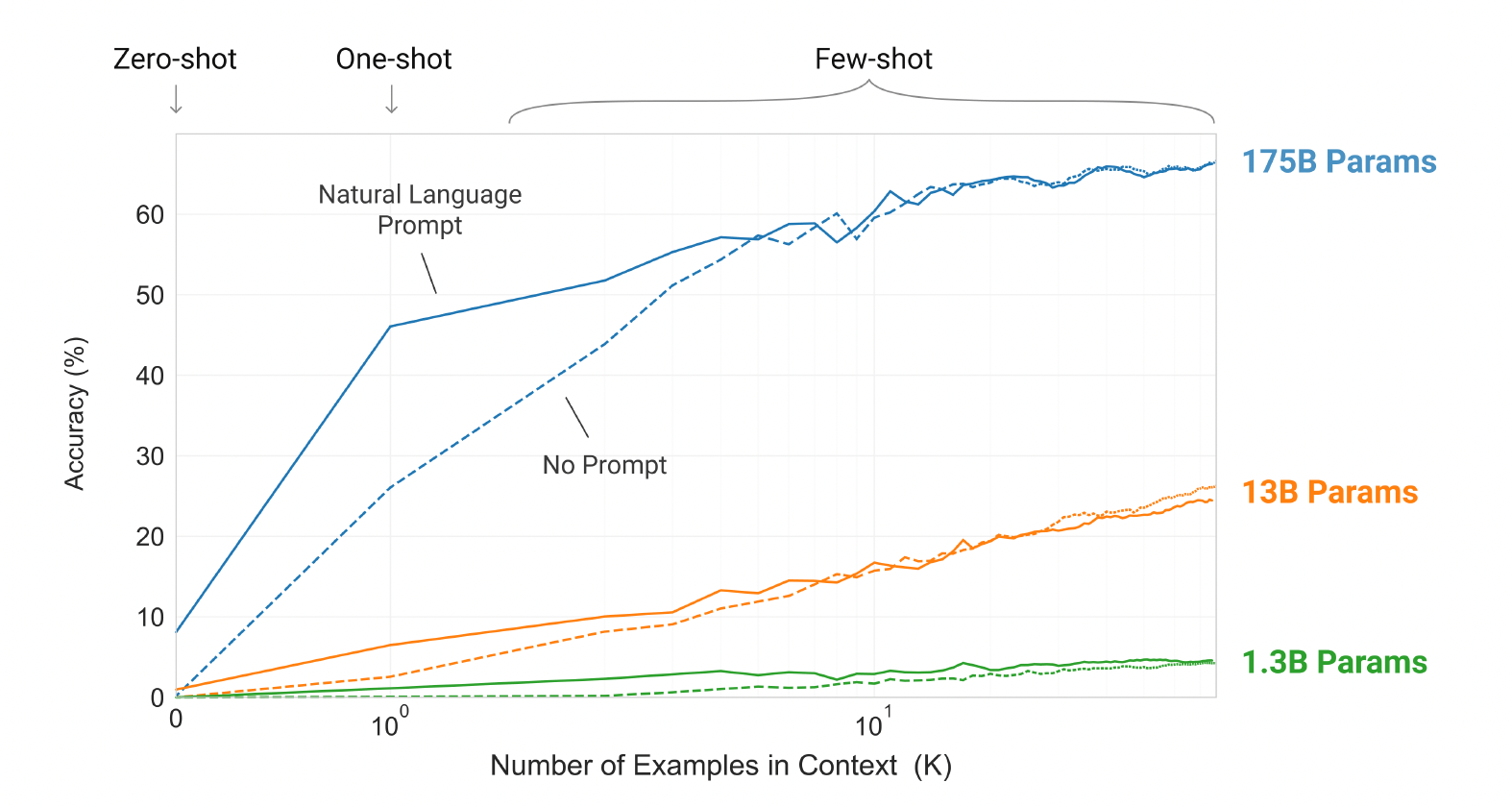
- 그리고 이제는, Few-shot 세팅에서 잘 작동하는지를 위해, Few-shot vs One-show vs Zero-shot으로 모델의 성능을 측정합니다.
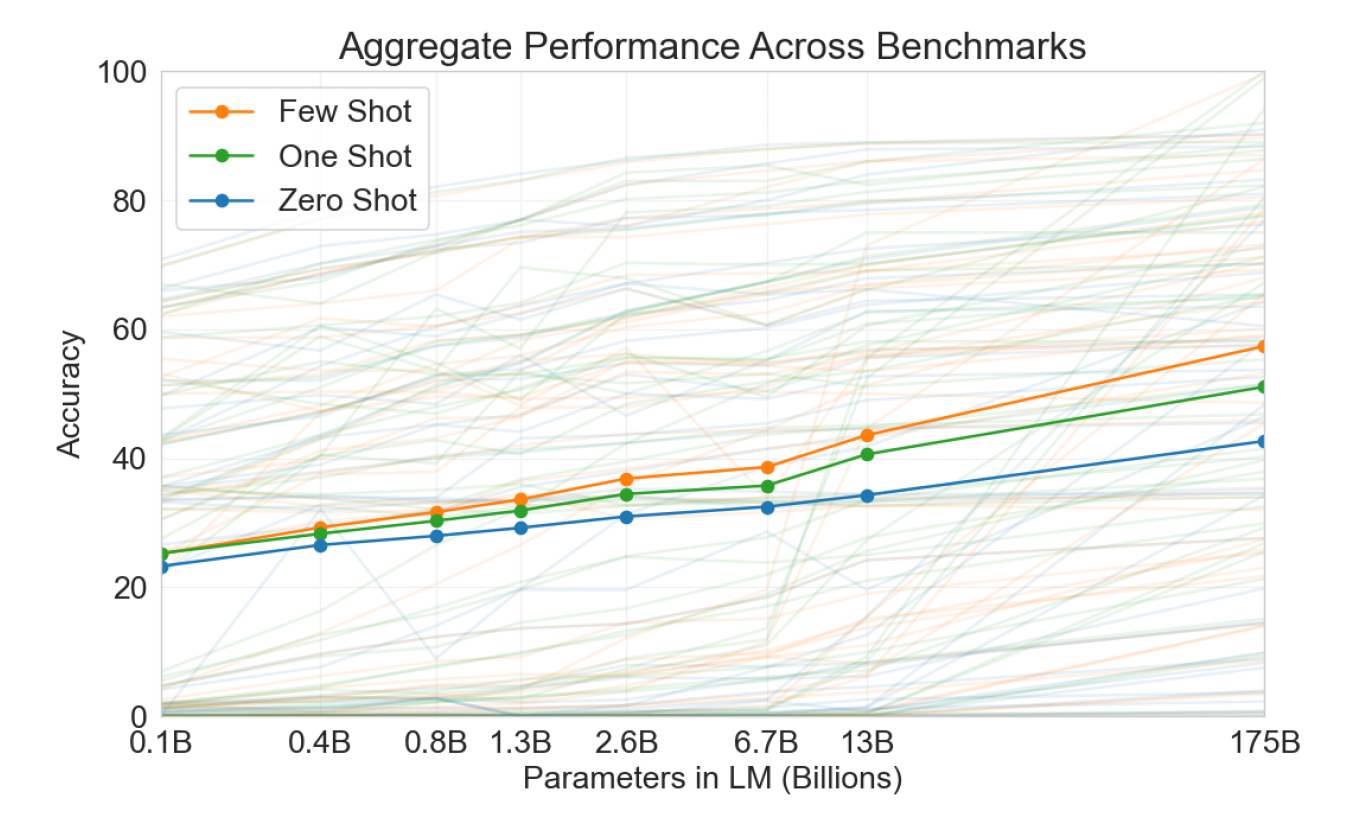
- 그 결과는 다음과 같습니다.
- Task에 대한 자연어 지시를 추가하면 모델 성능이 향상됩니다. (Natural Language Prompt > No Prompt)
- 모델에 제공되는 예제가 많을수록 성능이 증가합니다. (K에 비례하여 정확도 증가)
- 큰 모델일수록 in-context를 더 잘 활용했습니다.
→ 그 과정에서 Gradient Update, Fine-tuning은 진행하지 않았습니다.
K의 증가에 따라 정확도가 증가하는 것은, 오로지 문맥에 포함된 예재의 개수를 모델이 얼마나 잘 활용하는지에 기인합니다.
- 다만, 논의해야 할 사항이 있습니다.
- 일부 자연어 추론 작업과 독해에서 아직은 어려움이 있습니다.
- 대규모 웹 데이터를 사용할 때, Test 데이터 셋이 Train 데이터셋에 포함될 가능성이 있습니다. (Data Contamination)
2. Approach
- GPT-3의 평가 조건은 4가지로 구분합니다

- Fine-tune : Downstream task에 특화된 Supervised 학습 데이터셋으로, Pre-trained model의 가중치를 업데이트합니다. 다만, 매 테스트에서 대규모 데이터셋이 필요하고, 현재 논문에서는 시행하지 않습니다.
- Few-Shot(FS) : 모델의 추론 과정에서 예시는 제공하지만, 가중치 업데이트는 제공하지 않습니다. 보통 task에 대한 설명과 함께 task에 관한 K개(:context window, 10~100개)의 예시를 이용합니다. Fine-tuning의 학습 필요성은 줄어들지만, 성능은 아직 SOTA Fine-tune을 따라가지 못합니다.
- One-Shot(OS) : FS와 세팅이 같으나, 예시를 하나만 제공합니다. One-shot이 인간의 커뮤니케이션과 비슷하기 때문입니다.
- Zero-Shot(ZS) : task에 대한 예제 없이, 지시어만 공개합니다.
2.1 Model and Architectures
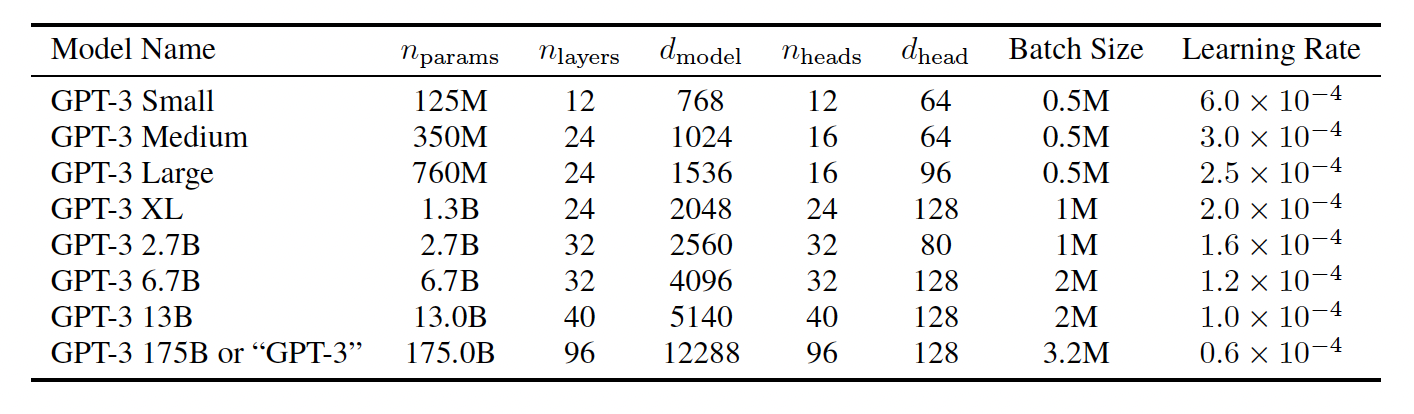
- 기본적으로 GPT-2와 같지만, Transformer 층의 Attention 패턴에 대해 dense와 locally banded sparse attention을 번갈아 사용했습니다.
- 더 큰 모델에서는 더 큰 Batch size, 더 작은 Learning rate를 사용합니다. 또한, 큰 모델 학습에서는 메모리가 부족할 수 있어, 행렬곱에 있어 모델 병렬화와 레이어 사이의 모델 병렬화를 섞어서 사용합니다.
: 학습가능한 파라미터 전체 개수
: 레이어 수
: 각 bottleneck layer 안에 있는 unit의 수 (해당 논문에서는 항상 )
: 각 Attention head의 차원
모든 모델은 = 2048의 차원을 가집니다.
2.2 Training Dataset
- 가장 주로 학습하는 데 사용되는 데이터는 Common Crawl 데이터셋이지만, 여러 정제 과정을 필요로 합니다.
- high-quality로 분류되는 데이터만 필터링한 결과, 45TB → 570GB로 필터링했습니다.
- 다만 걱정되는 점은, Data Contamination입니다.
- 본 논문에서는 모든 벤치마크의 test/dev set과 겹치는 부분을 제거하려 노력했습니다.
- 최종적으로는 해당 데이터를 그대로 사용한 것이 아닌, Crawling 데이터셋의 단점을 보완하기 위해 고품질의 데이터를 섞어서 데이터셋을 구축했습니다. 그 과정에서 가중치를 두어, 깔끔한 데이터셋이 상대적으로 높은 빈도로 학습되도록 합니다.
정리하면 다음과 같스니다.
- 데이터 샘플링 방식:
- 데이터셋 크기에 비례하지 않습니다.
- 품질이 높다고 판단되는 데이터셋 더 자주 샘플링합니다. 이 과정에서 발생하는 약간의 과적합은 넘어갑니다.
- 데이터 오염 문제:
- 중복 데이터를 제거하기 위해 노력했지만, 아직은 완벽하지 않습니다.
- 향후 연구에서 더 적극적인 데이터 오염 제거 계획이 있습니다.
3. Results
- GPT-3에서 Zero-shot, One-shot, Few-shot 설정으로 성능을 평가했고, Few-Shot에서는 일부 작업에서는 Fine-tuned 모델 이상의 성능을 보여줬습니다.
3.1 Language Modeling, Cloze, and Completion Tasks
- Zero-Shot 설정으로도 기존 모델보다 낮은 Perplexity를 기록하여 SOTA를 달성했습니다.
3.1.1 Language Modeling
- PTB에서 20.50 perplexity로 15포인트 차이로 새로운 SOTA를 달성했습니다.
- 몇 가지 예제 학습을 평가할 명확한 분리가 없어, 제로샷으로만 측정했습니다.
3.1.2 LAMBADA
- 언어의 장기 의존성을 모델링하는 task입니다.
- 문단을 읽고, 문장의 마지막 단어를 예측하고, Zero-Shot으로 76% 정확도를 달성했습니다.
3.1.3 HellaSwag
- 짧은 글이나 지시사항을 끝내기 알맞은 문장을 고르는 태스크입니다.
- GPT-3에서 One-shot, Few-shot으로 80%가까운 정확도를 보였지만, Fine-tuning 모델에 비해서는 낮게 도출되었습니다.
3.1.4 StoryCloze
- 다섯 문장의 긴 글을 끝맺기에 적절한 문장을 고르는 태스크입니다.
- GPT-3는 zero-shot 설정에서 83.2%, few-shot 예제 학습 설정에서 87.7%(K = 70) 정확도를 달성했습니다.
- BERT 기반 모델로 Fine-tuned model보다 낮지만, 이전보다 10%이상 향상했습니다.
3.2 Question Answering
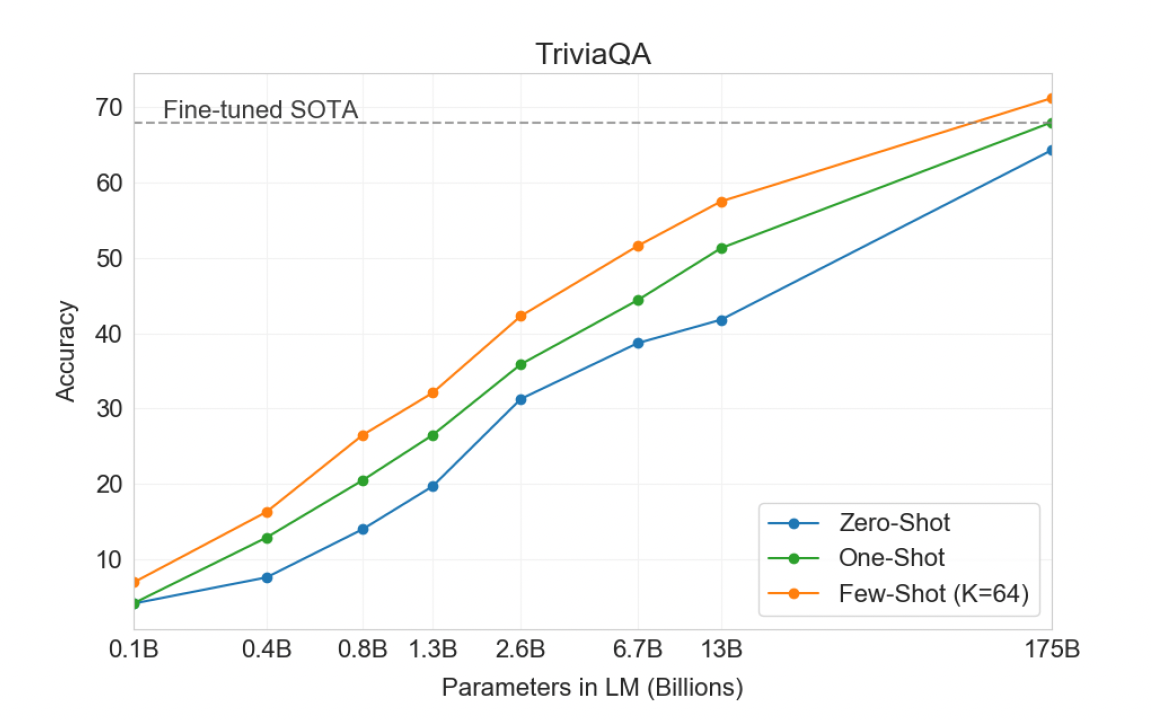
- TriviaQA : Few-shot& Zero-shot 성능으로 T5-11B 모델의 fine-tuning 기반의 접근법 성능을 뛰어넘었습니다.
- WebQuestions : Zero-shot에 비해 Few-shot으로 갔을 때 성능 향상이 큽니다.
3.3 Translation
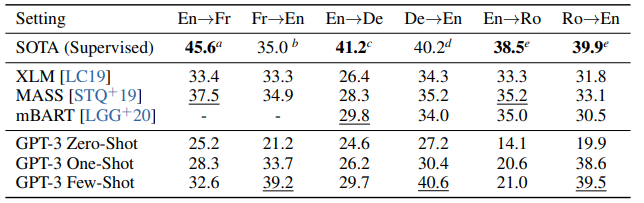
- GPT-3은 큰 모델로 인해 여러 언어에서 좋은 성능의 결과를 얻었습니다.
- few-shot은 BLEU score가 기존 SOTA보다 좋은 성능을 얻기도 했습니다.
3.4 Winograd-Style Tasks (대명사 지칭 문제)
- 문법적으로는 답이 모호하지만 사람에게는 의미적으로 명확한 문제
- 최근 Fine-tuned 모델에서는 사람에 근접한 성능을 부였지만, 더 어려운 데이터셋에서는 뒤떨어지는 결과를 얻었습니다.
- GPT-3에서는 Few-shot 기준, SOTA와 거의 조금 차이밖에 존재하지 않습니다.
3.5 Common Sense Reasoning
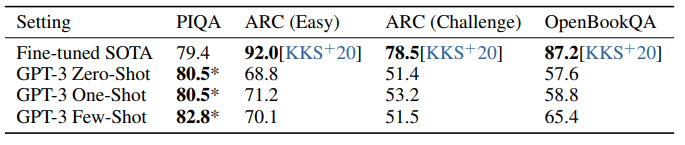
- PIQA : 물리학에 관한 문제로, few/zero shot 세팅에서 이미 SOTA를 넘겼지만 데이터오염 문제가 있을 수 있다 언급되었습니다.
- ARC : 모두 SOTA에는 미치지 못하는 성적을 보였습니다.
- OpenBookQA : Few-shot이 ZS, OS에 비해 좋은 성적이지만, SOTA에는 많이 모자릅니다.
3.6 Reading Comprehension
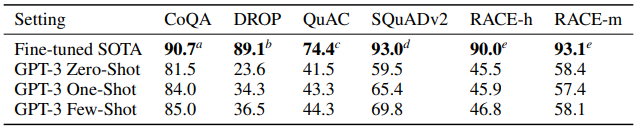
- 대부분의 결과가 SOTA에 미치지 못했습니다.
3.8 NLI
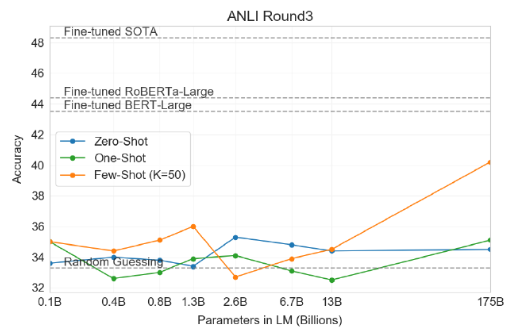
- 두 문장 간의 관계를 이해하는 것을 측정합니다.
- 두 번째 문장이 첫 번째 문장과 같은 논리를 따르는지, 모순되는지, 중립적인지 판별합니다.
- Few-Shot조차 Fine-tuning 모델에 미치지 못합니다.
3.9 Synthetic and Qualitative Tasks
- Arithmetic (산술능력)
- 자리 수가 많아질수록, 성능이 떨어진 것을 확인했습니다.
- 아직 산술 연산에 많이 약합니다.
- Word Scrambling and Manipulation Tasks : 단어 재조합
- 적은 수의 예로 새로운 symbolic manipulation을 학습하는 능력을 측정하기 위한 방법입니다.
- 모델 크기가 커질 수록 성능도 조금씩 개선되었습니다. 하지만 단어를 뒤집는 RW task는 성공하지 못 했습니다.
4. Measuring and Preventing Memorization Of Benchmarks
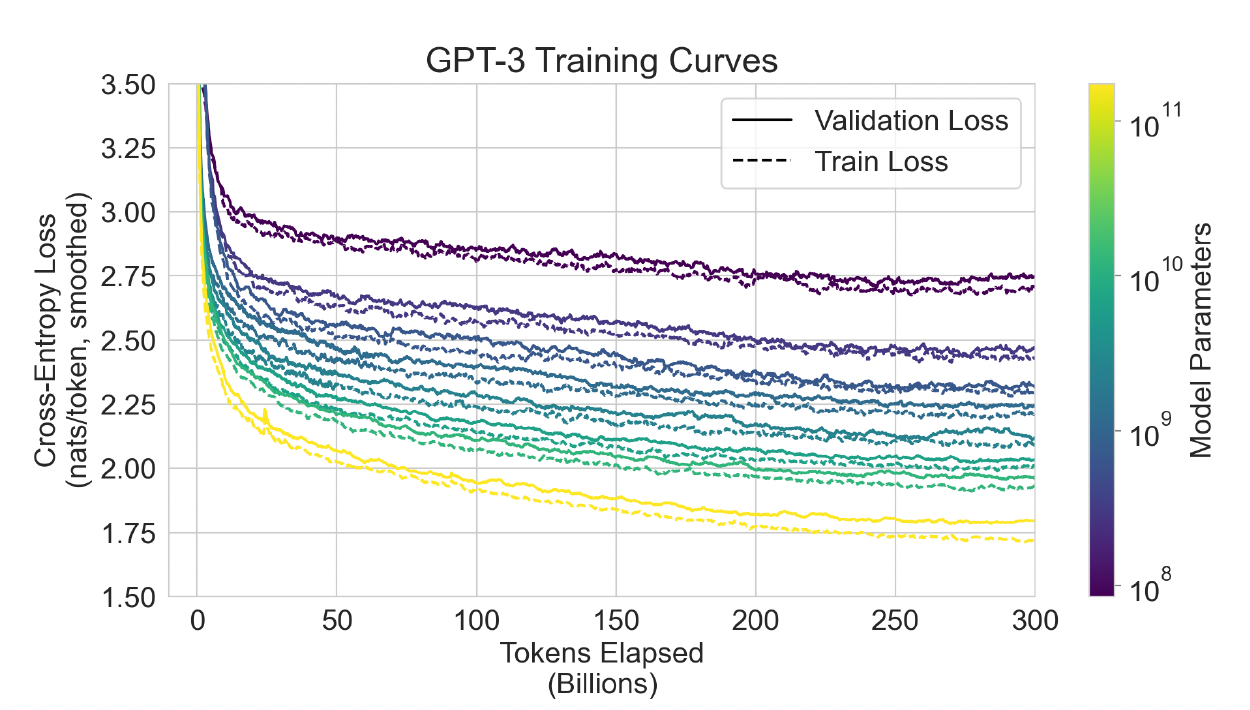
- 데이터셋의 오염에 관련된 부분입니다.
- 훈련 데이터셋은 인터넷에서 수집되었기 때문에, 모델이 테스트 데이터셋 중 일부를 훈련 데이터로 사용했을 가능성이 있습니다.
- 위 그래프를 확인해보면, 오염이 있을 가능성은 있지만, 그 영향은 크지 않다고 예상됩니다.
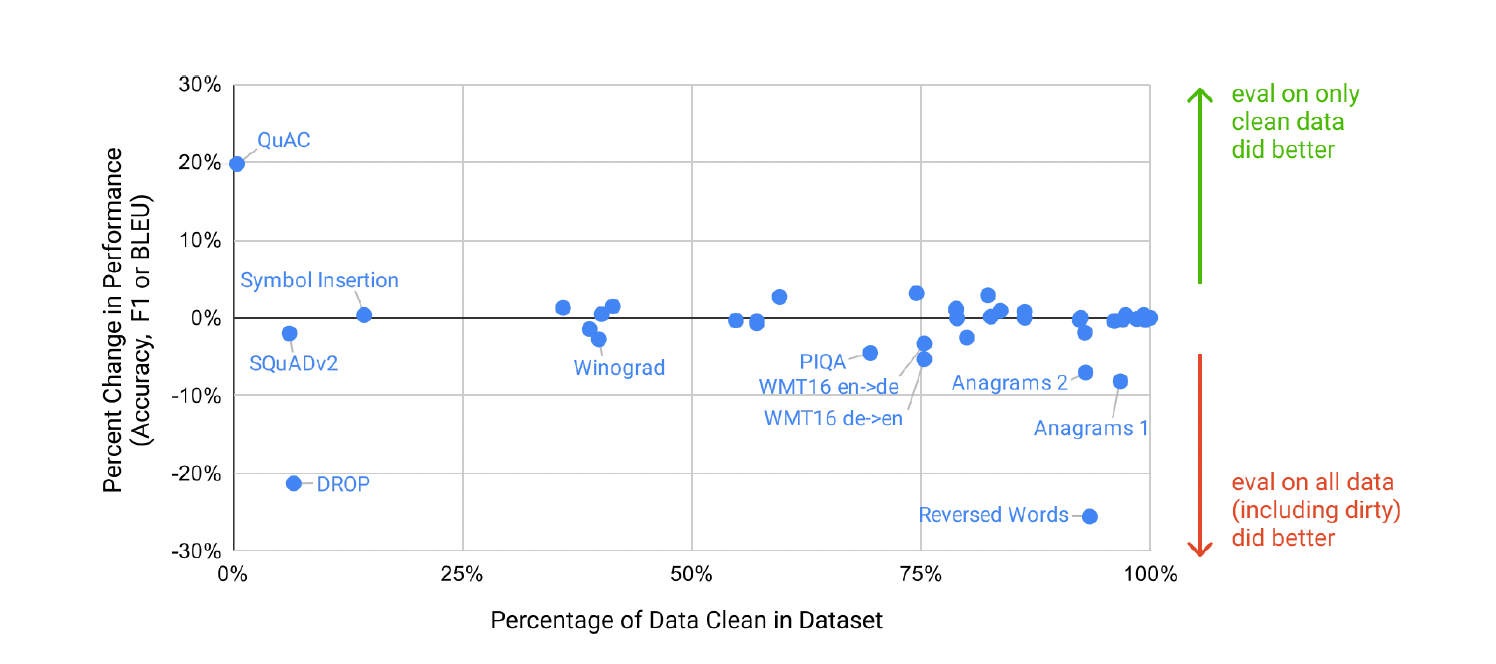
- 또한, 각각 벤치마크에 대해 사전 학습 데이터와 중복이 있는 예제 데이터를 삭제하는 Clean 버전의 테스트 셋을 생성해 benchmark로 평가를 진행했습니다.
- Clean 데이터와 비교해본 결과, 성능 차이는 크게 존재하지 않습니다.
→ 즉, 사전학습으로 테스트 데이터셋을 암기한 것은 아닙니다.
5. Limitations
- 성능적 한계
- 다른 모델에 비해 NLP 태스크들에 대해 성능 향상이 있었으나, 여전히 잘 못 푸는 태스크들이 존재합니다.
- 생성에 있어서 문단 레벨에서 동어 반복 현상이 여전하고, 긴 글에서 가독성이 떨어집니다.
- 또한, 관련이 없는 내용을 만들어내기도 합니다.
- 모델의 구조/알고리즘적 한계
- 양방향적인 구조나 Denoising 훈련 목적 함수는 고려하지 않았기 때문에 빈칸 채우기/두문단 비교하기 등 부분에서 성능이 낮게 나왔을 수 있습니다.
- 본질적 한계
- 현재의 목적함수는 모든 토큰에 대해 동일한 가중치를 적용하고 있고, 어떤 토큰을 예측하는 것이 더 중요한지를 반영하지 않습니다.
- 그렇기에, 단순히 규모만 키우는 것에 대해서는 한계에 부딪히고, 다른 접근법이 필요할 것입니다.
- 훈련 과정의 효율성
- 사전 학습을 위해, 엄청난 양의 데이터를 봐야 할 것입니다.
- Few-show setting의 불확실성
- 이 Few-shot Learning이 과연 새로운 태스크를 배우고 푸는 것인지, 학습하는 동안 배운 태스크 중 하나를 수행하는 것인지 명확하지 않습니다.
- 비용
- GPT-3 스케일의 모델 학습 비용은 비싸고 추론이 쉽지 않을 것입니다.
- 해석 가능성
- 대부분의 딥러닝 모델처럼, 설명력이 떨어지고, 새로운 input에 대해 Calibration이 잘 이루어지지 않습니다. 그렇기에, 예측에 있어 분산이 더 큰 경향이 강하고, 훈련 데이터에 대한 편향이 존재할 수 있습니다.
6. Broader Impacts
6.1 Misuse of Language Models
- 옳지 못한 부분에서 활용될 가능성 (potential misuse application)
- 어떠한 방법으로든 악용될 가능성이 존재합니다. 대표적으로 스팸, 피싱 등이 있습니다.
- 모델이 정교하게 생성한 가짜 정보를 판단할 필요가 있습니다.
- Threat Actor에 대한 분석 (Threat Actor Analysis)
- Advanced persistent threats (APTs): 지능형 지속 공격
- 언어 모델의 오사용에 대한 논의가 꽤 있었으나, 실제로 모델을 이용해 못된 짓을 하는 데 성공한 사례까지는 찾지 못했다고 합니다.
6.2 Fairness, Bias, and Representation
- 성별
- 모델이 성별과 직업의 편향을 가지는지 확인했습니다.
- 남성과 관련된 어휘를 주로 선택한 것으로 나타났습니다.
- Race
- 모델이 인종에 대한 편견을 가지고 있는지 확인합니다.
- 아시아 인종에 대해 7개 중 3개에서 일관적으로 긍정적인 점수가 나온 반면, 7개 중 5개 모델이 흑인과 관련해서 부정적인 답변이 나왔습니다.
- Religion
- 지역적 편향을 반영하는지 여부를 확인합니다.
- 이슬람교와 terrorism, violent 등의 부정적인 단어를 주로 연관짓는 것으로 확인됩니다.
7. Conclusion
- GPT-3는 대규모 데이터와 모델을 바탕으로 한 Auto-regressive Pre-trained language model입니다.
- Fine-tuning을 사용하지 않고도, in-context learning을 통해 높은 few-shot 성능을 보였다는 점에서 좋은 성과를 거뒀습니다.
