CS224W의 A General Perspective on Graph Neural Networks를 주 내용으로 참조했습니다..
GNN의 전반적인 과정
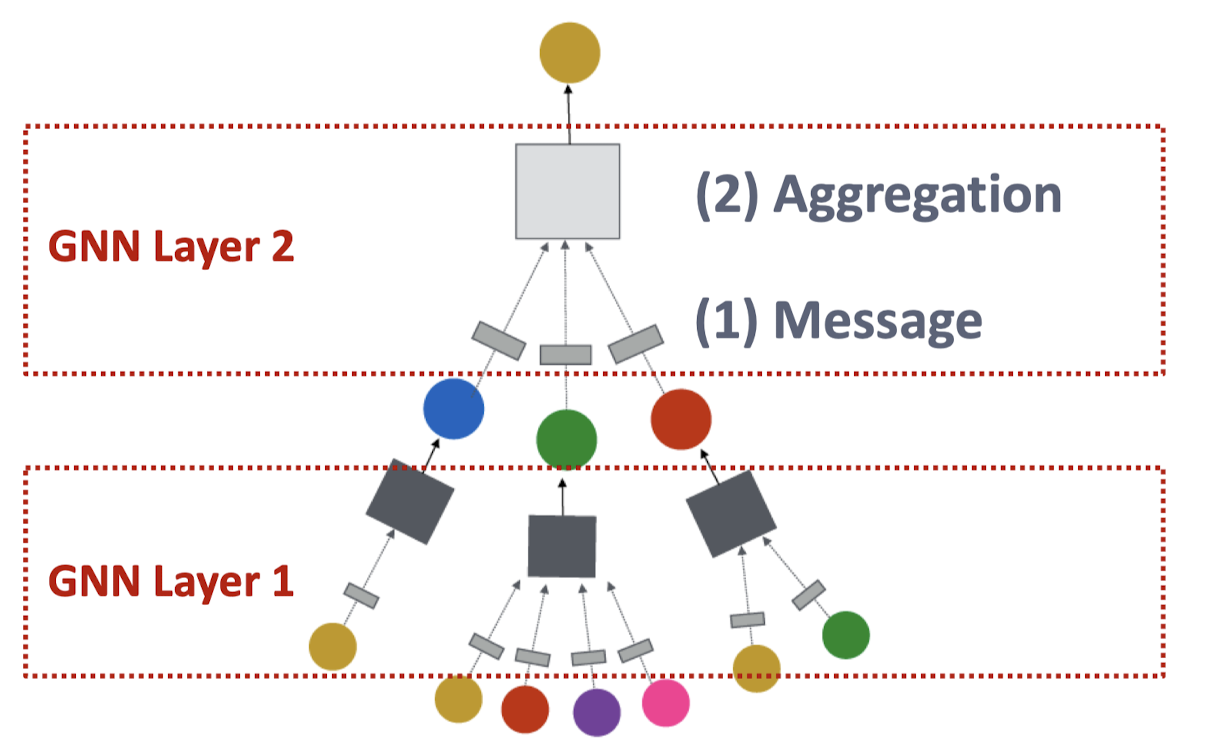
- 각 노드의 벡터를 메시지로 변환
- 변환된 메시지들을 집계
이 과정에서 Computation graph를 통해 Layer connectivity가 반영되고, Graph augmentation이 활용되기도 함.
1. Message Computation (메시지 계산)
메시지로 변환하는 함수는 다음의 과정을 거칩니다.
각 노드(layer)는 메시지를 생성하고, 이후 다음 노드(layer)로 전송합니다. 이전 레이어에서 온 정보인 이 현재 레이어의 메시지 변환 함수 를 통과하여 현재 레이어의 정보가 되는 것입니다.
선형 함수를 메시지 변환 함수로 사용할 수 있고, 행렬 과의 곱도 Message function이 될 수 있음.
2. Message Aggregation (메시지 집계)
노드 의 이웃으로부터 메시지를 집계하는 메시지 집계 함수를 수식으로 표현하면 다음과 같이 나타냅니다.
이 수식은 평균, 합, 최댓값 등 다양한 함수를 사용할 수 있습니다. (예시는 합)
하지만 이 경우, 노드 로부터 전달되는 정보가 손실이 될 수 있다.
원인 : 을 계산할 때 이전 레이어의 에 직접 의존하지 않기 때문임. (이 전혀 상관없기 때문)따라서 를 계산에 직접 포함해 문제를 해결할 수 있음.
메시지를 계산할 때는 이웃 노드로부터 오는 정보는 동일하게 계산하지만, 여기에 노드 가 직접 메시지를 전달하는 계산을 추가한다. (집계 이후 메시지를 기존 노드의 메시지와 연결)
- : 레이어의 가중치 행렬
- : 레이어 의 바이어스 벡터, 각 노드의 이전 상태 정보를 유지하는 정도. 노드의 이전 특징 벡터 에 추가적인 조정을 가하기 위해 사용.
메시지를 집계할 때에는 도 같이 집계한다.
단일 레이어에서
위의 메시지 계산 함수와 메시지 집계 함수를 같이 두어야 하는데, 활성화 함수를 통해 표현력을 높이기 위해, 비선형성을 더한다. → 이 때 ReLU나 시그모이드를 사용한다.
전통적인 GNN 레이어 (1) : GCN
이 식에서, 이 메시지 집계, 이 메시지 계산 함수가 됨.
- 은 이전 임베딩의 평균이 된다.
각 이웃으로부터 시그마 뒤의 항을 계산하는데, 메시지 계산 시 로 정규화함. 그리고, 메시지 집계는 합, 활성화 함수로 시그모이드를 사용했다. 또한, 노드 자신 스스로 합에 포함이 된다.
전통적인 GNN 레이어 (2) : GraphSAGE
GraphSAGE는 GCN에 기반을 둔 모델이고, GCN과는 메시지 집계 함수에서 차이가 있다.
메시지는 에서 계산을 진행하고, 메시지 집계를 두 단계에 걸쳐서 진행한다.
이웃 노드로부터 메시지를 집계하는 과, 노드 자기 자신과 추가로 집계를 하는 로 구분된다.
또한, 모든 노드는 동등한 중요도를 가진다.
GraphSAGE에는 3가지의 집계 함수가 존재한다.
- 평균
- GCN과 동일한 방법으로 이웃들의 가중 평균을 계산한다.
- Pooling
- 메시지 계산으로 MLP를 사용하고, 평균이나 최댓값으로 집계함.
- LSTM
- LSTM을 이용하여 집계시, 순서 불벼ㅓㄴ성에 주의하여 이웃들의 순서를 섞은 다음에 적용한다.
L2 정규화
선택적이지만, 모든 레이어의 임베딩 벡터에 L2 정규화를 적용할 수 있다.
L2 정규화를 수행하지 않는다면, 임베딩 벡터들은 서로 다른 스케일을 갖게 된다. 어떤 경우에는 임베딩 벡터에 대한 정규화가 성능 향상을 가지고 온다고 이야기를 하게 되고, 정규화를 하게 되면, 모든 벡터는 같은 L2-Norm을 가진다.
전통적인 GNN 레이어 (3) : GAT
Graph Attention Networks는 이웃 노드에 대한 중요도를 나타낸 Atttention Weights를 추가한 모델이다.
는 attention weights이다.
인데, 중요도를 Node degree로 두었다고 볼 수 있음. (모든 노드가 동등한 중요도를 가짐)
이렇게 정의된다면, 이웃 노드가 모두 동등하게 중요하게 여겨지게 된다. 단, 당연하지만, 모든 이웃 노드는 같은 중요도를 가지지 않는다. 어텐션을 활용하면 입력 데이터의 중요한 부분에 초점을 맞추고, 나머지는 거의 무시하게 된다. 데이터에서 어떤 부분이 더 중요한지는 상황에 따라 다르고, 학습을 통해 알 수 있다.
그래프에서의 Attention
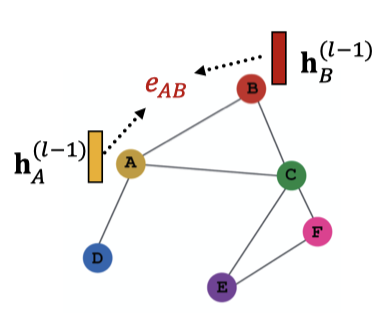
어텐션 매커니즘 의 를 계산하면, 노드쌍 의 메시지를 기반으로 어텐션 개수 를 계산한다. 이때 는 노드 로 가는 의 메시지 중요도를 말한다.
그리고 이 를 정규화해 최종 어텐션 가중치인 에 넣는다. 이때, 이 되도록, 소프트맥스 함수를 사용한다.
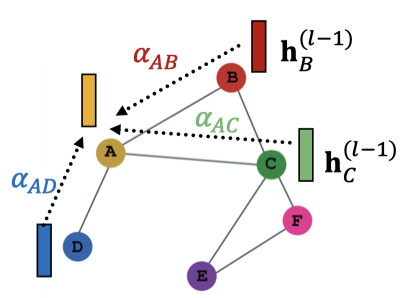
마지막으로, 최종 어텐션 가중치를 이용해 가중합을 계산한다.
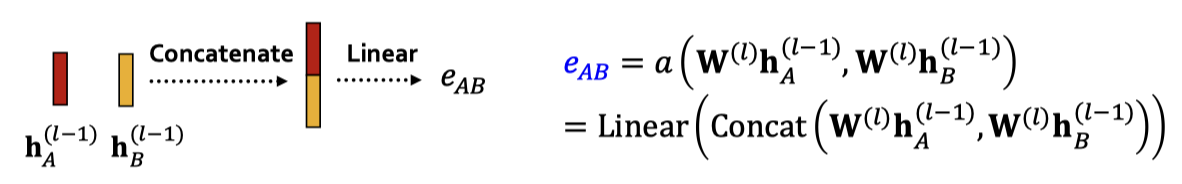
여기서 어텐션 매커니즘 a는 어떤 것도 가능하다.
멀티 헤드 어텐션의 경우는, 어텐션 매커니즘의 학습 과정을 안정화한다. 여러 개의 어텐션 점수를 생성하고, concatenation이나 합을 이용해 결과를 집계한다.
위의 어텐션 매커니즘은 다음의 장점을 갖는다.
- 계산 효율성 : 어텐션 계수 계산은 그래프의 모든 엣지에 대해 병렬화가 가능하다.
- 저장 효율성 : Sparse Matrix는 O(V + E) 이상의 공간을 사용하지 않고, 그래프 크기와 상관없이 고정적인 파라미터 개수를 갖는다.
- 국소성 : 국소적인 네트워크 이웃에만 의존한다.
- 귀납 가능성 : Edge-wise 매커니즘과 공유 가능하며 전역적인 그래프 구조에 의존하지 않는다.
GNN Layer의 활용
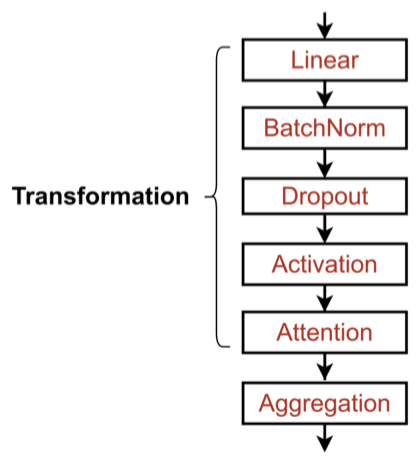
기존 딥러닝에서 쓰이는 layer들을 함께 활용해 높은 성능의 GNN Layer을 얻을 수 있음.
Batch Normalization
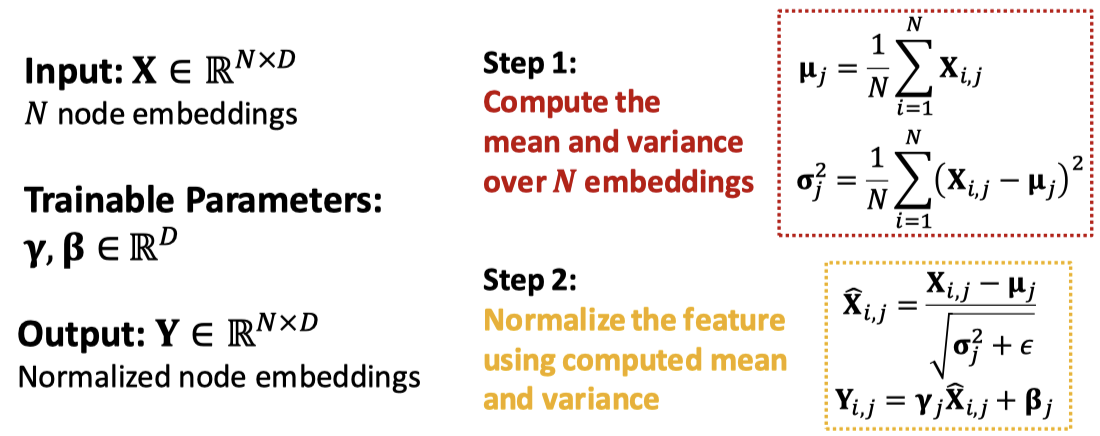
배치 정규화의 목적은 신경망을 안정시키는 것이다. 노드 임베딩의 배치가 주어졌을 때, 평균을 0, 분산을 1로 만든다.
Dropout
신경망이 오버피팅하는 것을 방지하기 위해 사용한다. 학습 중에서는 의 확률로 임의의 뉴런을 끄고, 테스트 중에는 모든 뉴런을 사용한다.
GNN에서는 메시지 함수의 Linear layer에 드롭아웃을 적용한다.
Activation Function
ReLU, Sigmoid, Parametric ReLU 등을 사용한다.
Staking Layer in GNN
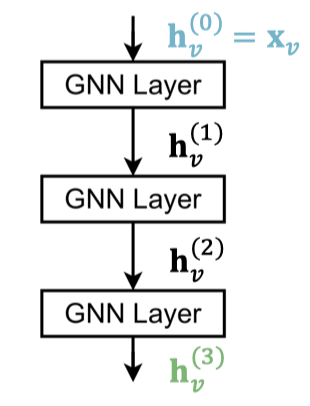
일반적으로 GNN을 구축할 때는 GNN 층을 순서대로 쌓는다. Input value로는 초기화한 노드 피처 를 받고, 개의 GNN 층을 거친 노드 임베딩 을 결과로 얻는다.
그렇지만, GNN 레이어를 많이 쌓게 되면, 다음의 문제가 발생한다.
Over-smoothing : 모든 노드 임베딩이 같은 값으로 수렴하는 현상
Over Squashing : 많은 양의 정보가 좁은 경로를 지나가면서 중요한 정보가 왜곡되거나 손실되는 현상
노드 임베딩을 사용하는 이유가, 노드마다 차이를 두기 위함인데, Over-smoothing 문제가 발생한다면, 모순이 발생한다.
Problem 1 : Over Smoothing
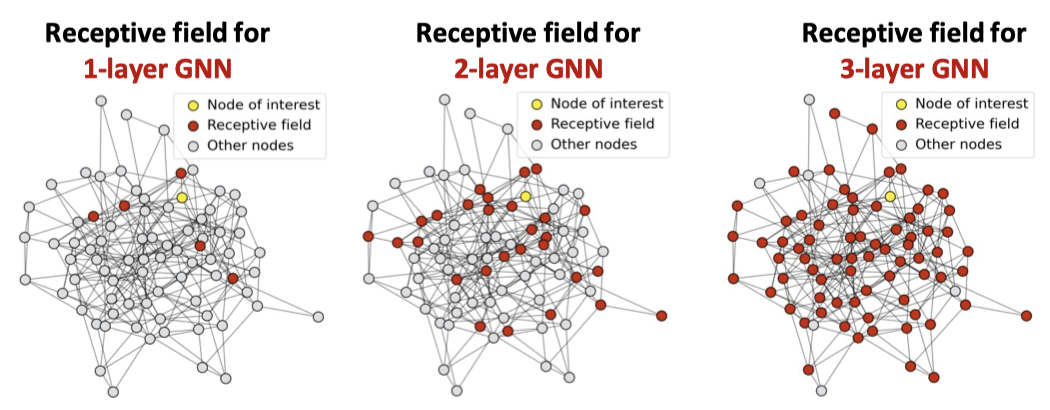
그림의 설명은 다음과 같다.
k개의 layer을 사용한 GNN 모델은 각 노드가 -hop neighborhood의 수용 영역(receptive field)을 가지게 되는데, 레이어가 많을 수록, 이 수용 영역은 넓어지게 되고, 임베딩은 수용 영역에 의해 결정됨. 즉, 층이 깊어질수록 수용 영역이 많이 겹치게 됨.
만약, 2개의 노드가 매우 많이 겹치는 수용 영역을 가진다면, 두 노드의 임베딩은 매우 비슷해짐. 그렇기에, 많은 레이어를 쌓으면 대부분의 노드가 하나의 수용 영역을 공유하게 되고, 이로 인해 노드 임베딩이 비슷해지는 현상, 즉 Over-smoothing 현상이 발생한다.
즉, 정보 수용에 대한 shortest path가 증가하는 것이다. 이로 인해, target node에 대한 정보가 희석되어 결국은 모든 노드 임베딩이 같은 값으로 수렴하게 된다.
→ 이 문제를 해결하기 위해서는 GNN 층을 쌓을 때 개수를 잘 조절해야 하는데, 이를 위해 그래프의 직경과 같은 수용 영역에 대한 정보를 먼저 분석하고, 그보다 조금 많은 수의 레이어만을 쌓아야 한다.
Problem 2 : Over Squashing
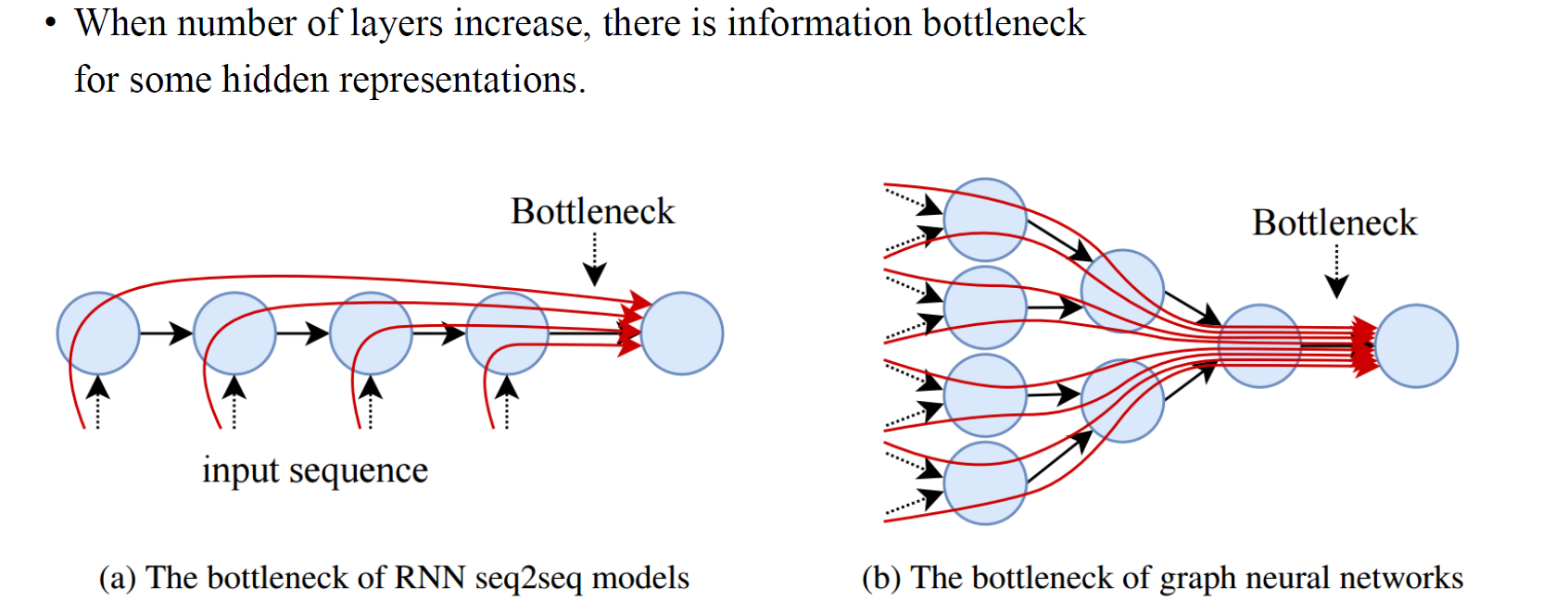
Over Squashing은 target node의 측면에서 발생하는 문제이다.
여러 time step으로부터 정보를 모은다면, 굉장히 많은 정보들이 모일 것이고, 이는 은닉층에 전부 담지 못하게 된다. 즉, 너무 많은 정보 수집으로 인해 정보량이 기하급수적으로 늘어나게 된다.
특정 깊이만큼 떨어져 있는 이웃에 target node를 알 수 있는 아주 중요한 힌트를 넣어놓고, GNN 층을 쌓으며 Acc를 비교한 결과, Depth가 커지면서 오히려 성능이 감소한다.
즉, Layer 수를 무작정 늘리는 것이 좋은 것이 아니고, 특정 임계값을 넘어가면 정확도가 급감하는 현상이 일어난다.
Over Smoothing 해결
1. GNN 레이어 내의 표현력을 높이는 것
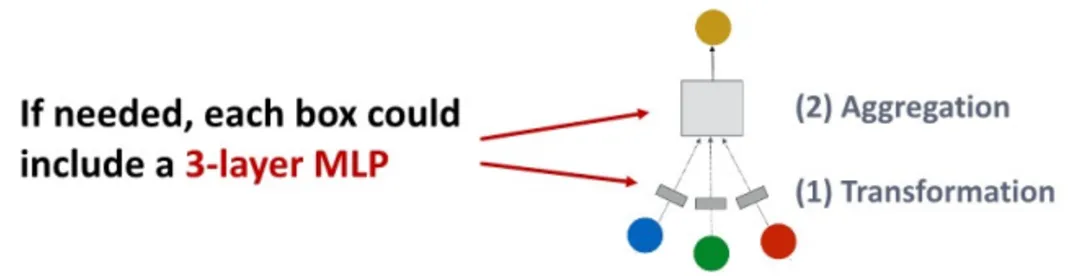
변환 함수나 집계 함수는 하나의 선형 레이어에 하나만 들어가기에, 집계 함수나 변환 함수를 조금 더 복잡한 Neural Network로 만들 수 있을 것
이들의 표현력을 높이기 위해, 각각의 function이 하나의 MLP layer로 구성되게 해, GNN layer 하나 당 총 3개의 layer로 구성되게 한다.
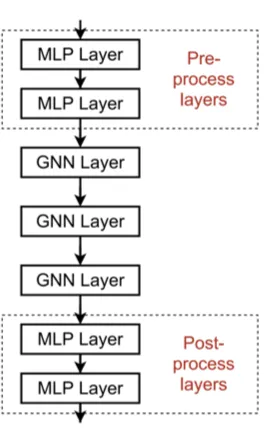
2. 메시지를 전달하지 않는 레이어를 추가하는 것
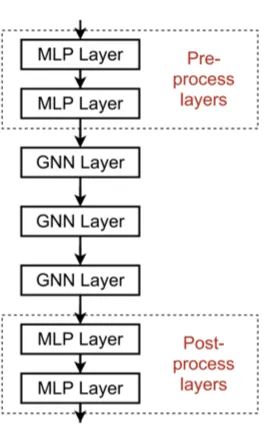
GNN은 반드시 GNN 레이어만 포함할 필요는 없다. 예를 들면, GNN 레이어 앞뒤에 MLP 레이어를 넣어도 무방하다.
GNN 레이어 앞에 넣을 때는, 노드 피처를 인코딩하는 것이 중요할 때가 될 것이고, 뒤에 넣을 때에는 노드 임베딩에 대한 추론이나 변환이 중요할 때가 된다. 실제로 이런 방식으로 레이어를 쌓는 것이 큰 도움이 된다.
- Pre-Processing layer : 노드 특징을 인코딩
- Post-Processing layer : 추론
3. Skip-Connection
이 방법은 GNN layer을 깊게 쌓고 싶을 때 사용하는 방법이다.
오버스무딩 문제를 잘 보면, 오히려 초기의 GNN 레이어에서 노드 임베딩에서 노드마다 차이가 큰 것을 확인할 수 있음. 따라서 초기 레이어의 영향력을 증가시키기 위해, GNN에 Skip-Connection을 추가한다.
임베딩 결과가 원래 정보와 완전 상이할 수 있는데, 이럴 경우 잔차를 학습할 수 있도록 Skip-connection을 통해 두 정보를 더해준다.
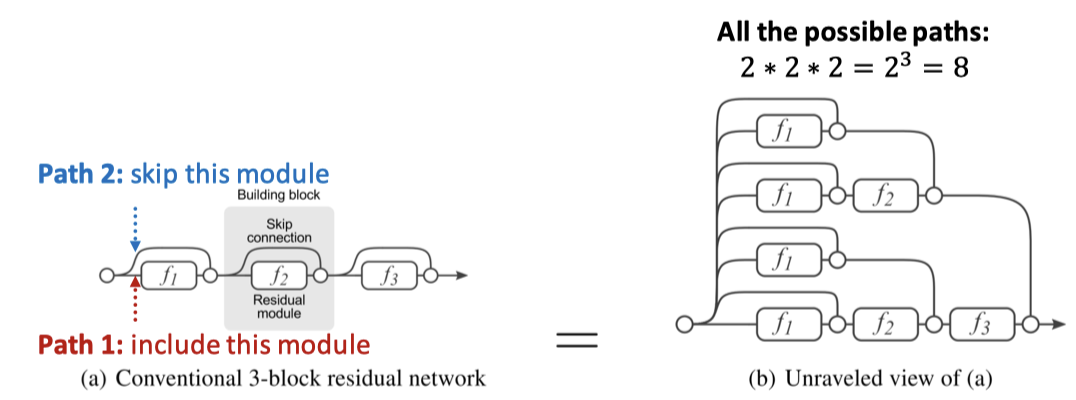
Skip-Connection은 일종의 혼합 모델을 생성한다. N개의 Skip-connection이 있다면, 모두 개의 경로가 생긴다.
각 경로에는 최대 개의 모듈이 있는데, 자동적으로 얕은 GNN과 깊은 GNN의 합성 모델을 얻게 된다.
→ 일종의 정규화 효과를 주어 더 모델이 일반화할 수 있게 해준다.
Skip Connection을 사용한 일반적인 GCN layer은 다음과 같이 전환된다.
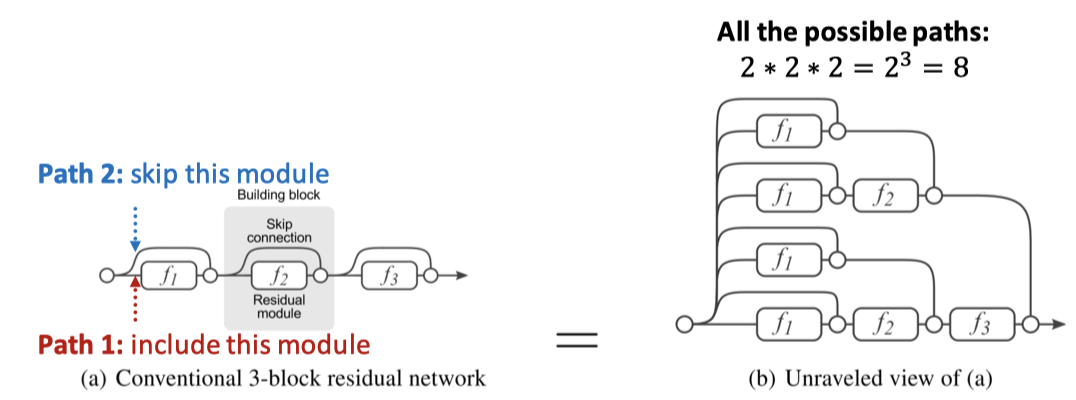
다른 옵션으로는 다이렉트로 모든 Skip-connection을 집계(Aggregation) 레이어 이전으로 보내는 방법이 있음.
이 방식은 GNN 모델에에서 target node가 v인데 은 1-hop거리 이웃한테만 메시지를 받은 것이고, 은 2-hop, 3-hop까지 받은 정보이다.
이렇게 최종 layer에 모든 입력이 한번씩 잔차 학습하는 것은, 실제로 몇 hop까지 정보를 받는 것이 수용 영역에 걸치는지 명확하지 않은 경우 모든 hop의 정보를 한 번씩 더 줘서 마지막 집계 부분에서 학습을 통해 판단하도록 만든다. 이렇게 된다면, 자연스럽게 shallow GNN과 deep GNN의 혼합 모델을 가지게 된다.
GNN에서의 그래프 조작
지금까지 원천 입력 그래프르 연산 그래프로 가정했지만, 이 가정을 만족시키기는 실제로 쉽지 않음. 피처 수준에서 입력 그래프의 피처가 부족할 수도 있음. 구조 수준에서는 그래프가 너무 희소해서 메시지 전달이 충분하지 않을 수도 있고, 그래프가 너무 조밀해서, 전달 비용이 지나치게 클 수도 있음. 또는 그래프가 너무 커서 계산 그래프를 GPU에 적합시키지 못하는 경우도 존재.
그렇기에, 입력 그래프가 임베딩을 위한 최적의 연산 그래프가 될 가능성은 거의 없지만, 그래프를 조작하여 문제를 해결할 수 있음.
- 그래프 피처 조작 → 노드 특징 정보가 부족한 경우
- 입력 그래프의 피처가 부족한 경우, 특징 추가(feature augmentation) 수행
- 그래프 구조 조작 → 구조적 특성이 GNN 학습에 부적합한 경우
- 그래프가 너무 희소한 경우, 가상 노드/엣지 추가
- 문제 : 메시지 전달이 비효율적일 수 있음
- 그래프가 너무 조밀한 경우 메시지 전달 시 이웃을 샘플링
- 문제 : 메시지 전달의 계산 비용이 매우 높아질 수 있음.
- 그래프가 너무 큰 경우 임베딩 계산 시 서브그래프 활용
- 문제 : 큰 그래프를 통째로 GNN에 입력하기 어려움 (메모리 제약)
그래프 피처 조작
인접 행렬의 정보만 있다면, 피처가 없게 된다.
→ 이는 인접 행렬 정보만 있고, 노드 특징 행렬이 없는 경우에 해당한다.
가장 일반적인 방법으로는
- 모든 노드에 상수를 부여하기
- 각 노드에 고유 ID를 부여하고 One-Hot Encoding 수행하기
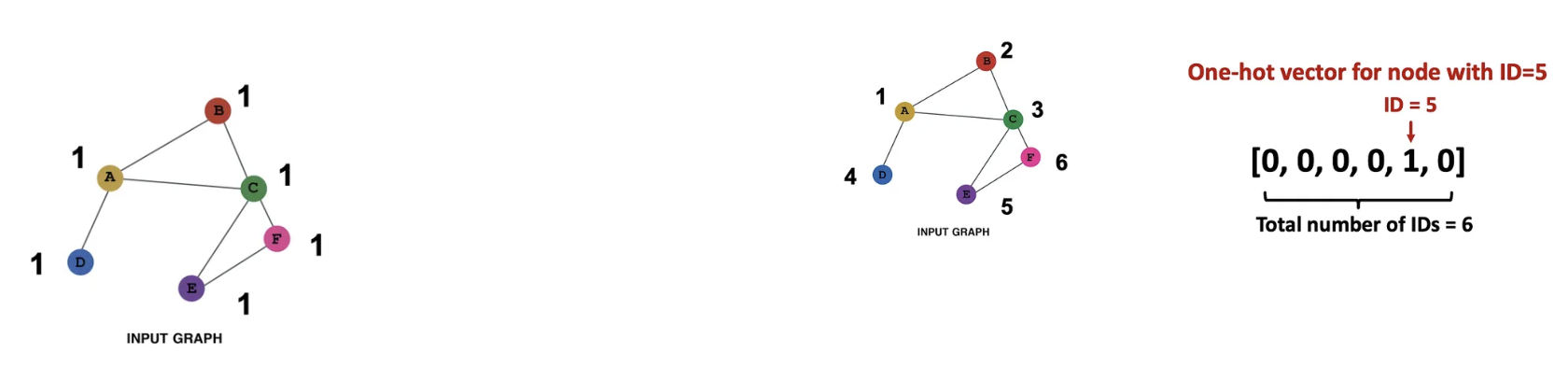
| 상수 노드 피처 | One-hot Encoding | |
|---|---|---|
| 표현력 | 중간 수준, 모든 노드의 피처 값이 같지만 GNN은 여전히 그래프의 구조를 학습할 수 있음. | 높은 수준으로 각 노드가 고유의 ID를 갖고 있기 때문에 노드마다의 정보를 저장할 수 있음 |
| 새로운 노드에 대한 일반화 | 새로운 노드에 일반화하여 적용할 수 있음. 새로운 노드에 대해 같은 상수를 부여하는 방법 | 새로운 노드에 일반화할 수 없음 GNN이 새로운 노드에 대한 고유 ID를 찾을 수 없음. |
| 계산 비용 | 1차원 피처만 필요하기 때문에 낮음 | 노드 개수만큼 차원이 필요하기에 높음 |
| Usecase | 어떤 그래프에도 사용가능, 유도 학습 설정에도 가능 | 작은 그래프에만 가능하며 새로운 노드가 없는 경우에만 가능 |

GNN은 특징 구조에 대한 학습이 매우 어렵다. 예시로, 그래프 내 순환 구조에 대한 피처를 들 수 있는데, 두 그래프에서 똑같은 을 구분하지 못한다. degree가 똑같이 2이기 때문이다. 따라서 연산 그래프는 똑같은 이진 트리를 구성하게 되는데, 이런 경우 순환 구조의 수를 노드 피처로 추가 가능하다.
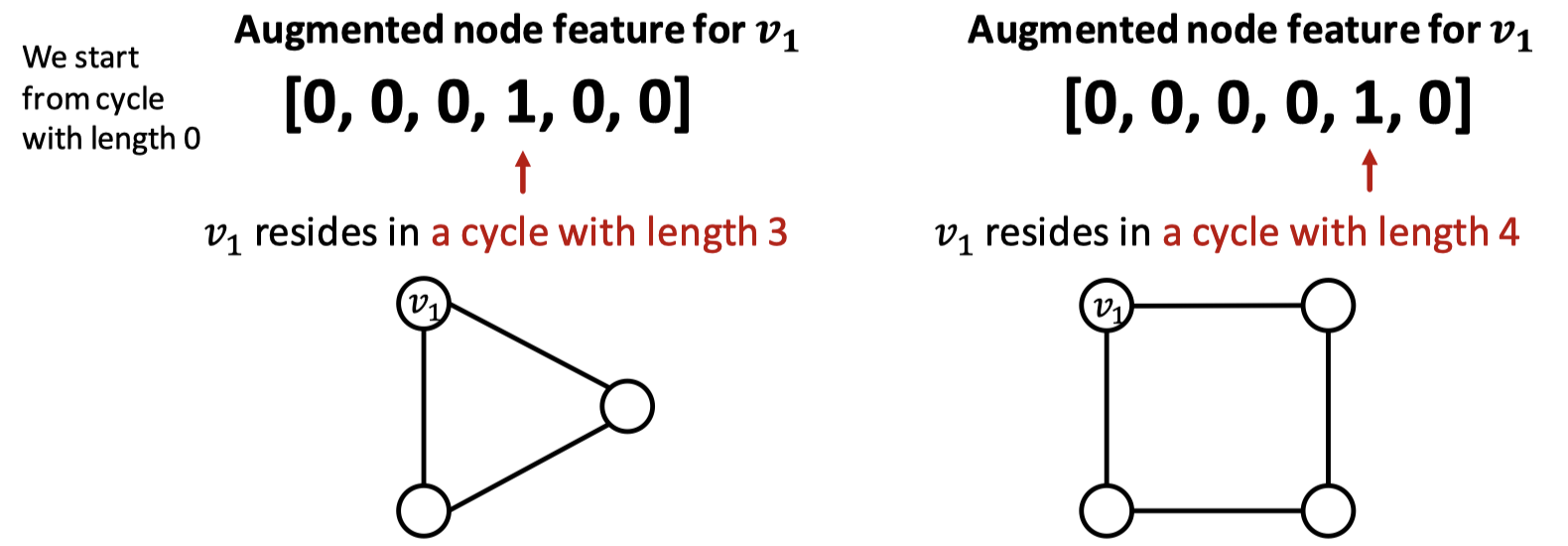
순환 구조의 크기를 0부터 시작해 그 크기를 변수화한다. 첫번째 그래프는 순환 구조 크기가 3, 두번째 그래프는 순환 구조 크기가 4이다.
이외에도 군집 계수, PageRank, 중심성 등 여러 추가 피처를 사용할 수 있다.
그래프 구조 조작
- 가상 노드/엣지 추가 (그래프가 지나치게 Sparse한 경우)
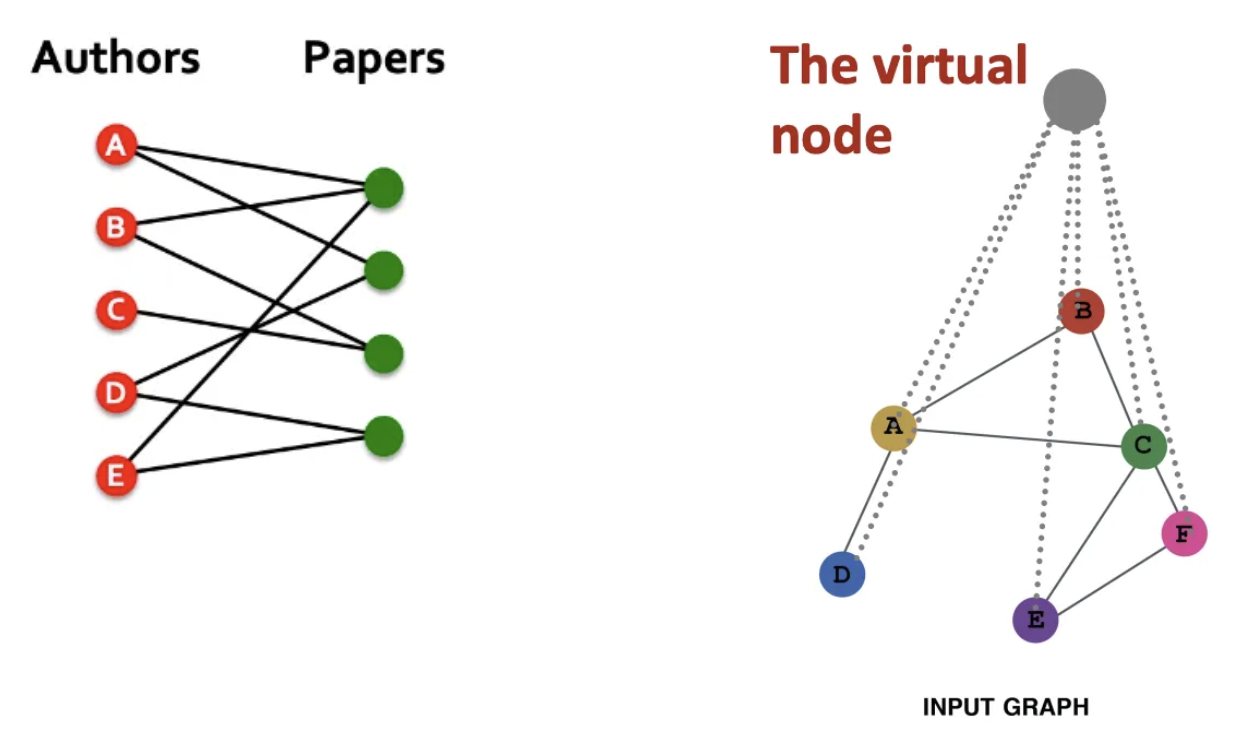
일반적으로 희소한 그래프에 대해서 가상 노드나 가상 엣지를 추가한다. 가상 엣지를 추가할 때에는 일반적인 접근법으로 가상 엣지를 통해 2-hop neighbor을 연결하는 것이다. 인접 행렬을 이용해 만 계산하면 된다.
가상 노드의 경우, 모든 노드와 연결되도록 추가한다. 그렇게 하면 모든 노드는 다른 노드와의 거리가 2가 되고, 희소한 그래프에서 메시지 전달에서 크게 효과를 볼 수 있다.
- 노드 이웃 샘플링 (그래프가 지나치게 Dense한 경우)
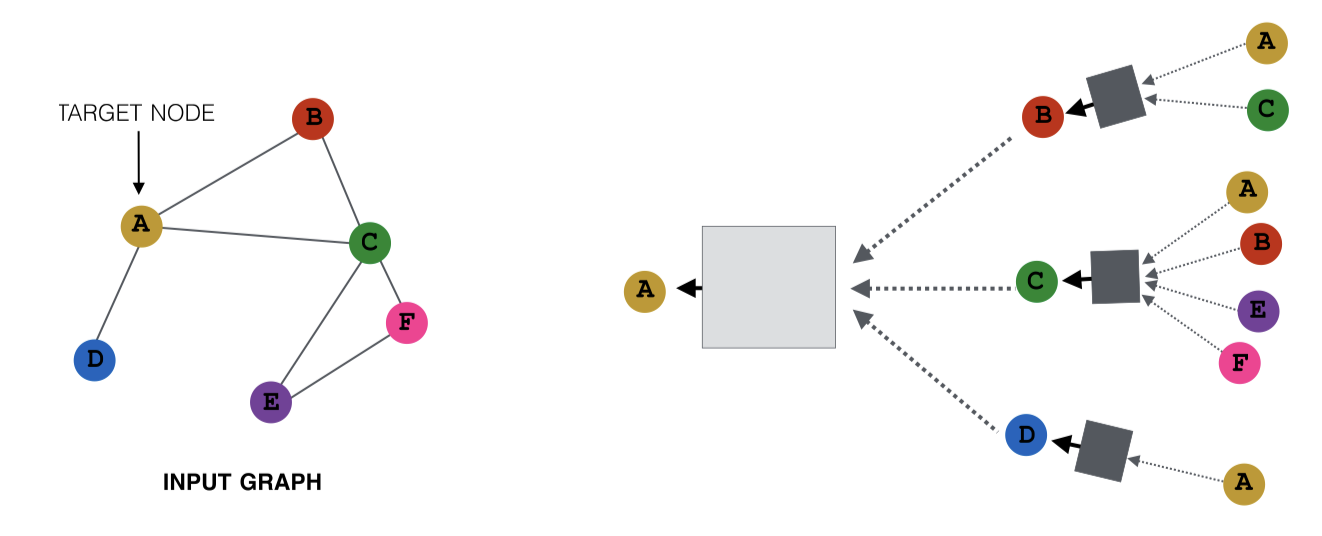
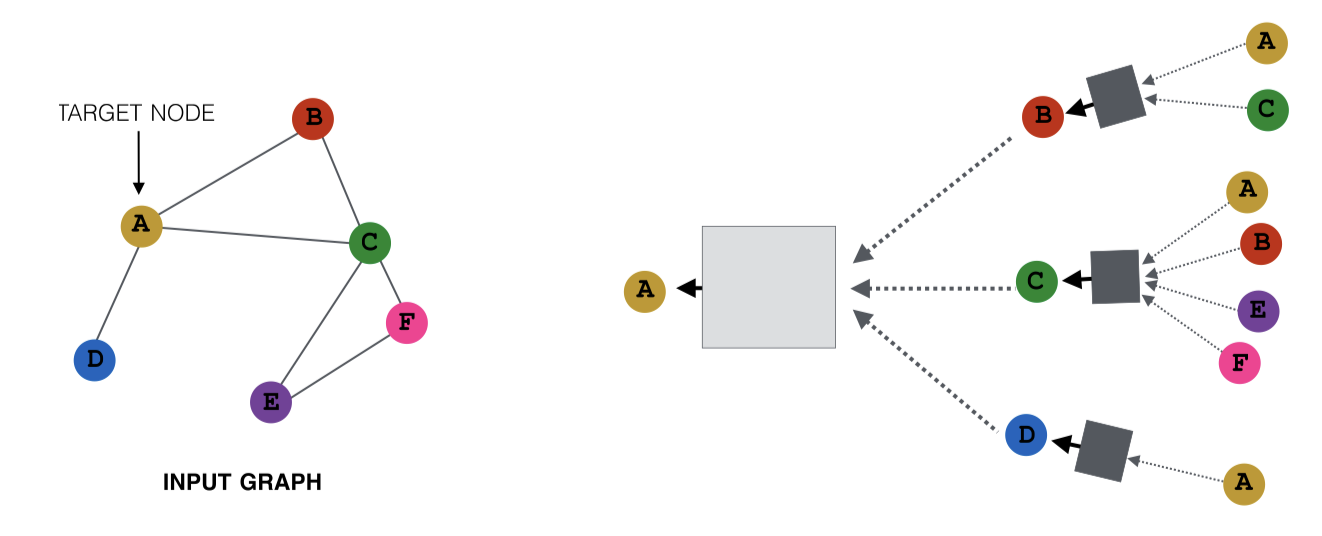
노드 이웃을 샘플링하여 조밀한 그래프에서 학습을 용이하게 할 수 있음. 위와 같이 생긴 그래프에서 메시지 전달에 참여하는 노드를 샘플링할 수 있는데, 예를 들어 A 노드로 메시지를 전달하는 노드로 B와 D를 샘플링하면 다음과 같다.
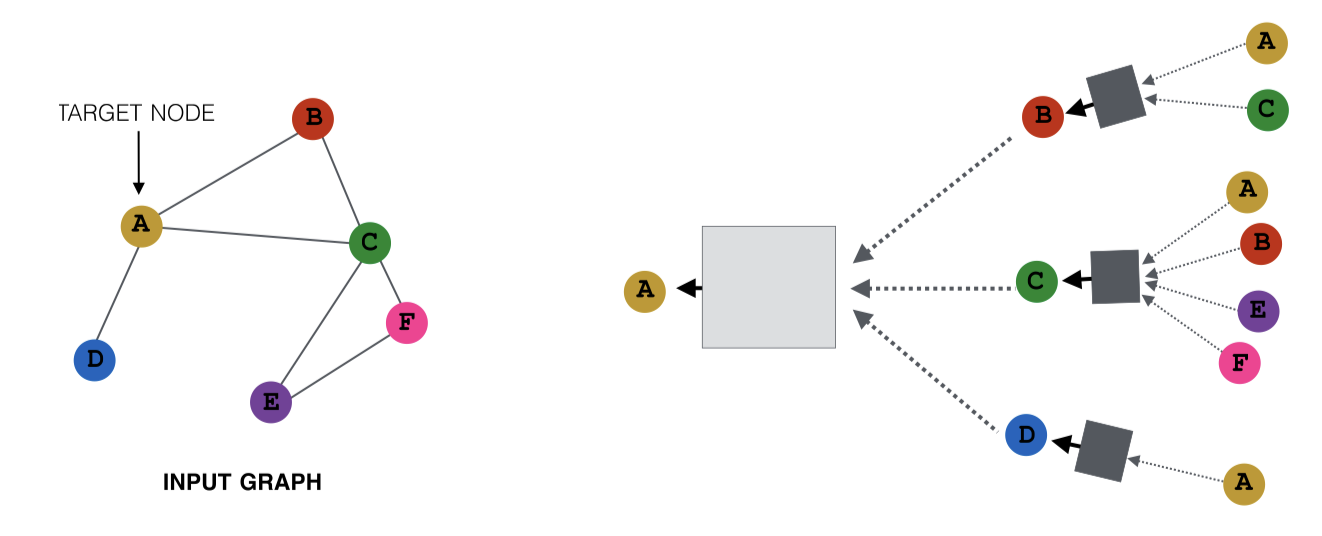
만약 A 노드로 메시지를 전달하는 노드가 C와 D인 경우라면 다른 그림이 된다.
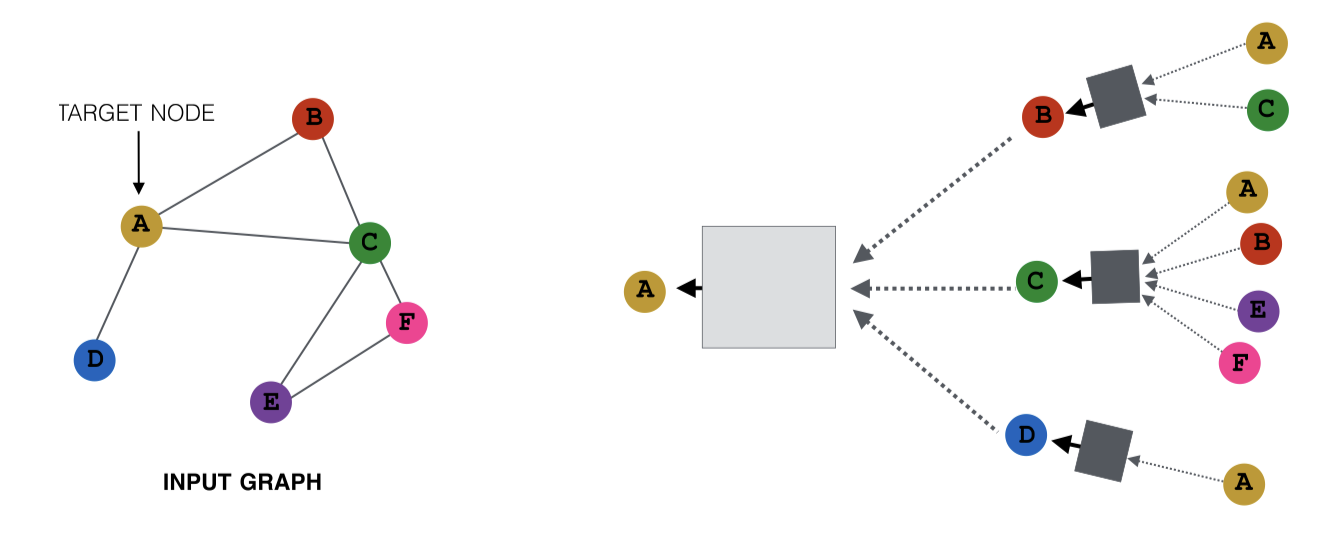
이렇게 해도 모든 이웃이 사용되는 경우와 유사한 임베딩을 얻을 수 있다. 하지만, 계산 비용을 줄이고 실제 시나리오에서도 좋은 성능을 보인다.
-
임베딩 계산 시 서브그래프 활용 (그래프가 매우 큰 경우)
노드 수가 많으면 거대한 그래프의 경우, 전체 그래프를 한 번에 처리하기 어려울 수 있음. 이런 경우에는 서브그래프를 샘플링하여 임베딩을 계산할 수 있다.
서브 그래프는 전체 그래프의 특징을 잘 반영하도록 선택되어야 하고, 이를 통해 자원의 한계를 극복할 수 있다.
참조
https://meaningful96.github.io/graph/Graph2/#d-gnn-prediction-task
https://otzslayer.github.io/cs224w/2023/06/16/cs224w-05.html
