Task and Evaluation
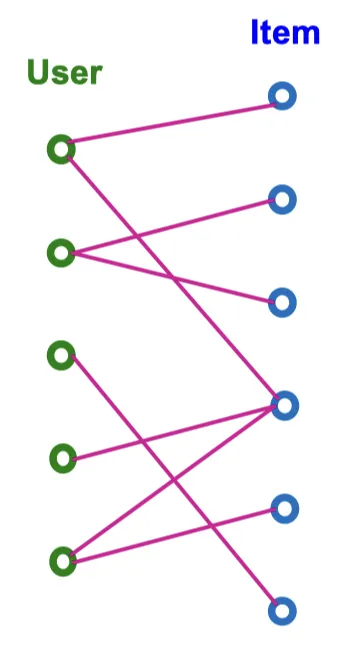
Recommender System(추천 시스템)은 기본적으로 이분 그래프(bipartite graph) 형태로 나타낼 수 있다.
해당 그래프에는 User, Item의 2가지 노드 타입이 존재한다. 이 2가지 노드를 연결하는 엣지는 User-Item 상호작용을 의미한다. Recommend task는 과거의 사용자-아이템의 상호작용을 이용해 앞으로 각 사용자가 소비할 아이템을 예측하는 형태로 진행된다. 이런 과정은 Link Prediction Task로 나타낼 수 있다. 따라서, 노드 에 대해 다음 스코어 를 계산하는 것과 같음.
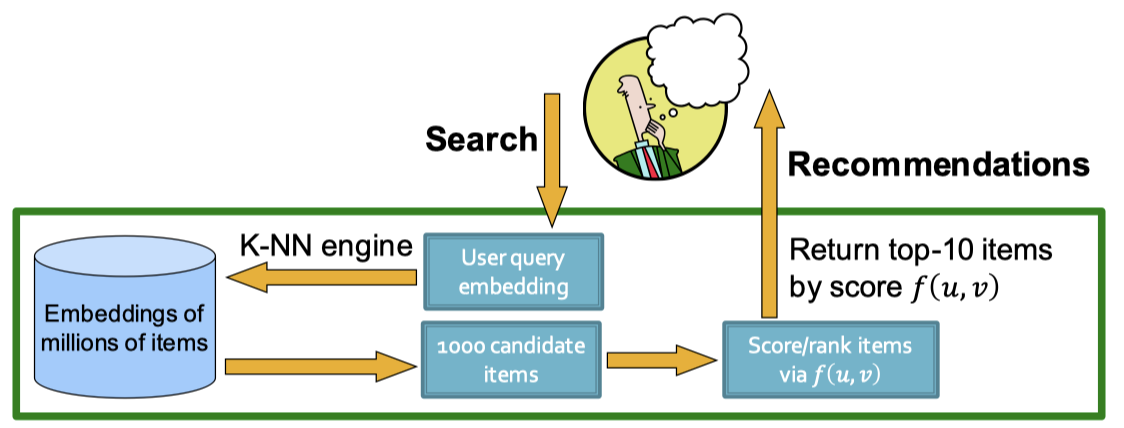
하지만 현재는, 너무 많은 사용자와 아이템이 있기에, 모든 사용자-아이템 쌍에 대해 계산하는 것은 힘들다. 그렇기에, 최근에는 2단계의 추천 시스템을 많이 사용한다.
먼저, Top-K 방식을 활용해 추천 후보군을 빠르게 생성하고, 그 후보군에 대한 순위를 학습/추론하는 단계를 거친다. 이때, 추천의 효과를 높이기 위해, K는 상대적으로 낮은 값을 사용한다. Top-K의 목표는 K개의 아이템에 따라 사용자가 미래에 소비할 아이템을 최대한 많이 포함시키는 것이다.
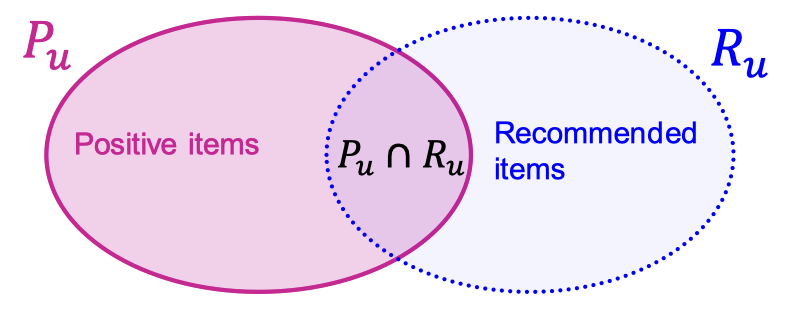
이를 위한 평가 지표로 Recall@K를 사용한다. Recall@K는 다음과 같이 정의한다.
사용자 에 대해 를 사용자가 미래에 상호작용할 아이템의 집합, 를 모델이 사용자에게 제공한 추천 아이템 집합이라고 하자. 여기서, 가 되고, 이때 사용자가 이미 상호작용한 아이템은 에서 제외된다.
Recall@K의 값이 높을수록 좋으며, 모든 사용자에 대해 Recall@K의 평균을 최종 평가 지표로 사용한다.
Embedding-Based Models
사용자의 집합, 아이템의 집합, 이미 가지고 있는 사용자-아이템 상호작용을 라고 하고, 다음과 같이 정의한다.
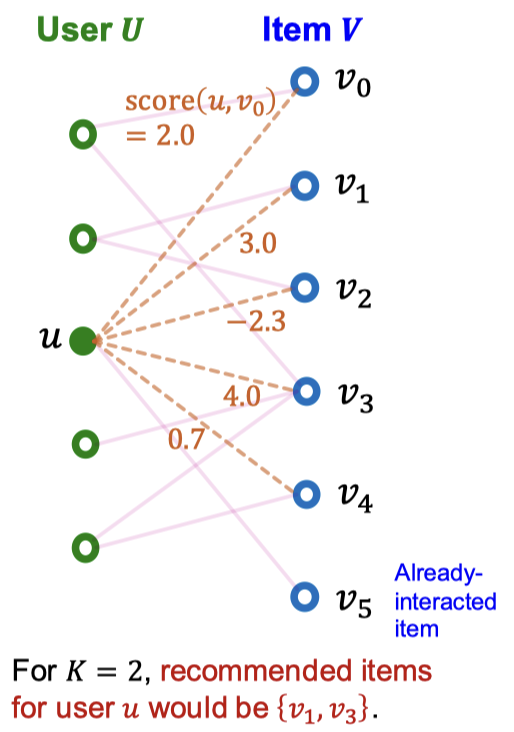
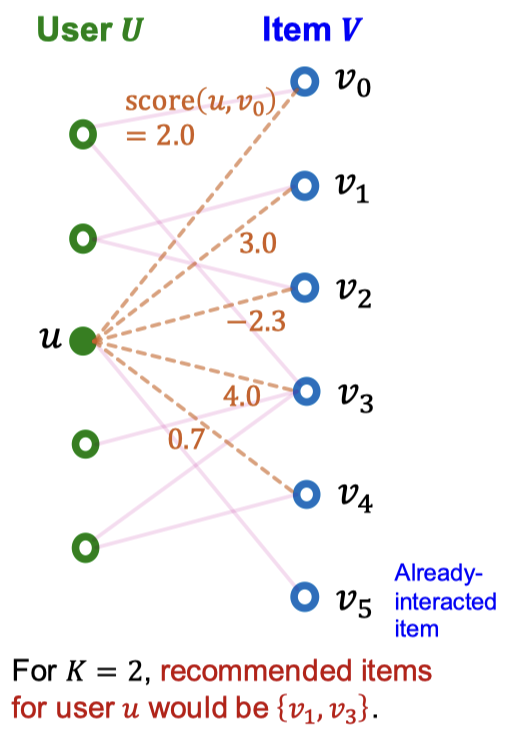
Top-K Item을 얻기 위해, 사용자-아이템 상호작용에 대한 스코어링 함수가 필요함. 그 스코어링 함수는 두 노드 간의 스코어이고, 이 점수가 높고 사용자와 상호작용하지 않은 K개의 아이템을 사용자에게 추천한다. 위 그림에서는 K=2에 대해 점수가 가장 높은 가 추천된다.
이때, 사용자-아이템 상호작용에 점수를 매기기 위해 임베딩 기반 모델을 고려할 수 있다. 여기서,
사용자 에 대해 차원 임베딩 ,
아이템 에 대해 차원 임베딩 으로 둘 수 있음.
이때 파라미터화한 함수 가 있고, 이 함수가 스코어링 함수가 됨.
이렇게, 임베딩 기반 모델은
- 사용자 임베딩
- 아이템 임베딩
- Scoring Function
총 3가지 종류의 파라미터가 존재함. 학습 데이터 내의 사용자-아이템 상호작용을 많이 맞추는, 즉 높은 Recall@K를 달성하는 모델 파라미터를 최적화하면 됨. 그리고 테스트 데이터에 대해서도 높은 Recall@K를 보이면 더 좋음.
단, Recall@K는 미분이 불가능하기에, 경사 하강법과 같은 기울기 기반의 최적화 방법을 사용할 수 없음. 그렇기에, Recall@K를 대체할 수 있는 효율적인 2가지 기울기 기반 최적화 손실 함수를 사용하는데,
- Binary Loss
- Bayesian Personalized Ranking (BPR)
을 사용한다. 이들은 모두 미분 가능하고, 기존 학습 목적에도 잘 부합한다.
Binary Loss
학습 데이터에 있는 엣지 집합 와 사용자 아이템 간 상호작용이 없는 노드쌍 집합 가 있을 때 Binary Loss는 다음과 같이 정의함.
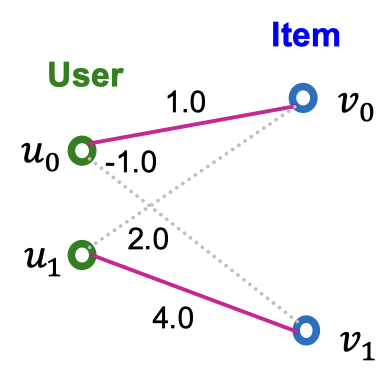
Binary Loss는 에 속한 엣지의 스코어를 에 속한 엣지보다 높게 만든다. 그렇지만, 위의 그림처럼 엣지 은 가 속하는 Positive Edge지만, Negative Edge인 보다 스코어가 낮은 경우에, 모델은 Negative Edge가 Positive Edge보다 스코어가 높기 때문에 ,계속해서 패널티를 주게 된다.
결국, 에 속한 모든 엣지를 에 속한 엣지보다 높게 만들어서 사용자마다 개인화된 추천이 이루어지지 않게 된다. 하지만, Recall@K는 개인화된 평가 지표이기 때문에, Binary Loss는 적절하지 않다. 결국 Recall@K를 대체하는 손실함수는 개인화된 방법으로 작동해야 하기에, BPR이 이 문제를 해결해줄 수 있다.
Bayesian Personalized Ranking (BPR)
BPR은 개인화된 대체 손실함수이다. BPR은 사용자별로 Positive Edge와 Negative Edge를 구분하여 손실 함수를 계산한다. 사용자별 Positive Edge와 Negative Edge는 다음과 같다.
이제 사용자마다 positive edge의 스코어를 negative edge의 스코어보다 높여주도록 계산하면 되는데, 사용자 에 대한 BPR loss는 다음과 같다.
그리고 위 식을 이용해 모든 사용자에 대해 다음과 같이 계산한다.
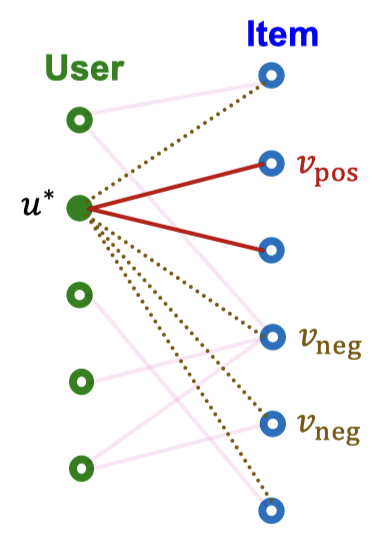
위 BPR 식은 미니배치를 이용해 근사할 수 있는데, 각 미니배치마다 사용자를 샘플링한다. 그리고 각 사용자 에 대해 하나의 postive item 와 샘플링한 negative item {} 을 샘플링한다. 미니배치 손실 함수는 다음과 같이 계산한다.
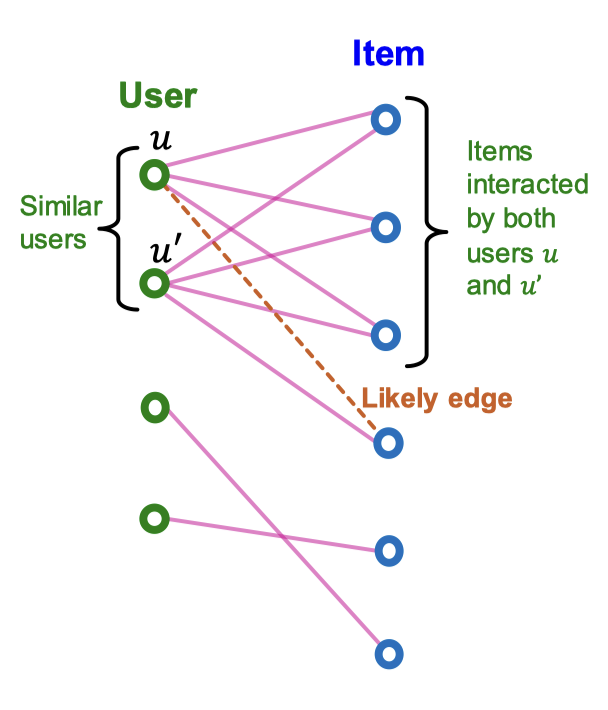
임베딩 기반 모델이 잘 작동하는 이유는 Collaborative Filtering에서 찾을 수 있다. 협업 필터링은 자신과 유사한 사용자의 선호도를 모아 사용자에게 추천을 해주는데, 자신과 비슷한 사용자들은 비슷한 아이템을 선호한다는 가정이 Basis에 깔려 있다. 이 때 가장 중요한 요소는, 사용자 간 유사도를 계산하는 것인데, 임베딩은 강제로 사용자나 아이템 간 유사도를 잡아낼 수 있다. 이를 통해 모델은 아직 알지 못하는 사용자-아이템 상호작용을 효과적으로 예측할 수 있다.
Neural Graph Collaborative Filtering (NGCF)
전통적인 협업 필터링은 Matrix factorization, shallow encoder에 기반을 두고 있다. 그렇기에, 사용자 피처나 아이템 피처는 사용하지 않는다. 각 사용자 와 아이템 에 대해 학습 가능한 shallow embedding 을 생성한다. 스코어링 함수로는 단순 inner product을 사용한다.
다만, 이는 모델 자체만으로 그래프의 구조를 반영하지 못하고, 학습 목적 함수로 1차원적인 구조만 잡아낼 수 있다. 즉, Multi-hop 관계는 전혀 잡아내지 못한다.
→ 이를 해결하기 위해 Neural Graph Collaborative Filtering이다.
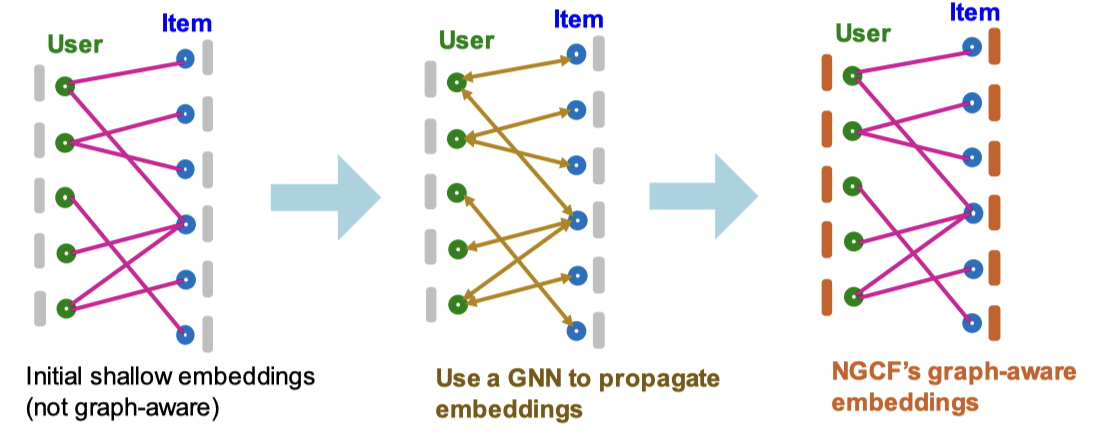
NGCF는 사용자/아이템 임베딩을 생성할 때, 고차원 정보가 전파된 임베딩을 만드는 것이 목표이다. 다시 말해, 이를 통해, 기존의 문제였던 Multi-hop 관계를 캐치할 수 있다.
사용자-아이템에 대한 이분 그래프(Bipartite Graph)가 주어졌을 때, 우선 각 노드에 대해 학습 가능한 Shallow Embedding을 생성한다. 그리고 Multi layer GNN을 사용해 이분 그래프에 대한 임베딩을 전파시킨다. 이를 통해 고차원 그래프 구조를 잡아낸다. 이 과정에서 사용자/아이템 임베딩, GNN파라미터가 같이 학습된다.
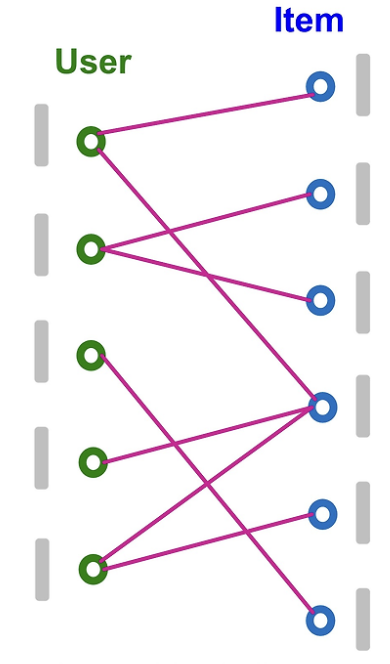
자세히 보면, 첫 step에서 노드 피처로 initial node embedding을 할당한다. 각 사용자 에 대해 을 사용자의 shallow embedding으로, 각 아이템 에 대해 을 아이템의 shallow embedding으로 초기화한다.
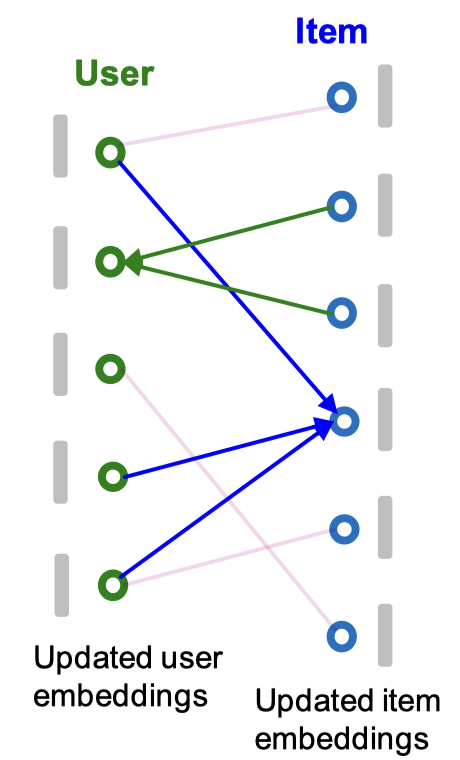
그리고 사용자 임베딩은 연결되어 있는 아이템 노드의 임베딩을 집계하여 업데이트하고 아이템 임베딩은 연결되어 있는 사용자 노드의 임베딩을 집계하여 업데이트를 반복한다.
이런 반복을 통해서 Multi-hop을 잡아낸다. AGGR, COMBINE을 어떻게 설정하느냐에 따라 다른 아키텍쳐를 만들 수 있다. AGGR은 평균, COMBINE(x,y)은 ReLU(Linear(Concat(x,y)))으로 보통 사용한다.
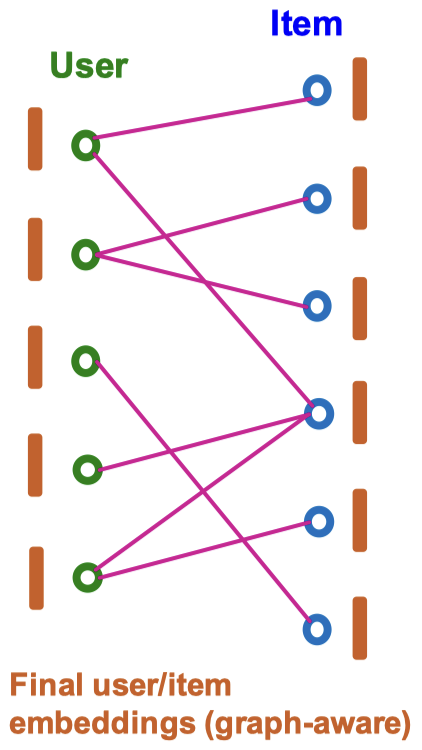
이웃 집계를 K번 반복하고 나면 최종 사용자/아이템 임베딩인 을 얻게 된다. 마지막으로 다음과 같이 설정한다.
스코어링 함수는 inner product를 사용한다.
LightGCN
NGCF에서는 Shallow Embedding을 사용했는데, 얕은 임베딩만으로 충분히 표현력을 가질 수 있다. 모든 사용자/아이템 노드에 대해 임베딩을 학습하는데 노드의 수가 충분히 많기 때문.
임베딩 차원 크기 보다 일반적으로 노드의 수 이 더 큰데, 얕은 임베딩은 , GNN은 이기 때문. 그래서 GNN의 파라미터는 성능에 크게 영향을 주지 않는다.
LightGCN은 이런 관찰을 통해 NGCF를 다음 방법으로 단순화해 성능을 개선한다.
- 이분 그래프를 위한 인접 행렬 생성
- GCN의 행렬화
- 비선형성을 제거하여 GCN 단순화
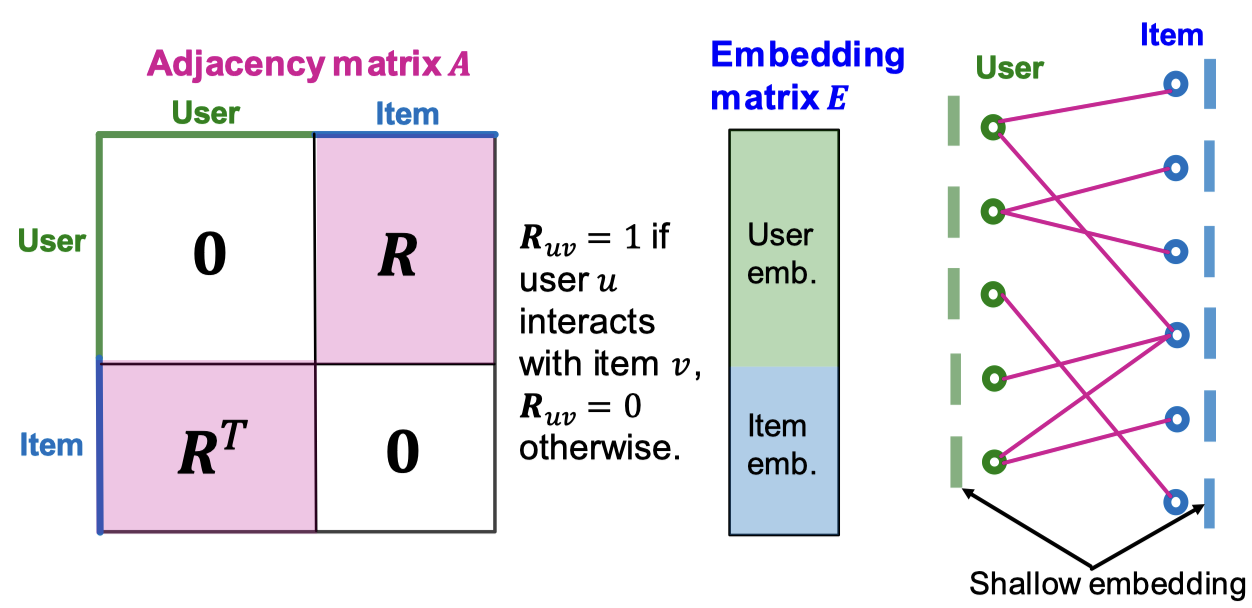
이분 그래프를 새로운 형태의 인접 행렬로 나타내면 다음과 같음. 인접 행렬 의 차원은 사용자의 수, 아이템 수를 합친것과 같음.

GCN을 행렬식으로 바꾸는데, 의 Degree Matrix를 라고 두었을 때, 정규화한 인접 행렬 를 다음과 같이 정의할 수 있다.
번째 레이어의 임베딩 행렬을 라 했을 때, GCN의 Aggregation Layer을 다음 행렬 형태로 쓸 수 있다.

여기서 는 이웃 집계, 는 학습 가능한 선형 변환이다. 이제 여기서 ReLU를 제거해 선형성을 제거하여 GCN을 단순화한다.
마지막 노드 임베딩 행렬은 다음과 같이 정의할 수 있다.
이처럼 ReLU를 제거하면 GCN을 단순하게 만들 수 있다. 식을 살펴보면, Correct&Smooth처럼 노드 임베딩이 그래프 전체로 확산되는 형태이다. 간단하게는 를 번 하는건데 각 행렬곱이 현재 임베딩을 노드의 이웃으로 확산되는 알고리즘이다.
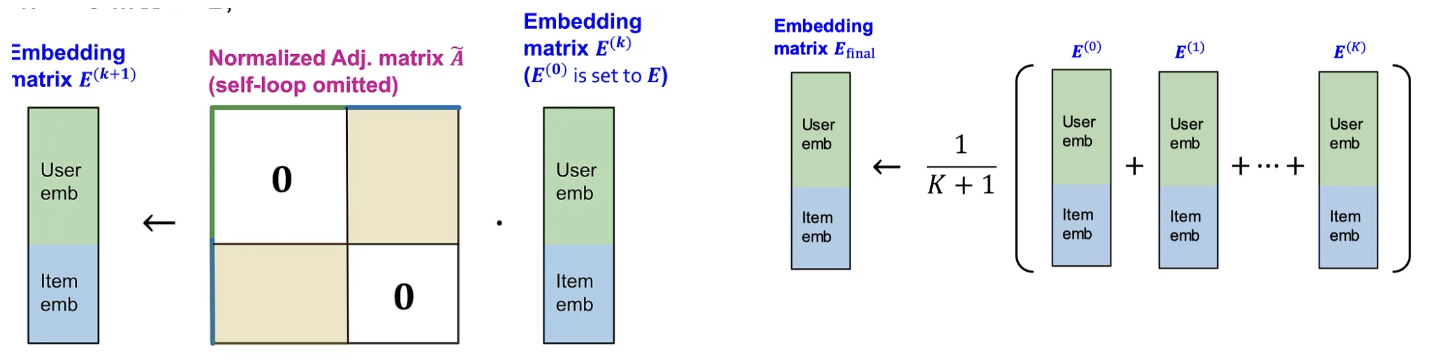
과한 smoothing을 방지하기 위해 다음의 Multi-Scale Diffusion을 고려할 수 있다. 여기서 각 layer의 에 가중치 를 곱해 더하는 것임. 모델의 단순화를 위해 LightGCN에서는 uniform한 를 사용했다.
위 식대로라면 임베딩을 Multi-hop 규모로 확산할 수 있다. 은 일종의 self-connection이고, 는 하이퍼파라미터이다. LightGCN에서는 간단하게 로 사용한다.
이런 간단한 확산 전파(diffusion propagation)이 잘 작동하는 이유는 확산 그 자체로 유사한 사용자/아이템 임베딩이 실제 비슷한 위치에 있도록 만들어져있기 때문임. 유사한 사용자나 아이템은 공통의 이웃을 가지고 있고, 미래에도 비슷한 선호도를 보일 것으로 예상하기 때문이다.
GCN/C&S와의 연관성
LightGCM의 임베딩 전파는 GCN/C&S (Correct and Smooth)와 밀접한 연관이 있다. GCN/C&S의 이웃 집계 부분은 다음과 같다. 다만 일부 차이가 존재한다.
LightGCN에는 self-loop가 포함되지 않고, Multi-scale diffusion에는 self-loop가 포함되어 있다. 또한, 마지막 임베딩에서 모든 레이어의 임베딩 평균을 사용한다.
Matrix Factorization과의 비교
LightGCN과 Shallow Encoder 모두 사용자와 아이템에 대한 고유 임베딩을 학습한다는 공통점이 있다. LightGCN은, 스코어링 과정에서 확산된 사용자/아이템 임베딩을 사용하지만, 행렬 분해는 사용자/아이템 임베딩에 직접 스코어링을 한다. 이로 인해 LightGCN의 성능이 얕은 인코더보다 낫지만 추가적인 확산 계산으로 계산적 비용은 더 높게 된다.
PinSAGE
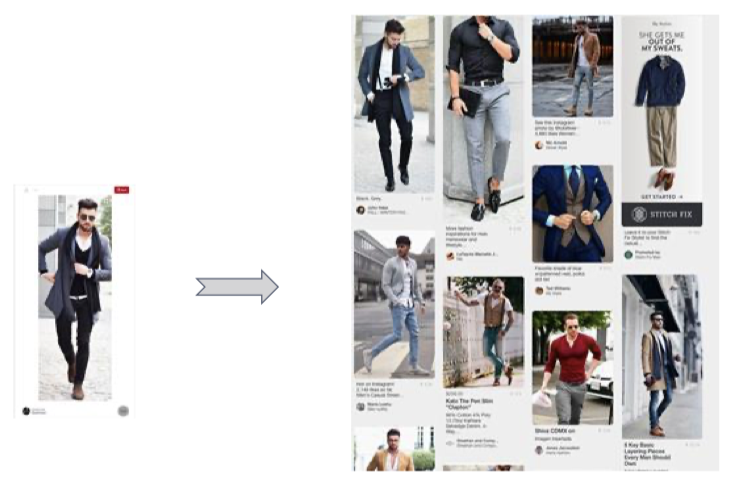
Pinterest에서 개발한 추천 알고리즘, 이미지, 텍스트, 그래프 정보를 모두 통합한 모델이다. GCN을 이용하여 배포된 서비스 중에 업계에서 가장 큰 서비스로 새로운 콘텐츠에 대해서도 잘 작동하고, 핀을 생성하고 몇 초 안에 바로 사용할 수 있다.
PinSAGE의 목표는 수십억 개의 오브젝트가 포함된 대규모의 Pinterest 그래프에서 노드에 대한 임베딩을 생성하는 것이다. 이에 대한 핵심 아이디어는 근처에 있는 노드로부터 정보를 빌려오는 것이다.

정원의 울타리, 침대의 레일을 생각해보자. 이 둘은 비슷하게 생겼지만, 문과 침대는 그래프에서 인접할 확률이 매우 적은 점을 활용하는 것이다. 핀 임베딩은 추천, 분류, 랭킹 등 다양한 태스크에서 매우 중요하게 사용된다.
PinSAGE 논문에서는 수십억 개에 달하는 노드나 엣지를 사용하는 추천 시스템을 사용하기 위해 다음의 기법을 사용했다.
- 미니 배치 내 사용자간 공유되는 Negative sample
- 하드 네거티브 샘플
- 커리큘럼 학습
- 큰 그래프에 대한 미니 배치 GNN 학습
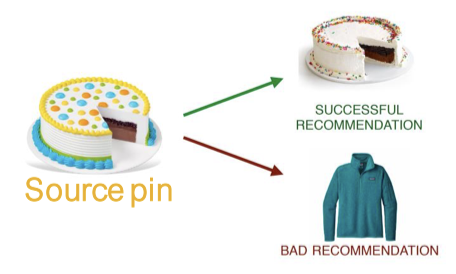
PinSAGE 모델에서 수행하는 태스크를 요약하면, 사용자에게 관련된 핀을 추천해주는데,
과 같은 방식으로 임베딩을 학습한다.
네거티브 샘플 공유
BPR Loss는 미니 배치 내 사용자에 대해 하나의 Positive item과 샘플링한 Negative item 집합을 학습에 사용한다. 여기서 사용자마다 Negative 샘플을 더 추가하면 성능 향상에는 기여할 수 있지만, 그만큼 계산 비용이 높아진다. 그래서 네거티브 샘플을 미니 배치 내 사용자끼리 공유하는 방식으로 위 문제를 해결했다.
기존의 방식대로라면 만큼의 임베딩을 생성해야 하지만, 미니 배치 내 사용자가 네거티브 샘플을 공유하면 생성해야 할 임베딩은 로 줄어든다. 이런 방법을 사용해도 성능 저하는 보이지 않았다.
하드 네거티브, 커리큘럼 학습

실제 서비스에서 사용해야 하는 추천 시스템은 세분화된 예측을 진행해야 한다. 아이템 수는 셀 수 없이 많지만, 사용자에게 추천하는 아이템은 많아야 10~100개이다. 이로 인해 발생할 수 있는 문제는 네거티브 샘플 공유에서 임의로 샘플링을 진행하는 것이다. 이 샘플 중에서 대부분은 크게 Positive 아이템과 크게 구분할 필요 없는 Easy Negative이다. 그래서 모델의 결과를 더 높여줄만한 Hard Negative를 샘플링 해야한다. 아예 관련이 없는 핀을 하드 네거티브 아이템으로 정의한다.
이 과정에서 커리큘럼 학습(Curriculum Learning)을 수행하는데 학습이 진행될수록 더 하드한 샘플을 사용한다. 번째 에포크에서 개의 하드 네거티브 아이템을 추가한다. 그러면 모델은 점점 세분화된 예측을 하는 방법을 학습한다.
각 사용자 노드에 대해 하드 네거티브 아이템은 그래프에서 사용자 노드에 가깝지만, 연결되지 않은 노드이다. 사용자 에 대해 하드 네거티브 아이템은 다음과 같이 얻어진다.
- 사용자 에 대해 개인화된 페이지 랭크(PPR)을 랜덤 샘플링
- 아이템을 PPR 내림차순으로 정렬
- PPR 점수가 적당히 높은 아이템을 랜덤 샘플링
이러한 하드 네거티브 아이템은 공유 네거티브 샘플에 사용된다.

