[Paper Review] VRKG4Rec: Virtual Relational Knowledge Graph for Recommendation
Abstract
추천 시스템에서 지식 그래프를 사용할 때, KG의 관계 유형을 대부분의 연구에서는 독립적으로 사용하고 있습니다. 그렇지만, 그런 경우에는 Relation Type이 너무 많거나, 너무 적은 케이스가 많이 존재합니다. 그 속에서, 잠재적인 관련성이 존재할 수 있기에, 아이템 인코딩에 모든 릴레이션 유형을 고려하는 것이 필요할 것 같습니다.
VRKG는 릴레이션의 잠재적 관련성을 클러스터링하여 가상 관계(Virtual Relation)을 생성하는 모델입니다.
VRKG4Rec 모델은 다음의 과정으로 수행됩니다.
- Unsupervised Learning을 통해 Virtual Relational Knowledge Graphs를 생성합니다.
- 각 VRKG에서 노드 인코딩을 수행하기 위해, Local Weighted Smoothing을 수행하여 노드 임베딩을 반복적으로 업데이트합니다.
- Representation Learning을 통해 사용자 표현 학습을 진행합니다.
Local Weighted Smoothing (LWS) : 국소 가중치 평활화
데이터의 지역적(국소적) 패턴을 강조하면서 평활화(smoothing)하는 기법입니다. 이는 비선형 데이터에서 노이즈를 제거하고, 데이터의 전반적인 추세를 효과적으로 파악하기 위해 주로 사용됩니다.
실험 결과, 위 방법이 기존 최신 추천 모델들의 성능을 앞질렀습니다.
Why?
Relation Type의 이슈 (어느 한쪽에 쏠리거나, 어느 한쪽에만 부족할 수 있음), 잠재적 관계를 발견하지 못할 가능성이 존재합니다.
How to solve?
VRKG를 통해 관계적 지식을 활용해 사용자 표현을 학습하여 잠재적 관계를 파악해나갑니다.
1 Introduction
기존 추천 시스템은 사용자-아이템 간 상호작용 데이터를 바탕으로 Collaborative Filtering에 의존했지만, Sparsity 문제로 인해 골머리를 앓았습니다. 그렇지만, Knowledge Graph의 등장에 따라, 아이템 속성을 더욱 풍부하게 표현하고, Sparsity 문제를 극복했습니다.
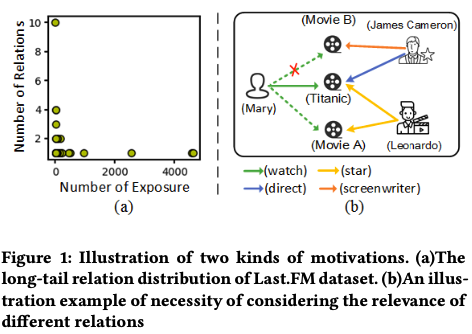
다만, Knowledge Graph를 활용하는 연구는 First-order connectivity (1-hop)에 초점을 맞추고, 전역적인 엔티티 간의 관계를 무시했습니다. 이외에도 Meta path 기반의 방법은 전문가의 지식이 필요하기에, 대규모 지식 그래프에 적용하기 어렵다는 문제가 있습니다. 추가로, Graph Neural Network 기반 방법을 활용하면, 이웃 노드로부터 정보를 집계해 성능을 높이지만, 관계 유형과 데이터 희소성의 문제에서 자유로울 수 없습니다.
이러한 문제점들을 해결하기 위해, VRKG4Rec 모델을 제안했습니다.
VRKG4Rec은 다음의 특징을 가집니다.
- 해당 모델은 KG의 관계를 클러스터링하여 유사한 가상 관계로 통합하기에, long-tail problem을 해결하고, 중요한 관계만 남길 수 있습니다.
- Local Weight Smoothing을 통해 VRKG 내에서 이웃 노드 정보를 연결해 아이템 표현을 학습합니다. 그렇기에, 별도의 추가 파라미터 없이, 노드 임베딩을 반복적으로 업데이트할 수 있습니다.
- 사용자-아이템 이분 그래프(Bipartile Graph)에서도 LWS 매커니즘을 활용해 사용자 표현을 학습합니다.
이러한 과정을 통해, KG relation의 관련성을 효과적으로 반영하고, long-tail problem을 완화했습니다. 추가로, LWS 매커니즘을 통해 이웃 정보를 가중치를 통해 아이템 표현으로 집계했습니다.
그 결과, 기존 최신 방법론보다 우수한 성능을 보였습니다.
2 Problem Formulation
지식 기반 추천 작업은, 사용자와 아이템 간 상호작용 데이터 및 지식 그래프를 입력해, 특정 사용자와 후보 아이템들 간의 유사도 점수를 출력합니다.
총 명의 사용자와 개의 아이템이 있다고 가정한다면, 사용자 집합 와 아이템 집합 이라고 정의합니다. 또한, 는 positive interaction(긍정적 상호작용)의 집합으로 나타냅니다.이전 연구를 참조하면, 상호작용을 관계 로 보고, 사용자-아이템 이분 그래프 를 생성할 수 있습니다.
여기서, 아이템 는 에서 지식 그래프의 엔티티 와 정렬될 수 있습니다.
지식 그래프는 triplet으로 구성되는데, 와 같이 사용합니다.
여기서 는 엔티티 집합, 는 관계 집합을 말합니다.
추천 작업에서는 아이템을 지식 그래프의 엔티티()와 정렬하여 아이템 표현을 지원하기 위한 부가 정보를 활용합니다.
3 The Proposed Model
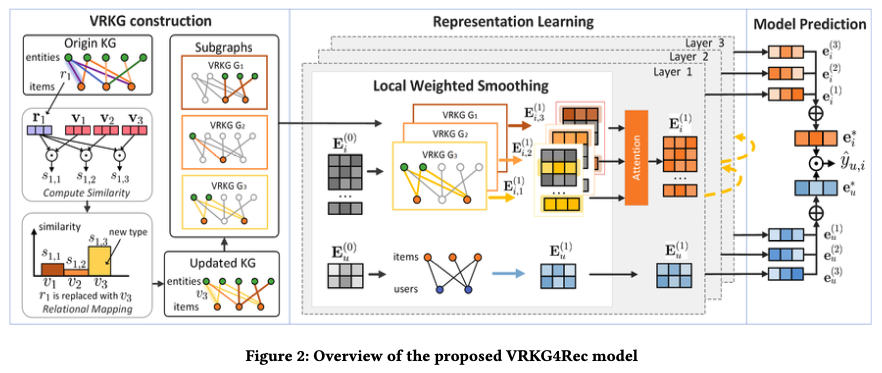
VRKG는 다음의 3가지 과정으로 구성됩니다.
- Virtual Relational Knowledge Graph construction
- Local Weighted Smoothing Aggregation module
- Representation Learning
3.1 VRKG Construction
아이템 인코딩을 위한 관련 관계를 밝히기 위해, 원래 관계를 개의 가상 관계로 클러스터링합니다. 그 다음, 이 관계를 바탕으로 VRKGs를 생성하여 아이템을 다양한 측면에서 표현합니다.
이를 위해서, 각 원래 관계의 잠재 요인을 탐색하고 유사 잠재 요인을 가진 원래 관계를 하나의 가상 관계로 통합하는 Unsupervised Learning 방법을 사용하는데, 먼저 가상 관계의 표현을 가상 중심 벡터 행렬 로 초기화합니다.
여기서 는 번째 가상 관계의 표현을 말합니다. 는 가상 관계의 수이며, 기본 3으로 나타냅니다.
여기에 원래 KG의 관계와 가상 관계 간의 유사도를 계산하는데, 관계 에 대해, 유사도 벡터 는 다음과 같이 구합니다.
여기서, 는 관계 의 임베딩이며, 는 유사도 함수로, inner product를 사용합니다.
다음으로, 는 가장 높은 유사도를 가진 관계 로 대체, 지식 그래프 는 이에 따라 업데이트됩니다.
여기서, 가상 중심 벡터 행렬 는 추천 모델의 파라미터 와 함께 학습되는데, 이러한 공동 학습은 후속 추천 작업에서 더 적합한 가상 관계를 생성하는 것에 도움을 줍니다.
모델 학습 후, 원래 지식 그래프 를 여러 서브그래프로 나누는데, 이 서브그래프를 VRKGs라고 하며, 관계 간의 연결 정보를 캡처하고 아이템 속성의 의미적 독립성을 유지합니다.r VRKGs는 다음의 과정으로 생성됩니다.
3.2 Local Weighted Smoothing
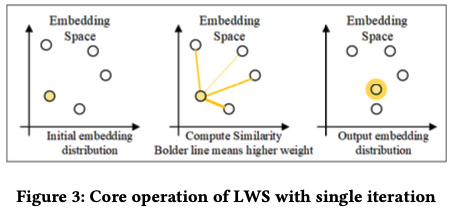
해당 과정에서는 Local Weight Smoothing을 활용해 임베딩 공간에서 유사한 이웃에 더 가깝게 노드 벡터를 반복적으로 업데이트하고, 추천에 가장 적합한 아이템 임베딩을 최적화하는 것을 목표로 합니다.
VRKG 에서 엔티티 의 이웃 노드 집합은 로 정의됩니다. 여기서, 토폴로지 구조를 특성화하기 위해, 로컬 정보 전파를 통해 이웃 노드의 임베딩을 가중치로 평활하는 방식을 제안합니다.
여기서 은 엔티티 의 ID 임베딩, 는 로컬 정보 전파에서 의 가중치를 말합니다. 이는 엔티티 가 엔티티 의 속성을 설명하는데 기여하는 정도를 말합니다. 엔티티가 더 중요할수록, 더 많은 정보가 전파괴고, 임베딩 공간에서 서로 가까워야 합니다. (가) 여기서는 inner product를 사용합니다.
여기서 은 엔티티 의 ID 임베딩을 말합니다.
그 다음, 엔티티 표현 와 로컬 정보 표현 를 집계해 임시 벡터 을 얻습니다.
Aggregator에서 추가적인 학습 파라미터를 도입하지 않고, 단순히 두 표현을 더하는데, 이 단계에서 소프트맥스를 사용해 가중치를 정규화하지 않습니다. 이 방식으로, 각 노드에 고정된 수의 이웃만 샘플링해야 하는 소프트맥스의 한계에서 벗어날 수 있습니다. 이로써, 지식 그래프의 샘플링 손실 없이 모든 정보를 최대한 활용가능합니다. 다만, 정규화를 생략한다면, 벡터의 크기가 커져 비교가 어려워질 수 있기에, 임시 벡터 을 다음과 같이 정규화합니다.
는 벡터 의 2-norm 벡터입니다. 이로써, 벡터의 크기를 0~1의 범위로 정규화하고, 방향과 상대적인 크기를 유지합니다. 전체 집계 함수는 로 표시합니다.
노드 퓨현을 수정하고, 임베딩 공간에서 거리가 유사성을 더 잘 반영하기 위해, 위의 가중치 전파 식을 반복적으로 수행합니다.
여기에서는 Q=3으로 설정하고, 마지막으로 엔티티 의 표현을 다음과 같이 업데이트합니다.
각 단계에서 의 벡터만 평활화하고, 이웃 벡터는 변경하지 않습니다. 그렇기에, VRKG 에서 1차 정보를 노드 임베딩에 통합하는 전체 평활화 작업을 로 나타냅니다.
여기서 은 VRKG 에서 업데이트된 엔티티 의 표현입니다. 이로써, 1차 정보가 아이템 표현에 인코딩되어 임베딩 공간에서 유사 엔티티에 더 가까워지도록 합니다.
3.3 Representation Learning
Item Representation Learning
아이템 속성의 의미적 독립성을 유지하기 위해, 각 VRKG에 LWS를 적용하여 아이템을 여러 관점에서 인코딩한 후, K개의 임베딩을 Attention Machanism을 사용해 융합하여 최종 아이템 표현 을 얻습니다.
여기서 는 지식 그래프에서 1차 연결성 정보를 수집한 표현이고, 는 VRKG 에서 학습된 표현의 가중치를 말합니다. 이는 아이템 인코딩에서 가상 관계의 중요도를 말하고, 학습 과정에서 학습됩니다.
더 높은 차수의 이웃을 포함하기 위해, 더 많은 LWS 집계 layer을 쌓습니다. layer 후 엔티티 의 표현을 다음 식으로 공식화합니다.
여기서 은 의 표현이며, 이웃으로부터의 정보를 포함합니다. 실험에서는 으로 설정합니다.
User Representation Learning
사용자 표현을 얻기 위해, 사용자-아이템 상호작용 데이터를 기반으로 사용자-아이템 이분 그래프 를 생성합니다. 구체적으로는 일 때만 사용자 , 아이템 간 에싲가 존재합니다.
다음으로, 과거 상호작용 정보를 확인하고 인식하기 위해, 에서 LWS를 적용하여 사용자 표현에 historical interactions를 불균등하게 인코딩합니다.
여기서 는 사용자 가 상호작용한 아이템 집합을 말합니다. 는 각각 사용자 , 아이템 의 ID 임베딩을 말합니다. 아이템 는 지식 그래프 와 이분 그래프 모두에 나타나는 노드로, 두 그래프를 연결하는 다리 역할입니다.
이 연결을 통해 두 그래프 사이에 정보가 원활히 전달되며, 정보를 병렬로 전파해 사용자, 아이템 표현을 동시에 학습합니다. 여러 LWS layer을 쌓음으로써, 추천 성능을 향상시킵니다.
3.4 Prediction
개의 LWS layer을 쌓은 후, 각 layer에서 각 계층에서 사용자, 아이템 의 표현을 얻는데, 각 출력 임베딩은 서로 다른 hop의 이웃에 초점을 맞추기에, 각 계층의 output을 합산해 최종 표현을 생성합니다.
최종적으로, Inner product similarity를 사용해 예측을 수행하니다.
3.5 Optimization
모델을 학습하기 위해, BPR Loss를 사용합니다.
BPR Loss (Bayesian Personalized Ranking)
여기서 는 학습 데이터셋입니다. 는 사용자-아이템 간의 긍정적 상호작용 쌍을 나타내며, 는 한번도 상호작용하지 않은 아이템 에서 무작위로 샘플링된 부정적 쌍입니다. 는 시그모이드를 나타냅니다.
모델 매파라미터를 학습하기 위한 최적화 함수는 다음과 같습니다.
여기서 는 모델 파라미터 집합을 말하고, 는 아이템 집합 를 포함하는 엔티티 집합이며, 입니다. 또한, 는 과적합을 방지하기 위한 정규화 하이퍼파라미터입니다.
4 Experiments
4가지 질문에 대한 검증을 진행합니다.
- RQ1: VRKG4Rec은 최신 KG 기반 접근법들과 비교했을 때 더 나은 성능을 보이는가?
- RQ2: VRKG 생성을 포함한 핵심 구성 요소가 모델 성능에 어떤 기여를 하는가?
- RQ3: 하이퍼파라미터가 모델 성능에 어떤 영향을 미치는가?
- RQ4: VRKG4Rec은 사용자 선호도를 어떻게 탐구하며 직관적인 설명 가능성을 제공하는가?
실험 데이터셋은 다음 2가지를 사용합니다.
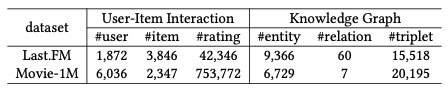
- Last.FM : 2000여명의 사용자가 음악을들은 기록으로 구성된 데이터셋
- MovieLens-1M : 100만여개 영화 평점 데이터로 구성된 추천 데이터셋
비교한 모델은 다음과 같습니다.
- FM : 아이템, 지식 그래프의 2차 상호작용 행렬 분해 모델
- NFM : FM을 개선한 신경망 기반의 행렬 분해 모델
- CKE : 지식 그래프의 임베딩을 활용한 협업 필터링 모델
- KGAT : 지식 그래프의 고차 연결성을 모델링
- KGIN : 지식 그래프를 활용해 사용자-아이템 상호작용 탐색
평가 기준은 Recall, NDCG, Precision, HR을 사용합니다. 그리고, 추천의 개수는 20개로 선택합니다.
RQ1: VRKG4Rec은 최신 KG 기반 접근법들과 비교했을 때 더 나은 성능을 보이는가?
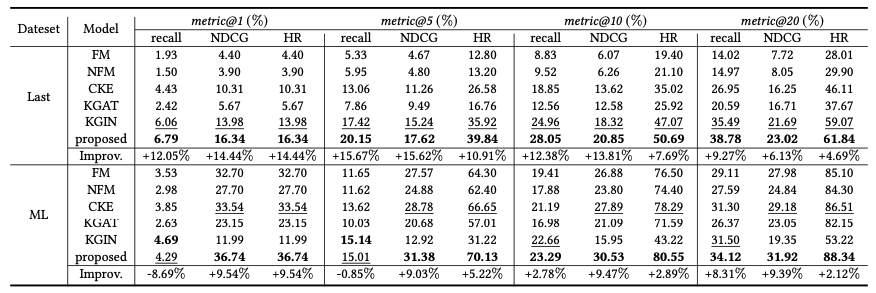
- VRKG4Rec 모델은 두 데이터 셋 모두에서 기존 모델들의 성과를 능가했습니다.
RQ2: VRKG 생성을 포함한 핵심 구성 요소가 모델 성능에 어떤 기여를 하는가?
- Case 1 : VRKG를 생성하지 않고, 모든 관계를 동일하게 처리
- 관계 정보를 무시하기에, 성능이 저하되었습니다.
- Case 2 : Virtual Relational Custering을 생략하고 각 원본 관계를 별도로 처리
- 일부 관계가 비효율적이거나, 노이즈를 유발해 성능이 감소한 것을 확인했습니다.
→ Virtual Relation의 개수가 3일 때 가장 성능이 좋았으며, 관계 유형이 많을수록, VRKG의 효과가 커집니다.
RQ3: 하이퍼파라미터가 모델 성능에 어떤 영향을 미치는가?
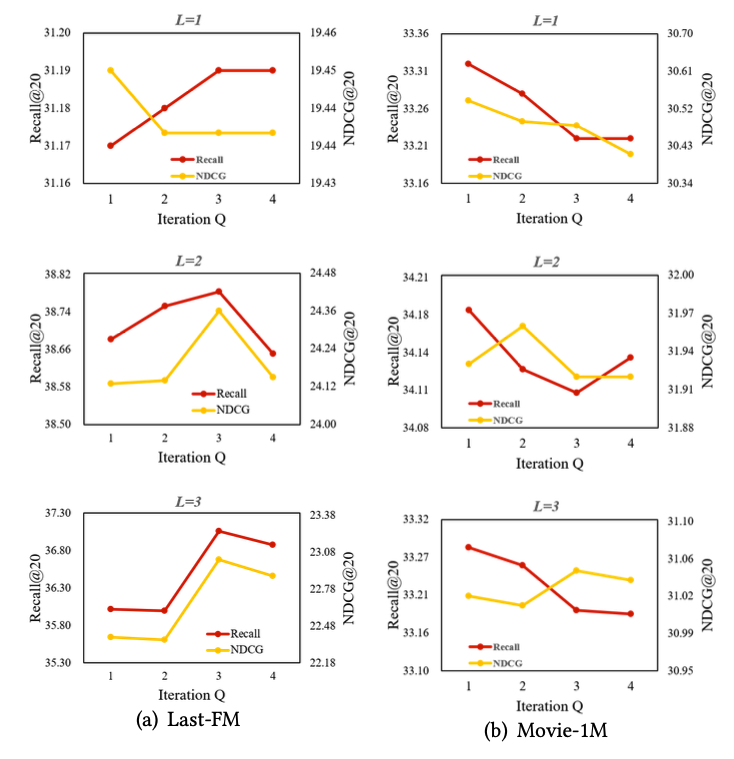
- 반복 횟수에 따른 차이(Iteration Q) : 반복 횟수가 증가할 수록 성능이 향상하지만, 필요 이상으로 커지면 노드 간 임베딩이 과도하게 가까워져 성능이 저하됩니다.
- GNN layer 수에 따른 차이 (L) : layer 수가 증가하면 더 많은 차수의 연결 정보를 학습하지만, 너무 많다면, 노이즈가 포함될 가능성이 있어 성능이 저하합니다.
RQ4: VRKG4Rec은 사용자 선호도를 어떻게 탐구하며 직관적인 설명 가능성을 제공하는가?
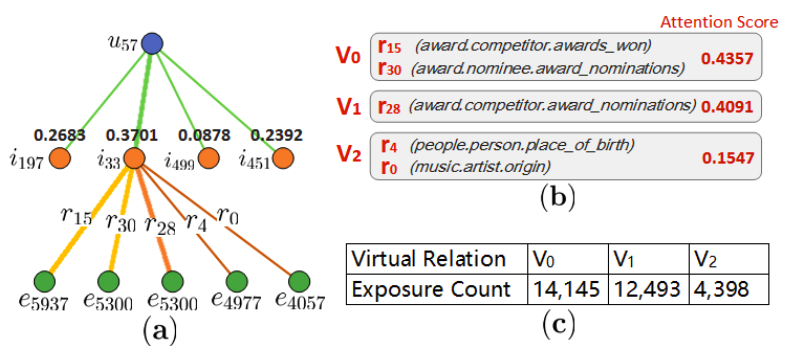
특정 사용자, 특정 아이템을 대상으로 Virtual Relation의 중요성과 노출 횟수를 비교한 결과는 다음과 같습니다.
특정 Virtual Relation이 사용자 선호를 더 잘 반영하고, long-tail problem 문제를 완화했습니다. 그리고, 사용자는 2개의 Virtual Relation에 대해 다른 관심도를 보였습니다.
5 Related Work
임베딩 기반 방법의 경우, KG 내의 사실을 부가 정보로 활용하지만, 1차 연결성(1-hop)에 초점을 맞추고, 엔티티 간의 전역 관계를 간과하는 케이스가 많았습니다.
경로 기반 방법의 경우는 2가지 주요 문제점이 존재합니다.
- 전문적인 지식, transfer ability(전이 능력)이 필요합니다.
- 대규모 KG를 사용할 경우, 인력과 시간 소모가 큽니다.
이러한 방법을 해결할 수 있어야 합니다.
GNN 기반의 방법은 이웃 노드의 정보를 집계해 중심 노드의 표현을 업데이트하는 방법으로 진행되어 왔습니다.
여러 연구들에서 해당 연구들을 사용해왔습니다.
6 Conclusion
해당 연구에서는 지식 그래프 기반의 추천 시스템 성능을 향상시키기 위한 Virtua Relational Knowledge Graph와 LWS를 포함한 VRKG4Rec를 제안했습니다.
해당 연구는 가상 관계로 클러스터링하여 long-tail problem을 개선하고 추천에 유용한 정보를 포함했으며, 별도의 학습 파라미터를 추가로 설정하지 않아도 이웃 관계 정보를 아이템 표현에 통합할 수 있었습니다.
이제는 VRKG 생성에 있어, 최적의 Unsupervised Learning 방식을 탐구하여 VRKG4Rec을 발전시키는 것이 과제입니다.
