그래프
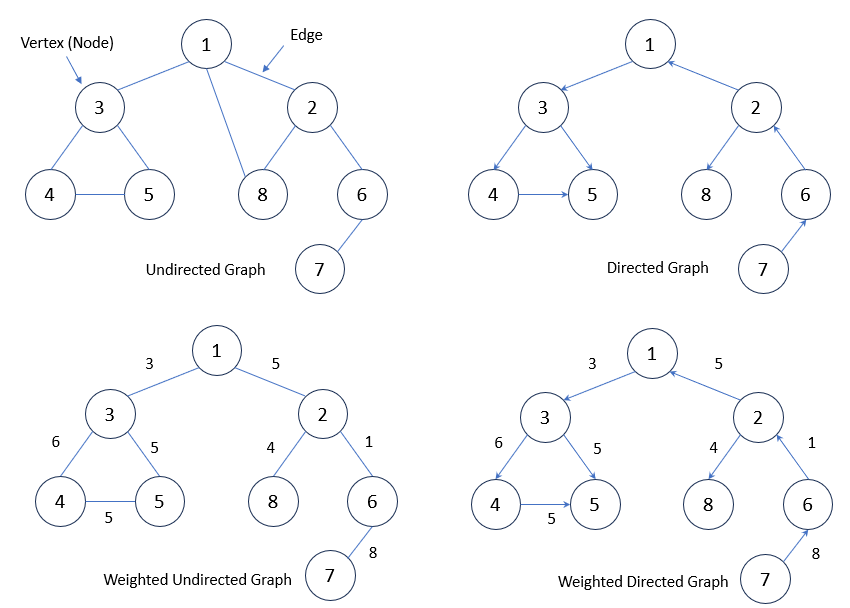
그래프는 점들과 그 점들을 잇는 선으로 이루어진 데이터 구조
관계나 상호작용을 나타내는 데이터를 분석할 때 주로 사용됨.
그래프의 정의
로 정의됨.
- (Vertex) : 점의 집합
- (Edge) : 두 점을 잇는 선의 집합
그래프는 주로 인접 행렬(Adjacement Matrix)로 표현되는데, 점의 개수가 n개일 때, Adjacement Matrix의 크기는 이다.
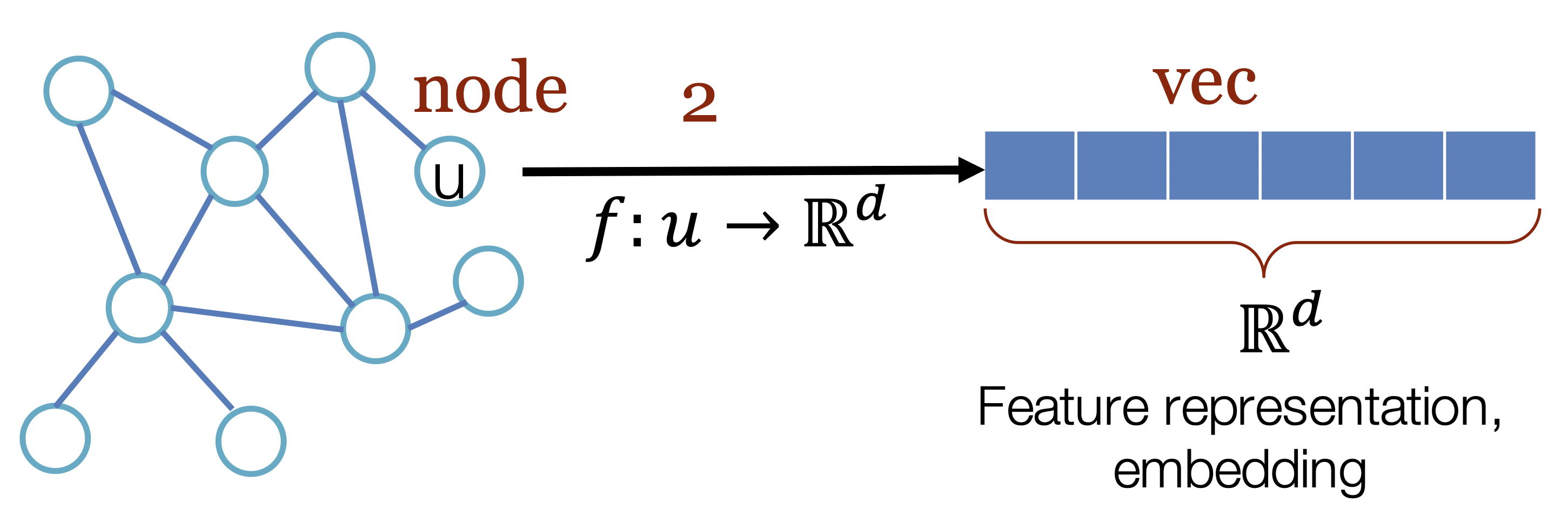
ML에서 그래프를 다룰 때에는 점들의 특징을 묘사한 Feature Matrix로 표현하는데, feature의 개수가 일 때, feature matrix의 차원은 이다.
그래프를 분석하기 어려운 이유
-
그래프는 텍스트, 이미지와 다르게 유클리드 공간에 존재하지 않는다.
익숙한 좌표로 표현할 수 없다.
-
그래프는 고정된 형태가 아닌, 계속해서 변화한다.
-
그래프는 사람이 해석할 수 있도록 시각화하는 것이 어렵다.
그래프를 다루는 이유
- 관계나 상호작용과 같은 추상적인 개념을 다루기에 적합하다.
- 복잡한 문제를 더 간단한 표현으로 단순화하기도 하고, 다른 관점으로 표현해 해결할 수 있다.
- 소셜 네트워크, 미디어의 영향 등을 연구하고 모델링할 때 사용가능하다.
기존 그래프 분석 방법
- 검색 알고리즘 (BFS, DFS)
- 최단 경로 알고리즘 (다익스트라, A* 알고리즘)
- 신장 트리 알고리즘 (Prim, Kruskal)
- 클러스터링 (연결 성분, 클러스터링 계수)
→ 입력 그래프에 대한 사전지식이 필요하다는 한계점이 존재하기에, 그래프 자체에 연구하는 것이 불가능함.
머신러닝에서는 어떻게 그래프를 다뤘을까?
- 기존의 머신러닝 기법들에서는 그래프를 각각 도메인, task에 맞게 feature-engineering해서 노드, 링크, 그래프 레벨의 변수를 생성했다.
- 그리고 이렇게 만들어진 변수들로 각 태스크와 도메인에 맞게 모델을 정하고 튜닝을 진행했는데, 여러 단계를 거쳐갔다…
→ 무언가 좀 더 효율적인 방법이 필요하지 않을까?
Graph Neural Network
- 점, 선, 면 레벨에서 예측 작업에 쓰임
발표된 논문을 보면
- Recurrent Graph Neural Network
- Spatial Convolutional Network
- Spectral Convolutional Network
로 나뉜다.
GNN의 핵심은 점이 이웃과의 연결에 의해 정의된다는 것이다. 만약 특정 점의 이웃과 연결이 끊기면, 그 점은 아무 의미를 가지지 않는다.
GNN은 주로 연결관계와 이웃들의 상태를 이용해 각 점의 상태를 업데이트(Train)하고, 마지막 State를 통해 예측하는 과정을 수행한다.
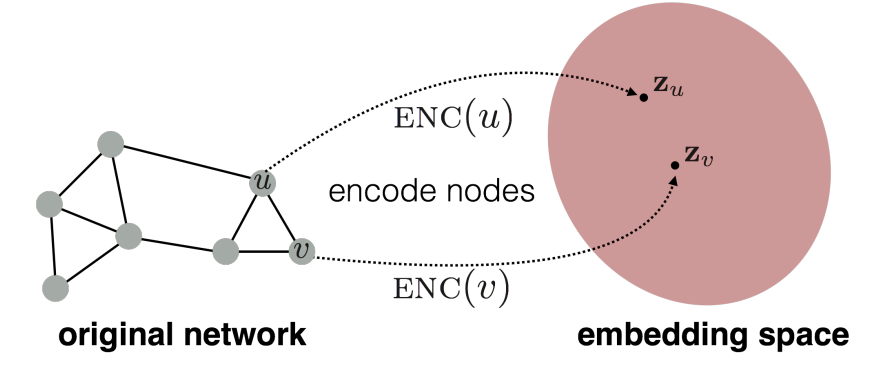
노드 사이의 관계를 모델링하고, 그에 대한 Representation 생성
마지막 상태를 “node embedding”이라고 부른다.
이웃 노드들 간의 정보를 이용해 특정 노드를 잘 포현할 수 있는 특징(벡터)를 잘 찾아내는 것이 GNN의 목표
→ 노드 상태를 사용해 출력, 즉 개념에 대한 결정을 생성할 수 있음.
→ 모든 GNN Task는 인접 노드에 대한 정보를 보고, 각 노드의 Node Embedding을 결정하는 것이다.
💡 Node Embedding
- 그래프의 노드(Vertices)를 저차원의 벡터로 표현하는 과정
- 노드 간의 구조적 관계, 의미적 정보를 내포하고, 노드 간의 유사성, 관계를 반영해 그래프의 다양한 작업에 사용한다.
- Node Embedding을 사용하는 이유
- 차원의 저주 문제 완화
- 노드 간 유사성 표현 : 노드 간의 연결성, 공통 이웃, 전역적인 그래프 구조를 임베딩 벡터에 반영해 노드의 유사성을 효과적으로 학습
.3. 머신러닝 적용 용이성 : 벡터화된 데이터는 일반적인 머신러닝 알고리즘에서 쉽게 처리 가능하기에, 그래프 기반의 문제를 쉽게 다룰 수 있음.
노드 임베딩에 대한 자세한 설명은 다음 페이지에서 확인하자.
https://velog.io/@oneman98/Node-Embedding#trade-off-of-bfs-dfs
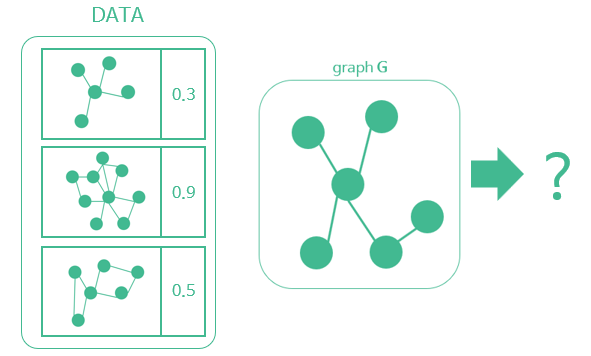
다음의 예시를 생각해보자
SNS 사용자의 네트워크 관계가 그래프로 주어질 때 해당 유저의 영향력 예측하기
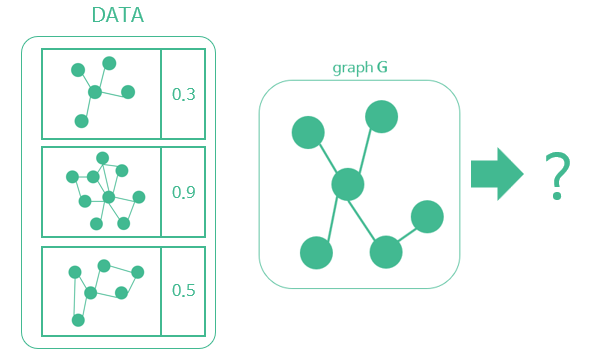
이를 수행하기 위해서는 임의의 구조 그래프 G가 들어왔을 때, 이를 하나의 0~1사이의 Representation으로 표현해야 한다.
즉, F(G) = embedding으로 변환할 수 있는 함수 F를 찾는 것이 목표
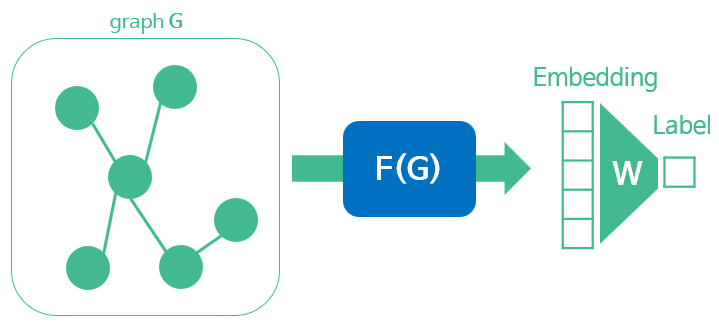
그래프를 임베딩할 수 있는 모델은 대표적으로 RNN이 있으며, 이는 체인으로 연결된 구조 데이터에 사용할 수 있는 특별한 구조로, 이전 타임의 hidden과 현재 타임의 input을 결합하여 현재의 hidden representation을 생성한다.
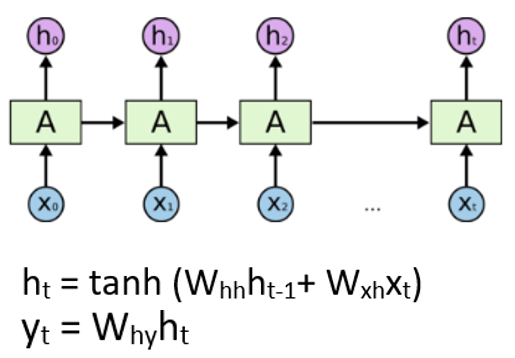
이 과정에서 RNN을 이용한 Graph Neural Network를 위해 생각해야 할 것은 2가지
- 각각의 노드 Embedding하기
- 노드 하나하나는 RNN의 Unit으로 사용된다.
- 해당 예시에서는 사용자의 나이, 성별, 활동 기간 등의 설명 변수를 벡터로 만들어 임베딩할 수 있다.
- 엣지 타입에 따른 Neural Network 정의하기
- 그래프에서는 다양한 엣지 타입이 있을 수 있는데, 종류에 따라 네트워크를 다르게 구성한다.
- 친구, Follow가 있다면, 이 둘은 서로 다른 가중치를 사용하는 네트워크로 표현한다.
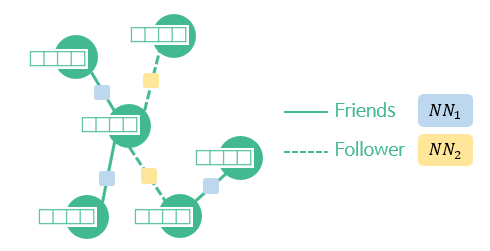
→ 이제 각 노드를 recurrent unit으로 생각한다면, 각 노드는 가장 인접한 노드를 (t-1) 시점으로 보고, recurrent unit을 사용해 새로운 hidden을 생성할 수 있다.
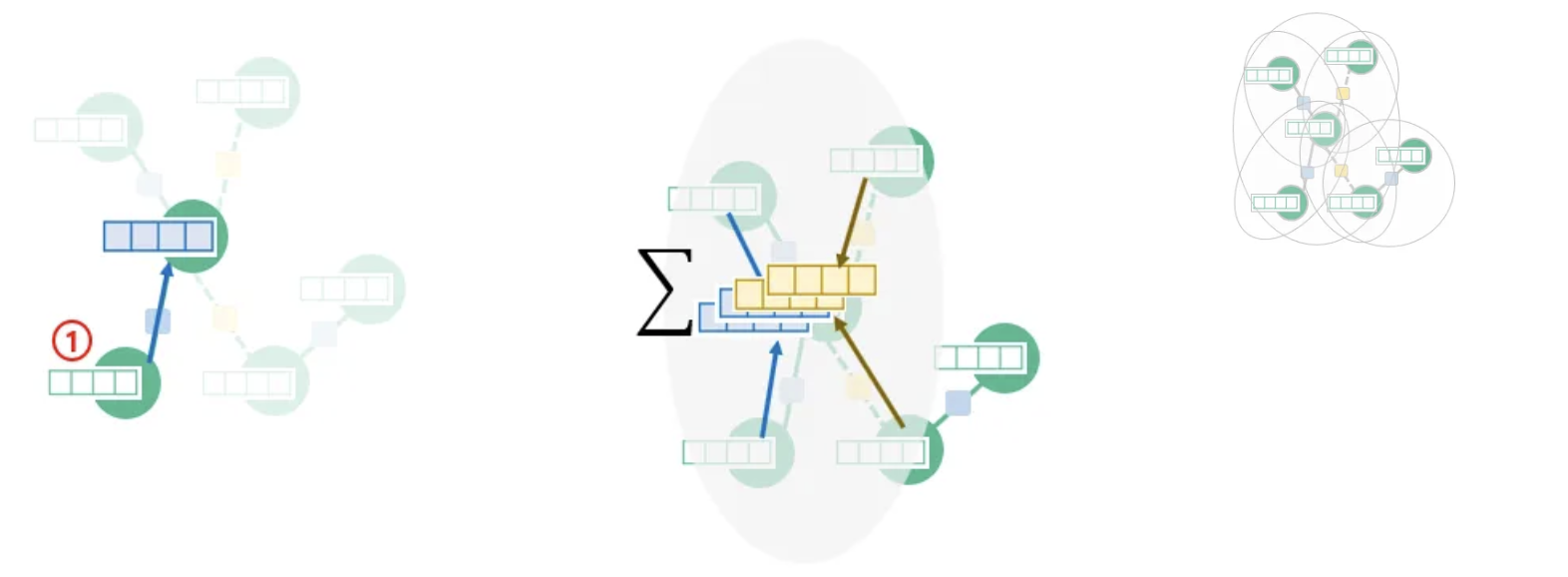
위 이미지처럼, 가운데 노드에 대해 가장 인접한 노드 ①에서 사용해 정보를 결합, 새로운 representation(파란색 블록으로 표시)을 생성할 수 있음.
같은 방식으로 가장 인접한 4개의 노드에 대해 RNN을 적용하면 4개의 Hidden을 얻게 된다. 노드 사이의 순서를 고려하지 않는다면, 4개의 Hidden을 합해 가운데 노드에 대한 새로운 representation을 생성한다. 이렇게 생성된 representation은 한단계 인접해 있는 노드의 정보를 포함한 representation이 된다.
위와 같이, 모든 노드에 대해 한 단계 인접한 노드와 RNN으로 정보를 결합한다면, 이제 모든 노드는 각자의 인접한 노드를 알고 있는 representation을 가지게 된다.
그래프에 대한 최종 임베딩은 업데이트된 representation을 합해 생성할 수 있고, 이 경우에도 노드의 순서 정보는 고려되지 않는다.
→ 이를 순열 불변성(permutation invariant)라고 한다.
- 같은 구조의 그래프라면, 그래프 표현의 관점에서 무조건 같은 결과가 나와야함.
이러한 과정으로 GNN은 다음의 문제를 해결할 수 있다.
- Node Classification (노드 임베딩을 통해 점들을 분류하는 문제)
- 그래프의 일부만 레이블된 상황에서 semi-supervised learning을 사용
- ex) Reddit 게시물, Youtube 동영상
- Link Prediction (그래프의 두 점 사이에 얼마나 연관성이 있을지 예측하는 문제)
- ex) 페이스북 친구 추천, OTT 영상 추천
- 이 과정에서는 영화와 유저가 점이고, 유저가 영화를 봤으면 선으로 연결
- Community detection (밀집되어 연결된 노드의 클러스터 식별)
- Network similarity (두개의 sub-network들이 얼마나 비슷할지)
GNN에서의 학습
GNN에서 결과물로 나온 , 임베딩 벡터를 학습하기 위해서는 손실함수를 정의하고 최적화를 진행해야 한다. 학습과정은 Supervised, Unsupervised 모두 사용가능하다.
- 비지도 학습
- : 손실 함수
- CE : Cross Entropy
- DEC : Decoder
- : 에 대해 합산을 나타냄
비지도 학습에서의 손실함수는 위와 같으며, 유사도는 랜덤워크 등의 방법이 사용되고, 디코더는 내적(inner product)가 사용된다.
는 노드가 유사할 경우 1, 그렇지 않으면 0을 나타내는데, 디코더 또한 유사한 경우 1, 그렇지 않으면 0을 게산하도록 파라미터가 최적화된다.
- 지도 학습
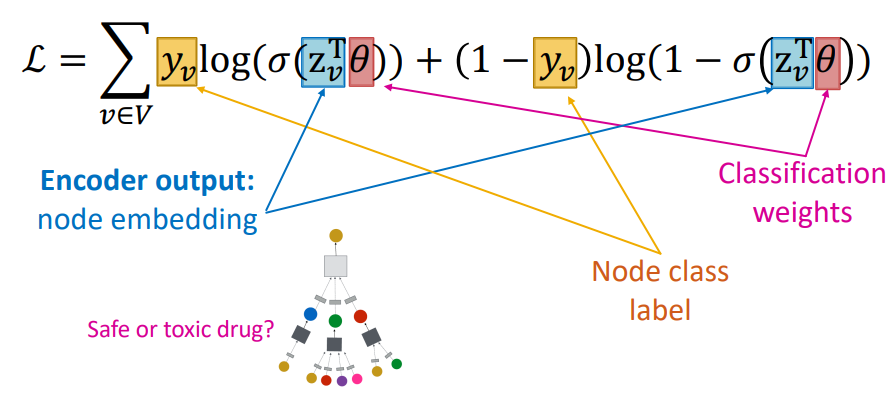
- : 손실 함수, 그래프의 모든 노드 v∈V에 대한 손실의 합으로 정의됨.
- :
- : 노드 v의 Embedding Vector (Encoder)
- : classification weight
- : 노드 임베딩, 분류 가중치의 내적
- : 시그모이드 함수로 이진 분류 확률 계산
- : 노드 v의 실제 클래스 레이블 (0 or 1)
- loss 항목
- : 레이블이 1일 때 손실
- : 레이블이 0일 때 손실
Model Design
전체적인 GNN 요약하면 크게 4가지 정보로 설명할 수 있다.
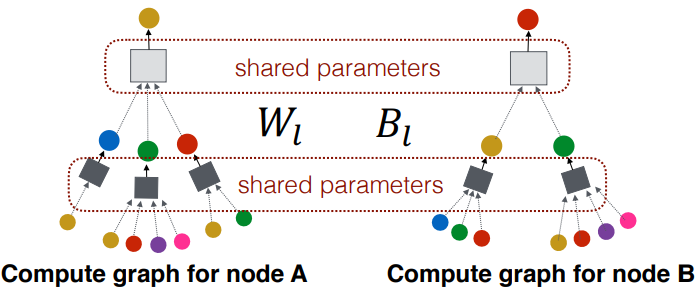
- Neighborhood Aggregation Funtion 정의 (이웃 집계 함수)
- 각 노드가 이웃 노드의 정보를 집계하여 임베딩으로 업데이트
- 그래프 구조를 활용해 정보 전달 수행
- Embedding에 대한 Loss Function 정의
- 학습 목표를 정의하기 위해 노드 임베딩에 대한 손실함수 정의
- Cross Entropy나 유사한 손실 함수 사용
- 노드 집합(배치)에서 학습
- 한 번에 일부 노드에 대해 계산 그래프를 생성하고 이를 학습
- 효율성을 위해 미니배치 방식으로 처리
- 필요할 때 노드 임베딩 생성
- 학습된 모델을 사용해 필요할 때 각 노드의 임베딩 생성
- 생성된 임베딩은 Downstream task에 사용
→ GNN에서는 모든 계산 그래프에서 구조에 상관 없이 파라미터가 공유된다. 이는 학습에 사용되지 않았던 노드들을 추가학습 없이 임베딩 벡터를 효과적으로 생성할 수 있는 능력을 GNN 모델이 갖추었다 할 수 있다.
즉, 하나의 그래프에 대해 학습을 진행하면, 새로운 그래프에 대해서도 일반화할 수 있다.
Graph Convolutional Network
GCN은 그래프에서 CNN에서처럼 커널 또는 필터를 이용해 convolution 연산을 수행하면서 그래프의 내재된 정보를 학습하는 모델이다.
해당 모델의 기본 아이디어는 노드의 이웃이 연산 그래프를 정의하는 것이다.
이미지를 인접한 픽셀끼리 연결된 그래프라고 생각하면, CNN에서 커널을 이동해가며 학습하는 것도 graph convolution의 일종으로 볼 수 있다.
CNN에서 사용하는 이미지 데이터는 픽셀의 위치와 다른 픽셀 간의 거리가 중요해서 locality를 학습하지만, 그래프는 non-euclidean 공간에 존재하므로 거리가 아닌 관계 그 자체가 중요하고, 정점 간의 연결 강도가 어느정도인지 학습하는 것이 중요하다.
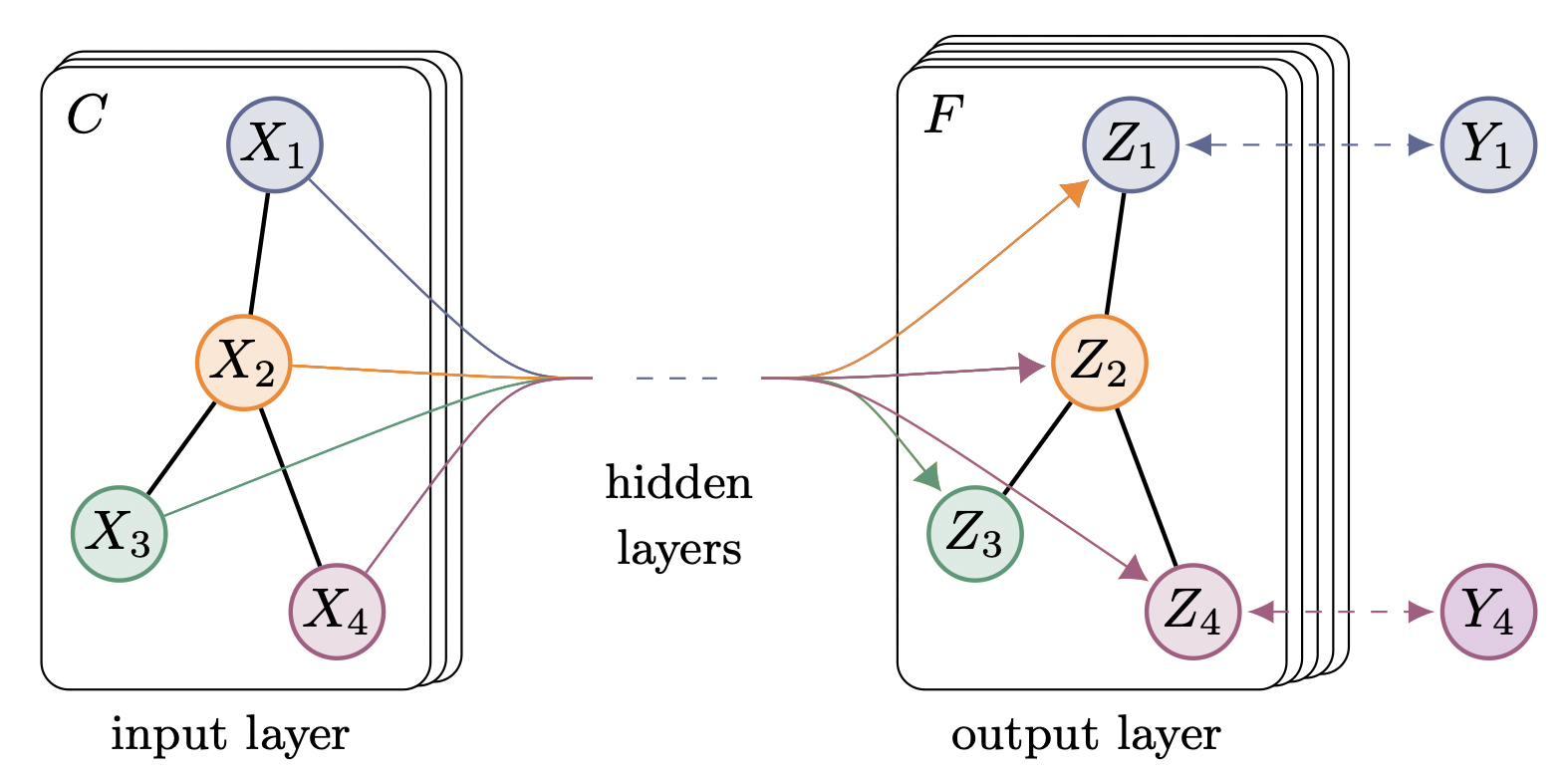
단, GCN은 완전한 Spatial이 아닌, Spectral → Spatial 방법론으로 연결해주는 방법에 속한다.
Spatial 도메인의 Convolution 연산이 Fourier 도메인에서 곱과 같다는 성질을 이용해 인접 정점으로부터 Convolution 연산을 사용하기 때문이다.
GCN에서 순전파의 과정
- 각 노드 별 계산 그래프 생성
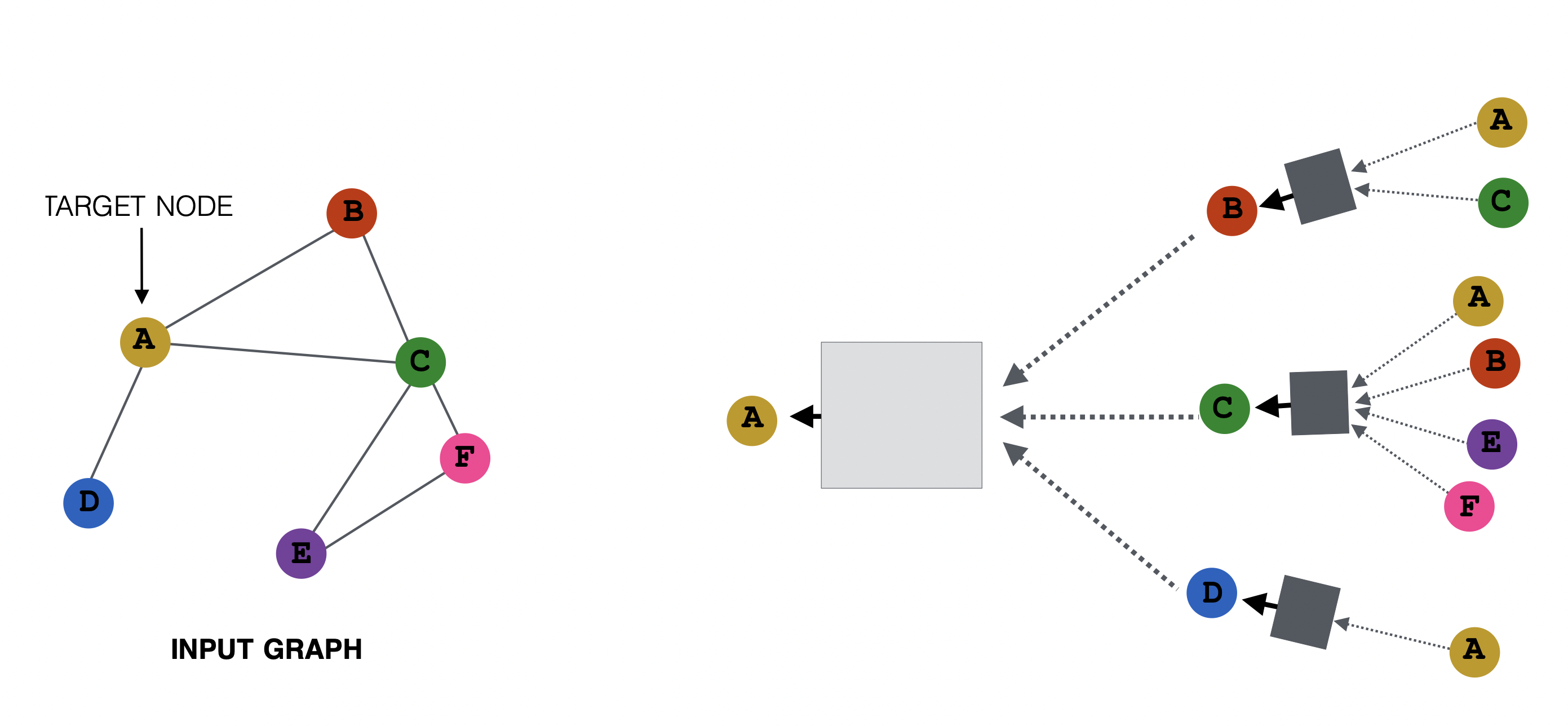
타겟 노드 A에서 이웃 노드인 B, C, D로부터 정보를 받고, 이웃 노드인 B, C, D는 이어서 그들의 이웃 노드로부터 정보를 받는다.
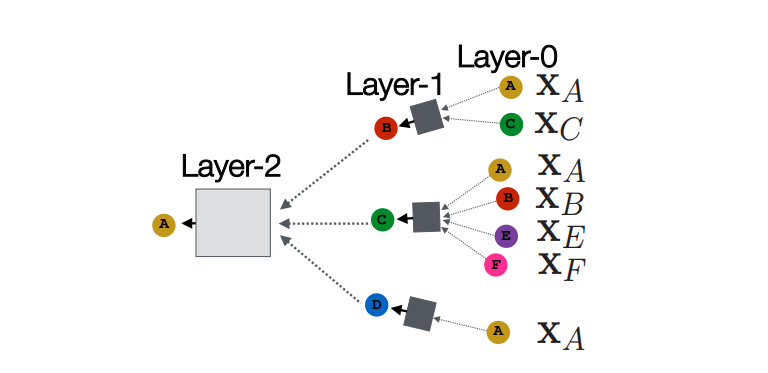
- 순전파 (Neighborhood Aggregation)
각 레이어는 평균/합을 통해 이웃 노드들의 정보를 모은다.
첫번째 hidden layer의 입력값은 각 노드의 변수벡터 혹은 임베딩이고, 두번째 hidden layer부터 마지막 층까지는 각 레이어의 이웃노드의 벡터와 평균의 이전 레이어에 해당하는 노드()를 선형 변환한 것을 결합해 활성화 함수를 통과한 값이다.
파라미터 변수는 다음과 같다.
- : 0번째 레이어의 임베딩은 노드 피처의 같은 값으로 초기화함
- : Relu와 같은 비선형 활성함수 사용
- : 이웃 노드의 이전 레이어 임베딩 평균
- : l번째 레이어에서의 노드 v 임베딩
- : 전체 레이어 수
- : l번째 레이어에서의 이웃 집계 후 임베딩x
- : 레이어의 가중치 행렬
- : 레이어 의 바이어스 벡터, 각 노드의 이전 상태 정보를 유지하는 정도. 노드의 이전 특징 벡터 에 추가적인 조정을 가하기 위해 사용.
위 식에서 합 연산은 모두 순열 불변셩을 갖는 풀링이나 집계방식임.
→ 파라미터는 이 전부, 모든 계산 그래프는 동일한 가중치를 가진다.
- Matrix Formulation
연산을 행렬 단위로 계산한다면, 효율적인 계산이 가능하다.
(1) : l번째 레이어의 모든 노드들의 벡터를 concat해서 표현할 수 있다.
(2) 와 인접행렬의 연산은 모두 이웃 노드 벡터들의 합이 된다.
(3) : D는 대각행렬이고, 각 대각 성분 v노드의 이웃노드의 수를 갖는다고 하면, 대각행렬 D의 역행렬은 v노드의 이웃노드 수의 역수가 된다.
→ 가 됨.
그리고 이 식을 정리하자면,
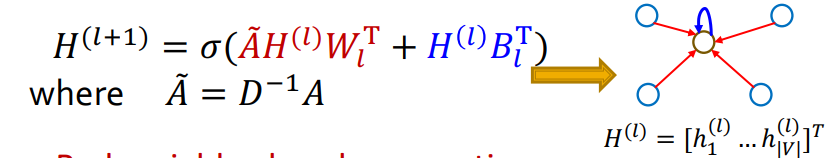
가 된다.
GNN vs CNN
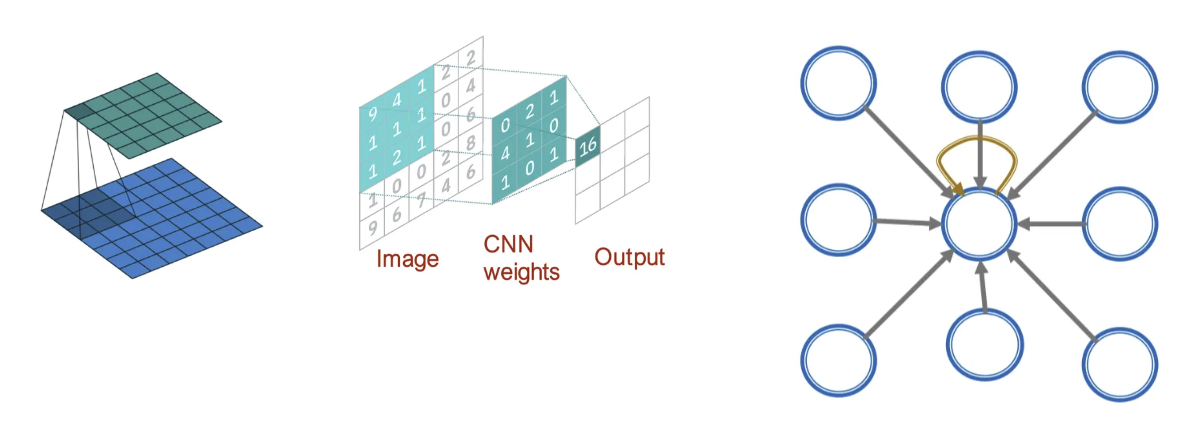
GNN과 CNN의 차이점은 이미지 픽셀 v가 주어졌을 때, 서로 다른 이웃 u에 대해 서로 다른 를 학습할 수 있다는 점이다. 중앙 픽셀에 대한 상대 위치를 사용해 9개 이웃에 대한 순서를 마음대로 고려할 수 있음.
- CNN은 고정된 이웃 크기와 순서를 가진 특수한 GNN이다.
- 필터의 크기는 CNN에 의해 미리 정의된다
- GNN은 각 노드마다 다른 Degree를 가진 임의의 그래프를 처리한다는 장점이 있다.
- CNN은 순열 불변하거나 순열 등변하지 않는다.
- 픽셀의 순서를 바꾸면 다른 결과를 반환한다.
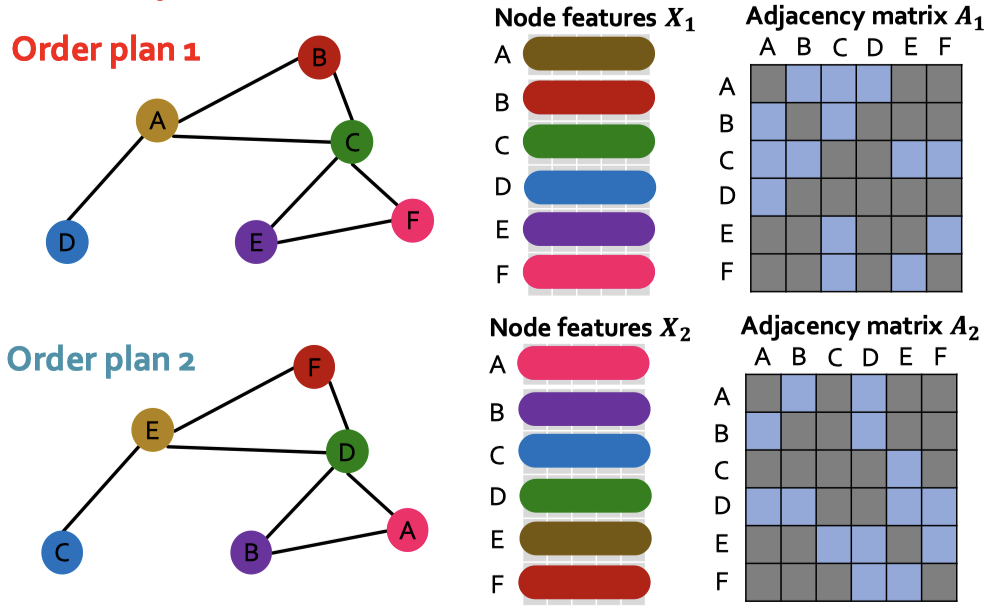
💡 순열 불변성 (Permutation Invariance)
- 노드의 이름만 바뀐 경우라면 그래프에 대한 표현과 노드에 대한 표현은 항상 같아야 함.
- 모든 순서 i, j에 대해 다음의 공식 만족
- GNN에서의 순열 불변성 구현
- 집계 함수 : 합, 평균, 최대값 등 순서에 의존하지 않는 연산 사용
- 그래프 수준의 임베딩에서 순열 불변성 보장
- 위의 식을 같은 말로 바꾸면
- 에 대해 임의의 순열 를 적용한 에 대해
💡 순열 등변성 (Permutation Equivariance)
- 입력 데이터의 순서가 바뀌면 모델 출력도 이에 맞게 동일한 방식으로 순열 적용
- 노드 수준의 출력을 생성하는 작업에서 요구
- 노드 A, B, C의 출력이 [a, b, c]라면, 순서가 B, C, A로 바뀌면 출력도 [b, c, a]로 바껴야 함.
- 에 대해 임의의 순열 를 적용한 에 대해
- GNN에서 순열 등변성 구현
- 메시지 패싱과정에서, 각 노드의 임베딩은 이웃 노드의 순서가 아닌, 그래프 구조에 따라 결정됨
- 노드 수준의 임베딩(각 노드를 하나의 벡터로 표현)에서 순열 등변성 보장
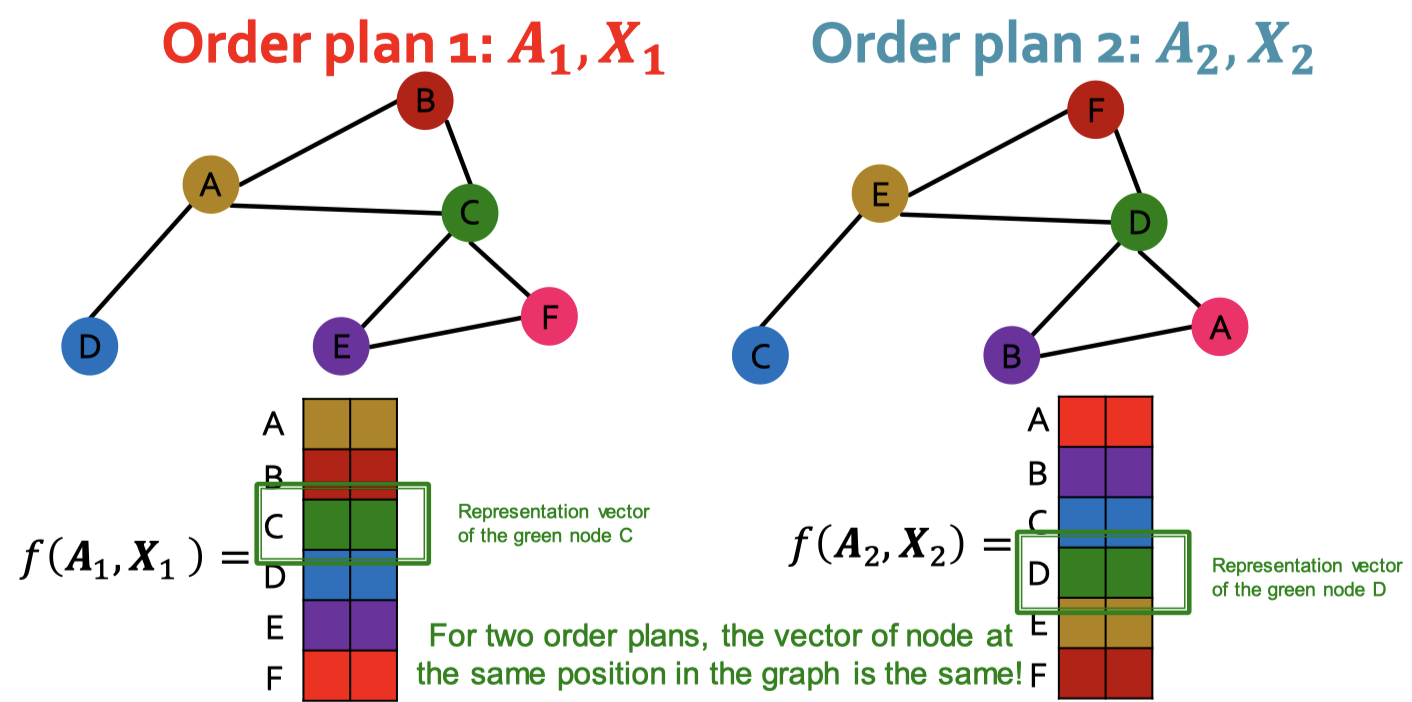
참조
https://littlefoxdiary.tistory.com/16
