원본 영상 : https://www.youtube.com/watch?v=kcE_1n41xdk
오늘 다뤄볼 주제는 실전 이탈 예측에 관한 내용입니다. 이탈이라는 상황은 게임에서도 흔히 발견될 수 있는 사항인데, 간단하게 말하면 철새를 생각하면 이해하기 쉽습니다. 특정 기간에 이벤트를 많이 하다가, 이벤트가 끝나면 다시 빠져나가는, 그런 현상이 이탈입니다. 이와 관련해서 발표가 진행되었었습니다. 이와 관련해서, 실제로 사용자 로그를 추출해 데이터 분석이 많이 이루어지기도 하는 분야이고, 머신러닝 등 예측 분야가 많이 사용되는 부분이기도 해서 관심있게 봤던 분야인 것 같습니다.
1. 이탈예측
- 이탈 예측 : 유저가 유저로 남아있을지, 아니면 이탈자로 남아있을지 예측하는 것
- 유저 개별의 생존확률(이탈확률), 생존기간, 특정 유저군의 잔존율을 예측하는 것
이탈 예측을 하는 이유
- 고객의 이탈을 방지하고 고객 생애 가치(LTV), 투자 대비 수익(ROI) 등을 정확히 계산하여 데이터 기반의 의사 결정에 일조
💡 데이터 기반의 의사 결정에 일조하는 것은 분석가의 꿈이라고 할 수 있음.
이탈 예측의 중요성
- 신규 유저 유입 대비 기존 유저 유지의 비용이 작음. → 새로운 유저를 유치하는 것보다 기존의 유저를 잔존시키는 것이 효율적
- 모바일이 주 플랫폼인 세상에서 유저 생존기간이 짧고, 이탈 방지를 위한 직접적인 방안이 존재 (EX. 푸시 메일, 출석 보상)
2. 예측 모델링 프로세스
예측 모델링 프로세스

- 학습 데이터 생성
-
이탈은 어떻게 정의할지?
-
누구를 대상으로 정해야 할지?
학습 데이터 = 학습 대상+ 각 대상에 대한 정보 + 레이블
💡 학습 대상 : 누구인지?
레이블 : 이탈했는지 안했는지, 얼마나 생존을 했는지 등 즉, 이탈했는지, 살아있는지?- 학습 대상 고려 사항
-
전체 유저에 대해 이탈 예측을 하자니 유저마다 성향이 너무 다름 → 정확도가 떨어지는 문제점이 발생
-
모든 유저를 대상으로 하는 이탈 예측은 비효율적 (성능, 비용 등 모든 측면에서) → 반례 : 봇, 악성 유저, 근본적으로 성향이 맞지 않아 이탈 방지가 불가능한 유저들 ex. 친구 따라 pc방에서 계정 만들어본 사람들
⇒ Bot이 아니고, 악성 유저도 아니면서, 장기간 플레이할 것 같은 유저? 진성유저라고 할 수 있음
💡 진성 유저 : 해당 게임을 충분히 좋아하는 것이 증명된 유저
진성유저를 유저 클러스터링으로 분류하고 이탈 예측의 대상으로 진행했지만, 팀의 예측일 뿐이고, 이탈 정책/목표에 맞는 유저군을 찾는 것이 중요
- 레이블
-
이탈의 정의 : 흔히 탈퇴를 생각하기 쉬움. 하지만, 게임계정의 경우 탈퇴의 경우는 거의 적음.
-
실제로 1년 이상 미접속 유저 중 서비스 탈퇴 유저는 고장 0.8%에 불과함. → 사실상 아무도 탈퇴를 하지 않음.
-
연속 미접속 기간 : 일정 기간 이상동안 접속하지 않은 유저는 탈퇴자로 보겠다고 임의로 정의
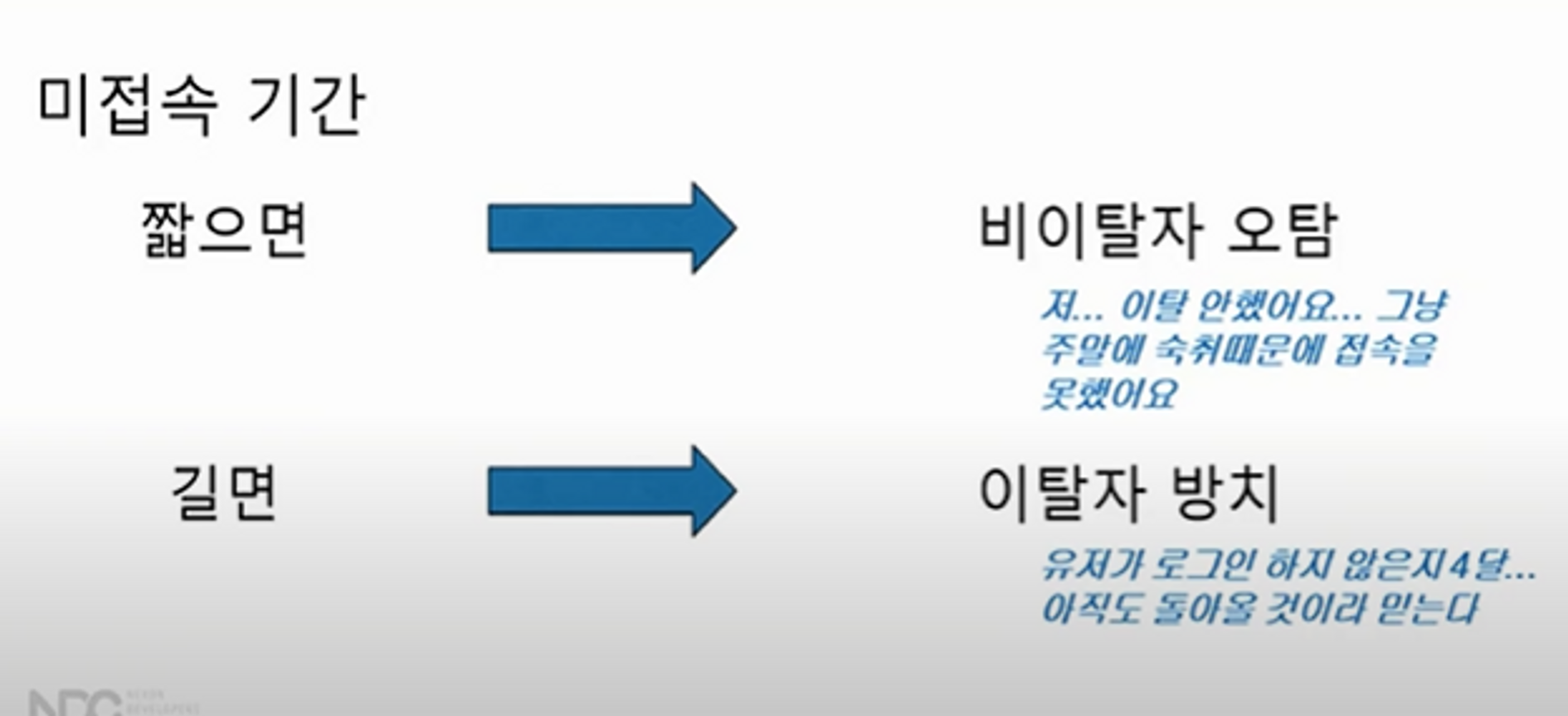
- 미접속 기간이 짧으면 비이탈자 오탐의 경우가 많아짐.
- 미접속 기간이 길면, 이탈자 방치의 현상이 발생. ⇒ 적절한 미접속 기간을 정의하는 것이 필요

→ 이를 위해 내부 요인 + 미접속 기간에 따른 복귀/이탈률을 고려해야 함.

- 해당 그래프는 아이온 유저들의 연속 미접속 기간에 따른 이탈률을 정의함.
- 상한선을 26주로 둔 이유? → 아이온의 경우 6개월마다 대규모 업데이트를 진행함. 이는 게임이 아예 바뀌는 것이기 때문.
- 특별한 변곡점이 보이지는 않음. 임의로 75%에 달하는 13주를 기준으로 삼음.
발표자의 추천
- 충분한 기간동안 Windowing하는 것을 추천
- 시점에 따라 이탈/복귀율이 크게 차이남 → 설날, 입대시즌일수도 있고 다른 여러 변수가 존재
-
-
데이터 가공
-
어떤 데이터를 가공해서 사용하는지 결정

-
대표적으로 활동이력이 있음. 이탈 시점이 길어질수록, 이탈자의 플레이 타임은 감소하는 반면, 비이탈자의 플레이 타임은 일정,
-
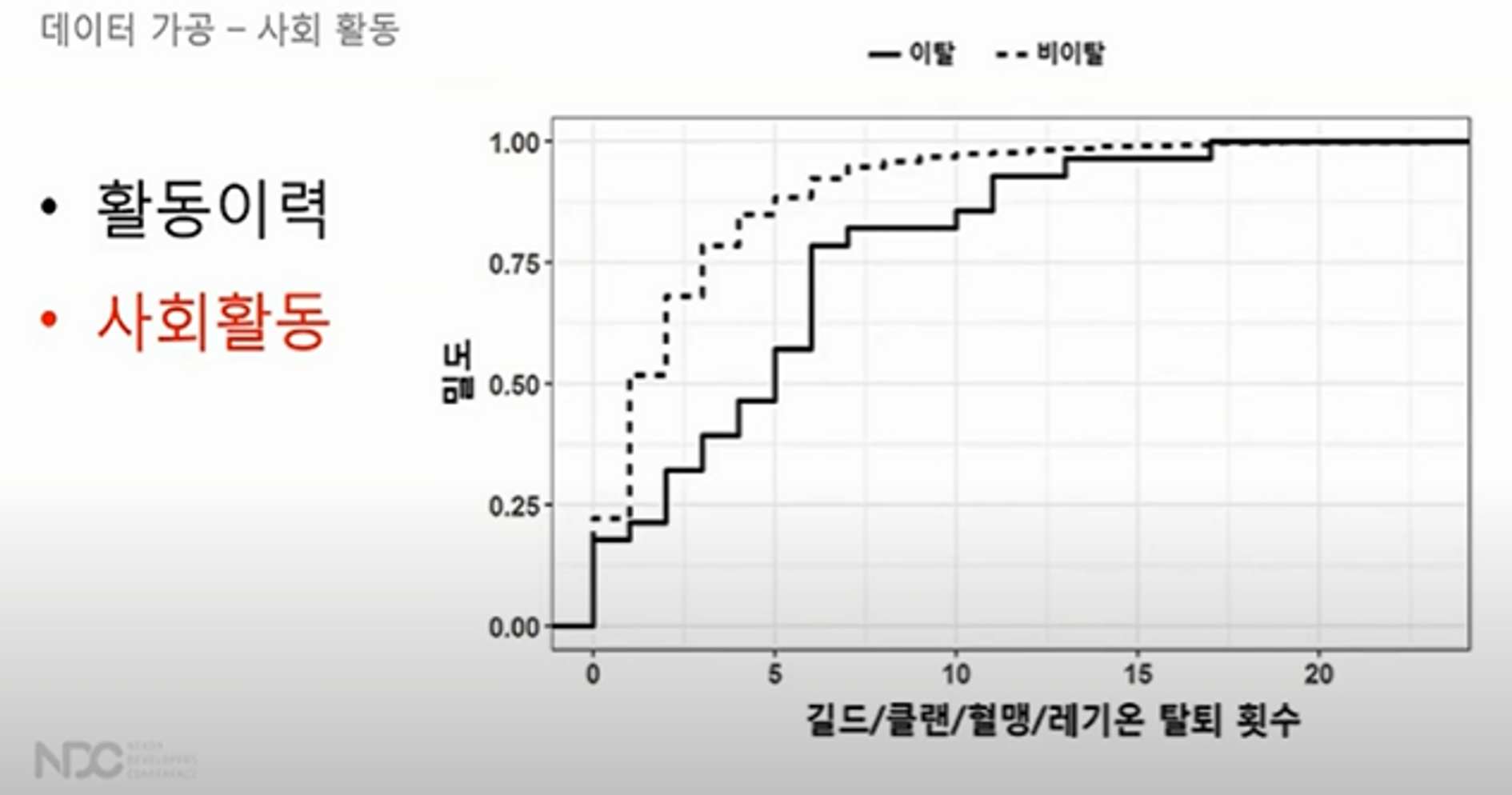
추가로 사회활동 데이터를 사용할 수 있음
-
사회활동은 길드, 클랜, 혈맹, 레기온 등을 가입하고 탈퇴하는 횟수를 말함
-
비이탈자 대비 이탈자들은 이탈시점이 다다를수록, 길드, 클랜 등 가입 또는 탈퇴의 횟수가 비이탈자에 비해 높은 것으로 확인
-
추가적으로 결제이력 등에 대해 추세, 변동성 등 계산해서 변수가공 → 결제문제는 민감함
⇒ 변수문제는 회사마다 협업하는 도메인 지식 전문가와 협업하는 것이 좋음.
💡 도메인 지식 전문가 : 게임 담당자
이들은 매일 게임을 모니터링하면서, 유저들과 호흡을 맞추고, 피드백을 맞추면서 지식을 많이 쌓기에, 데이터 분석가가 백날 야근하는 것보다 효율적인 인사이트 제공할 수 있음.
- 모델 생성
-
어떤 알고리즘을 사용할지?
-
어떤 모델링 기법을 적용할까?
예측력 + 해석력 측면으로 구분할 수 있음.
→ 한쪽이 좋으면 한쪽이 안좋은 알고리즘을 사용할 수 있음.
둘 다 가능한 알고리즘을 사용하는 것이 좋음.
이탈 방지를 하려면, 이탈 요인이 무엇인지, 모델에서의 해석력을 통해 추정하게 되는데 해석력이 떨어지는 모델을 사용하면 이탈의 원인을 파악할 수 없어서, 요인 추정 모델을 추가로 만들어야 됨.
이탈의 원인을 모르면, 정확하게 이탈자를 예측해도 이탈을 방지할 수 없음.

- 모델링, 예측 목표에 따라, 단순 이탈확률을 예측하는 것인지, 생존 기간을 예측하는 것인지 달라짐.
- 경험에 따르면 생존기간 분석에 대한 모델 추천
- 성능 평가
- 정확도만 높으면 장땡일까?
- 정확도는 어떻게 정의해야 할까?
- 성능 평가의 기준 Precision : 확실히 이탈 예측 가능한 유저만 예측 Recall : 최대한 많은 유저들을 잠재 이탈자로 간주하고, 이에 대해 이탈 방지 캠페인을 하겠다고 목표를 잡는 것이 됨. → 어떤 metric(방법)을 쓸지 결정을 할 때에도, 이탈 방지 정책, 목표를 고려해야 함. → 이탈 정책에 부합하도록 성능을 측정해야 함.
- 부족한 성능평가의 예시
- 예를 들면, 내일 이탈 예측을 한 유저가 3일 후에 이탈한다면? → 이탈하긴 했는데, 기간을 못맞춤
- 접속은 하지만, 게임 내 활동이나 구매가 없는 경우 → 영혼은 이탈했는데, 몸은 남았나??
- 1주 후 이탈 예측률을 100%인데, 2주 후 이탈 예측률은 10%인 경우 → 잘맞춘다고 보기는 애매함.
- 업데이트 전에는 예측률 100%, 업데이트 후 0% → 업데이트마다 모델을 새로 만들 것인지….
- 예를 들면, 내일 이탈 예측을 한 유저가 3일 후에 이탈한다면? → 이탈하긴 했는데, 기간을 못맞춤
3. 실전 고려 사항
문제를 해결할 수 있는 알고리즘
- Time Dependent ROC Curve
- IBS(Integerated Brie Score)
- 이것들 외에도 다수의 평가 데이터를 사용하는 것이 좋음
4. 결론
- 이탈의 정의? → 탈퇴가 아닌, 연속 미접속으로 정의
- 이탈 예측의 대상? → 이탈 정책에 부합하는 유저군을 선택 e.g. 장기 진성 유저
- 이탈 예측을 위한 데이터는 어떤 것이 있는가? → 활동, 결제, 매출, 사회활동. 무엇보다도 도메인 지식 전문가의 도움이 필요함
- 어떤 모델링 기법을 사용해야 하는가? → 해석력 + 예측력, 생존기간 (생존분석) 추천
- 성능 평가시 고려해야 할 사항? → Precision vs Recall인데, 이탈 정책에 맞도록 성능을 측정해야 함.
→ 경험담을 통해 이탈 예측을 할 때 삽질을 덜 할 것임.
