대학원에 가서 연구에 필요한 Graph Neural Network에 대한 개괄적인 이론을 이해하기 위해서 만든 내용이지만, 어떻게든 머리에 쑤셔넣는 글입니다….
그래프란?
- Entity를 표현하는 노드와 노드 간의 관계를 표현하는 엣지로 구성
- G = (V, E)로 구성
- ex) 소셜 네트워크에서는 각각의 개인이 노드, 사람들 사이의 관계는 엣지로 표현
- Vertex : 노드들의 집합
- Edge : 노드 사이를 연결하는 엣지들의 집합
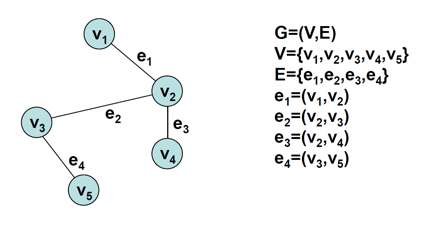
-
그래프 유형
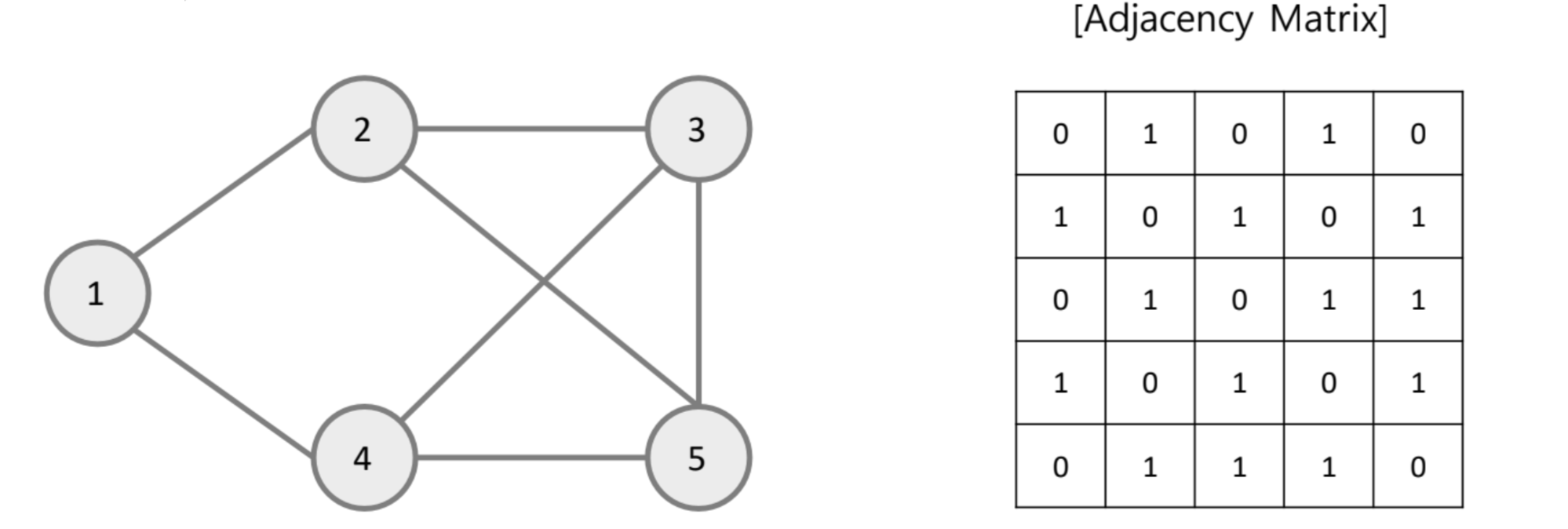
- Undirected Graph : Edge에 방향성을 가지지 않음 ex) 친구 관계
- Directed Graph : Edge에 방향성을 자김 ex) 웹페이지 링크
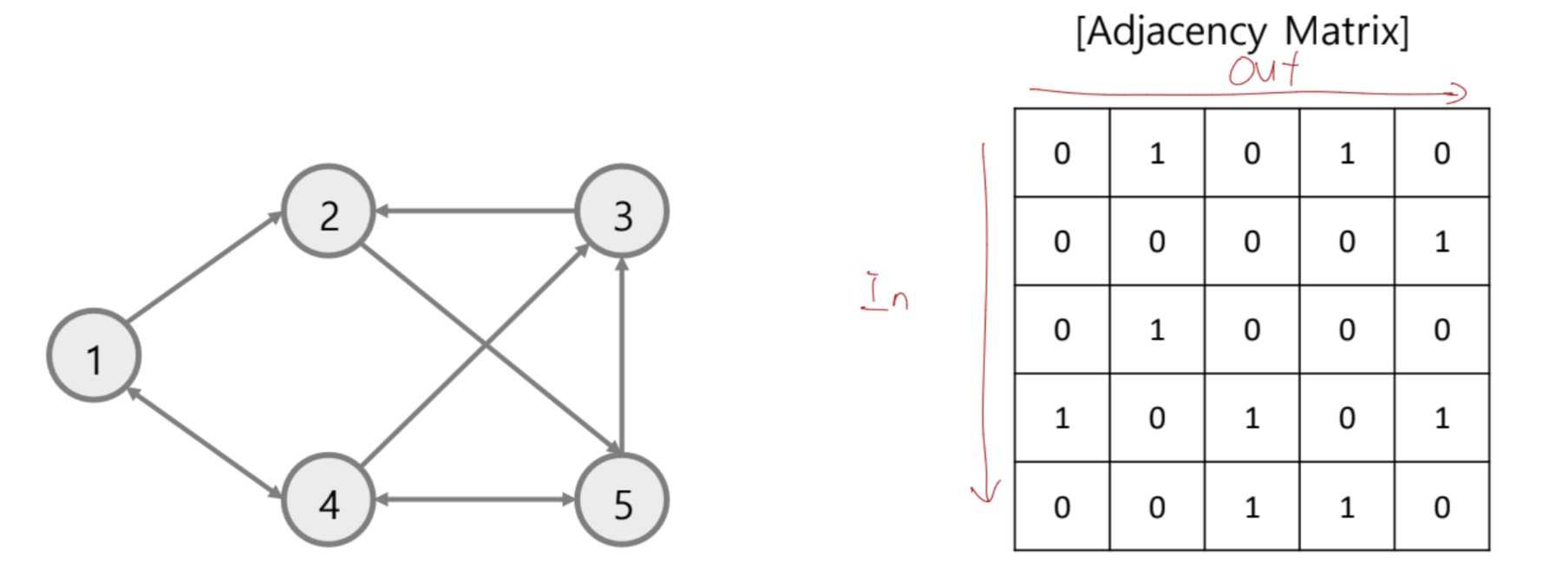
- 이 과정에서, 에서 으로 향하는 엣지 이 있따면, 를 predecessor, 을 sucessor이라고 부름.
- 을 의 outgoing edge, 의 incoming edge라고 부름
- Unweighted Graph : 모든 edge에 대해 weight가 똑같음
- Weighted Graph : 간선에 가중치가 부여된 그래프 ex) 거리, 관계 강도, 네트워크 연결 비용
- Undirected Graph : Edge에 방향성을 가지지 않음 ex) 친구 관계
그래프의 행렬 형태 표현

Adjacency Matrix
Adjacency 행렬은 그래프 노드의 개수가 N개라면, NxN 정사각 행렬임. i노드, j노드가 연결되어 있다면 =1, 그렇지 않다면 0
Degree Matrix
그래프 노드의 개수가 N개라면, NxN의 크기를 가지는 대각행렬임. 각 꼭짓점의 차수에 대한 정보를 포함하고 있는 행렬, 꼭짓점의 차수가 꼭짓점과 연결된 엣지의 개수
Laplacian Matrix
Adjacency 행렬은 노드 자신에 대한 정보가 없음. 반대로, Laplacian 행렬은 노드와 연결된 이웃노드와 자신에 대한 정보가 모두 포함된 행렬.
Degree 행렬에서 Adjacency 행렬을 뺀 값
그래프 마이닝
-
그래프 데이터를 분석하고 유용한 패턴, 관계, 구조를 추출하는 과정
-
그래프 마이닝에서 포함하는 기술
- 구조 분석 : 그래프의 전체적 혹은 지역적 특징 이해
- 패턴 탐색 : 빈번하거나 유의미한 서브그래프 식별
- 특징 추출 : 그래프 또는 노드의 속성을 학습해 표현
- 이상 탐지 : 그래프 내에서 비정상적인 노드나 서브그래프 찾음
-
기본적인 그래프마이닝 기술
- DeepWalk
- 그래프 구조 → 저차원 벡터로 임베딩
- 그래프 데이터를 단어 시퀀스처럼 처리해 Word2Vec 방식을 사용
- 과정
- 랜덤 워크 생성 :
- 그래프의 각 노드에서 시작하여 무작위로 이웃 노드를 방문하며 고정된 길이의 노드 시퀀스를 생성.
- 노드 시퀀스는 단어 시퀀스처럼 간주됨 (A → B → C → D → A)
- 각 노드의 맥락(context) 정보를 포함한 시퀀스 데이터 생성
- Word2Vec 학습
- 생성된 노드 시퀀스를 Word2Vec의 Skip Gram 모델에 입력
- 중심 노드를 기반으로 주변 노드를 예측하도록 동작
- 노드 간의 구조적 유사성과 관계 학습
- 노드 임베딩
- 학습이 완료되면, 각 노드는 고유한 저차원 벡터로 표현, 그래프 구조와 이웃 관계 내재화
- 랜덤 워크 생성 :
- 효율적이고 구현이 수비지만, 전역적 관계 학습에 있어서 단점 존재
- 또한, 노드의 속성 정보를 활용하지 않음.
- Node2Vec
- 랜덤 워크 전략을 개선해 그래프의 지역적 정보, 전역적 정보를 모두 학습할 수 있도록 설계된 알고리즘
- 과정
- Biased Random Walk
- 단순 랜덤 워크 대신 DFS, BFS의 비율을 조정해 노드 시퀀스 생성
- DFS : 전역적 탐색, 먼 노드까지 관계 탐구
- BFS : 지역적 탐색, 이웃 노드 중심
- 매개변수 p,q로 탐색 전략 제어
- p : 이전 노드로 돌아가는 확률
- q : 새로운 방향으로 나아가는 확률
- 단순 랜덤 워크 대신 DFS, BFS의 비율을 조정해 노드 시퀀스 생성
- Word2Vec 학습
- DeepWalk와 마찬가지로, 생성된 노드 시퀀스를 Word2Vec 모델에 입력하여 노드 임베딩을 학습.
- 노드 임베딩
- 학습된 벡터는 그래프의 지역적 및 전역적 구조를 모두 포함.
- Biased Random Walk
- 그래프의 전역, 지역적 정보를 모두 학습할 수 있지만, 매개변수 p와 q에 대한 튜닝이 필요
- 대규모 그래프에서는 계산 비용 증가
- DeepWalk
-
그래프 마이닝 기법
-
HITS (Hyperlink Induced Topic Search)
-
노드의 중요도를 좋은 Hub와 좋은 Authority로 판단하는 것이 특징
-
Hub는 다른 문서로 연결되는 문서를 의미하고, Authorities는 다른 문서에게 연결당하는 문서를 의미
-
좋은 허브는 권위 있는 페이지로 연결된 링크를 많이 가지는 페이지, 좋은 권위는 많은 허브 페이지로부터 링크를 받는 페이지
-
좋은 hub는, 많고 좋은 authorities들을 가리킨다. 좋은 authority는, 많고 좋은 hub들에 의해 가리켜진다.
과정
-
초기화 : 모든 노드의 허브 점수 와 권위 점수 를 초기화 (보통 1로 설정)
-
허브 점수, 권위 점수 업데이트
- 허브 점수는 연결된 이웃 노드의 권위 점수의 합으로 계산
여기서 는 노드 가 링크하는 노드 집합
b. 권위 점수 계산 : 권위 점수는 연결된 이웃 허브 노드의 점수 합으로 갱신
여기서 는 노드 로 링크하는 노드 집합
-
정규화 : 점수가 발산하지 않도록 각 노드의 허브와 권위 점수를 정규화
-
반복 : 허브와 권위 점수를 반복적으로 업데이트하며 수렴할 때까지 계산
-
결과 해석 : 최종 허브와 권위 점수를 기반으로 중요한 페이지 결정
-
-
PageRank
- 웹 페이지의 중요도를 측정하기 위해 설계
- 그래프에서 노드의 “인기도”를 점수로 계산하는 알고리즘
- 아이디어
- 웹 페이지의 중요성은 해당 페이지로 링크하는 다른 페이지의 중요성에 비례.
- 모든 페이지는 동일한 중요도를 가질 필요가 없으며, 링크의 출처가 중요한 역할을 수행함.
- 과정
-
초기화
- 모든 노드에 동일한 초기 PageRank 값 할당
-
PageRank 점수 계산
- 각 노드의 PageRank 점수는 해당 노드로 링크하는 다른 노드들의 PageRank 값을 이용해 갱신
- 링크의 중요성은 각 노드의 아웃링크(outlink) 개수로 나눠 균등 분배
- : 노드 v의 PageRank 점수
- : 감쇄 계수 (일반적으로 0.85)
- : 노드 v로 들어오는 링크를 가진 노드의 집합
- : 노드 u의 아웃링크 개수
-
감쇄 계수 (Damping Factor)
- 사용자가 무작위로 다른 페이지를 방문할 확률
- : 사용자가 무작위로 그래프 내 임의의 노드로 이동할 확률
- 이를 통해 스팸 페이지나 고립된 노드가 중요도를 독점하지 못하도록 막음
-
반복 및 수렴
- 계산된 PageRank 값을 반복적으로 갱신
- 갱신된 PageRank 값이 이전 값과 거의 차이가 없어질 때까지(수렴) 이 과정을 반복
-
최종 결과
- 각 노드의 최종 PageRank 점수는 해당 노드의 중요도
- 점수가 높을수록 더 중요한 페이지로 간주
-
- 전역적으로 웹 페이지의 중요도를 효율적으로 평가.
- 계산 비용이 크고, 대규모 데이터에서 반복 시간이 길어짐
- 초기 그래프 구조와 링크 품질에 민감
- PageRank를 반복적으로 수행하다보면, page의 연결 구조상 제대로 Rank가 다른 page로 전달되지 못하는 치명적인 문제가 있음
-
Object Ranking
- 객체(노드)의 중요도를 순위화하는 기법
- HITS와 PageRank와 유사하지만, 그래프의 특성과 문제에 따라 맞춤화
- 아이디어
- 객체는 그래프의 노드로 표현되며, 객체 간의 관계는 그래프의 간선으로 나타남.
- 각 객체의 중요도는 해당 노드로 들어오거나 나가는 간선의 특성과 연결된 다른 객체의 중요도에 따라 결정됨
- 그래프의 특성과 문제에 맞게 커스터마이징 가능
- 다양한 관계와 데이터를 통합할 수 있지만, 가중치 설정이 어려울 수 있고, 계산 비용이 높아질 가능성이 있음.
-
GNN (Graph Neural Network)
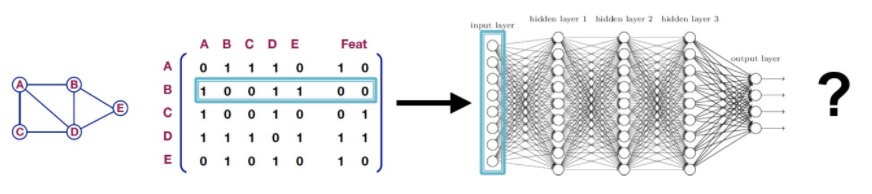
- 그래프 구조를 기반으로 다양한 분야의 데이터를 처리하는 아키텍처
- 그래프로 표현할 수 있는 데이터를 처리하기 위한 인공신경망의 한 종류
- 입력 데이터로 그래프 구조를 사용, 그래프 신경망을 통해 텍스트나 이미지를 처리할 수 있음.
- E-commerce에서 유저들과 유저들이 구매한 아이템 간의 관계를 학습하는 추천 시스템에 활발히 사용되고 있음.
- GNN을 통해서 각 노드를 잘 표현할 수 있는 임베딩 추출을 기대할 수 있음.
-
GNN은 그래프 구조를 활용해 loss를 최적화하는 과정이라고 할 수 있음.
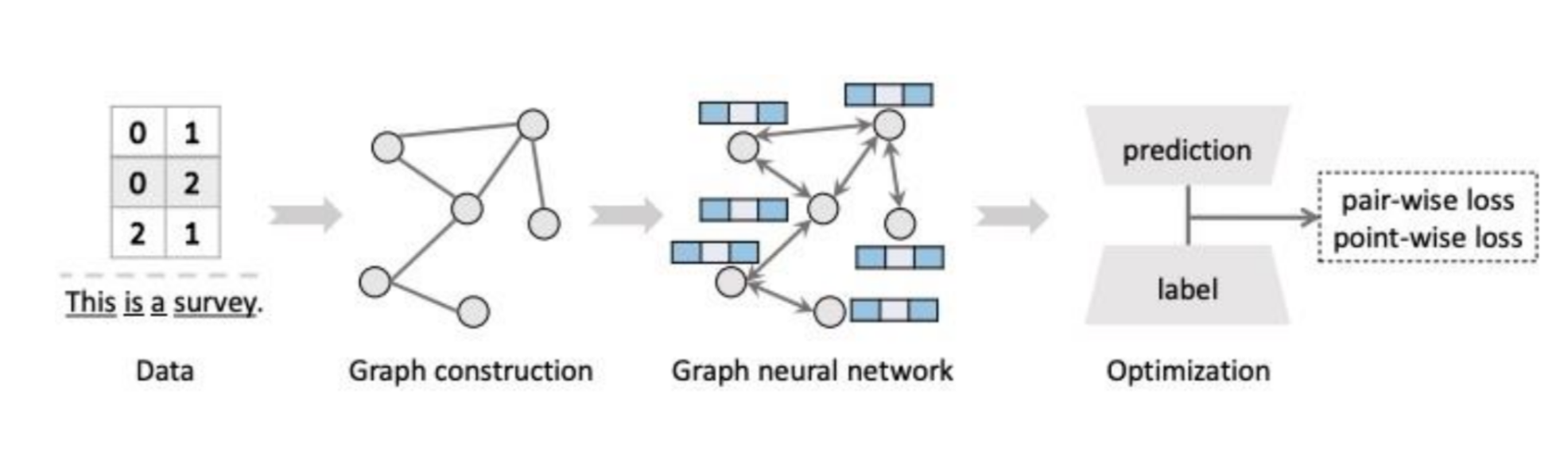
-
Motivation of GNN → By CNN
GNN의 아이디어는 Convolutional Neural Network에서 시작되었음.
CNN의 특징은 다음 3가지를 가지고 있다.
- Local connectivity
- Shared weights
- Use of Multi-layer
→ 이로 인해 CNN은 Spatial Features를 계속해서 layer마다 계속해서 추출해 나가면서 고차원 특징을 표현할 수 있음. 이제는 이를 그래프의 영역에서도 적용 가능
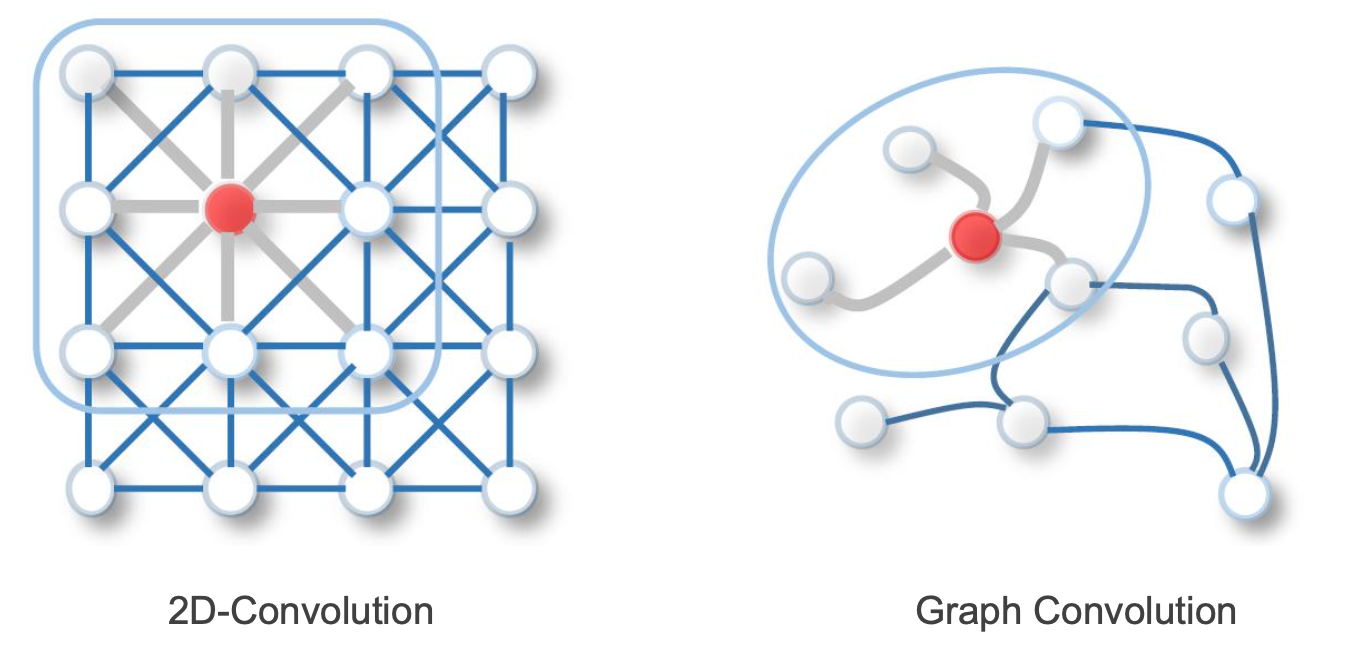
Local Connectivity
그림을 보면, CNN과 GCN의 유사한 점을 확인할 수 있음.
Graph도 한 노드와 이웃노드 간의 관계를 local connectivity라 볼 수 있기 때문에, 한 노드의 특징을 뽑기 위해 local connection에 있는 이웃노드들의 정보만 받아 특징을 추출할 수 있음.
Shared Weights
graph 노드의 특징을 추출하는 weight은 다른 노드의 특징을 추출하는데도 동일한 가중치를 사용할 수 있어, computational cost를 줄일 수 있음/
Use of Multi-layer
Multi-layer 구조로 여러 층을 쌓게 되면, 초반에는 low-level feature 위주로 뽑고, 네트워크가 깊어질수록 high-level feature만 뽑음.
그래프의 경우, Multi-layer 구조로 쌓게 되면, 초반 layer은 단순한 이웃노드 간의 관계에 대해서만 특징을 추출 → 네트워크가 깊어질수록 나와 간접적으로 연결된 노드의 영향력까지 고려된 특징을 추출할 수 있음.
Original Graph Neural Network
GNN의 목적 : 이웃노드들 간의 정보를 이용해 해당 노드를 잘 표현할 수 있는 특징 벡터를 찾아내는 것
→ 이렇게 찾아낸 특징 벡터를 통해 task 수행 가능
💡 수행가능한 task
- 노드 분류
- 각 노드가 어떤 클래스에 속하는지 예측
- 노드로 표현된 한 사람이 어떤 소셜 관계에 포함되는지 예측
- 링크 예측
- 노드와 노드 사이 누락된 링크 예측
- 소셜 관계망에서 두 사람의 관계가 이어졌을지 예측 (얼마나 친한지)
- 그래프 분류
- 서로 다른 그래프를 분류하는 작업
- 그래프로 표현된 여러 분자 구조가 어떻게 분류 되는지를 예측
- 그래프 생성
- 새로운 그래프 생성
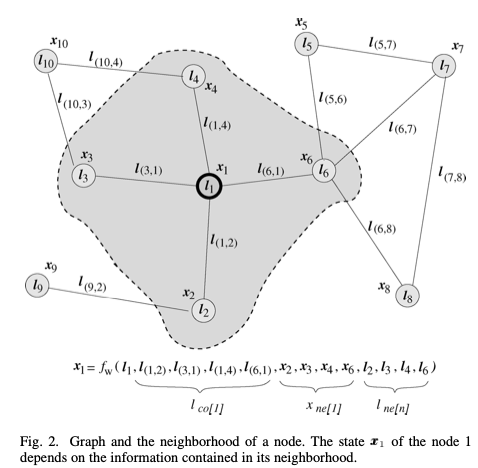
GNN의 Step은 크게
- Propagation step (전파, 전이(transition)라고도 부름) : 이웃 노드들의 상태를 받아 자신의 상태를 업데이트
- Output step : task 수행을 위해 노드 벡터에서 task output을 출력
으로 구분된다.
이를 수식으로 표현하면 다음과 같음.
여기서 은 각각 n 노드의 라벨, n 노드와 연결된 엣지들의 라벨, 이웃 노드들의 states, 이웃 노드들의 라벨임.
여기서 는 각각 propagation function와 output function
propagation function : 이웃 노드들의 정보와 노드와 연결된 엣지 정보들을 토대로 현재 자신의 노드를 표현함. 즉,d-차원의 공간에 이러한 input들을 받아 매핑하는 과정이라고 생각하면 됨.
output function : task 수행을 위해 학습을 통해 얻은 node feature를 입력으로 하여 output을 얻음.
- 예를 들면, node label classification이면 node label이 output이 됨.
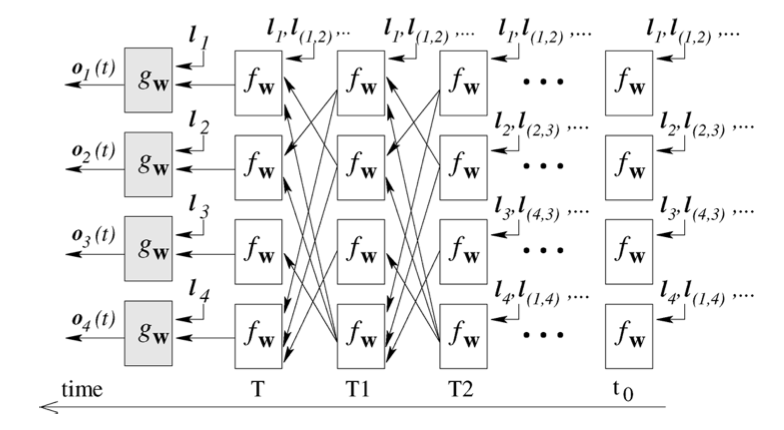
어떻게 학습이 이루어지는지?
Multi-layer을 GNN에 사용하면 얻는 이점은 layer가 깊어질수록 직접적으로 연결된 이웃 노드 외에 멀리 있는 노드들의 영향력을 고려해 현재 노드의 feature를 구성할 수 있음.
💡 Message Passing
- 멀리 있는 노드에서 현재 노드까지 정보가 전달되는 과정
- GNN의 학습이 이루어지는 과정을 Message Passing이라고 함.
다만, 초기 GNN의 경우는 Multi-layer 구조가 아닌 주로 단일 구조이기에, 이러한 Messgae Passing이 불가능함.
따라서, Banach fixed point theorem에 따라, iterative method(반복법)로 고정된 node feature를 찾음.
💡 Banach Fixed Point Theorem (바나흐 고정점 정리)
- 수학적으로 수렴성을 보장하는 중요한 이론
- 어떤 함수 f가 수축 사상(Contraction Mapping)이라면, 반복적으로 f를 적용하면 고정점(Fixed point)에 수렴한다는 것을 보장
- 고정점 (Fixed point) : 를 만족하는 점
- 수축 사상 : f가 입력 값의 거리를 점점 좁혀주는 특성을 가진 함수(즉, )
Iterative Method로 고정된 노드 특징 찾기
- 초기화 : 각 노드의 특징을 임의 값(혹은 초기 값)으로 설정 ( )
- 반복 갱신 : 이 과정을 k → 로 반복
- 특정 임계값 이하로 변화량이 작아지면 (), 업데이트를 멈춤. 이 상태에서 노드 특징은 고정점에 도달함.
이 어떤 수렴된 값을 가지려면, Banach fixed point theorem에 의하면, propagation function이 contraction map이여야 함.
💡 Contraction Map (수축 사상)
- 함수가 입력값들 사이의 거리를 점점 줄여주는 성질을 가지는 것
- 바나흐 고정점 정리에서 주요 역할 수행
- 이 조건은 f가 입력값 x와 y사이의 거리를 최대 c배로 줄이는 것
그래프 신경망의 방법론
- GNN은 Spectral과 Spartial한 방법론으로 구분됩니다.
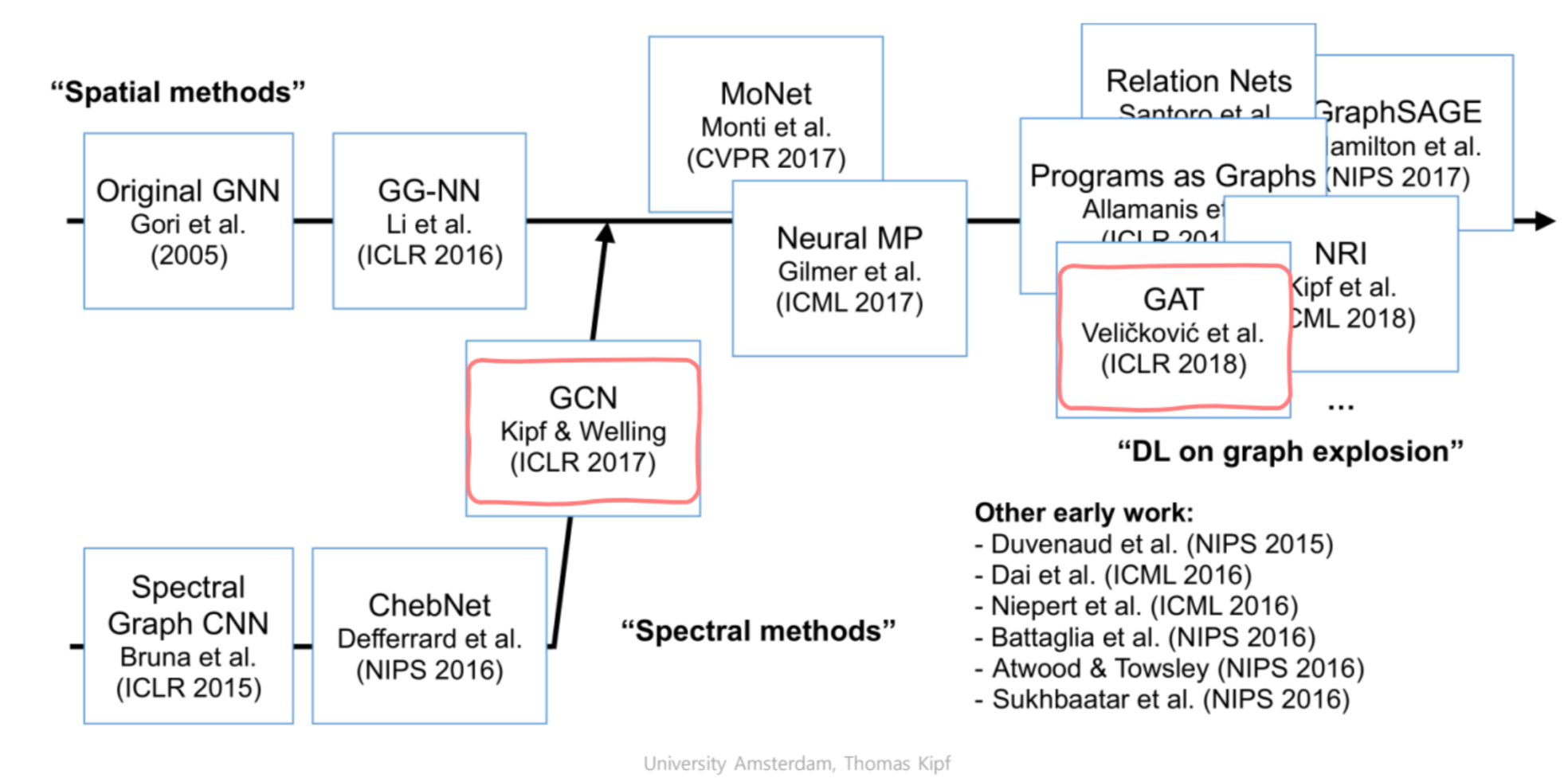
0d6e-4bc5-bf3c-b447fa3761c1/4b493cba-ec7f-4da8-84cb-7d81eab6cc2e/image.png)
이미지 출처 : https://velog.io/@whattsup_kim/Graph-Neural-Networks-기본-쉽게-이해하기
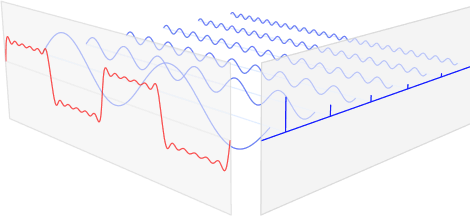
Spectral 방법론
- 그래프의 스펙트럼, 즉 그래프 라플라시안 행렬의 고유값과 고유벡터를 기반으로 그래프 데이터를 처리하는 방법
- 어떤 특정 신호를 단순한 요소의 합으로 분해하는 것
- 대표적인 방법이 푸리에 변환
- 푸리에 변환 : 임의의 입력 신호를 다양한 주파수를 갖는 주기함수들의 합으로 분해하여 표현 (알고만 있자!!)
- 그래프 신호에서 푸리에 변환은 그래프의 라플라시안 행렬을 고윳값분해 하는 것.
- 신호 전처리 분야에서 어떠한 신호를 스펙트럼처럼 처리해서 분석하는 것
- 오디오, 이미지 등 주어진 어떤 신호를 frequency domain의 관점에서 단순한 요소의 합으로 분해하는 것
- 라플라시안 행렬을 고유값 분해하여 그래프의 전역적 구조를 반영하고, 특정 고유벡터를 사용해 그래프 노드를 임베딩하거나 변환
- 예시
- Graph Convolutional Network : 그래프 필터링을 수행하는 데, 그래프 라플라시안과 고유벡터를 기반으로 설계
- ChebNet : GCN의 계산 복잡성을 개선하기 위해 다항식 근사 활용
- 전체 구조를 반영할 수 있지만, 비용이 비쌈
Spatial 방법론
- 노드의 공간적(spatial) 이웃(인접 노드)의 정보를 활용해 그래프 데이터를 처리하는 방법
- Convolution 연산을 그래프 위에서 직접 수행하는 방식, 각 노드와 가깝게 연결된 이웃 노드들에 한해서 convolution 연산을 수행
- = 노드와 이웃노드들을 특정 grid form으로 재배열하여 convolution 연산을 수행하는 것
- 그래프를 직접적으로 다루며, 노드 간 지역적 관계 강조
- 각 노드는 자신의 이웃 노드와의 관계를 활용해 임베딩을 학습하고, 노드 주변의 정보를 집계(aggregation)하여 새로운 표현 생성
- 입력의 위치가 바뀌어도 출력은 동일 (local invariance) → 특정 변환이나 작은 변환에도 변하지 않음
- 조건 : 고정된 이웃 노드에서만 정보를 받아 노드의 정보를 업데이트
- 예시
- GraphSAGE : 샘플링 및 이웃 집계를 통해 효율적으로 그래프 임베딩 학습
- GAT (Graph Attention Network) : 이웃 노드의 중요도를 계산해 정보를 가중집계
- 전역적 구조보다는 지역적 구조에 집중
참조 사이트
https://ralasun.github.io/deep learning/2021/02/11/gcn/
https://velog.io/@whattsup_kim/Graph-Neural-Networks-기본-쉽게-이해하기
