[Paper Reveiw] Language Models are Unsupervised Multitask Learners (GPT2)
Abstract
- 기존 자연어 처리 task들은 Task에 따른 특정 데이터 셋에 대해 Supervised learning에 의해 이루어졌습니다.
- GPT-2 모델에서는 WebText라는 웹페이지의 데이터셋에 대해 다양한 자연어 task에 대해 별도로 지정하지 않고 처리하는, 범용적인 언어 모델을 구축했습니다.
- 언어 모델의 용량은 Zero-shot을 위해 필수이고, 점점 많은 데이터를 적용하게 된다면 log-linear하게 증가합니다.
- 언어 모델의 용량(capacity)은 모델이 가진 파라미터 수나 복잡성을 나타냅니다.
- 모델이 얼마나 많은 정보를 저장하고 처리할 수 있는지에 대한 지표입니다.
→ 해당 연구는 기존의 Task 중심적인 작업을 넘어 아직은 일반화 능력이 부족할 순 있지만, Zero-shot을 통해 언어 모델의 가능성을 열었습니다.
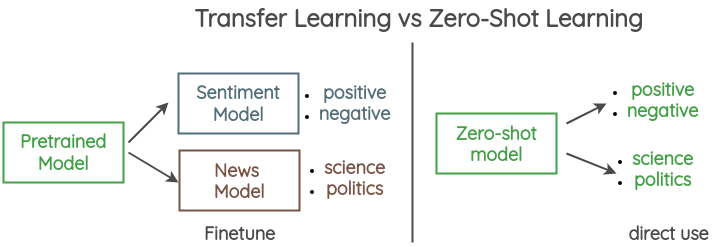
💡 Zero-Shot
- 라벨링 되지 않은 새로운 클래스에 대한 분류 작업을 수행할 때, 이전에 학습된 모델을 사용해 분류하는 기술
- 기존의 Supervised learning은 학습 데이터에 포함된 클래스에 대해서만 분류를 수행할 수 있었지만, Zero-shot 학습은 학습 데이터에 없는 새로운 클래스를 인식하고 분류할 수 있음
- 단, 새로운 클래스에 대한 정보가 있어야 함.
1. Introduction
- 기계 학습에서 Supervised learning을 통해 고성능 모델들이 여러 등장했지만, 이는 데이터의 분포가 조금이라도 바뀌면 불안정해지고, 특정 Task에서만 좋은 성능을 발휘합니다.
→ 다양한 Task에 대해 적용가능한 범용적 모델의 필요성이 대두되었습니다.
💡 Narrow Expert → General Expert로 나아가는 것이 필요합니다.
- 이를 위해서 다양한 도메인에서 적용가능한 General 모델이 필요하며, 이는 데이터를 수동으로 생성하고 라벨링할 필요가 없어야 할 것입니다.
- Multitask learning은 General 성능을 높이는 좋은 방법이지만, 아직 연구 초기이기에, 더 연구해야 합니다.
- 심지어, 최근의 기계 학습을 이용한 언어 모델은 일반화를 위해 수십만개의 데이터가 필요하지만, Multitask learning을 위해서는, 이보다 훨씬 더 많이 필요할 것입니다. 그렇기에, 확장하기에 제한이 있습니다.
- 최근의 가장 좋은 성과는 Pre-training과 Fine-tuning을 결합한 언어 모델입니다
- 이 부분은 전이 학습 형태로 발전되었고, 단어 → 문맥 표현으로 발전했습니다.
- 최근에는 작업별 아키텍쳐의 불필요와, Self-Attention 블록의 transfer만으로 충분하다는 연구 역시 발표되었습니다.
→ 그렇지만, 이 역시 아직은 Supervised learning이 필요합니다.
- 위 논문의 모델 GPT-2에서는 파라미터나 모델 구조의 변화 없이, Zero-shot을 통해서 Downstream task를 수행할 수 있음을 보여줍니다.
→ 이로 인해서, 넓은 범위의 과제를 수행할 수 있음과 언어 모델의 발전 가능성을 확인하였고, 8개의 test 중 7개에서 SOTA를 달성했습니다.
2. Approach
- GPT-2의 핵심 접근 법은 “language modeling”입니다.
💡 Language Modeling
- 각 원소가 과 같은 symbol의 sequence로 구성된 예제 에서 unsupervised 분포를 추정하는 것으로 정의됩니다. (즉, 문장의 일부를 보고 다음 단어를 예측합니다.)
- 언어는 자연적으로 연속된 순서를 가지기에, 조건부 확률의 곱으로 이루어진 symbol에 따른 합동 확률을 구합니다
→ 이러한 접근을 통해서 이전까지의 문장을 바탕으로 다음에 올 Symbol을 예측합니다.
- Transformer과 같은 Self-Attention 구조는 language modeling의 조건부 확률을 계산할 수 있는 모델의 표현력이 증가했습니다.
- Single task에서는 으로 계산합니다.
- Multitask의 경우 로 정의됩니다.
-
즉, 입력에 task가 함께 표현됩니다.
-
예시
1. translation train : translate to french, english text, french text
2. reading comprehension training example : (answer the question, document, question, answer)→ 즉, Fine-tuning을 진행하지 않고 Multitask가 가능합니다.
-
- 이러한 성능을 확인하기 위해 다양한 작업에서 Zero-shot setting에서 언어 모델의 성능을 분석하여 구현 가능한지 확인할 것입니다.
2.1 Training Dataset
- 그동안의 선행 연구에서는, 뉴스, Wikipedia 등과 같이 하나의 영역에서만 가져온 데이터로 구성되어 있습니다. 그렇기에, 해당 연구에서는 여러 도메인에 적용을 위한 다양한 출처로부터 데이터를 가져오려 했습니다.
- 단, Web scraping을 사용했지만, 데이터 품질 이슈로 인해 사람에 의해 필터링 된 글만을 사용합니다.
- 이를 위해, Reddit에서 3 karma 이상 받은 글에 포함된 외부 링크의 글만을 가져 왔습니다.
→ 이 데이터셋의 이름을 WebText라고 합니다.
- 2017년 12월 이후의 글과 위키피디아 글은 제거했으며, 중복 제거 등 전처리를 통해 8M개의 문서를 확보했습니다.
- 위키피디아는 흔하게 사용되고, 데이터 겹침 문제로 인해 제외했습니다.\
2.2 Input Representation
- Language model은 어떠한 문자열에 대해서도 확률을 계산할 수 있어야 하기에, 대소문자 구분, out-of-vocabulary 토큰화와 같은 전처리 과정을 필수로 거쳐야 합니다.
- 해당 연구에서는 BPE를 통해서 글자 입력 수준을 조절했습니다.
💡 BPE (Byte Pair Encoding)
- 텍스트 데이터를 효율적으로 처리하기 위해 단어를 더 작은 단위로 분해 및 결합하는 방법입니다.
- 모델의 어휘 크기를 조절하는데 유용합니다.
- 단어를 더 작은 subword로 나누어 처리하고, 흔히 등장하는 단어는 하나의 서브워드 토큰으로, 드문 단어는 여러 서브워드로 분해해 표현합니다.
- 희귀 단어를 문자나 서브워드 조합으로 표현할 수 있고, 어휘 크기와 메모리 사용이 줄어든다는 장점이 있습니다.
- 같은 어휘에 포함되지 않은 단어도 서브워드 조합을 통해 생성가능하기에, 일반화 가능성 또한 뛰어납니다.
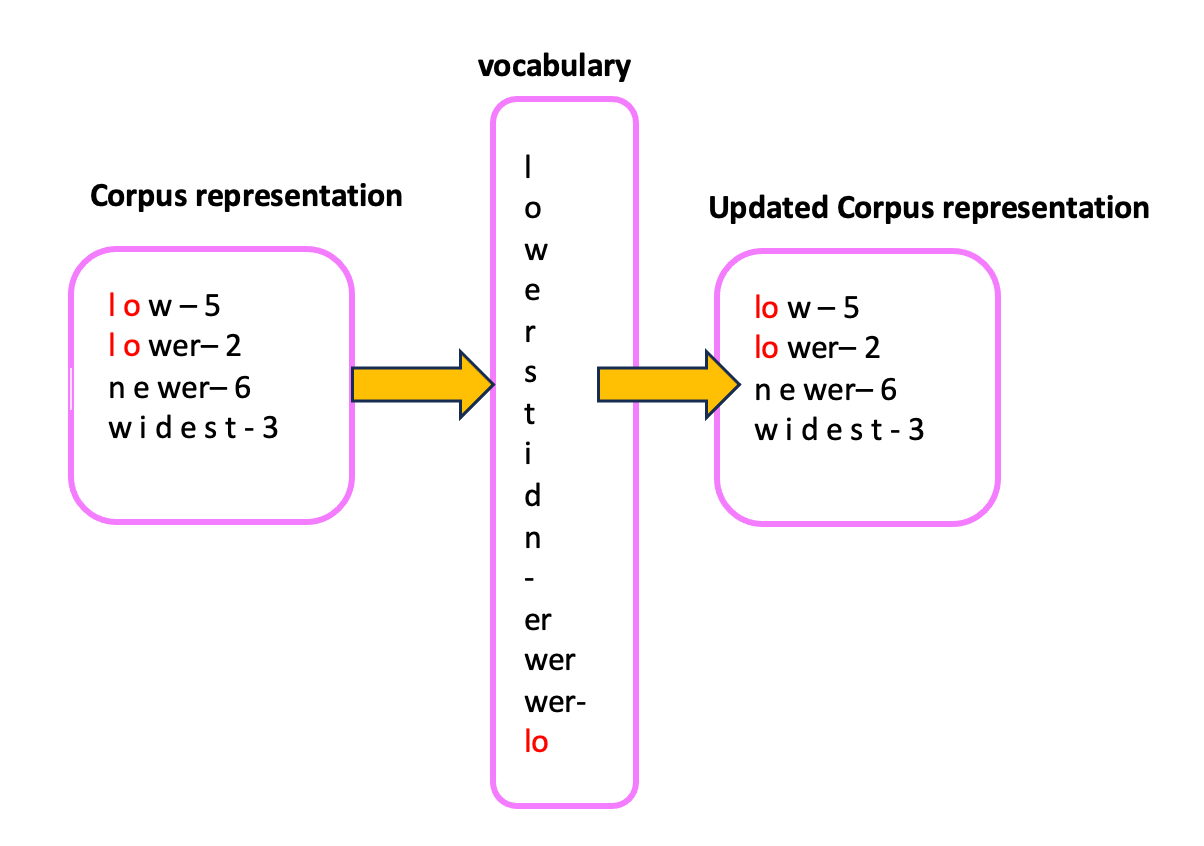
- Unicode Sequence 기반의 기존 인코딩과는 다르게 Byte 기반의 BPE를 사용함으로써, Vocabulary 상의 문제를 해결했습니다.
- 다만, 유의미하지 않은 Variation을 추가할 수 있어서, Vocabulary 크기를 최적으로 사용하지 못할 가능성이 큽니다.
→ 해당 연구에서는 BPE를 적용하기 위해 문자 수준 이상의 병합을 막았습니다.
2.3 Model
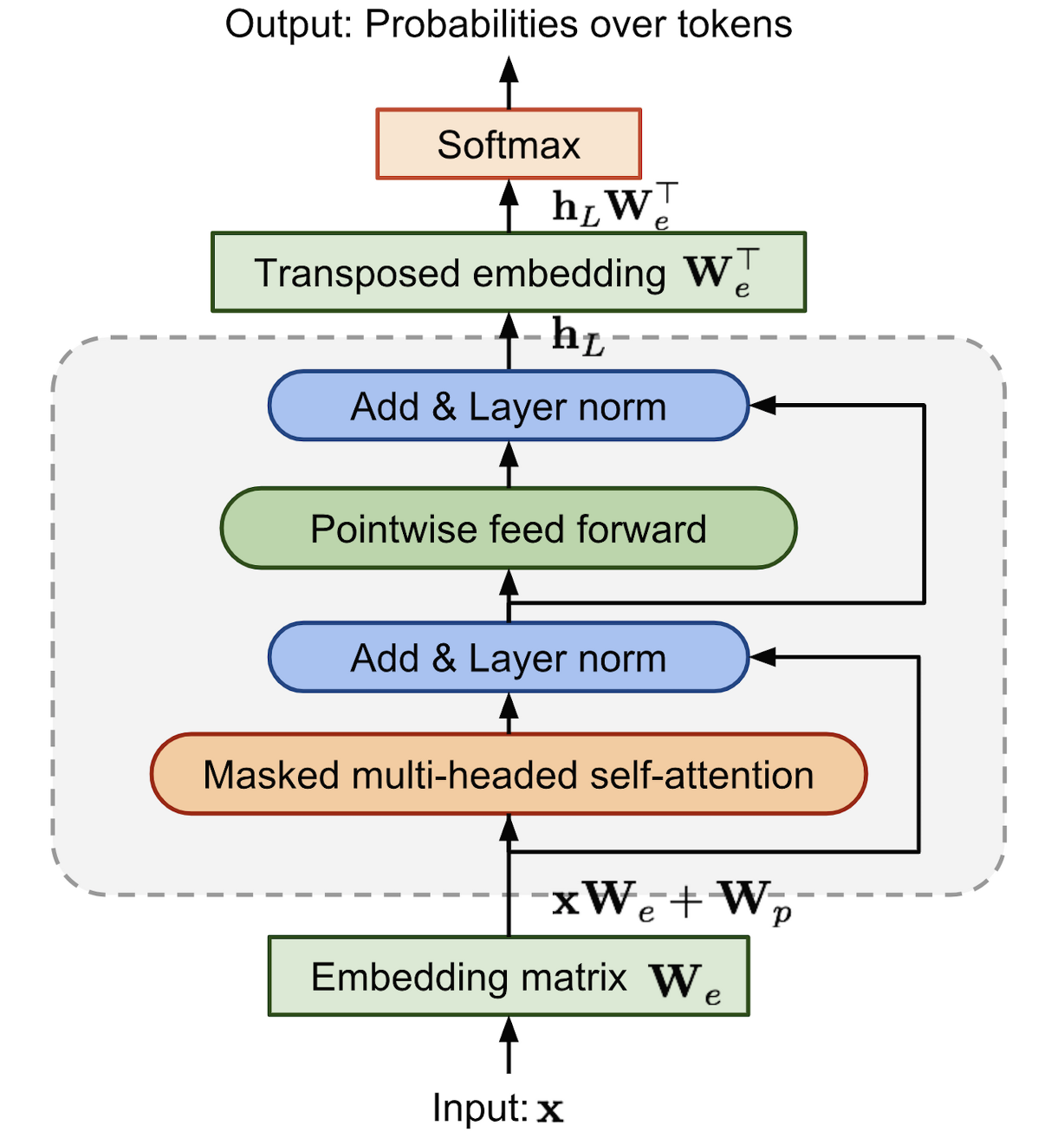
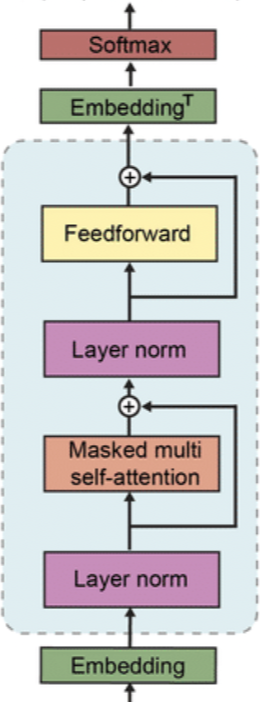
- Transformer 기반의 구조를 Language Model에 사용하며, GPT-1의 구조를 대부분 따릅니다. 단 특정 부분에서 차이점이 있습니다.
- Layer Normalization block이 각 sub block의 input으로 옮겨졌습니다.
- 마지막 self-attention 블록 이후에도 추가적인 레이어 정규화를 추가했습니다.
- 모델 깊이에 따른 residual path의 누적에 따른 초기화 방법이 변경되었습니다.
- N이 residual layer일 때, residual layer의 가중치에 로 초기화합니다.
- 어휘 크기가 50,257로 확장되었고, context size가 512~1024개, batch size가 512개로 증가했습니다.
- 순서대로 GPT-1, GPT-2 아키텍처 이미지입니다.
3. Experiments
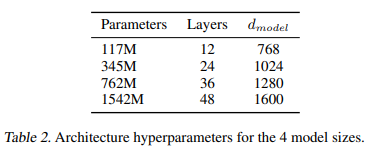
- 4개의 언어 모델로 구분해서 실험을 진행했습니다.
- 가장 작은 모델은 원래 GPT와 동일합니다.
- 두번째로 작은 모델은 와 동일합니다.
- 가장 큰 모델인 GPT-2는 GPT보다 한 단계 더 큰 파라미터를 가지고 있습니다.
- 모든 모델은 WebText에 대해 Underfit되었으며, 학습 시간이 길어질수록, 성능이 증가할 가능성이 존재합니다.
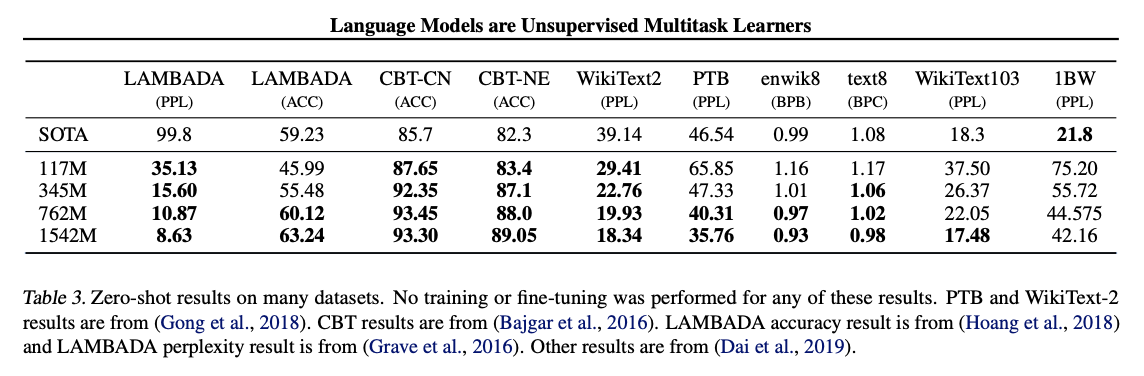
성능 평가
- Language Modeling
- WebText LM에 따라 데이터셋의 로그 확률을 계산하고 정규화된 단위 수로 나눔으로써 동일한 양을 평가합니다.
- GPT-2는 BPE를 적용했기에, 기존에 존재하는 벤치마크 데이터셋에 자유롭게 적용이 가능하며, 는 40억번 중 26번밖에 나타나지 않았습니다.
- GPT-2 결과, 2.5~5의 perplexity가 도출되었으며, 어떤 Fine-tuning도 없이 Zero-shot 환경에서 8개 중 7개에서 SOTA를 달성했습니다.
💡Perplexity
- 적인 언어 모델의 평가 지표
- 이 다음 단어를 예측하는 데 얼마나 "확신이 있는지”를 나타냄, 값이 낮을수록 성능이 좋음. (각 단어에 대해 평균적으로 몇 가지의 선택지를 고려하는지)
- 언어 모델이 얼마나 "혼란스럽지 않은지"를 나타내는 지표, 테스트 데이터에서 얼마나 정확히 확률을 할당했는지를 나타내는 지표
→ Perplexity=1이면, 모델이 완벽히 데이터를 예측함.
- Children’s book test
- 품사에 따른 language model의 성능 비교를 위한 데이터셋입니다.
- 빠진 개체나 명사에 대해 예측하도록 구성되어 있으며, 좋은 성능을 보였습니다.
- Accuracy : 89% → 93&
- LAMBADA
- 시스템이 텍스트의 장거리 종속성을 모델링하는 능력을 테스트하빈다.
- 최소 50개의 토큰 컨텍스트가 필요한 문장의 마지막 단어를 예측합니다.
- Perplexity가 99.8 → 8.6으로 대폭 향상되었습니다.
- Winograd Schema Challenge
- 텍스트의 모호성을 해결하여 추론 능력을 평가합니다.
- 기존보다 7%의 향상을 이루었습니다.
- Reading Comprehension
- 독해 능력과, 대화 내용에 따라 질문에 답하는 능력을 평가하며, 4개 중 3개의 base line model을 능가했습니다.
- Summarization
- 요약은 오히려, 점수가 6.4점 하락했습니다.
- Translation
- 성능이 좋게 나온 것은 아니지만, 10mb의 프랑스어 corpus를 활용했다는 점에서 의미가 있습니다.
- Question Answering
- 더 많은 질문에 대한 올바른 답변을 제공하는 것으로 확인되었습니다.
4. Generalization vs Memorization
- GPT-2 모델은 Zero-shot learning으로도 여러 task에서 좋은 성능을 보였습니다.
- 그렇지만, 학습 데이터 양이 많기에, 기존 task의 테스트와 overlap될 가능성 역시 존재합니다.
- Overlap이 크다면, 큰 모델은 결국 모델 파라미터에서 기억하는 내용을 출력할 것입니다.
- WebText 데이터셋과 기존 데이터셋이 크지 않은 overlap을 보였지만, 어느 정도 영향이 있었음을 확인할 수 있습니다.
- 아직은 Underfit 되어있기에, 모델의 크기 증가에 따라 더 개선될 여지가 있습니다.
6. Discussion
- Unsupervised learning에서 더 나아가야 합니다.
- 요약을 제외한 부분에서는 좋은 성능을 보였지만, 요약 부분에서는 일반적인 성능밖에 보여주지 못했습니다. 그렇기에, 아직 사용에는 무리가 있습니다.
- Random보다 성능이 떨어질 우려가 있지만, Zero-shot을 감안하면 좋습니다.
- GPT-2의 성능이 Fine-tuning을 통한 한계가 명확하지 않고, BERT에서 언급된 단방향 표현의 비효율성을 극복할 수 있는 것에 대한 의문에도 아직 물음표입니다.
7. Conclusion
- Language Model이 충분히 크고, 다양한 데이터셋에서 학습된다면, 더 좋은 성능을 보일 것입니다.
- GPT-2는 Zero-shot임에도 8개 중 7개 부분에서 State-of-the-art를 달성했습니다.
- 이는 Language model에서 명시적인 감독 없이도 다양한 작업을 수행하는 방법을 배우기 시작하는 것을 보여줍니다.

추천시스템을 연구하는 대학원생입니다.