
😶🌫️ 메모리
🗃️ 메모리 계층
구조
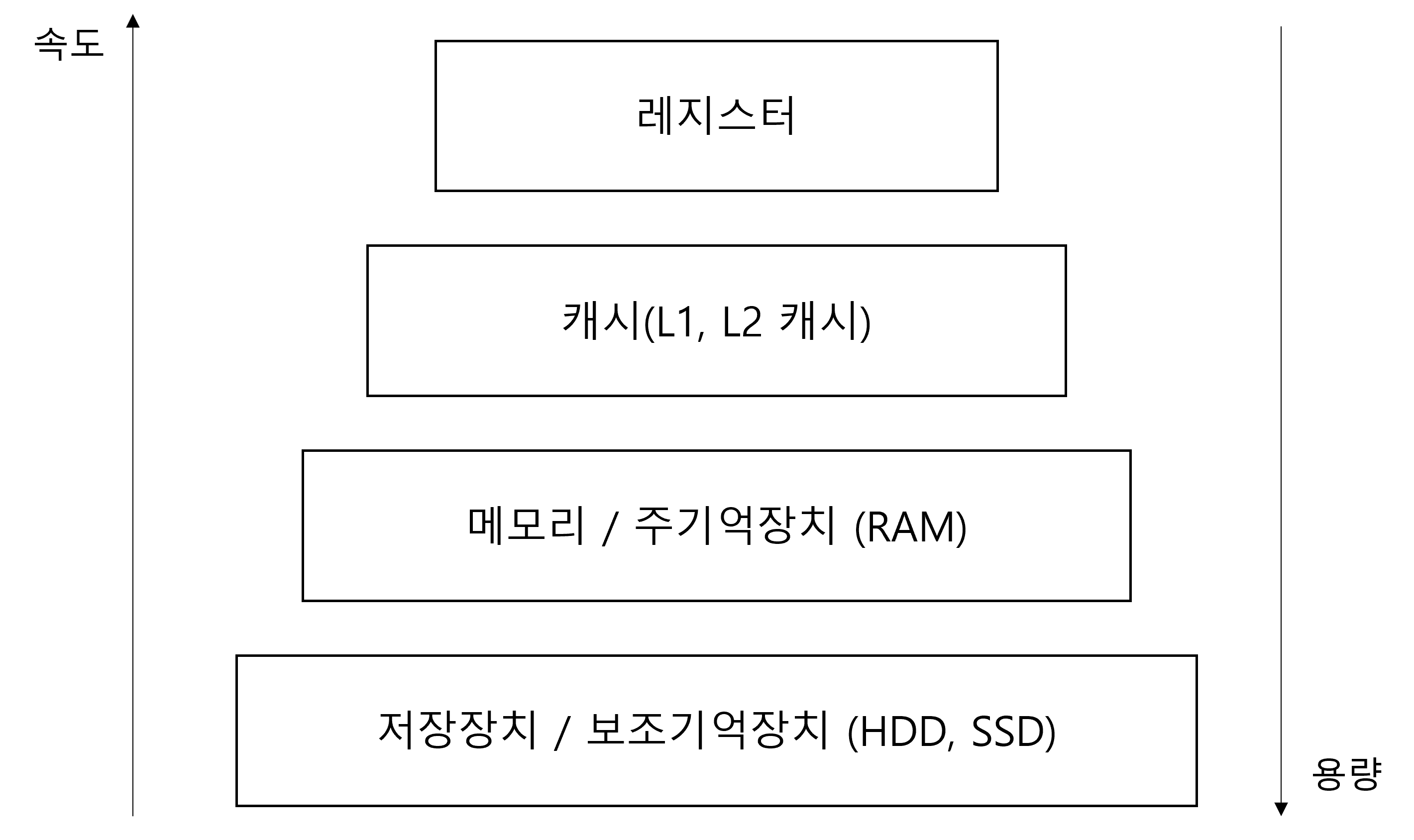
- 레지스터
- CPU 내부의 작은 메모리
- 휘발성
- 속도 가장 빠름
- 기억 용량 가장 적음
- 캐시(L1, L2 캐시)
- 휘발성
- 속도 빠름
- 기억 용량 적음
- L3 캐시도 있음
- 주기억장치(RAM)
- 휘발성
- 속도 보통
- 기억 용량 보통
- 보조기억장치(HDD, SSD)
- 비휘발성
- 속도 느림
- 기억 용량 많음
- 계층이 있는 이유 = 경제성, 지역성
- 경제성
- 윗 계층으로 갈수록 속도가 빨리지고 용량이 적어지며 가격이 비싸짐.
- 아래 계층으로 갈수록 속도가 느려지고 용량이 많아지며 가격이 싸짐.
- 지역성
- 자주 쓰는 데이터는 계속 자주 쓰임.
- 캐싱 계층을 통해 이를 구현.
- 경제성
캐시(Cache)
데이터를 미리 복사해놓는 임시 저장소이자 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리
- 데이터를 접근하는데 시간이 오래 걸리는 것을 해결
- 다시 계산하는 시간 절약
- 속도 차이를 해결하기 위해 위 계층과 아래 계층 사이에 있는 계층을 캐싱 계층이라고 함.
- CPU와 메모리 사이의 레지스터
- 캐시 메모리와 보조기억장치 사이에 있는 주기억장치
지역성의 원리
- 자주 사용하는 데이터에 대한 근거
- 시간 지역성과 공간 지역성이 있음.
시간 지역성(Temporal Locality)
최근 사용한 데이터에 다시 접근하려는 특성
- for 문에서 변수 i에 계속해서 접근이 이루어짐.
공간 지역성(Spatial Locality)
최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하려는 특성
- 배열을 순회할 때 인접한 배열의 각 요소에 대한 접근이 이루어짐.
캐시히트, 캐시미스
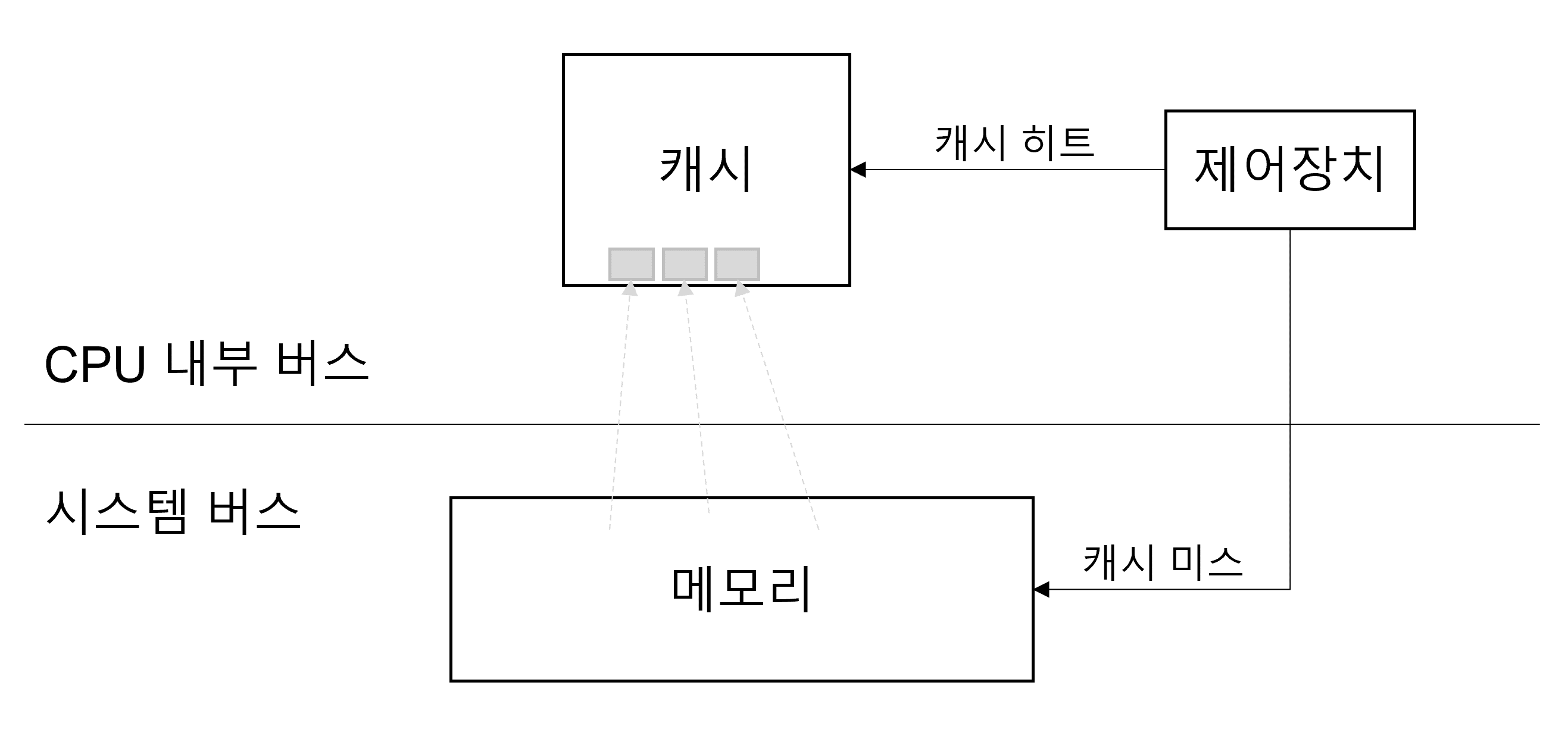
- 캐시히트
- 캐시에서 원하는 데이터를 찾은 것
- 위치가 가깝고 CPU 내부 버스를 기반으로 작동하기 때문에 빠름.
- 캐시미스
- 캐시에 원하는 데이터가 없어서 주기억장치에서 데이터를 찾아오는 것
- 시스템 버스를 기반으로 작동하기 때문에 느림.
캐시 매핑
캐시가 히트되기 위해 매핑하는 방법. CPU의 레지스터와 주 메모리(RAM) 간의 데이터를 주고받을 때 사용
- 직접 매핑(Directed Mapping)
- 메모리와 캐시의 주소를 순서대로 매핑하는 방법
- 메모리 1~100, 캐시 1~10 일 때 1:1~10, 2:11~20 형태로 매핑
- 처리가 빠르지만 충돌 발생이 잦음.
- 연관 매핑(Associative Mapping)
- 순서를 일치시키지 않고 관련 있는 캐시와 메모리를 매핑하는 방법
- 충돌이 적지만 모든 블록을 탐색해야 하기 때문에 속도가 느림.
- 집합 연관 매핑(Set Associative Mapping)
- 직접 매핑과 연관 매핑을 합친 것.
- 순서를 일치시키되 집합을 둬서 저장하는 방식
- 블록화되어 있기 때문에 검색이 조금 더 효율적임.
- 메모리 1~100, 캐시 1~10일 때 캐시 1~5에는 메모리 1~50의 데이터를 무작위로 저장
웹 브라우저의 캐시
- 대표적인 소프트웨어적인 캐시
- 사용자의 커스텀 정보, 인증 모듈 관련 사항 등 저장
- 아이덴티티나 중복 요청 방지를 위해 사용됨.
- 쿠키
- 만료기한이 있는 키-값 저장소
- same site 옵션을 strict로 설정하지 않았을 경우 다른 도메인에서 요청했을 때 자동 전송됨.
- 4KB까지 데이터 저장 가능
- 클라이언트나 서버에서 만료기한을 정할 수 있음.(보통 서버에서 정함)
- document.cookie로 쿠키를 볼 수 없게 httponly 옵션을 거는 것이 중요
- 로컬 스토리지
- 만료기한이 없는 키-값 저장소
- 10MB까지 데이터 저장 가능
- 웹 브라우저를 닫아도 유지됨.
- 도메인 단위로 저장 / 생성 됨.
- HTML5를 지원하지 않는 웹 브라우저에서는 사용할 수 없음.
- 클라이언트에서만 수정 가능
- 세션 스토리지
- 만료 기한이 없는 키-값 저장소
- 탭 단위로 생성, 탭을 닫으면 삭제됨.
- 5MB까지 데이터 저장 가능
- HTML5를 지원하지 않는 웹 브라우저에서는 사용할 수 없음.
- 클라이언트에서만 수정 가능
데이터베이스의 캐싱 계층
메인 데이터베이스 위에 레디스(redis) 데이터베이스 계층을 캐싱 계층으로 두어 성능을 향상시키기도 함.
🔍 메모리 관리
가상 메모리(Virtual Memory)
컴퓨터가 실제로 이용 가능한 메모리 자원을 추상화하여 사용자들에게 매우 큰 메모리로 보이게 만드는 것
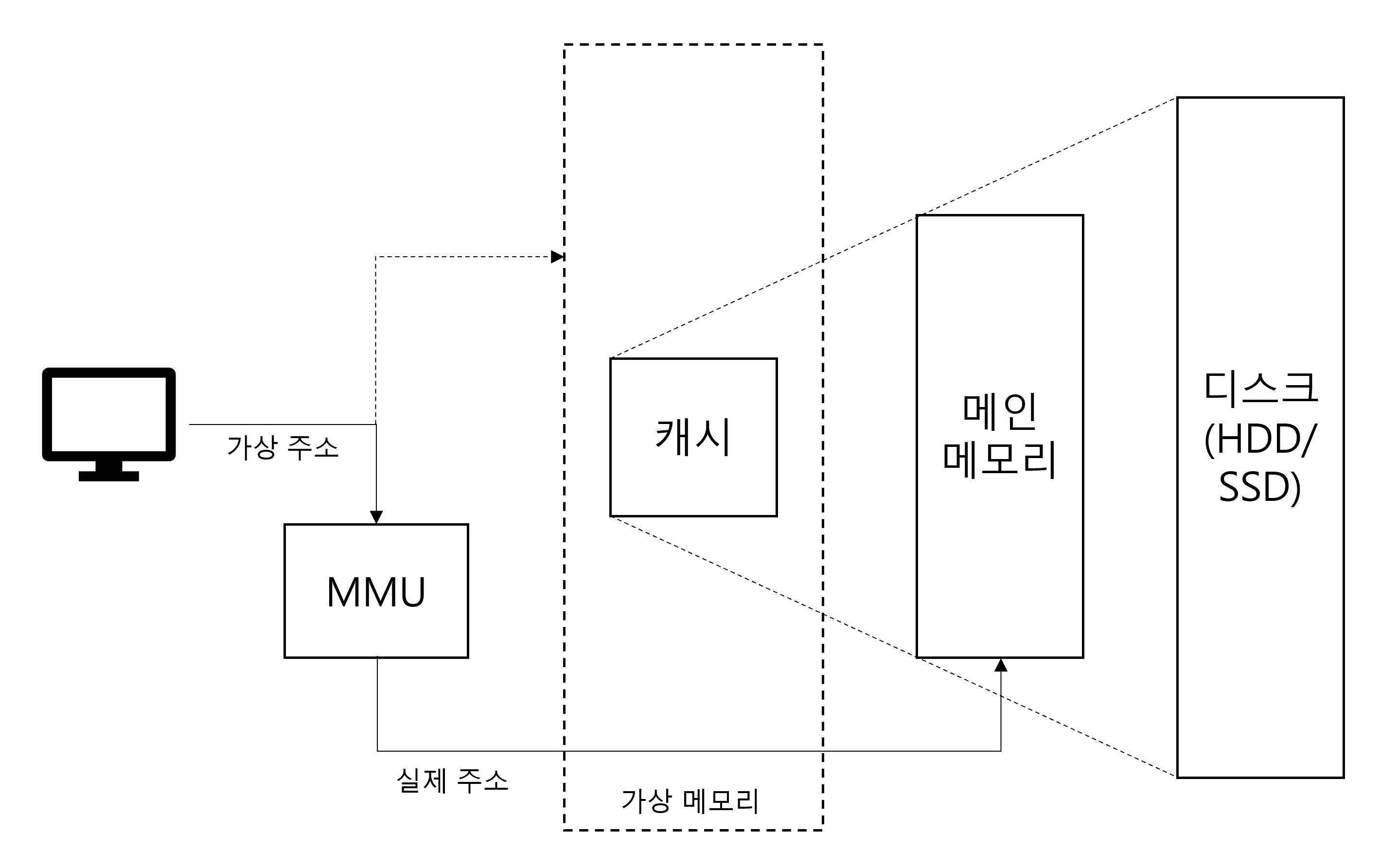
- 가상 주소가 메모리관리장치(MMU)에 의해 실제 주소로 변환됨.
-> 사용자는 실제 주소를 의식할 필요 없이 프로그램을 구축할 수 있게 됨. - 가상 메모리는 가상 주소와 실제 주소가 매핑되어 있고 프로세스의 주소 정보가 들어있는 페이지 테이블로 관리됨.
-> 속도 향상을 위해 TLB 사용.
가상 주소(Logical Address)
가상적으로 주어진 주소
실제 주소(Physical Address)
실제 메모리상에 있는 주소
TLB
- 메모리와 CPU 사이에 있는 주소 변환을 위한 캐시.
- 페이지 테이블에 있는 리스트를 보관
- CPU가 페이지 테이블까지 가지 않도록 해 속도를 향상시킴.
메모리 할당
시작 메모리 위치, 메모리의 할당 크기를 기반으로 할당함.
연속 할당
메모리에 연속적으로 공간을 할당하는 것
- 고정 분할 방식(Fixed partition allocation)
- 메모리를 미리 나누어 관리하는 방식
- 내부 단편화 발생
- 가변 분할 방식(Variable Partition Allocation)
- 매 시점 프로그램의 크기에 맞게 동적으로 메모리를 나눠 사용하는 방식
- 내부 단편화는 발생하지 않지만 외부 단편화 발생 가능
- 최초적합(First Fit)
- 위쪽이나 아래쪽부터 시작해서 홀을 찾으면 바로 할당
- 최적적합(Best Fit)
- 프로세스의 크기 이상인 공간 중 가장 작은 홀부터 할당
- 최악적합(Worst Fit)
- 프로세스의 크기와 가장 많이 차이가 나는 홀에 할당
-
내부 단편화(Internal Fragmentation)
- 메모리를 할당할 때 프로세스가 필요한 양보다 더 큰 메모리가 할당되어서 프로세스에서 사용하는 메모리 공간이 낭비되는 상황.
-
외부 단편화(External Fragmentation)
- 메모리가 할당되고 해제되는 작업이 반복될 때 생긴 사용하지 않는 작은 메모리가 많아져서 총 메모리 공간은 충분하지만 실제로 할당할 수 없는 상황.
-
홀
- 할당할 수 있는 비어 있는 메모리 공간
불연속 할당
메모리를 연속적으로 할당하지 않는 것
- 현대의 운영체제가 사용하는 방법.
페이징(Paging)
- 동일한 크기의 페이지 단위로 나누어 메모리의 서로 다른 위치에 프로세스를 할당하는 방식.
- 동일한 크기의 페이지 단위로 나누었기 때문에 외부 단편화가 없어짐.
- 내부 단편화는 여전히 존재.
- 주소 변환이 복잡해짐.
세그멘테이션(Segmentation)
- 페이지 단위가 아닌 세그먼트(Segment)라는 의미 단위로 나누는 방식.
- 프로세스의 코드와 데이터 등을 이를 기반으로 나누거나 함수 단위로 나눌 수 있음.
- 공유와 보안 측면에서 좋음.
- 세그멘테이션 크기에 맞는 공간에 할당하기 때문에 내부 단편화가 발생하지 않음.
- 외부 단편화가 여전히 존재.
페이지드 세그멘테이션(Paged Segmentation)
- 공유나 보안을 의미 단위의 세그먼트로 나누고, 물리적 메모리는 페이지로 나누는 방식.
페이지 폴트와 스와핑
페이지 폴트(Page Fault)
프로세스의 주소 공간(가상 메모리)에는 존재하지만 지금 이 컴퓨터의 RAM(물리 메모리)에는 없는 데이터에 접근했을 경우 발생하는 것.
- 페이지 폴트가 일어나면 CPU 이용률이 낮아짐.
스와핑(Swaping)
당장 사용하지 않는 영역을 하드디스크로 옮겨 필요할 때 다시 RAM으로 불러와 올리고, 사용하지 않으면 다시 디스크로 내림을 반복하여 RAM을 효과적으로 관리하는 방법.
페이지 폴트를 해결하는 과정(요구 페이징)
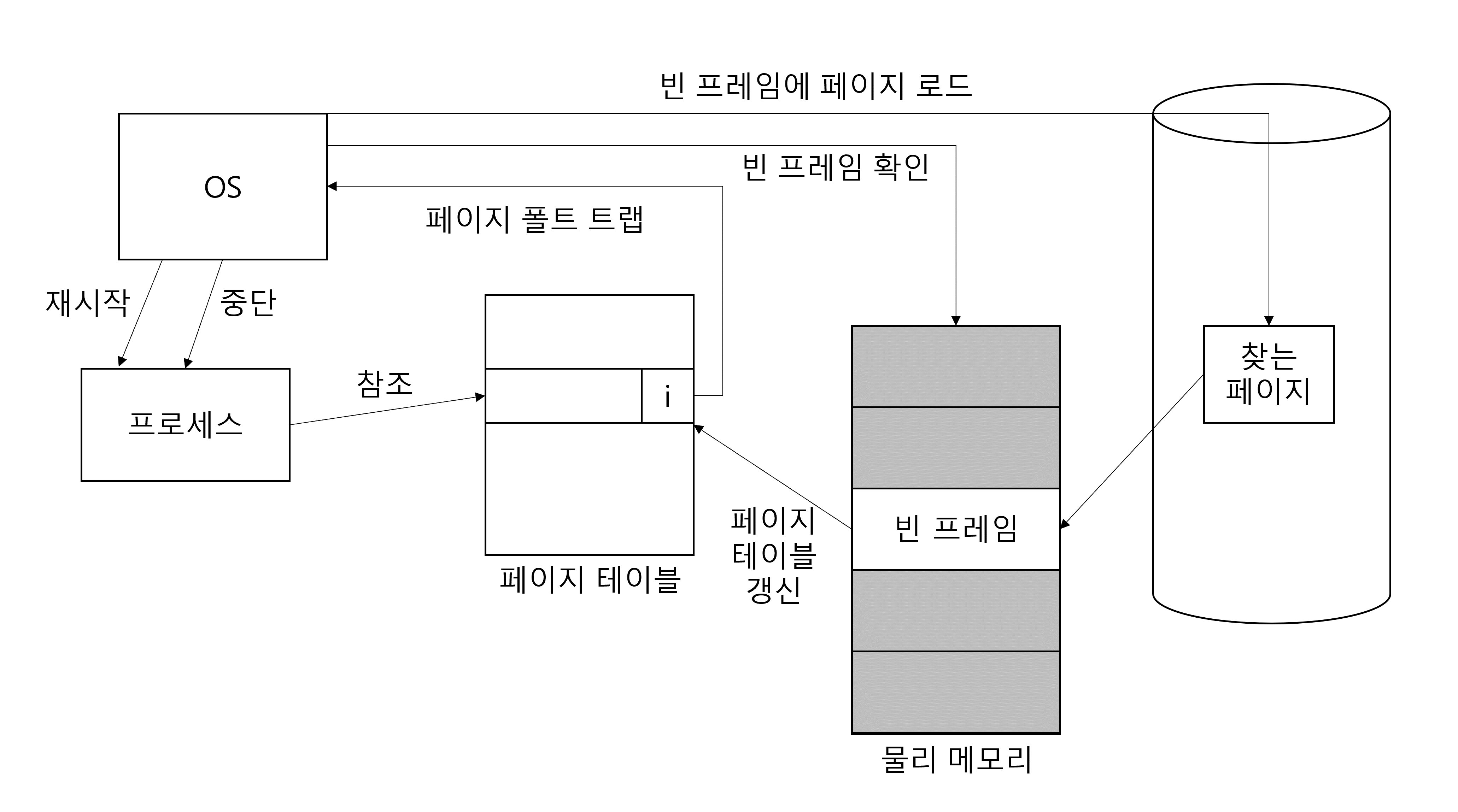
- 프로세스가 페이지 테이블을 참조하여 페이지 폴트일 경우 트랩을 발생시켜 운영체제에 알림.
- 운영체제가 프로세스의 동작을 잠시 멈춤.
- 운영체제가 물리 메모리에 빈 프레임이 있는지 확인함. 빈 프레임이 없다면 스와핑 발생
- 비어있는 프레임에 해당 페이지를 로드하고 페이지 테이블을 최신화함.
- 중단 되었던 프로세스를 다시 시작함.
- 페이지(Page)
- 가상 메모리를 사용하는 최소 크기 단위
- 프레임(Frame)
- 실제 메모리를 사용하는 최소 크기 단위
스레싱(Thrashing)
메모리의 페이지 폴트율이 높은 것.
- 컴퓨터의 심각한 성능 저하를 초래함.
- 메모리에 너무 많은 프로세스가 동시에 올라갔을 때 스와핑이 많이 일어나서 발생.
- 페이지 폴트로 인해 CPU 이용률이 낮아지고, 운영체제가 CPU 가용성을 높이기 위해 더 많은 프로세스를 메모리에 올리는 것이 반복되며 스레싱 발생.
해결 방법
- 메모리 늘리기
- HDD를 SSD로 변경
- 운영체제에서 해결
- 작업세트
- PFF
작업 세트(Working Set)
프로세스의 과거 사용 이력인 지역성(Locality)을 통해 결정된 페이지 집합을 만들어서 미리 메모리에 로드하는 것.
- 탐색에 드는 비용과 스와핑을 줄일 수 있음.
PFF(Page Fault Frequency)
페이지 폴트 빈도를 조절하는 방법으로 상한선과 하한선을 만드는 것.
- 상한선에 도달하면 페이지를 늘림.
- 하한선에 도달하면 페이지를 줄임.
페이지 교체 알고리즘
페이지 교체 알고리즘을 기반으로 스와핑이 일어나며, 스와핑이 많이 일어나지 않도록 하는 것이 목적.
오프라인 알고리즘(Offline Algorithm)
- 먼 미래에 참조되는 페이지와 현재 할당하는 페이지를 바꾸는 알고리즘으로 가장 좋은 방법.
- 미래에 사용될 프로세스를 알 방법이 없으므로 사용할 수 없는 알고리즘.
- 다른 알고리즘과의 성능 비교에 대한 기준이 됨.
FIFO(First In First Out)
- 가장 먼저 온 페이지를 교체 영역에 가장 먼저 놓는 방법.
LRU(Least Recently Used)
- 참조된지 가장 오래된 페이지를 바꾸는 방법.
- 오래된 것을 파악하기 위해 각 페이지마다 계수기, 스택을 두어야 하는 문제점이 있음.
- 이중 연결 리스트와 해시 테이블을 이용해 구현
- 이중 연결 리스트
- 한정된 메모리를 표현
- 해시 테이블
- 이중 연결 리스트에서 빠르게 찾을 수 있도록 하기 위해 사용
NUR(Not Used Recently)
-
LRU에서 발전한 알고리즘.
-
최근에 사용하지 않은 페이지를 교체하는 알고리즘.
-
최근 사용여부를 파악하기 위해 각 페이지마다 두 개의 비트를 둠.(참조 비트(Reference Bit), 변형 비트(Modified Bit))
-
참조 비트가 0이면 호출되지 않음, 1이면 호출됨을 나타냄.
-
변형 비트가 0이면 페이지 내용이 변경되지 않음, 1이면 변경됨을 나타냄.
-
교체 순서는 아래와 같음.
| 참조 비트 | 변형 비트 | 교체 순서 |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 2 |
| 1 | 0 | 3 |
| 1 | 1 | 4 |
LFU(Least Frequently Used)
- 가장 참조 횟수가 적은 페이지를 교체하는 알고리즘.
참고
