

[챗GPT와 랭체인을 활용한 LLM 기반 AI 앱 개발] 책을 읽고 스터디한 내용을 정리했습니다.
LLM은 Large Language Model의 약자로, 대형 언어 모델을 의미합니다. 이는 방대한 양의 텍스트 데이터를 기반으로 학습된 인공지능 모델로, 자연어 처리(NLP) 작업을 수행하는 데 사용됩니다.
자연어 처리(NLP, Natural Language Processing)
1. 개념
자연어 처리(NLP, Natural Language Processing)는 인간이 사용하는 언어를 컴퓨터가 이해하고 처리할 수 있도록 하는 인공지능 기술입니다. 이 기술을 통해 컴퓨터는 텍스트나 음성 데이터를 분석하고, 언어의 의미와 문맥을 파악해 번역, 음성 인식, 감정 분석, 자동 요약 등 다양한 작업을 수행할 수 있습니다.
2. 전처리 기술
자연어 처리의 첫 단계는 원본 텍스트 데이터를 분석 가능한 형태로 변환하는 전처리 과정입니다. 이를 통해 텍스트를 모델에 적합하게 변환하여, 정확한 결과를 도출할 수 있습니다. 주요 전처리 기술은 아래와 같습니다.
2.1 토큰화(Tokenization)
- 개념: 텍스트를 단어나 구처럼 더 작은 단위(토큰)로 나누는 과정입니다.
- 예시:
- 문장: "I am learning NLP."
- 토큰화 결과: ["I", "am", "learning", "NLP", "."]
- 이유: 컴퓨터는 문장을 하나의 덩어리로 처리할 수 없으므로, 텍스트를 의미 단위로 나누어야 합니다. 이렇게 분리된 토큰은 각 단어의 의미를 개별적으로 분석하는 데 사용됩니다.
2.2 형태소 분석 및 표제어 추출(Lemmatization)
- 개념: 단어의 변형된 형태(시제, 복수형 등)를 기본 형태로 변환하는 과정입니다. 이를 통해 단어의 의미를 통일된 방식으로 처리할 수 있게 합니다.
- 예시:
- "running" → "run"
- "better" → "good"
- 이유: 동일한 단어가 다양한 형태로 표현되더라도 의미는 같으므로, 기본 형태로 변환하면 분석과 해석이 더 용이해집니다.
2.3 불용어 제거(Stopword Removal)
- 개념: 분석에 큰 영향을 미치지 않는 불필요한 단어들을 제거하는 과정입니다. 빈도가 높은 "the", "and", "with" 같은 단어들이 여기에 해당합니다.
- 예시:
- 문장: "I am learning NLP with a book."
- 정지 단어 제거 결과: ["learning", "NLP", "book"]
- 이유: 정지 단어는 문장에서 자주 등장하지만, 실제로 중요한 의미를 전달하지 않기 때문에 분석의 효율성을 높이기 위해 제거됩니다.
LLM의 2가지 모델
1.LLMs
- 개념: 일반적인 대규모 언어 모델로, 하나의 텍스트 입력에 대해 하나의 텍스트 출력을 반환하는 방식입니다.
- 예시: "프랑스의 수도는 어디인가요?”라고 입력하면, "파리"라는 응답을 받습니다.
from langchain.llms import OpenAI
# OpenAI LLM 객체 생성
llm = OpenAI(api_key="{YOUR_API_KEY}")
# 텍스트 입력
input_text = "프랑스의 수도는 어디인가요?"
# 모델 호출하여 응답 생성
output = llm(input_text)
# 결과 출력
print(output)2.Chat Models (채팅 모델)
- 개념: 대화 형식의 입력을 처리하는 모듈로, 질문과 답변이 반복되는 대화를 시뮬레이션합니다. 이 모델은 대화의 흐름을 자연스럽게 유지하며, 메시지는 주로 내용과 역할이라는 두 가지 요소로 구성됩니다.
- 예시: 사용자가 "안녕하세요, 기분이 어떠세요?"라고 입력하면, 모델은 "안녕하세요! 저는 잘 지내고 있습니다. 당신은요?"와 같은 자연스러운 응답을 생성합니다.
- 유형:
- SystemMessage: 시스템이 AI 모델에게 특정 작업을 지시하거나 설정을 조정하는 메시지입니다. 예를 들어, 대화의 톤을 정하거나 추가 질문을 포함하도록 지시합니다.
- 예시: 시스템이 모델에게 "응답은 친근하게 작성하고, 추가로 사용자에게 질문도 포함시켜 주세요."라는 지시를 보냅니다.
- HumanMessage: 사용자가 입력한 질문이나 요청입니다.
- 예시: 사용자가 "좋은 식당 추천해 주실 수 있나요?"라고 입력합니다.
- AIMessage: AI가 사용자에게 제공하는 답변이나 정보입니다. 모델이 SystemMessage의 지시에 따라 응답을 작성합니다.
- 예시: 시스템의 지시에 따라 모델이 "시내에 새로 생긴 이탈리안 레스토랑이 좋습니다. 최근에 가보셨나요?"라는 응답을 생성합니다.
- SystemMessage: 시스템이 AI 모델에게 특정 작업을 지시하거나 설정을 조정하는 메시지입니다. 예를 들어, 대화의 톤을 정하거나 추가 질문을 포함하도록 지시합니다.
from langchain.chat_models import ChatOpenAI
from langchain.schema.messages import HumanMessage, SystemMessage, AIMessage
# ChatOpenAI 객체 생성
chat = ChatOpenAI(openai_api_key="{YOUR_API_KEY}")
# 대화 메시지 정의
messages = [
SystemMessage(content="응답은 친근하게 작성하고, 추가로 사용자에게 질문도 포함시켜 주세요."),
HumanMessage(content="좋은 식당 추천해 주실 수 있나요?"),
]
# 모델 호출
aiMessage = chat.invoke(messages)
# AI의 응답 출력
print(aiMessage.content)Callback
- 개념: 콜백은 모델이 작업을 처리하는 동안 특정 시점에 자동으로 실행되는 추가 작업이나 처리를 정의하는 기능입니다. 주로 작업의 진행 상태를 모니터링하거나 특정 이벤트에 반응하기 위해 사용됩니다.
- 예시
- 로그 기록: 작업의 시작, 진행, 완료 상태를 자동으로 기록합니다.
python 코드 복사 from langchain.callbacks import CallbackHandler class LogCallback(CallbackHandler): def on_start(self, **kwargs): print("작업이 시작되었습니다.") def on_end(self, **kwargs): print("작업이 완료되었습니다.") # 콜백 사용 예 callback = LogCallback() # 콜백을 모델에 전달 model = ChatOpenAI(api_key="{YOUR_API_KEY}", callbacks=[callback]) - 특정 이벤트 반응: 모델이 새로운 텍스트를 생성할 때마다 특정 처리를 자동으로 실행합니다.
python 코드 복사 from langchain.callbacks import CallbackHandler class WordLoggerCallback(CallbackHandler): def on_new_token(self, token, **kwargs): print(f"새로운 토큰: {token}") # 콜백 사용 예 callback = WordLoggerCallback() # 콜백을 모델에 전달 model = ChatOpenAI(api_key="{YOUR_API_KEY}", callbacks=[callback])
- 로그 기록: 작업의 시작, 진행, 완료 상태를 자동으로 기록합니다.
PromptTemplate
개념: 프롬프트 템플릿은 모델에 제공하는 입력(프롬프트)을 일정한 형식으로 미리 준비해 두는 것입니다. 이를 통해 일관된 입력을 제공하고, 모델의 응답을 더욱 정확하게 조절할 수 있습니다.
예시:
from prompt_toolkit import PromptTemplate
# 고객의 이름과 문의 사항을 받기 위한 템플릿 정의
template = PromptTemplate("""안녕하세요, {고객_이름}님!
저희에게 문의해주셔서 감사합니다. 다음은 고객님이 남기신 문의 사항입니다:
"{문의_내용}"
저희가 곧 답변을 드리겠습니다. 감사합니다!""")
# 변수에 실제 값을 넣어 템플릿 채우기
filled_prompt = template.fill(고객_이름="홍길동", 문의_내용="제품의 배송 상태에 대해 알고 싶습니다.")
print(filled_prompt)Few-shot prompt
- 개념: AI에게 몇 가지 예시를 제공하여 특정 작업을 수행하게 도와주는 방법입니다. 모델이 주어진 예시를 참고하여 새로운 입력에 대해 더 정확하고 일관된 응답을 생성할 수 있습니다.
- 예시:
- 입력: "다음 문장을 긍정적으로 바꿔주세요."
- 예시 1:
- 원문: "오늘 날씨가 나빠요."
- 변환: "오늘 날씨가 상쾌해요."
- 예시 2:
- 원문: "이 영화는 재미없어요."
- 변환: "이 영화는 독특한 스타일을 가지고 있어요."
- 새로운 입력: "이 책은 지루해요."
- 예상 출력: "이 책은 깊이 있는 내용이 담겨 있어요."
Example Selector (예제 선택기)
- 개념: Example Selector는 모델에 제공할 예제를 선택하는 기능입니다. 사용자가 입력한 내용에 따라 적절한 예제를 자동으로 선택하여, 모델이 더 나은 응답을 생성할 수 있도록 도와줍니다.
- 예시
- 길이로 예제 선택하기 (Select Examples by Length)
- 개념: 길이에 따라 사용할 예제를 선택합니다. 보통 입력 토큰 길이의 제약이 있기 때문에, 긴 입력의 경우 포함할 예제를 적게 선택하고 짧은 입력의 경우 포함할 예제를 더 많이 선택합니다.
- 의미적 유사성으로 예제 선택하기 (Select Examples by Semantic Similarity)
- 개념: 입력된 텍스트와 의미적으로 가장 유사한 예제를 선택하는 방법입니다.
- 의미적 n-그램 중복으로 예제 선택하기 (Select Examples by Semantic N-gram Overlap)
- 개념: 입력된 텍스트와 예제 간의 의미적 n-그램(연속된 n개의 단어) 중복을 기반으로 예제를 선택하는 방법입니다.
- 최대 한계 관련성으로 예제 선택하기 (Select Examples by Maximal Marginal Relevance, MMR)
- 개념: 입력과 관련성이 높으면서도 서로 간에 다양성을 가진 예제들을 선택하는 방법입니다.
- LangSmith Few-Shot 데이터셋에서 예제 선택하기 (Select Examples from LangSmith Few-Shot Datasets)
- 개념: LangSmith에서 제공하는 Few-Shot 학습용 데이터셋에서 적절한 예제를 선택하는 방법입니다.
- 길이로 예제 선택하기 (Select Examples by Length)
- 참고링크
Output Parsers
-
개념: Output Parsers는 LLM의 출력을 구조화된 형식으로 변환하는 도구입니다. 이를 통해 모델의 응답을 더 쉽게 처리하고 활용할 수 있습니다.
-
예시:
- 출력 포맷 변경: 모델의 출력을 사용자가 원하는 형식으로 변환합니다. 예를 들어, JSON 데이터를 테이블 형식으로 변환합니다.
- 정보 추출: 원시 텍스트에서 필요한 정보를 추출하여 구조화된 데이터를 생성합니다. 예를 들어, 날짜, 이름, 위치 등을 추출합니다.
- 결과 정제: 모델 출력에서 불필요한 정보를 제거하고, 응답을 더 명확하게 만듭니다.
- 조건부 로직 적용: 출력 데이터에 따라 특정 조건을 기반으로 추가 질문을 하거나 다른 모델을 호출합니다.
-
참고 링크
출력 파서 (Output Parser)
Chains
개념: Chains는 랭체인에서 여러 프로세스를 순차적으로 연결하여 복잡한 작업을 수행하는 구조입니다.
예시:
-
LLMChain:
PromptTemplate,Language Model,OutputParser를 연결 -
SimpleSequentialChain - 여러 개의 체인을 연결
-
LLMRouterChain: 체인 분기 실현 가능
Memory
- 개념: Chat API는 stateless하여 대화 상태를 기억하지 않습니다. 메모리는 대화 이력을 저장하고 활용하여, 대화의 흐름을 유지하고 연속적인 응답을 가능하게 합니다.
- 예시
- ConversationBufferMemory: 대화 중의 모든 메시지를 저장하여 대화의 흐름을 유지합니다.
- ConversationBufferWindowMemory: 최근 대화의 일정 부분만 저장하여, 그 구간의 맥락을 유지합니다.
- ConversationTokenBufferMemory: 최근 대화의 히스토리를 버퍼를 메모리에 보관하고, 대화의 개수가 아닌 토큰 길이 를 사용하여 대화내용을 플러시(flush)할 시기를 결정합니다.
- ConversationSummaryBufferMemory: 대화가 진행되는 동안 대화를 요약하고 현재 요약을 메모리에 저장 합니다.
RAG(Retrieval Augmented Generation)
- 개념: AI 모델이 답을 생성할 때, 외부 정보를 가져와서 정확하고 풍성하게 답변하는 기술.
- 실행과정:
1. 외부 데이터 생성- API, 데이터베이스, 문서 리포지토리 등 다양한 소스에서 LLM의 원래 학습 데이터 외부에 있는 새 데이터를 가져옴.
- 데이터는 파일, 데이터베이스 레코드, 긴 텍스트 등 다양한 형식으로 존재하며, 이를 수치로 변환해 벡터 데이터베이스에 저장함.
- 관련 정보 검색
- 사용자 쿼리를 벡터로 변환하고, 벡터 데이터베이스와 매칭함.
- 사용자 쿼리: 사용자가 입력한 질문이나 요청
- 벡터화(Vectorization)
- 텍스트나 단어를 숫자형태로 변환하는 과정
- 컴퓨터는 텍스트를 이해할 수 없기 때문의 숫자의 배열로 바꿔줘야함.
- 예를 들어 "이 약의 부작용은 무엇인가요?"라고 물으면, 관련된 약물 정보와 부작용에 대한 정책 문서를 검색함.
- 사용자 쿼리를 벡터로 변환하고, 벡터 데이터베이스와 매칭함.
- LLM 프롬프트 확장
- 검색된 데이터를 사용자 입력에 추가하여 LLM에 전달함.
- 이렇게 확장된 프롬프트를 통해 LLM이 더 정확한 답변을 생성함.
- 외부 데이터 업데이트
- 외부 데이터가 오래된 경우, 문서를 비동기적으로 업데이트하고 임베딩 표현도 갱신함.
- 임베딩: 데이터(단어,문장,이미지 등)을 고차원 공간에서 저차원 벡터로 변환
- 단어 임베딩: 단어를 벡터로 변환하여 비슷한 의미를 가진 단어들이 가까운 위치에 있도록함. 예를 들어, "고양이"와 "강아지"는 같은 카테고리의 동물이므로 벡터 공간에서 가깝게 위치하게함.
단어 임베딩 벡터 강아지 [0.9, 0.1, 0.5] 고양이 [0.85, 0.15, 0.4] //각 숫자: 벡터의 각 숫자는 해당 단어의 특징을 나타냅니다. //예를 들어, 첫 번째 숫자는 "동물"이라는 카테고리의 관련성을, //두 번째 숫자는 "귀여움" 정도를, //세 번째 숫자는 "상대적인 크기"를 나타낼 수 있습니다. //유사성: 강아지와 고양이의 벡터는 서로 비슷한 값을 가지므로, //ㅜ두 단어가 비슷한 의미를 가지고 있다는 것을 컴퓨터가 이해할 수 있게 됩니다. - 문장 임베딩: 문장을 벡터로 변환하여 문장의 의미를 캡쳐함. 두 개의 문장이 비슷한 의미를 가진다면, 이들의 벡터도 서로 가까운 값을 가짐.
- 단어 임베딩: 단어를 벡터로 변환하여 비슷한 의미를 가진 단어들이 가까운 위치에 있도록함. 예를 들어, "고양이"와 "강아지"는 같은 카테고리의 동물이므로 벡터 공간에서 가깝게 위치하게함.
- 임베딩: 데이터(단어,문장,이미지 등)을 고차원 공간에서 저차원 벡터로 변환
- 이는 자동화된 실시간 프로세스나 주기적 배치 처리를 통해 이뤄짐.
- 외부 데이터가 오래된 경우, 문서를 비동기적으로 업데이트하고 임베딩 표현도 갱신함.
- 이점
- 비용 효율성: RAG는 LLM을 재교육하지 않고도 새로운 데이터에 접근할 수 있어, 도메인별 정보를 제공할 때 시간과 비용을 절감함.
- 최신 정보 제공: RAG를 통해 실시간 데이터와 연결해 최신 정보나 연구를 반영하여 사용자에게 신뢰할 수 있는 정보를 제공.
- 사용자 신뢰 강화: 출처 표시와 인용 기능으로 사용자에게 정확성과 신뢰성을 높인 응답을 제공해, 생성형 AI에 대한 신뢰도를 높임.
📖 벡터화(Vectorization)
- 텍스트나 단어를 숫자형태로 변환하는 과정
- 컴퓨터는 텍스트를 이해할 수 없기 때문의 숫자의 배열로 바꿔줘야함.
Data Connection
- 개념: RAG를 사용하는 LangChain의 모듈로 문서읽기/문서변환/문서벡터화/문서저장/문서검색 등의 역할 수행.
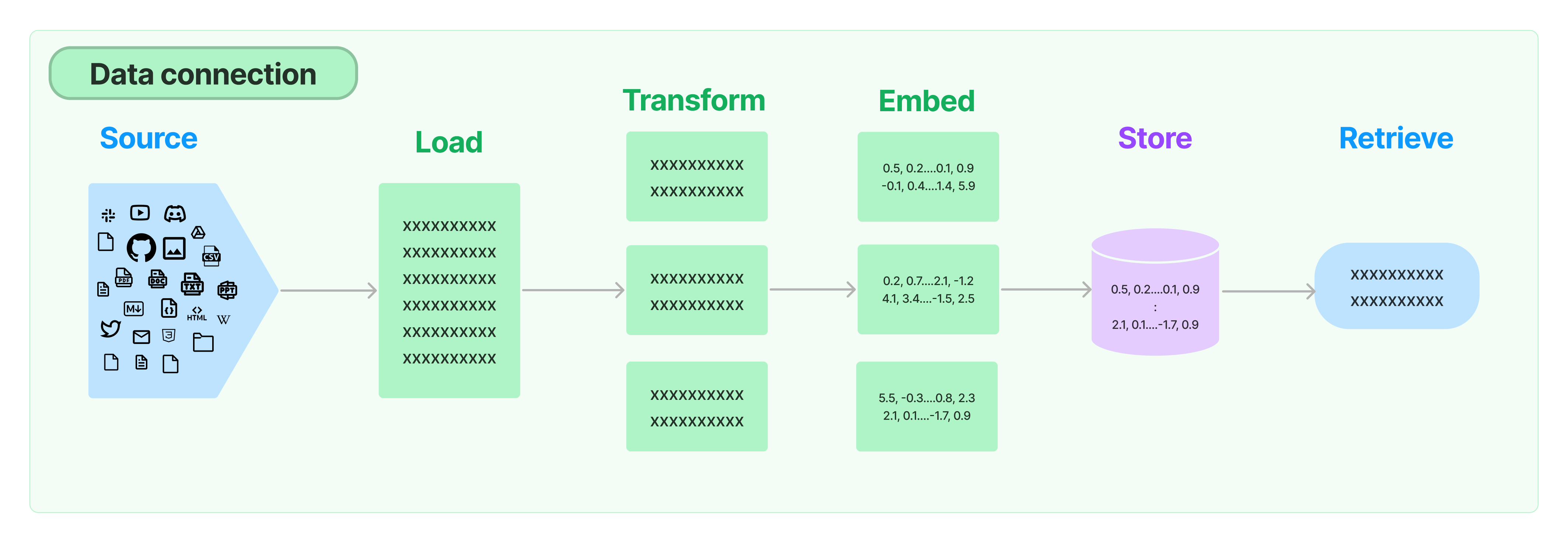
- 역할
- Document Loaders: PDF, TXT, Word 등 다양한 형식의 문서를 로드함.
- Document Transformers: 문서의 내용을 변환하는 기능으로 긴 문서를 분할하고, Q&A형식으로 변환하고, 중복 문서를 삭제 하는 등 정보의 효율성을 높임.
- Text Embedding Models: 텍스트를 벡터화하여 AI가 문서를 검색/분류하는데 사용함.
- Vector Stores: 텍스트 임베딩으로 변환된 벡터를 데이터베이스에 저장함.
- Retrievers: 사용자의 입력에 맞는 정보를 검색하여, 벡터 저장소에서 가장 유사한 벡터를 반환함.
Agents
- 개념: Agents는 AI 에이전트를 구현하기 위한 모듈로, 사용자가 입력한 내용을 바탕으로 적절한 외부도구를 활용하여 작업을 실행함.
- 예시: 사용자가 "특정 폴더의 파일 목록을 나열해줘!"라고 요청하면, Agents는 터미널 명령어를 사용하여 해당 폴더의 파일 목록을 검색하고 결과를 사용자에게 표시할 수 있음.
