[EECS 498-007 / 598-005] 강의정리 - 8강(CS231n 9강) CNN Architectures
[CS231n] + [EECS 498-007 / 598-005]

CNN Architectures
- AlexNet(2012)
1) Model
2) Why this model?
3) Trends - ZFNet: A Bigger AlexNet(2013)
1) Model - VGG: Deeper Networks, Regular Design(2014)
1) Model
2) Why this model?
3) AlexNet vs VGG-16 - GoogLeNet: Focus on Efficiecy(2014)
1) Aggressive Stem
2) Inception Module
3) Global Average Pooling
4) Auxiliary Classifiers - Residual Networks(2015)
1) Background
2) Solution
3) Model
4) Bottleneck Block
5) Power of ResNet
6) Improving Residual Networks: Block Design - Comparing Complexity
- Model Ensembles(2016)
- ResNeXt: Improving ResNets
- Squeeze-and-Excitation Networks(2017)
- Densely Connected Neural Networks
- MobileNets: Tiny Networks(For Mobile Devices)
- Neural Architecture Search
- Summary
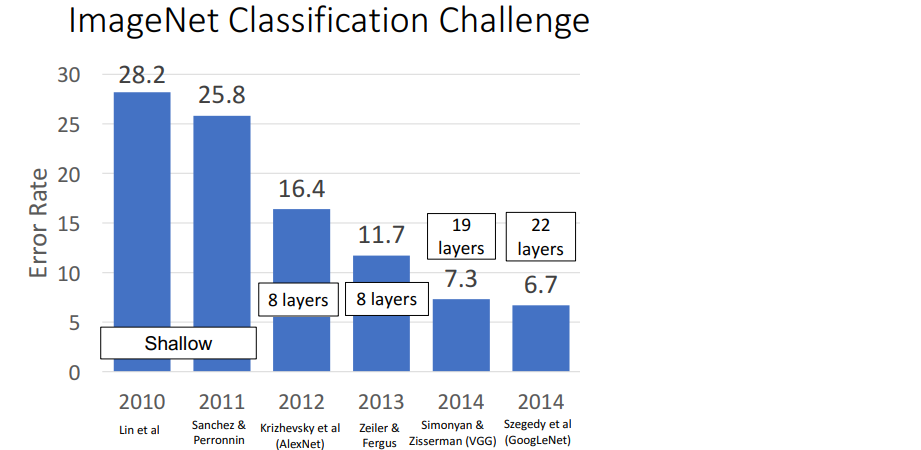
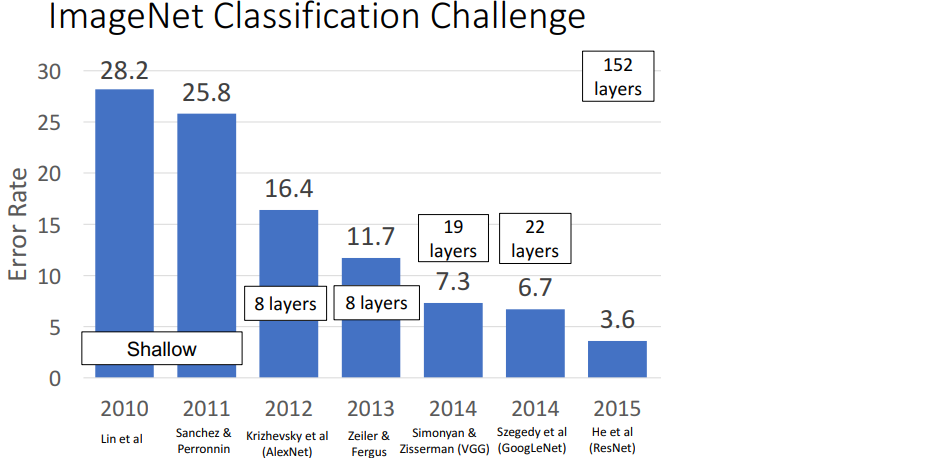
ImageNet Classification Challenge
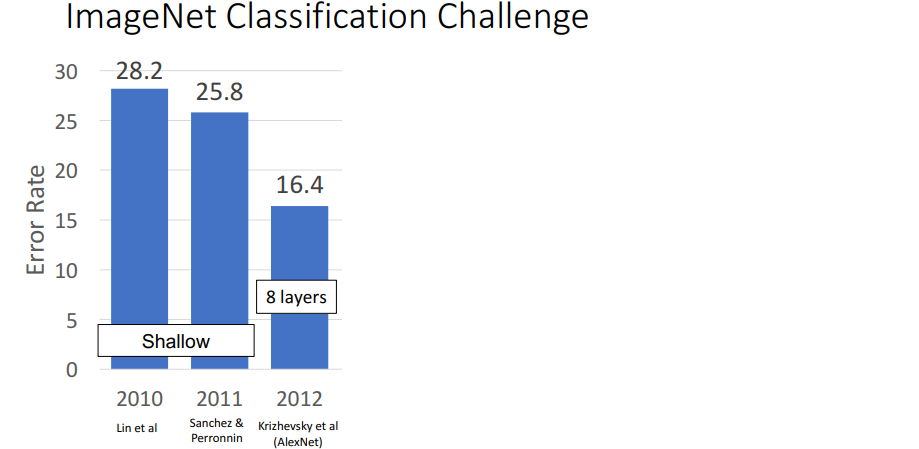 2010년부터 ImageNet 데이터셋 (1.2 million data to classify 1000 categories)을 사용하여 대결하는 챌린지이다. 기존 mlp방식의 방식을 모두 제치고 2012년
2010년부터 ImageNet 데이터셋 (1.2 million data to classify 1000 categories)을 사용하여 대결하는 챌린지이다. 기존 mlp방식의 방식을 모두 제치고 2012년 AlexNet이 굉장한 성능을 보였다.
1. AlexNet(2012)
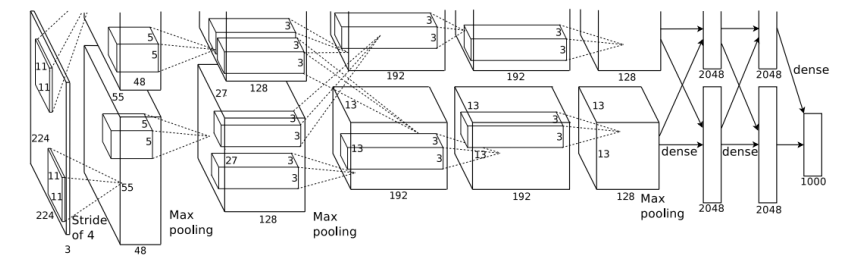
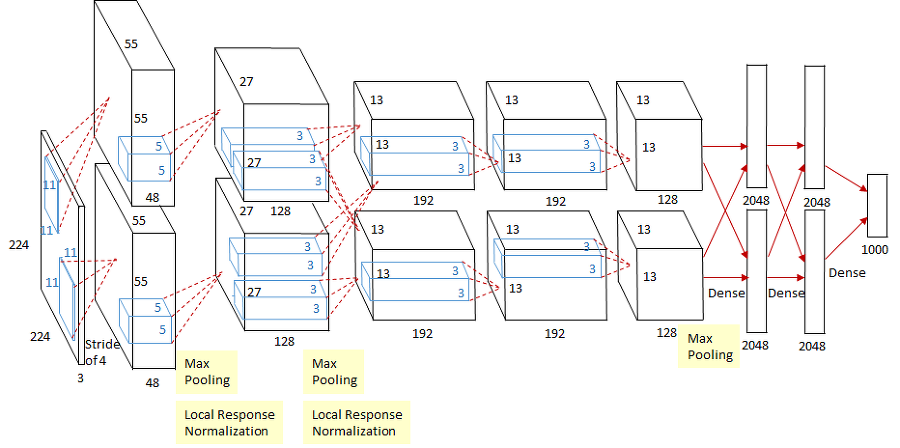
227 x 227 inputs
5 Convolutional layers
Max pooling
3 fully-connected layers
ReLU nonlinearitiesLocal response normalization이라는 normalization을 사용하는데 이는 더이상 사용되지 않고 현재는 보통 batch normalization을 사용한다.
그리고 당시에넌 3GB memory밖에 없는 GTX580이 최신 GPU였기 때문에 Model을 두개의 GPU로 나누어 학습시켰다. 그래서 사진의 Model도 두개로 분리되어있다.
1) Model
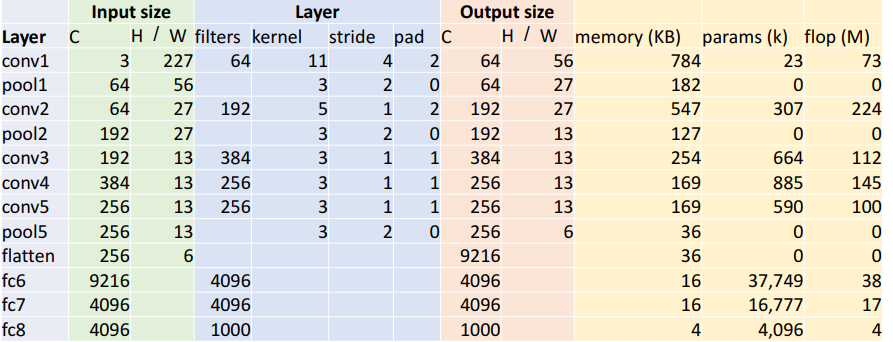 Conv layer 이후헤는 항상(거의)
Conv layer 이후헤는 항상(거의) ReLU등의 non-linearity 함수를 거친다.
첫번째 layer에 대해서만 자세히 들여다 보자.
a. Output size
input이 3 channel, 227 x 227 image이고 Conv1은 64 filters, 11 kernel, 4 stride, 2 pad 이므로 의 output size를 가진다.
b. Memory
Output elements의 개수는 이다.
Bytes per element = 4 (for 32-bit floating point)
따라서 KB = (number of elements) X (bytes per element) / 1024
이다.
c. Params
d. flop(M)
최근 GPU는 multiply + add 를 1 cycle에 수행하므로 이를 묶어서 하나의 floating point operation이라고 한다. 따라서 총 개수는
2) Why this model?
trial and error에 기반...
3) Trends
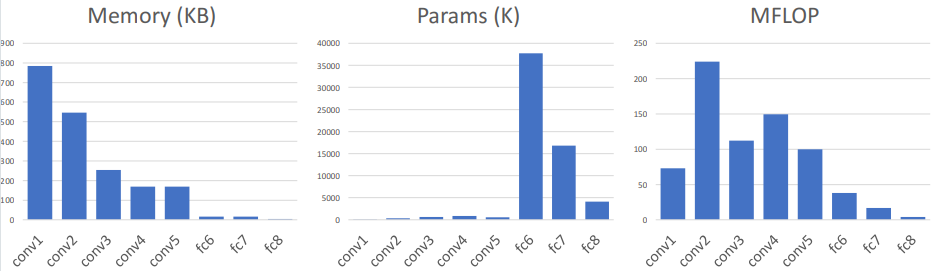
- 대부분의 memory는 초반 convolution layers에서 사용된다.
- 거의 모든 parameters는 fully-connected layers에 있다.
- 대부분의 floating-point ops는 convolution layers에서 발생한다.
2. ZFNet: A Bigger AlexNet(2013)
AlexNet의 bigger 버전이다. 더 많은 trial and error로 AlexNet에서 이것 저것 바꾸어서 더 좋은 성능을 내었다.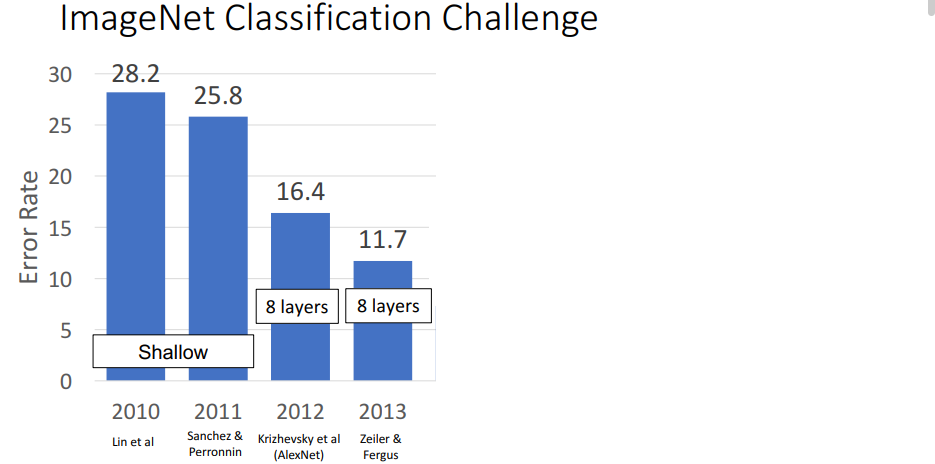
1) Model
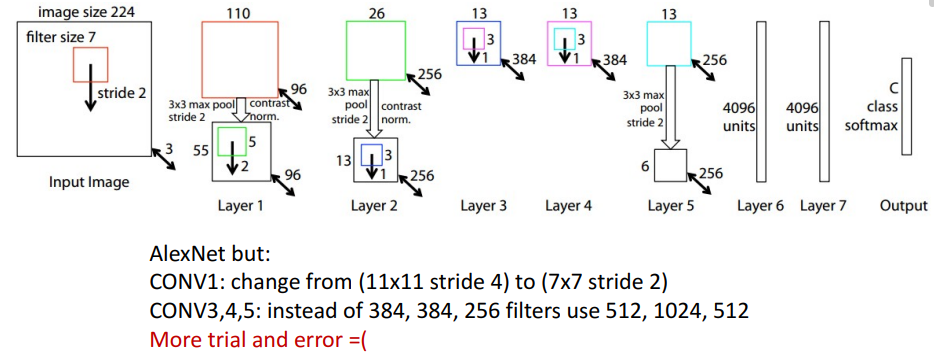 stride를 줄임으로써 down sampling을 적게 하고 이를 통해 high resolution 값을 얻었다. 즉, 더 많은 계산을 한 것이다. filters 개수도 늘림으로써 더 큰 모델이 되었다.
stride를 줄임으로써 down sampling을 적게 하고 이를 통해 high resolution 값을 얻었다. 즉, 더 많은 계산을 한 것이다. filters 개수도 늘림으로써 더 큰 모델이 되었다.
3. VGG: Deeper Networks, Regular Design(2014)
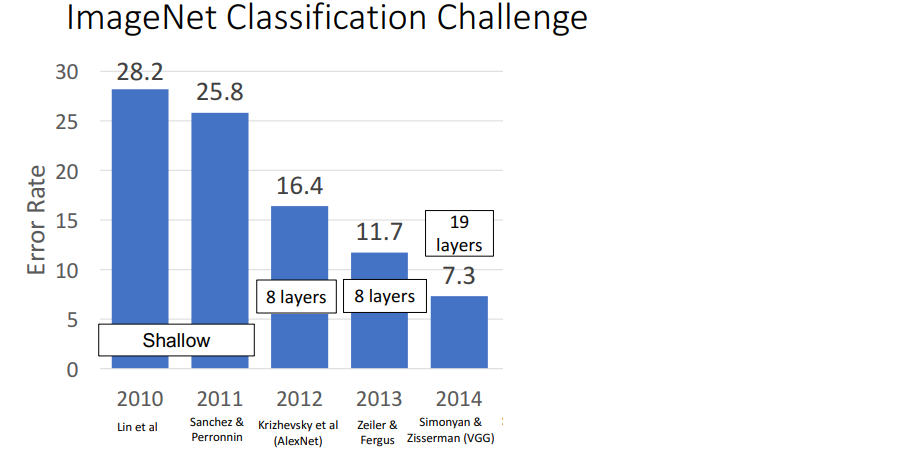
AlexNet, ZFNet은 hand made이자 trial and error로 탄생한 모델들로, 이들을 기반으로 scale을 키우거나 줄이기에는 어려움이 있었다. 어떤 규칙이나 모듈 형식이 아니었기 때문이다.
2014년에 등장한 VGG는 일반화된 디자인을 가진 모델이었다.
- All conv are 3x3 stride 1 pad 1
- All max pool are 2x2 stride 2
- After pool, double #channels
의 간단한 design rules를 갖고 있다.
1) Model
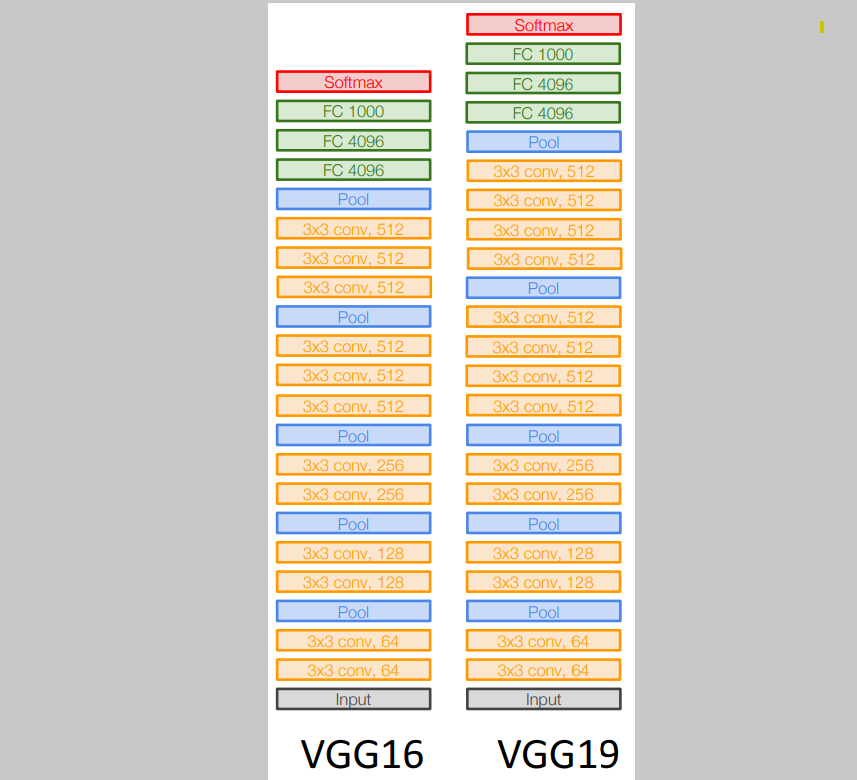 여러 VGG의 종류가 있지만 가장 유명한 VGG16과 VGG19이다. 네트워크는 5 개의 convolutional stages를 갖는다:
여러 VGG의 종류가 있지만 가장 유명한 VGG16과 VGG19이다. 네트워크는 5 개의 convolutional stages를 갖는다:
Stage 1: conv-conv-pool
Stage 2: conv-conv-pool
Stage 3: conv-conv-pool
Stage 4: conv-conv-conv-[conv]-pool
Stage 5: conv-conv-conv-[conv]-pool
(VGG-19 는 stage 4와 stage 5에서 4개의 conv를 갖는다)
2) Why this model?
a. All conv are 3x3 stride 1 pad 1
| Option 1 | Option 2 |
|---|---|
| Conv(5x5, C->C) | Conv(3x3, C->C) Conv(3x3, C->C) |
| Params: 25 | Params: 18 |
| FLOPs: 25 | FLOPs: 18 |
option1과 option2는 서로 비슷한 receptive field를 결과로 출력하지만 option2에서 더 적은 parameters와 적은 computation을 수행한다. 따라서 더 효율적이다. 따라서 conv사이즈를 hyperparameter로 설정하여 정하는 것 보다 3x3 conv layers를 몇층으로 쌓을 것인가의 문제가 된다.
만약 두 3x3 conv layers 사이에 ReLU와 같은 non-linear 함수를 적용한다면 더 깊고 nonlinear한 결과를 가질 수 있다. 따라서 더 적은 parameter과 computation뿐만 아니라 single 5x5 conv layer보다 더 좋다.
b. All max pool are 2x2 stride 2 & After pool, double # channels
design rules에 맞는 max pooling을 거치기 전의 conv layer과 거친 후의 conv layer연산을 보자.
| Before Max pooling | Max pooling | After Max pooling | |
|---|---|---|---|
| Input: | |||
| Layer: | Conv(3x3, CC) | Conv(3x3, 2C 2C) | |
| Memory: | |||
| Params: | |||
| FLOPs: |
Max pooling전과 후(이전 stage의 conv layer과 다음 stage의 conv layer)를 비교해보았을 때, 이후가 이전보다 Parameter의 수는 4배 더 많지만 메모리 소비는 절반에 불과하고 Flops는 동일한 것을 알 수 있다. 즉 conv layer에서의 이점과 비슷하게 더 좋은 성능을 더 적은 비용으로 효율적으로 얻을 수 있다.
3) AlexNet vs VGG-16
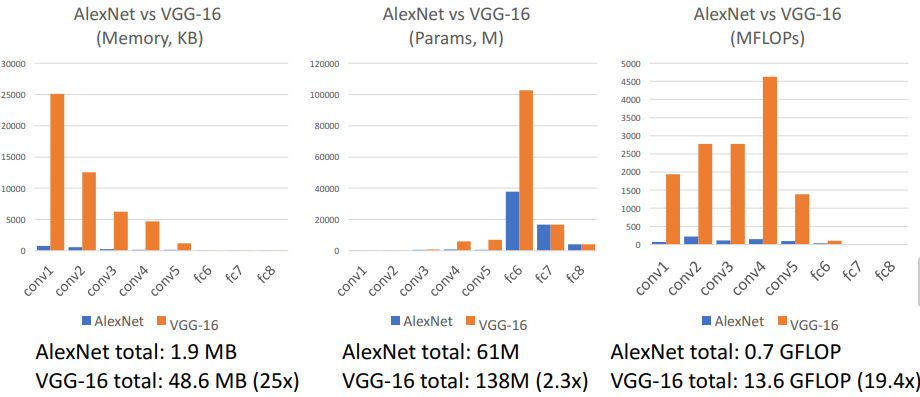 그래프에서도 볼 수 있듯이
그래프에서도 볼 수 있듯이 VGG-16은 매우 큰 네트워크이다.
4. GoogLeNet: Focus on Efficiecy(2014)
 같은 2014년에 나왔던 모델이고 우승했던 모델이었다. 이 모델은 efficiency에 집중했던 모델이었다.
같은 2014년에 나왔던 모델이고 우승했던 모델이었다. 이 모델은 efficiency에 집중했던 모델이었다. AlexNet, ZFNet, VGG를 보면 더 큰 네트워크가 더 좋은 성능을 냈다. 그러나 구글은 굉장히 잘 작동하면서도 간단한 모델을 만들고자 했다.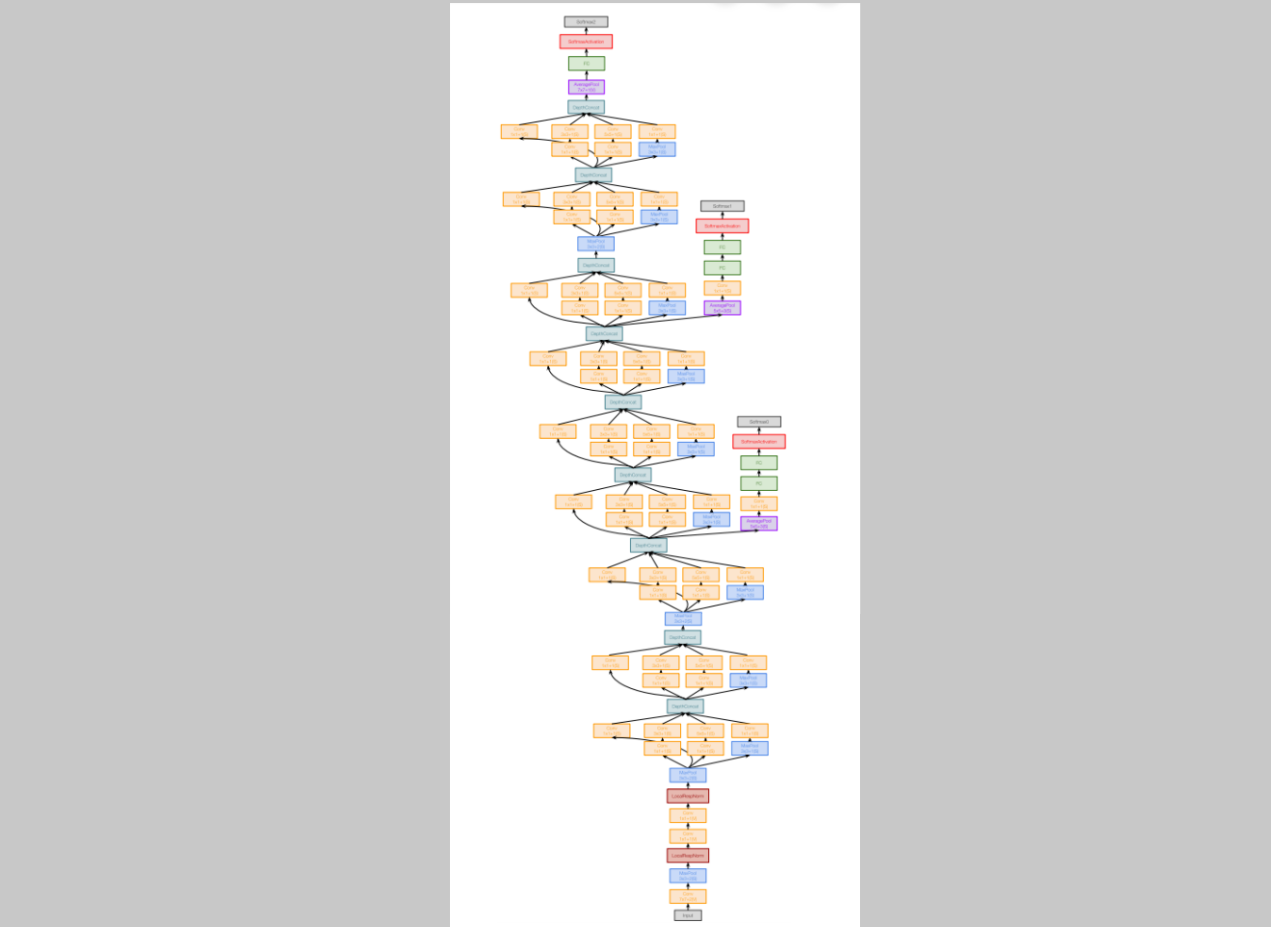 (아래에서부터 시작)
(아래에서부터 시작)
1) Aggressive Stem
GoogLeNet의 초기 conv layer에서 Stem network는 input images를 매우 빠르게 downsampling시켰다. 왜냐하면 기존 다른 모델들은 이 초반 layers에서 큰 conv computations를 하기 때문이다.
Stem network at the start aggressively downsamples input
(Recall in VGG-16: Most of the compute was at the start)
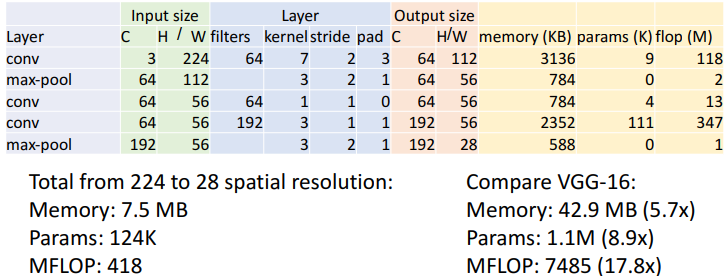 224x224 size 이미지를 매우 빠르게 28x28까지 줄인다.
224x224 size 이미지를 매우 빠르게 28x28까지 줄인다.
2) Inception Module
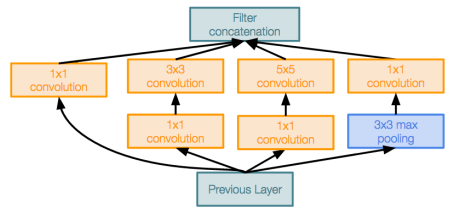 위와 같이 생긴 Inception Module을 여러번 반복하는 구조로 모델이 이루어져있다.
위와 같이 생긴 Inception Module을 여러번 반복하는 구조로 모델이 이루어져있다.
VGG는 kernel size등의 설정을 hyperparameter로 두지 않기 위해 3x3 conv layer을 여러번 쌓으면 더 효과적이라는 것을 밝혔다. 그러나 구글은 다른 접근을 시도했는데, 그냥 모든 좋은 설정을 다 해보자는 것이다. 그래서 이 모듈에는 여러개의 kernel sizes 등을 parallel하게 진행한다.
또한, 1x1 Bottleneck layers를 사용하여 값비싼 conv를 하기 전에 channel dimension을 줄이도록 하였다. 이 부분에 대한 내용은 ResNet에서 더 깊게 다룬다.
3) Global Average Pooling
기존 다른 모델들은 flattening을 하여 텐서를 일자로 전부 펴는 과정을 거쳤다. 이 과정에서 대부분의 parameters가 생겨났다. 그러나 구글은 대신에 마지막 spatial size와 같은 크기로 average pooling을 진행했다.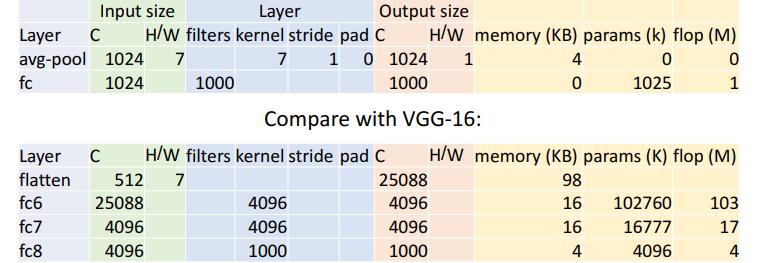 이러한 방식으로 parameter 개수를 효과적으로 줄였다.
이러한 방식으로 parameter 개수를 효과적으로 줄였다.
4) Auxiliary Classifiers
Batch normalization이 발견되기 이전에 나온 모델이였기 때문에 이 시기의 모델들은 deep하게 만들기 힘들었다. 10layers가 넘어가는 모델들은 converge하기 힘들었고 잘 작동하지 않앗다. gradients가 깨끗하게 propagate하지도 못했다.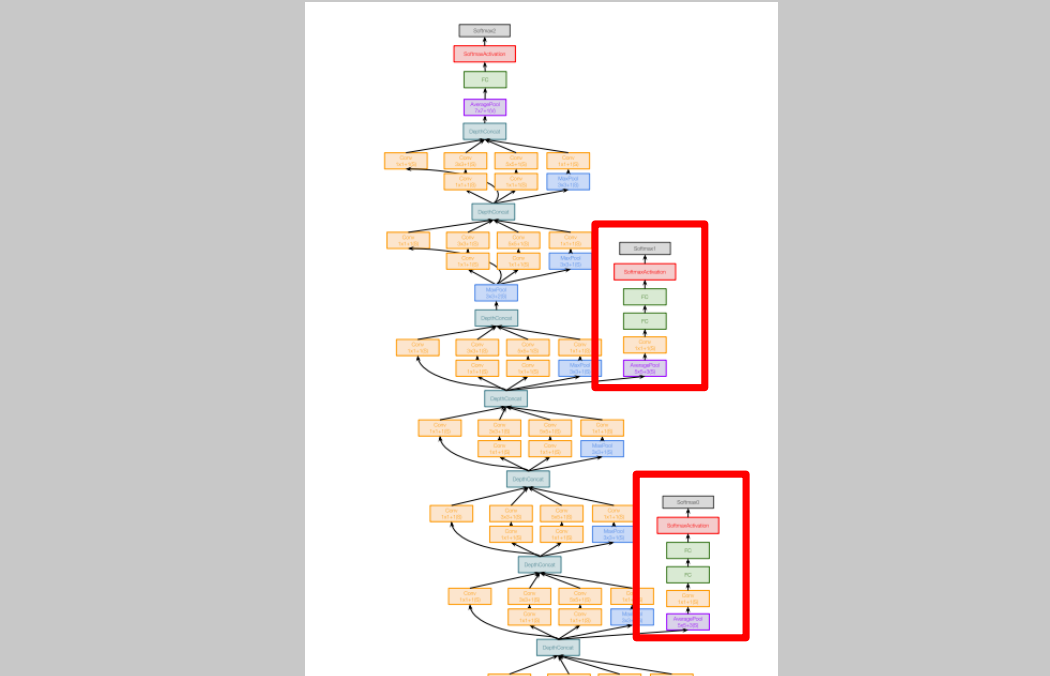 이를 해결하기 위해 auxiliary classifiers를 여러 중간 단계에 붙였고, 이곳에서도 분류를 진행하고 loss를 생성하여 계산한다.
이를 해결하기 위해 auxiliary classifiers를 여러 중간 단계에 붙였고, 이곳에서도 분류를 진행하고 loss를 생성하여 계산한다.
Batch normalization을 사용한 이후부터는 이러한 트릭은 사용할 필요가 없어졌다.
5. Residual Networks(2015)
1) Background
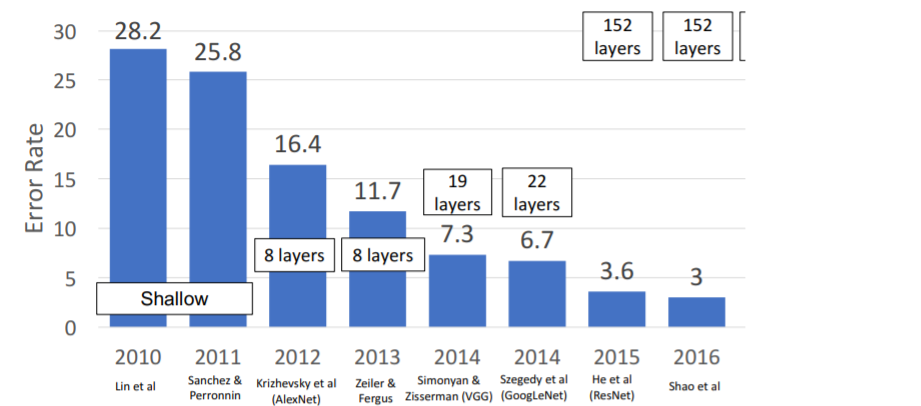
Batch normalization이 등장하고 사람들은 10개 이상의 layers를 쌓는 deeper network가 가능해짐을 깨달앟다. 기존 트렌드는 더 깊은 네트워크일수록 더 좋은 성능을 내 왔기 때문에 deeper network에서 더 좋은 성능을 낼 것으로 기대했다. y축이 Test-error인 그래프를 보면 56-layer에서 더 안좋은 성능을 냈는데, 이를 보고 사람들은 deep model이 overfitting하고 있다고 예측했다. 그러나 Training error을 살펴본 결과 deep model은 사실상 underfitting되었다. 어떤 이유에서인지 deeper model에서 optimize가 제대로 이루어지지 않은 것이다.
어떤 이유에서인지 deeper model에서 optimize가 제대로 이루어지지 않은 것이다.
문제점
deeper model은 항상 shallower model을 emulate할 수 있다. 즉, 20 layers를 복사하고 나머지를 항등함수(identity function)으로 정의하면 20 layer를 나타낼 수 있다.
가설
optimization 문제라고 생각하였다. Deeper model은 optimize하기 어렵고, 따라서 shallow model을 emulate하기 위한 항등함수를 학습하지 않는다는 것이다.
해결방법
네트워크를 변형하여 extra layers에서 더 쉽게 항등함수를 학습할 수 있게 한다.
2) Solution
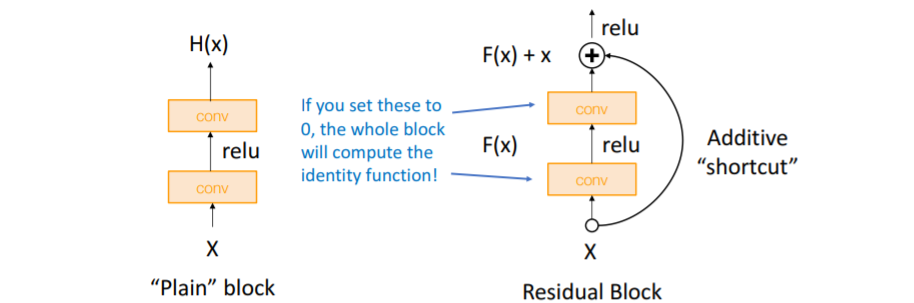 왼쪽
왼쪽 Plain block은 VGG의 conv layers이다. 오른쪽 Residual block은 기존 방식에서 추가로 input X를 더해서 결과를 내는데, 이는 만약 conv layer의 weight값을 0으로 설정하면 전체 block은 결국 input X와 같은 결과를 내어 항등함수를 학습할 수 있다. 따라서 더 쉽게 항등함수를 학습할 수 있게 되었다.
3) Model
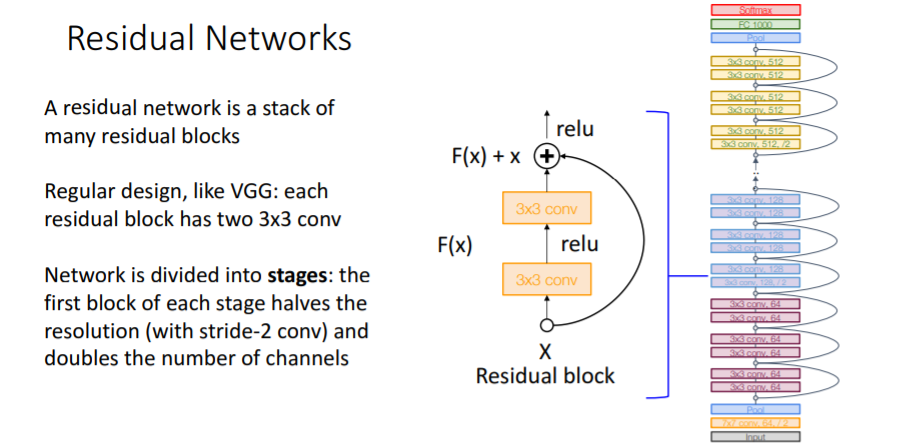
residual network는 많은 residual blocks의 stack이다. VGG와 같이 3x3 conv를 사용한 일반화된 디자인이다.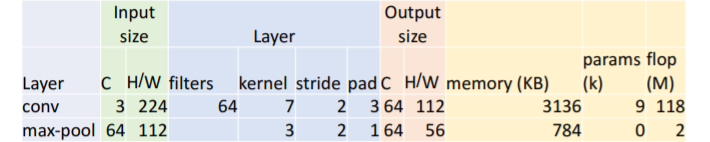
 그리고
그리고 GoogLeNet과 같이 aggressive stem을 사용하여 residual blocks를 적용하기 전에 input을 4배로 downsampling시킨다. 그리고
그리고 GoogLeNet과 같이 커다란 fc layer 대신에 global average pooling을 사용하였다.
| ResNet-18 | ResNet-34 | |
|---|---|---|
| Stem: | 1 conv layer | 1 conv layer |
| Stage 1 (C=64): | 2 res. block = 4 conv | 3 res. block = 6 conv |
| Stage 2 (C=128): | 2 res. block = 4 conv | 4 res. block = 8 conv |
| Stage 3 (C=256): | 2 res. block = 4 conv | 6 res. block = 12 conv |
| Stage 4 (C=512): | 2 res. block = 4 conv | 3 res. block = 6 conv |
| Linear | linear | linear |
| --------------------------- | --------------------------- | --------------------------- |
| ImageaNet top-5 error: | 10.92 | 8.58 |
| GFLOP: | 1.8 | 3.6 |
VGG-16의 ImageNet top-5 error은 9.62였고, GFLOP은 13.6이었다.
4) Bottleneck Block
 위의 3) Model 에서 소개한
위의 3) Model 에서 소개한 ResNet-18과 ResNet-34와 같이 얕은 model에서는 Basic Residual block을 사용하였지만 깊은 model에서는 이를 bottleneck Residual block으로 수정하여 사용한다. 첫번째 Conv에서 channel 수를 1/4로 줄인 다음에 3x3 Conv를 수행하고 다시 1x1 Conv를 통해 channel 수를 복구한다.
이러한 block을 사용하면 Total FLOPs는 더 적어서 적은 computation을 수행하지만 더 많은 non-linearity를 갖는다.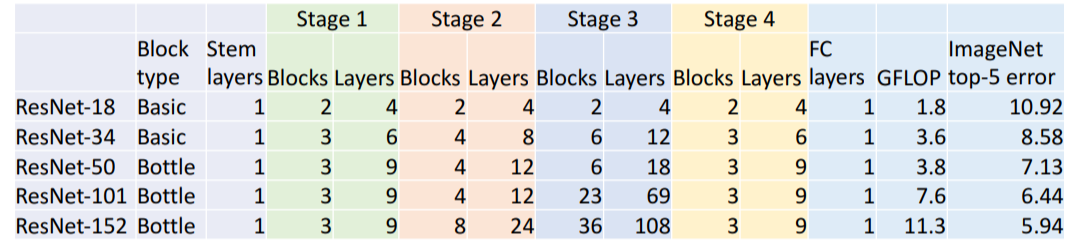
ResNet-50은 ResNet-34와 같지만 Basic block을 Bottleneck block으로 대체한 것이다. 이를 통해 비슷한 계산으로 더 깊은 모델을 만들 수 있다.
ResNet-101과 ResNet-152는 더 정확한 성능을 갖지만 computation 또한 무겁다.
5) Power of ResNet

- Able to train very deep networks
- Deeper networks do better than shallow networks (as expected)
- Swept 1st place in all ILSVRC and COCO 2015 competitions
- Still widely used today!
6) Improving Residual Networks: Block Design
 기존 ResNet block에서 순서를 바꿈으로써 아주 조금 더 좋은 성능을 낼 수 있음을 알게 되었다.
기존 ResNet block에서 순서를 바꿈으로써 아주 조금 더 좋은 성능을 낼 수 있음을 알게 되었다.
ResNet-152: 21.3 vs 21.1
ResNet-200: 21.8 vs 20.7
6. Comparing Complexity
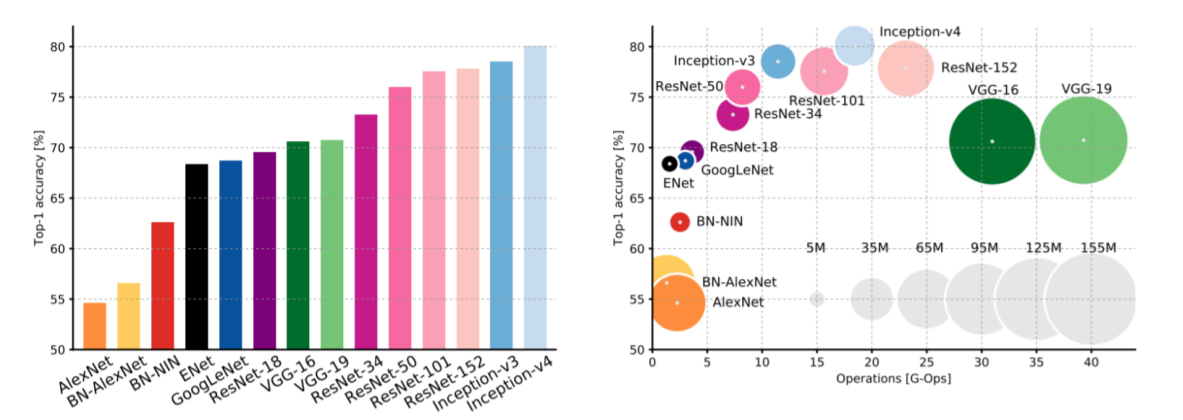 x축은 FLOPs, y축은 정확도, 원의 크기는 learnable parameters 수이다.
x축은 FLOPs, y축은 정확도, 원의 크기는 learnable parameters 수이다.
| Model | 특징 |
|---|---|
| VGG | 가장 큰 memory사용, 가장 많은 operations |
| GoogLeNet | 매우 효율적이지만 정확성이 조금 떨어짐 |
| AlexNet | 적은 operations, 많은 parameters. 정확성도 매우 낮음 |
| ResNet | 간단한 디자인, 효율적이며 높은 정확성을 가짐 |
7. Model Ensembles(2016)
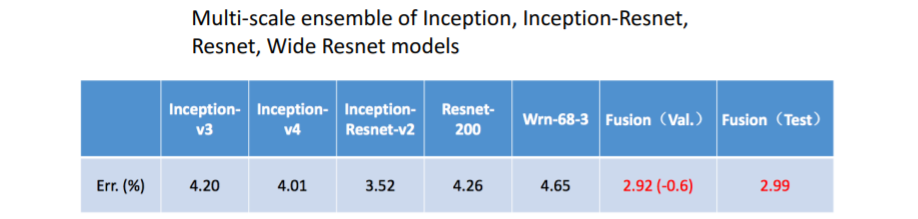
Inception, Inception-Resnet, Resnet, Wide Resnet models의 Multi-scale ensemble을 사용한 모델이 우승하였다.
8. ResNeXt: Improving ResNets
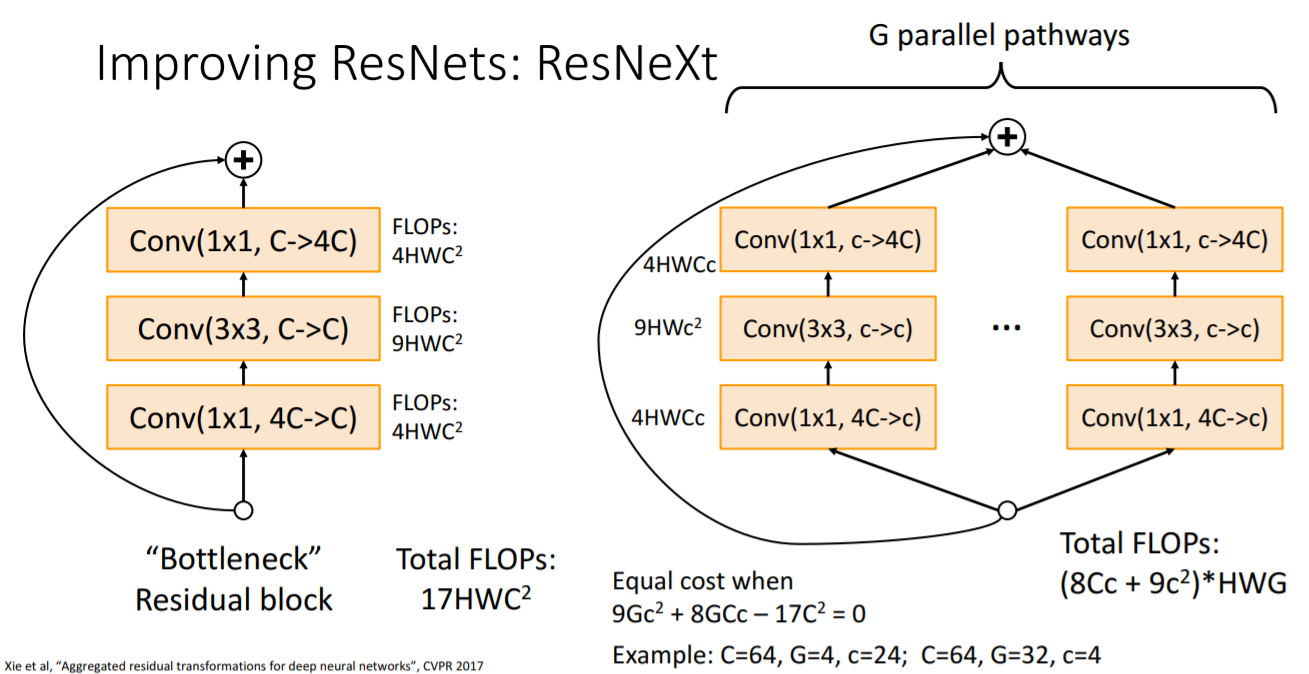 기존의 Bottleneck Residal block을 G개의 parallel한 bottleneck block을 사용하는 것으로 변형하였다. 여기에서 차이점은 G개의 parallel bottleneck block은 중간의 Conv layer이 가 아니라 라는 것이다. 따라서
기존의 Bottleneck Residal block을 G개의 parallel한 bottleneck block을 사용하는 것으로 변형하였다. 여기에서 차이점은 G개의 parallel bottleneck block은 중간의 Conv layer이 가 아니라 라는 것이다. 따라서 ResNeXt의 Total FLOPs는 이다.
위 사진의 아래 수식을 보면 기존 bottleneck residual block과 동일한 연산을 수행하는 ResNeXt의 Conv와 G의 값이다.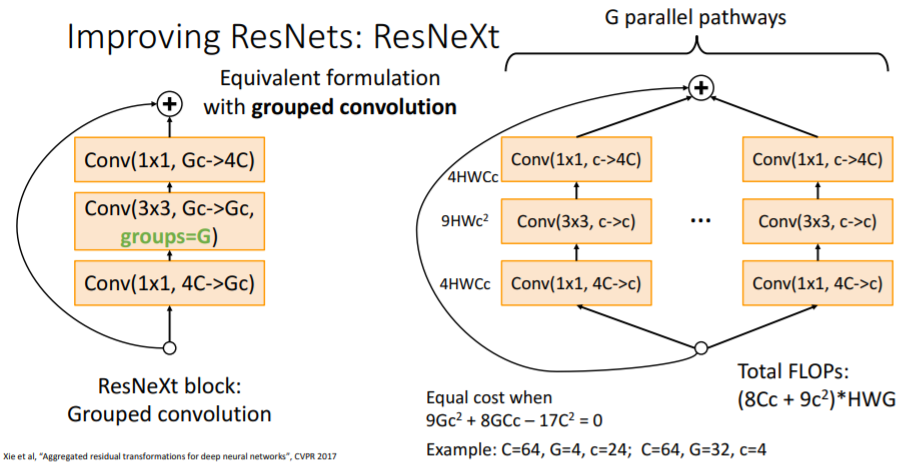 이후에 이 방식이 채택되어 ResNeXt block인 Grouped convolution을 수행하는 쉬운 방법이 생겼다.
이후에 이 방식이 채택되어 ResNeXt block인 Grouped convolution을 수행하는 쉬운 방법이 생겼다.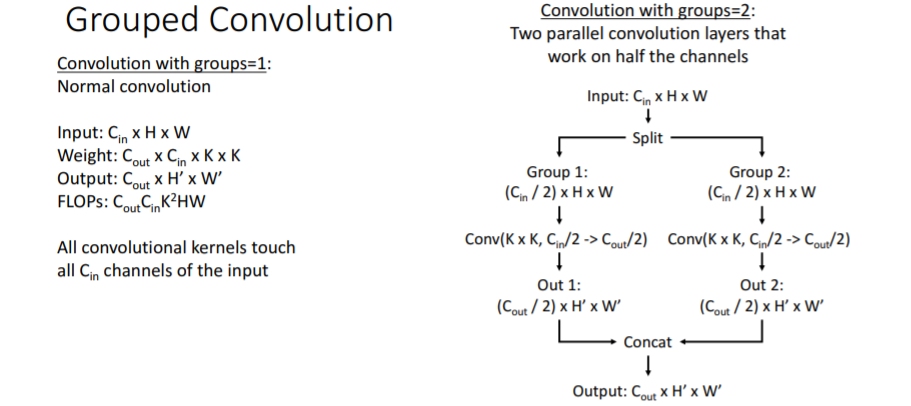
 Grouped Convolution은 Group의 수만큼 GPU를 병렬적으로 사용하는데, 이때 채널을 GPU의 수만큼 분리해서 각 GPU별로 학습을 진행한다고 한다. 그리고 ResNeXt에서 이 방식을 사용한다고 한다.블로그 참조
Grouped Convolution은 Group의 수만큼 GPU를 병렬적으로 사용하는데, 이때 채널을 GPU의 수만큼 분리해서 각 GPU별로 학습을 진행한다고 한다. 그리고 ResNeXt에서 이 방식을 사용한다고 한다.블로그 참조 파이토치에서도 이 기능을 제공한다.
파이토치에서도 이 기능을 제공한다. Groups를 추가함으로써 computation 수를 유지할 수 있고, groups를 추가하는 것은 같은 computational complexity로 더 좋은 성능을 낼 수 있게 한다.
Groups를 추가함으로써 computation 수를 유지할 수 있고, groups를 추가하는 것은 같은 computational complexity로 더 좋은 성능을 낼 수 있게 한다.
9. Squeeze-and-Excitation Networks(2017)
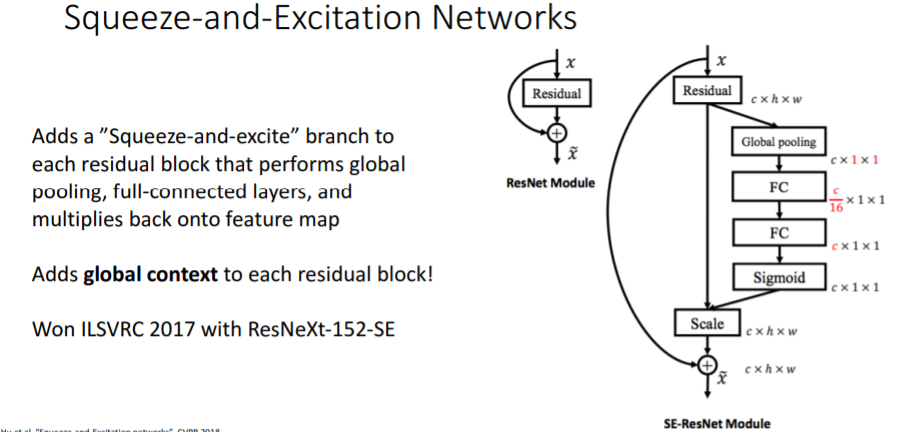 아쉽게 이 부분에 대한 설명은 넘어갔다... 그리고 2017년을 기점으로 ImageNet 대회는 종료되고 Kaggle에 남아있다.
아쉽게 이 부분에 대한 설명은 넘어갔다... 그리고 2017년을 기점으로 ImageNet 대회는 종료되고 Kaggle에 남아있다.
10. Densely Connected Neural Networks
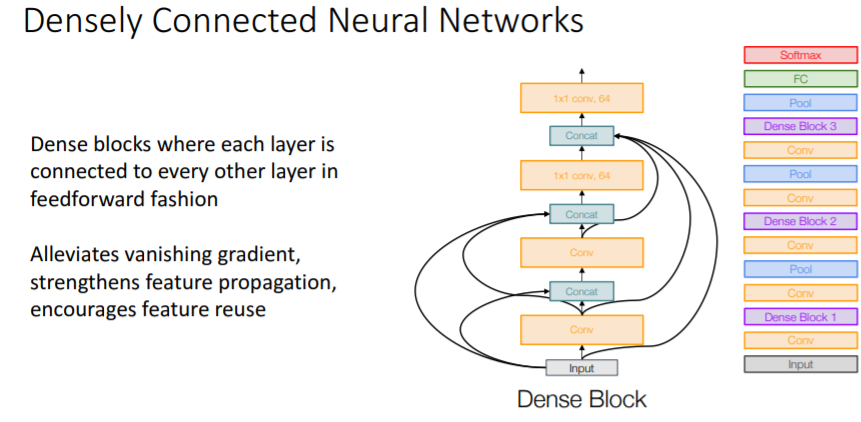 ImageNet 대회는 종료되었지만 여전히 더 나은 모델을 만들기 위한 노력이 이어졌고, 이 모델이 등장하였다. 기존
ImageNet 대회는 종료되었지만 여전히 더 나은 모델을 만들기 위한 노력이 이어졌고, 이 모델이 등장하였다. 기존 ResNet에서처럼 input X를 전달하여 더하는 것이 아니라 Concat을 하는 방식이다.
11. MobileNets: Tiny Networks(For Mobile Devices)
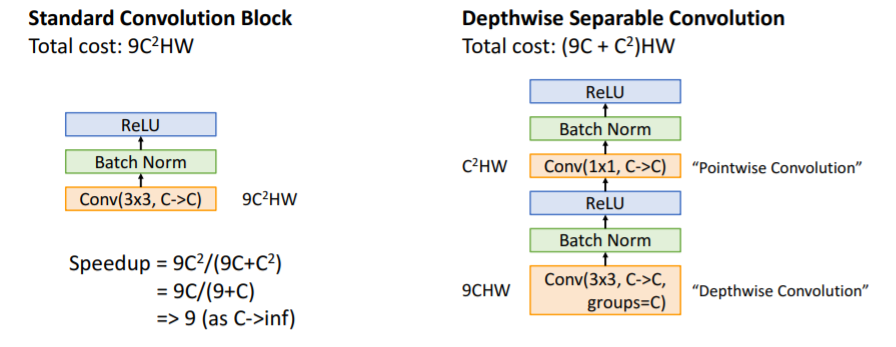
 Depthwise Separable Convolution을 사용하여 매우 적은 계산으로 어느정도 봐줄만한 성능을 내는 모델을 만들었다.
Depthwise Separable Convolution을 사용하여 매우 적은 계산으로 어느정도 봐줄만한 성능을 내는 모델을 만들었다.
12. Neural Architecture Search
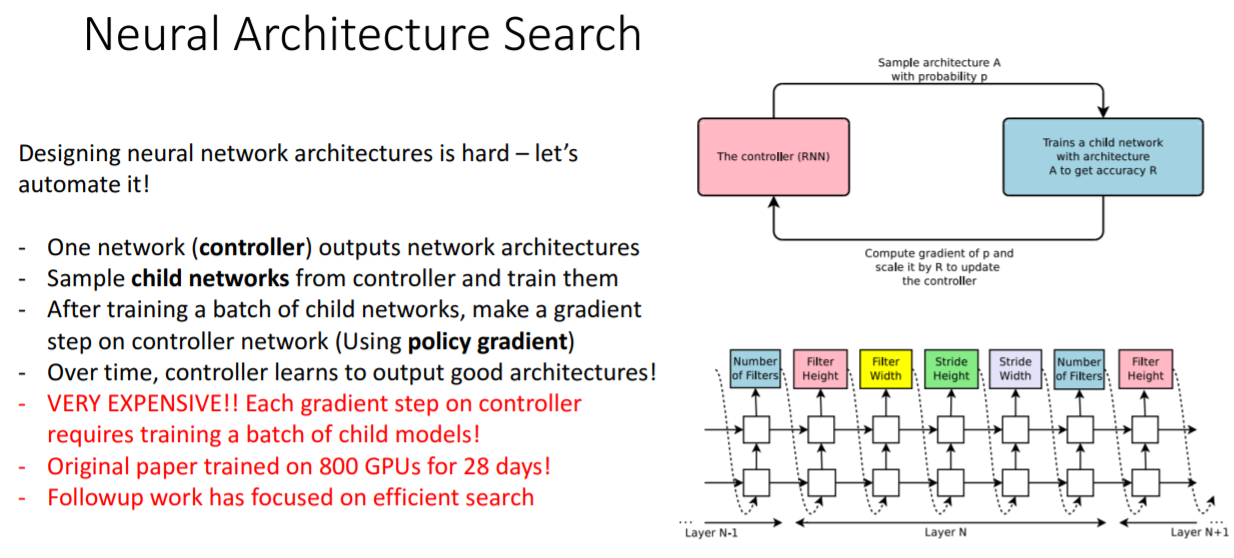
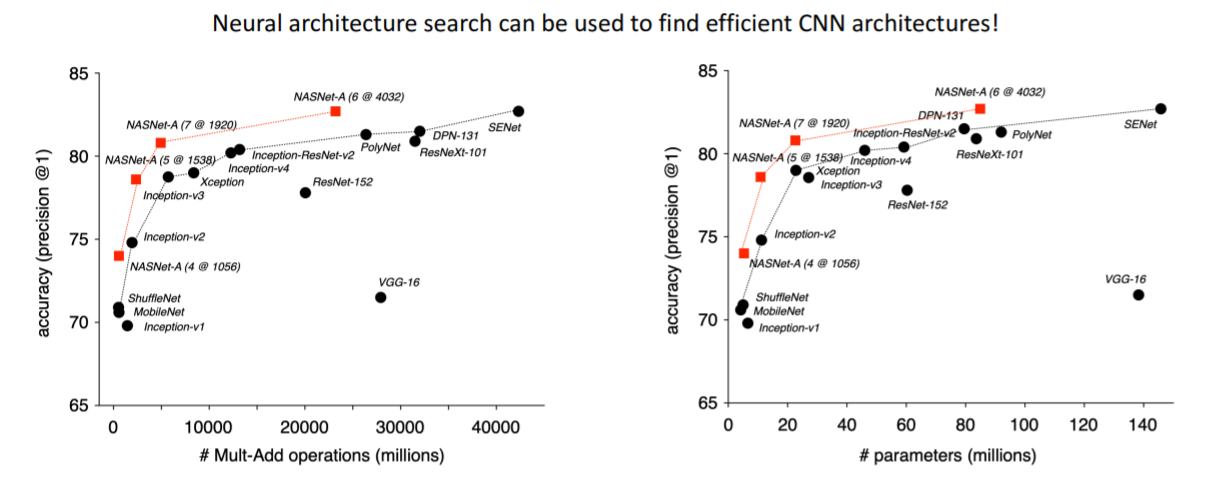 아키텍쳐를 출력하는 모델이다. 이는 매우 성능 좋은 모델을 만들지만 800개의 GPU로 28일 학습시켰다고 한다...
아키텍쳐를 출력하는 모델이다. 이는 매우 성능 좋은 모델을 만들지만 800개의 GPU로 28일 학습시켰다고 한다...
13. Summary
- Early work (AlexNet -> ZFNet -> VGG) shows that bigger networks work better
- GoogLeNet one of the first to focus on efficiency (aggressive stem, 1x1 bottleneck convolutions, global avg pool instead of FC layers)
- ResNet showed us how to train extremely deep networks – limited only by GPU memory! Started to show diminishing returns as network got bigger
- After ResNet: Efficient networks became central: how can we improve the accuracy without increasing the complexity? Lots of tiny networks aimed at mobile devices: MobileNet, ShuffleNet, etc
- Neural Architecture Search promises to automate architecture design

