[CS231n] [EECS 498-007 / 598-005] 강의정리 - 8강(EECS 9강) Deep Learning Software
[CS231n] + [EECS 498-007 / 598-005]

여기 내용부터는 cs231n으로 듣기에는 최신 내용들이 아니라서 cs231n instructor이셨던 교수님의 다른 강의를 정리하려고 합니다
Deep Learning Software
1. CPU vs GPU
NVIDIA vs AMD
강의에서 장난식으로 이를 소개하는데, AMD gpu를 사용한다면 딥러닝에 매우 큰 어려움을 겪을 것이라고 한다 ㅋㅋㅋ Nvdia가 독점적이라고 한다.
1) CPU vs GPU
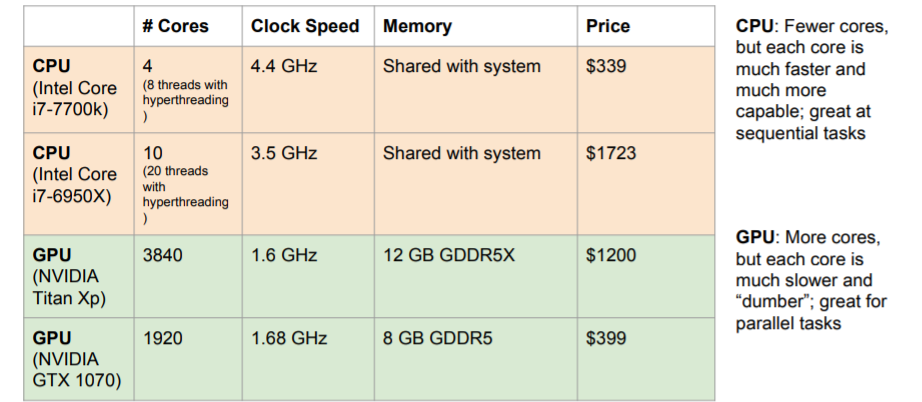 cpu와 gpu는 크게 core의 개수에서 차이난다. gpu는 수천개의 코어를 갖고 있다. 각각의 코어가 더 느린 클럭 스피드를 갖고 있지만 이 많은 코어들이 하나의 테스크를 병렬적으로 해결한다.
cpu와 gpu는 크게 core의 개수에서 차이난다. gpu는 수천개의 코어를 갖고 있다. 각각의 코어가 더 느린 클럭 스피드를 갖고 있지만 이 많은 코어들이 하나의 테스크를 병렬적으로 해결한다.
그리고 메모리에서도 차이가 난다. cpu의 캐시는 비교적 작고 RAM에서 가져와 사용한다. 그러나 gpu는 칩 안에 RAM이 내장되어있다.
이러한 특성에 의해 gpu는 병렬처리에 강하고 Matrix Multiplication에 매우 강력하다.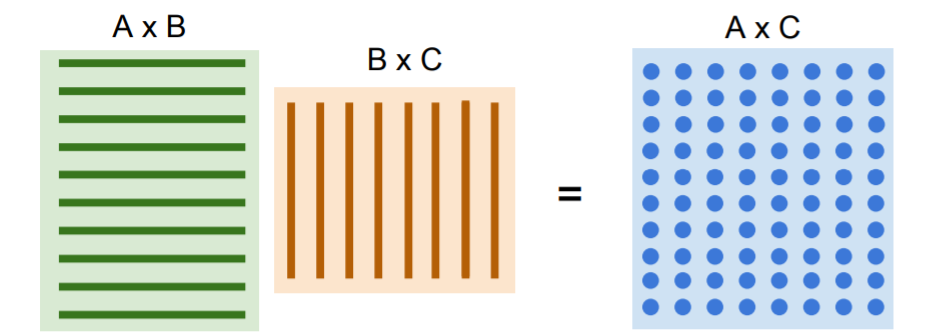 많은 수의 dot product를 모두 병렬로 수행할 수 있다. 각 요소들을 병렬로 계산할 수 있으므로 매우 빠르다.
많은 수의 dot product를 모두 병렬로 수행할 수 있다. 각 요소들을 병렬로 계산할 수 있으므로 매우 빠르다.
2) CPU / GPU Communication
Model과 Model weights는 GPU RAM에 있지만, 실제 train data는 하드디스크 등에 존재하므로 이를 불러올 때 보틀넥이 생길 수 있다. 따라서 데이터셋이 작은 경우에 이들을 모두 RAM에 올려놓을 수도 있고, cpu의 다중스레드를 사용ㅇ해서 RAM에 미리 올려놓을 수 있다.(pre-patching)
3) TPU
EECS 498-007 / 598-005 강의에서는 TPU에 대한 내용도 설명하고 있지만 넘어갔다.
2. Deep Learning Frameworks
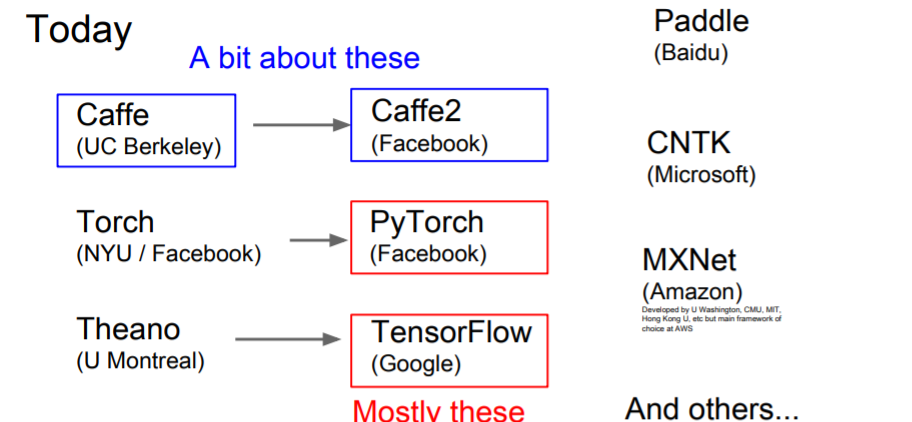
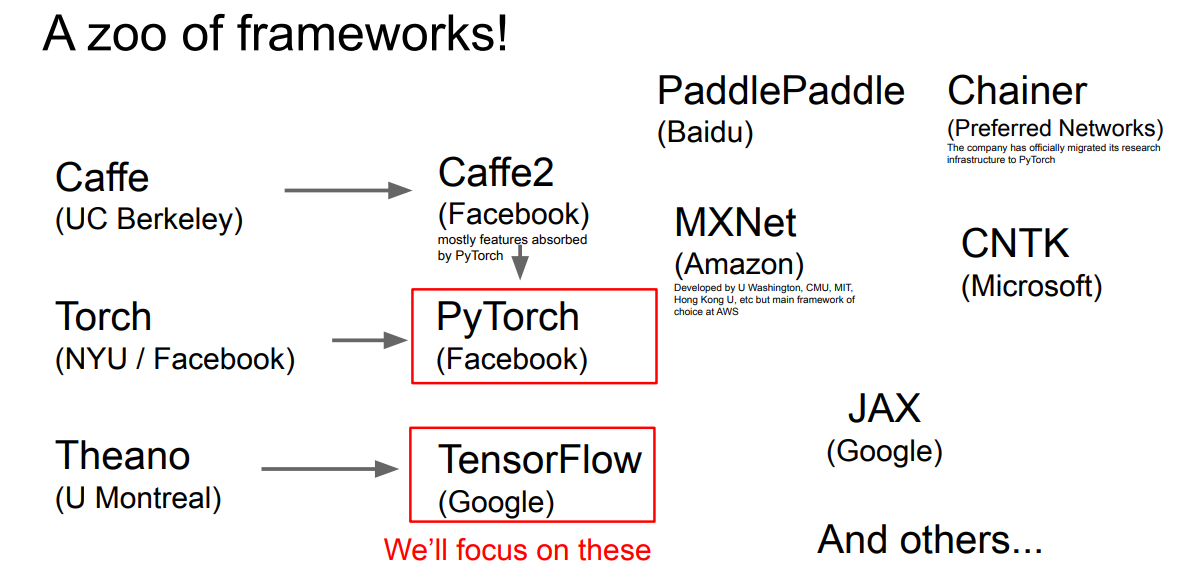 cs231n 2017강의와 cs231n 2021강의 차이.. 4년 사이에 너무 많은 것이 발전해버렸다.. cs231n 2017 강의만 무료로 풀려서 어쩔수 없이 2021년 강의를 못듣는게 안타까울 뿐 ㅜㅜ
cs231n 2017강의와 cs231n 2021강의 차이.. 4년 사이에 너무 많은 것이 발전해버렸다.. cs231n 2017 강의만 무료로 풀려서 어쩔수 없이 2021년 강의를 못듣는게 안타까울 뿐 ㅜㅜ
1) 딥러닝 프레임워크를 사용하는 이유
- 엄청 복잡한 computational graphs를 그리지 않아도 된다.
- gradients를 자동으로 계산해준다.
- GPU를 효율적으로 사용할 수 있게 해준다. (cuDNN, cuBLAS 등등.. 이)
즉, numpy스럽게 forward pass를 구현해주기만 하면 프레임워크가 gradients를 계산해주고, gpu도 사용할 수 있게 해준다.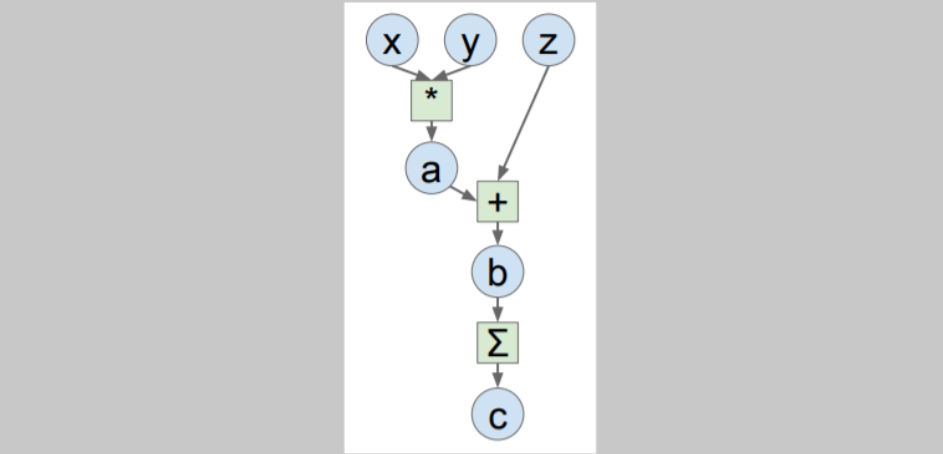 위 예시에서 코드를 짜면 numpy에서는 gradients를 모두 직접 코딩해야하지만 파이토치로 짠다면,
위 예시에서 코드를 짜면 numpy에서는 gradients를 모두 직접 코딩해야하지만 파이토치로 짠다면,
import torch
from torch.autograd import Variable
N, D = 3, 4
x = Variable(torch.randn(N, D).cuda(), requires_grad=True)
y = Variable(torch.randn(N, D).cuda(), requires_grad=True)
z = Variable(torch.randn(N, D).cuda(), requires_grad=True)
a = x + y
b = a + z
c = torch.sum(b)
c.backward()
print(x.grad.data)
print(y.grad.data)
print(z.grad.data)이처럼 numpy스럽게 짜고 자동 gradients계산과 gpu사용까지 된다.
2) TensorFlow
ReLU와 fc-layer with L2 loss인 two-layer example
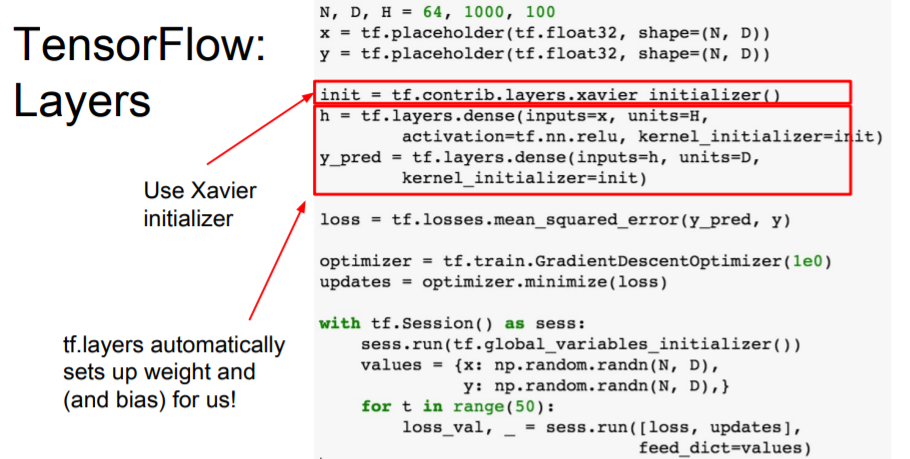
TensorFlow를 scratch부터 작성하는 방법과 tf.layer에 대한 내용을 설명하고 있다. PyTorch만 사용해와서 이 부분은 그냥 듣고 넘어갔다. 그리고 옛날 버전이라 현재랑도 안맞는 것 같다.. cs231n 2021년도 강의 풀어주세요 ㅜㅜ
3) Keras
TensorFlow를 백엔드로 해서 computational graph를 알아서 만들어준다. Theano 백엔드도 지원한다.
Keras도 그냥 듣고만 넘어갔다.
4) PyTorch
cs231n 에서는 이전 버전을 다루고 있어서 들어도 의미가 없다.. 그래서 2021년도 강의 교재와 cs231n 강의를 맡으셨던 Justin Johnson 교수님의 다른 강의 내용을 참고하여 들었다.
a. Tensors
pytorch tensor는 numpy와 매우 유사하지만 GPU에서도 돌아간다.
b. Autograd
computational graphs를 구축하고 gradients를 계산한다.
requires_grad=True로 설정해야 autograd를 가능하게 한다. 위 사진 예시헤서는 w1, w2에 설정되어있으므로 이들에 대해서 computational graph를 만들고 gradients를 계산하기 위해 이들을 tracking 한다.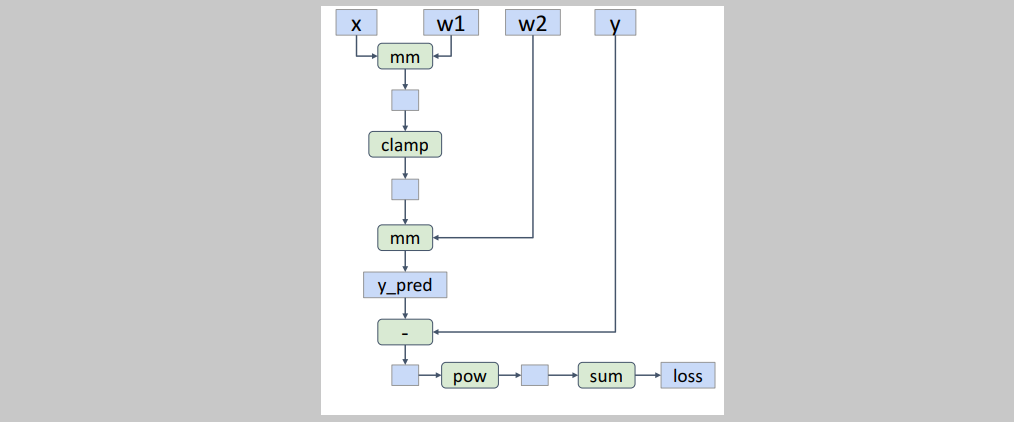 자동으로 tracking하므로 계산 결과들을 하나하나 저장할 필요가 없다.
자동으로 tracking하므로 계산 결과들을 하나하나 저장할 필요가 없다.
y_pred = x.mm(w1).clamp(min=0).mm(w2)
loss = (y_pred - y).pow(2).sum()으로 계산만 해주면 위 사진과 같은 computational graph를 작성한다.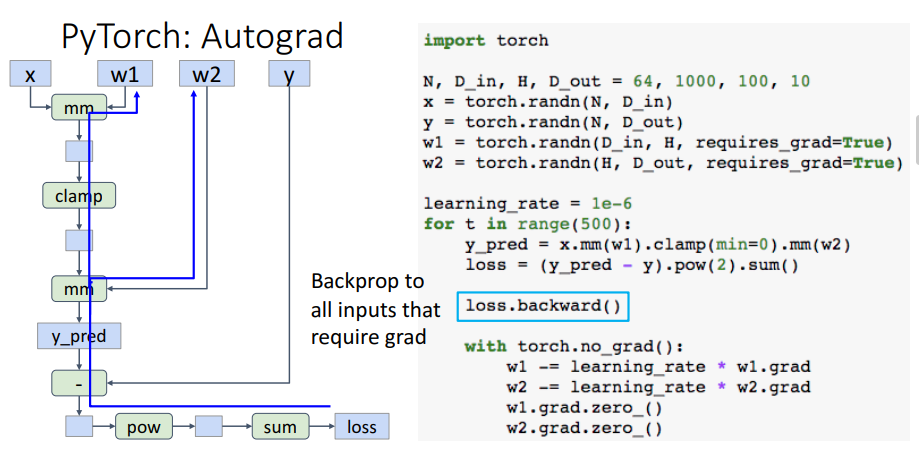 그리고
그리고 loss.backward()를 통해 w1, w2의 gradients를 계산한다. 그 값들은 w1.grad와 w2.grad에 저장된다. 계산 이후 computational graph는 파괴되고, learning rate와 함께 계산되어 w1, w2를 업데이트한다. 그리고 저장된 gradients를 zero로 다시 초기화해준다.
b.1 New functions
def sigmoid(x):
return 1.0 / (1.0 + (-x).exp())python 함수로 정의하고 계산을 진행할 수도 있다.
y_pred = sigmoid(x.mm(w1)).mm(w2)
loss = (y_pred - y).pow(2).sum()그러나 computational graph는 함수를 포함하여 만들어지지 않고 함수 내부의 계산까지 전부 포함하여 만들어진다. 위와같이 operator모듈을 만들어버리면
위와같이 operator모듈을 만들어버리면 sigmoid라는 모듈로 computational graph를 만들 수 있다.
b.2 nn
 layers의 sequence를 만들어서 model을 작성하고 이를 계산하도록 작성할 수도 있다. loss 또한 nn.functional에 작성된 함수를 불러와서 계산할 수 있다.
layers의 sequence를 만들어서 model을 작성하고 이를 계산하도록 작성할 수도 있다. loss 또한 nn.functional에 작성된 함수를 불러와서 계산할 수 있다.
b.3 optim
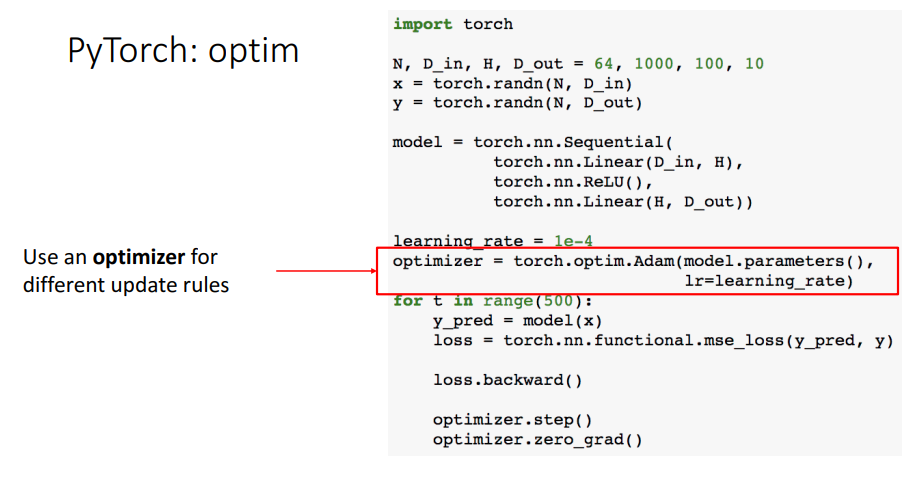 optim을 사용하여 업데이트를 진행할 수 있다.
optim을 사용하여 업데이트를 진행할 수 있다. optimizer.step()으로 업데이트를 한다.
c. Modules
 모듈을 만들어 그래프를 작성할 수 있다. 이는 custom Module subclasses를 mix and match할 수 있다.
모듈을 만들어 그래프를 작성할 수 있다. 이는 custom Module subclasses를 mix and match할 수 있다.

d. DataLoaders
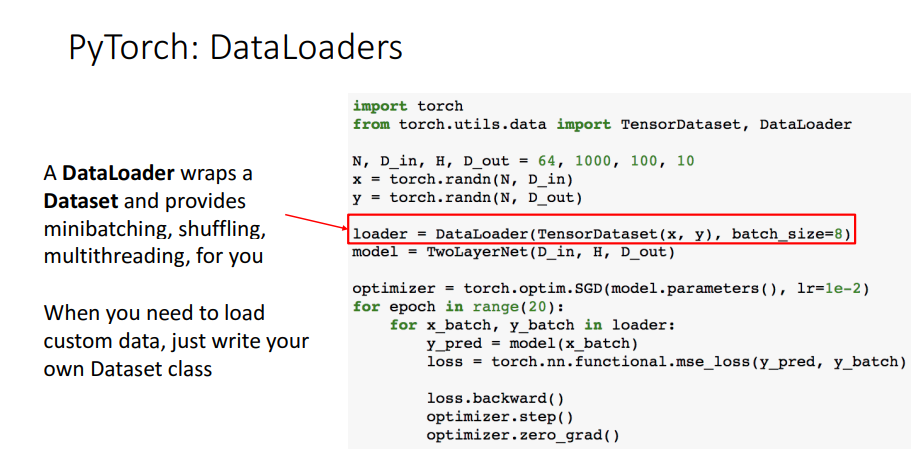 데이터를 불러오고 미니배치를 만들거나 섞는 등의 일을 할 수 있다.
데이터를 불러오고 미니배치를 만들거나 섞는 등의 일을 할 수 있다.
e. Dynamic Computation Graphs
파이토치는 기본적으로 y_pred와 loss를 정의하면 이를 그래프로 만들고, loss.backward()를 통해 gradients를 계산하고 나면 만들었던 그래프를 버린다. 그리고 for문을 돌면서 다시 그래프를 만들고 gradients를 계산하고 다시 그래프를 버린다. 이러한 과정은 비효율적으로 느껴지지만 normal regular Python control flow 와 같이 동작하므로 파이썬스럽게 작성 및 실행이 된다.
f. Static Computation Graphs
 모델을 함수로 정의하고
모델을 함수로 정의하고 torch.jit.script(model)을 하게 되면 graph object로 컴파일을 한다.
@torch.jit.script라는 annotation을 추가해서 파이썬 함수가 정의되면 이를 graph로 컴파일하도록 할 수 있다.
4.1) Static vs Dynamic Graphs
a. Optimization
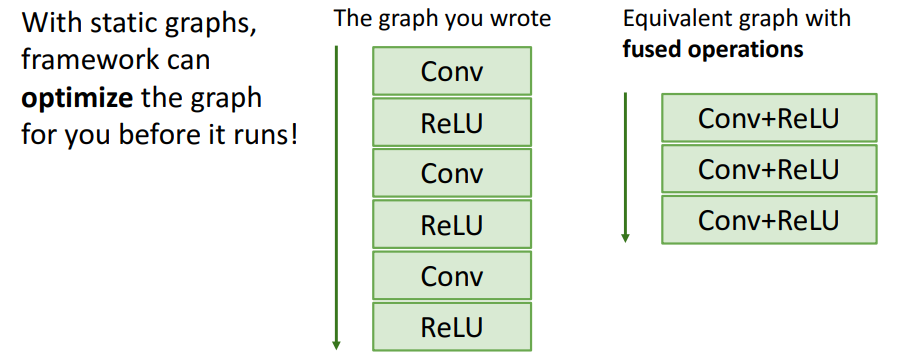 Static graph를 사용하면, 실행하기 전에 graph를 최적화시킬 수 있다.
Static graph를 사용하면, 실행하기 전에 graph를 최적화시킬 수 있다.
b. Serialization
 Static graph를 사용하면 python으로 모델을 학습시키고, 컴파일된 그래프를 python환경이 아닌 곳으로 새로운 자료구조 형태로 추출하여 사용할 수 있다.
Static graph를 사용하면 python으로 모델을 학습시키고, 컴파일된 그래프를 python환경이 아닌 곳으로 새로운 자료구조 형태로 추출하여 사용할 수 있다.
c. Debugging
 Dynamic graph는 쉬운 디버깅을 할 수 있는 장점이 있다.
Dynamic graph는 쉬운 디버깅을 할 수 있는 장점이 있다.
d. Dynamic graph
input에 의존하는 모델인
- recurrent networks
- recursivd networks
- modular networks
등을 사용할 때 효과적이다.
5) PyTorch vs TensorFlow

