
Convolutional Neural Networks
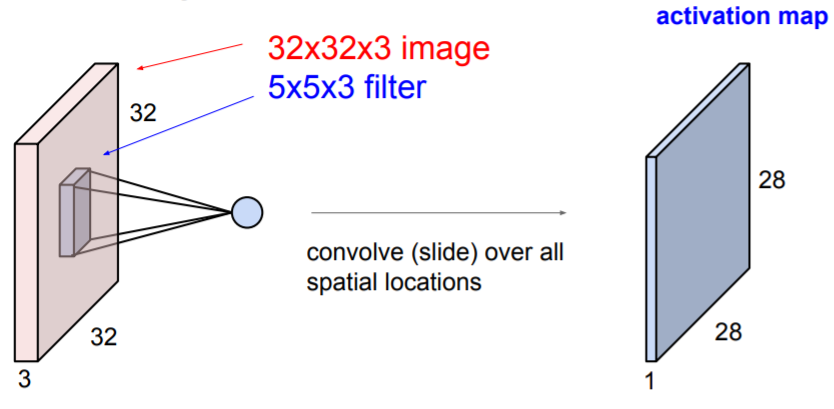 Convolution Layer은 이미지에 filters를 가지고 계산하여 activation map을 생성한다. filter은 이미지를 슬라이딩하며 이동하고 같은 위치에서 dot product를 계산한다. filter의 depth는 input의 depth와 같다.(위 사진에서는 3)
Convolution Layer은 이미지에 filters를 가지고 계산하여 activation map을 생성한다. filter은 이미지를 슬라이딩하며 이동하고 같은 위치에서 dot product를 계산한다. filter의 depth는 input의 depth와 같다.(위 사진에서는 3)
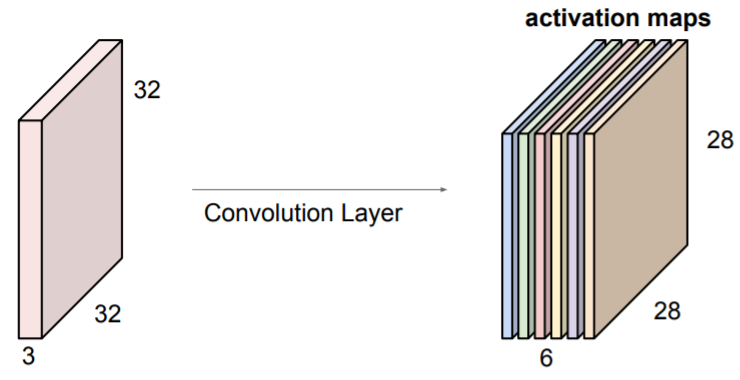 6개의 filter(6 x 5x5)을 적용하여 6개의 서로 다른 activation maps를 얻었다. 이들을 쌓아서 새로운 이미지 사이즈인
6개의 filter(6 x 5x5)을 적용하여 6개의 서로 다른 activation maps를 얻었다. 이들을 쌓아서 새로운 이미지 사이즈인 28 x 28 x 6을 만들어낸다.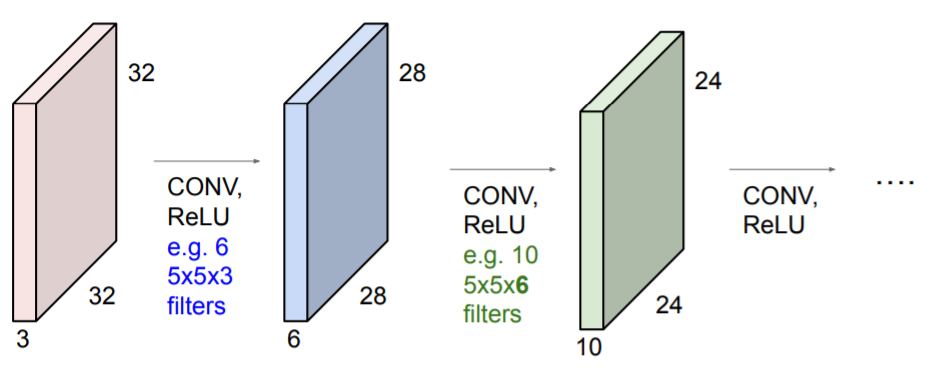 ConvNet은 Convolution Layers의 나열이다.
ConvNet은 Convolution Layers의 나열이다.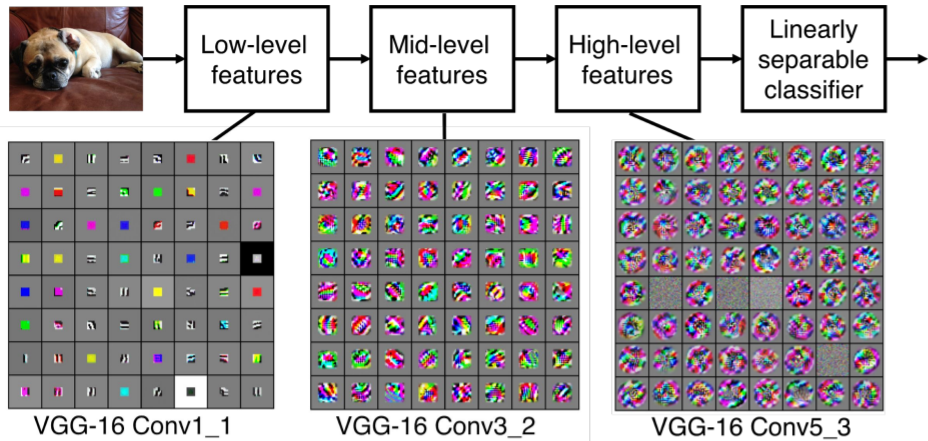 초반에는 Low-level features(직선 등.)을 학습하고 나중 Layer에서는 High-level features(실제 이미지와 비슷한 모양들, 곡선 등.)을 학습한다. 그리고 이들 features를 모두 합쳐 분류 등을 하기 위해 fc-layer을 사용한다.
초반에는 Low-level features(직선 등.)을 학습하고 나중 Layer에서는 High-level features(실제 이미지와 비슷한 모양들, 곡선 등.)을 학습한다. 그리고 이들 features를 모두 합쳐 분류 등을 하기 위해 fc-layer을 사용한다.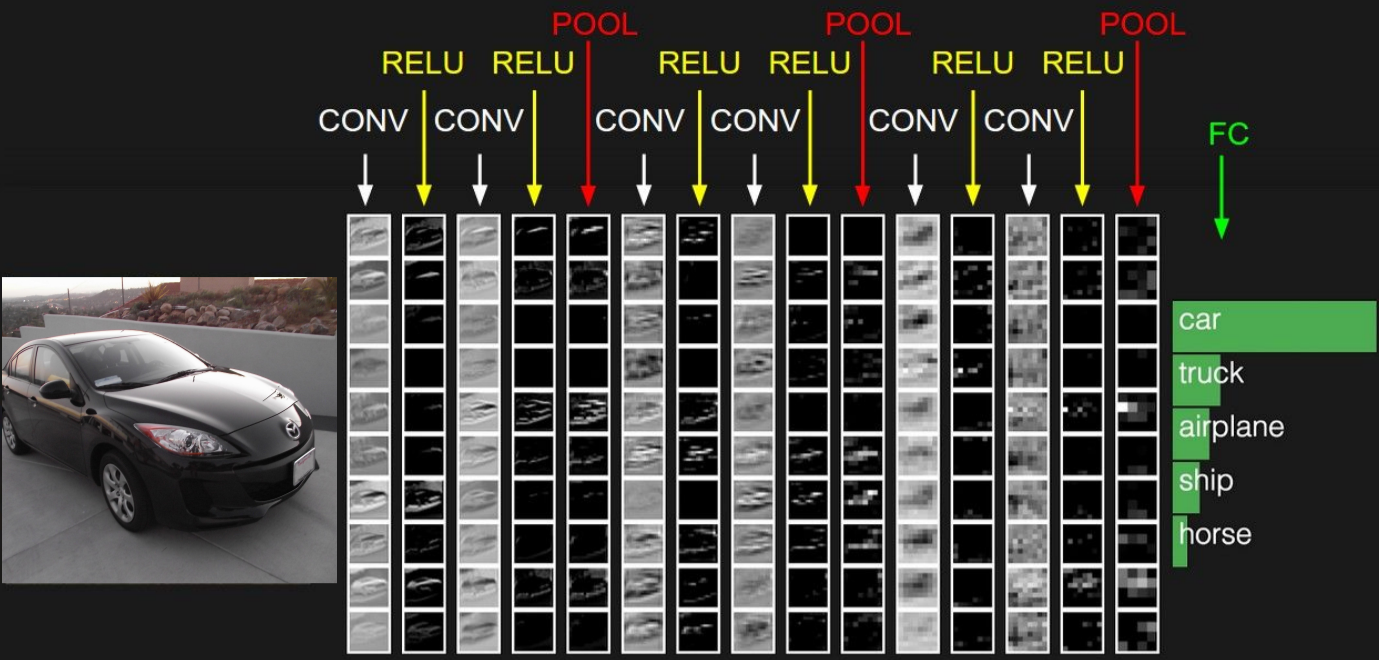 activation map이 계산되는 과정은 아래와 같다.
activation map이 계산되는 과정은 아래와 같다.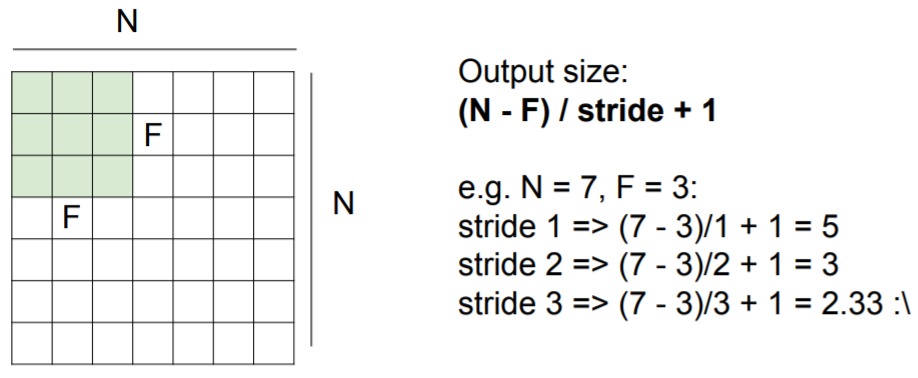

stride : filter가 한번에 이동하는 거리
padding : 기존 이미지의 상하좌우에 0 또는 다른 값을 추가하여 이미지 사이즈를 늘린다
이미지 사이즈가 N이고, filter 사이즈가 F라고 할 때, activation map의 사이즈는
(N - F) / stride + 1
이다. 따라서 나눗셈을 할 때 정수로 떨어지지 않는다면 적용할 수 없다.
Padding은 output 이미지의 사이즈를 맞추거나 input 이미지의 모서리 부분을 더 잘 학습시키기 위해 사용된다. 이미지의 중심부분은 filter가 여러번 거쳐 잘 학습되지만 모서리 부분은 한번밖에 거치지 않기 때문이다.
Example
 이 layer에서 사용된 파라미터의 개수는 총 760개이다.
이 layer에서 사용된 파라미터의 개수는 총 760개이다.
한 개의 filter은 총 5 x 5 x 3(depth) + 1 = 76 개의 파라미터를 가지는데, 총 10개의 filter을 사용했기 때문에 76 x 10 = 760 개의 파라미터를 갖는다.
Common settings
K(filter의 개수) = 2의 거듭제곱 (e.g. 32, 64, 128, 512)
F(filter 사이즈), S(stride), P(zero padding)
| F | S | P |
|---|---|---|
| 3 | 1 | 1 |
| 5 | 1 | 2 |
| 5 | 2 | 알맞게 |
| 1 | 1 | 0 |
1 x 1 convolution layers는 어떤 일을 하는가?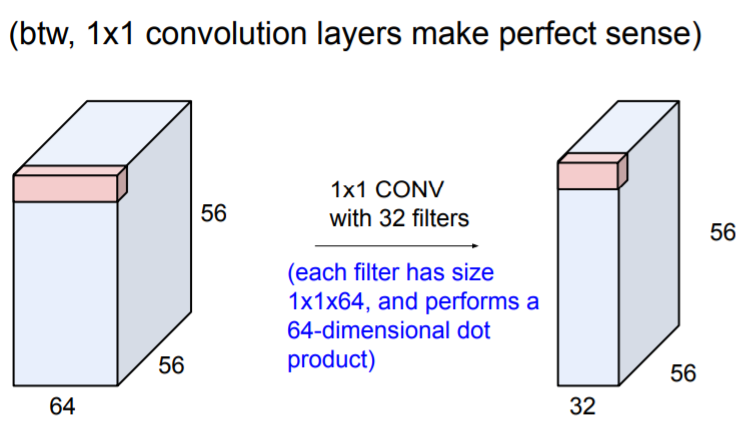 depth와 상관없이 이미지만의 특성을 학습한다.
depth와 상관없이 이미지만의 특성을 학습한다.
Pooling layer
Pooling layer은 activation map에 활성화함수를 거치고 나온 feature map을 다운샘플링하는 역할을 한다.
- representations를 더 작고 사용하기 쉽게 만들어준다
- 더 적은 파라미터 수
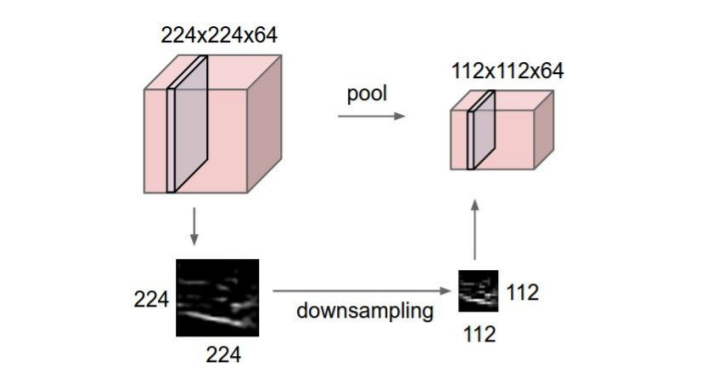 Pooling의 종료에는
Pooling의 종료에는 Max pooling과Average pooling등이 있다. Max pooling은 filter 내에 있는 값들 중 Max값만 뽑아낸다. 기존 Conv layer와 같은 방식으로 일정 크기의 filter가 stride 크기만큼 슬라이딩하며 값을 뽑는다. 따라서 pooling후의 결과이미지 사이즈도 Conv layer에서 계산했던 식과 같다.
결국 이미지 사이즈를 줄여주기 때문에 Conv layer에서 stride와 유의미한 차이가 있지 않다. 그리고 요새는 pooling 대신에 stride를 사용하여 다운샘플링을 하는 것이 더 성능이 좋고 인기가 좋다고 한다.
ConvNetJS demo
여기에서 CIFAR-10으로 학습된 ConvNet의 activation map과 과정을 확인할 수 있다.
Summary
- ConvNet은 CONV, POOL, FC-layers를 쌓은 네트워크이다.
- 작은 filter과 더 깊은 아키텍처가 유행이다
- POOL과 FC-layers는 점차 사용되지 않고 CONV만 사용되는 추세이다
- 과거 아키텍처는
[(CONV - RELU) x N - POOL?] x M - (FC - RELU) x K, SOFTMAX
(N 5, M is large, 0 K 2)- 그러나 최근 등장한 ResNet/GoogLeNet은 이러한 패러다임과 달라졌다.
