
Videos
 지난 강의에서 3d shape를 나타내기 위해 4D tensor을 사용했다(C x V x V x V). 이때 우리는 3차원 공간을 나타내기 위해 이미지보다 한차원을 더 사용했다.
지난 강의에서 3d shape를 나타내기 위해 4D tensor을 사용했다(C x V x V x V). 이때 우리는 3차원 공간을 나타내기 위해 이미지보다 한차원을 더 사용했다.
그런데 비디오를 다룰 때에도 4D tensor을 사용하는데, 이때 공간을 위한 3차원이 아니라, 시간 T를 추가하여 3차원을 만든다. 비디오는 sequence of images이기 때문이다.
1. Video Classification
 그동안 다루었던 Image classification은 objects(noun)을 구분하였다. 그렇지만 비디오에서는 주로 actions(verb)를 구분한다. 그리고 대부분의 video train sets는 사람의 actions에 대한 것들이다.
그동안 다루었던 Image classification은 objects(noun)을 구분하였다. 그렇지만 비디오에서는 주로 actions(verb)를 구분한다. 그리고 대부분의 video train sets는 사람의 actions에 대한 것들이다.
1.1) Problem: Videos are big!
 우리가 video 데이터를 다룰 때 극복해야하는 가장 중요한 문제이다.
우리가 video 데이터를 다룰 때 극복해야하는 가장 중요한 문제이다.
압축되지 않은 30fps video는
(640x480)해상도에서 1.5GB/minute
(1920x1080)해상도에서 10GB/minute
이다.
Solution
이를 해결하기 위해서 매우매우 짧은 clips를 사용하여 학습시킨다. 예를 들어 3-5초의 video. 그리고 fps도 30fps에서 5fps등으로 줄인다. 또한 해상도도 줄인다.
보통 이미지를 다룰 때 224x224의 해상도를 사용했던 것을 기억할 것이다. 그러나 비디오를 다룰 때에는 더욱 해상도를 줄여 112x112를 사용한다.
1.2) Training on Clips
 raw video는 long, high fps이므로 training time에는 짧은 clips(with low fps)를 classify할 수 있도록 학습한다.
raw video는 long, high fps이므로 training time에는 짧은 clips(with low fps)를 classify할 수 있도록 학습한다.
짧은 clips를 classify하는 모델을 만들었기 때문에 test time에도 같은 크기의 clips를 사용하여 test해야한다. 따라서 전체 비디오를 여러개의 조금씩 다른 clips로 나누어 이들에 대해 classification을 진행하고 prediction을 평균내어 최종 output을 출력한다.
1.3) Video Classification(1): Single-Frame CNN
첫번째 video classification 모델을 살펴보자. 비디오의 시간적 특성을 버릴뿐더러 매우매우 간단하고 바보같은 방법이지만 강력한 baseline이다.
비디오의 시간적 특성을 버릴뿐더러 매우매우 간단하고 바보같은 방법이지만 강력한 baseline이다.
비디오의 모든 frame을 나누어서 각각의 2D 이미지를 독립적으로 classify할 수 있도록 하는 기본 2D CNN을 학습시킨다.
그리고 test time에는 다시 test 비디오의 모든 frame을 나누어 학습한 2D CNN에 넣고 prediction의 평균값으로 최종 output을 계산한다.
이는 매우 바보같은 방법이지만 video classification에 적용할 수 있는 매우 강력한 baseline이며 교수님이 이 방법을 무시하지 마라고 하셨다.
1.4) Video Classification(2): Late Fusion (with FC layers)
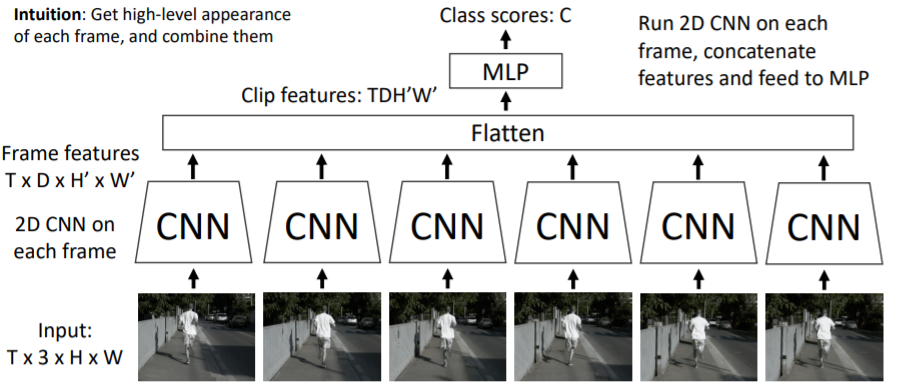 이 방식은 비디오의 시간적 특성을 활용한다.
이 방식은 비디오의 시간적 특성을 활용한다.
- Input(Tx3xHxW) sequence를 frame별로 각각 2D CNN에 통과시킨다.
- 2D CNN의 ouput으로 (TxDxH'XW')의 Frame features들이 계산된다. 여기에서 D는 CNN feature map에서 C(channel)이라고 생각하면 된다.
- 각각의 CNN에서 나온 Frame features를 Flatten시켜 차례대로 이어붙여 (TDH'W')의 Clip features를 생성한다.
- Clip features를 fc-layer로 연결하여 최종 class scores를 내도록 한다.
이 방식이 Late Fusion이라고 불리는 이유는 초창기 input 비디오를 받을 때에는 비디오의 시간적 특성을 활용하지 않았지만 나중에 Clip features를 만들면서 시간적 특성을 만들기 때문이다.
1.5) Video Classification(2): Late Fusion (with pooling)
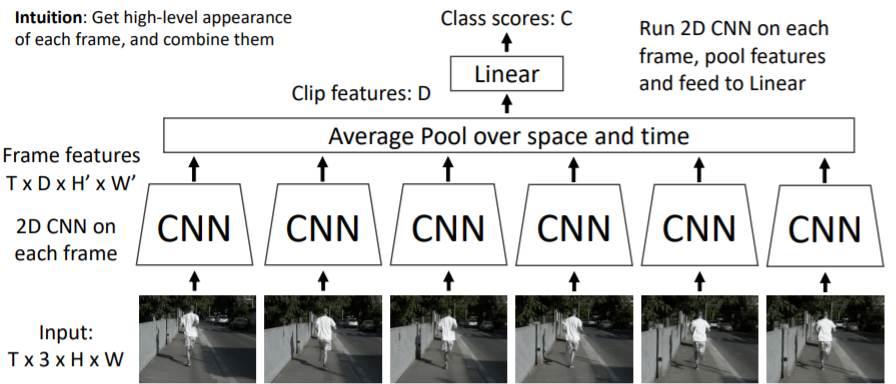 많은 parameters와 computations가 일어나는 fc-layer대신에 Average pool을 하여 (D)차원의 Clip features를 만들어 class scores를 계산한다.
많은 parameters와 computations가 일어나는 fc-layer대신에 Average pool을 하여 (D)차원의 Clip features를 만들어 class scores를 계산한다. Problem: Hard to compare low-level motion between frames
Problem: Hard to compare low-level motion between frames
위 그림에서 빨간색 원에 나타나는 것처럼 미세한 이미지의 차이(위 그림에서는 사람이 달리고 있어서 한쪽 다리가 올라갔다 내려갔다가 반복됨)를 frame별로 비교하기가 어렵다. 그저 픽셀 몇개의 차이밖에 나지 않기 때문이다.
1.6) Video Classification: Early Fusion
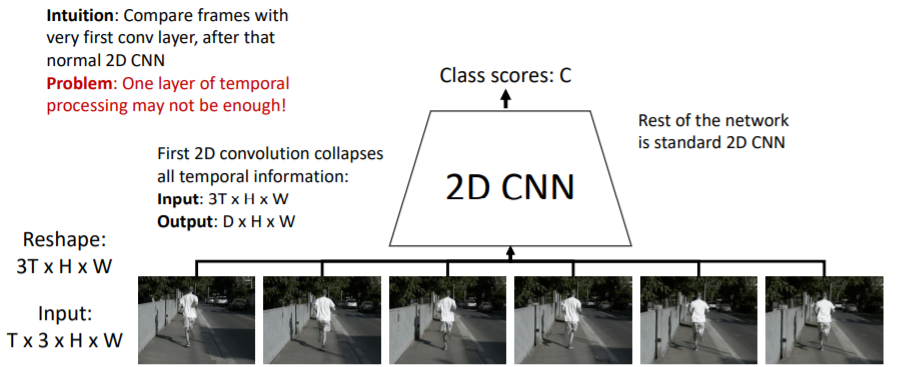 Late Fusion은 각각의 비디오 frame을 독립적으로 CNN에 통과시키고 나중에 시간적 특성을 연결하였다. Early Fusion은 순서를 바꾸어서 비디오 frame의 시간적 특성을 먼저 연결한다.
Late Fusion은 각각의 비디오 frame을 독립적으로 CNN에 통과시키고 나중에 시간적 특성을 연결하였다. Early Fusion은 순서를 바꾸어서 비디오 frame의 시간적 특성을 먼저 연결한다.
Input 이미지 sequence는 Tx3xHxW 차원을 갖는다. 이를 2D CNN에 넣기 위해 reshape을 한다. RGB를 나타내는 차원에 temporal(시간) 차원인 T를 stacking하여 (3TxHxW)모양을 만든다. 이렇게 되면 기본적인 2D CNN에서 받는 (CxHxW) = (3TxHxW)모양이 된다.
그리고 나서 일반적인 single 2D CNN을 사용하여 class score을 계산한다.
그러나 처음에 한번 temporal processing을 하는 것은 충분하지 않다는 문제가 있다
2D CNN을 거치고 나면 처음 생성한 temporal 특성이 붕괴되기 때문이다.
1.7) Video Classification: 3D CNN
위의 Late Fusion과 Early Fusion은 시간적 특성을 언제 결합하냐에 따라 각각의 단점이 존재했다. 따라서 slowly fusing(천천히 시간적 특성을 결합함)을 사용한다.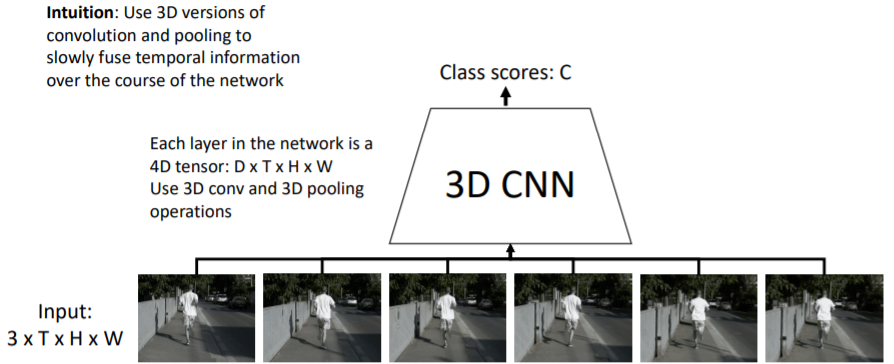 3D CNN 또는 Slow Fusion Network라고 불린다.
3D CNN 또는 Slow Fusion Network라고 불린다.
3D CNN을 사용하기 때문에(3D Conv, 3D pooling) CNN을 진행할 때에도 계속해서 기존 4D Tensor 모양(DxTxHxW)을 유지시켜준다. 따라서 네트워크가 진행되면서 전반적으로 temporal information을 결합해준다.
2. Early Fusion vs Late Fusion vs 3D CNN
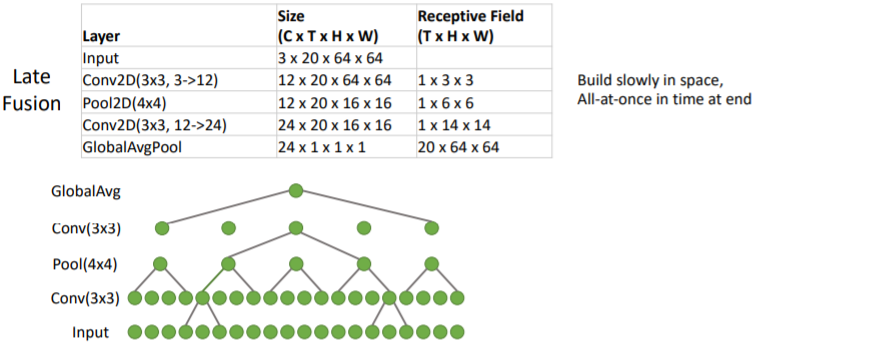
 매우 작고 간단한 architecture을 가지고 세가지 방법을 비교해보았다.
매우 작고 간단한 architecture을 가지고 세가지 방법을 비교해보았다.
Late Fusion과 Early Fusion은 2D Conv를 사용하여 space에서는 점진적으로 receptive field가 증가하지만, time은 딱 한번 생성된다. Late Fusion은 마지막에, Early Fusion은 처음에 딱 한번 time을 다루기 때문이다. receptive field에서 T의 값을 보면 된다.
그러나 3D CNN은 3x3x3 3D Conv를 사용하기 때문에 space에서와 time에서 모두 점진적으로 receptive field가 증가하는 것을 볼 수 있다. time에 대해서도 지속적으로 conv를 수행하기 때문이다.
그렇다면 2D Conv와 3D Conv의 차이는 무엇일까?
3. 2D Conv (Early Fusion) vs 3D Conv (3D CNN)
3.1) 2D Conv (Early Fusion)
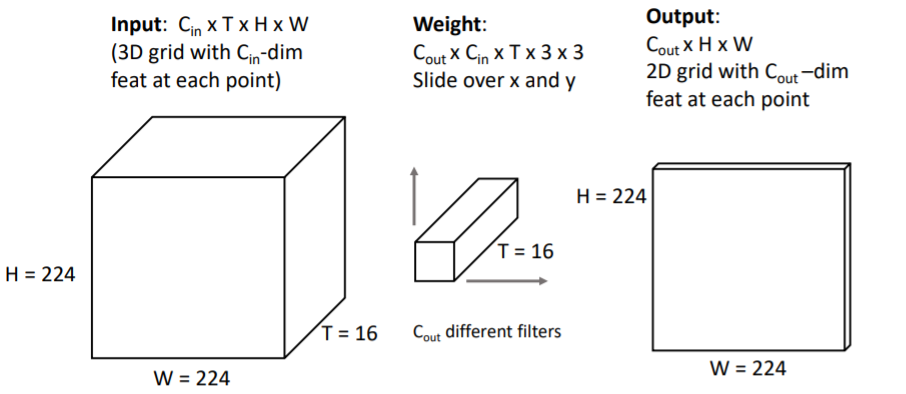 Early Fusion에서
Early Fusion에서 2D Conv를 사용하는 방식은 Input 차원을 TxHxW로 바꾸어 사용한다. 3d grid의 각 point가 을 갖는 의 Input을 사용한다.
그리고 conv filter은 을 사용한다. 원래 conv가 그렇듯 모든 input channel을 수용하는 filter을 사용하기 때문에 위의 방식에서도 filter는 모든 time 를 수용하는 filter이다. 따라서 2D conv의 계산으로 input의 모든 에 대해 한번에 계산하게 된다.
그런데 이러한 방식은 time을 다루는 데 문제가 있다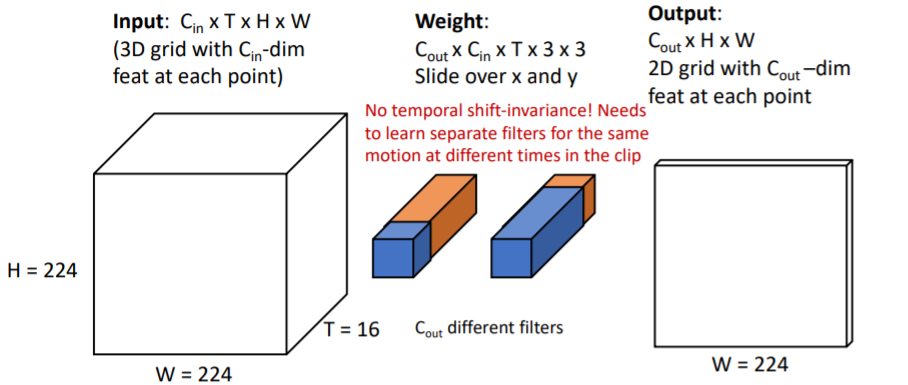 No temporal shift-invariance! Needs to learn separate filters for the same motion at different times in the clip
No temporal shift-invariance! Needs to learn separate filters for the same motion at different times in the clip
즉, 만약 우리가 영상에서 왼쪽부분은 "시간 3"에서 파란색에서 주황색으로 바뀌고,
오른쪽부분은 "시간 7"에서 주황색으로 바뀌는 것을 학습하고 싶다면
두 개의 서로 다른 filter을 사용해서 학습해야한다.
이는 같은 motion에 대해서 서로 다른 filter을 사용해야되는 문제가 발생한다.
3.2) 3D Conv (3D CNN)
 3.1)에서와 같은 Input에 대해서
3.1)에서와 같은 Input에 대해서 3D Conv는 의 filter을 사용한다. 따라서 에 대해서만 receptive field가 증가하는 것이 아니라 에 대해서도 점진적으로 커진다. (기존 2D Conv에서는 에 대해서만 살피고 방향은 그저 channel처럼 다루어졌음.)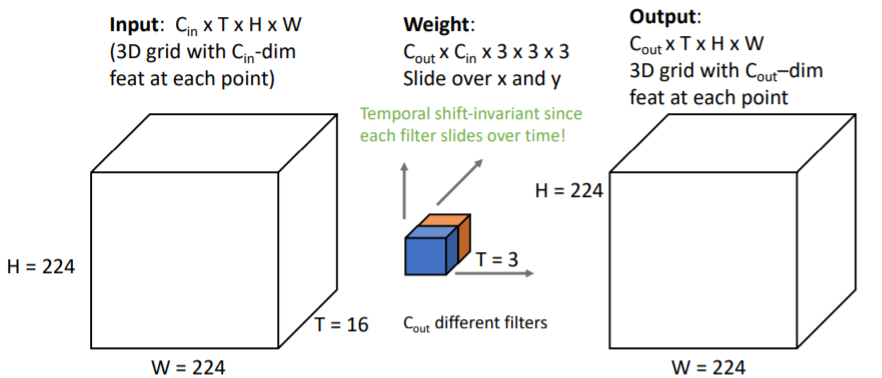 Temporal shift-invariant since each filter slides over time!
Temporal shift-invariant since each filter slides over time!
3.1)에서의 문제를 해결할 수 있다. time에 대해서도 filter가 sliding하기 때문에 같은 motion에 대해서 하나의 filter로 학습할 수 있다.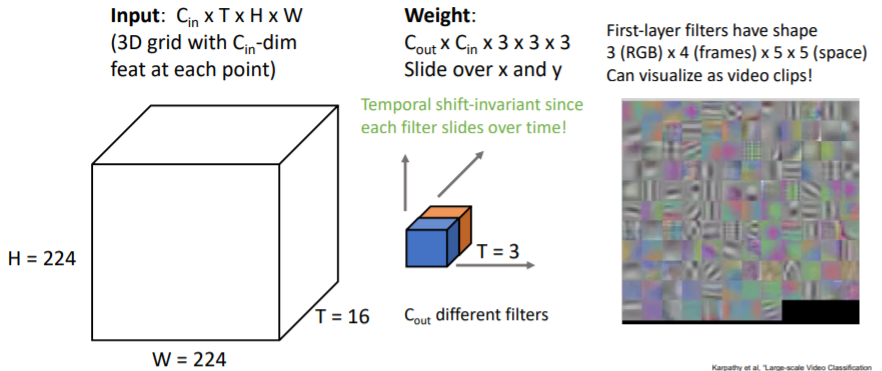 First-layer의 filters를 살펴보면
First-layer의 filters를 살펴보면 2D Conv에서처럼 line, blobs등을 살필 뿐만 아니라 motion에 대해서도 학습하고 있는 것을 볼 수 있다.
3.2.1) Example Video Dataset: Sports-1M
 Sports-1M이라는 비디오 dataset을 가지고 학습하여 실행한 결과이다.
Sports-1M이라는 비디오 dataset을 가지고 학습하여 실행한 결과이다.
3.3) Performance : Early Fusion vs Late Fusion vs 3D CNN
Large-scale Video Classification with Convolutional Neural Networks 논문
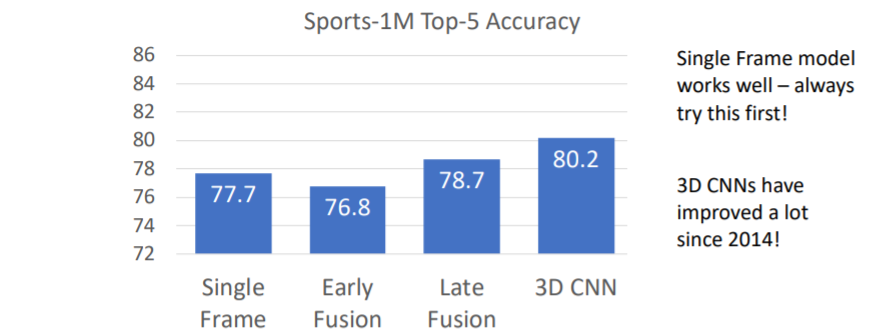 Single Frame방식이 생각보다 매우 강력한 것을 확인할 수 있다. 그리고 Late Fusion과 3D CNN은 그렇게 큰 폭으로 좋은 성능을 내고 있지는 않다.
Single Frame방식이 생각보다 매우 강력한 것을 확인할 수 있다. 그리고 Late Fusion과 3D CNN은 그렇게 큰 폭으로 좋은 성능을 내고 있지는 않다.
이 당시는 2014년으로 cpu cluster을 사용하여 학습시켰었고, 학습에 몇달이 걸렸다고 한다....
3.4) C3D: The VGG of 3D CNNs
Learning Spatiotemporal Features with 3D Convolutional Networks 논문
VGG에 3C CNN을 사용한 버전이다.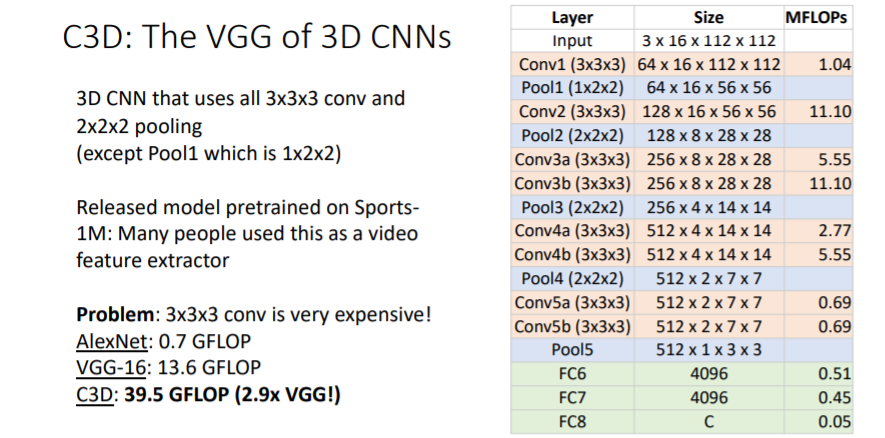 Conv와 Pooling을 사용하였다. 그리고 처음 layer에서만 time이 아니라 space에 대해서만 pooling하였다.
Conv와 Pooling을 사용하였다. 그리고 처음 layer에서만 time이 아니라 space에 대해서만 pooling하였다.
그러나 매우 많은 computations가 필요하고, vgg와 비교하여 무려 3배나 더 많은 computations가 필요하다.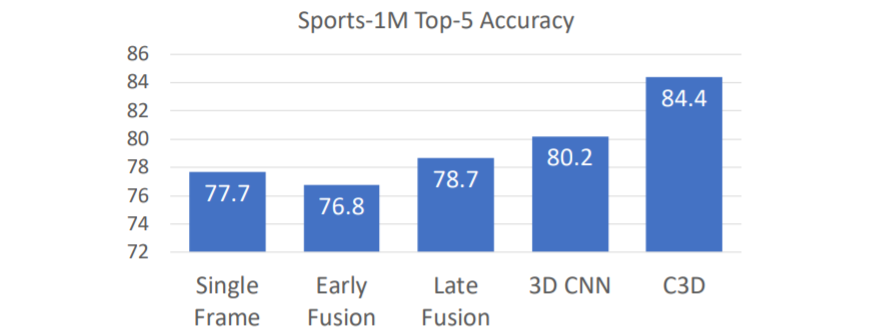 많은 계산을 필요로 하지만 C3D모델은 조금 더 큰폭의 성능 향상을 이루었다. 이는 초기 2D Image classification task에서 더 깊은 모델이 더 좋은 성능을 낸 것과 비슷한 동향이다.
많은 계산을 필요로 하지만 C3D모델은 조금 더 큰폭의 성능 향상을 이루었다. 이는 초기 2D Image classification task에서 더 깊은 모델이 더 좋은 성능을 낸 것과 비슷한 동향이다.
4. Recognizing Actions from Motion
위에서 살펴봤던 방식들은 space와 time을 같은 방식으로 다루고 있다. Input도 space와 time이 합쳐진 형태이고, 같은 Conv를 통해 둘을 함께 다룬다.
그러나 우리는 이 둘이 다른 것을 알고 있고, 따라서 motion과 time을 따로 나누어 다른 방식으로 (서로에게 더 나은 방식으로) 다루는 방식에 대해 살펴보아야 한다.
여기에서는 motion을 더 명시적으로 representation할 수 있는 방식에 대해 살펴본다. We can easily recognize actions using only motion information
We can easily recognize actions using only motion information
사람은 위의 점들처럼 매우 low-level의 motions를 가지고 어떤 action이 일어나는지 쉽게 알아차릴 수 있다.
즉, 비디오(이미지)의 모든 픽셀을 하나하나 다 살피지 않고서도 action을 쉽게 알아차릴 수 있다는 것이다. 게다가 그 action을 하는 것이 사람임을 보지 않고서도 알아차릴 수 있다!
이러한 motion 정보를 explicit하게 표현하는 방식이 존재한다.
4.1) Measuring Motion: Optical Flow
Two-Stream Convolutional Networks for Action Recognition in Videos 논문
motion을 measuring하는 방법으로 Optical Flow가 있다. a pair of adjacent video frames 를 input으로 받아서 각 pixel마다 다음 frame에 어디에 위치해 있을지를 설명하는 Optical flow를 계산한다. (input으로 받은 두 frames 사이의 displacement(변위)를 준다.)
a pair of adjacent video frames 를 input으로 받아서 각 pixel마다 다음 frame에 어디에 위치해 있을지를 설명하는 Optical flow를 계산한다. (input으로 받은 두 frames 사이의 displacement(변위)를 준다.)
optical flow를 계산하는 알고리즘은 여러가지가 존재하지만 다루지 않고 넘어갔다.
위 그림의 오른쪽 그림은 horizontal과 vertical에 대한 Optical flow로, 사람의 팔에 대한 local motion을 highlighting한다. 즉 optical flow는 motion을 highlighting한다.
즉, Optical flow는 motion에 대한 low-level signal로, 이를 CNN에 통과시켜 어떤 일이 일어나고 있는지 명확히 할 수 있다.
4.1.1) Separating Motion and Appearance: Two-Stream Networks
video recognition에 대한 매우 유명한 모델인 Two-Stream Networks이다. 두개의 ConvNet Stacks를 병렬적으로 해놓은 구조이다.
두개의 ConvNet Stacks를 병렬적으로 해놓은 구조이다.
-
Spatial stream ConvNet :
single frame baseline이 얼마나 강력한지 우리는 알고 있다. 따라서 이를 사용하여 비디오의 single frame을 input으로 넣고 classification distribution을 predict한다. -
Temporal stream ConvNet:
motion information에 대해서만 다룬다. 개의 frames가 있는 clip을 input으로 받아서 각 adjacent video frames pair에 대한optical flow를 계산한다.
개의 frames를 받았기 때문에 개의optical flowset이 나온다. 그리고 각각의optical flowfields는 2 channel-dim을 갖는다(와 ). 이들(개)을 전부 concatenate하여 하나의 big tensor로 만든다. 그리고 이들을 가지고 Early Fusion방법을 사용한다. 그리고 일반적인2D Conv를 진행한다.
Temporal stream에서도 Spatial stream과 독립적으로 classification decision을 진행한다. 여기에서는 motion information만을 사용하여 classification을 한다.
Train에서는 이 둘을 독립적으로 학습시키고, Test시에는 이 둘에서 각각 나온 classification distribution을 average하여 최종 class score을 계산한다.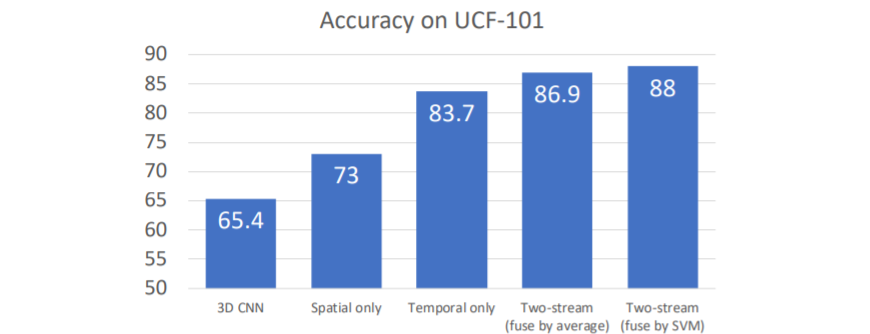
UCF-101데이터셋에서 측정한 결과이다. Temporal information만 사용하였음에도 엄청난 성능을 내는 것을 확인할 수 있다. 이는 인간만 motion을 가지고 action을 쉽게 알아차리는 것이 아니라 컴퓨터도 이를 해낼 수 있음을 알 수 있다.
그리고 Two-stream을 사용한 결과 더 나은 성능을 낼 수 있다.

정말 감사합니다. 저희 프로젝트에 큰 도움이 될 것 같네요ㅠㅠ