Abstract
sparse set을 보강함으로써 comples scenes의 novel views를 합성하는 방식을 제안한다. 일반적인 Neural scene representation 방법들(렌더링을 위해 장면별로 함수를 최적화 하는 방식)과 달리, novel scenes로 일반화하는 generic view interpolation function을 학습한다. 또한, classic volume rendering을 사용하여 이미지를 렌더링한다.
1. Introduction
-
IBR
novel view synthesis의 초창기 연구는
image-based rendering(IBR)에 집중되어있었다.
IBR 방식은 보통 warping, resampling, blending 등을 통해 만들었다. 그러나 매우 많은 input views가 필요하였다. -
Neural scene represantations
좋은 성능을 내었지만, 각각의 새로운 scene마다 매우 긴 최적화 과정을 필요로 하였다. 이는 실생활에 사용하기 힘들었다.
이 논문에서는 IBR과 NeRF의 아이디어를 가져와 ray를 렌더링하면서 densith/occlusion/visibility reasoning/color blending을 동시에 수행하는 일반화된 view interpolation funcion을 학습한다.
ray를 따라 3D location을 샘플링한다 근처의 sourse views로부터 latent 2D features를 얻는다 2D features를 모아서 density feature을 만든다(feature이 표면에 들어날지 아닐지를 결정하는.) ray transformer 모듈이 ray를 따라 이전의 density feature을 고려하여 scalar density value를 계산한다
2. Related Work
Image based rendering
Volumetric Representations
Neural scene representations
3. Method
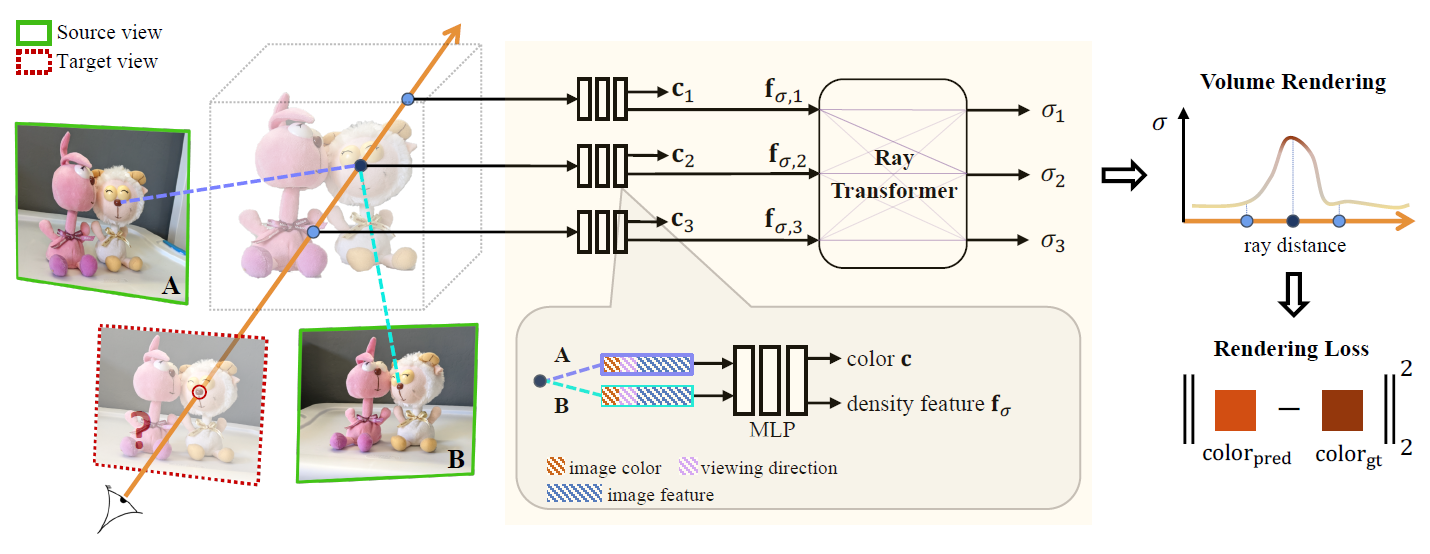
1. target 주위의 source views를 선별하여 input으로 하고 이들로 부터 dense features를 추출한다.
2. 연속적인 5D locations에서의 volume densities 와 colors 를 예측한다.
3. 이들 colors과 densities를 volume rendering으로 합성하여 이미지를 생성한다.
3.1 View selection and feature extraction
전체 scene을 단일 네트워크로 인코딩하려는 neural scene representations와 달리, 논문은 nearby source views를 보간하여 novel target view를 합성한다.
효과적인 target view 근처의 source views를 고르기 위해 target view와 가장 비슷한 방향으로 보고 있는 N개의 views를 고른다.
-th source view에서 은 color image이고, 는 camera projection matrix이다.
shared U-Net based CNN을 사용하여 dense featues 를 각 이미지 로부터 추출한다. 그리고 이들 의 튜플 셋은 target view렌더링의 input으로 사용된다.
3.2 RGB- prediction using IBRNet
IBRNet을 통해 colors와 densities를 예측한다.
ray 위의 point location 를 모든 source views에 project하고, bilinear interpolation으로 colors 와 features 를 추출한다.
3.2.1 Volume density prediction
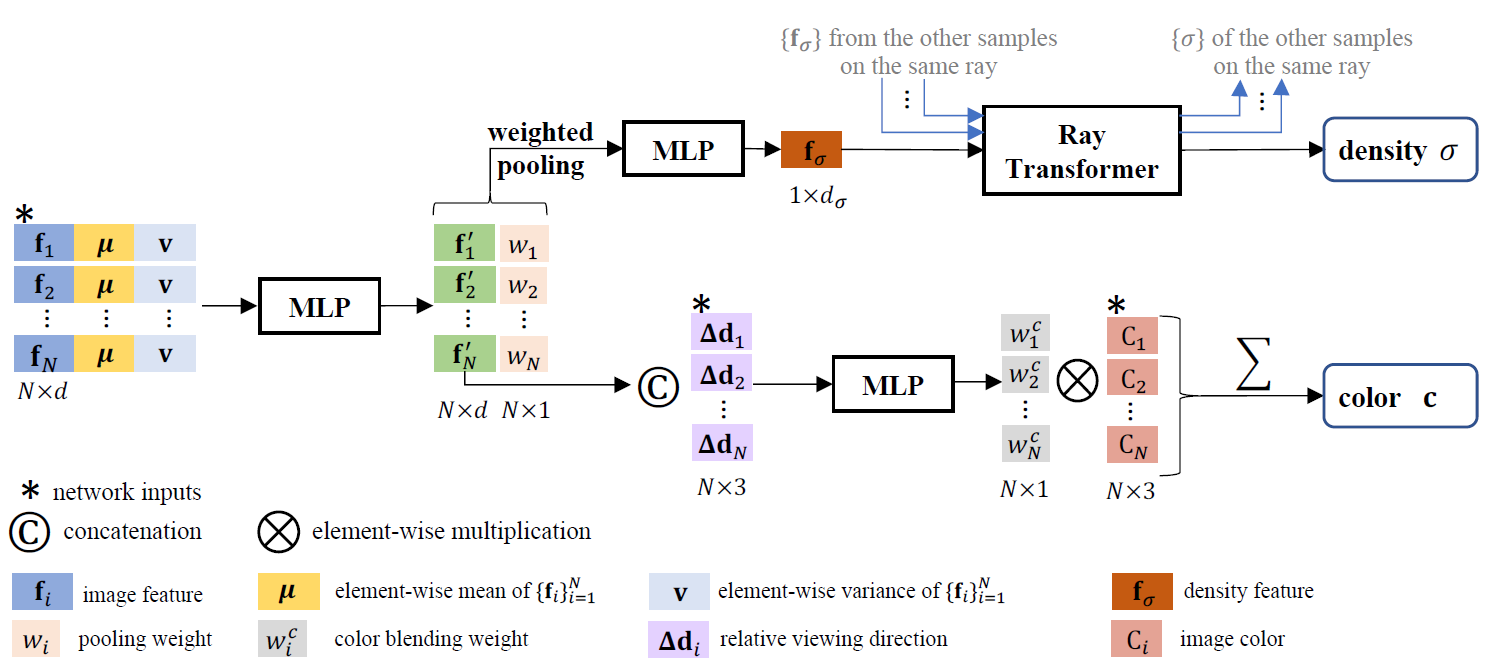
에서 $multi-view features 합쳐서 density feature을 얻는다. 그리고 ray의 모든 샘플들에 대한 density features를 ray transformer가 받고, long-range contextual information을 포함하여 각 샘플에서의 density를 예측한다.
-
Multi-view feature aggregation
features 들 사이의 consistency를 체크하여 density를 추론하는 것이 효과적이다. features로부터 먼저 per-element mean 를 계산하고 variance 를 계산하여 global information을 얻고, 각각의 를 와 와 concatenate한다. 그리고 small shared MLP를 통과하여 local과 global information을 합쳐서 multi-view aware feature 와 weight vector 를 얻는다. 그리고 weighted pooling을 하고 MLP를 통과하여 density feature 를 얻는다.
-
Ray transformer
