논문스터디
1.[논문스터디] FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
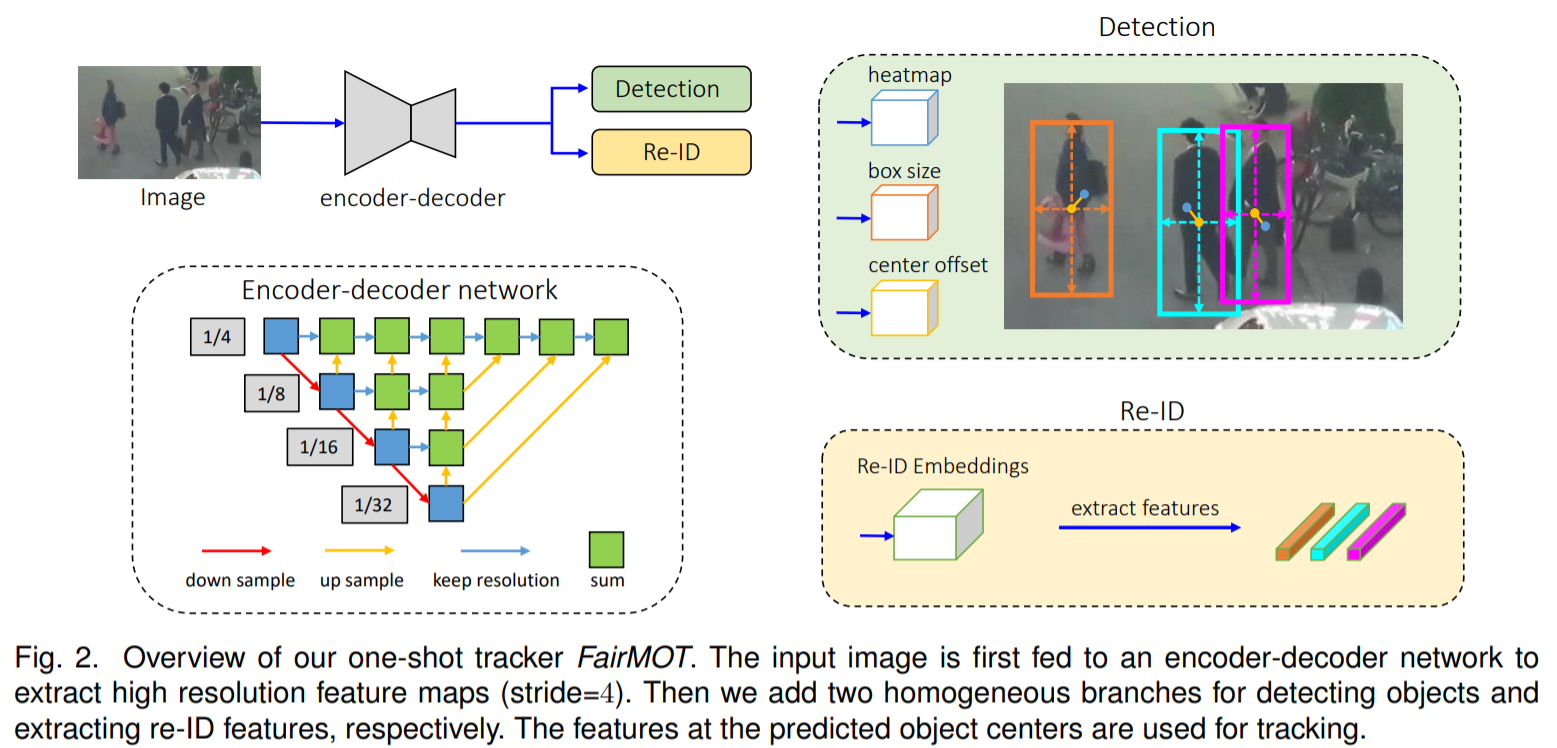
FairMOT 노션에서 작성하였습니다. 링크
2.[논문스터디] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
.png)
fully-connected deep network를 사용하여 scene을 represent한다.input은 single continuous 5D coordinate (spatial location (x, y, z)과 viewing direction ($\\theta$
3.[논문스터디] pixelNeRF: Neural Radiance Fields from One or Few Images

한 개 또는 매우 적은 input images로 작동하는 learning framework인 pixelNeRF를 제안한다. 기존의 방식들은 모든 scene을 독맂벅으로 optimizing하는데, 많은 calibrated views와 많은 시간을 필요로 했다. 그러나 N
4.[논문스터디] Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields

NeRF는 single ray per pixel(픽셀 당 1개의 ray)를 사용하기 때문에 다른 해상도로 관찰할 때 지나치게 흐릿하거나 aliased(계단현상)이 발생할 수 있다. 그러나 픽셀 당 여러 ray를 사용하여 렌더링 하기 위해서는 각 ray를 렌더릴 할 때
5.[논문스터디] Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis

https://www.ajayj.com/dietnerf!youtubeRF_3hsNizqw적은 이미지로도 scene representation 성능 향상이 가능한 DietNeRF를 소개한다. 보조 의미 일관성 손실(auxiliary semantic consist
6.[논문스터디] InfoNeRF: Ray Entropy Minimization for Few-Shot Neural Volume Rendering

few-shot 학습에 대해 information-theoretic regularization을 적용하였다. 제안된 접근방식은, 각 ray에 밀도의 엔트로피 제약(entropy constraint of the density in each ray)을 가함으로써 부족한 v
7.[논문스터디] RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs
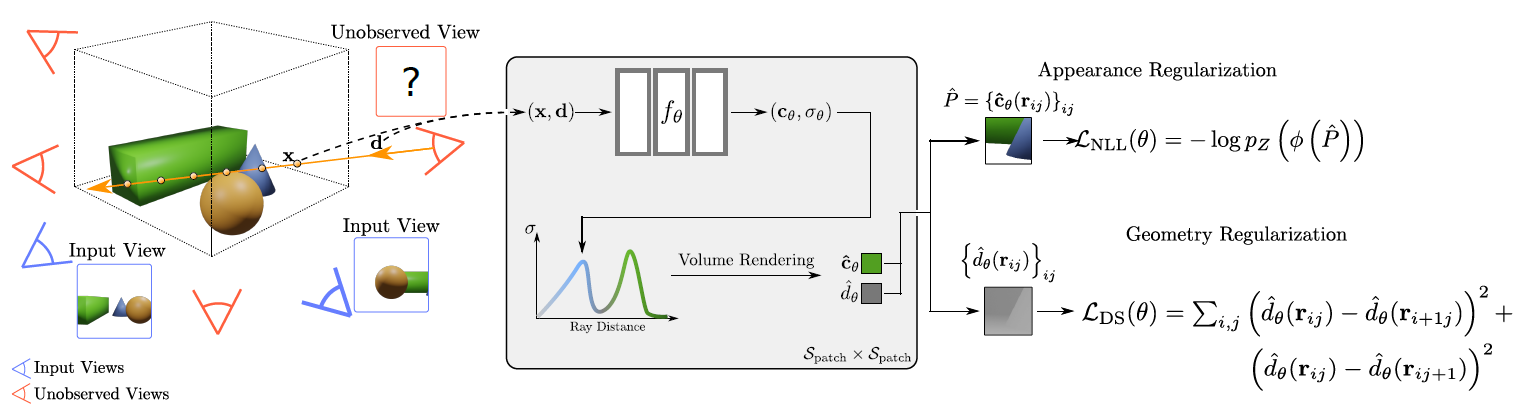
참고자료 https://m-niemeyer.github.io/regnerf/index.html !youtube[QyyyvA4-Kwc] Abstract 부족한 input scenes에서 대부분의 아티팩트는 estimated scene geometry에서의 에러와 학습
8.[논문스터디] IBRNet: Learning Multi-View Image-Based Rendering
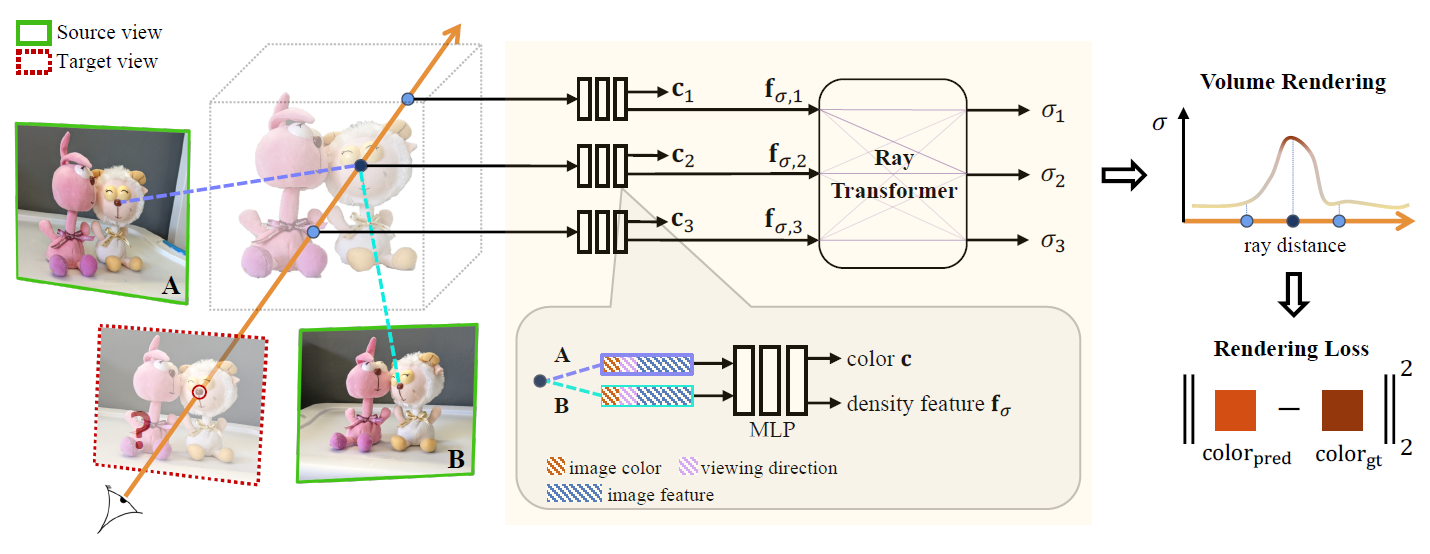
sparse set을 보강함으로써 comples scenes의 novel views를 합성하는 방식을 제안한다. 일반적인 Neural scene representation 방법들(렌더링을 위해 장면별로 함수를 최적화 하는 방식)과 달리, novel scenes로 일반화
9.[논문스터디] Mesh R-CNN

- 논문 정리
