참고자료
Abstract
부족한 input scenes에서 대부분의 아티팩트는 estimated scene geometry에서의 에러와 학습 시작시 발산되는 현상에 의해 발생한다는 것을 관찰했다.
unobserved viewpoints에서 렌더링한 패치들의 geometry와 appearance(외관?)을 regularize하고, 학습 과정에서 ray sampling space를 해제함으로써 이를 해결했다. 그리고 추가적으로 normalizing flow model을 사용하여 unobserved viewpoints의 색을 정규화했다.
1. Introduction

문제점
PixelNeRF와 같은 모델은 multi-view 이미지와 카메라 포즈 주석이 있는 많은 장면의 대규모 데이터셋에 대한 pre-training이 필요하다. 이러한 모델은 좋은 결과를 달성하지만, 다양한 장면을 캡쳐하거나 렌더링하여 필요한 pre-training 데이터를 얻는 것은 엄청난 비용이 들 수 있다.
게다가 이러한 기법은 테스트시 새로운 영역(novel domains)에 일반화되기 힘들 수 있으며, 희박한 입력 데이터의 모호성으로 인한 흐릿한 아티팩트가 나타날 수 있다.
한가지 대안적인 접근방식은 모든 새로운 장면에 대해 처음부터 네트워크 weights를 최적화하고, sparse input에서의 성능향상을 위해 regularization을 진행할 수 있다.(e.g. extra supervision을 추가하거나 | input views를 대표하는 embeddings를 학습(DietNeRF)하는 등) 그러나 이 방식들은 항상 사용할 수 있는 걸이 아닌 외부 supervisory signals에 의존하거나, high-level information만 제공하는 저해상도 렌더링에서만 작동된다.
Contribution
- unobserved viewpoints로부터 렌더링된 depth maps를 위한 patch-based regularizer.
아티팩트를 줄이고 scene geometry를 개선함. - 렌더링된 패치의 log-likelihood를 최대화함으로써 unseen viewpoints에서 예측되는 색을 regularize하여 다른 views 사이의 color shift(색 변이 현상?)를 방지함.
- scene content를 작은 범위로 샘플링하여 학습 초기에 발산하는 것을 방지함.
2. Related Work
mip-NeRF를 기반으로 하지만, 훨씬 더 희박한 input scenario에서 novel views를 합성한다.
scene geometry와 appearance를 regularize함으로써, 3개의 wide-baseline만으로도 높은 품질의 렌더링이 가능하다.
Sparse Input Novel-View Synthesis
많은 input을 요구하는 상황을 피하기 위해, radiance fields 모델을 pre-train하여 prior knowledge를 모아왔다.(PixelNeRF)
PixelNeRF는 input images로부터 local CNN featues를 추출하여 사용하였다.
MVSNeRF는 이미지 와핑을 통해 3D cost volume을 얻었다.
이러한 방식들은 pre-training을 위해 여러 다른 장면에 대한 multi-view image 데이터셋을 필요로 하였다. 이러한 데이터들은 항상 존재하지 않고 얻기에 어렵다.
In this work
이 논문에서는 novel views에서의 geometry와 appearance를 regularize하는 방식으로 값비싼 pre-training을 피하였다. 이러한 방식은 DS-NeRF와 DietNeRF에서도 포함하고 있다.
DS-NeRF와 비교하여 논문의 접근방식은 RGB images만 사용하고, depth input을 필요로 하지 않는다.
그리고 DietNeRF는 저해상도로 렌더링된 unseen viewpoints에 대한 CLIP 임베딩을 비교하는 방식을 사용하지만, 이러한 semantic consistency loss는 high-level 정보만 제공하며 sparse inputs에 대한 scene geometry를 향상시키지 못한다. 이와 비교하여 이 논문에서는 rendered patches에 기반한 scene geometry와 appearance를 regularize한다.
3. Method
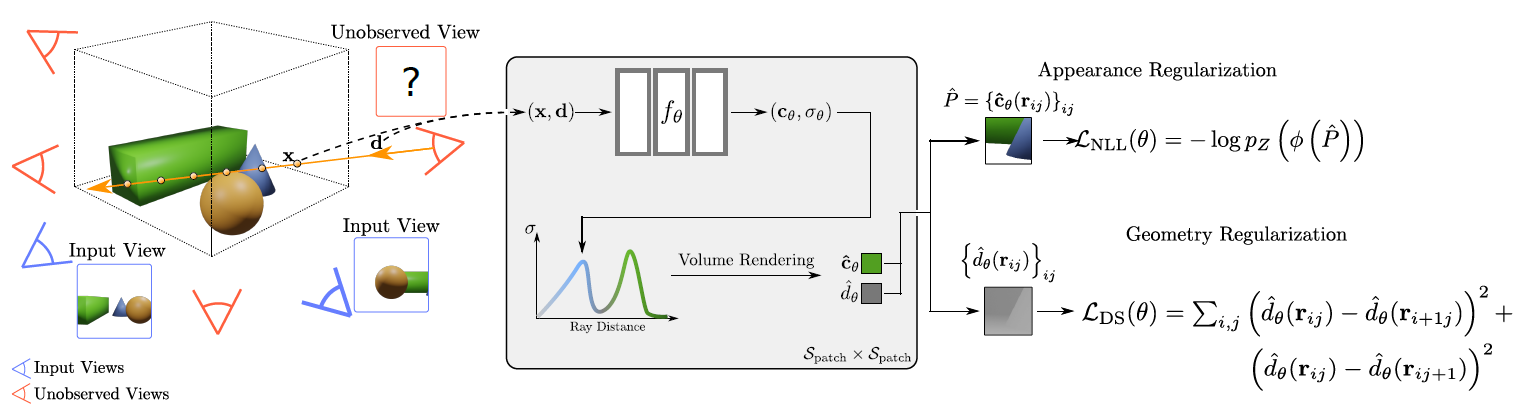
mip-NeRF의 view synthesis는 부정확한 scene geometry와 학습시 발산으로 인해 품질이 떨어진다. 이를 극복하기 위해 unseen viewpoints에서의 predicted color과 geometry를 regularize한다.(patch-based approach로)
3. Background
mip-NeRF
NeRF가 단일 ray : 단일 픽셀인 바면에 mip-NeRF는 cone을 캐스팅한다. positional encoding은 극소점을 나타내는 것에서 conical frustum(원추형 단면)으로 덮인 볼륨에 대한 누적으로 변경되었다.
3.2 Patch-based Regularization
sparse input 상황에서 NeRF는 과적합 문제를 발생시킨다. 이러한 문제를 해결하기 위해 논문에서는 unseen viewpoints에 대해 regularize를 한다.
구체적으로 말해서, unseen이지만 관련성이 있는 viewpoints를 정의하고, 이러한 카메라로부터 랜덤으로 추출한 작은 패치를 렌더링한다. 이러한 패치들을 regularize하여 부드러운 geometry와 높은 확률의 색상을 생성할 수 있다.
-
Unobserved Viewpoint Selection (여기 다시 공부해봐야될듯 잘 모르겠다)
unobserved viewpoints에 대해 regularization을 적용하려면 먼저 unobserved camera poses에 대한 sample space를 정의해야한다.
-
Geometry Regularization
실제 세계에서 geometry는 객체(조각)별로 매끄럽다. (즉, 평평한 표면이 high-frequency structure보다 가능성이 높다) unobserved viewpoints에서 depth smoothness를 장려함으로써 위의 prior을 모델에 적용하였다.
이 논문에서는 expected depth를 아래와 같이 계산하였다.Depth smoothness loss
: camera poses 로부터 샘플링된 a set of rays
: 을 중심으로 한 패치의 픽셀 를 통과하는 ray
: the size of rendered patches -
Color Regularization
degenerate colores(color shitfs)를 피하고 안정적인 최적화를 위해서 color prediction 또한 regularize한다. rendered patches의 likelihood를 예측하고 최적화 과정에서 이를 maximize시킽다. 이를 위해서 즉시 사용할 수 있는 구조화되지 않은 2D image 데이터셋을 사용한다.
는
RealNVP normalizing flow model로 학습된 bijection mapping an RGB patch of size to 이다.
Color regularization loss: 에서 샘플링한 a set of rays
: 중심 에서 예측한 RGB color patch
: negative log-likelihood with Gausian -
Total Loss
: input poses에서의 a set of rays
: random poses 에서의 a set of rays
3.3 Sample Space Annealing
sparse input 상황에서 NeRF는 학습 초기에 발산하기도 하는 문제를 갖고 있다. 샘플링된 scene space를 최적화 과정의 초기 iterations에 걸쳐 신속하게 annealing(초기에 무작위성을 최대로 하고 점차 낮춘다)하면 이런 문제를 해결할 수 있다.
를 camera의 near and far plane이라고 하고, 을 둘 사이의 중앙이라고 하면,
라고 정의하였다. 는 현재 training iteration이고, 는 full range로 도달할때까지의 iteration을 나타내는 하이퍼파라미터이다. 는 start range(e.g., 0.5)를 나타내는 하이퍼파라미터이다.
이러한 annealing을 input poses와 sampled unobserved viewpoints 모두에 적용하였고, 이 방식은 초기 학습에서의 안정성을 확보하고 발산을 피하도록 도와주었다.
