.png)
Abstract
fully-connected deep network를 사용하여 scene을 represent한다.
input은 single continuous 5D coordinate (spatial location (x, y, z)과 viewing direction (, ))
output은 volume density와 공간에 대한 view-dependent emitted radiance이다.
1. Introduction
사물을 찍은 사진을 가지고 다른 view에서 바라본 모습을 알아내는 task이다. 이 논문에서 저자는 좋은 성능을 위해 새로운 함수를 고안하였다.
Radiance : 에서 의 방향으로 방출되는 광원
Convolutional layers를 사용하지 않고 5D coordinate 로부터 single volume density와 view-dependent RGB color을 얻는다.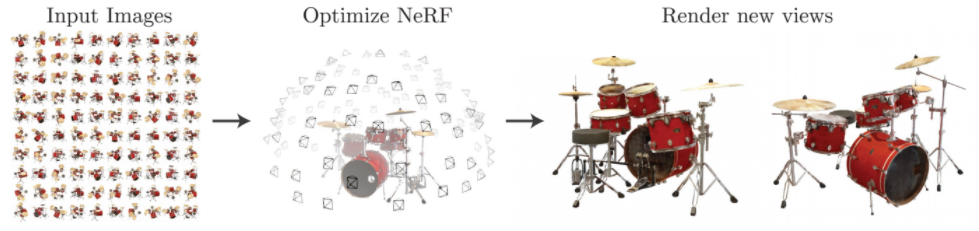
- 카메라 광선을 이동시키며 3D points의 sampled set을 얻는다
- 이 points와 그들의 2D viewing directions를 뉴럴네트워크에 넣어 그 위치에서 바라본 사물의 color와 density를 얻는다
- classical volume rendering techniques로 color과 density를 2D 이미지에 축적한다
-> 이를 통해 새로운 view에서 사물을 바라봤을 때의 장면을 얻을 수 있다.
관찰된 이미지와 NeRF로 생성된 이미지 사이의 에러를 최소화시킴으로써 뉴럴네트워크를 optimize할 수 있다.
2. Neural Radiance Field Scene Representation
의 위치에서 바라보는 방향 를 입력받아 color 와 volume density 를 얻는다.
x에서 바라보는 방향을 직교좌표계 (x, y, z)로 구성된 unit vector d로 표현하여 (x, d) (c, )로 만드는 MLP network를 만들었다.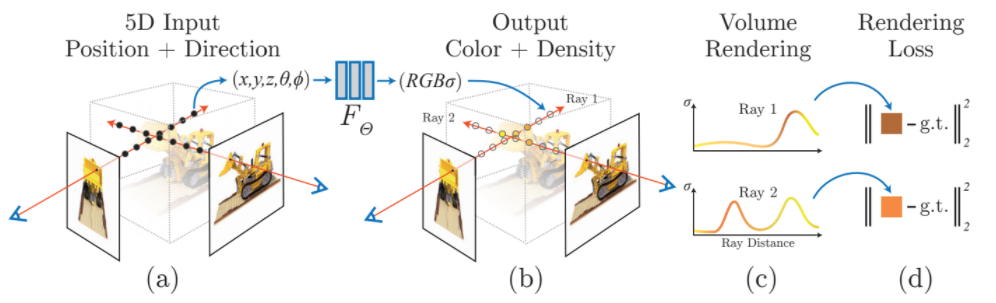
문제점
특정 view에서만 좋은 성능을 내는 편향을 해결하기 위해서
- x만을 가지고 volume density 를 구한다.
- x, d를 가지고 c를 구한다.
3. Volume Rendering with Radiance Fields
Expected color 구하기
volume density는 x 위치의 극소입자에서 끝나는 광선의 미분 확률로 해석할 수 있다. (The volume density σ(x) can be interpreted as the differential probability of a ray terminating at an infinitesimal particle at location x.)
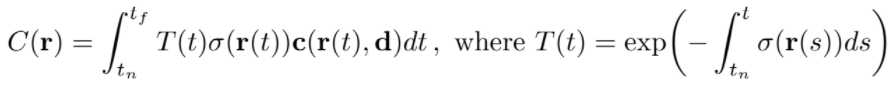 는 부터 까지 ray가 사물을 통과할 때 만나는 점들에서의 투과율을 축적한 것이다.
는 부터 까지 ray가 사물을 통과할 때 만나는 점들에서의 투과율을 축적한 것이다.
stratified sampling approach
C(r)의 적분을 효과적으로 계산하기 위해 사용하는 방식으로, 적분구간 를 N개의 구간으로 나누고, 각 구간에서 임의로 하나씩 뽑아 discrete한 적분의 구간으로 사용한다.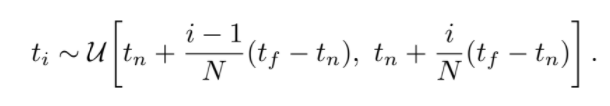 적분에 사용할 값들(ti)를 선별하여 필요없는 픽셀을 적분범위에서 제거할 수 있다.
적분에 사용할 값들(ti)를 선별하여 필요없는 픽셀을 적분범위에서 제거할 수 있다.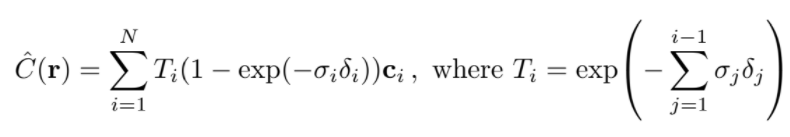 는 인접한 샘플들 사이의 거리이다.
는 인접한 샘플들 사이의 거리이다.
4. Optimizing a Neural Radiance Field
Positional Encoding과 Hierarchical sampling procedure 기법을 사용하여 NeRF가 고주파 Scene을 표현할 수 있게 한다.
-
Positional Encoding
input coordinates를 positional encoding하여 고주파 데이터를 처리할 수 있도록 MLP를 돕는다. -
Hierarchical sampling procedure
고주파 scene을 효율적으로 sampling할 수 있게 돕는다.
4.1 Positional encoding
고주파 함수로 input data를 고차원 data로 매핑하여 input에 넣으면 고주파 영역에 더 잘 fit함을 알 수 있다. 따라서 기존의 네트워크 가 를 바로 처리하기보다 로 reformulate를 하였다. 는 을 의 고차원 space로의 매핑이고 는 여전히 regular MLP이다. encoding function을 자세히 보면, 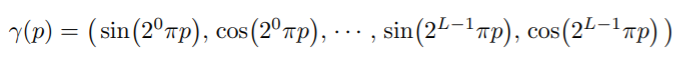
NeRF에서 positional encoding은 transformer에서와 조금 다르게, 연속적인 입력 데이터의 좌표들을 고차원 데이터로 매핑하여 MLP가 고차원 함수를 더 쉽게 근사할 수 있도록 한다.
4.2 Hierarchical volume sampling
기존에는 camera ray에서 N개의 point를 임의로 뽑아서 사용하려 했지만 camera ray는 객체뿐만 필요없는 공간까지 포함되어 좋은 결과가 나오지 않았다. 따라서 final rendering에서 예측되는 효과에 비례하게 point를 sampling하는 방식을 사용하였다.
하나의 single 네트워크를 사용하여 scene을 만들기보다, 두개의 네트워크 coarse와 fine을 사용하였다.
Coarse 네트워크
- 개의 위치에서 stratified sampling을 이용하여 값을 뽑는다. 그리고 이 위치들을 가지고
coarse네트워크를 계산한다. coarse네트워크의 output을 가지고 각각의 ray에서 volume density가 높은 좌표를 뽑는다.coarse네트워크에서 alpha composited color을 구하는 식 을 sampled colors 의 weighted sum으로 rewrite한다.
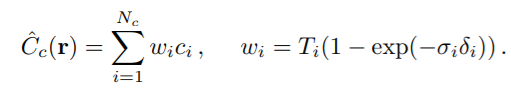
Fine 네트워크
- camera ray에서 inverse transform sampling을 사용해 위치들에서 값을 뽑아내고 의 모든 샘플을 사용하여 을 계산한다.
이 방식을 사용하면 실제로 객체가 존재할 영역에 있을만한 좌표를 더 많이 사용하게 된다. 이를 통해 성능 향상을 이루어냈다.
4.3 Implementation details
Dataset
captured RGB images of the scene, corresponding camera poses, intrinsic parameters(카메라의 특성), scene bounds
로 구성된 데이터셋을 얻는다.
학습 시 each epoch마다 camera ray를 만나는 dataset의 pixel을 일부 선별하여 hierarchical sampling을 수행하고 coarse와 fine네트워크에 넣어서 계산한다.
그리고 volume rendering procedure을 통해 camera ray가 가는 곳의 색상을 렌더링한다.
네트워크로 렌더링한 값과 실제 렌더링 값을 비교하여 loss를 구한다.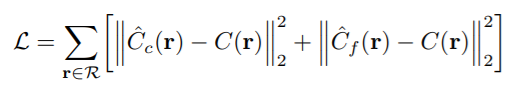 여기에서 은 각 batch의 ray들의 집합이고, 은 각각 ground truth, coarse volume predicted(
여기에서 은 각 batch의 ray들의 집합이고, 은 각각 ground truth, coarse volume predicted(coarse네트워크로 얻은 값), fine volume predicted RGB colors(fine네트워크로 얻은 값) 이다.
5. Results
5.1 Datasets
-
DeepVoxels(Diffuse Synthetic 360)
람베르트 반사 성질을 지닌 표면으로 구성된 4개의 객체. 촬영된 scene은 512x512이고 반구형 궤적으로 촬영되었다. -
Realistic Synthetic 360
non-람베르트 성질을 가진 8개의 객체. 800x800이다.
5.2 Comparisons

 Synthetic dataset comparisons
Synthetic dataset comparisons Real world scenes
Real world scenes
5.3 Discussion
NeRF는 매우 작은 용량을 사용한다. LIFF에서 15GB이상이 필요했던 것에 비해 5MB의 용량으로 네트워크의 weights를 다룬다.
아래 영상을 보면 더욱 이해가 쉽게 될 것 같다.
