
에서 간단한 내용을 확인할 수 있다.
Abstract
한 개 또는 매우 적은 input images로 작동하는 learning framework인 pixelNeRF를 제안한다. 기존의 방식들은 모든 scene을 독립적으로 optimizing하는데, 많은 calibrated views와 많은 시간을 필요로 했다. 그러나 NeRF의 volume rendering방식을 활용하여 명시적인 3D supervision없이 이미지에서 직접 훈련될 수 있다.
1. Introduction
저자는 input view의 희박한 집합에서 장면의 새로운 view를 합성하는 문제를 연구하였다. NeRF가 photorealistic novel views를 렌더링할 수 있지만, 매우 많은 images와 긴 optimization을 필요로하여 실용적이지 않았다.
이미지 features를 전혀 활용하지 않는 기존 NeRF 네트워크와 달리 pixelNeRF는 픽셀마다 정렬된 공간 이미지 feature을 입력으로 가져간다.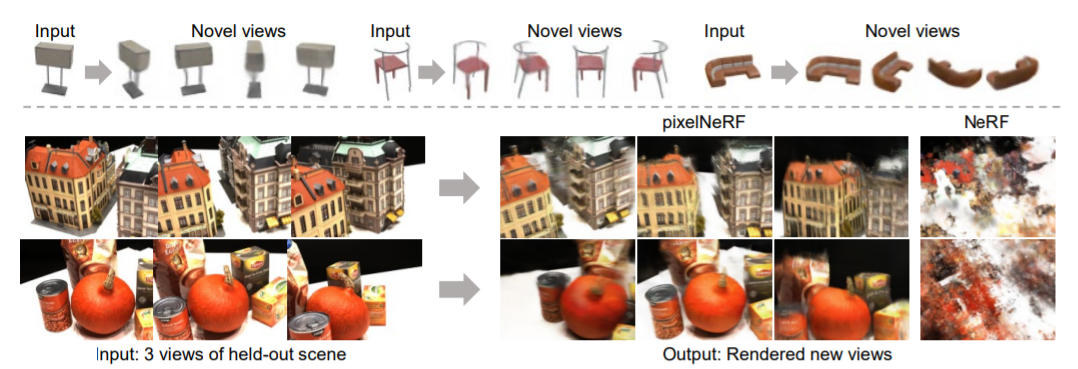
NeRF vs pixelNeRF
구체적으로, 먼저 input image에서 fully convolutional image feature grid를 계산하여 NeRF의 input image를 조절한다. 그리고 각각의 query spatial point 와 viewing direction 에 대해 projection과 bilinear interpolation(이중 선형 보간)을 통해 해당 image feature을 샘플링한다.
query의 사양(specification)은 image features와 함께 density와 color을 출력하는 NeRF 네트워크에 전송되며, 여기서 공간 이미지 특성이 각각의 레이어에 residual로 공급된다.
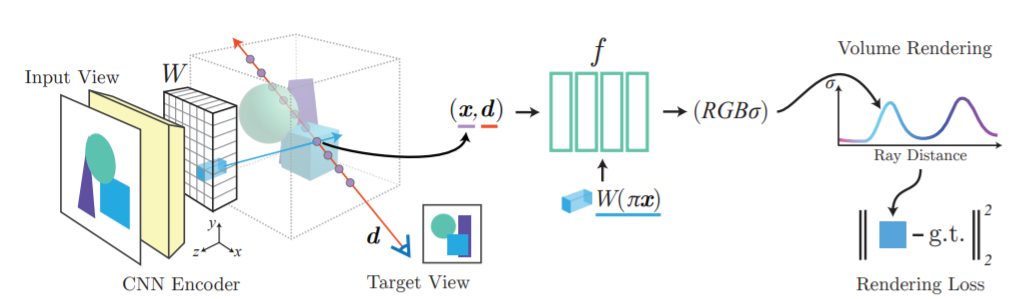
방향으로의 camera ray에서 query point 에 대해 대응되는 image feature은 로 추출된다.(projection과 interpolation을 통해) 이 feature은 spatial coordinates와 함께 NeRF 네트워크 에 들어간다. output인 RGB와 density value는 volume-rendered되고 target pixel value와 비교된다. 는 input view의 camera coordinate system이다.
PixelNeRF의 장점
- ground truth 3D shape나 object masks와 같은 추가적인 supervision없이 multi-view images 데이터셋으로만 학습이 가능하다.
- input image의 카메라 좌표계에서 NeRF representation을 예측한다. (표준 좌표 프레임 대신.) 완전히 정해진 표준 좌표계가 없는 상황에서 유연하다.
- test-time 최적화 없이 다양한 수의 posed input views를 통합한다. (? 무슨말이지)
2. Background: NeRF
NeRF는 color과 density의 연속적인 체적 광도 로 장면을 인코딩한다. 구체적으로, 3D point 과 viewing direction unit vector 에 대해 는 미분가능한 density 와 RGB color 를 return한다.()
그러면, 체적 광도 field는(volumetric radiance field) 아래 식을 통해 2D 이미지로 렌더링 된다.
camera ray 에 대해 렌더링 된 pixel value는 그에 대응하는 ground truth pixel value인 과 비교된다. 따라서 NeRF 렌더링 loss는! 와 같다. 는 target pose 에 대한 모든 camera ray들의 집합이다.
와 같다. 는 target pose 에 대한 모든 camera ray들의 집합이다.
Limitations
NeRF가 SOTA를 달성했지만, 기존의 multiview stereo methods와 유사하게 기하학적 일관성을 유일한 신호로 사용하는 optimization-based 접근법이다. 따라서 scene들 간에 knowledge가 공유되지 않고 각 scene을 개별적으로 최적화해야한다.
이 작업은 시간이 많이 걸릴 뿐만 아니라 single or extremely sparse view(단일 또는 극도록 희박한 장면)의 한계에서 재구성을 가속화하거나 shape completion(형상 완성)을 위해 world의 어떠한 prior knowledge를 사용할 수 없다. (왜지?)
3. Image-conditioned NeRF
scene들 간의 knowlege 공유가 안되는 NeRF representation의 한계를 극복하기 위해 공간 이미지 features에 대해 NeRF를 조절하였다.
저자의 모델은 두개의 components로 구성된다.
1. fully-convolutional image encoder (input image를 pixel-aligned feature frid로 인코딩해준다)
2. NeRF 네트워크 (공간 위치와 그에 대응하는 encoded feature에 대한 color과 density를 출력한다)
위에서 논의된 이유 때문에 표준 공간(canonical space)가 아닌 input view의 카메라 공간(camera space)에서 공간 쿼리를 모델링하기로 결정하였다.
3.1 Single-Image pixelNeRF
우리는 한개의 input image로부터 novel views를 렌더링 하는 방식을 설명하였다. 우리는 좌표계를 input image에 대한 view space로 고정하고, 이 좌표계에서 위치와 camera ray를 지정하였다.
scene에 대한 input image 가 주어지면, 먼저 feature volume 를 추출한다. 그리고 camera ray의 point 를 known intrinsics를 사용하여 image 평면(image 좌표 에 투영하여 대응하는 image feature을 검색한다. 그리고 pixel단위 features 사이에 bilinearly interpolate를 하여 featuer vector 를 추출한다.
image features는 NeRF네트워크로 전송된다.(input view 좌표계의 position과 view direction과 함께) 은 기존의 NeRF에 도입된 6개의 기하급수적으로 증가하는 주파수를 가진 상의 positional encoding이다.
은 기존의 NeRF에 도입된 6개의 기하급수적으로 증가하는 주파수를 가진 상의 positional encoding이다.
Query view direction
few-shot view 합성 task에서 query view direction은 NeRF네트워크에서 특정 image feature의 중요성을 결정하는데 유용하다.
query view direction이 input view방향과 유사한 경우, model은 input에 더욱 의존할 수 있다. 그렇지 않은 경우 model은 학습된 prior을 활용해야한다.
multi-view의 경우에, view directions는 다른 view의 관련성과 위치에 대한 신호로 작용할 수 있다. 이러한 이유로, 우리는 NeRf네트워크의 시작부분에 view방향을 입력한다.
(무슨 말일까..)
3.2 Incorporating Multiple Views
Multiple views는 scene에 대한 추가 정보를 제공하고 single view case에 내재된 3D 기하학적 모호성을 해결한다. 테스트 시 single input view만 사용하도록 설계된 기존 접근방식과 구별하여, 우리는 임의의 수의 view를 허용하도록 모델을 확장하였다.또한, 우리의 공식은 world space의 선택과 input views의 순서와 무관하다.
multiple input views를 가졌다고 했을 때, 우리는 상대적인 카메라 포즈만 알 수 있다고 가정한다.(무슨말?)
번째 input image를 라고 하고, 이와 관련된 camera transform from the world space to its view space를 라고 한다.
새로은 target camera ray에 대해, 우리는 query point 와 view direction 를 각 input view 의 좌표계로 transform한다. output인 density와 color을 얻기 위해 각각의 view좌표 프레임에서 좌표와 해당 features를 독립적으로 처리하고 NeRF네트워크 내의 view에서 집계한다.
output인 density와 color을 얻기 위해 각각의 view좌표 프레임에서 좌표와 해당 features를 독립적으로 처리하고 NeRF네트워크 내의 view에서 집계한다.
각각의 input image를 feature volume 으로 인코딩한다. view-space point 에 대해 대응되는 image feature을 projected image 좌표 의 에서 추출한다.
그리고 이 inputs를 NeRF의 initial layer인 에 넣어서 intermediate vectors를 얻는다. intermediate 는 average pooling operator 와 합쳐진후 final layer인 로 보내져서 density와 color을 예측한다.
intermediate 는 average pooling operator 와 합쳐진후 final layer인 로 보내져서 density와 color을 예측한다.
4. Experiments
우리는 세가지 카테고리로 테스트 하였다.
1. ShapeNet benchmarks for category-specific and category-agnostic view synthesis
2. ShapeNet scenes with unseen categories and multiple objects, both of which require geometric priors instead of recognition, as well as domain transfer to real car photos
3. Real scenes from the DTU MVS dataset

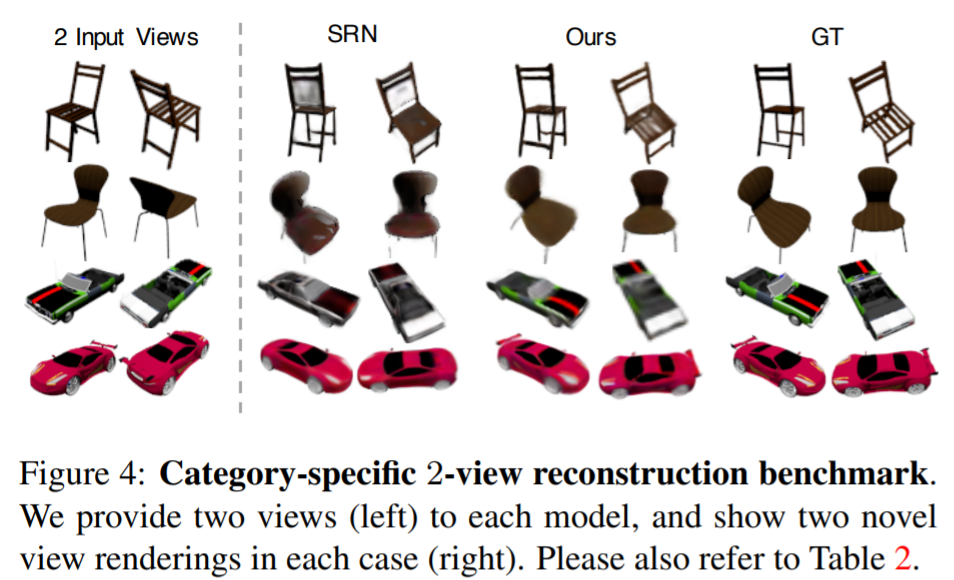
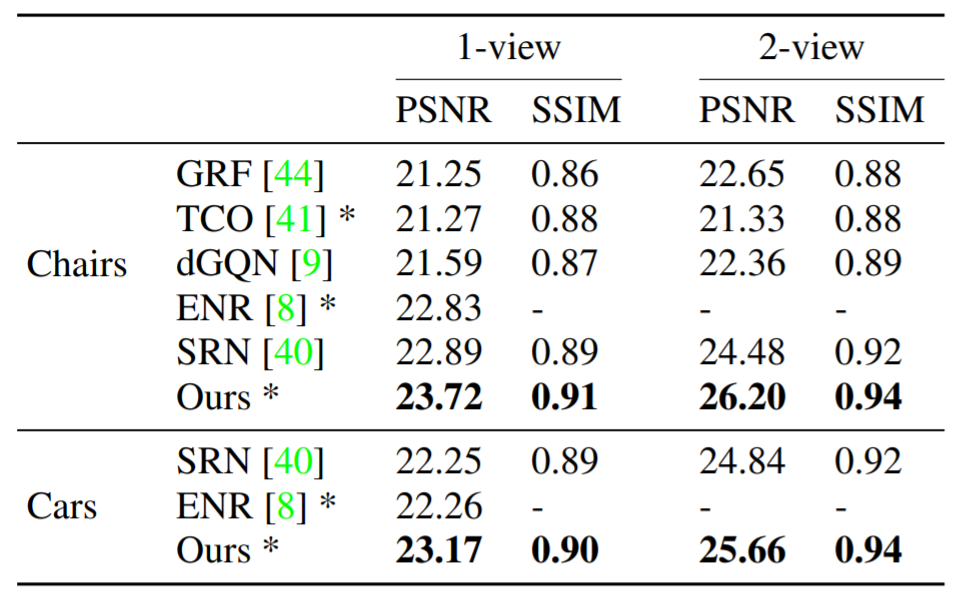
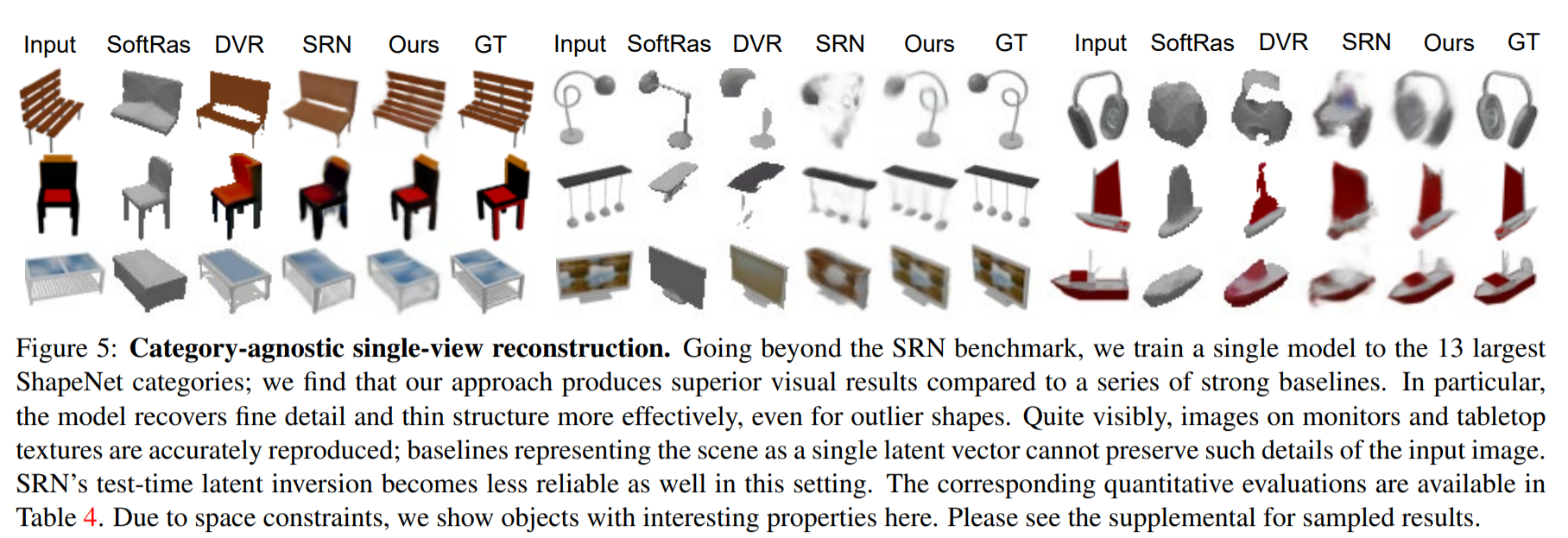
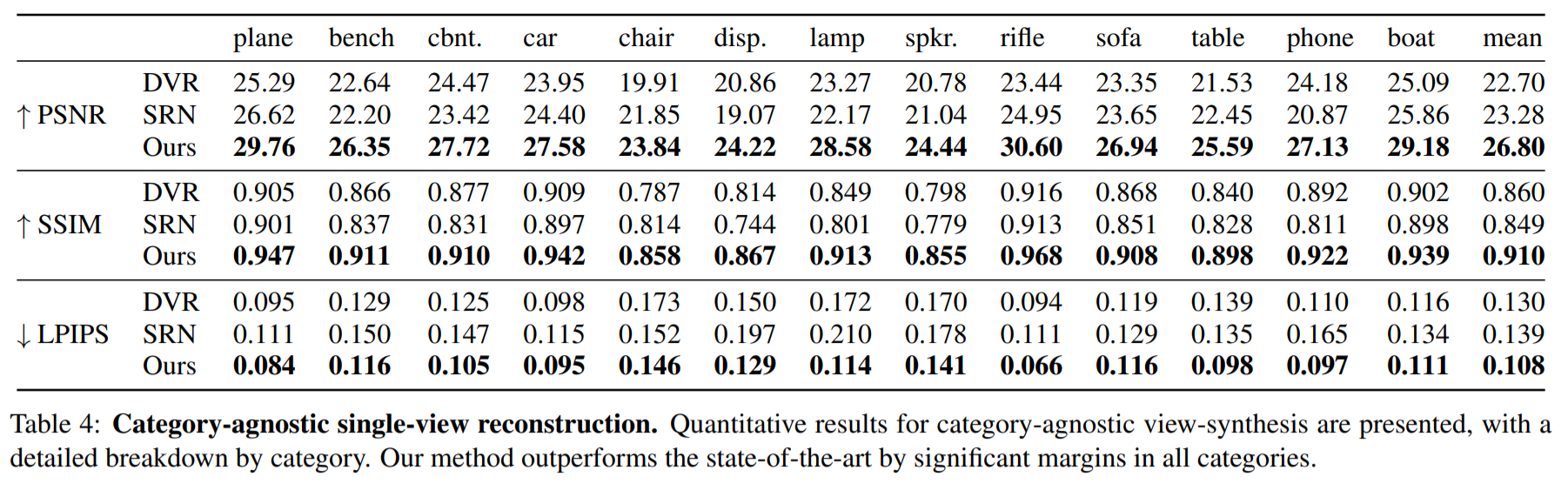


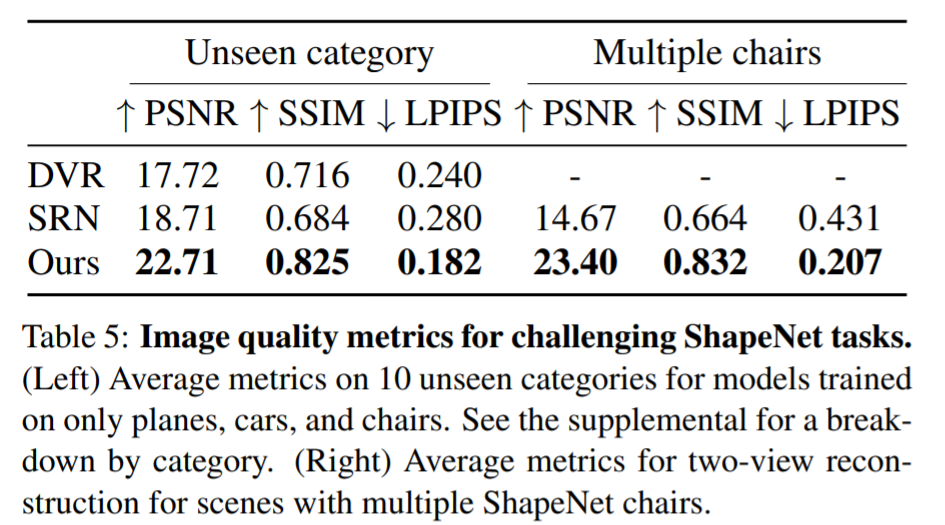


5. Discussion
저자는 하나 또는 몇 개의 image에서 NeRF를 재구성하기 위한 scene prior을 학습하는 프레임워크인 pixelNeRF을 제시하였다.
한계점
- NeRF와 같이 rendering time이 느리고, input views가 더 들어올 수록 선형적으로 runtime이 증가한다.
- 다른 방식들이 mesh를 recover할 수 있는 반면 NeRF기반은 매우 사실적으로 mesh를 변환할 수 없다.
- vanilla NeRF와 같이, 저자는 ray sampling bounds 과 positional encoding의 스케일을 자체적으로 튜닝했다. NeRF관련 방식에서 스케일 불변으로 만드는 것은 매우 어렵다.
- 궁극적으로 저자의 접근법은 large-scale wide baseline multi-view datasets에서 병목현상을 일으킨다. 이로인해 ShapeNet 및 DTU와 같은 데이터셋의 적용 가능성을 제한한다.
느낀점
무슨말이지? ㅜ.ㅜ

ㅜ.ㅜ