Context-aware Domain Adaptation for Time Series Anomaly Detection
Kwei-Herng Lai, Lan Wang, Huiyuan Chen, Kaixiong Zhou, Fei Wang, Hao Yang, Xia Hu
Proceedings of the 2023 SIAM International Conference on Data Mining (SDM), 2023
Abstract
문제점:
- 시계열 이상 탐지는 실제 응용 분야가 넓지만, label 부족 때문에 어려운 문제임
- deep anomaly detector 훈련은 종종 비지도 학습에 의존함
- 최근에는 유사한 도메인의 지식을 활용하기 위한 time series domain adaptation 연구가 활발함.
- 'negative knowledge transfer' 문제:
- source domain에서 학습한 지식이 target domain의 성능을 오히려 악화시키는 경우
- 이상치의 다양성과 희소성
- 맥락(context)의 중요성
- source domain에서 학습한 지식이 target domain의 성능을 오히려 악화시키는 경우
본 연구의 동기 및 목표:
- 두 도메인 간의 'context alignment'에 대한 실증 연구에서 영감을 받음.
- context alignment: 두 개의 서로 다른 시계열 도메인에서 특정 사건(특히 이상치)을 이해하는 데 필요한 context window의 크기가 서로 다르다면, 이 context window의 크기를 각 도메인에 맞게 조절하여 유사하게 만드는 과정
- 두 도메인에 대한 context information를 adaptively sampling하여 지식을 전이하는 것을 목표로 함
- sampling: 시계열 데이터에서 분석에 필요한 일정 길이의 subsequence(context window)를 잘라내는 행위
- 이 context window의 크기를 adaptive하게
- 복잡한 도메인 내 시간 의존성과 cross-domain correlation을 동시에 모델링해야 함.
- source domain의 레이블 정보를 효과적으로 활용해야 함.
제안 방법론:
- 'context sampling'과 'anomaly detection'를 결합한 '공동 학습(joint learning) 프레임워크'를 제안
- context sampling 문제를 'Markov decision process(MDP)'으로 공식화함.
- deep reinforcement learning을 활용하여 context sampling을 통한 Time Series Domain Adaptation 프로세스를 최적화함
- 이상 탐지를 위한 두 도메인의 더 나은 정렬을 위해 'domain-invariant features'을 생성하는 맞춤형 보상 함수를 설계함
1. Introduction
Time Series Anomaly Detection
- Label Sparsity: 이상에 대한 label 매우 제한적
- Complex Temporal Dependencies: 개별 시점 간의 복잡한 연관성 때문에 이상을 탐지하기 어려움
Time Series Domain Adaptation
기존 방법 1) Domain Discrepancy Minimization : 도메인 불일치 최소화
- 두 도메인의 subsequence를 shared subspace으로 매핑한 후, metric distance를 강제로 최소화
- 두 도메인의 데이터 분포가 다를 경우 비최적화된 subspace 초래하여 negative knowledge transfer
기존 방법 2) Domain Discrimination : 도메인 판별
- 적대적 학습을 통해 domain invariant 특징을 추출
- 두 도메인의 subsequence 길이가 잘 정렬되지 않으면 학습 어려움
Context Alignment
서로 다른 도메인 간의 지식 전이를 촉진하려면 시점의 "context" (서브시퀀스의 길이)를 정렬하는 것이 매우 중요
- 컨텍스트 정렬 없이 지식 전이를 시도할 경우 부정적인 전이가 발생할 수 있음
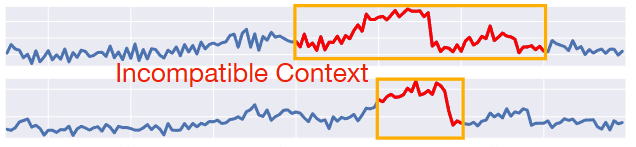
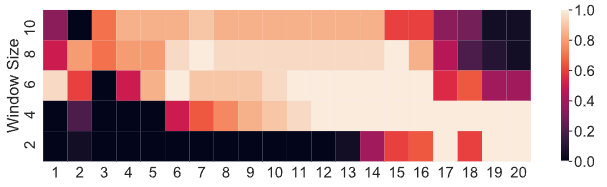
- target domain의 윈도우 크기를 조절할 때 이상 탐지 성능이 향상됨. 특정 이상치는 특정 윈도우 크기에서 더 잘 탐지됨
ContextTDA
- Context Sampling 문제 정의: 문맥 샘플링 문제를 Markov Decision Process(MDP)로 정형화
- Deep Reinforcement Learning 활용: Deep Q-learning(DQN)과 같은 DRL 알고리즘을 사용하여 문맥 샘플링 과정을 최적화
- Tailored Reward Function 설계: 도메인 불변 특징을 생성하고 두 도메인을 이상 탐지에 더 잘 정렬하기 위한 보상 함수를 설계
2. Preliminary
2.1 Problem Statement
- 이상치 점수 함수 (): 입력 데이터 를 바탕으로 각 시점 의 이상치 정도를 평가하는 함수 .
→ 점수가 높을수록 이상치일 가능성이 높음. - Context Window: 이상치 점수 함수 의 입력 데이터인 는 에서 Context Window 크기 을 이용해 샘플링된 서브시퀀스
- 최종 목표: 컨텍스트 샘플링 정책을 사용하여 소스 도메인 정보(와 레이블 )를 타겟 도메인의 이상치 탐지기 로 전달하여 의 성능을 최적화하는 것임.
Context Sampling Problem
- 목표: 이상 탐지기와 함께 샘플링 정책 를 공동으로 학습하는 것
- 샘플링 정책(): 와 를 두 개의 컨텍스트 윈도우 크기 과 으로 매핑
- 도메인 적응: 이 과 을 사용하여 소스 도메인의 서브시퀀스 와 타겟 도메인의 서브시퀀스 를 샘플링
- 최적화: 이를 통해 타겟 도메인 에서의 이상 탐지 성능을 최적화하는 것을 목표로 함.
2.2 Deep Time Series Anomaly Detection
Deep Learning 기반의 시계열 이상 탐지 방법들은 정상 데이터가 고차원 공간에서 밀집된 형태를 보인다는 가정에 기반
→ 이를 위해 오토인코더를 사용하여 데이터의 주된 패턴을 모델링하고, 정상과 이상 데이터의 경계를 식별
- Sliding Window: 시계열 데이터를 고정된 크기의 슬라이딩 윈도우로 분할하여 지역적 패턴을 반영하는 서브시퀀스를 생성함.
- Autoencoder: 인코더와 디코더로 구성된 오토인코더를 사용해 주된 패턴을 모델링. 입력 서브시퀀스와 디코더를 통해 재구성된 서브시퀀스 간의 불일치를 최소화하는 방식으로 학습.
- Loss Function:
- = 분할된 시계열 데이터 텐서, = 인코더, =디코더
- 이상치 탐지: 학습된 오토인코더는 잠재적 이상치 서브시퀀스의 손실 값(재구성 오류)을 정상 서브시퀀스보다 훨씬 크게 만듦.
모델 확장:
- LSTM: MLP 대신 LSTM을 사용하여 개별 서브시퀀스 간의 시간적 상관관계를 추가로 포착할 수 있음.
→ 본 논문에서 이를 핵심 이상 탐지기로 채택. 다른 RNN 기반 이상 탐지기들도 이 프레임워크에 적용 가능
2.3 Time Series Domain Adaptation
1. Domain Discrepancy Minimization
두 도메인의 데이터를 공통 공간으로 매핑해 특징 벡터 간 거리를 최소화한다.
→ 기존 연구는 서브시퀀스 크기를 정렬하는 데 사용되었지만, 이상 탐지에는 적용하기 어렵다.
- 공통 subspace에 매핑하는 mapping function
2. Domain Discrimination
GAN과 유사한 적대적 학습을 통해 도메인을 구별할 수 없는 특징을 만든다.
→ 이 방법들 역시 주로 분류나 예측에 맞춰져 있어, 소수 분포인 이상치 탐지 문제에 직접 적용하면 negative transfer를 유발할 수 있다.
-
: 생성자(G)는 판별자(H)를 속여서 목적 함수를 최대화하려 하고, 판별자(H)는 도메인을 정확히 구분해 목적 함수를 최소화하
-
판별자가 실제 데이터()를 '진짜'로 판단하는 확률을 높임.
판별자가 생성자(G)가 만든 '가짜' 데이터()를 '가짜'로 정확히 판단하는 확률을 높임.
ContexTDA의 해결책
기존 방법들의 한계를 극복하기 위해 컨텍스트 샘플링 정책을 도입
→ 각 시점에 대한 맞춤형 컨텍스트 정보를 샘플링하여, 시계열 데이터의 시간적 의존성을 고려한 지식 전달을 가능하게 함
2.4 Solving Markov Decision Process via Deep Reinforcement Learning
1. Markov Decision Process(MDP)의 정의
- 순차적 의사결정을 모델링하는 수학적 틀
- 상태(), 행동(), 전이 확률(), 보상(), 할인율()로 이루어져 있음.
- 누적 보상을 최대화하는 최적의 정책()을 찾는 것이 목표
2. 심층 Q-러닝(DQN)을 통한 해결
- 딥러닝 신경망으로 Q 함수()를 근사해 최적의 행동 가치를 학습하는 방식임.
Q함수는 현재 상태()와 행동()의 가치가 다음 상태()에서 받을 보상과 다음 상태에서 취할 수 있는 최적 행동()의 최대 Q값의 합과 같다는 것을 나타냄.- 학습의 안정성을 위해 재생 버퍼와 타겟 네트워크를 사용함.
- 본 논문에서 MDP를 해결하기 위해 DQN을 사용함.
3. Methodology
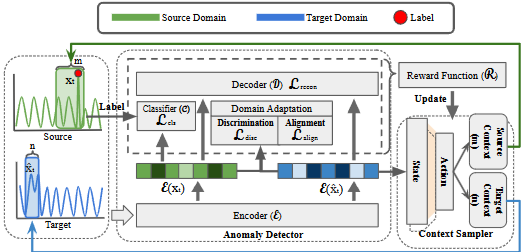
1) Context Sampler
각 시점에 대한 최적의 contextual information을 샘플링하는 정책을 학습 > 샘플링된 context information은 anomaly detector의 입력값으로
2) Anomaly Detector
두 도메인의 데이터를 모델링하고, feature vector로 변환하여 knowledge transfer, anomaly detection 수행
- Context sampler에 의해 결정된 새로운 context window size()에 따라, anomaly detector에 입력될 다음 데이터()가 해당 윈도우 크기만큼 샘플링
- context sampler의 행동()이 anomaly detector의 다음 입력 데이터에 직접적인 영향을 미치며, anomaly detector는 이 샘플링된 데이터를 바탕으로 다시 새로운 피처 벡터()를 생성하여 MDP 루프를 이어감
Loss
1) Source Domain Classification Loss
: Source 도메인의 레이블 정보를 효과적으로 활용하여 anomaly detection 성능을 높임
2) Unsupervised Reconstruction Loss
: Anomaly detection task에서 majority modeling을 반영하기 위해 source 및 target 도메인의 일반적인 데이터 분포를 정확하게 모델링하도록 장려
3) Domain Adaptation Losses
: Source 도메인에서 target 도메인으로의 knowledge transfer를 촉진
3.1 Context Sampling as Markov Decision Process
State()
- 시간 에서의 시스템 상태를 나타내는 2n차원의 벡터를 의미
- 현재의 소스 데이터 와 타겟 데이터 에 기반한 이상 탐지기의 인코더 에서 나온 두 개의 n차원 특징 벡터, 와 를 결합하여 구성
- 이상 탐지기가 현재 source와target 데이터를 어떻게 인지하는지를 요약해 보여주는 값임
Action()
- 시간 에서의 행동을 나타내는 2차원 벡터
- 첫 번째 차원: source 도메인의 윈도우 크기
- 두 번째 차원: target 도메인의 윈도우 크기
- 각 도메인의 윈도우 크기는 1부터 주어진 최대 윈도우 크기까지의 범위를 가집니다.
Reward()
- 시간 에서의 보상을 나타내는 복합적인 신호
- 여러 loss들을 조합하여 계산
- source domain classification loss: source 데이터의 분류 정확도와 관련된 손실
- source and target domain reconstruction loss: 원본 데이터를 얼마나 잘 복원하는지와 관련된 손실
- domain alignment and discrimination loss: source 도메인과 target 도메인이 얼마나 잘 정렬되었는지(유사한 특징을 가지는지)와 관련된 손실
- reward의 목표는 context sampler가 레이블 정보 활용과 domain adaptation 성능을 향상시키는 데 도움이 되는 양질의 데이터 배치를 샘플링하도록 유도하는 것
강화 학습 기반 도메인 적응 프로세스
- state() 생성: 시간 에 끝나는 source 및 target 윈도우를 기반으로 상태()를 만듦
- action() 생성: 로부터 엡실론-그리디 정책()에 따라 다음 소스 및 타겟 도메인의 컨텍스트 윈도우 크기를 정하는 행동()을 생성합니다.
- 다음 state() 생성: 를 바탕으로 이상 탐지기와 소스 분류기 학습에 필요한 다음 입력 데이터를 샘플링하고, 이를 통해 다음 상태()를 만듭니다.
문제 해결 방식
- 위에서 설명한 마르코프 결정 과정(MDP)을 풀기 위해 deep reinforcement learning을 활용
- 이를 통해 state와 action 사이의 역학 관계를 모델링하고, domain adaptation을 위한 context sampling 정책을 학습
- 두 도메인의 윈도우 크기는 유한한 정수이므로 행동 공간은 이산적(discrete) >> 심층 Q-러닝(deep Q-learning)을 도입
- 보상 함수: 학습 과정을 이끄는 가장 중요한 요소. 여러 손실 값들의 조합의 역수로 설계됨
- Q-함수 및 정책: Q-함수는 multi-layer perceptron으로 근사화하며, 샘플링 정책 는 엡실론-그리디 알고리즘을 통해 만들어짐
3.2 Contextual Domain Adaptation
- 현재 상태 에서 특정 행동 를 취했을 때 얻게 되는 보상
- Deep Q-learning(DQN) 에이전트는 이 보상을 최대화하는 방향으로 학습하여 최적의 Context Window Size를 선택하는 정책을 학습
- 보상 함수가 역수 형태로 되어 있으므로, 분모에 있는 손실 값들의 합이 작아질수록 보상은 커짐
- 손실 함수들을 최소화하는 방향으로 학습을 유도하는 것과 같음
1) : Classification Loss
- Source Domain의 레이블 정보를 활용하여 이상 및 정상 데이터에 대한 분류 정확도를 높이는 것을 목표로 하는 손실
- : source domain 에서 샘플링된 시계열 subsequence
- : 의 실제 이진 label(정상 또는 이상).
- : 인코더 가 생성한 feature vector를 입력으로 받아 분류 예측을 수행하는 MLP 분류기
- : 입력 시계열 subsequence를 feature vector로 변환하는 인코더
- : 이상과 정상 데이터에 대한 가중치로, 이상 데이터에 더 높은 중요도를 부여
- : Binary Cross-Entropy 손실 계산에 사용되는 로그 함수
2) : Reconstruction Loss
- Anomaly Detector가 소스 및 타겟 도메인의 일반적인 데이터 패턴(정상 데이터)을 정확하게 학습하도록 유도하는 역할
- : 소스 도메인에서 정상이라고 레이블이 지정된 subsequence. 모델은 이 데이터를 사용하여 정상 패턴을 학습
- : 레이블이 없는 타겟 도메인의 subsequence
- : 인코더 가 만든 압축된 특징 벡터를 원래의 subsequence로 복원하는 디코더
- : L2 Norm의 제곱으로, 원본 데이터와 모델이 재구성한 데이터 간의 오차를 측정하는 데 사용. 이 오차가 작을수록 재구성이 잘 되었다는 의미
3) : Domain Alignment Loss
- 소스와 타겟 도메인 간의 특징 분포 차이를 최소화하는 역할.
- 이를 통해 모델은 두 도메인 모두에 적용될 수 있는 도메인 불변(domain-invariant) 특징을 학습하게 됨
- 와 : 각각 소스 도메인과 타겟 도메인에서 인코더 에 의해 생성된 특징 벡터
- : L2 Norm의 제곱으로, 소스와 타겟 특징 벡터 사이의 거리를 측정. 이 값이 작을수록 두 도메인의 특징 분포가 유사하다는 것을 의미.
의 주요 역할은 인코더가 도메인에 관계없이 유사한 특징 표현을 생성하도록 유도함으로써, 소스 도메인에서 학습한 지식이 레이블이 없는 타겟 도메인으로 효과적으로 전달되도록 돕는 것.
4) : Domain Discrimination Loss
- GAN(생성적 적대 신경망)과 유사한 방식으로 작동
- 목표는 인코더가 도메인(소스 또는 타겟)을 구별할 수 없는 도메인 불변(domain-invariant) 특징을 생성하도록 학습시키는 것
- : 인코더 에 의해 생성된 특징 벡터
- : 입력 특징 벡터가 소스 도메인에서 왔는지 타겟 도메인에서 왔는지 판별하는 도메인 분류기(Discriminator)
- : 입력 데이터의 실제 도메인 레이블(예: 소스는 0, 타겟은 1)
의 역할은 보상 함수()의 분모에서 음수 항으로 사용된다는 점이 중요
- DQN이 보상 을 최대화> 분모에 항이 음수로 들어가므로, 보상을 최대화하려면 값이 커져야 함
- 이러한 설계는 Context Sampler가 도메인 분류기 가 소스와 타겟 도메인을 더 잘 구별할 수 있는 데이터 배치(context window size)를 선택하도록 유도함
- 즉, 샘플러는 도메인 구별이 더 쉬운 '경계'에 가까운 데이터를 선택하도록 학습되며, 이는 궁극적으로 인코더 가 도메인 불변 특징을 생성하는 적대적 학습 과정의 균형을 맞추는 데 기여
- 논문에서는 이러한 행동을 "도메인 식별 손실을 최대화"하여 "도메인 고유 표현을 생성"하는 것으로 설명
3.3 Anomaly Inference
이상치 탐지 방법
학습된 샘플링 정책 와 훈련된 anomaly detector를 결합하여 target domain의 이상을 탐지
- context window 크기 샘플링: 학습된 정책 를 사용하여 각 시점의 context window 크기를 결정
- 이상 탐지 수행: 샘플링된 context window를 anomaly detector에 입력하여 이상을 탐지
훈련 과정
훈련 과정에서는 액션 카운터(action counter) 을 도입하여 source domain에서 가장 자주 선택된 context window 크기를 식별
- source domain: source domain의 모든 시점에 대해, 가장 자주 선택된 윈도우 크기(=고정된 크기)를 사용하여 데이터 를 샘플링하고 를 생성
→ context sampler가 target domain 데이터의 context sampling에 더 집중하도록 - target domain: 정책 로 샘플링된 context window를 기반으로 인코더 를 통해 를 생성
- 상태() 생성: 두 벡터(와 )를 결합하여 상태 를 얻음
매 반복마다 target domain의 특징 벡터 는 소스 분류기 에 입력되어 이상일 확률(confidence score)을 얻음
이상치 점수 계산
- :
- 타겟 도메인 시점의 데이터 포인트에 대한 최종 이상치 점수
- 이 점수가 높을수록 이상치일 가능성이 큼
- :
- Source Classifier 가 판단한 이상치일 확률
- Source domain 의 label 데이터를 학습하여, target domain 데이터 가 Source domain의 이상치 패턴과 얼마나 유사한지를 평가
- :
- 재구성 오류(Reconstruction Error)
- 이는 오토인코더가 정상 패턴을 학습한 후, 실제 데이터 와 모델이 재구성한 데이터 간의 차이를 측정한 것
- 일반적으로 정상 데이터는 오류가 작고, 이상치는 오류가 크게 나타남
4. Experiment
1) Homogeneous Transfer
: Source 와 Target이 동일 feature space 공유하는 경우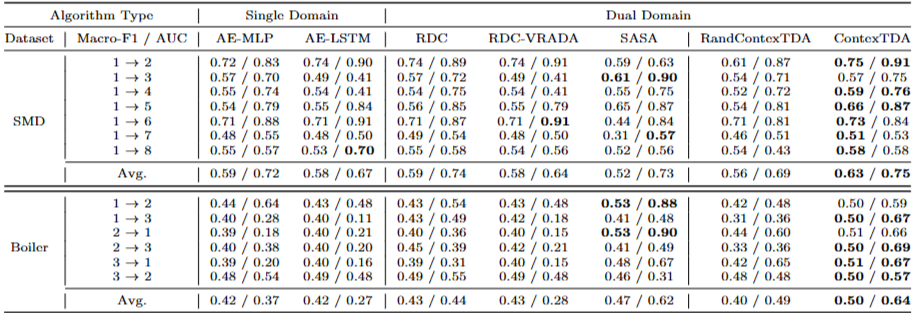
- 평균 Macro-F1 점수: ContexTDA는 다른 baseline model보다 평균적으로 6.7%에서 6.3% 더 우수한 성능을 보임
- 평균 AUC 점수: ContexTDA는 다른 baseline 모델들보다 더 높은 평균 AUC 점수를 달성
- SMD : 7개 설정 중 6개에서 다른 모델들보다 뛰어난 성능
- Boiler: 6개 설정 중 4개에서 다른 모델들보다 뛰어난 성능
1. 통합된 컨텍스트 윈도우 크기의 한계
- source/target 도메인에 동일한 context window 크기를 적용하는 방식은 이상 탐지에 한계가 있음
- 이중 도메인 모델(RDC, RDC-VRADA, SASA)은 단일 도메인 모델(AE-LSTM)보다 AUC 점수는 높았지만, Macro-F1 점수는 비슷하거나 더 낮음
→ 통합된 컨텍스트가 전반적인 분류 능력은 향상시키지만, 실제 중요한 이상 데이터 탐지에는 효과가 제한적임
2. 국지적 컨텍스트 정렬의 이점
- ContexTDA는 각 도메인에 맞는 국지적 컨텍스트 크기를 적용하여 기존 이중 도메인 모델보다 AUC 점수를 소폭 향상시키고, Macro-F1 점수에서는 모든 기준 모델을 능가
- 개별 시점에 맞춘 context 정렬이 정상 및 이상 데이터 모두의 지식 전이에 효과적임을 증명
3. MMD와 도메인 판별 결합 시 컨텍스트 정렬의 중요성
- MMD와 도메인 판별을 결합할 때는 컨텍스트 정렬이 매우 중요
- RDC-VRADA는 RDC에 도메인 판별을 추가했음에도 성능이 하락했는데, 이는 적절한 컨텍스트 정렬 없이 두 기법을 결합하면 부정적 전이(negative transfer)가 발생할 수 있음을 보여준줌
- ContexTDA는 개별 시점에 최적화된 컨텍스트를 제공하여 훨씬 나은 성능을 달성했다.
4. 컨텍스트 샘플링 정책 학습의 효과
- 제안된 컨텍스트 샘플링 정책은 DQN(심층 Q-러닝)을 통해 성공적으로 학습
- 무작위 샘플링 방식인 RandContexTDA와 비교했을 때, ContexTDA의 성능이 모든 데이터셋에서 크게 향상되었다.
- 이는 설계된 보상 함수가 도메인 적응을 위한 정책 학습 과정을 효과적으로 안내하며, DQN이 최적의 컨텍스트 샘플링 정책을 성공적으로 학습했음을 시사
5. 예외적 상황
- SASA가 ContexTDA보다 뛰어난 경우: 두 도메인 간의 이상 행동 패턴이 매우 유사할 때 지도 학습이 더 유리
- 이는 이상 데이터 분포가 명확히 클러스터를 형성하여, 컨텍스트 샘플링 없이도 지도 학습 기반의 이진 분류가 효과적일 수 있음을 나타냄
2) Heterogeneous Transfer
: 데이터 특성이 완전히 다른 이종 도메인 환경
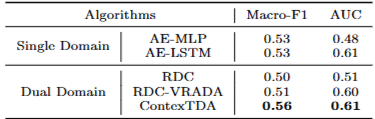
- SASA 적용 불가: SASA는 소스와 타겟 도메인이 동일한 특징 공간을 공유해야 한다는 전제 조건 때문에, SMAP과 MSL 같은 이종 도메인에는 적용할 수 없음
- dual domain baseline: 이종 도메인 특성을 반영하여, 소스와 타겟 도메인에 각각 개별적인 encoder-decoder 네트워크 구현. 두 네트워크의 특징 표현을 활용해 도메인 정렬 및 식별을 수행
- Macro-F1: 차선(second-best) 베이스라인 대비 9.9% 향상.
- AUC: 1.6% 향상.
도메인 차별(Domain Discrimination)의 중요성
- RDC(Domain Discrepancy Minimization)와 같은 기법으로 완전히 다른 두 도메인을 강제로 정렬하는 것은 상당한 Negative Transfer를 일으킴
- RDC + 도메인 차별 기법 = RDC-VRADA를 비교해 보면, domain-invariant 특징을 추출하기 위한 도메인 차별이 Negative Transfer를 완화하는 데 도움이 됨
Local Context 정보 샘플링의 효과
- ContexTDA는 모든 도메인 적응 프레임워크 중 유일하게 Negative Transfer 없이 AE-LSTM 대비 Macro-F1 점수를 향상시킴
- 개별 시점에 대해 로컬로 샘플링된 컨텍스트 정보가 모델이 유익한 정보에 집중하도록 돕기 때문인 것으로 분석됨.
- 윈도우 크기 분산: 이종 도메인 설정에서는 동질적 설정에 비해 선택된 윈도우 크기의 분산이 더 높게 나타남.
→ context sampler가 지식 전이를 방해하는 정보를 줄이고, 도움이 되는 정보를 증폭시켜 더 나은 성능을 달성했음
3) Ablation Study , Hyperparameter Tuning

Ablation Study
1. 도메인 적응 목표(,) 제거 시:
- 모델 성능에 큰 변화가 없음
- 두 도메인(machine 1, machine 4)의 데이터 대부분이 매우 유사한 분포를 가지고 있기 때문.
- 실제로 이 두 머신은 값이 0인 속성을 공통적으로 가지고 있음
2. 소스 레이블() 정보의 중요성
- 재구성 목표인 에 비해 소스 레이블 정보인 가 이상치 탐지에 더 중요한 역할을 수행
- 두 도메인의 이상치 행동이 서로 유사하다는 것을 의미
- 두 도메인 모두에서 발생하는 급증과 같은 이상치 패턴이 높은 일관성을 보임 → 소스 도메인에서 학습한 레이블 정보가 타겟 도메인의 이상치 탐지에 효과적으로 활용
Hyperparameter Tuning
1. (소스 도메인 분류 손실 가중치)
- 두 도메인의 이상치 행동이 유사할 때 더 크게 설정
- 이상치 패턴이 유사하면 소스 도메인의 레이블 정보가 타겟 도메인의 이상치 탐지에 매우 효과적으로 작용하기 때문.
2. (재구성 손실 가중치)
- 레이블이 지정된 이상치 데이터가 부족할 때 더 큰 값을 사용
- 레이블 정보가 부족한 경우, 를 높여 모델이 각 도메인의 일반적인 패턴(정상 데이터)을 더 잘 모델링하도록 유도하여 이상 탐지 기반을 강화
3. (도메인 정렬 손실 가중치)
- 두 도메인의 일반적인 데이터 패턴이 유사할 때 성능 향상을 위해 사용. 특히 동종(homogeneous) 도메인 간의 지식 전이에 유용
- 를 크게 하면 두 도메인 간 특징 공간이 더 잘 정렬, 소스에서 학습한 지식이 타겟으로 원활하게 전이
4. (도메인 판별 손실 가중치)
- 이종(heterogeneous) 도메인 환경에서 도메인 불변 특징 추출을 촉진하기 위해 더 큰 값을 설정
- 보상 함수에서 는 음수 항으로 포함되므로, 를 크게 하면 DQN이 보상을 최대화하는 과정에서 를 최대화하게 됨. 이는 Min-Max Optimization 과정을 통해 도메인에 구애받지 않는 특징 벡터를 생성하게 만듦
5. Related Work
1. Domain Adaptation
: 레이블이 있는 소스 도메인의 지식을 레이블이 부족한 타겟 도메인으로 전달하는 기술
- 주요 전략:
- MMD (Maximum Mean Discrepancy): 두 도메인의 데이터 분포 차이를 최소화하여 특징 공간을 정렬
- 도메인 판별 (Domain Discrimination): 적대적 학습을 통해 도메인 불변 특징을 생성
- ContexTDA는 위 두 가지 전략을 통합하여 사용
2. Time Series Domain Adaptation
- 기존 방법: RNN-LSTM, self-attention 등을 특징 추출기로 사용하며, 주로 시계열 회귀 및 분류 문제에 중점을 둠. 이는 대부분의 데이터 분포(정상 데이터)를 정렬하는 데 초점을 맞춤.
- 문제점: 소수 분포인 이상치에 대한 지식 전달에는 negative transfer를 유발할 수 있음
3. Partial Domain Adaptation
: 모든 도메인이 동일한 레이블 공간을 공유한다는 가정을 완화하기 위해 인스턴스 단위의 선택적 전이 전략을 개발
- 접근 방식:
- 가중치 재조정 (Re-weighting): 도메인 판별기에서 얻은 확률에 따라 소스 샘플의 가중치를 조절
- 반복적 인스턴스 선택 (Iterative instance selection): 강화 학습을 통해 인스턴스 선택 문제를 해결
- 문제점: 이러한 방법들은 시계열 데이터의 시간적 의존성을 고려하지 않아, 임의의 인스턴스 선택이 제대로 작동하지 않을 수 있음
ContexTDA의 해결책
- ContexTDA 프레임워크: 기존 방법들의 한계를 극복하기 위해, 시계열 데이터의 개별 인스턴스에 대한 context sampling에 초점을 맞추어 시간적 의존성을 고려한 지식 전이를 가능하게 함
6. Conclusion
본 논문은 시계열 이상 감지를 위한 ContexTDA(Context-aware Domain Adaptation) 프레임워크를 제안
-
주요 방법론:
- 강화 학습: 컨텍스트 샘플링 문제를 마르코프 결정 과정(MDP)으로 공식화
- 맞춤형 보상 함수: 시계열 이상 감지를 위한 지식 전달을 최적화하기 위해 특별히 설계된 보상 함수를 사용
- 심층 강화 학습: 이 알고리즘을 사용하여 최적의 컨텍스트 샘플링 정책을 학습
-
실험적 증명:
- 동질적(homogeneous) 지식 전달: 두 개의 공개 데이터셋을 사용한 실험에서 ContexTDA의 우수한 성능이 입증
- 이종(heterogeneous) 지식 전달: 완전히 다른 두 시계열 데이터셋에 대한 파일럿 연구를 통해, 두 도메인의 컨텍스트 윈도우 크기를 정렬하는 것이 이종 지식 전달의 핵심 요소가 될 수 있음을 보여줌
