Towards a General Time Series Anomaly Detector with Adaptive Bottlenecks and Dual Adversarial Decoders
Qichao Shentu, Beibu Li, Kai Zhao, Yang Shu, Zhongwen Rao, Lujia Pan, Bin Yang, Chenjuan Guo
International Conference on Learning Representations (ICLR), 2025
Abstract
기존 방법 한계
- 각 데이터셋별 별도 모델 훈련 필요
- 다른 타겟 데이터셋에 대한 일반화 능력 제한
- 훈련 데이터 부족 시나리오에서 이상 탐지 성능 저하 문제 발생
- 기존 한계 극복 목표. 광범위한 다중 도메인 데이터셋으로 사전 훈련된 일반 시계열 이상 탐지 모델 구축. 다양한 다운스트림 시나리오에 적용 가능.
- 일반 모델 구축 시 두 가지 주요 과제 존재:
1) 다양한 정보 병목(information bottlenecks) 요구 사항 충족: 시계열 데이터 도메인별 정보 밀도 상이. 통합 모델이 각 데이터셋에 최적화된 정보 병목 요구 사항 충족 필요. ('정보 병목'은 모델이 데이터를 압축하여 잠재 공간(latent space)으로 표현 시 정보 흐름 제한 지점 의미.)
2) 정상 및 이상 패턴 구별 능력 강화: 효과적인 이상 탐지를 위해 다양한 정상 및 비정상 패턴 명확히 구별하는 능력 필수.
제안 모델
DADA (General time series anomaly Detector with Adaptive Bottlenecks and Dual Adversarial Decoders):
- Adaptive Bottlenecks: 데이터에 따라 병목(bottleneck) 크기 유연하게 선택. 다양한 데이터 정보 밀도 요구 사항에 적응하여 모델 일반화 능력 향상
- Dual Adversarial Decoders: 정상 시계열과 비정상 시계열 간 명확한 구별 명시적 강화. normal decoder는 정상 패턴 학습 후 정확한 재구성 목표, anomaly decoder는 다양한 이상 패턴 학습. 적대적 훈련 메커니즘을 통해 정상-이상 결정 경계 명확히 학습 유도
1. Introduction
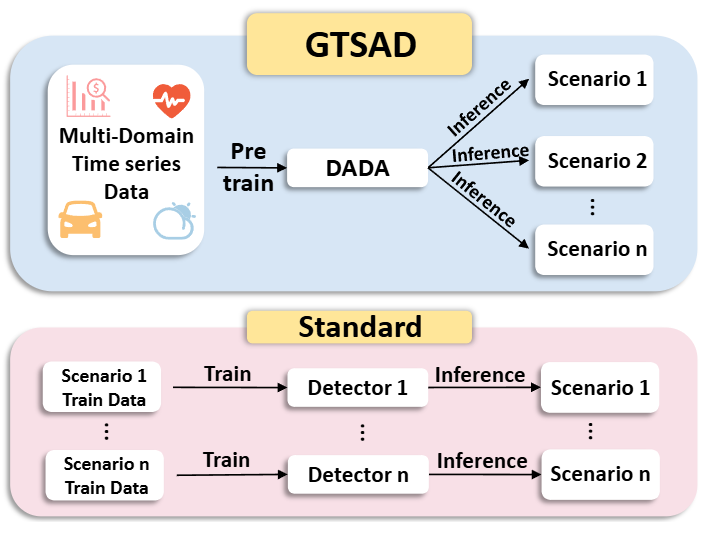
GTSAD 모델의 필요성: 여러 도메인의 방대한 시계열 데이터로 pre-training되어 다양한 다운스트림 시나리오에 효율적으로 적용될 수 있는 일반 시계열 이상 감지(GTSAD) 모델을 제안. 이는 '도메인별 특화 패턴에 대한 과적합을 완화하고 더 일반화 가능한 패턴과 모델을 학습'하는 것을 목표로 함
2. Related Work
Time Series Anomaly Detection
1) Non-Learning
- Density-based method: data point들이 클러스터 내에서 분포하는 밀도를 분석하여 비정상적인 데이터 포인트를 식별. 주변 data point들과 비교하여 밀도가 현저히 낮은 지점을 이상으로 간주
ex) LOF (LOF: identifying density-based local outliers), HBOS (Histogram-based outlier score: A fast unsupervised anomaly detection algorithm) - Similarity-based method: 대부분의 시계열과 크게 다른 시계열을 이상으로 표시
ex) Matrix Profile
2) Classical Learning
주로 정상 데이터로만 구성된 학습 데이터셋을 사용, 테스트 데이터가 정상 데이터와 유사한지 여부를 분류 → 이상 데이터가 희소하다는 가정에 기반
3) Deep Learning
- 재구성 기반(Reconstruction-based) 방법
- AutoEncoder (AE): 입력 데이터를 저차원 잠재 공간으로 인코딩한 후 다시 원본 형태로 디코딩하여 재구성
- Variational AutoEncoder (VAE): AE와 유사하지만, 잠재 공간에 확률 분포를 학습하여 더 다양한 정상 패턴을 포착
- Generative Adversarial Network (GAN): 생성자(generator)와 판별자(discriminator)의 적대적 학습을 통해 정상 데이터를 모델링 → 이상 데이터는 생성자가 잘 생성하지 못하거나 판별자가 쉽게 구분
- Transformer 아키텍처: 시계열의 복잡한 시간적 의존성을 효과적으로 학습하여 재구성 성능을 높임
- 예측 기반(Prediction-based) 방법: 과거 관측치를 사용하여 현재 값을 예측하고, 예측 결과와 실제 값 사이의 차이(예측 오차)를 이상 기준으로 사용 → 예측 오차가 크면 이상
Time series pre-training models
기존 시계열 사전 학습 방법
- BERT-스타일 마스킹 (Masked Pre-training): 데이터의 일부를 가리고 나머지 부분을 이용해 가려진 부분을 복원하도록 학습시키는 방식
- 대조 학습 (Contrastive Learning): 데이터의 증강된 뷰(augmented view) 간의 유사성/비유사성을 학습하여 유용한 표현 추출
- LLM 활용: 대규모 언어 모델을 시계열 예측 작업에 재활용하는 시도도 있음
zero-shot
- 제로샷 시계열 예측 모델들 존재
- 시계열 이상탐지 모델은 부족 → 기존의 이상 탐지 사전 학습 방법들은 대상 데이터셋에 대한 추가 학습(fine-tuning)이 필요
- DADA는 다중 도메인 사전 학습으로 제로샷 시계열 이상 탐지 분야의 부족분을 해결. 단일 모델로 다양한 시나리오에서 탁월한 성능을 발휘하며, 도메인별 맞춤 학습이 불필요
3. Methodology
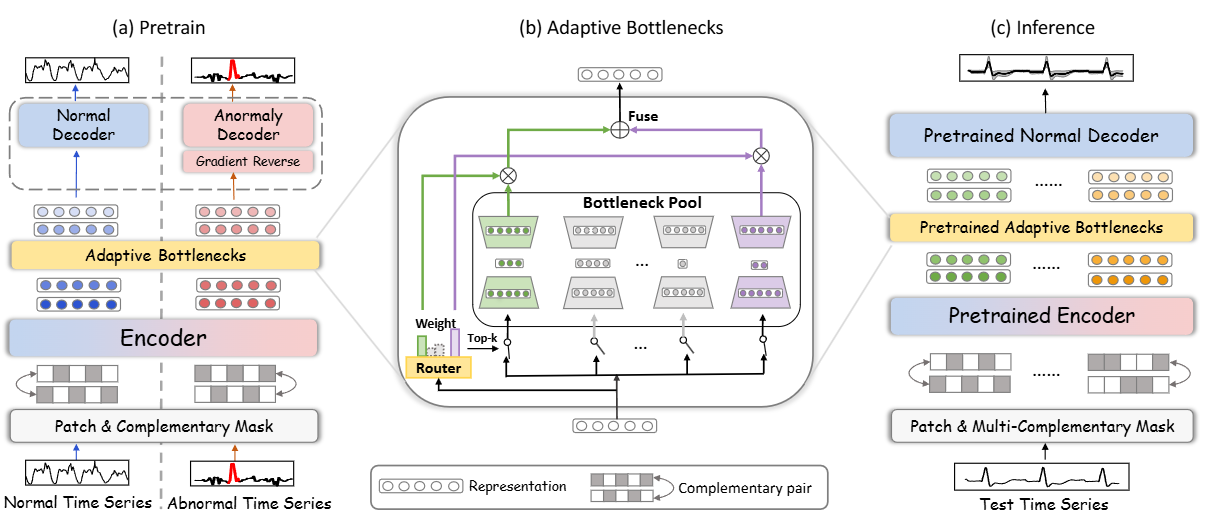
모델 목표
다양한 도메인의 시계열 데이터로 사전 학습 후, 추가 미세 조정 없이 바로 적용 가능한 일반적인 시계열 이상 탐지 모델 구축.
데이터 처리
- 입력 시계열:
- 채널 독립성(channel independence) 적용: -변량 시계열을 개의 단변량 시계열로 처리.
핵심 구성 요소
- Patch & Complementary Mask
- 시계열을 패치로 분할
- 상호 보완적 마스크 생성 → 양방향 시간 의존성 포착
- Encoder
- 마스킹된 패치 임베딩에서 시간적 특징 추출
- Adaptive Bottlenecks (AdaBN)
- 데이터셋별 정보 밀도에 맞춰 동적으로 병목 크기 조절
- 여러 도메인에 걸친 일반화된 표현 학습 지원
- Dual Adversarial Decoders
- Normal decoder: 정상 시계열 재구성
- Anomaly decoder: 비정상 시계열 재구성
- 적대적 학습(adversarial training) → 정상/비정상 결정 경계 명확화
Pre-training
- 입력: 정상 시계열 + 비정상 시계열(노이즈 섭동 포함)
- 마스크 기반 재구성으로 시계열 모델링 및 패턴 학습
Inference
- 비정상 디코더 제거
- 여러 상호 보완적 마스크로 패치 임베딩 생성
- 재구성 분산(variance) → 이상 점수(anomaly score)
- 정상: 낮은 분산
- 비정상: 높은 분산
- SPOT 등으로 임계값 설정 → 이상 지점 탐지
3.2 Complementary Mask Modeling
- 시계열 데이터의 이상 탐지 성능을 높이는 핵심 전략
- 데이터를 패치로 분할하고, 두 개의 상호 보완적인 마스크를 사용해 정상적인 시계열 패턴을 효과적으로 학습
1. 패치 임베딩
단일 변수 시계열을 개의 패치( 차원)로 나눔. ()
2. 상호 보완적인 마스크 시계열 생성
마스크 를 생성해 두 개의 상호 보완적인 시계열을 만듦.
- 첫 번째 시계열:
- 두 번째 시계열:
3. 재구성 및 결합
두 시계열을 재구성한 후, 최종 결과를 결합함.
- 재구성: 인코더, AdaBN, 디코더를 거쳐 를 만듦.
- 결합: 다음 수식을 사용해 최종 재구성 결과를 얻음.
3.3 Adaptive Bottlenecks(AdaBN)
- DADA 모델의 핵심 구성 요소로, 다양한 데이터 분포에 유연하게 대응하고 일반화 능력을 높이는 역할
- 기존 모델의 고정된 보틀넥이 가진 과적합 및 정보 손실 문제를 해결
- 큰 보틀넥: 원본 데이터를 정확하게 재구성, 정상 패턴과 관련 없는 불필요한 노이즈까지 학습
→ 과적합을 유발 - 작은 보틀넥: 데이터의 본질적인 정보를 효율적으로 압축, 다양한 정상 패턴의 손실을 초래
→ 재구성 성능이 떨어질 수 있음
- 큰 보틀넥: 원본 데이터를 정확하게 재구성, 정상 패턴과 관련 없는 불필요한 노이즈까지 학습
1. Bottleneck Pool
- 서로 다른 크기()의 잠재 공간으로 특징을 압축하는 여러 bottleneck()의 집합
- 다양한 정보 밀도를 가진 데이터를 처리하기 위해 여러 압축 수준을 제공
- 작동 방식:
- : 인코더 출력 를 더 작은 잠재 공간으로 압축
- : 압축된 잠재 공간에서 원래 차원으로 복원
2. Adaptive Router
입력 데이터의 재구성 요구 사항에 따라 보틀넥 풀에서 가장 적합한 bottleneck을 동적으로 선택하는 전략
-
가중치 생성: 라우팅 함수 를 사용해 각 보틀넥에 대한 가중치를 생성
- : 인코더의 출력 표현
- : 학습 가능한 가중치
- : 무작위성을 위한 노이즈
-
Top-k 선택 및 융합: 가장 높은 가중치를 가진 개의 보틀넥을 선택하고, 그 출력을 가중 평균으로 융합
- : 선택된 개 보틀넥의 인덱스 집합.
3.4 Dual Adversarial Decoders
- 다양한 정상 및 이상 패턴을 명확하게 구분하는 능력을 강화하기 위해 제안된 모듈
- 기존 시계열 이상 감지 방법들은 대개 '정상' 패턴만을 학습하고 '이상'에 대한 명시적인 구분을 학습하지 않았음.
- 하지만 실제 다중 도메인 시계열 데이터에서는 이상 패턴 또한 매우 다양하게 나타나며, 단순히 정상 패턴만을 학습하는 것으로는 일반적인 이상 감지 능력을 확보하기 어려움.
→ 다중 도메인 데이터에 존재하는 다양한 정상 및 이상 패턴 간의 결정 경계를 명확하게 학습하는 것을 목표로 함.
정상 디코더 (Normal Decoder, )
- 정상 시계열 데이터()를 정확하게 재구성하는 데 중점을 둠 → 모델은 정상 데이터의 고유한 패턴과 특징을 깊이 있게 학습하게 됨.
- 손실 함수는 정상 시계열의 재구성 오류를 최소화하는 방향으로 학습
- : 정상 훈련 시계열의 총 개수
- : 번째 정상 훈련 시계열
- : 번째 정상 훈련 시계열의 재구성 결과
- : Encoder와 Adaptive Bottlenecks를 포함하는 특징 추출기
- : 정상 디코더
- : 재구성 오차를 측정하는 L2 거리(Squared Euclidean Distance)
이상 디코더 (Anomaly Decoder, )
- 이상 시계열 데이터()의 이상 패턴을 학습
- 이상 데이터의 재구성 오류를 최소화하려고 하지만, 이 과정이 특징 추출기()와의 적대적 관계 속에서 진행
- 레이블된 이상 데이터에 대한 의존성을 줄이고 특정 도메인 이상 패턴에 대한 과적합을 방지하기 위해 이상 주입(anomaly injection)을 통해 이상 데이터를 생성
- 손실 함수: 이상 시계열의 재구성 오류를 최소화하는 방향으로 학습
- : 이상 훈련 시계열의 총 개수
- : 번째 이상 훈련 시계열
- : 번째 이상 훈련 시계열의 재구성 결과
- : 번째 이상 시계열의 이상 레이블(0 또는 1)
- : 요소별 곱셈 → 이상 부분만 재구성 오차 계산에 반영되도록 함
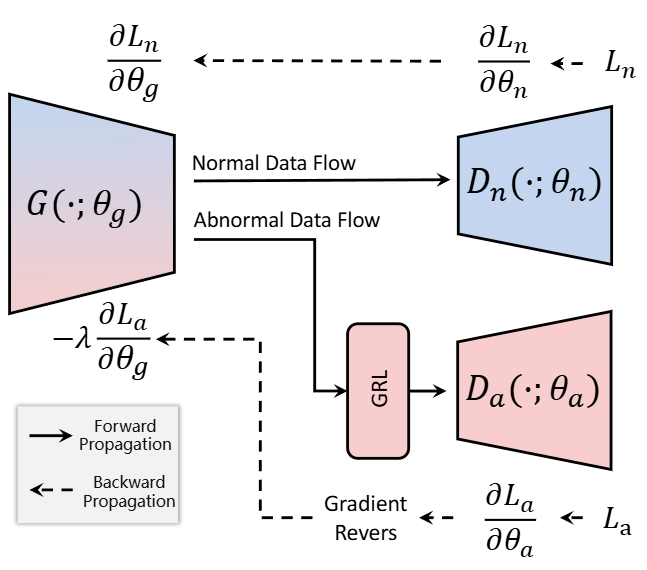
적대적 학습 메커니즘
Encoder ()와 Anomaly Decoder () 사이에 Gradient Reversal Layer (GRL)를 삽입하여 적대적 학습을 수행함.
- Encoder ()의 목표: 이상 데이터로부터 '이상' 정보를 가능한 한 적게 포함하는 특징을 학습하여, Anomaly Decoder가 이상 데이터를 재구성하는 것을 어렵게 만듦.
- Anomaly Decoder ()의 목표: Encoder가 생성한 특징으로부터 이상 데이터를 가능한 한 잘 재구성함.
- 정상 디코더 ()의 목표: Encoder ()와 함께 정상 데이터의 재구성 손실()을 최소화함.
→ 이러한 구조를 통해 Encoder는 정상 패턴을 최대한 잘 나타내는 표현을 학습하게 되고, 동시에 Anomaly Decoder는 다양한 이상 패턴을 인식하게 됨.
→ 정상과 이상 패턴 사이의 명확한 결정 경계를 형성하는 데 기여
추론 단계 (Anomaly Criterion)
- 학습된 모델은 단일 시계열에 대해 여러 쌍의 상호 보완적인 마스크된 시계열을 생성하고, 각각을 재구성함.
- 정상 데이터 포인트는 여러 재구성 과정에서 안정적으로 유사한 값을 가지며 재구성됨.
- 반면, 이상 데이터 포인트는 재구성이 어렵고, 재구성된 값들 사이에 큰 편차를 보임.
- 따라서, 각 시점에서 재구성된 값들의 분산을 anomaly score로 사용
- 이 분산이 클수록 해당 시점이 이상일 가능성이 높다고 판단
- 이후 SPOT와 같은 통계적 방법을 사용하여 임계값()을 결정하고, 이상 점수가 임계값보다 높으면 이상으로 분류함.
4. Experiments
Evaluation Protocol
DADA 모델은 '제로샷' 평가 프로토콜을 통해 탁월한 성능과 실용성을 입증 → 단일 모델이 다양한 데이터셋에 유연하게 적용될 수 있음을 보여줌.
- 기존 모델들은 특정 데이터셋의 train 세트로 훈련된 후, 동일한 데이터셋의 test 세트로 평가
- DADA는 방대한 멀티 도메인 데이터셋으로 pre-training된 후, 한 번도 접하지 않은 새로운 downstream 데이터셋에 바로 적용되어(zero-shot) 이상 감지 성능을 평가
→ 데이터나 자원이 부족한 실제 시나리오에서의 모델의 실용성을 증명함.
성능 비교
- 주요 5개 데이터셋 (Table 1):
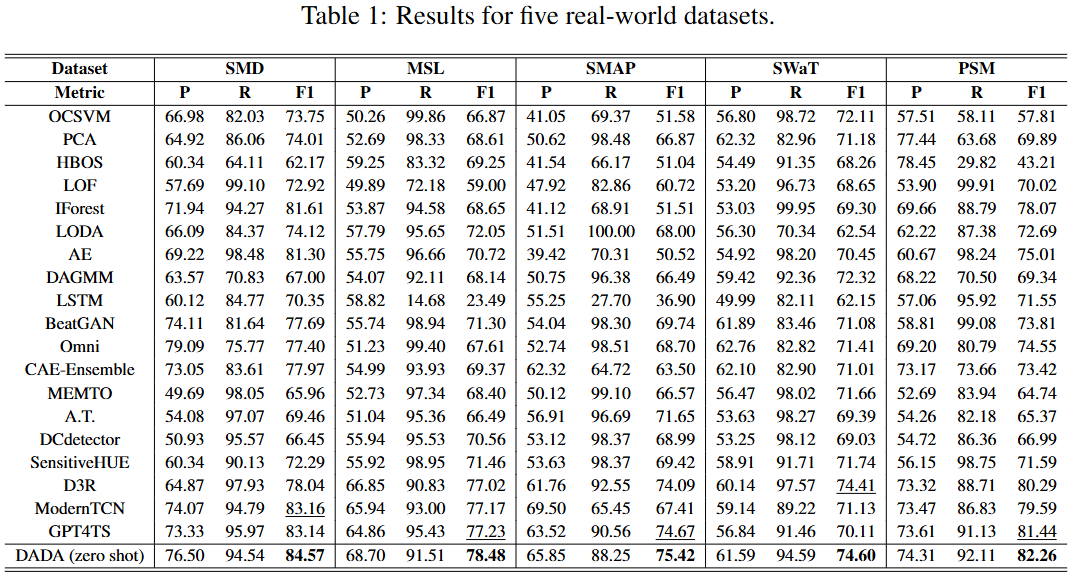 5개 주요 실세계 데이터셋에 대한 평가에서, DADA는 각 데이터셋에 맞춰 특별히 훈련된 SOTA 모델들과 비교하여 경쟁적이거나 심지어 우수한 결과를 달성
5개 주요 실세계 데이터셋에 대한 평가에서, DADA는 각 데이터셋에 맞춰 특별히 훈련된 SOTA 모델들과 비교하여 경쟁적이거나 심지어 우수한 결과를 달성 - NeurIPS-TS 데이터셋 (Table 2):
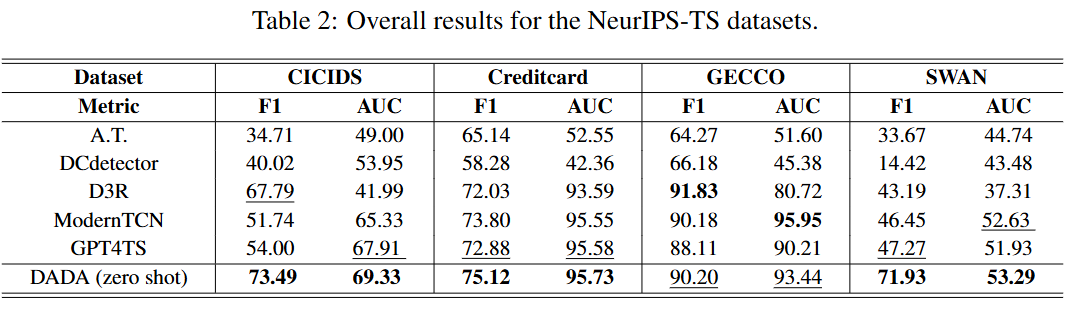 이상 유형이 다양하고 복잡한 NeurIPS-TS 벤치마크 데이터셋에서도 DADA는 Anomaly Transformer (A.T.), DCdetector, GPT4TS와 같은 최신 모델들과 비교했을 때 가장 좋거나 가장 경쟁력 있는 성능을 보임.
이상 유형이 다양하고 복잡한 NeurIPS-TS 벤치마크 데이터셋에서도 DADA는 Anomaly Transformer (A.T.), DCdetector, GPT4TS와 같은 최신 모델들과 비교했을 때 가장 좋거나 가장 경쟁력 있는 성능을 보임.
결과
- 사전 학습된 하나의 모델로 여러 시나리오에 효율적으로 적용될 수 있어, "one-model-for-many"라는 목표를 달성
- 이는 각 데이터셋별로 모델을 개별적으로 훈련할 필요가 없음을 의미
Ablation Study 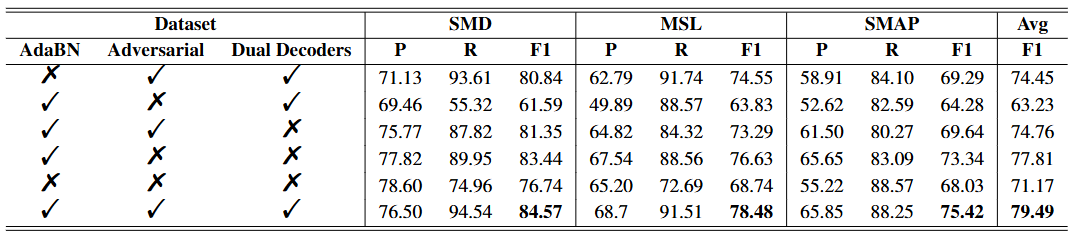
Adaptive Bottlenecks (AdaBN)
다중 도메인 데이터셋에 대해 하나의 고정된 보틀넥을 사용하고, AdaBN 모듈을 제거
→ DADA 대비 성능이 5.04% 하락
Dual Adversarial Decoders
- 적대적 메커니즘 제거: 이상 데이터의 재구성 오류를 직접적으로 최대화하고, 적대적 메커니즘을 제거 → DADA 대비 성능이 16.26% (79.49% 63.23%) 크게 하락
→ 적대적 메커니즘이 없으면 이상 디코더가 임의의 재구성 결과를 만들어 인코더의 정상 패턴 모델링 능력을 방해할 수 있음. - 단일 디코더 사용: 정상 및 이상 시계열을 모두 하나의 디코더로 재구성
→ 제로샷 성능이 저하 - 단일 디코더 및 적대적 메커니즘 제거:
→ 성능 저하
4.3 Model Analysis
-
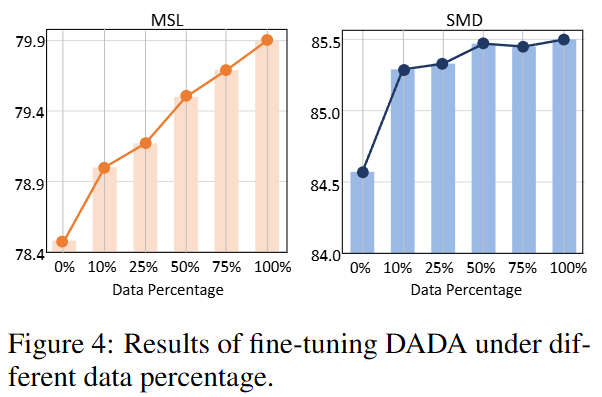
Fine-tuning with downstream data: 사전 학습된 DADA가 다운스트림 데이터에 대해 추가 학습(fine-tuning)을 진행했을 때 성능이 향상됨. 이는 DADA가 제로샷 성능을 넘어, 특정 도메인에 더 잘 적응할 수 있음을 보여줌.
-
Analysis on adaptive bottlenecks: Adaptive Bottlenecks 모듈이 모델의 일반화 능력에 기여함을 분석함. 고정된 병목(fixed bottleneck) 크기를 사용하는 경우와 비교하여 동적 병목(dynamic bottleneck)의 효과를 입증함.
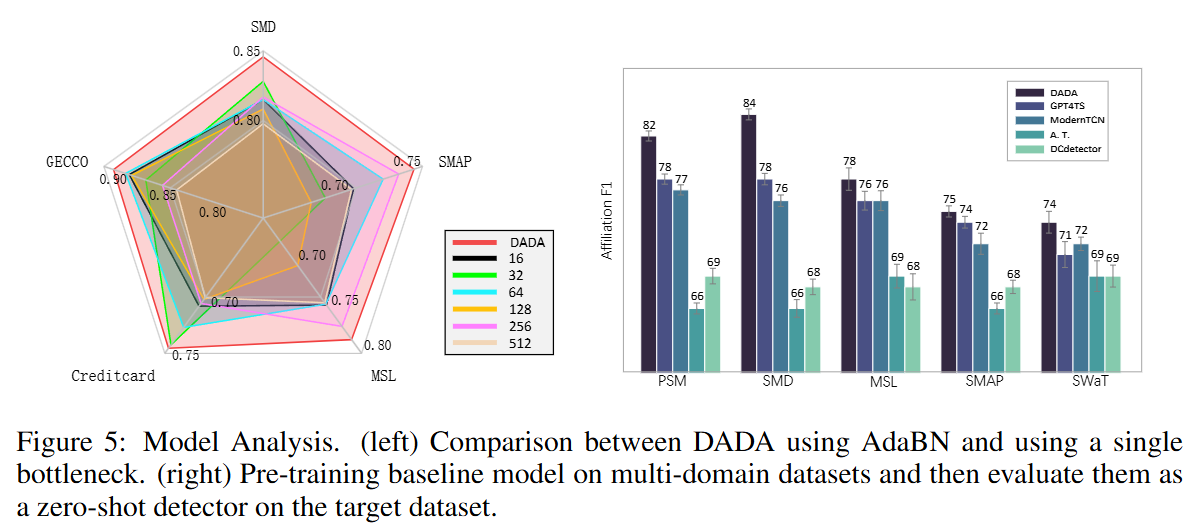
-
Analysis on multi-domain pre-training: 다중 도메인 사전 학습이 모델의 일반화 능력에 미치는 영향을 평가함. DADA는 다른 베이스라인 모델들이 실패한, 다중 도메인 데이터에서 일반화 능력을 효과적으로 추출하는 이점을 가짐.
-
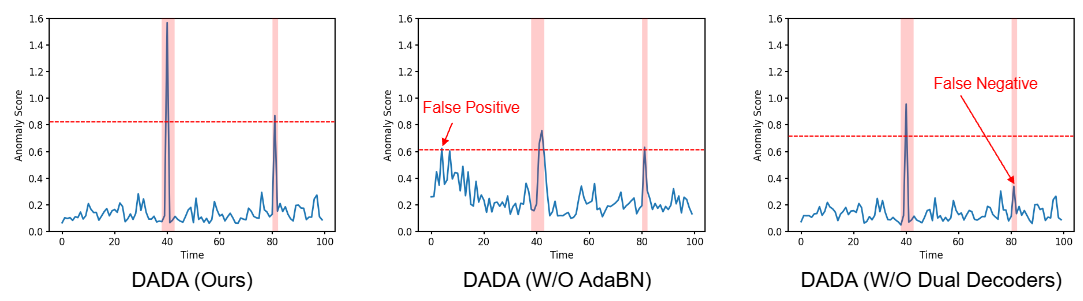
Visual analysis: PSM 데이터셋 등 실제 데이터셋에서 생성된 이상 점수(anomaly scores)를 시각화함. DADA가 오탐(false positive) 및 미탐(false negative)을 줄이며 이상 데이터를 얼마나 정확하게 식별하는지 보여줌.