Revisiting Multimodal Transformers for Tabular Data with Text Fields
Thomas Bonnier
Findings of the Association for Computational Linguistics (ACL), 2024
Abstract
-
문제점
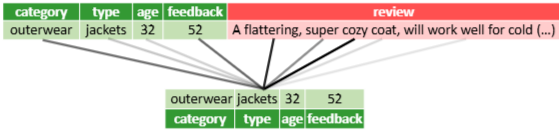
금융 위험 평가, 의료 진단 예측 등에서 텍스트 필드를 포함한 테이블 데이터를 활용할 때, 수치형 특징 인코딩과 융합 전략 선택이 중요함.
→ Tabular-Text Transformer (TTT) 제안: 테이블·텍스트 이중 스트림(dual-stream) 트랜스포머 네트워크 -
핵심 구성 요소
- Distance-to-Quantile 임베딩
- 수치형 특징 전용 임베딩 방식
- 각 특징 값을 분포의 퀀타일까지 거리로 변환 → 이상치·순서 정보 반영
- Overall Attention 모듈
- 자기-어텐션 + 교차-모달 어텐션 동시 수행
- 테이블·텍스트 간 상호작용 학습
- Distance-to-Quantile 임베딩
-
불확실성 정량화 및 설명
- 정량화: 두 모달리티 스트림의 예측 불일치 시, 불확실하다고 판단
- 설명: Shapley 값 샘플링 기반 근사 → 불확실성의 원인 특징 설명
1. Introduction
활용 분야
- 금융 위험 평가 (예: 기업 신용도 예측)
- 의료 진단 예측 (예: 임상 데이터 + 간병인 노트)
기존 문제점
- 수치형 특징 인코딩: 기존 선형 매핑은 순서·극단값 반영 한계
- 어텐션 구조: 단일/교차 모달리티만 각각 고려하는 한계
- 불확실성: 예측 신뢰도 및 원인 설명 필요
기여
- TTT 모델 제안: 표 데이터 + 텍스트 처리 듀얼 스트림 Transformer
- Distance-to-Quantile 임베딩: 수치형 특징 분포·극단값 반영
- Overall Attention 모듈: Self-attention + Cross-modal attention 동시 적용
- 불확실성 정량화: 두 모달 스트림 활용
- 불확실성 설명: Shapley 값 기반 특징 기여도 분석
- 성능 입증: 8개 데이터셋, 6개 베이스라인과 비교·검증
2. Related Work
1) Embeddings for tabular features
- 목표: 수치·범주 데이터를 고차원 벡터로 변환해 Transformer 등 모델 성능 향상
- 범주형 특징: 룩업 테이블로 각 범주에 임베딩 벡터 할당
- 수치형 특징: 선형 함수, 구간별 선형 인코딩 사용
2) Multimodal machine learning
- 정의: 서로 다른 모달리티(텍스트, 이미지, 오디오 등)를 함께 활용해 작업 수행
- 융합 전략
- 초기 융합: 초기에 모달 결합, 모든 레이어에서 pairwise attention
- 후기 융합: 최종 표현 결합 (덧셈, 연결)
- TFN: 임베딩의 카르테시안 곱
- MulT: 교차 모달 어텐션 + 별도 자체 어텐션
3) Uncertainty quantification and explanation
- 불확실성 종류
- Aleatoric(우연적): 데이터 내재적 노이즈 또는 무작위성 때문에 발생
- Epistemic(인식론적): 데이터 지식 부족(적절하게 학습되지 않음), 분포 외(OOD)로 발생
- 불확실성 정량화 방법
- Conformal Prediction: 목표 커버리지 기반 예측 집합 생성
- True Class Probability Estimation: 실제 클래스 확률 추정
- 설명 방법
- MM-SHAP: 다중 모달 기여도 분석, 단일 모달 붕괴 감지
- Shapley Sampling Approximation: 특징 기여도 계산
- CLUE: 반사실 기반 불확실성 원인 식별
3. Tabular-Text Transformer
- 데이터셋:
- 입력
- : 텍스트 (상품 리뷰, 환자의 진료 기록 등)
- : 범주형 (국가, 제품 유형, 성별 등과 같이 이산적인 값)
- : 수치형
- 출력 : C-클래스 분류 과제의 정답 클래스 ()
3.1 Novel Components
3.1.1 Distance-to-quantile embedding
목적
- 수치형 특징 → 차원 임베딩 변환
- 순서·분포·극단값을 반영해 기존 선형 임베딩 한계 보완
원리
1. 분위수(Quantiles): 개의 분위수 사용
2. 분위수 임베딩: (학습 가능)
3. 가중치 계산:
- 이면 , 나머지 0
- 아니면 , 정규화 수행
- 임베딩 벡터:
장점
- 가까운 분위수 임베딩 영향 ↑
- 이상치는 극단 분위수로 처리
- 값의 순서를 자연스럽게 반영
- 각 수치형 특징별 개별 임베딩 생성 가능
3.1.2 Overall attention
-
목표: 모달리티 임베딩 가 Self-Attention과 Cross-Modal Attention을 동시에 활용해 정보 강화
-
입력: ,
-
통합 시퀀스:
-
쿼리/키/밸류:
-
계산식:
- : 질문()이 모든 키()와 얼마나 유사한지 계산
ex) 테이블 데이터의 '나이'라는 질문이 텍스트 데이터의 '어린', '중년', '노년'과 얼마나 관련이 있는지 - : 값이 너무 크거나 작아지는 것을 방지하는 정규화 역할
- 계산된 '중요도 가중치'들을 값(Value, )에 곱하여 가중 평균을 구함
- : 질문()이 모든 키()와 얼마나 유사한지 계산
-
특징: 자기 모달+다른 모달 모두에 attention → 더 넓은 컨텍스트 반영
3.1.3 Uncertainty quantification
배경 및 목적
- 실제 레이블 확보는 비용·시간 부담이 큼 → 레이블 없는 데이터 예측 시 불확실성 측정 필요
- 불확실한 예측은 전문가가 이해·개입할 수 있도록 지원
Dual Loss 학습
- 구성: 텍스트 스트림 + 테이블 스트림
- 목적: 각 스트림이 개별적으로 실제 레이블에 근접하도록 학습
- Loss 식:
- : 크로스 엔트로피 손실
- : 실제 클래스 레이블
추론 시 불확실성 정량화
- Stream Disagreement:
- 불일치: → 예측 불확실, 예측 집합에 두 레이블 포함
- 일치: 예측 집합에 하나의 레이블만 포함
- 활용:
- 전문가가 예측 영역 기반 신뢰도 판단
- 평균 예측 집합 크기 모니터링 → 증가 시 불확실성 상승
3.1.4 Explaining uncertainty
목적
- 텍스트 스트림과 테이블 스트림이 서로 다른 예측을 할 때 불확실성의 원인을 규명
- 데이터 부족, 클래스 오버랩 등 불확실성을 유발하는 특징 식별
가치 함수
-
Jensen-Shannon Distance (JSD): 두 스트림 확률 분포 차이 계산
- 는 텍스트 스트림의 Softmax 확률 벡터
- 는 테이블 스트림의 Softmax 확률 벡터
-
불확실성 분류기: 두 스트림 Softmax 확률로 불확실 여부 예측
Shapley 값 근사
1. 예측을 확실()/불확실()로 구분
2. 불확실 샘플에 대해 참조 샘플로 특징 일부를 교란(, )
3. JSD·분류기 기반 기여도를 계산 후 M회 평균
- JSD:
- 분류기:
활용
- 금융·의료 등 신뢰성이 중요한 분야에서 불확실성 원인 분석
- 전문가가 기여도 높은 특징을 바탕으로 예측 조정
3.2 TTT Overall Architecture
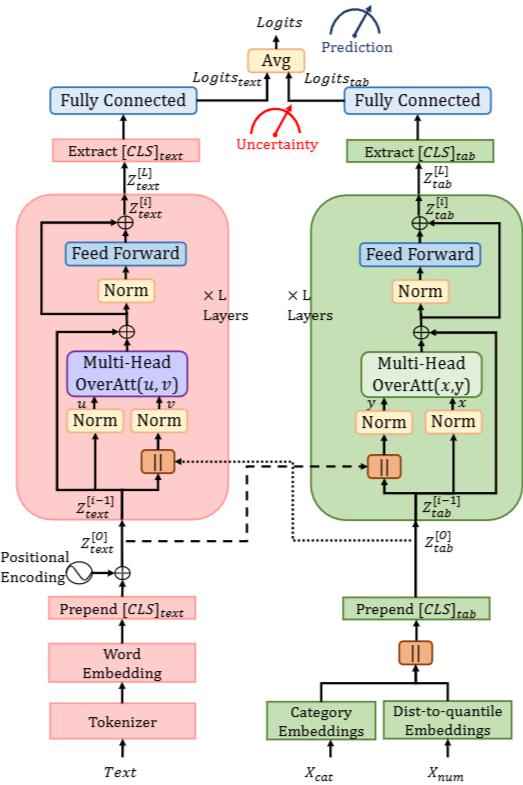
Embedding
- 텍스트 특징: 워드 임베딩으로 변환 ()
- 범주형 특징: 카테고리 임베딩으로 변환 ()
- 수치형 특징: Distance-to-Quantile 기법으로 임베딩 생성 ()
- 범주형+수치형 임베딩 결합 → , 여기서
- 각 시퀀스 시작에 [CLS] 토큰 추가
- 텍스트 임베딩에는 사인·코사인 기반 고정 위치 인코딩 적용
- 학습 과정에서 모든 임베딩은 모델이 직접 학습
Overall Attention Transformer
- L개의 overall attention 블록으로 구성
- 예: 태블러 스트림의 i번째 블록
- : 텍스트 모달리티의 로우레벨 특징
- 레이어 정규화 → 피드포워드 신경망 → 잔차 연결 적용
Classification Layers
- 각 스트림의 [CLS] 임베딩() → 완전연결층 → 로짓 생성
- 로짓은 불확실성 계산에 활용
- 최종 예측: 텍스트·태블러 로짓 평균의 argmax
- 성능 평가는 최종 단일 예측 레이블 기반
4. Experiments
성능


- TTT는 대부분 데이터셋에서 EarlyConcat, LateFuse, MulT, TFN보다 높은 성능
- 경량 모델 TTT-SRP(8.2M 파라미터)도 LateFuseBERT(81.3M)보다 우수, AllTextBERT(66.4M)와 유사
- 소규모 데이터셋(airbnb, petfinder, salary)에서 대형 모델보다 나은 결과
불확실성 정량화
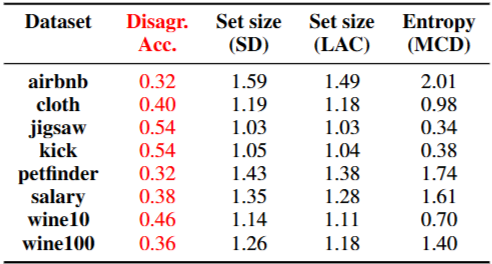
- 평균 예측 집합 크기 ↑ → 정확도 ↓ (음의 상관관계)
- TTT-SD 방식이 LAC, MCD보다 레이블 없는 데이터에서 불확실성 측정에 더 적합
- Pearson 상관계수: TTT-SD -0.953, LAC -0.947, MCD -0.932
Ablation Studies


- Overall Attention: Self-attention만 사용 시보다 성능↑
- Dual Loss: 단일 로스보다 성능↑
- Distance-to-Quantile: 수치형 특징 많은 데이터셋에서 유효
- 임베딩 초기화: TTT-SRP가 대부분 데이터셋에서 최고 정확도
불확실성 설명
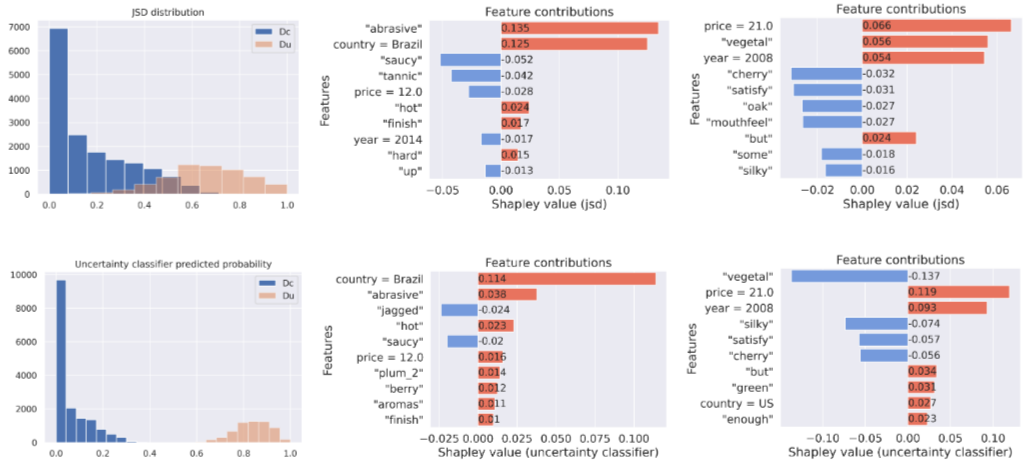
- 불확실성 분류기가 JSD보다 확실/불확실 구분 잘함
- 특징 기여도 분석: 특정 국가·단어가 불확실성에 영향
- 합성 감도 테스트: 가격·연도 불일치 → 불확실성 증가
- 텍스트 스트림은 정답 유지, 테이블 스트림은 오답
- Shapley 추정법과 Kernel SHAP의 Pearson 상관계수 높음
- JSD 0.93, 분류기 0.86
- 특정 상황에서 분류기 기반 설명이 더 일관성 높음
5. Conclusion
- Tabular-Text Transformer(TTT): 분류 작업에서 우수한 성능을 보인 멀티모달 접근법 제시
- 예측 불확실성의 정량화와 설명 가능성을 입증
- 향후 연구: TTT를 위한 사전 학습(pretraining) 전략 개발에 집중
6. Limitations
-
중요 업무 데이터셋 부재
- 본 연구에서 사용한 데이터셋은 의료·금융 등 중요한 업무와 관련 없음
- 해당 분야의 표·텍스트 데이터셋 공유 필요
-
불균형 시퀀스 길이의 영향
- 텍스트 시퀀스 길이와 표 특징 수의 불균형(예: 긴 텍스트, 적은 표 특징)에 대한 영향 미평가
- 이러한 불균형이 성능에 미치는 영향 연구 필요
-
불확실성 정량화와 커버리지
- TTT의 예측 집합 크기는 최대 2로 제한
- Conformal Prediction처럼 원하는 커버리지 수준 지정 불가
- 실제 커버리지는 검증 데이터로만 평가 가능하며, 조건부 커버리지는 인구 하위 그룹 등 차원별로 달라질 수 있음
- 참 레이블 확보 시, 조건부 커버리지 모니터링 필요
