TabGLM: Tabular Graph Language Model for Learning Transferable Representations Through Multi-Modal Consistency Minimization
Anay Majee, Maria Xenochristou, Wei-Peng Chen
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025
Abstract
- 문제: 테이블 데이터는 숫자·범주형·텍스트가 섞인 heterogeneous 데이터라 기존 딥러닝 모델이 성능이 떨어짐.
- 아이디어: 테이블 행을
완전 연결 그래프 → GNN으로 인코딩
직렬화된 텍스트 → 텍스트 인코더로 인코딩후, 멀티모달 자기 지도 학습으로 두 표현을 정렬. - 장점: 그래프·텍스트 정보를 모두 활용해 적은 파라미터로 효율적 학습 가능.
1. Introduction
기존 방법론:
- 텍스트 데이터를 수치형으로 인코딩
- 구조적 특징만 모델링 → 의미적(semantic) 정보 손실
- uni-modal 시도: tabular data를 이미지, 언어, 그래프 등으로 변환
- 이질성(heterogeneity)가 높을때 성능 저조
- DL모델들은 차원 높거나, 샘플 수 제한적일때 과적합에 취약
TabGLM:
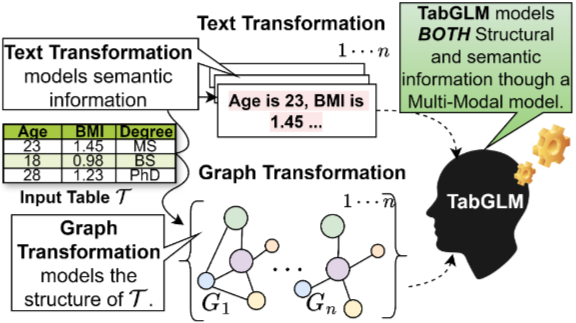
- multi-modal 아키텍처
- 표의 각 행을 1) fully connected graph와 2) serialized text로 변환
- 변환된 데이터는 각각 그래프 신경망(GNN)과 사전 학습된 텍스트 인코더를 사용하여 인코딩
- joint multi-modal, self-supervised learning 목표를 통해 두 표현을 정렬
- 두 모드의 상호 보완적인 정보를 활용하여 feature learning 강화
- graph-text 파이프라인은 기존 딥러닝 방식보다 훨씬 적은 수의 파라미터로 heterogeneous 데이터셋을 효율적으로 처리
2. Related Work
Traditional Tabular Machine Learning
- 대표 모델
- 트리 앙상블: Gradient Boosting, ExtraTrees, Random Forests → 패턴 학습·과적합 방지
- 부스팅: XGBoost, LightGBM → 효율·확장성 우수
- 회귀: Logistic Regression → 단순·해석 용이
- 범주형 특화: CatBoost → 범주형 처리 강점
- 장점: 해석 가능, 효율적, 실무 성능 안정적
- 한계: 수작업 특징 엔지니어링 필요, 자동 표현 학습 불가
Transformers for tabular data
- FT-Transformer: 숫자형·범주형 특징 분리, 분류·회귀 성능 우수
- Saint: 행별 어텐션으로 샘플 간 상호작용 포착
- Fastformer: 선형 복잡도의 경량 가산 어텐션 제안
- TransTab: 테이블 간 전이 학습 적용
최근 발전: 어텐션·임베딩 구조 조정으로 데이터 보간·크로스테이블 학습 지원
Self-supervised pretraining
레이블 없는 대규모 데이터로 유용한 특징을 스스로 학습 → 시각·언어 분야 성공 → 테이블 데이터로 확장
- 목표: 레이블 의존도 줄이면서 일반화된 특징 표현 학습
- 주요 방식
- Auto-encoder: 결측·손상된 데이터 복원 (VIME, SubTab)
- Contrastive learning: 특징 손상 후 유사 샘플은 가깝게, 다른 샘플은 멀리 (SCARF)
- Target-aware objective: 레이블 컬럼을 사전 학습에 통합 (Revisiting Pretraining Objectives, TransTab)
- 한계: 수치형·범주형·텍스트형 등 이질적 특징 컬럼 처리에 성능 저하
TabGLM 제안:
- 각 행을 그래프(구조) + 직렬화 텍스트(의미) 로 변환
- GNN과 사전 학습 텍스트 인코더로 인코딩
멀티모달 자기 지도 학습으로 두 표현을 정렬 → 이질적 데이터 처리 강화
Modality switch for Tabular Deep Learning
- 텍스트 변환: TabLLM → 컬럼 의미 잘 포착, 하지만 고차원 데이터에서 비효율·문맥 손실.
- 이미지 변환: SuperTML, DeepInsight → CNN 활용, 특징 관계 포착 가능하나 표현 다양성 제한.
- 그래프 변환: Table2Graph, IGNNet, GCondNet, CARTE, HyTrel 등 → 구조적 관계 학습 가능, 그러나 범주형·텍스트 의미 정보 반영 어려움, 대규모 데이터 확장성·그래프 구성 민감성 문제.
Multi-Modal Learning
텍스트·이미지·그래프 등 다양한 모달리티 데이터를 결합해 성능·일반화 향상.
- CLIP → 텍스트·이미지 정렬, 제로샷 학습·검색 가능
- CLIP 확장 → 3D 인식, 프롬프트 튜닝
- 교차 모달 지식 증류 → 모달 간 지식 전달
- 제로샷 텍스트-이미지 생성
- 장점: 각 모달리티의 상호보완 정보(공간 패턴·의미·구조 관계) 활용 가능
- TabGLM 기여: 그래프+텍스트 모달리티를 단일 테이블 입력에 적용, 통합 임베딩으로 분류 태스크 성능 향상. 탭형 데이터에 이런 멀티모달 학습을 적용한 최초 연구.
3. Method
3.1 Problem Definition
문제 설정
표 형식 데이터셋 에서 새 레코드 가 특정 클래스 에 속할 확률을 예측
- : 표 형식 데이터셋
- : 레코드 수
- : 특징 수
- : 번째 레코드의 레이블
- : 테스트 레코드
학습 목표
학습 데이터 의 샘플 로부터 특징 표현 를 학습하는 를 훈련함.
- : 특징 표현 학습기
- : 모델 파라미터
- : 학습된 특징 표현
다운스트림 태스크
를 분류기 에 입력하여 예측에 사용.
핵심 과제
모델 의 성능은 표현 의 품질에 좌우됨.
여기서는 수치형과 텍스트형이 혼합된 이질적 열을 가진 테이블 를 사용.
3.2 TabGLM: Tabular Graph Language Model
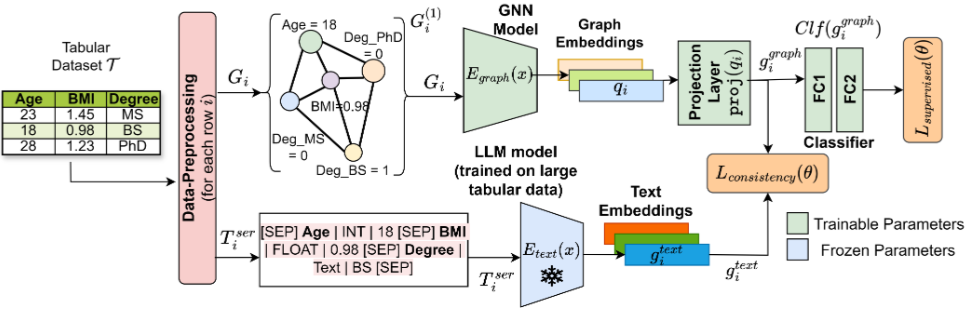
-
heterogeneous 테이블 데이터 문제를 해결하기 위한 multi-modal 아키텍처
-
기존 단일 모달 방식은 구조적 정보 또는 의미론적 정보 중 하나만 인코딩해 성능 저하가 발생
-
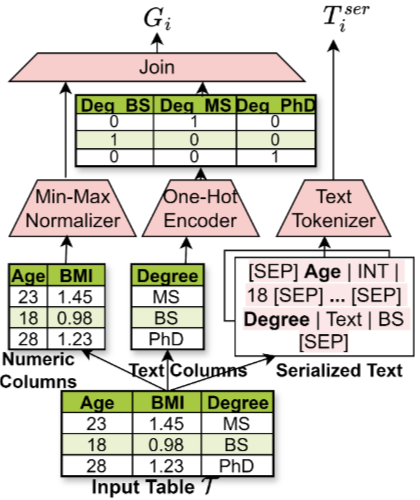
각 행을 두 가지 모달로 변환
- 1) 그래프 변환: 완전 연결 그래프 형태로 만들어 열 간 구조적 관계를 모델링하며, GNN(Egraph)으로 인코딩
- 2) 텍스트 변환: 행을 직렬화된 텍스트로 변환해 셀 값의 의미 정보를 포착하며, 사전 학습된 텍스트 인코더(Etext)로 임베딩
-
학습은 MUCOSA라는 공동 자기 지도 학습 목표를 사용
- L_consistency: 그래프와 텍스트 임베딩 간 일관성 손실 최소화 (레이블 불필요)
- L_supervised: 그래프 임베딩 기반 분류 예측과 실제 레이블 차이 최소화
- 최종 손실: → 정보 융합 및 과적합 완화 역할을 함.
-
효율성을 위해 Etext 파라미터를 학습 중 고정하고, 추론 시 Etext forward pass를 생략 → 파라미터 수를 80% 이상 줄이면서도 추론 속도를 향상
3.3 MUCOSA: Multi-Modal Consistency Learner
MUCOSA (Multi-modal Consistency Learner)는 TabGLM의 단일 단계 공동 준지도 학습 방식으로, 그래프·텍스트 모달리티의 표현을 결합하고 동시에 하위 작업에 적응하도록 함.
1. 다중 모드 정보 결합
- E_graph: 구조적 특징(g_graph_i) 인코딩
- E_text: 의미론적 특징(g_text_i) 인코딩
- 두 모달리티의 보완적 정보를 결합해 활용함.
2. 일관성 손실
- 목적: 같은 샘플의 텍스트 임베딩()과 그래프 임베딩()은 벡터 공간에서 서로 가까워지게, 다른 샘플의 임베딩끼리는 멀어지게 함.
- 방식: L2 정규화된 텍스트·그래프 임베딩 간 대조 학습 적용.
- 온도 사용, 역전파 차단 기법 포함.
- 효과: 의미가 유사한 데이터의 표현을 근접하게 만들고 과적합 완화.
3. 지도 손실
- 목적: 예측 로짓 와 실제 레이블 간 차이 최소화.
- 그래프 임베딩만 사용해 분류기 학습.
- 손실 함수: 교차 엔트로피.
4. 최종 목적 함수
- 두 손실을 가중합으로 결합.
- 로 설정.
4. Experiments
기존 선형·트리 기반 모델, SoTA Tabular 딥러닝 모델 대비
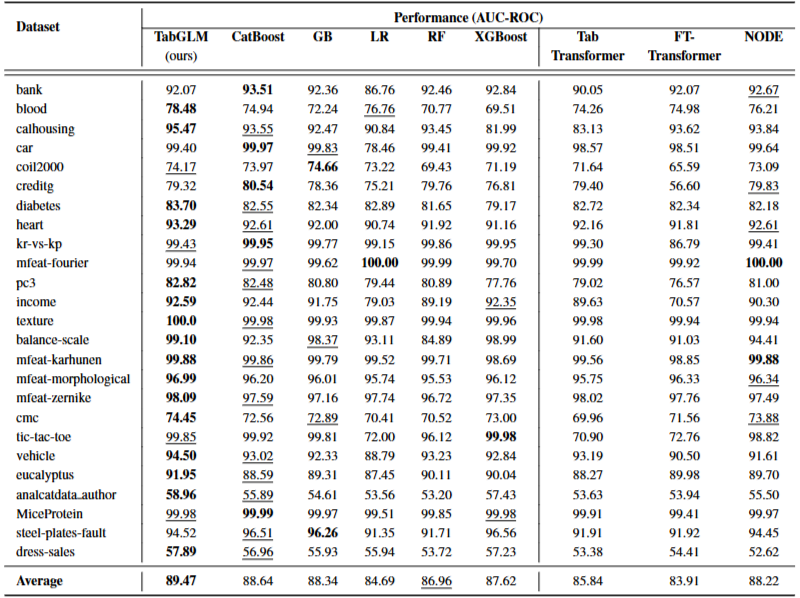
- LR(Logistic Regression) 대비 평균 AUC-ROC +4.77%
- RF(Random Forest) 대비 +2.51%
- 25개 분류 태스크 전반에서 우수한 성능
- 단, kr-vs-kp, pc3 등 feature column 수가 적은 단순 데이터셋에서는 CatBoost가 더 우세
- FT-Transformer 대비 +5.56%
- TabTransformer 대비 +3.64%
- NODE 대비 +1.26%
SoTA Uni-modal 딥러닝 아키텍처 대비
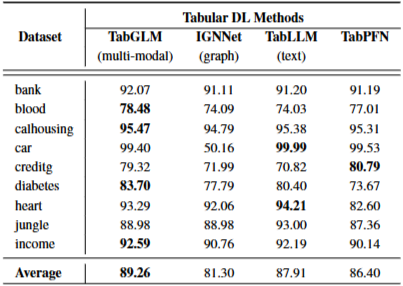
- TabLLM(table-to-text) 대비 +1.35%
- IGNNet(table-to-graph) 대비 +7.96%
4.4 Ablation Study
1) Multi-Modal vs. Uni-Modal training
- Multi-Modal: 그래프(Egraph) + 텍스트(Etext) 통합
- Uni-Modal 변형
- Graph only: IGNNet GNN 사용, 인코더·분류기 모두 학습
- Text only: TAPAS 인코더 사용, 인코더 고정·분류기만 학습
- 실험 데이터셋: pc3(수치형), bank(수치+범주형), creditg(범주형)
- 결과: 멀티모달이 모든 데이터셋에서 유니모달보다 일관되게 우수
→ 이질적 테이블 학습에서 모달리티 융합의 가치 입증
2) Choice of LLM architecture for Text Transformation
- 목적: 테이블 행 → 텍스트 직렬화 → 텍스트 인코더(Etext) 임베딩 생성
- 비교 대상: TAPAS / TAPEX / TabLLM (AUC-ROC & 파라미터 수 비교)
- 결과:
- 파라미터 수 적은 TAPAS가 TAPEX·TabLLM보다 성능 우수 또는 유사
- 단순 의미론적 콘텐츠 처리 시, 대형 LLM의 이점 제한적
- 채택: 텍스트 변환 파이프라인에 TAPAS 사용
5. Conclusion
- 다중 모드 변환: 각 행을 완전 연결 그래프 + 직렬화 텍스트로 변환 → 구조·의미 정보 모두 캡처
- 하이브리드 인코더: 그래프 → GNN, 텍스트 → 사전학습 텍스트 인코더로 인코딩
- 공동 학습 목표: 멀티모달 준지도 학습으로 일반화·표현력 향상
- 효율성: 다양한 특징 유형 처리, SoTA 대비 훨씬 적은 파라미터
- 성능: 25개 벤치마크에서 AUC-ROC 크게 향상, 기존 DL·ML 모두 능가
