MaPLe: Multi‑modal Prompt Learning
Muhammad Uzair Khattak · Hanoona Rasheed · Muhammad Maaz · Salman Khan · Fahad Shahbaz Khan
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
Abstract
- CLIP 같은 사전학습 Vision-Language(V-L) 모델은 다운스트림 작업에 대한 뛰어난 일반화 성능을 보임
- 그러나 입력 프롬프트에 민감하며, 좋은 성능을 위해 신중한 텍스트 템플릿 선택이 필요
- 최근 NLP 문헌에서 영감을 받아, CLIP을 적응시키는 기존 방법들은 주로 텍스트 프롬프트만을 학습하여 성능을 향상시킴
- CLIP의 한쪽 branch(언어나 비전)만을 조정하는 것은 비최적
→ 양쪽 표현 공간(language & vision)을 동적으로 조정할 수 없기 때문
- CLIP의 한쪽 branch(언어나 비전)만을 조정하는 것은 비최적
- Multi-modal Prompt Learning (MaPLe)을 제안
- 비전과 언어 프롬프트 모두를 학습하여 양쪽 표현 공간 정렬을 향상시킴
- 양쪽 프롬프트가 상호 작용하고 결합되도록 유도, 독립적인 단일 모달 해법 학습은 억제
- 초기 단계별로 분리된 프롬프트를 학습하여 계층적(context-rich) 표현을 가능
- MaPLe는 다음 세 가지 과제에서 기존 SoTA인 CoCoOp보다 우수한 성능을 보임:
1) 보지 못한 클래스(novel classes)
2) 새로운 타깃 데이터셋
3) 도메인 시프트
1. Introduction
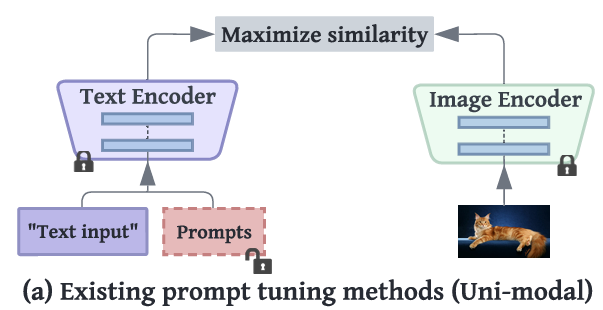
기존 문제점:
- CLIP은 멀티모달 모델(text + image)인데도, 기존 방법들은 텍스트 인코더만 조정하여 비효율적.
- 특히, 이미지 인코더의 표현공간은 그대로 두는 것은 비전-언어 정렬(alignment)에 불리함.
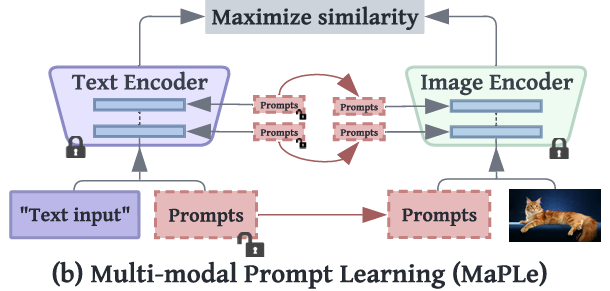
MaPLe
CLIP의 텍스트 인코더 + 이미지 인코더 양쪽에 모두 프롬프트를 학습시키는 방식으로 다음과 같은 설계를 가짐:
1) 양방향 연동 프롬프트 학습 (Coupling)
- 비전 프롬프트를 텍스트 프롬프트에 조건부로 생성하여, 두 모달리티 간 시너지 유도
- 텍스트 인코더와 이미지 인코더가 상호작용하며 함께 적응
2) 깊이 기반 프롬프트 분산 학습 (Deep Prompting)
- 한 층(layer)에만 프롬프트를 넣는 것이 아니라, 여러 Transformer block에 걸쳐 분산 적용
- 각 레이어의 문맥 정보를 점진적으로 반영하여 풍부한 표현 학습 가능
2. Related Work
Vision Language Models
- 최근 자연어 텍스트 + 이미지의 결합 학습이 컴퓨터 비전에서 큰 관심
- 대규모 V-L 모델들은 이미지와 언어를 웹 기반 데이터 (400M~1B 쌍)로 자기지도학습(self-supervised learning) 하여 강력한 표현 능력을 가짐.
- 다양한 다운스트림 작업에 강한 범용성을 보이지만, 효율적인 적응(adaptation)은 여전히 도전 과제
Prompt Learning
Prompt: "a photo of a [CLASS]"처럼 문장 형태의 지시어를 말하며, 모델에게 태스크 힌트를 제공
- Hand-crafted prompt: 사람이 수동으로 작성
- Learned prompt: 프롬프트 토큰 자체를 학습 (→ Prompt Learning)
Prompt Learning in Vision-Language Models
CLIP을 downstream task에 적응하는 기존 방식:
- Full fine-tuning: 전체 모델 파라미터를 학습 → 기존 V-L 표현 손상
- Linear probing: 고정된 feature extractor 위에 linear classifier만 학습 → zero-shot 능력 저하
해결책: NLP에서 영향 받은 end-to-end 프롬프트 학습
- CoOp: 텍스트 branch의 연속 벡터를 프롬프트로 학습 (few-shot transfer)
- CoCoOp: CoOp의 일반화 한계 → 프롬프트를 이미지 인스턴스에 조건부 생성
3.Method
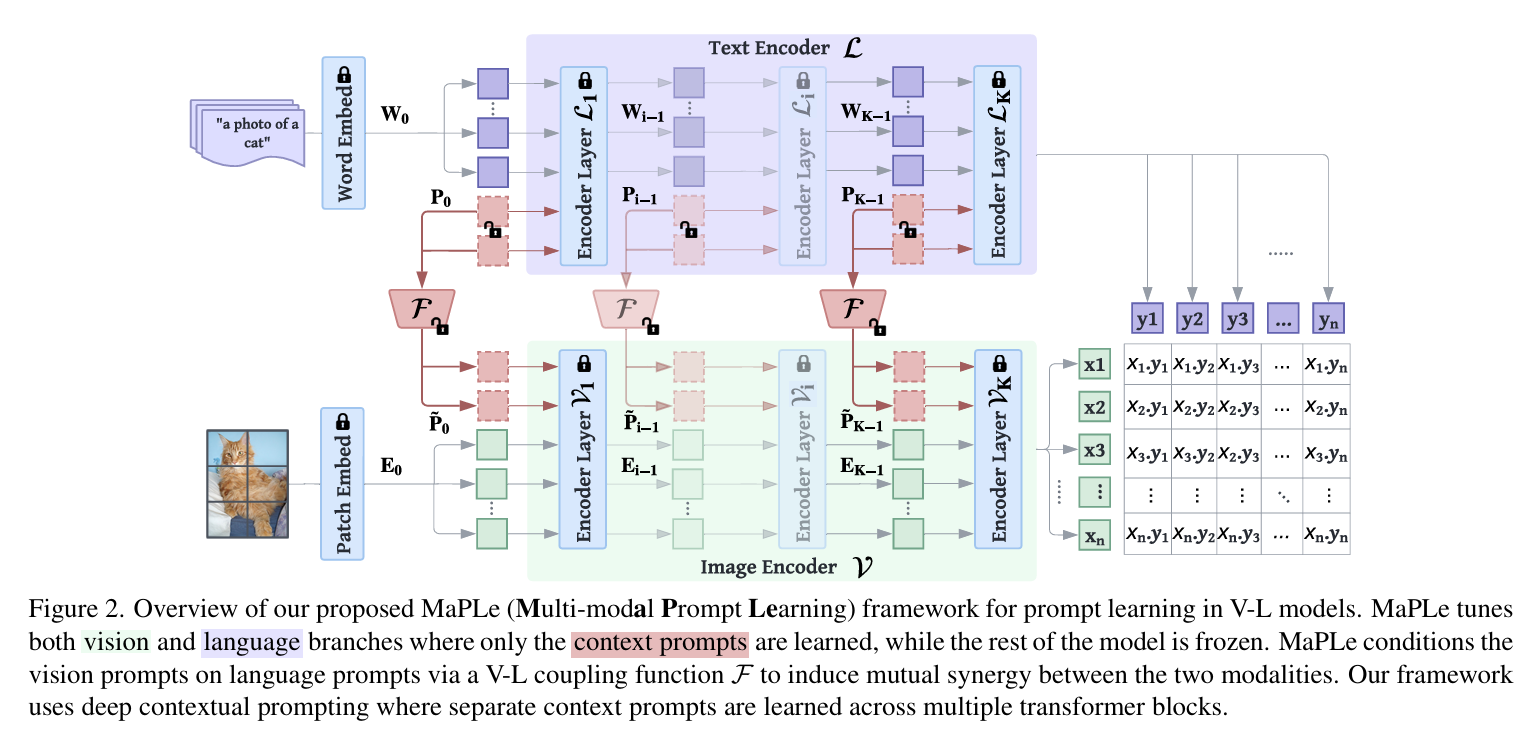 1) Joint Prompting (공동 프롬프트 학습)
1) Joint Prompting (공동 프롬프트 학습)
: Vision branch와 Language branch에 동시에 context token을 추가
2) Coupling Function (결합 함수)
: Language prompt를 기반으로 vision prompt를 조건화(conditional) 시킴
3) Deep Prompting
: 각 Transformer block마다 별도의 context token을 부착 → 계층적 문맥 표현 학습
4) Frozen Backbone
: CLIP의 본래 모델은 그대로 유지(freeze)하고, prompt token들과 결합 함수만 학습
구성요소
1. Deep Language Prompting
- 텍스트 입력 앞에 학습 가능한 프롬프트 토큰 추가
- 이 토큰들은 여러 Transformer 블록 (깊이 )에 걸쳐 적용돼 점진적인 언어 표현 학습 유도
- 이면 CoOp과 동일한 shallow prompting 구조
2. Deep Vision Prompting
- 이미지 입력 patch embedding 앞에 프롬프트 토큰 추가
- Transformer의 초기 개 레이어에 걸쳐 적용 → 계층적인 시각 표현 학습 가능
- 각 블록마다 따로 프롬프트 학습하는 것보다 같은 프롬프트 공유하는 게 성능 더 좋음
3. Vision-Language Prompt Coupling
- 단순한 Independent Prompting은 vision과 language 브랜치가 따로 학습됨 → 상호작용 없음
- MaPLe은 coupling 함수 를 사용해 vision 프롬프트 를 language 프롬프트 에서 생성
- vision prompt가 language prompt에 조건부로 종속되기 때문에 두 브랜치가 공유된 의미 공간 형성
- coupling 함수 는 linear projection layer로 구현
4. Experiments
4.1. Benchmark Setting
1. Base-to-Novel Generalization
: 기존 클래스(base)에서 학습한 뒤, 새로운 클래스(novel)로 일반화 능력 평가
2. Cross-Dataset Evaluation
: 다른 데이터셋으로 전이 학습 없이 테스트할 때 성능 유지되는지 확인
3. Domain Generalization
: 도메인 분포가 달라졌을 때의 강건성 평가
4.2. Prompting CLIP via Vision-Language Prompts
| Variant | 설명 |
|---|---|
| Shallow MaPLe | 언어+이미지 브랜치에 프롬프트를 주되, 첫 번째 layer에만 적용 (J=1). |
| Deep Vision Prompting | 이미지 브랜치에 여러 layer에 걸쳐 프롬프트 삽입 |
| Deep Language Prompting | 텍스트 브랜치에 여러 layer에 걸쳐 프롬프트 삽입 |
| Independent V-L Prompting | vision, language 브랜치 각각에 deep prompting 하되 서로 상호작용 없음 |
| MaPLe (ours) | vision prompt를 language prompt에 의존적으로 생성 (coupling) → 상호작용 강화 |
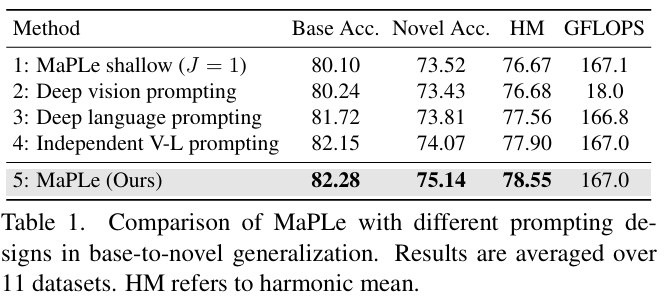
- Shallow MaPLe도 기존 CoOp/CoCoOp보다 좋음
- Deep Language Prompting > Deep Vision Prompting → 언어 정보 기반 프롬프트가 더 강력한 적응력 제공
- Independent V-L Prompting: 두 브랜치를 독립적으로 학습하므로 시너지 부족 → 성능 한계
- MaPLe: vision prompt를 language prompt에 기반해 생성
→ 두 모달리티 간 상호작용 덕분에 base와 novel 클래스 모두에서 성능 향상
→ Harmonic Mean (HM) 기준 최고 성능인 78.55% 달성
4.3. Base-to-Novel Generalization
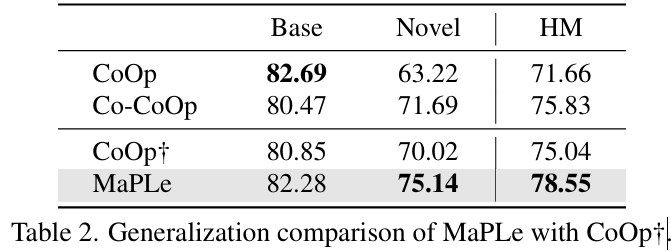
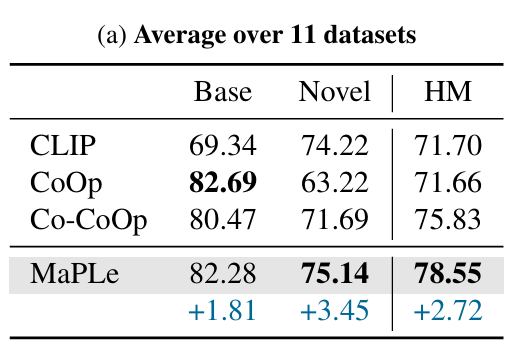
1. vs Co-CoOp
- MaPLe는 11개 전부 dataset에서 Co-CoOp보다 더 좋은 성능을 보임
- 단, Caltech101에서 base class만 소폭 하락
2. vs CLIP (zero-shot)
- CLIP보다 6/11개 dataset에서 성능 향상
- 평균 성능: 74.22% → 75.14%
3. Base Class 성능
- Co-CoOp보다 6/11개에서 성능 우위
- 평균 정확도: CoOp+ 80.85% → MaPLe 82.28% (+1.43%)
4.4. Cross-Dataset Evaluation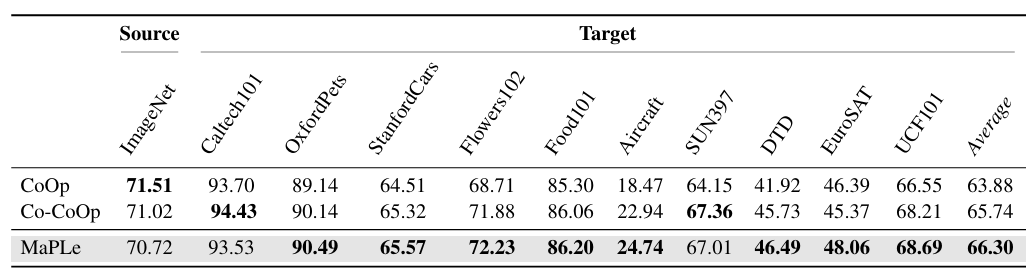
| 모델 | 성능 요약 |
|---|---|
| MaPLe | - 9/10개 데이터셋에서 CoOp보다 우수한 성능 - 8/10개에서 Co-CoOp보다 우수 |
| 평균 정확도 | 66.30% (세 모델 중 최고 성능) |
4.5. Domain Generalization
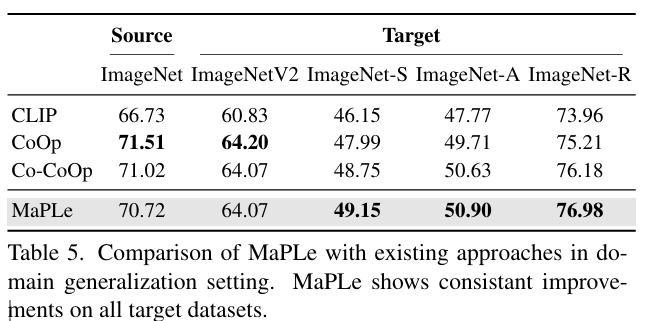 - 모든 도메인 전이 평가에서 CoOp, Co-CoOp 보다 우수한 성능
- 모든 도메인 전이 평가에서 CoOp, Co-CoOp 보다 우수한 성능
4.6. Ablation Experiments
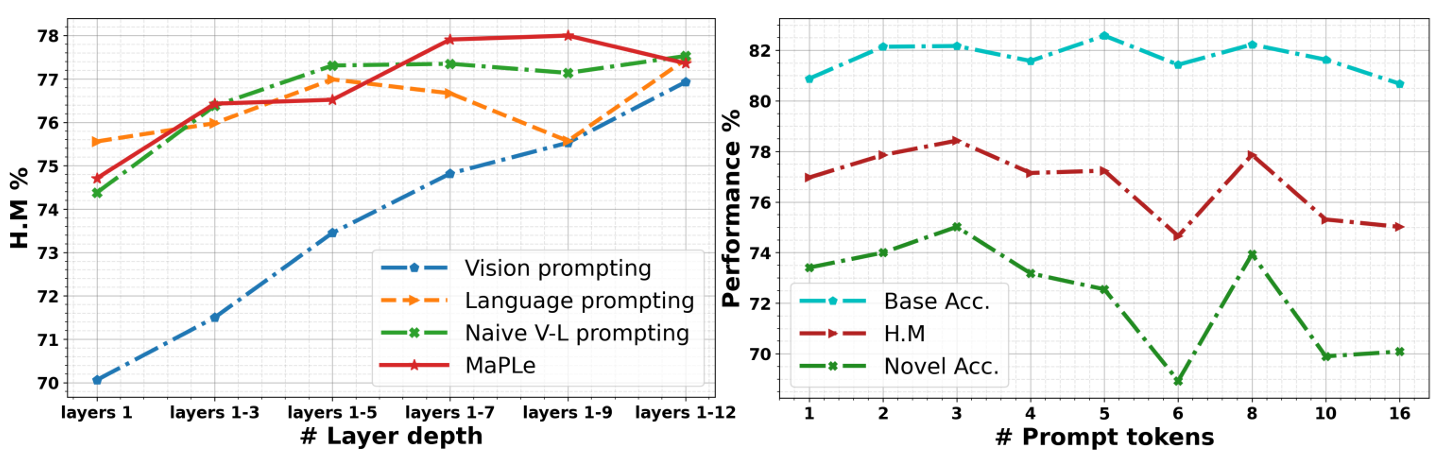
1) Prompt Depth (깊이 J)
- 깊이가 깊어질수록 성능 향상 경향 보임
→ 특히 J=9일 때 최고 성능
2) Prompt Length
프롬프트 길이(토큰 수) 증가 시:
- Base class 성능은 유지
- Novel class 성능은 감소 → 과적합 발생 → 일반화 성능 저하
3) Multi-modal Prompting의 효과
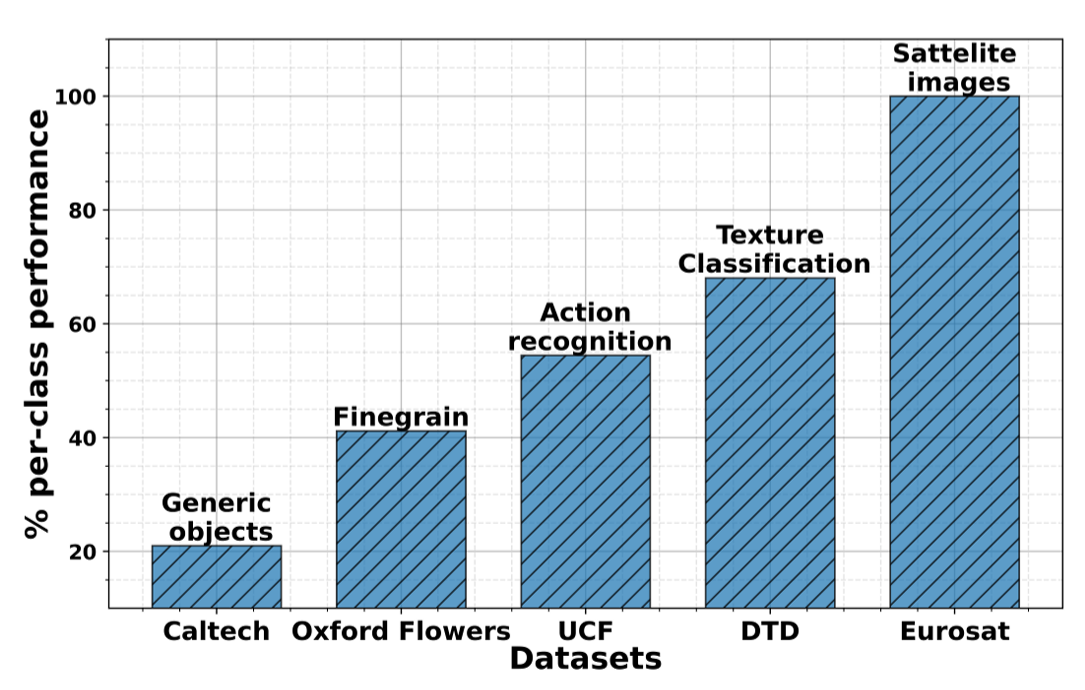
- Co-CoOp 대비 MaPLe가 도메인 변화가 큰 데이터셋일수록 더 큰 성능 향상 보임
- CLIP이 익숙하지 않은 시각 개념(rare concept)에서 더 큰 효과
5.Conclusion
- 미지의 클래스(novel categories) 일반화 향상
- cross-dataset 전이 성능 향상
- domain shift 상황에서도 강건성 확보
