Generative Model
= assigning density functions to images + sampling
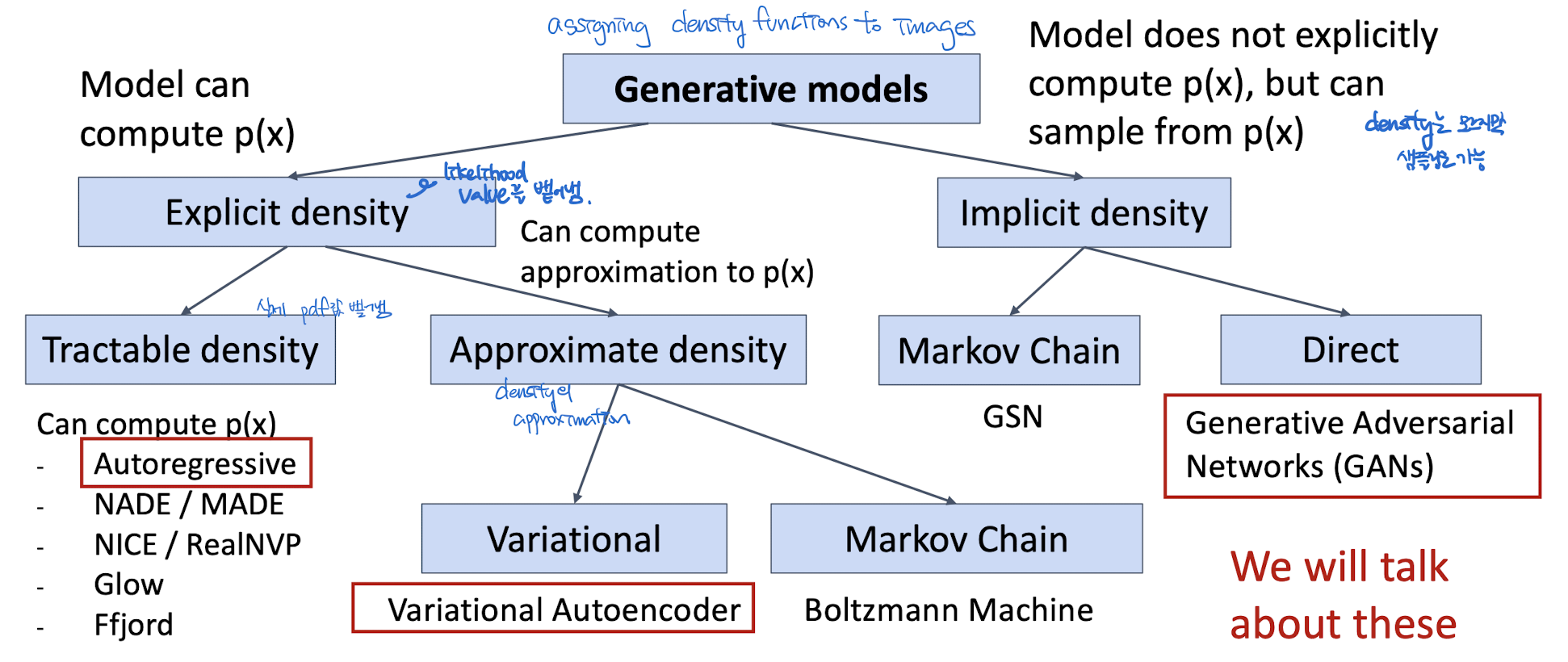
Figure adapted from Ian Goodfellow, Tutorial on Generative Adversarial Networks, 2017.
Explicit Density Estimation
x (image 혹은 pixel)의 확률 분포를 구할 수 있음. Explicit하게!
Tractable density
- x의 joint pdf를 구하는데, 실제 값을 정확하게 구할 수 있음.
- 즉, 명시적으로 Loss function의 값을 구할 수 있고, 최적화 함수의 값을 정확히 계산 가능.
Approximate density : VAE
Variational + AE
- x의 joint pdf를 구하는데, 실제 pdf 값을 구할 수는 없고, pdf의 lower bound만 알 수 있다.
- pdf, likelihood function을 정확하게 구해서 최적화하는 대신, density의 lower bound 값을 최적화 식으로 이용한다.
- not able to access the true value of the density function. BUT! we can compute lowerbound of the density. so, the Goal is to maximize lower bound.
Variational Auto Encoder
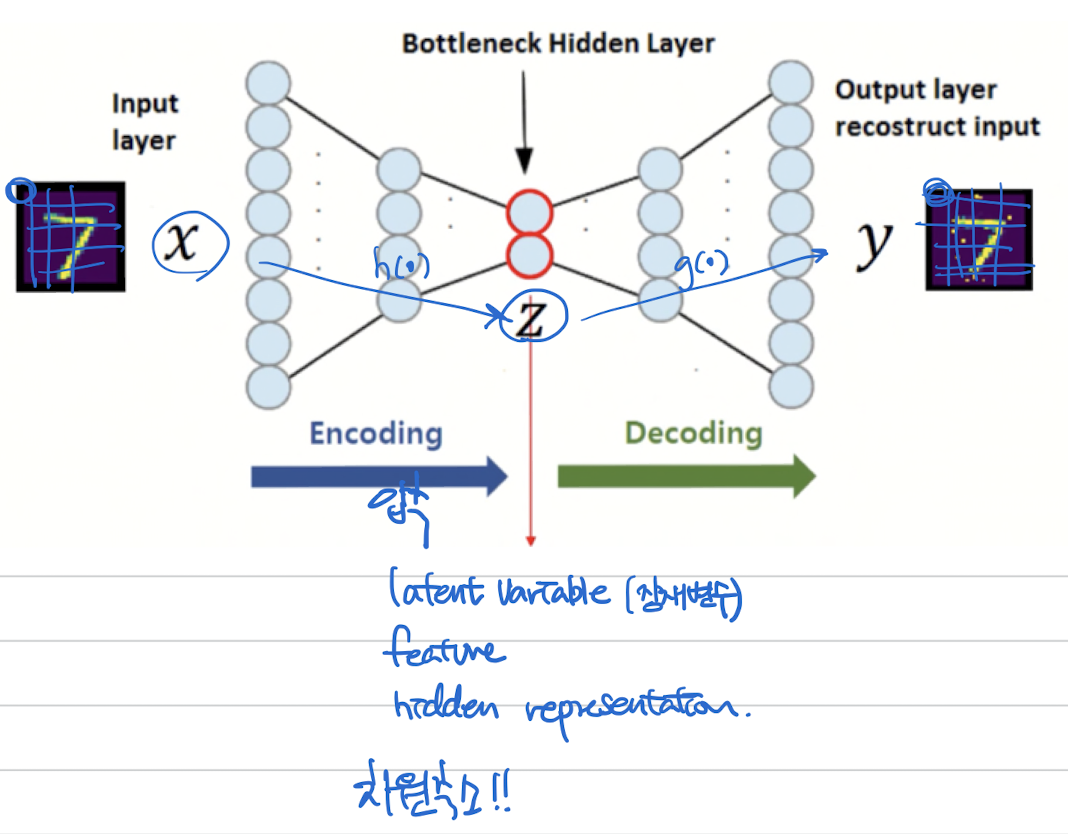
Auto Encoder (non-variational = non-probablistic)
- Unsupervised method for learning feature vectors
- *y 없이 x (data) 만으로 latent feature 를 뽑아내는 Encoder 모델*
- latent vector(feature vector)는 데이터의 중요한 정보를 압축적으로 담고 있어야함!!! 즉, 우리의 목적은 훌륭한 Encoder 만드는 것
- pretrain 후 Encoder만 사용
- Nice Encoder = 좋은 feature vector를 생성하는 = 차원이 낮고 + 중요한 정보를 함축하고 있는 feature vector
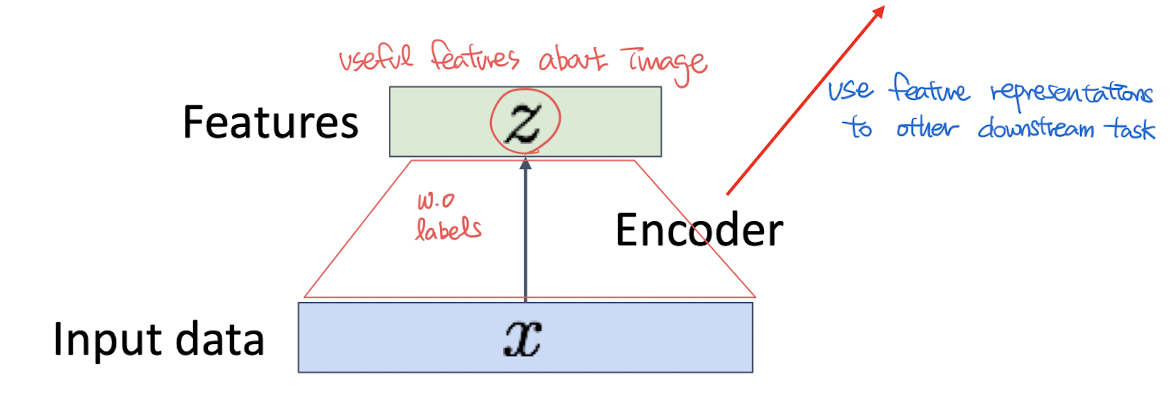
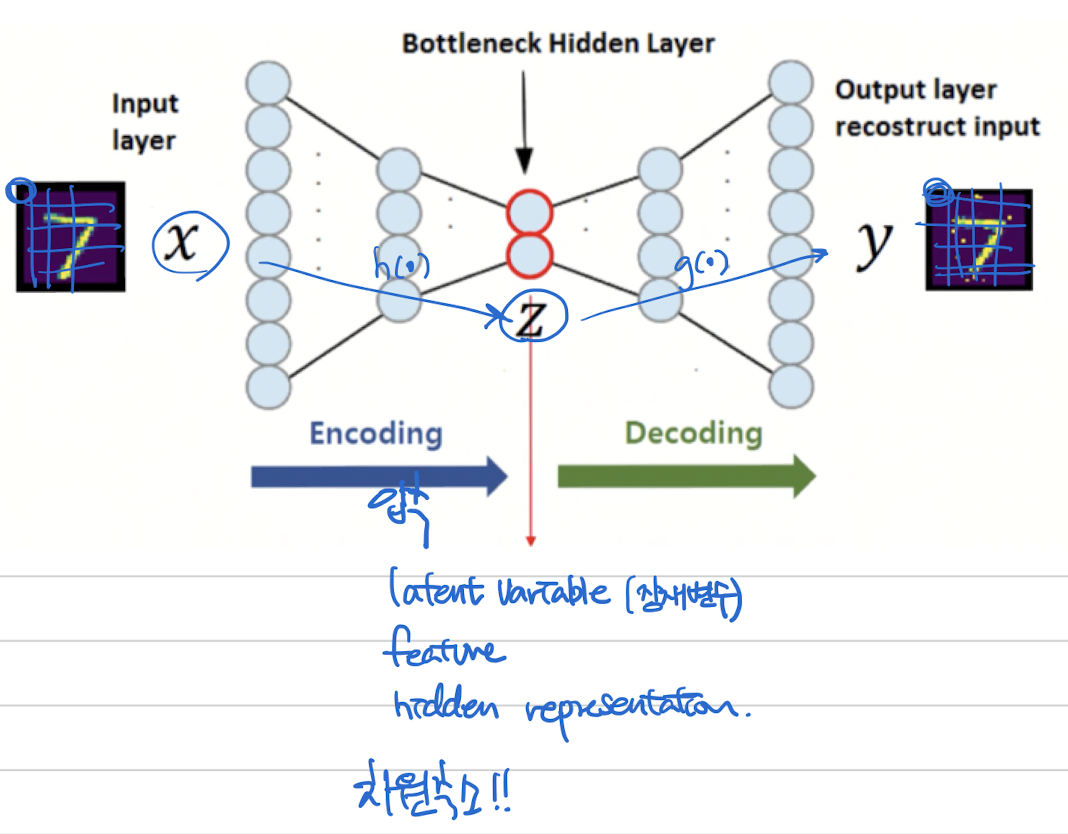
Main Idea of Training (Encoder)
Idea : Reconstruct the input data
input data를 주면, 똑같이 복원 시키는 것이 목표
“Decoder가 원래 이미지처럼 이미지를 잘 생성했다 (복원했다)” == “Encoder가 중요한 정보를 잘 뽑아내서 전달했다” 를 의미함!
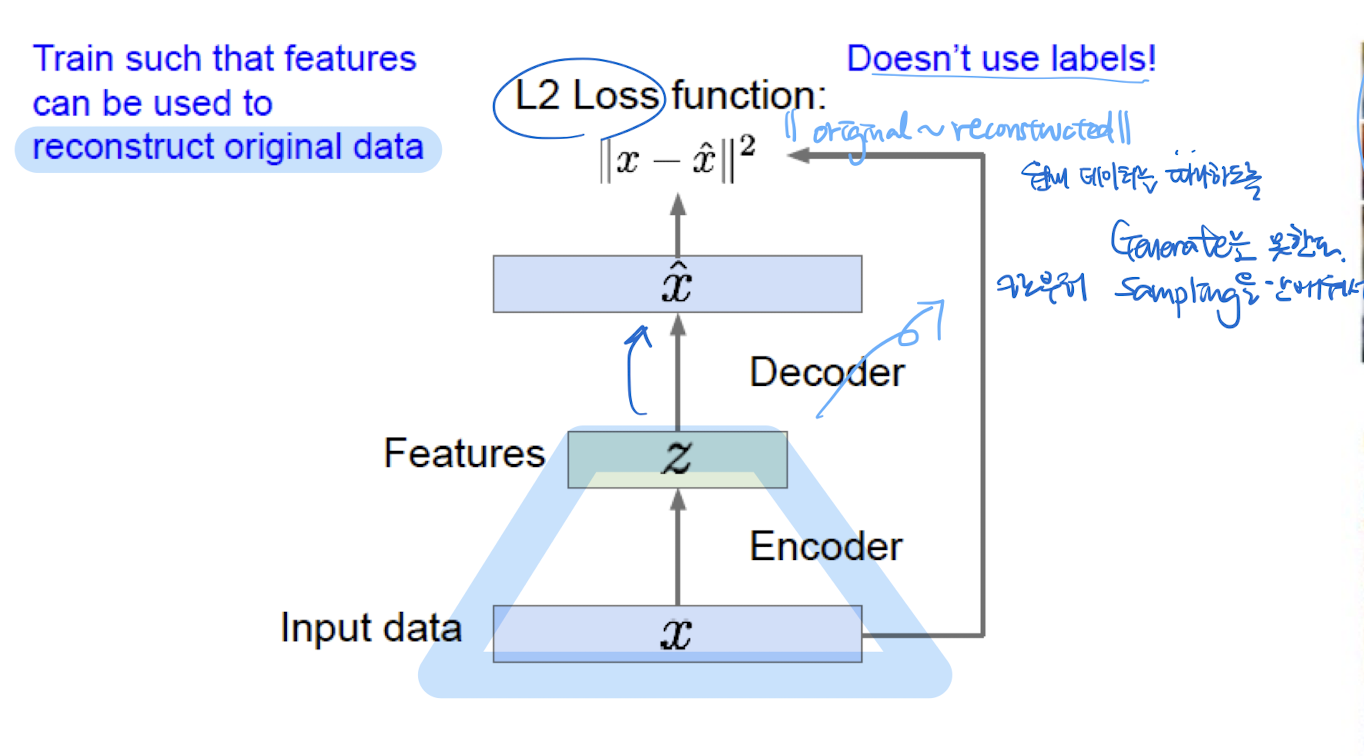
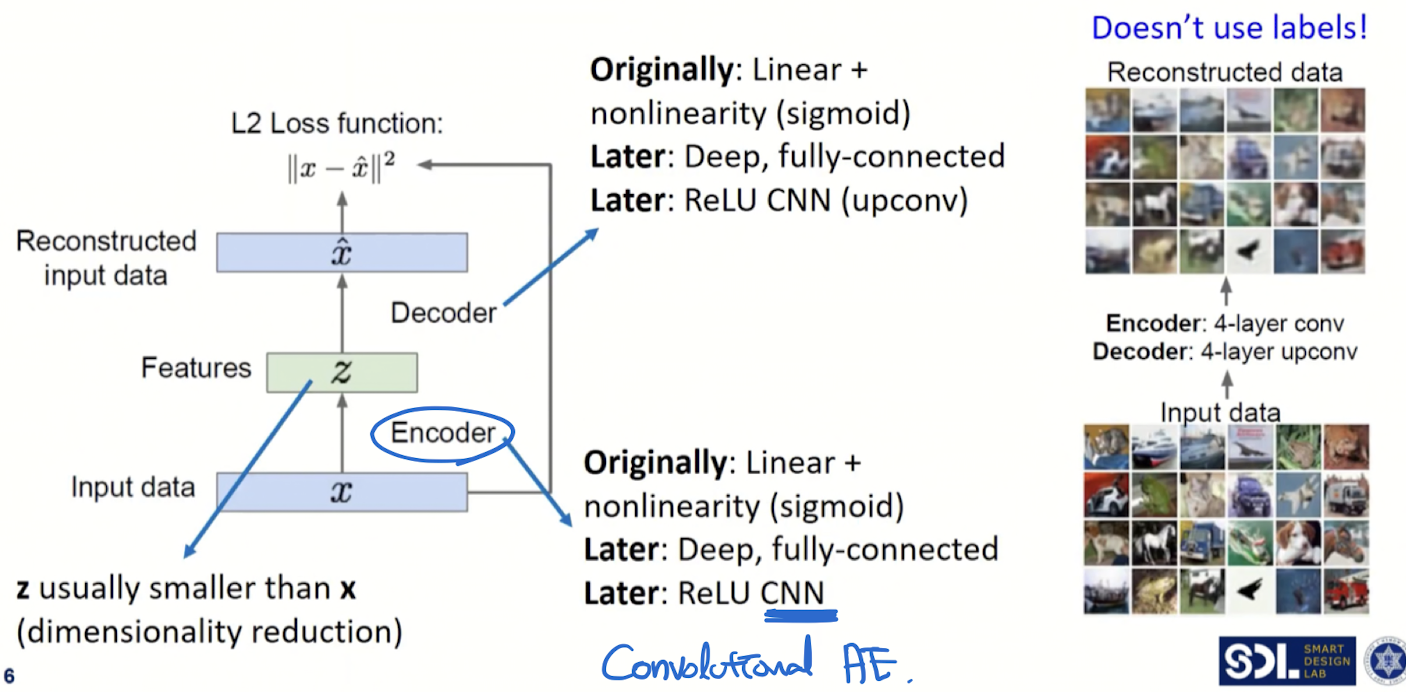
Loss
- original~reconstructed 차이를 최소화하는 loss
- 입출력의 pixel값이 동일하도록 하는 loss
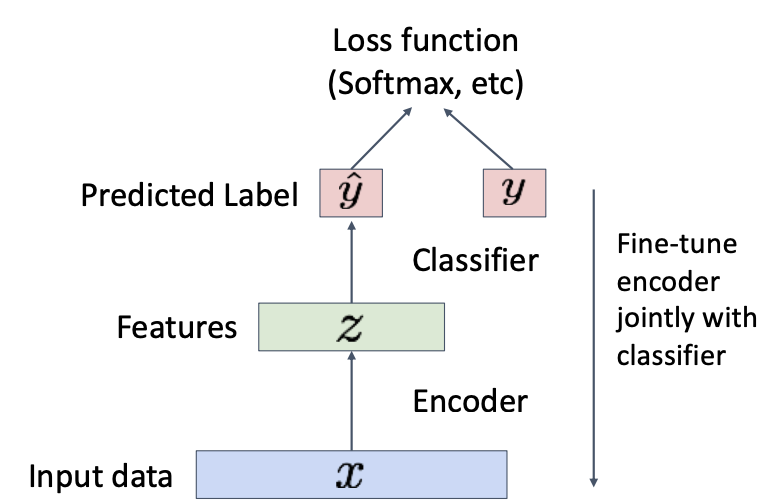
Application
Transfer learning
- After training, throw away decoder and use encoder for a downstream task
- 즉, Encoder만 떼어와서 + fine-tuning (classifier로 우리 데이터 소량 학습시킴)
Anomaly detection
- Normal data만 이용해서 AE 학습시키기
- test time
- Normal data → reconstruction error 낮음
학습을 많이 해서 좋은 latent 뽑아냄 → decoder는 복원 잘 할 수 있음
- Abnormal data → reconstruction error 높음
학습이 안된 input이라 latent 잘 못 뽑아냄 (Encoder 가 당황) → decoder도 이미지 복원 잘못함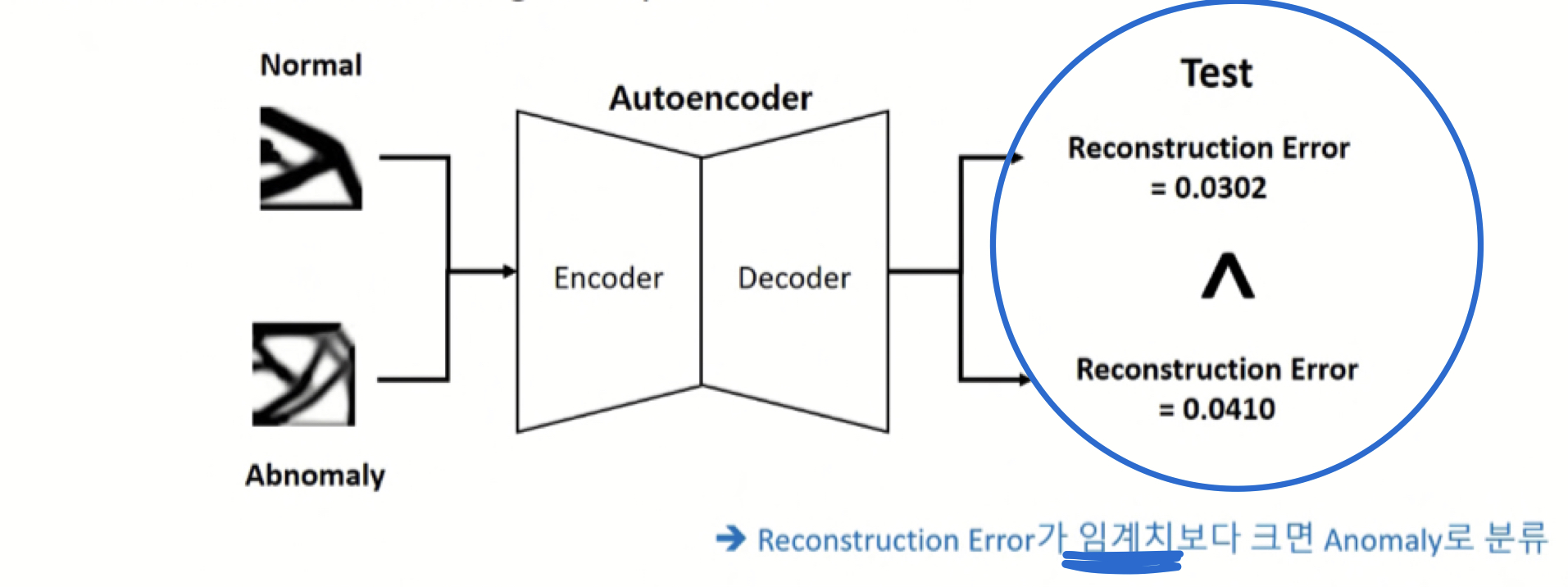
Can We Use AE to Image Generation?
👎
- Not probabilistic: No way to draw sample from p(z)
- We don't know the distribution of z
Variational Auto Encoder
Decoder를 활용하기 위해 개발됨
가정
- 모든 image는 latent vector로 부터 생성되었다. z→ x
- 우리 train data도 unseen latent z 로 부터 만들어졌을 것이다.
개요 및 특징
- Probabilistic spin on autoencoders → allows to
- Learn latent features z from raw data
- Sample from the model to generate new data
- Defines intractable density → optimize a lower bound
- (train time) Find p(z). z에 대한 prior distribution 작성
- (test time) p(z)로부터 sample z → [decoder estimates per-pixel distribution] → distribution over images. p(x)
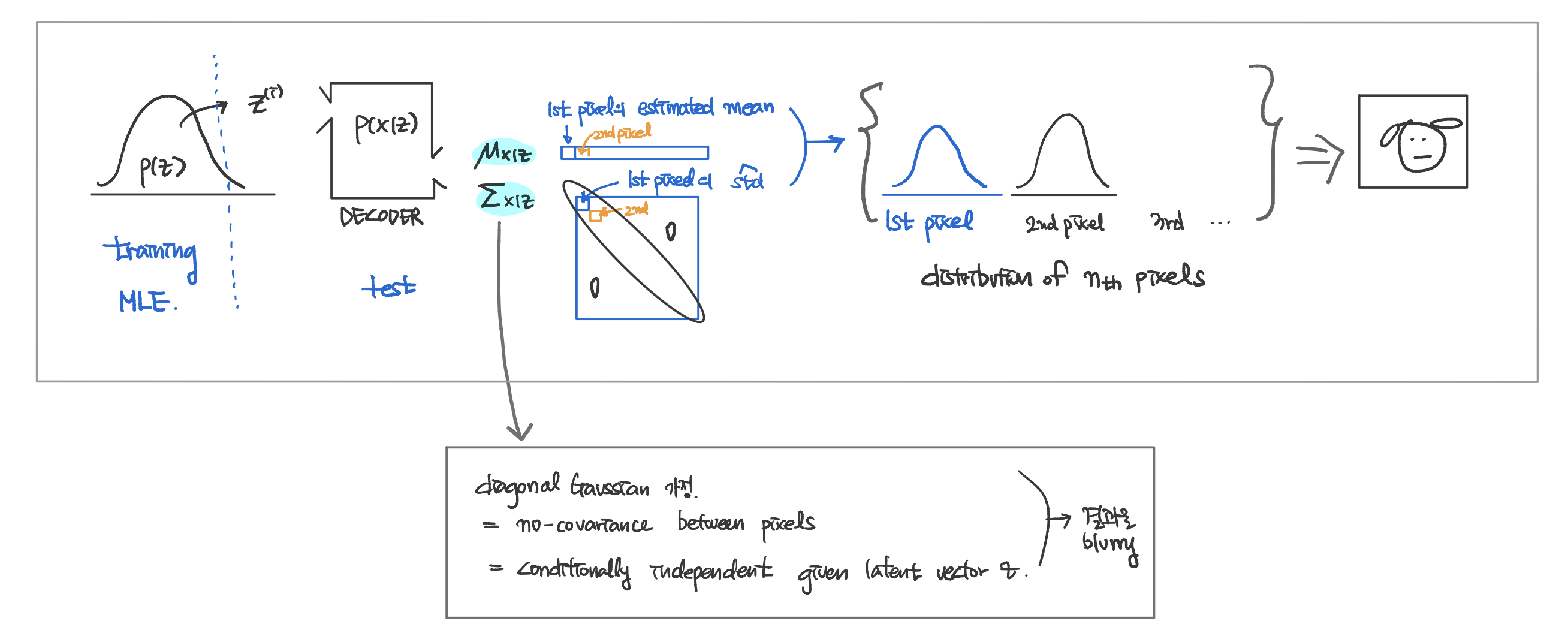
Training
Data Likelihood = p(x)
VAE의 목표 : p(x)를 알아내는 것임!
즉, decoder를 위해 개발됨.
(image, pixel distribution 알아낸 후 sampling == generating image)
liklihood p(x) 계산하기 위한 시도
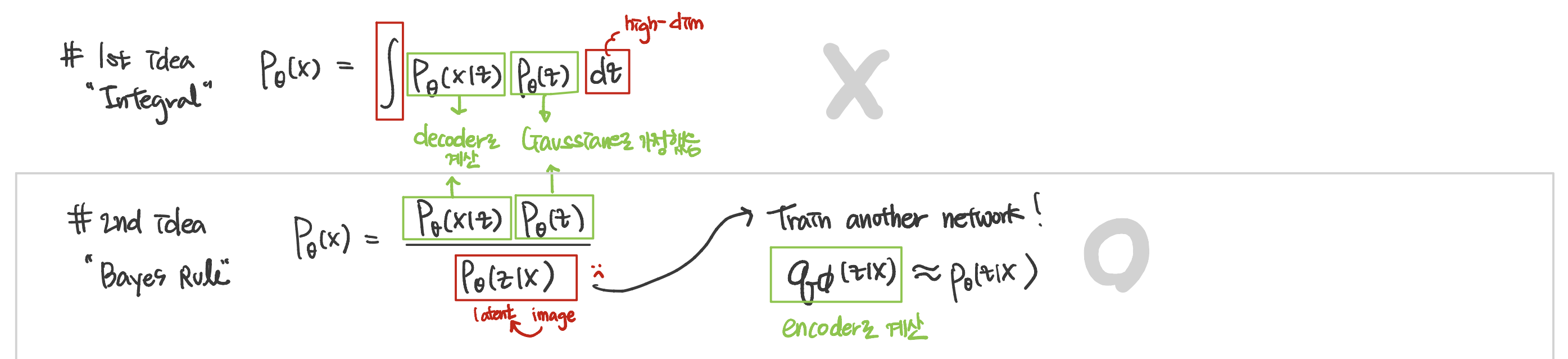

---
최종 학습 방식 + Loss
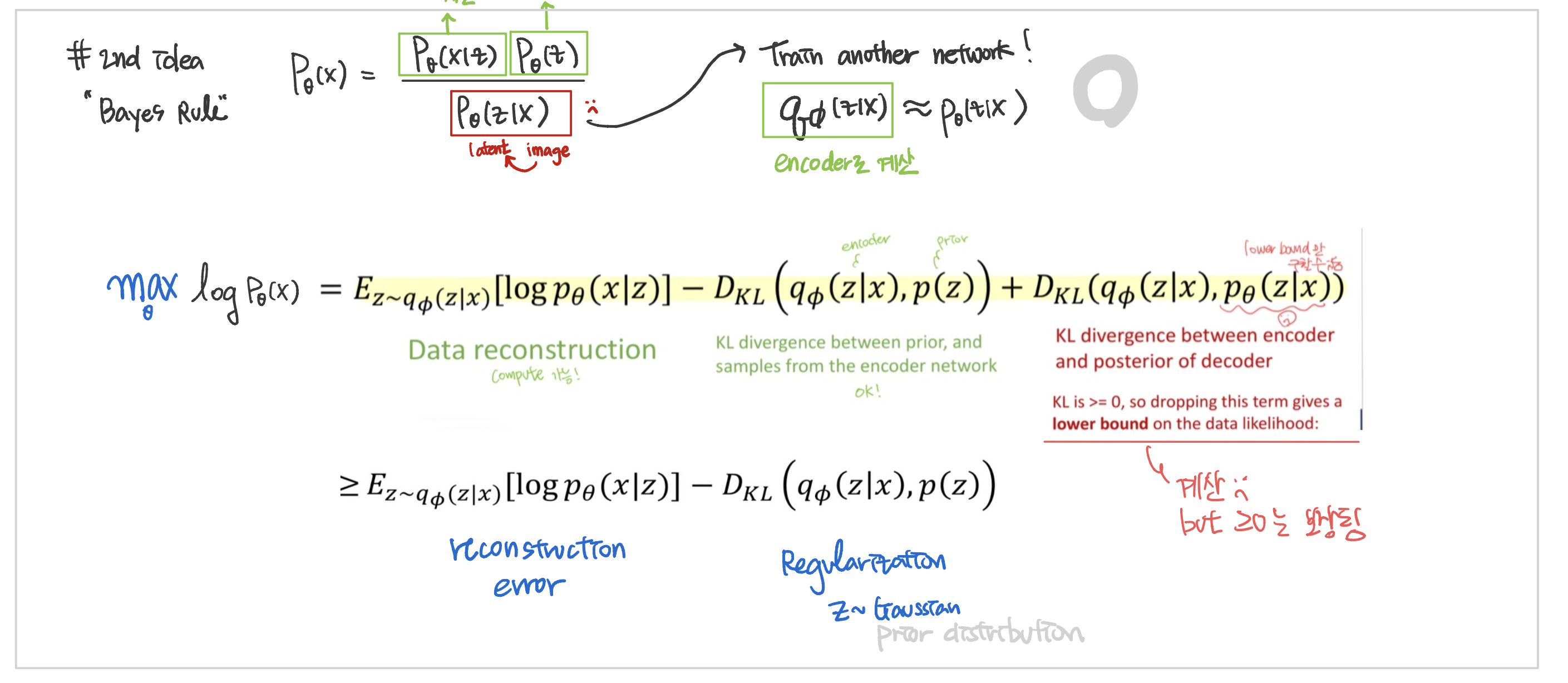
Loss
-
Reconstruction Error : input~output pixel 차이 최소화
- MSE : p ~ Gaussian
- Cross Entropy : p ~ bernoulli- Regularization : z 가 정규분포(prior)를 따르도록
- KL-Divergence로 계산
- Regularization : z 가 정규분포(prior)를 따르도록
요약
Autoencoder 와 VAE 는 목적이 반대 : AutoEncoder는 Encoder를 쓰기 위해 / VAE는 Decoder를 쓰기 위해 /