
🔎 데이터 조회
◽ 타이타닉 데이터셋
import seaborn as sns
df = sns.load_dataset('titanic')
df.head()
| 컬럼명 | 의미 | 인자 |
|---|---|---|
| survived | 생존여부 | 0 (사망) ; 1 (생존) ; |
| pclass | 좌석등급 (숫자) | 1 ; 2 ; 3 ; |
| sex | 성별 | male ; female ; |
| sibsp | 형제자매/배우자 인원 수 | 0 ~ 8 |
| parch | 부모/자식 인원 수 | 0 ~ 6 |
| fare | 요금 | 0 ~ 512.3292 |
| embarked | 탑승 항구 (알파벳) | S (Southampton) ; C (Cherbourg) ; Q (Queenstown) ; |
| class | 좌석등급 (영문) | First ; Second ; Third ; |
| who | 성별 | man ; woman ; |
| adult_male | 성인 남성 여부 | True ; False ; |
| deck | 선실 고유번호 맨 앞자리 글자 | A ; B ; C ; D ; E ; F ; G ; |
| embark_town | 탑승 항구 (전체이름) | Southampton ; Cherbourg ; Queenstown |
| alive | 생존여부 (영문) | no (사망) ; yes (생존) ; |
| alone | 혼자인지 여부 | True ; False ; |
◽ null 확인
모든 값에 대해 null 여부에 대한 데이터프레임 반환
df.isnull()| survived | pclass | ... | alive | alone | |
|---|---|---|---|---|---|
| 0 | False | False | ... | False | False |
| ... | ... | ... | ... | ... | ... |
| 890 | False | False | ... | False | False |
컬럼별 null 개수 확인
df.isnull().sum().sort_values(ascending=False)deck 688
age 177
embarked 2
embark_town 2
survived 0
pclass 0
sex 0
sibsp 0
parch 0
fare 0
class 0
who 0
adult_male 0
alive 0
alone 0
dtype: int64
------------------------------
869전체 데이터프레임에서 null을 갖는 행 개수 확인
df.isnull().sum().sum()869◽ 데이터프레임에 대한 정보 확인
-
df.head(n=5): 데이터프레임의 첫n줄 확인 -
df.tail(n=5): 데이터프레임의 마지막n줄 확인 -
df.info(): 총 데이터 수, 컬럼별 데이터 타입, 컬럼별 null이 아닌 데이터 수, 메모리 사용량<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 survived 891 non-null int64 1 pclass 891 non-null int64 2 sex 891 non-null object 3 age 714 non-null float64 4 sibsp 891 non-null int64 5 parch 891 non-null int64 6 fare 891 non-null float64 7 embarked 889 non-null object 8 class 891 non-null category 9 who 891 non-null object 10 adult_male 891 non-null bool 11 deck 203 non-null category 12 embark_town 889 non-null object 13 alive 891 non-null object 14 alone 891 non-null bool dtypes: bool(2), category(2), float64(2), int64(4), object(5) memory usage: 80.7+ KB -
df.describe(): 컬럼별 데이터 값의 n-percentile 분포도, 평균값, 최댓값, 최솟값survived pclass age sibsp parch fare count 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000 mean 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208 std 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429 min 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000 25% 0.000000 2.000000 20.125000 0.000000 0.000000 7.910400 50% 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200 75% 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000 max 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200
include='all': 수치형, 범주형 데이터 모두에 대한 통계include='np.number': 수치형 데이터에 대한 통계exclude='np.number': 수치형 데이터를 제외한 데이터에 대한 통계
📊 통계
** 인자가 0이면 열 기준, 1이면 행 기준
df.count(): 행/열의 데이터 개수 확인df.sum(): 행/열의 합계 확인df.mean(): 행/열의 평균값 확인df.median(): 행/열의 중앙값 확인df.min(): 행/열의 최솟값 확인df.max(): 행/열의 최댓값 확인df.abs(): 행/열의 절댓값 확인df.std(): 행/열의 표준편차 확인
** 인자가 0이면 빈도 수, 1이면 비율
df.value_counts(sort=True, ascending=False)
** 고유한 값
df.unique(): 고유한 값들 반환df.nunique(): 고유한 값들의 개수 반환
🎰 Pandas에서의 함수 처리 방법
| 메서드 | 대상 | 반환 데이터 타입 |
|---|---|---|
| map | 시리즈 (값별) | 시리즈 |
| apply | 데이터프레임 (열/행별) | 시리즈 |
| applymap | 데이터프레임 (값별) | 데이터프레임 |
◽ map() 예제
딕셔너리 지정
# 초기 시리즈
sex = ['male', 'female', 'male']
series = pd.Series(data=sex)
series0 male
1 female
2 male
dtype: object# 시리즈에 딕셔너리 매핑
to_num = {'male' : 0, 'female': 1}
series.map(to_num)0 0
1 1
2 0
dtype: int64사용자 정의 함수 지정
# 적용할 함수 정의
def clean_data(data):
return data.replace('!', '').lower()
# 초기 시리즈
fruit = ['!APPLE!', '!ORANGE!', '!STRAWBERRY!']
series = pd.Series(data=fruit)
series0 !APPLE!
1 !ORANGE!
2 !STRAWBERRY!
dtype: object# 시리즈의 각 값에 함수 적용
series.map(lambda x: clean_data(x))0 apple
1 orange
2 strawberry
dtype: object◽ apply() 예제
# 초기 데이터프레임
df = pd.DataFrame({
'apple': [10, 10],
'orange': [5, 15],
'strawberry': [20, 25]
}, index=['girl_likes', 'boy_likes'])
df| apple | orange | strawberry | |
|---|---|---|---|
| girl_likes | 10 | 5 | 20 |
| boy_likes | 10 | 15 | 25 |
시리즈에 적용 (map과 동일)
# 열 자체에 냅다 함수 적용하는 느낌
df['apple'].apply(lambda x: x + 5)girl_likes 15
boy_likes 15
Name: apple, dtype: int64집계함수 적용
# 열의 값들을 냅다 더해버리기
print(df.apply(lambda x: x.sum()), axis=0)
# 행의 값들을 냅다 더해버리기
print(df.apply(lambda x: x.sum(), axis=1))apple 20
orange 20
strawberry 45
dtype: int64
girl_likes 35
boy_likes 50
dtype: int64◽ applymap() 예제
# 초기 데이터프레임
df = pd.DataFrame({
'apple': [10, 10],
'orange': [5, 15],
'strawberry': [20, 25]
}, index=['girl_likes', 'boy_likes'])
df| apple | orange | strawberry | |
|---|---|---|---|
| girl_likes | 10 | 5 | 20 |
| boy_likes | 10 | 15 | 25 |
# map 동작을 원래 데이터프레임에 inplace 하는 느낌
df.applymap(lambda x: x + 5)| apple | orange | strawberry | |
|---|---|---|---|
| girl_likes | 15 | 5 | 20 |
| boy_likes | 15 | 15 | 25 |
✨ 고급 데이터 분석 함수
# 사용할 데이터
full_df = sns.load_dataset('titanic')
select_cols = ['age', 'sex', 'pclass', 'fare', 'survived']
df = full_df[select_cols]
df.head()| age | sex | pclass | fare | survived | |
|---|---|---|---|---|---|
| 0 | 22.0 | male | 3 | 7.2500 | 0 |
| 1 | 38.0 | female | 1 | 71.2833 | 1 |
| 2 | 26.0 | female | 3 | 7.9250 | 1 |
| 3 | 35.0 | female | 1 | 53.1000 | 1 |
| 4 | 35.0 | male | 3 | 8.0500 | 0 |
◽ pivot_table()
- pivot table : 데이터를 요약하는 통계표
- 데이터를 원하는 형태로 집계
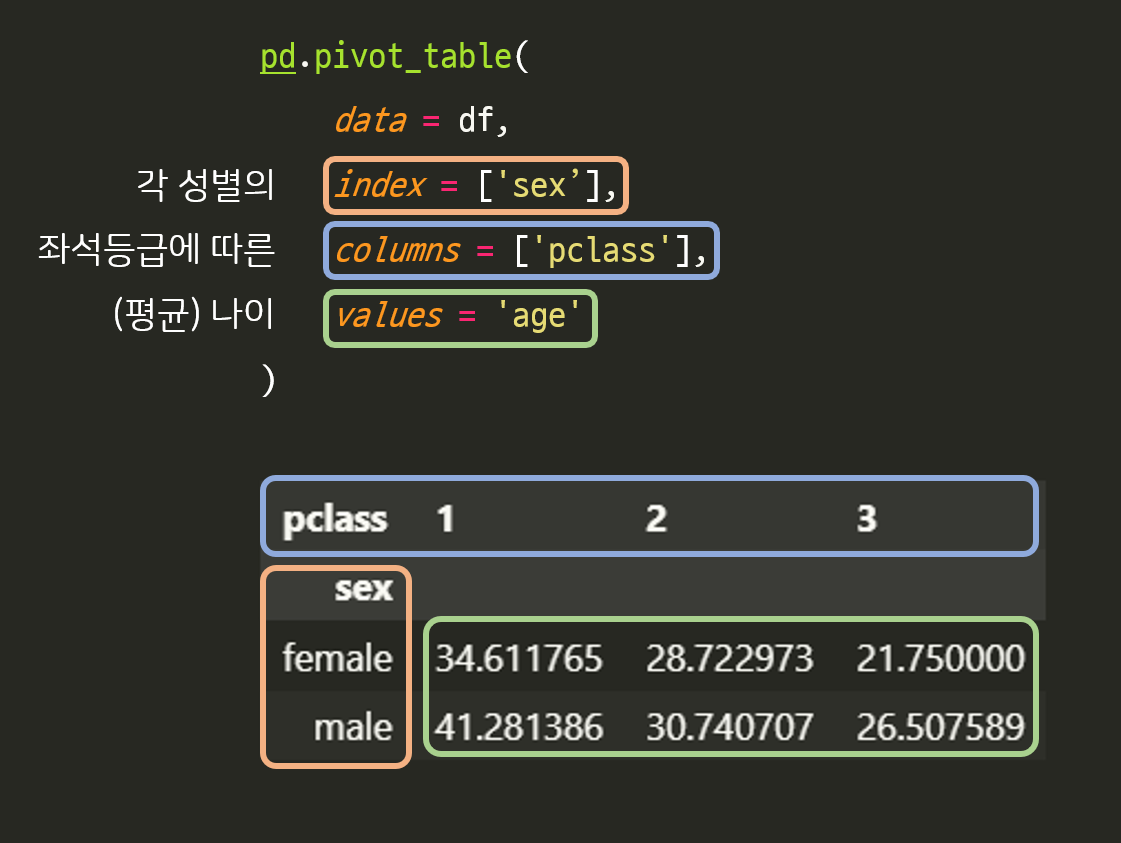
ex 1 ) 좌석등급에 따른 각 성별의 평균 나이
pd.pivot_table(
data = df,
index = ['sex'],
columns = ['pclass'],
values = 'age'
)
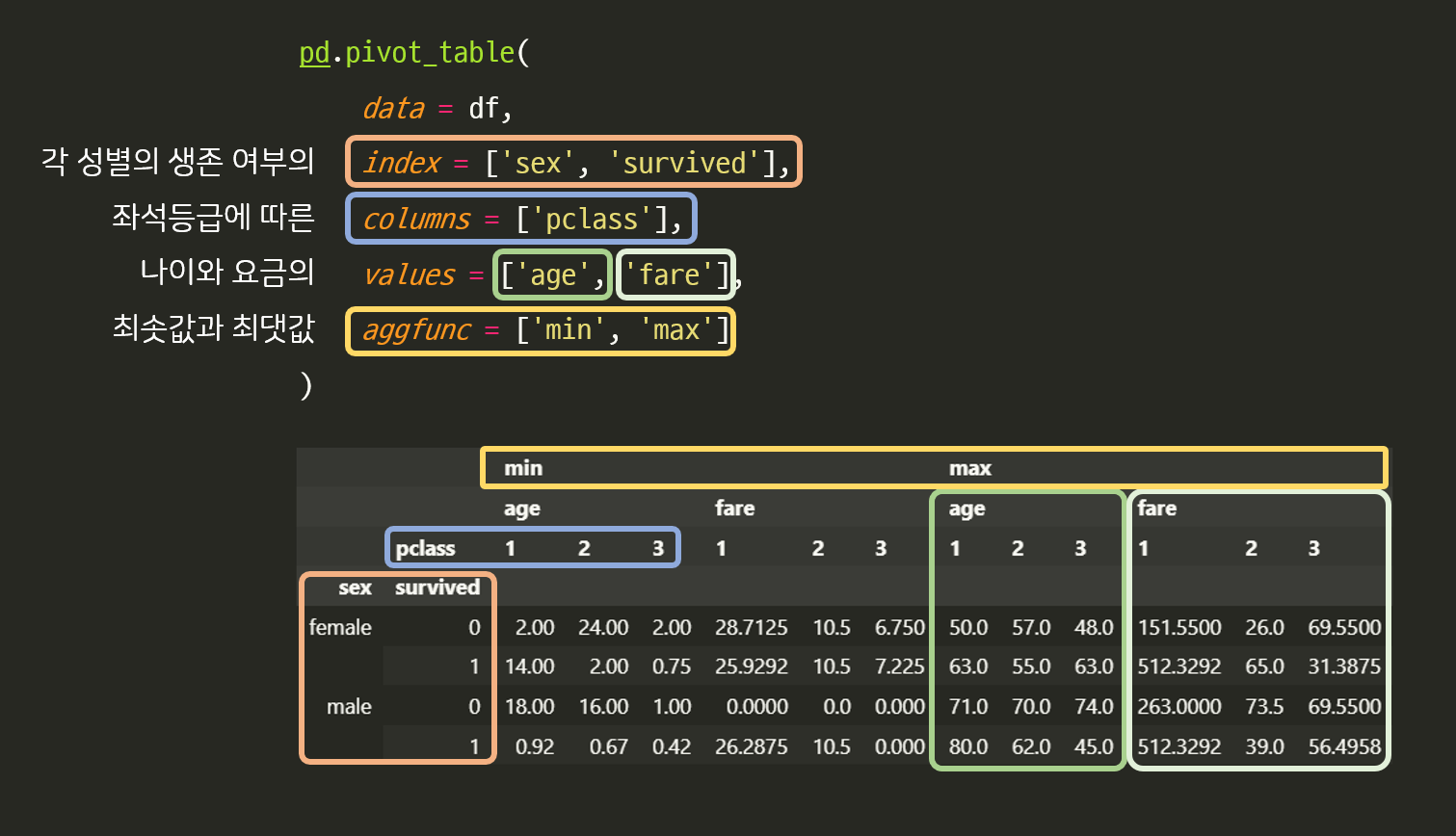
ex 2 ) 좌석등급에 따른 각 성별의 생존 여부의 나이와 요금의 최솟값과 최댓값 ( 뇌절 )
pd.pivot_table(
data = df,
index = ['sex', 'survived'],
columns = ['pclass'],
values = ['age', 'fare'],
aggfunc = ['min', 'max']
)
◽ groupby()
- 데이터를 그룹별로 분할
- 반환되는 객체의 데이터 타입은
DataFrameGroupBy- 이는 [키, 데이터프레임]을 튜플로 관리하는 객체
- 반복문을 통해 접근 가능
그룹화된 데이터프레임에 접근
groups = df.groupby(['sex', 'survived'])
for key, group in groups:
print('* key :', key)
print('* count :', len(group))
print(group.head(3))
print('-' * 50)* key : ('female', 0)
* count : 81
age sex pclass fare survived
14 14.0 female 3 7.8542 0
18 31.0 female 3 18.0000 0
24 8.0 female 3 21.0750 0
--------------------------------------------------
* key : ('female', 1)
* count : 233
age sex pclass fare survived
1 38.0 female 1 71.2833 1
2 26.0 female 3 7.9250 1
3 35.0 female 1 53.1000 1
--------------------------------------------------
* key : ('male', 0)
* count : 468
age sex pclass fare survived
0 22.0 male 3 7.2500 0
4 35.0 male 3 8.0500 0
5 NaN male 3 8.4583 0
--------------------------------------------------
* key : ('male', 1)
* count : 109
age sex pclass fare survived
17 NaN male 2 13.0 1
21 34.0 male 2 13.0 1
23 28.0 male 1 35.5 1
--------------------------------------------------그룹별 통계량 확인
groups.mean()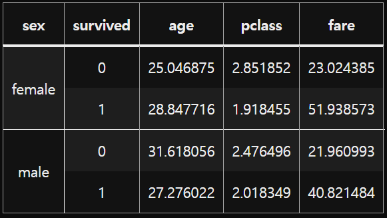
특정 그룹 가져오기
# 생존한 여성 그룹
group_female = groups.get_group(('female', 1))
group_female.head()| age | sex | pclass | fare | survived | |
|---|---|---|---|---|---|
| 1 | 38.0 | female | 1 | 71.2833 | 1 |
| 2 | 26.0 | female | 3 | 7.9250 | 1 |
| 3 | 35.0 | female | 1 | 53.1000 | 1 |
| 8 | 27.0 | female | 3 | 11.1333 | 1 |
| 9 | 14.0 | female | 2 | 30.0708 | 1 |
◽ agg()
- 다중 집계 작업
apply함수와 유사- 하지만 여러 함수를 한번에 적용할 수 있다는 점에서 차이 있음
groups = df.groupby('sex')기본 사용
df['fare'].agg(['sum', 'mean'])sum 28693.949300
mean 32.204208
Name: fare, dtype: float64groupby와 함께 사용
groups[['age', 'fare']].agg(['min', 'max'])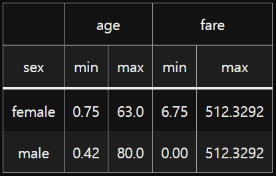
딕셔너리를 이용하여 특징에 따라 집계함수 지정
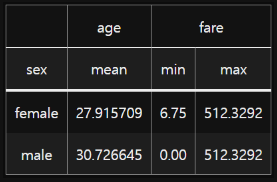
groups.agg({
'age': 'mean',
'fare': ['min', 'max']
})
◽ transform()
- 그룹별로 매핑함수 적용
- 결과를 그룹별로 묶어서 보여주지는 않음
groups = df.groupby('sex')
groups['age'].transform('mean')
# [male: 30.726645, female: 27.915709] 형식으로 보여주지 않고
# 그냥 각 값에 대해 함수의 결과값을 알려줌
# 니 알아서 잘봐라 느낌0 30.726645
1 27.915709
2 27.915709
3 27.915709
4 30.726645◽ filter()
DataFrame에서의 filter
df.filter(
items = [추출할 열의 이름],
like = [해당 문자열을 포함하는 열],
regex = [해당 정규표현식을 만족하는 열],
axis = [0: 행 추출, 1: 열 추출]
)DataFrameGroupBy에서의 filter
- 뇌피셜
- DataFrameGroupBy에서 람다함수 사용 시 값 하나하나 또는 행/열 하나하나를 적용하지 않고 데이터프레임 자체를 적용하는 듯
- 한마디로
lambda x: x에 대한 함수에서x는 데이터프레임이 되는 것
groups = df.groupby('sex')
groups[['sex', 'age']].filter(lambda x: len(x) < 400)| sex | age | |
|---|---|---|
| 1 | female | 38.0 |
| 2 | female | 26.0 |
| 3 | female | 35.0 |
| 8 | female | 27.0 |
| 9 | female | 14.0 |
- (성별로) 쪼개어진 데이터프레임 중에 데이터 수가 400개 미만인 데이터프레임만 가져오는 것
- 행 수가 400개 미만인
female만 출력됨

울레일라