CS231N, EECS 498-007 / 598-005에서 나타나는 개념을 정리하기 위하여 복기용도로 작성하였습니다.
간단히 정리한 내용을 살펴보며 모르는 부분이 있을 때 찾아보는 용도로 보시면 좋을 것 같습니다.
학습 후기
뺄 부분 없이 중요한 부분만 존재하여 분량이 점점 많아지네요..
learning rate
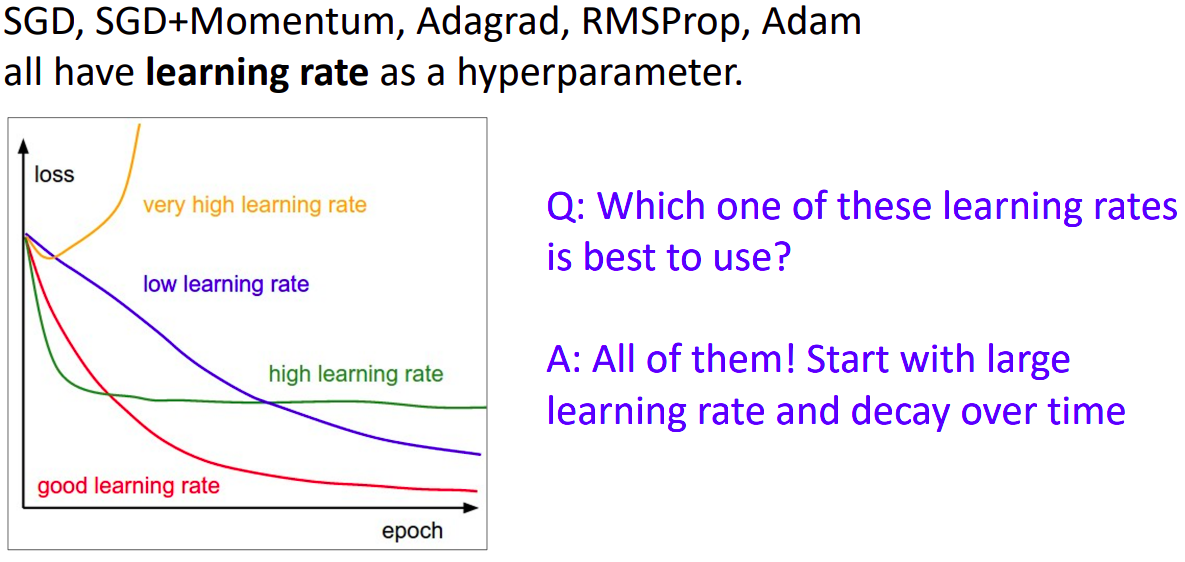
- 초기에는 초록색 lr을 선택하여 로스값이 일정하게 수렴하는 곳까지 학습을 진행한다.
- 이후 점점 lr을 줄여가며 파란색의 lr까지 학습을 진행해본다.
- 이러한 과정을 learning rate schedule이라고 한다.
learning rate: step
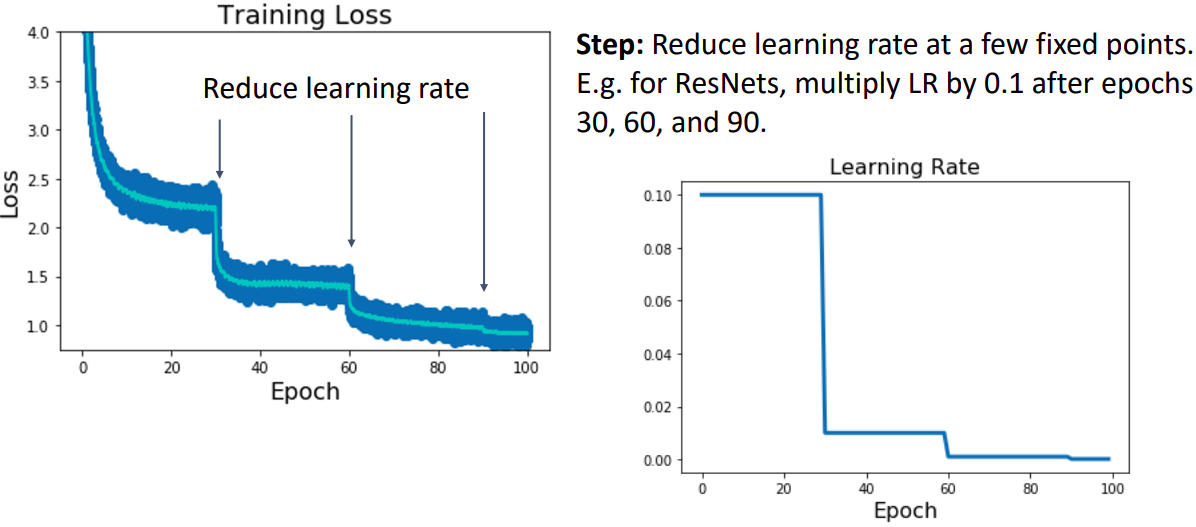
- 상대적으로 큰 lr으로 학습을 시작하며 특정 epoch(30)마다 lr에 0.1을 곱하여(step) 학습을 진행한다.
- 단점: 상당히 많은 hyperparameter을 설정해야 한다. 학습을 진행하면서 loss가 plateau가 되면 step하는것이 가장 이상적이다.
learning rate: Cosine
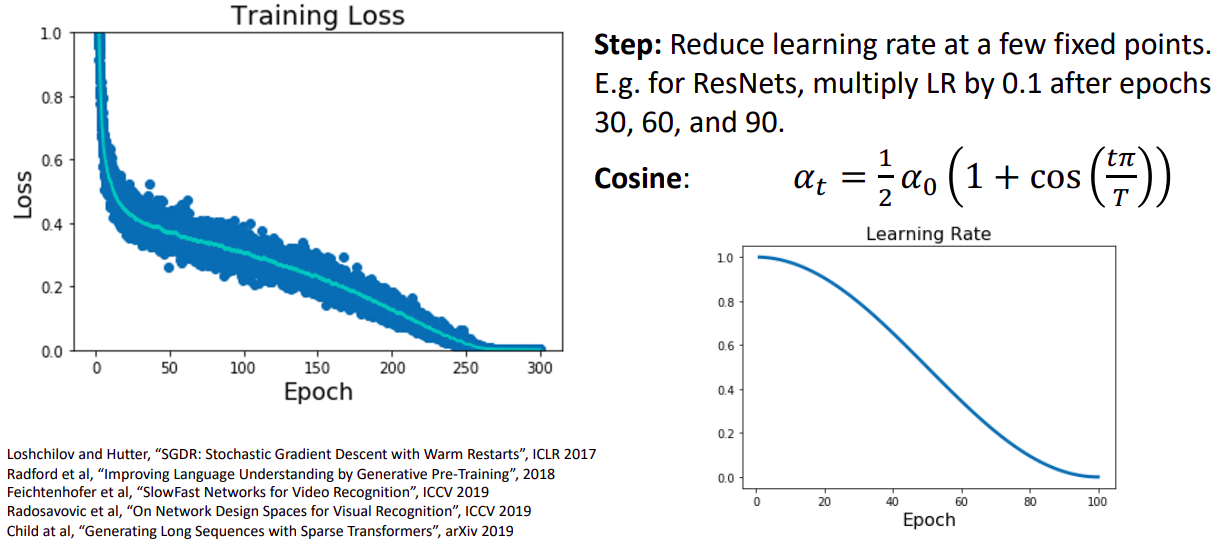
- 특정 epoch에 해당하는 lr를 갖는 코사인 함수를 지정한다.
- 단지 두가지 hyperparameter만 초기 lr인 와 epoch인 T만 가진다는 점에서 step방식보다 좋다. 따라서 조정하기에 더 쉽다.
- 특이점은 새로운 hyperparameter를 제공해주지 않는다는 점이다. 초기 설정한 hyperparameter는 단지 추가적인 해석이나 의미만 제공해준다.
- 일반적으로 T값은 오래둘수록 좋기 때문에 초기 lr 설정만 조정하면 된다.
- 보통 computer vision 영역에서 사용된다.
Learning Rate Decay: Linear
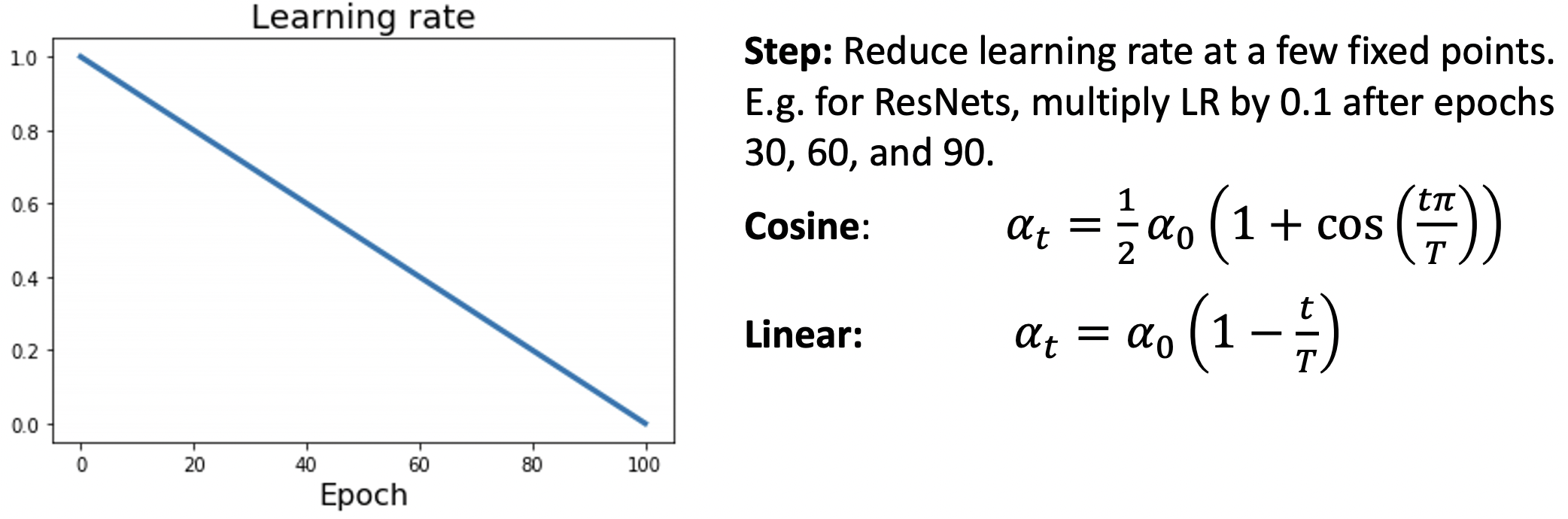
- 자연어 처리 영역에서 보통 사용된다.
Learning Rate Decay: Inverse Sqrt
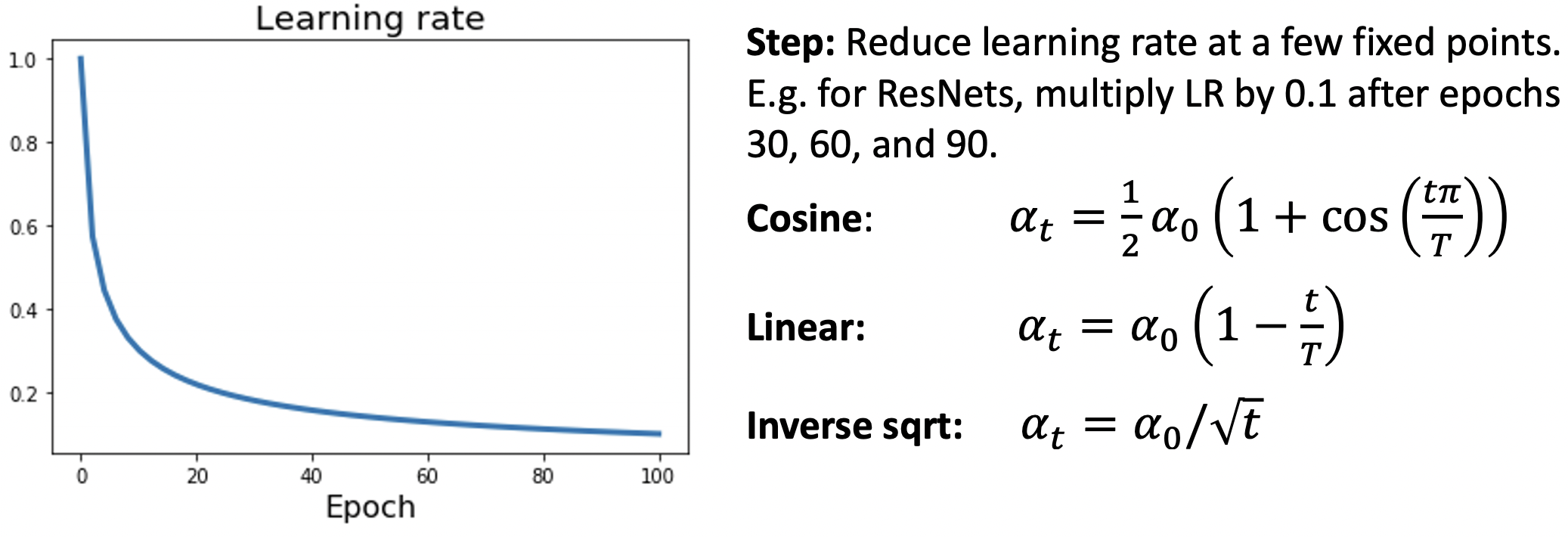
- 초기 높은 lr에 머무는 영역이 상대적으로 적어 잘 사용되지 않는다.
Learning Rate Decay: Constant

- 가장 일반적이며 보편적으로 사용되며 다른 lr보다 우선적으로 적용해보기를 권하고 있다.
- 모델의 동작여부에 lr선택이 영향을 주지는 않음으로 모델 생성후 테스트 마지막단계에서 조정하기를 권하고 있다.
Early stopping
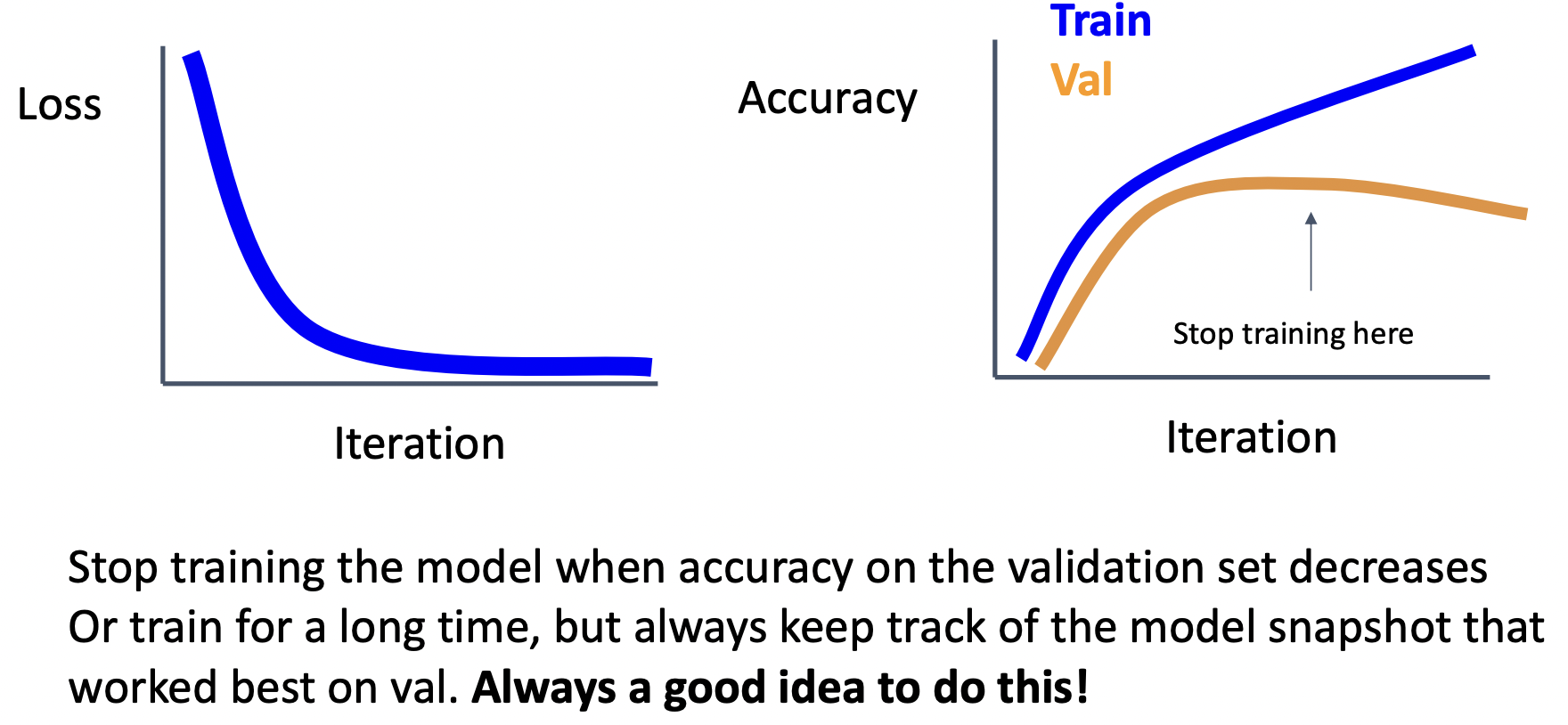
- 모델의 chepoint가 가장 높은 validation accuracy에 위치하기를 원하기 때문에 이 기능은 항상 적용해야하는 부분이다.
Choosing Hyperparameters
Choosing Hyperparameters: Grid Search Search
- 각 파라미터에 몇 가지 값을 설정해두고(로그함수에 선형적으로 설정), 모든 경우의 수를 학습하는 방식이다.
- GPU자원 소모가 굉장히 크다. (모든 경우 계산)
Choosing Hyperparameters: Random Search
- 각 파라미터의 범위를 선택하고 범위(로그함수에 선형적으로 설정)안에서 랜덤하게 선택하여 학습하는 방식이다.
Grid Search VS Random
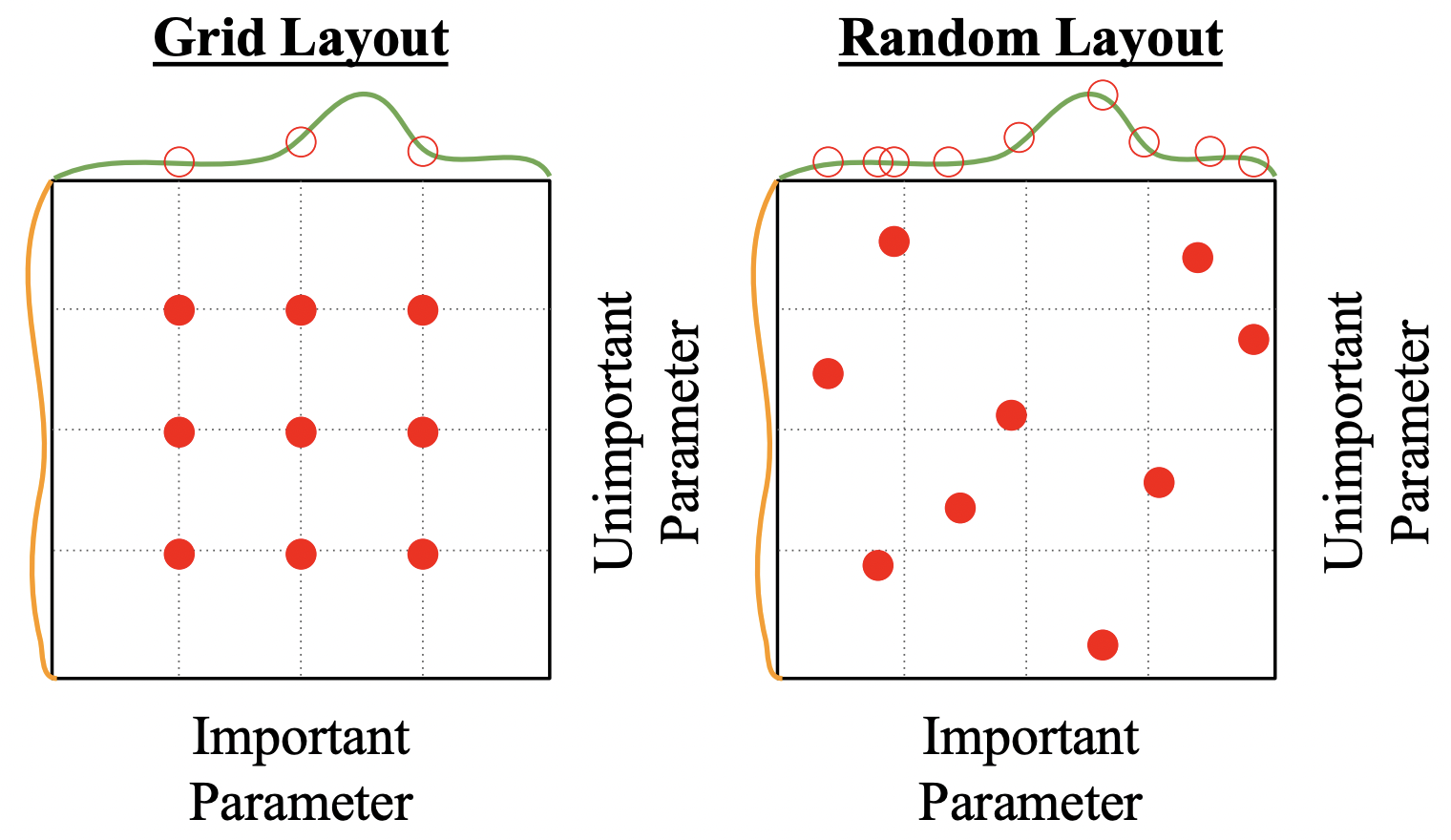
- 모델 성능에 중요한 파라미터(초록)와 그렇지 않은 파라미터(주황)가 존재하는데 grid search 방식은 좋은 성능을 갖는 파라미터가 무엇인지 판단에 어려움이 있다(초록색 그래프의 빨간색점이 균등하게 분포).
- 결과가 제공하는 정보가 제한적일 수 밖에 없다. 서로 같은 9번의 실험을 했지만 초록색 그래프의 파라미터에 대하여 3번 밖에 체크하지 못 했지만, 랜덤방식은 9번이나 확인 할 수 있다.
Choosing Hyperparameters: with out GPU
1. Check initial loss
- 로스함수의 구조를 파악하고 weight decay를 적용하지 않은 상태에서 로스값이 무엇인지 확인한다.(예: C개의 클래스인 softmax일 때 log(C))
2. Overfit a small sample
- 매우 작은 5~10의 미니배치를 구성하여 학습정확도가 100%가 되는지 체크해 본다.
- regularization을 적용하지 않고 architecture, learning rate, weight initialization를 조작해 본다.
- optimization과정에 버그가 있는지 체크하는 과정이다. 이 과정중 오버핏이 되지 않는다면 큰 데이터에서도 학습이 되지 않는다.
- 로스가 줄지 않는다면 lr이 너무 낮거나 초기화가 잘 못된 것이다.
- 로스가 넘치거나 NAN이 된다면 lr이 너무 높거나 초기화가 잘 못된 것이다.
3. Find LR that makes loss go down
- 전체 데이터 셋으로 weight decay를 켠 상태에서 100 iteration 이내에 로스가 급격하게 줄어드는 lr을 찾아낸다.
- 시도하기 좋은 lr: 1e-1, 1e-2, 1e-3, 1e-4
4. Coarse grid, train for ~1-5 epochs
- lr와 weight decay를 매우 적은 갯수로 설정하고 1~5 epoch사이로 테스트 해본다.
- 시도하기 좋은 weight decay: 1e-4, 1e-5, 0
5. Refine grid, train longer
- 4에서 선택한 모델으로 10~20 epoch내외로 lr decay 없이 길게 학습해본다.
6. Look at learning curves
- 학습 커브를 보면서 hyperparameter을 어떻게 해야할지 선택한다.
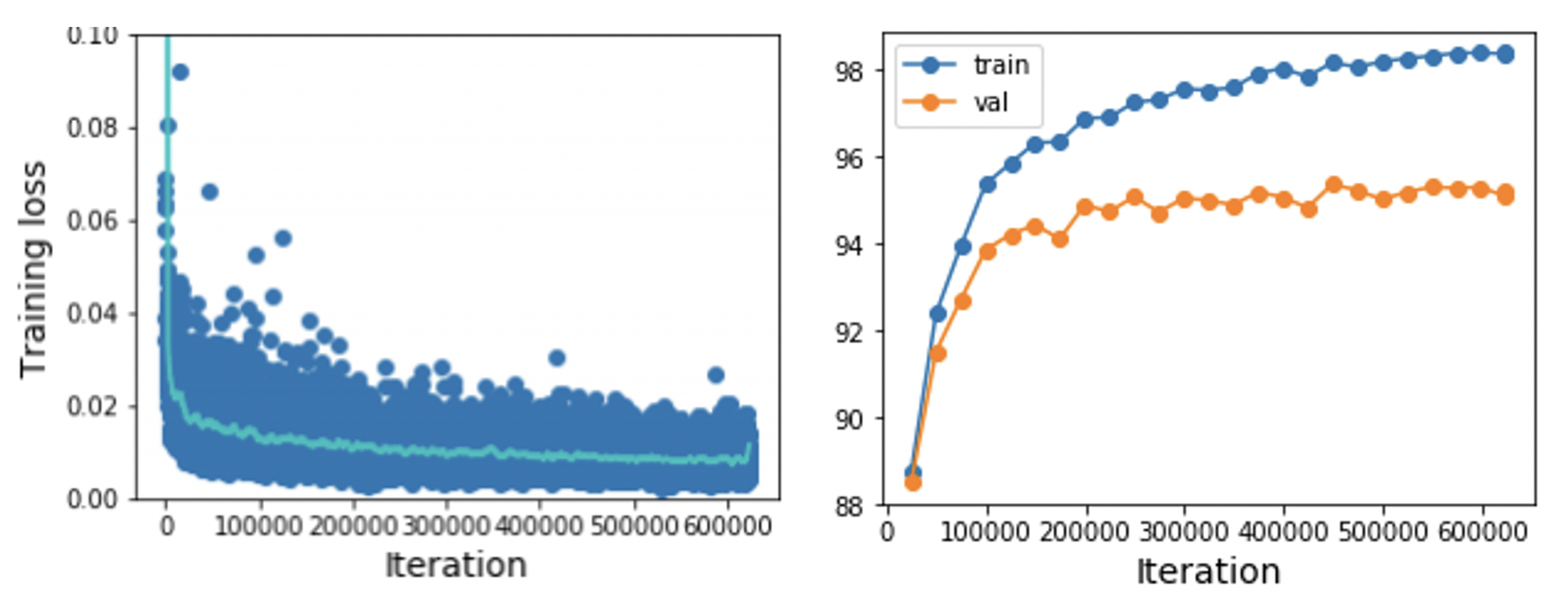
- 로스 값은 noise가 심해서 scatter plot과 moving average plot을 사용한다.
case1: 학습초기 로스가 줄지 않은 경우 => 초기화 잘 못됨
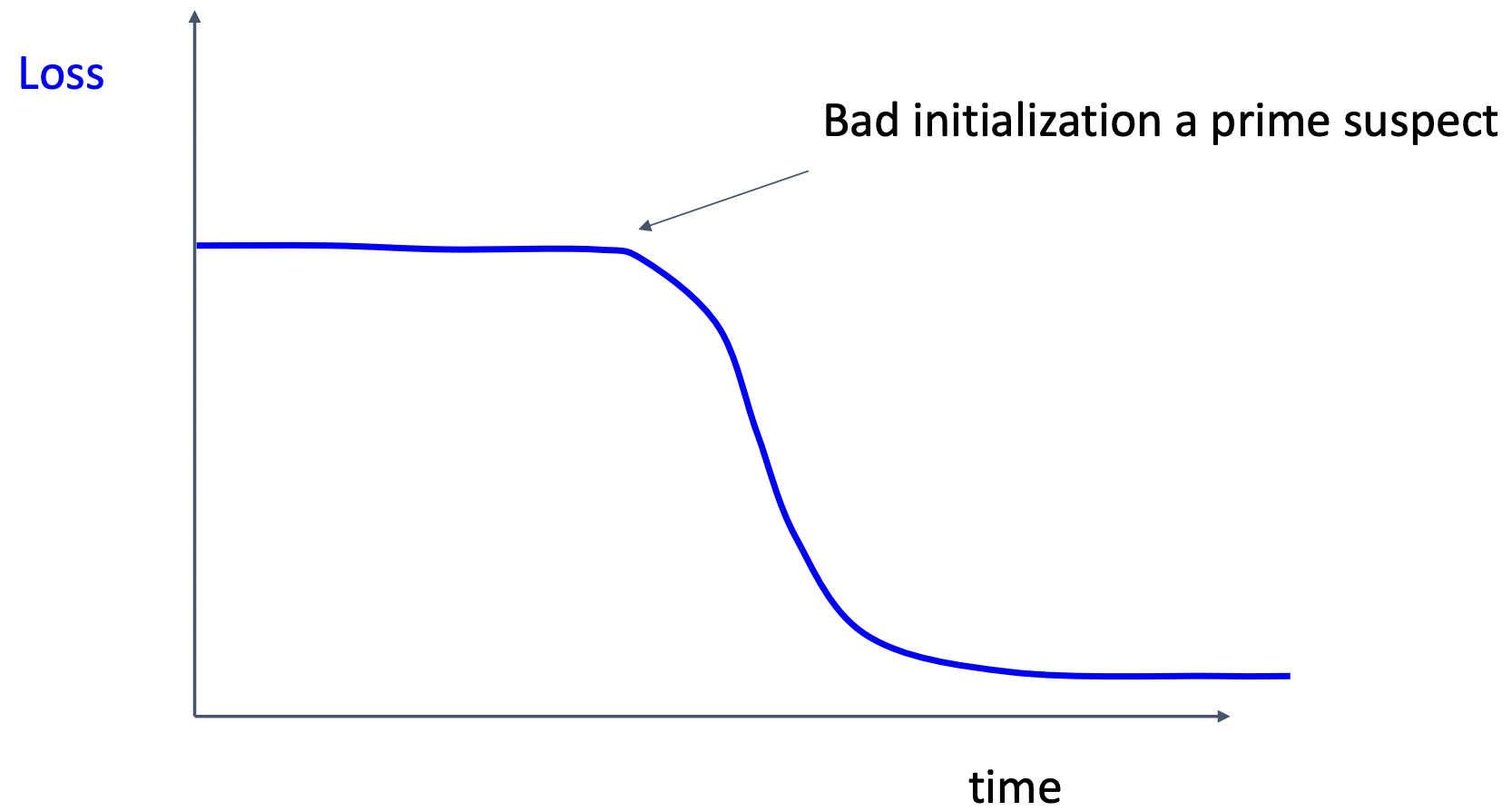
case2: 로스가 정체 될 때 => lr decay 사용 혹은 초기 lr 줄이기
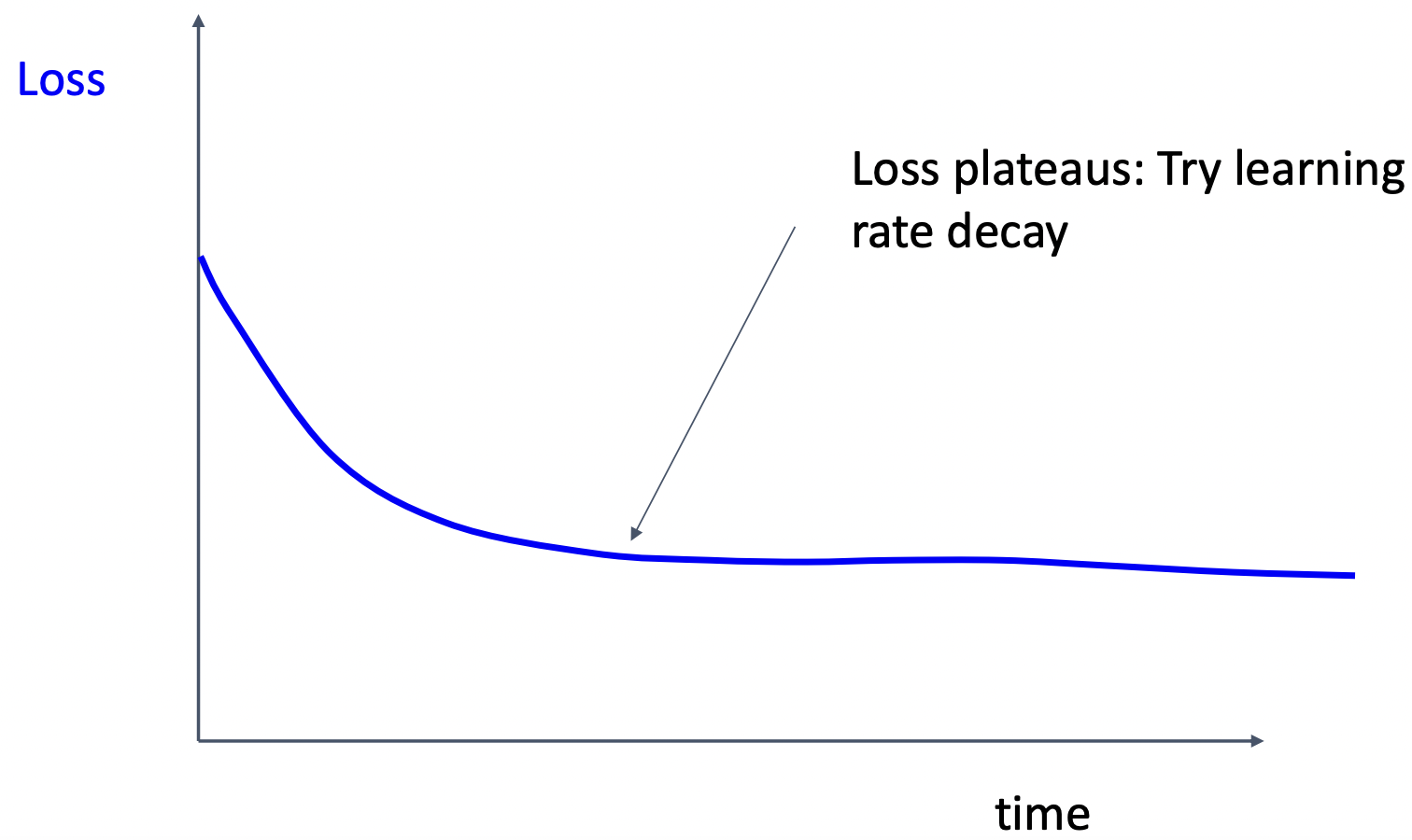
case3: 로스가 줄어드는 도중 step decay사용하여 정체 => decay가 너무 빨리 적용됨
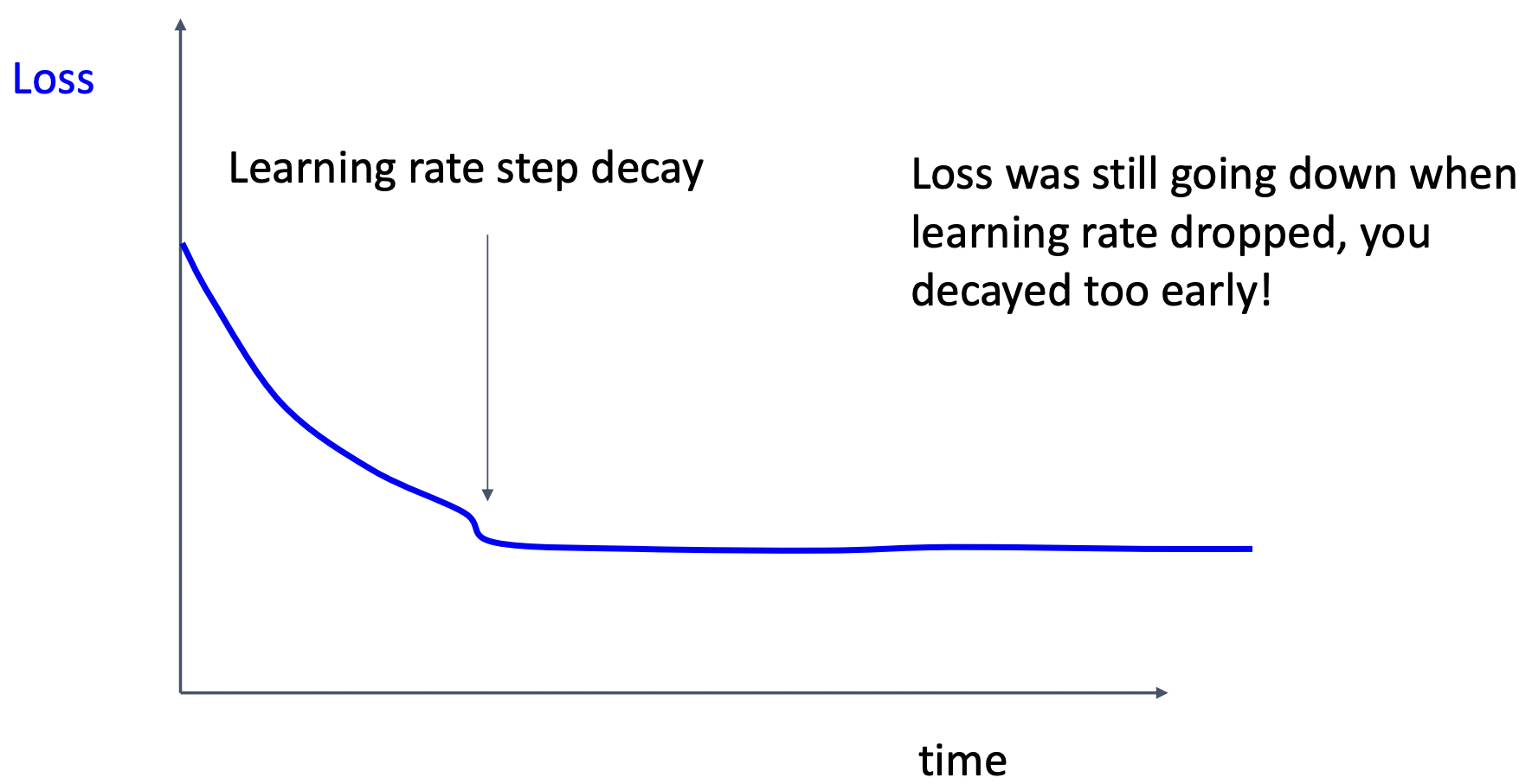
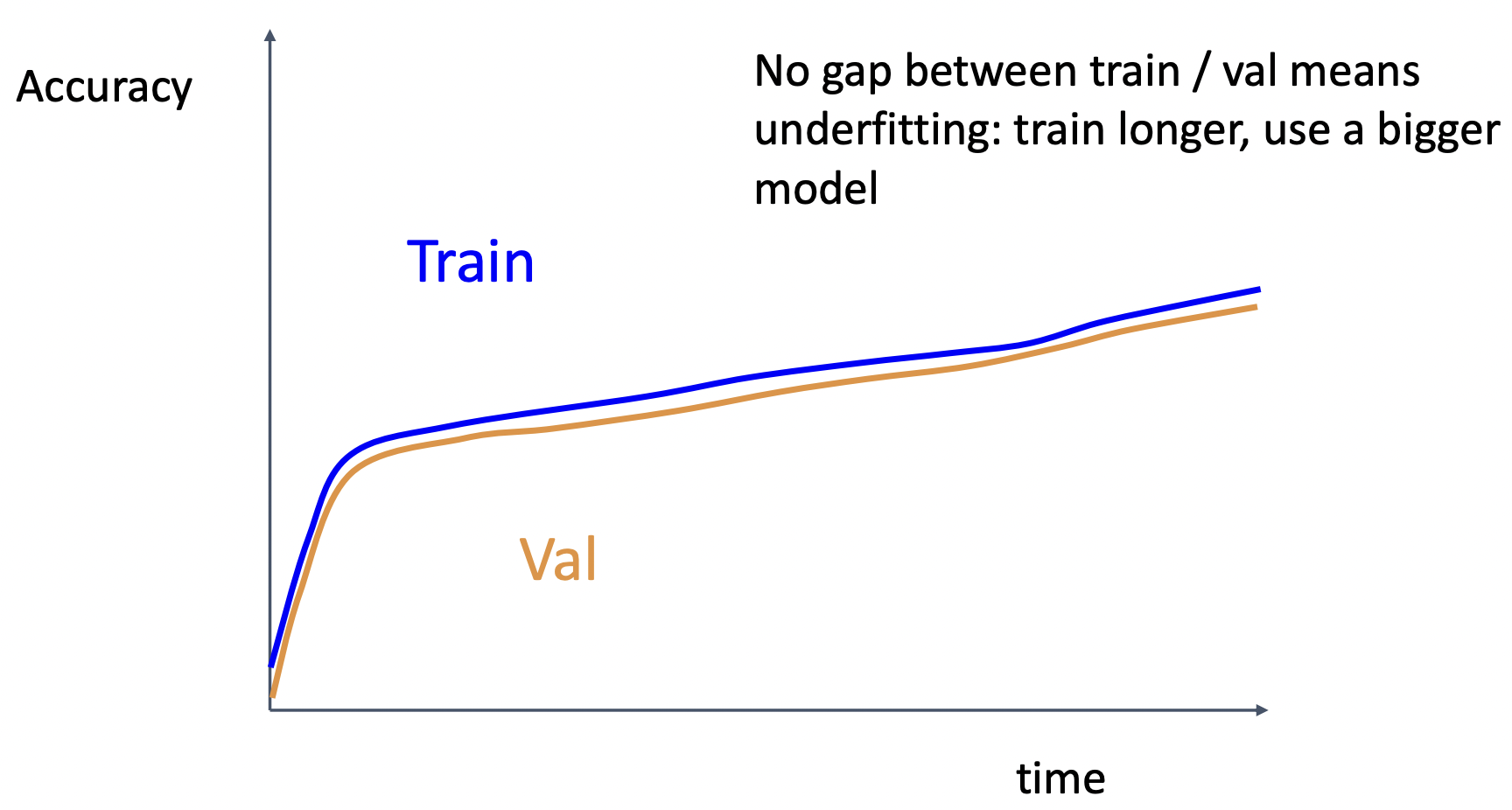
case4: 급격하게 성능이 오르다가 완만하게 증가, train&val 차이가 유지 => 학습을 유지
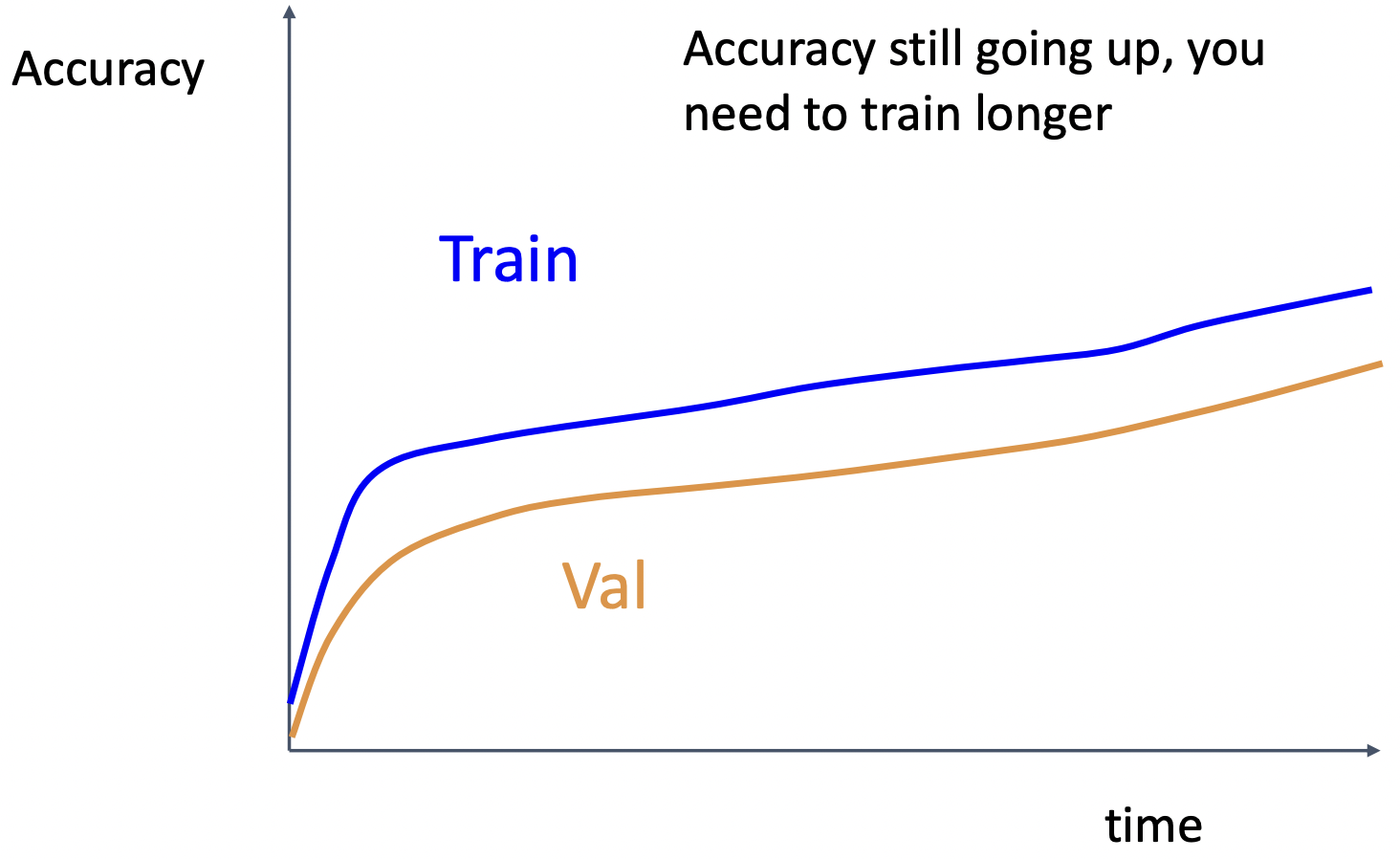
case5: train&val 차이가 커짐 => regularization 크게, 데이터 더 많이 혹은 모델의 크기를 줄이기
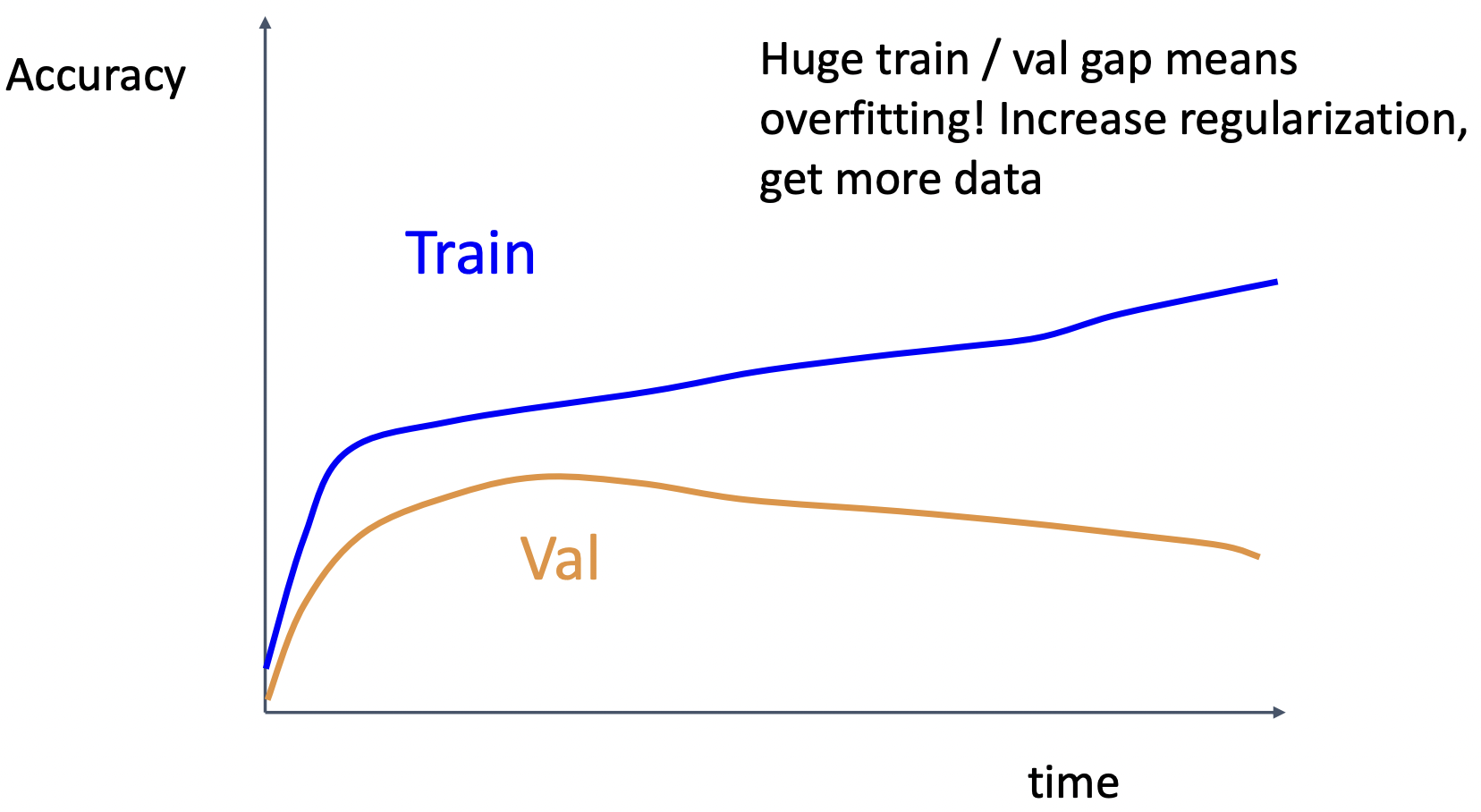
case6: train&val 차이가 없음 => 모델의 크기 키우기, regularization 작게
 .
.
Track ratio of weight update / weight magnitude
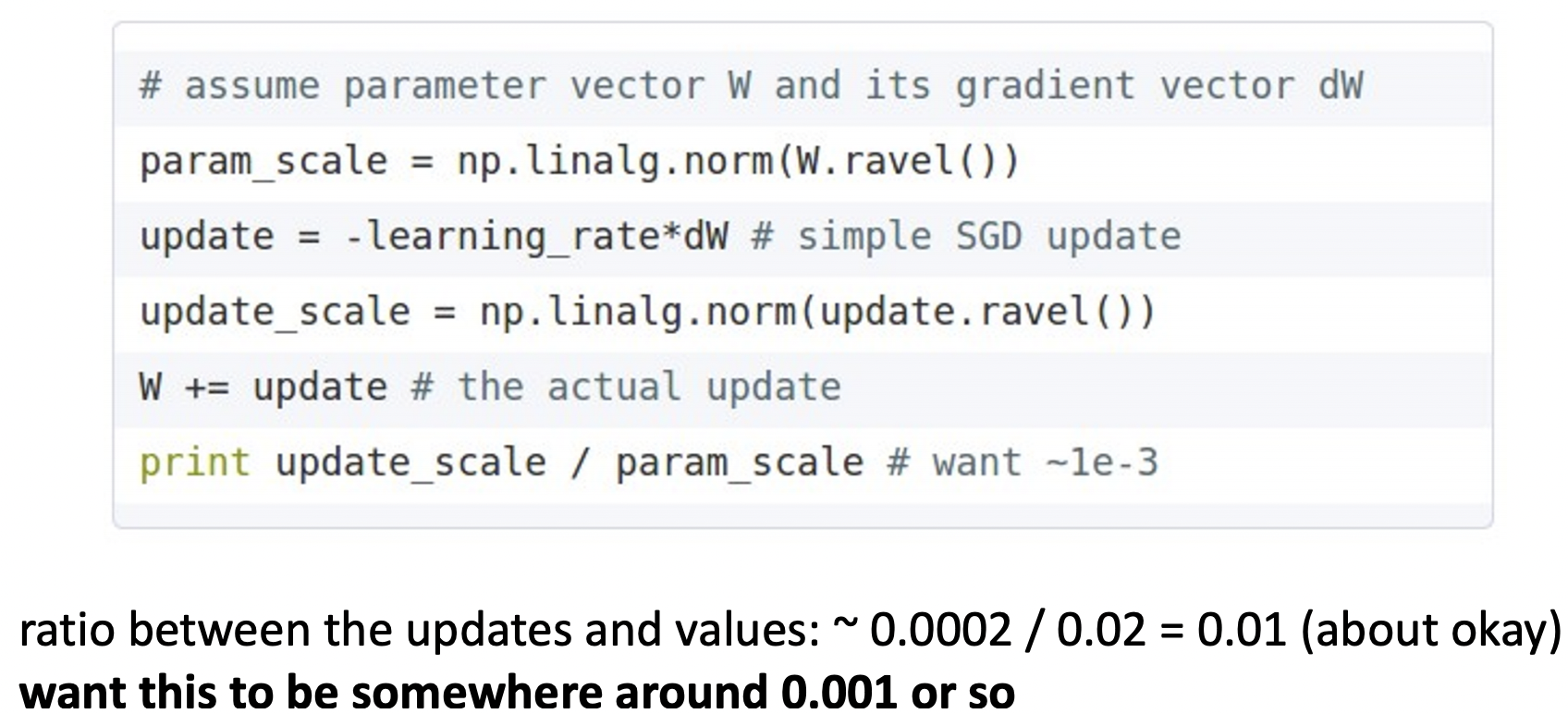
- weight의 업데이트 비율(업데이트 크기/현재 값)은 약 0.001 언저리에 있기를 원합니다.
Model Ensembles
- 다수의 독립적 모델을 학습한다.
- At test time, 각 모델의 결과를 종합한다.
(Take average of predicted probability distributions, then choose argmax)
- Enjoy 2% extra performance
Model Ensembles: Tips and Tricks1
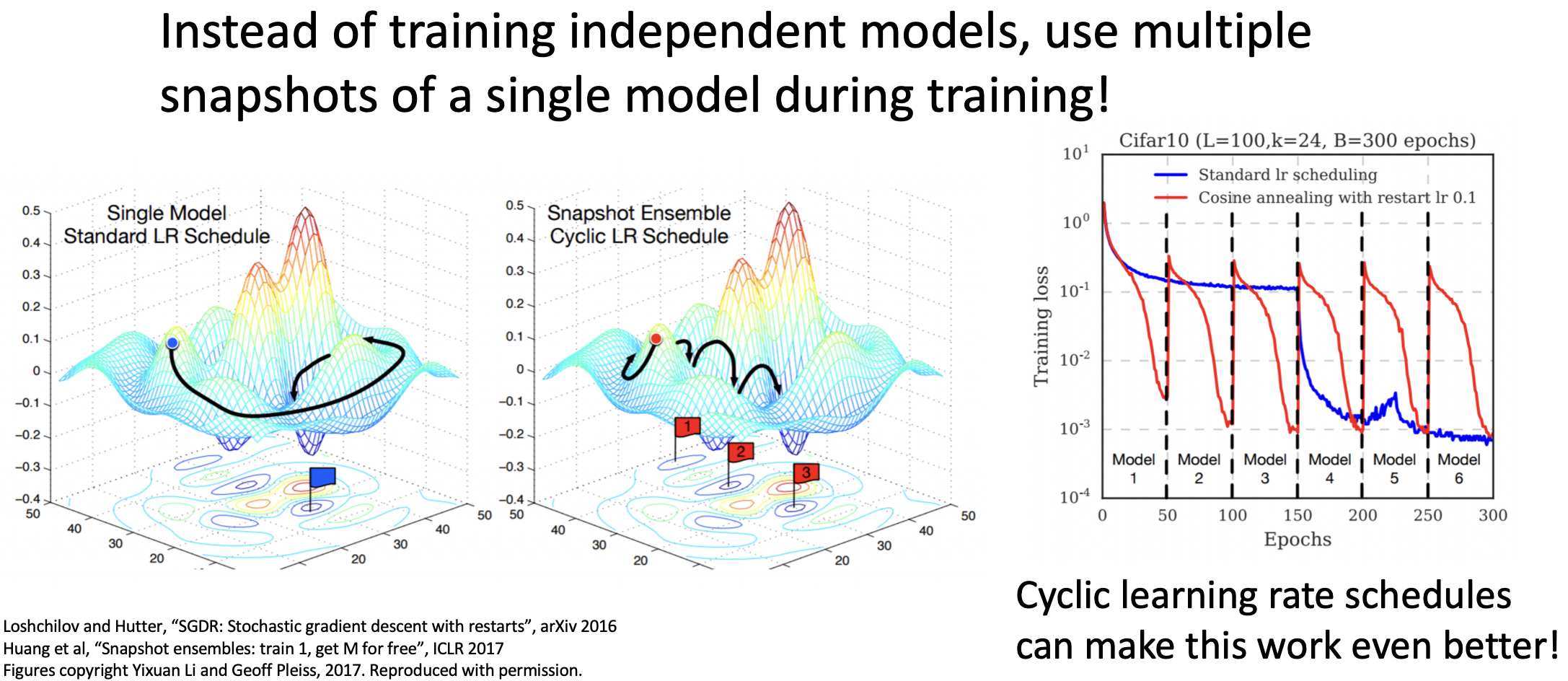
- 독립적인 모델을 학습하는 대신, 하나의 모델내에서 학습도중의 여러 snapshot들을 사용한다.
- 기괴한(bizarre) lr을 설정하여 학습을 진행한다.(Cyclic lr)
- 주로 사용되는 Ensemble은 아니다.
Model Ensembles: Tips and Tricks2
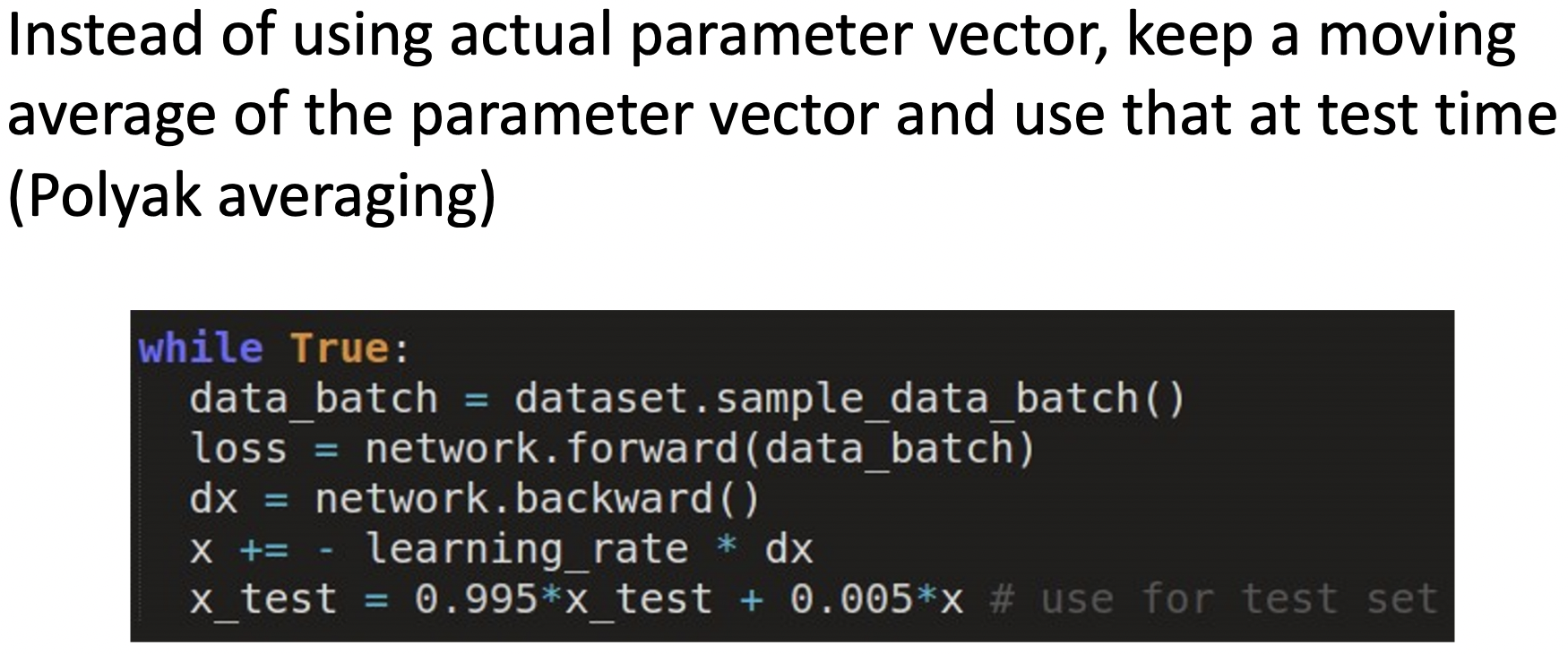
- 파라미터 벡터에 대한 moving average를 저장하고 있다가 test time에 사용한다.
- generate model에서 주로 사용한다.
Transfer Learning
-

-
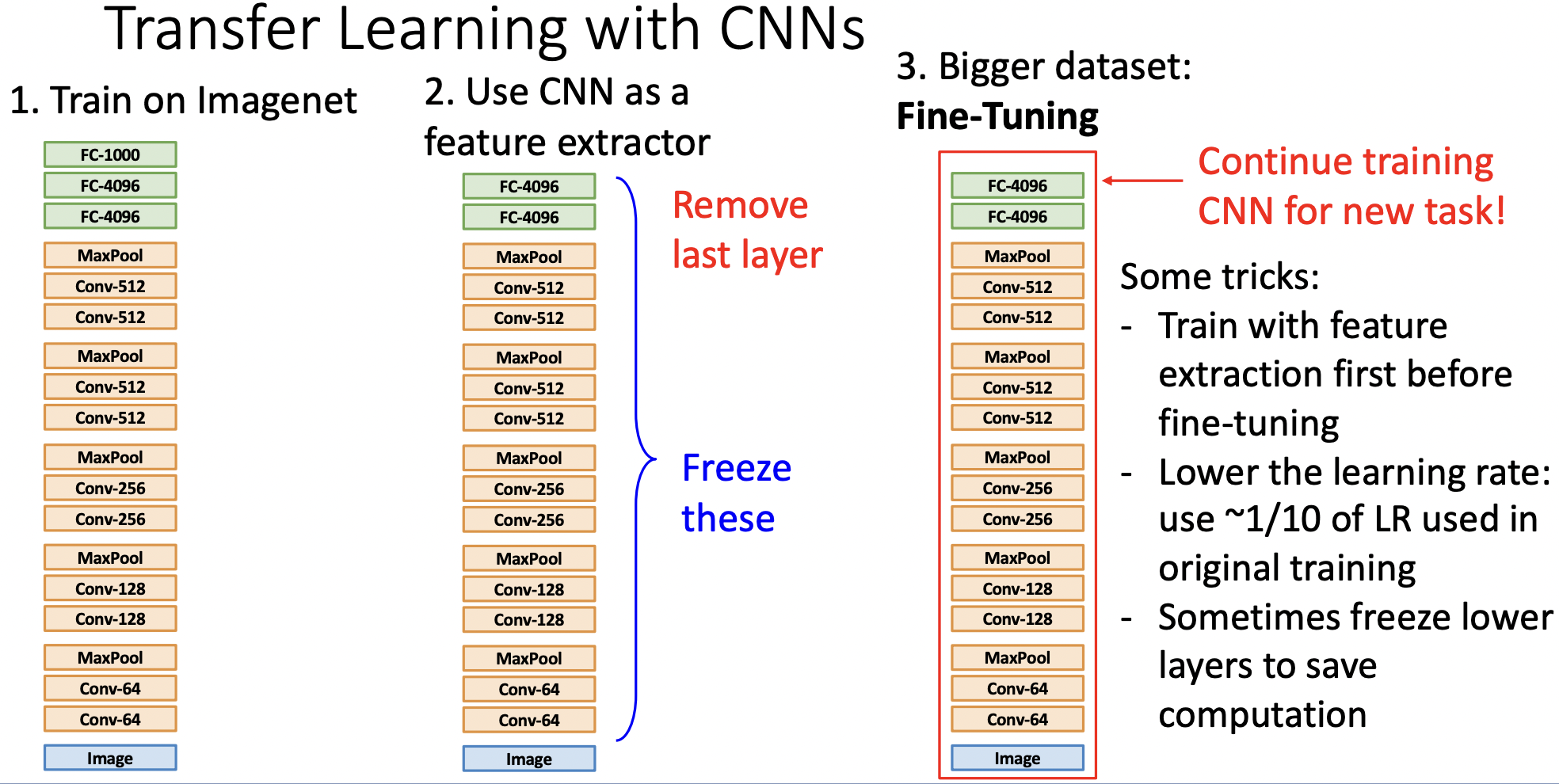
Alexnet CNN 아키텍쳐의 Last layer인 FC들은 Imagenet의 클래스 분류를 위한 것이므로 삭제를 한다.
-
직전 layer까지의 weight들은 모두 requires_grad = False로 설정하여 freeze하고, 업데이트에 사용하지 않는다. 피쳐 추출기로 사용하는 것이다.
-
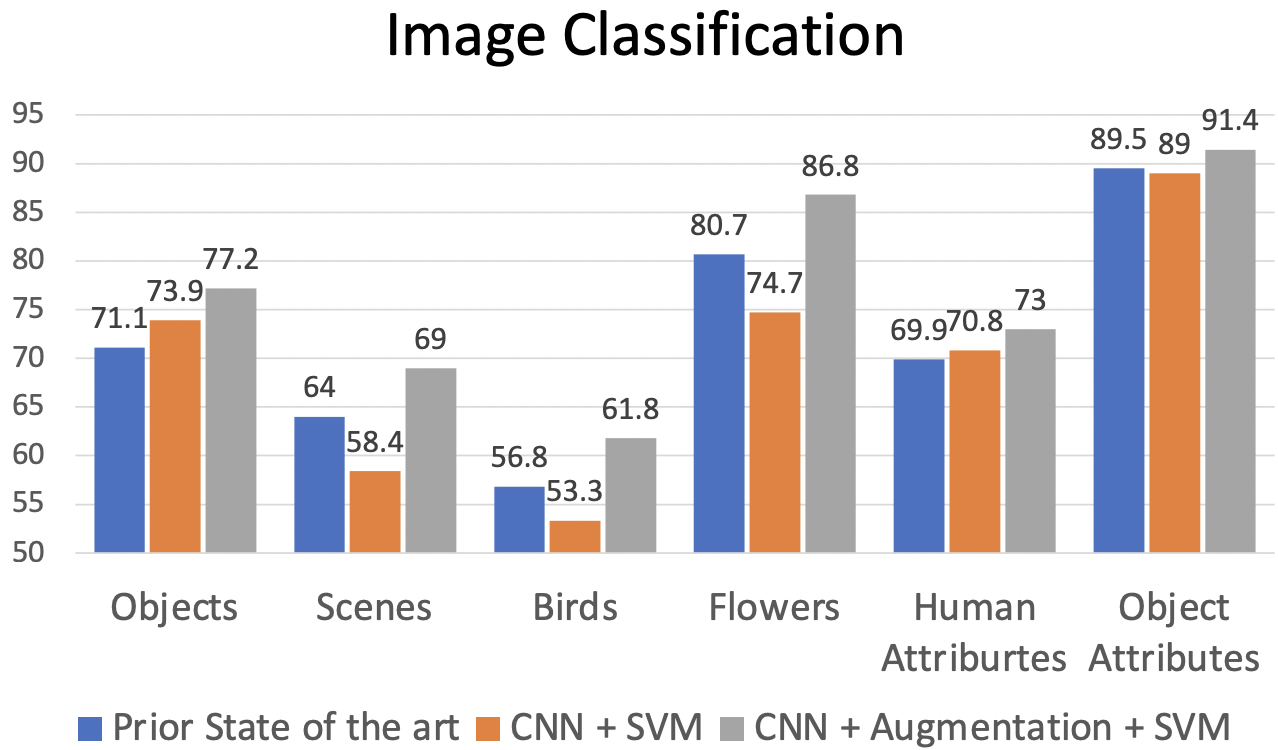
오른쪽 그래프에서 빨간색 선이 'rule기반으로 피쳐 추출기를 만든 후, 그 위에 linear classification을 한 방법'이다.
-
초록색과 파란색 선이 'top layer제거하여 피쳐추출기로 활용한 후, 그 위에 linear classification을 한 방법'이다.
-
이미지넷 pre-trained model을 사용할 수 있다면 관련된 부류의 많은 task들에 많은 데이터 없이도 좋은 성능을 갖을 수 있다.
-
-
각 도메인의 SOTA성능보다(파란) imagenet pretrained model을 사용한 방법이(회색) 모든 도메인에서 좋은 성능을 나타내었다.
-
-
Fine-Tuning이란 pre-trained model의 weight를 initial weight로 설정하고, 가진 데이터셋에 새로 훈련하는 것이다.
-
Trick1: feature layer는 학습하지 않고 말단의 추가한 선형레이어를 훈련시킨 뒤, 전체 모델을 함께 Fine-tuning 한다.
-
Trick2: Learning rate를 사용한다.
-
Trick3: 연산량을 절약하기 위해 lower level layer들은 그대로 사용할 수 있다.
-
-
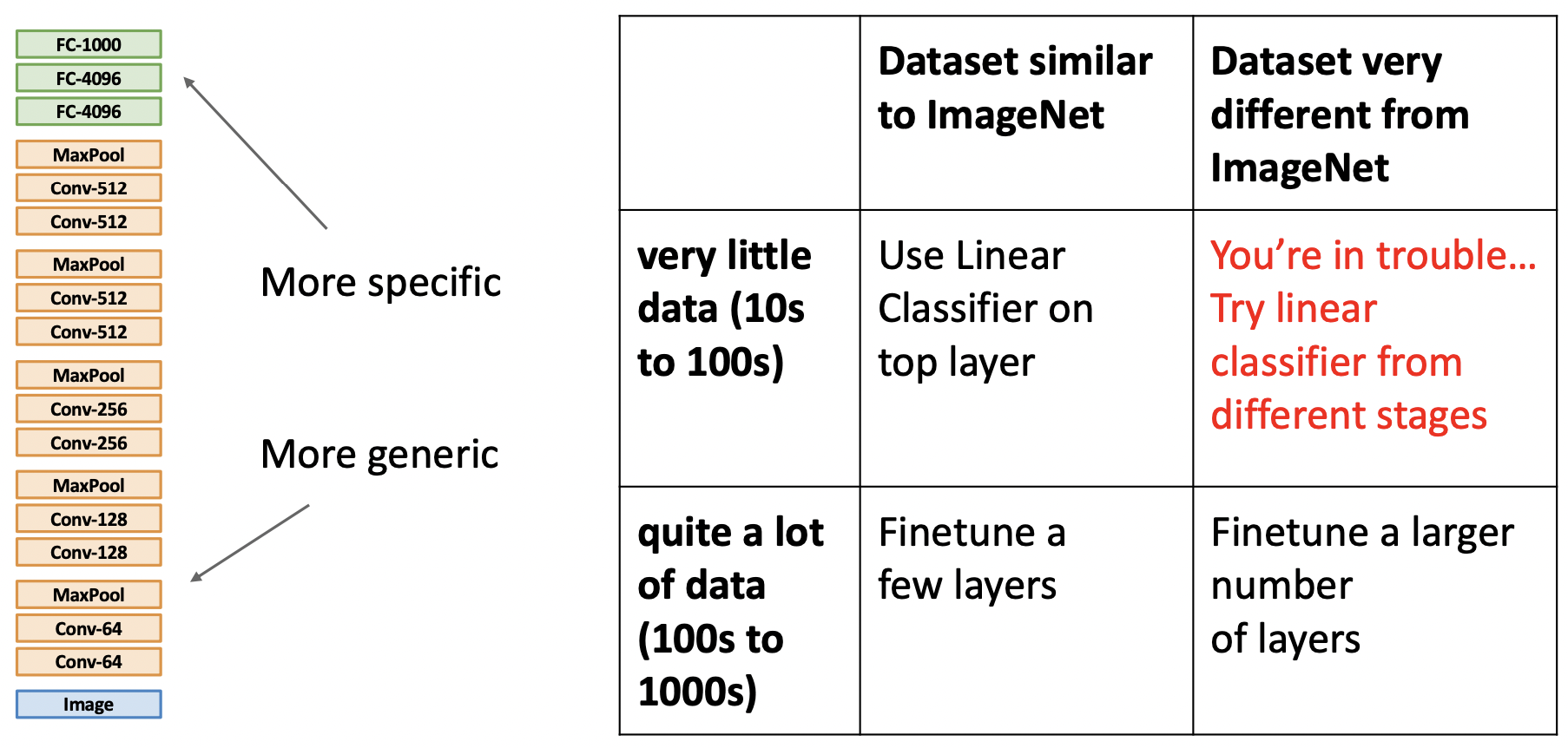
Case1: ImageNet과 비슷한 데이터 & 매우 적은 데이터(카테고리당 10~100장)
linear CLF를 추가한다. -
Case2: ImageNet과 비슷한 데이터 & 매우 많은 데이터(카테고리당 100~1000장)
feature layer의 적은 수의 레이어를 finetune한다. -
Case3: ImageNet과 비슷한 데이터 & 매우 적은 데이터(카테고리당 10~100장)
레이어를 추가하거나 finetune으로 성능이 좋을 수 있지만 적용하기 좋은 상황은 아니다. -
Case4: ImageNet과 비슷한 데이터 & 매우 많은 데이터(카테고리당 100~1000장)
feature layer의 많은 수의 레이어를 finetune한다. -
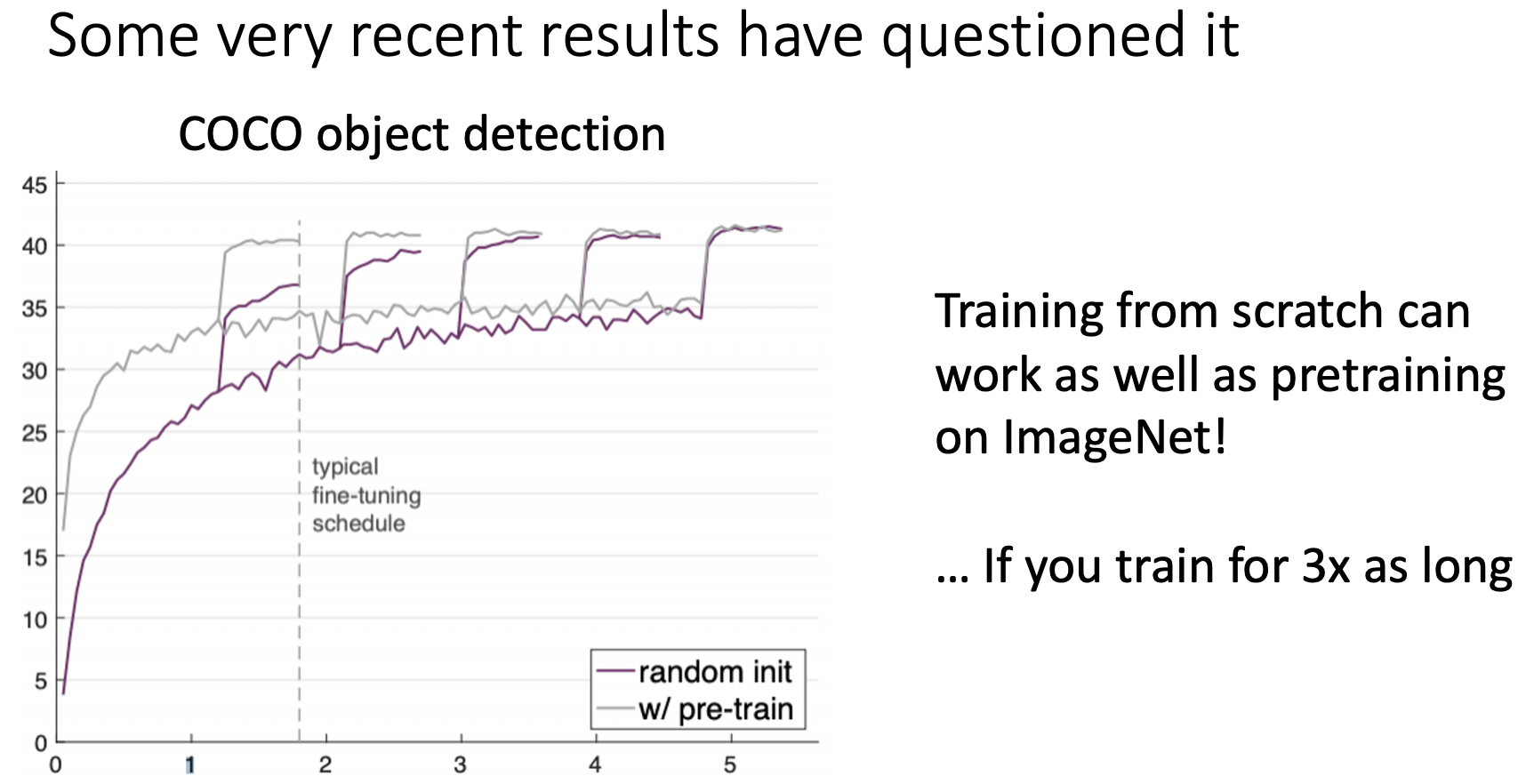
-
from scratch 방식으로 학습하는 것과 pre-trained 모델을 사용하는 방식의 결과는 비슷하게 나타나지만 3배 오래걸린다..
-
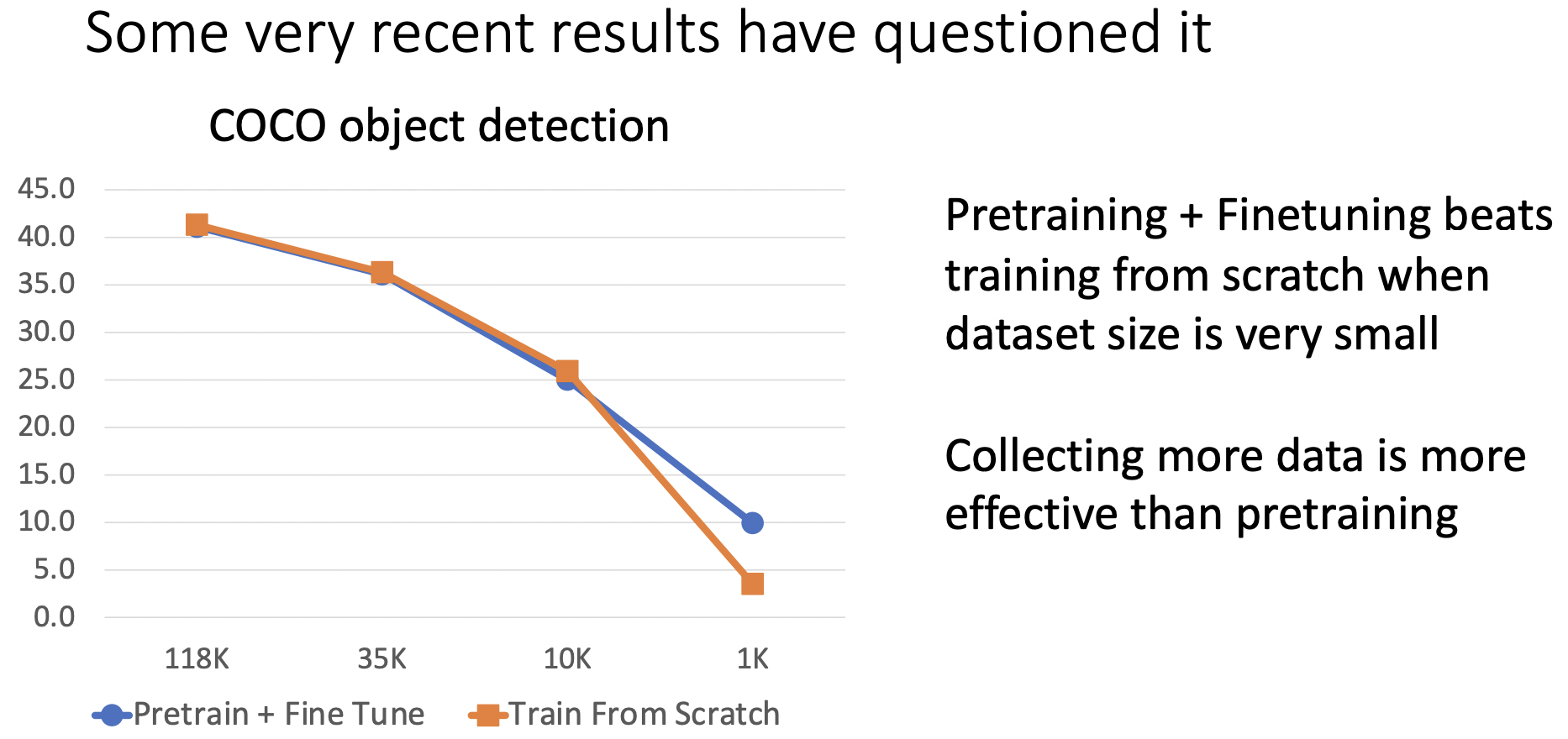
-
데이터가 적을경우 from scratch보다 pretrain-finetune 방식이 더 좋은 성능을 지닌다.
-
(justin) 결론
- pretrain-finetune이 학습 효율상 더 빠르고 효율적을 결과를 나타낸다.(VS from scratch)
- from scratch는 충분히 많은 데이터가 있을때 효과가 있다.(VS pretrain-finetune)
Distributed Training
Model Parallelism: Split Model Across GPUs
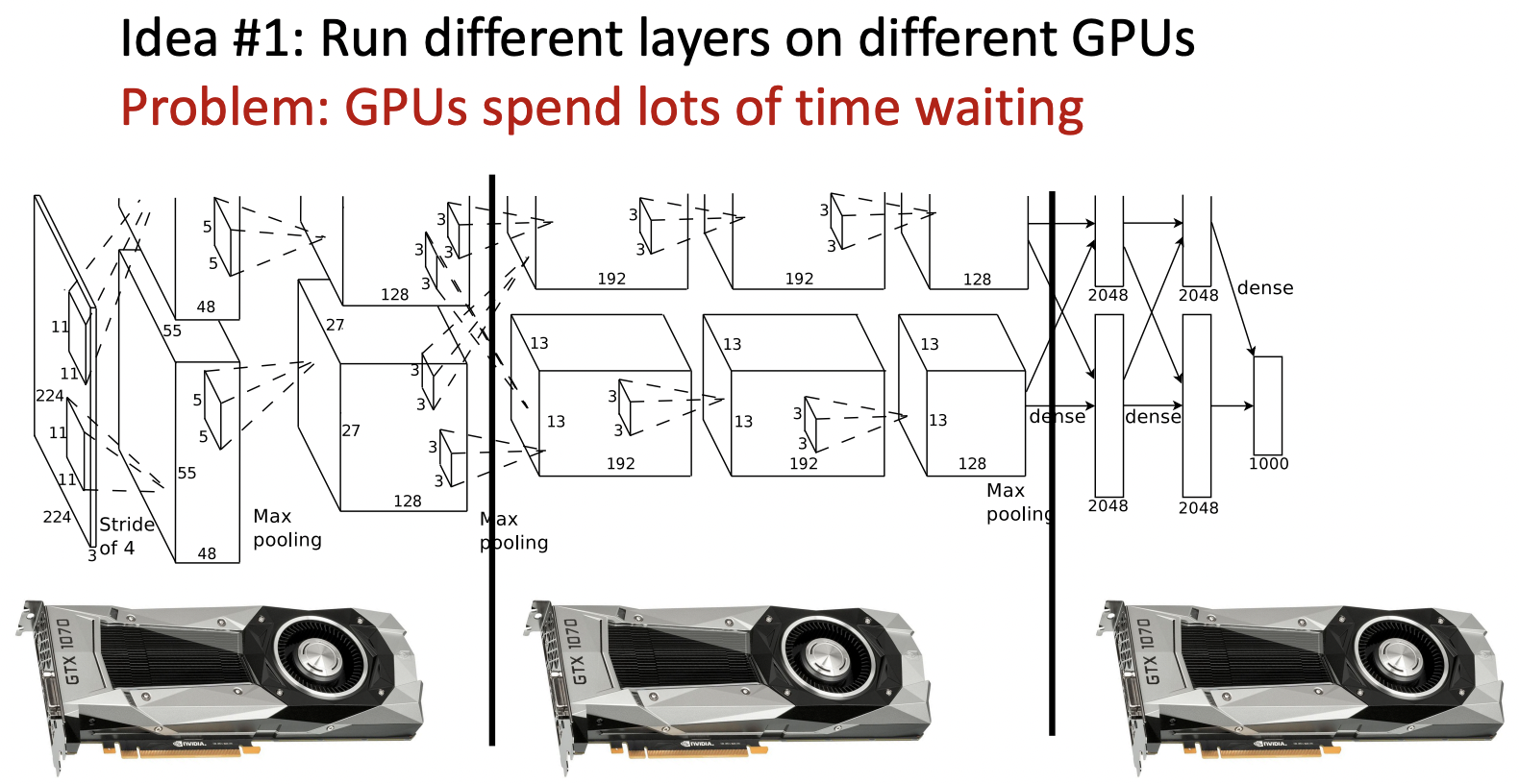
- 모델을 나눈뒤 나눈 부분마다 gpu를 할당하는 방식, gpu들이 기다리는데 오랜시간을 할애한다.

- 모델의 구조를 병렬적으로 나누어 학습, forward와 backward과정에서 communication과정이 많이 필요로 한다.
Data Parallelism: Copy Model on each GPU, split data
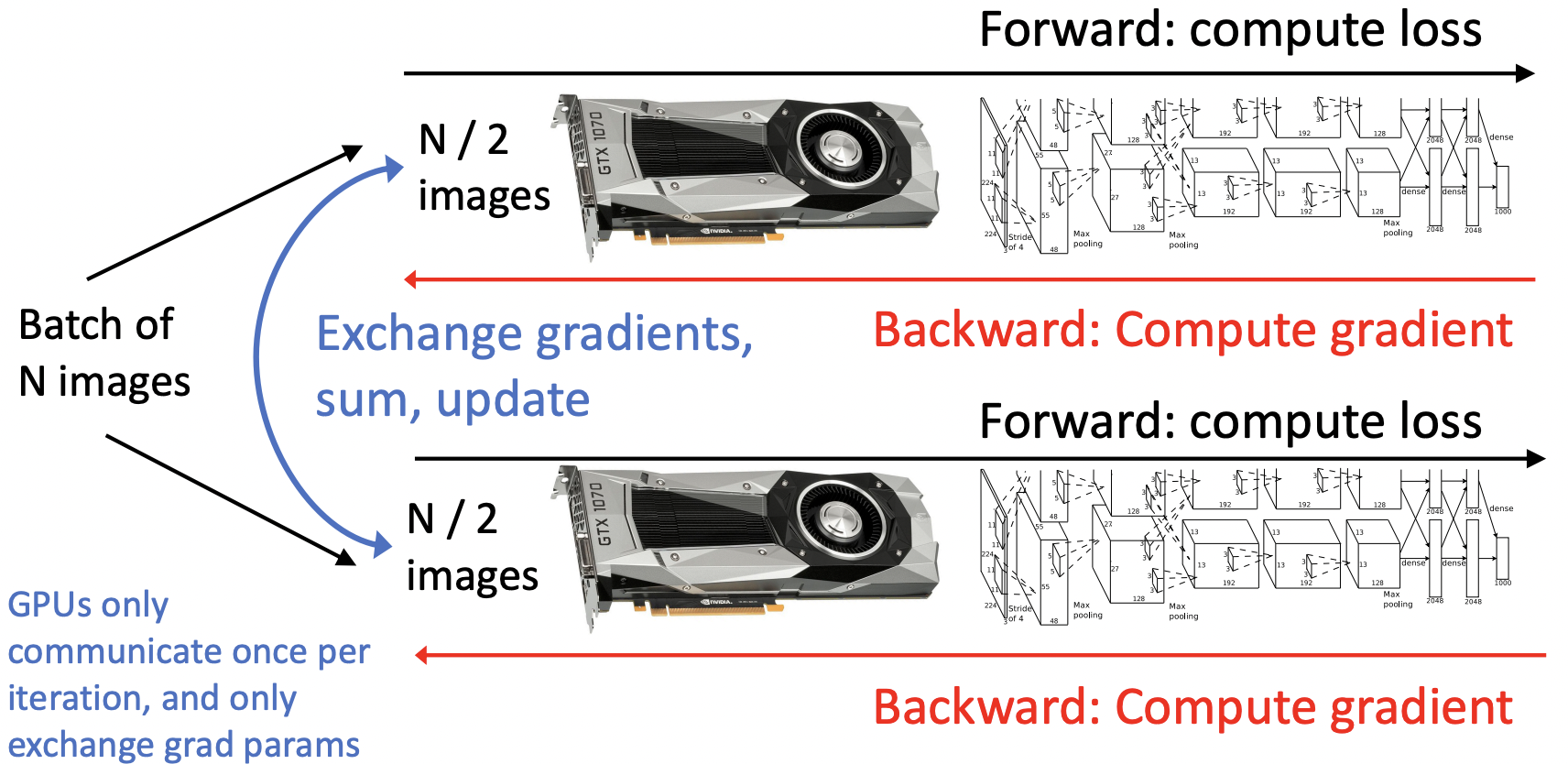
- 데이터를 나누어 각 GPU마다 할당하며, 독립적으로 학습을 진행하며 communication 과정이 각 iteration마다 작동한다.
Mixed Model + Data Parallelism
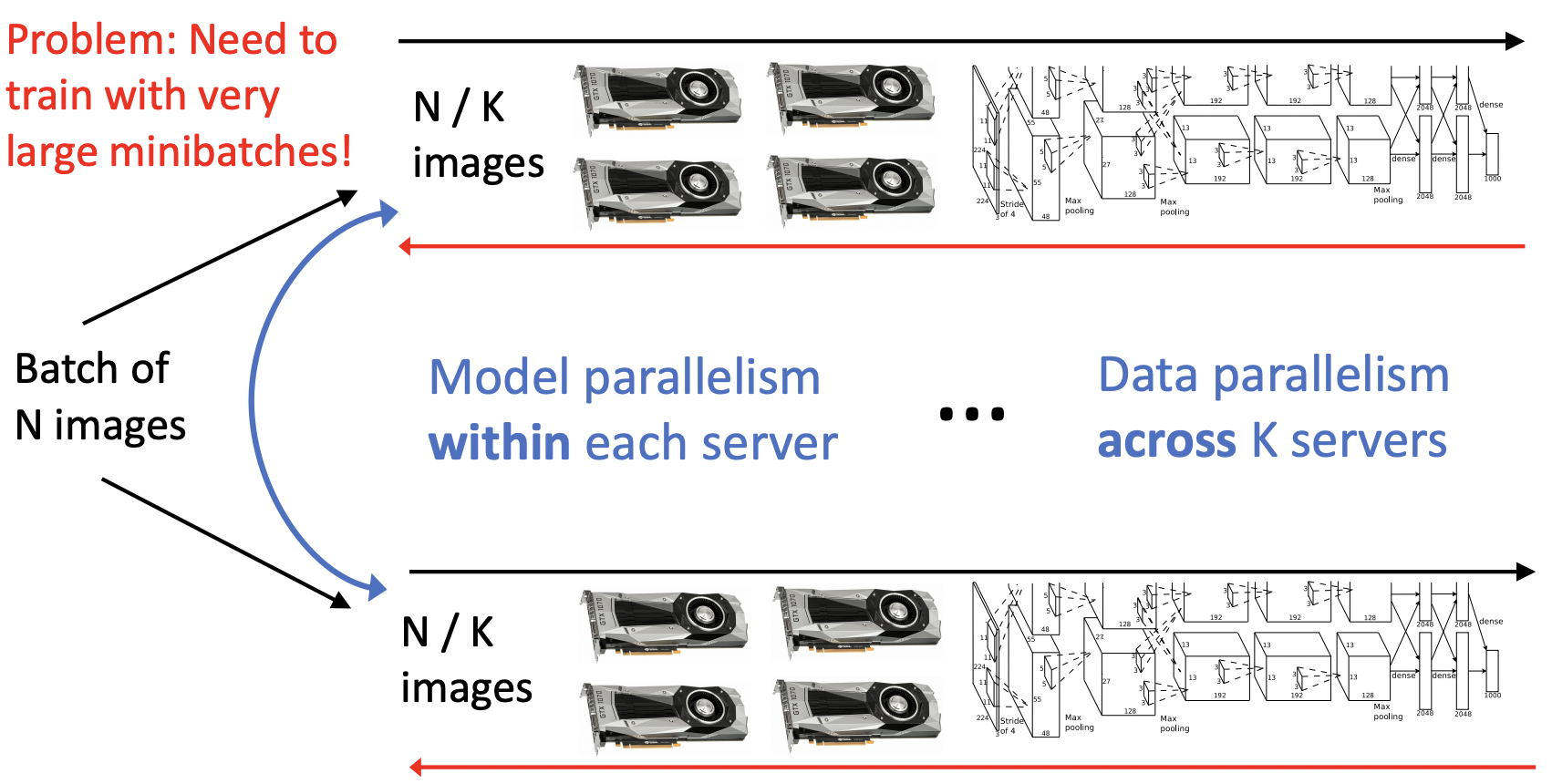
- 두 방식을 종합한 형태로, K개의 서버로 data parallelism을, 각 서버내에서 model parallelism을 적용한다.
- 매우 큰 minibatches를 필요로 한다.
Large-Batch Training

- 같은 수의 epoch을 가지지만 minibatch가 커지므로 훨씬 빠르게 학습이 가능하다.
- Single-GPU model: batch size N, learning rate ⍺
- K-GPU model: batch size KN, learning rate K⍺
lr warmup
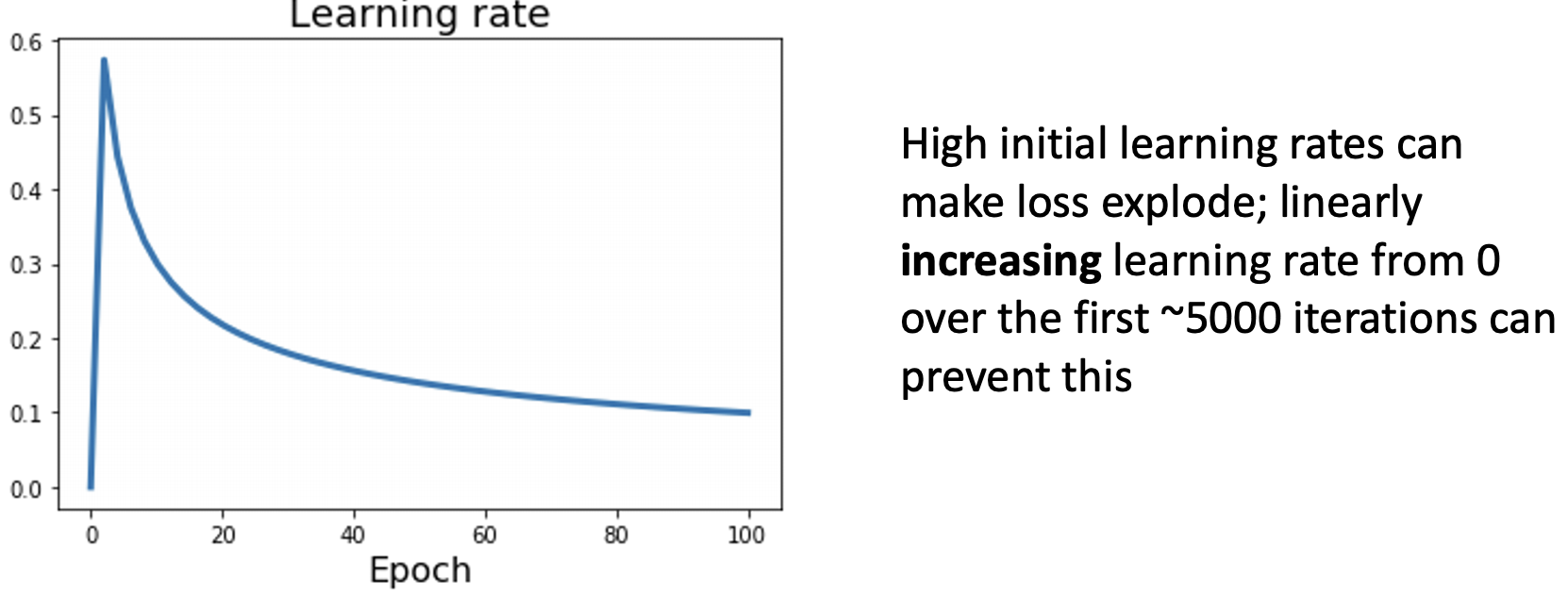
- K의 숫자가 높을수록 lr이 그만큼 커지기 때문에 초기 학습에서 explode할 수 있다. => lr warmup을 사용
- lr을 0에서 시작하여 점점 증가시킨뒤 감소시킨다.
- Be careful with weight decay and momentum, and data shuffling
- For Batch Normalization, only normalize within a GPU
참고자료
cs231n 강의 자료
cs231n 한글 강의 자료
EECS 498-007 / 598-005 2019 강의 자료
