CS231N, EECS 498-007 / 598-005에서 나타나는 개념을 정리하기 위하여 복기용도로 작성하였습니다.
간단히 정리한 내용을 살펴보며 모르는 부분이 있을 때 찾아보는 용도로 보시면 좋을 것 같습니다.
AlexNet
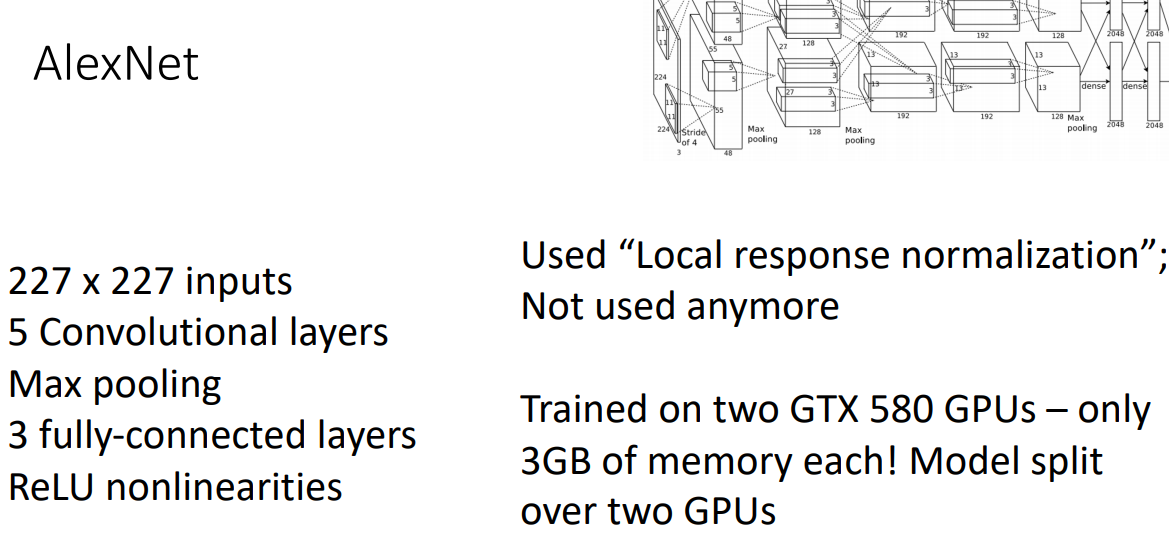
- 요즘 사용하지않는 local response norm을 사용했다.
- GPU 성능이 좋지않아 하나의 모델을 두개의 GPU에 나누어 할당했다.
conv1

- C
- Output channels = number of filters = 64
- H / W
- W’ = (W – K + 2P) / S + 1
= (227 – 11 + 2x2) / 4 + 1
= 220/4 + 1 = 56
- W’ = (W – K + 2P) / S + 1
- memory(KB)
- Number of output elements = C x H’ x W’
= 64 x 56 x 56 = 200,704 - Bytes per element = 4 (for 32-bit floating point)
- KB = (number of elements) x (bytes per elem) / 1024
= 200704 x 4 / 1024
= 784
- Number of output elements = C x H’ x W’
- params(k)
- Weight shape = Cout x Cin x K x K
= 64 x 3 x 11 x 11 - Bias shape = Cout = 64
- Number of weights = 64 x 3 x 11 x 11 + 64
= 23,296
- Weight shape = Cout x Cin x K x K
- flop(M)
- Number of floating point operations (multiply+add)
(곱하고 더하는 연산을 하나의 연산으로 계산하여 계산하면)
= (number of output elements) * (ops per output elem)
= (Cout x H’ x W’) x (Cin x K x K)
= (64 x 56 x 56) x (3 x 11 x 11)
= 200,704 x 363
= 72,855,552
- Number of floating point operations (multiply+add)
pool1
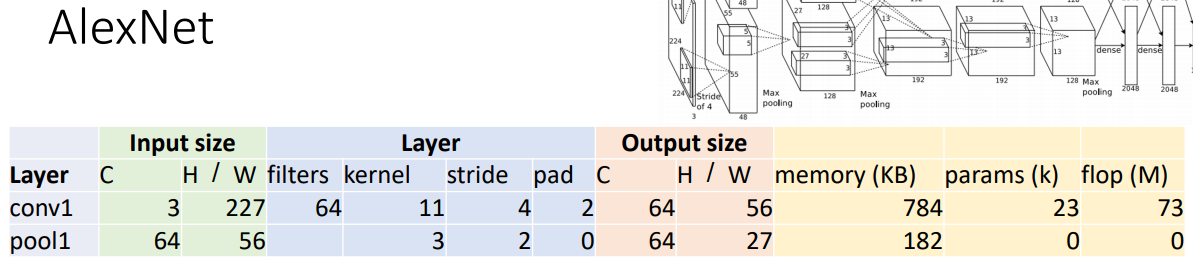
- C
- output channels = #input channels = 64
- H / W
- W’ = floor((W – K) / S + 1)
= floor(53 / 2 + 1) = floor(27.5) = 27
- W’ = floor((W – K) / S + 1)
- memory(KB)
- output elems = Cout x H’ x W’
- Bytes per elem = 4
- KB = Cout x H’ x W’ x 4 / 1024
= 64 x 27 x 27 x 4 / 1024
= 182.25
- params(k)
- Pooling layers have no learnable parameters!
- flop(M)
- Floating-point ops for pooling layer
= (number of output positions) * (flops per output position)
= (Cout x H’ x W’) x (K x K)
= (64 x 27 x 27) x (3 x 3)
= 419,904
= 0.4 MFLOP
- Floating-point ops for pooling layer
fc6
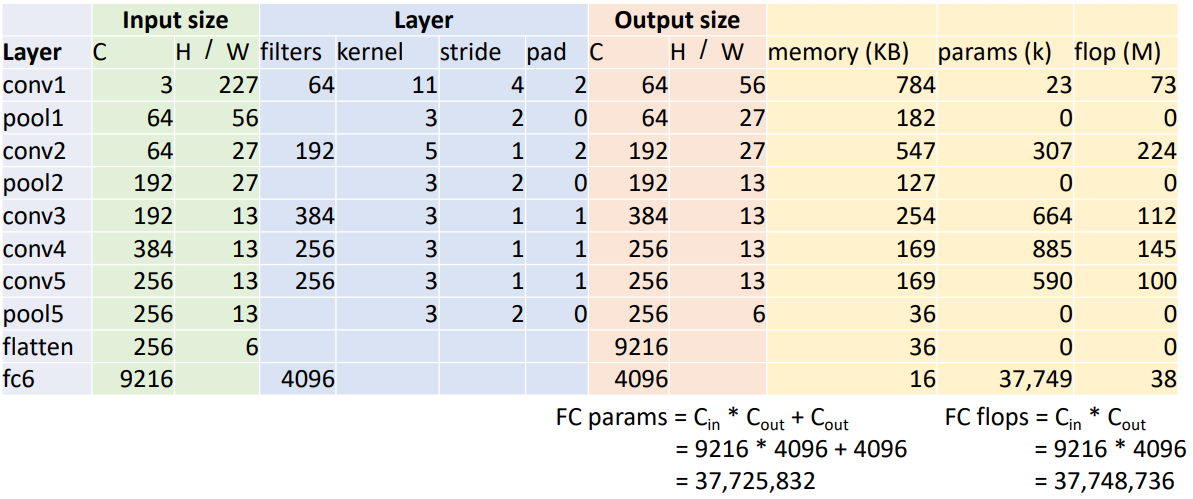
- params
- Cin x Cout + Cout
= 9216 x 4096 x 4096
= 37,725,832
- Cin x Cout + Cout
- flop
- Cin x Cout
= 9216 x 4096
=37,748,736
- Cin x Cout
Q: How to choose this?(아키텍쳐 구성질문)
A: Trial and error.
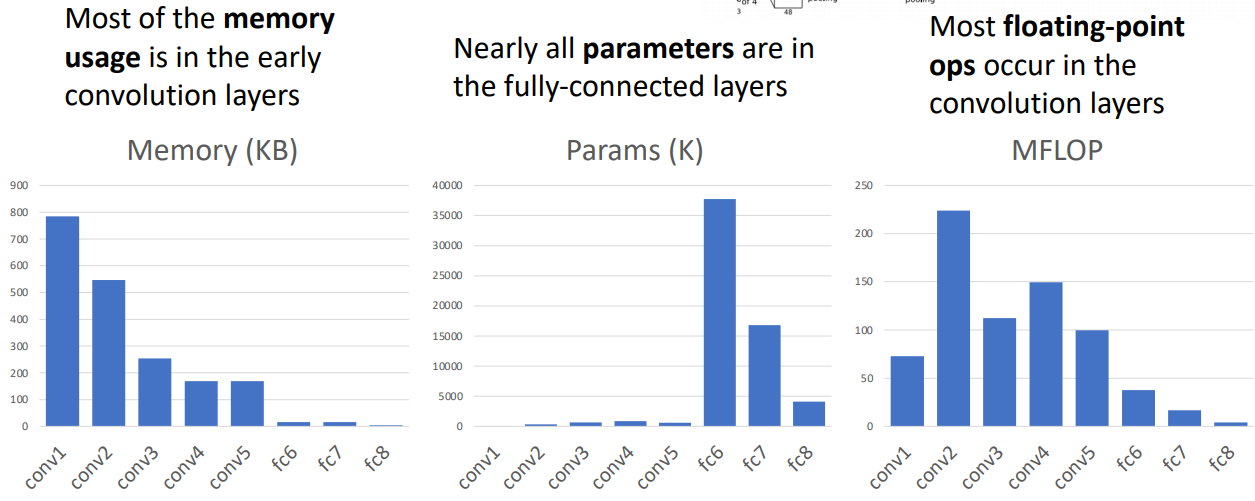
- 대부분의 메모리 사용은 초기(앞단) CONV의 activations 저장에 사용된다. 상대적으로 앞쪽의 CONV output이 high spatial resolution과 high number of filter이기 때문이다.
- CONV는 파라미터수가 거의 없다 시피하고 FC는 상대적으로 상당히 많다. 마찬가지로 초기 FC가 많은 수를 차지한다.
- FC는 연산량이 상대적으로 적음을 알 수 있는데, 이는 단순히 매우 큰 matrix를 곱하는 것이기 때문이다. CONV는 다수의 필터와 spatial size가 크기 때문에 연산량이 많다.
VGG
구성
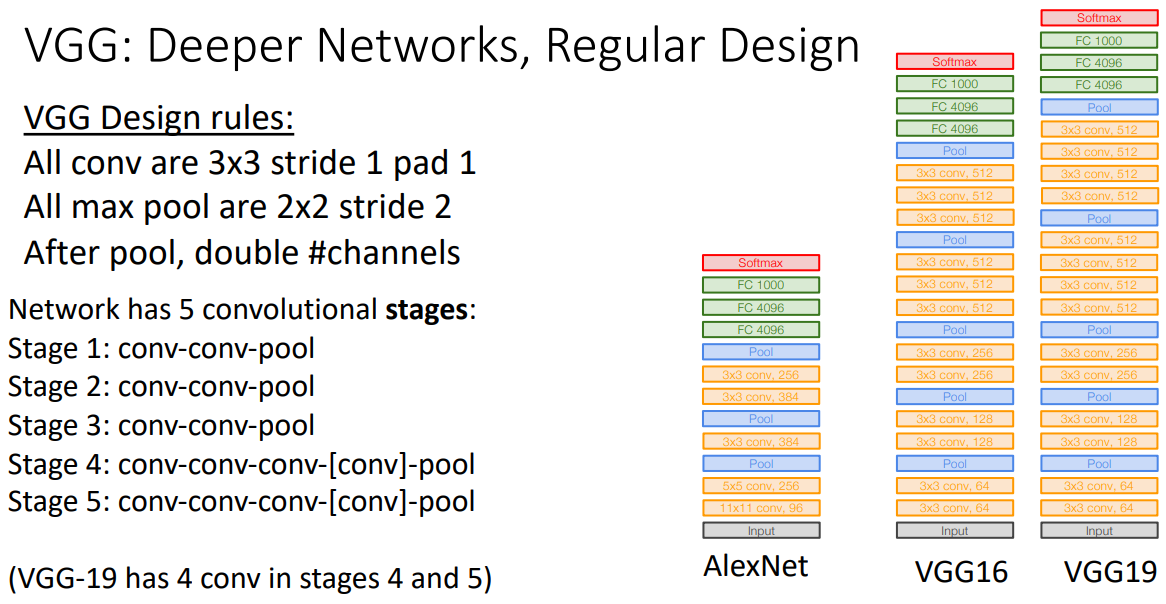
- 모든 CONV와 POOL에 대해 동일한 설정을 적용하였다.
- 5가지 stage를 둠으로 깊은 네트웍구성을 시도했다.
Design guide 1

- Option 1: Conv(5x5,C->C) VS Option 2: Conv(3x3,C->C) & Conv(3x3,C->C)
- Prams: >
- FLOPs: >
- Receptive field: same
- 따라서 같은 receptive field를 가지고 있으면 5x5 CONV대신 연산량과 파라미터수가 적은 3x3 CONV를 두개 쌓는 방식으로 대체하였다. 추가적으로 activation function이 두 번 들어가므로 non-linear computation을 더 표현할 수 있다고 한다.
Design guide 2
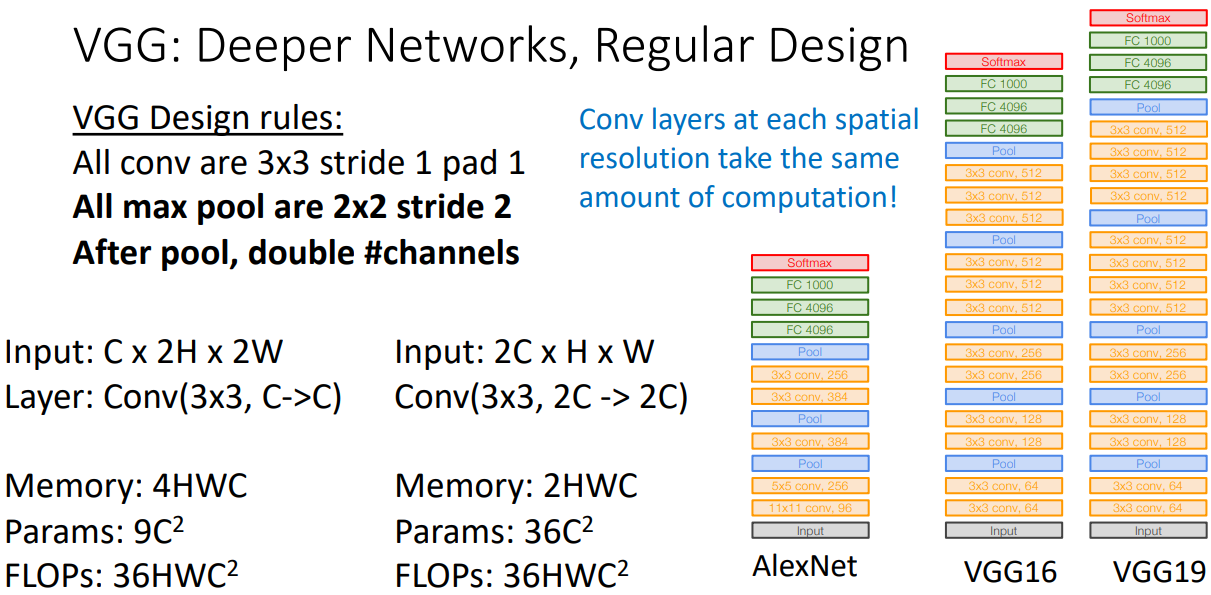
- 왼편의 입력값, 레이어 구성, 메모리, 파라미터, 플롭수는 첫번째 스테이지의 과정이며 오른편은 바로 다음 스테이지의 과정이다.
- 공통적으로 가져고가고 한 특성은 연산량이 동일하게 유지하고자 채널수는 두배로 spatial resolution은 반으로 구성하여 맞춰줌을 알 수 있다.
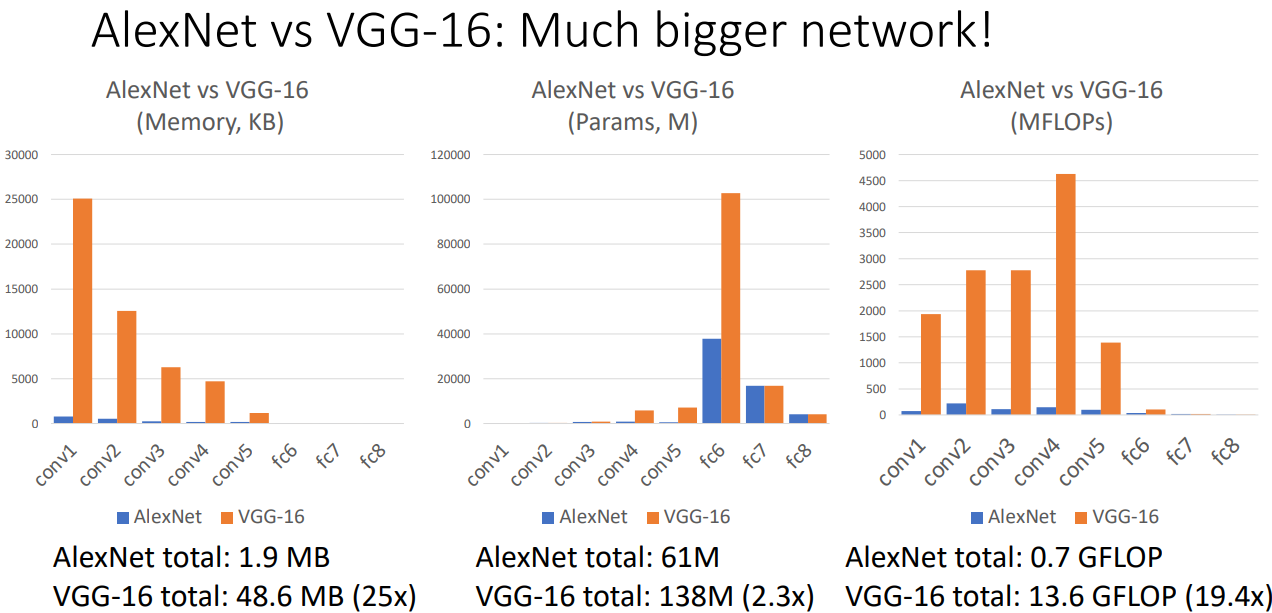
- VGG가 AlexNet보다, 표에서 알 수 있듯이 메모리(25배), 파라미터수(2.3배), 연산량(19.4배)등 굉장히 큰 모델임을 알 수 있다.
Google Net
특성
- focus on Efficiency: reduce parameter count, memory usage, and computation
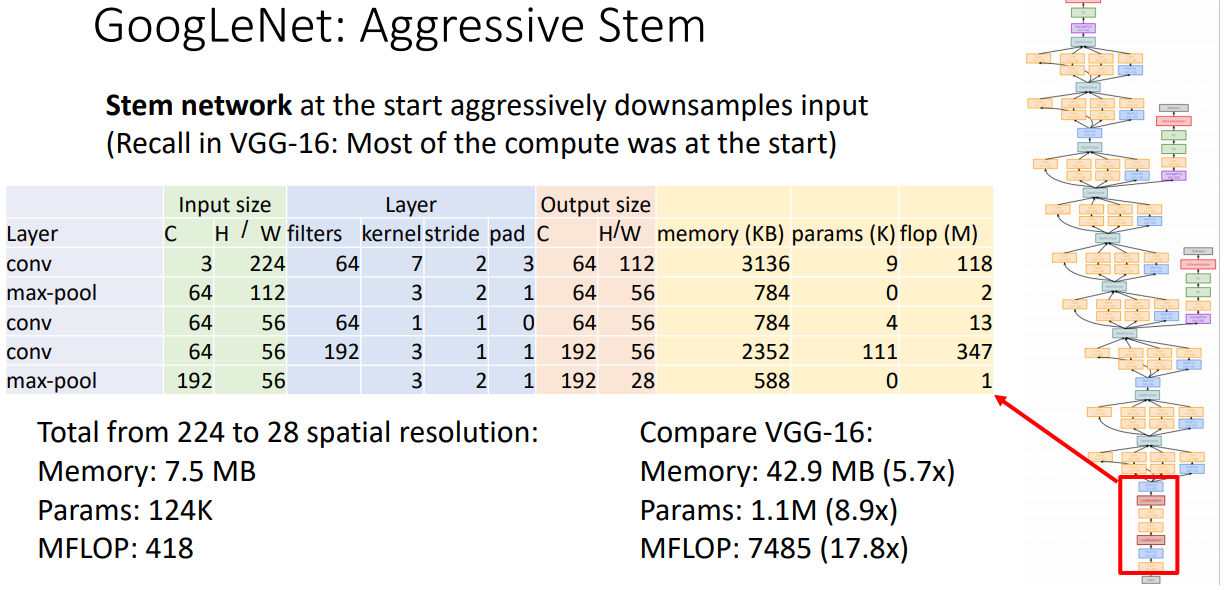
- stem entwork: spatial size를 224크기를 28까지 down sample할 때의 과정을 단지 몇개의 레이어로 구성하였다. VGG와 비교하여도 굉장히 많은 메모리,파라미터,연산량을 줄였다.
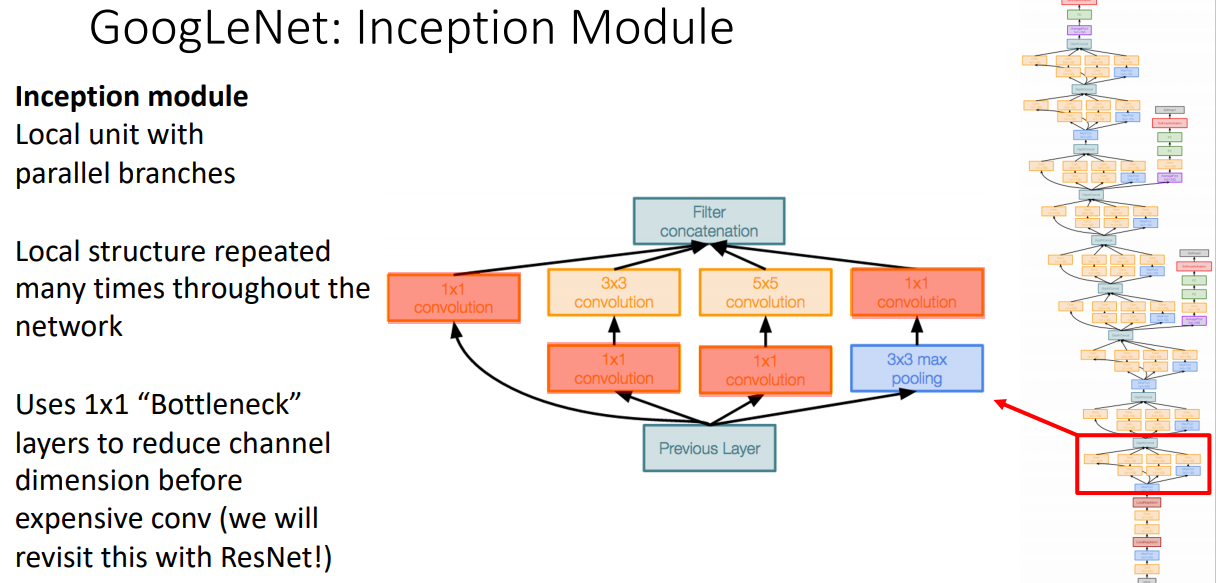
- Inception moduule: 커널사이즈라는 hyperparameter을 없애기위해 항상 모든 커널사이즈를 사용하였다.
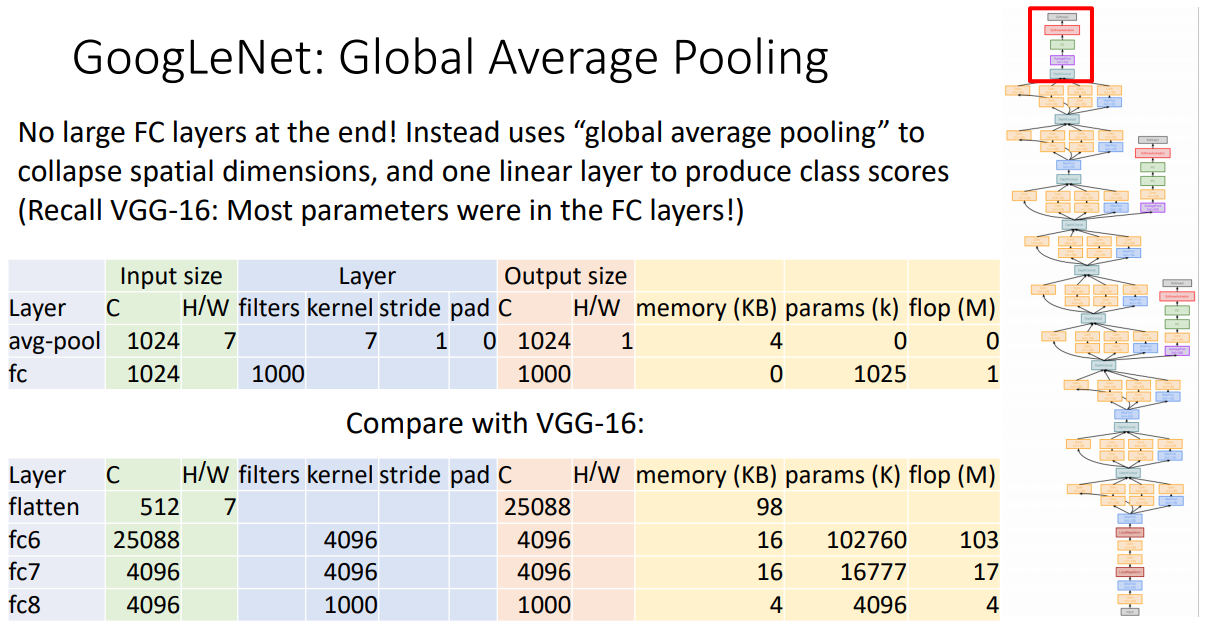
- Global Average Pooling(GAP): VGG와 AlexNet에서는 말단에서 flatten을 통해 spatial information을 destroy 했지만, GoogleNet은 대신 GAP 과정이 kernel size가 fianl spatial size가 되게 함으로 spatial information을 다른 방식으로 destroy 했다? 7x7 입력값을 GAP의 사이즈가 7인 커널을 사용하여 출력 size가 1이 되었다.

- Auxiliary Classifiers: Batch Norm이 사용되기 전이므로 깊은 모델 학습에 어려움이 있었다.따라서 Network 중간 중간에 Class score를 계산하는 과정(GAP등)을 넣음으로 해결하고자 했다. BN 출현이후 이 과정은 더이상 사용되지 않는다고 한다.
ResNet
특성
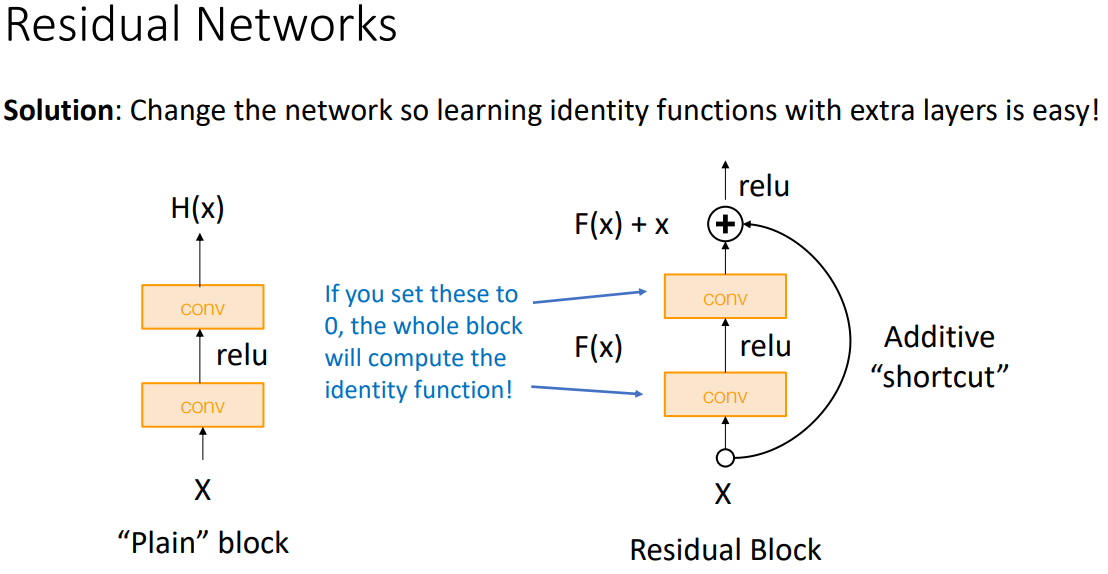
- 깊은 모델의 경우 얕은 모델을 복사하고 추가 레이어(초기에는 identity functions)를 학습하면된다. 그러나 최적화 단계에서 깊은 모델은 문제가 있었다.
- Residual Networks: 이 레이어의 장점은 identity function을 쉽게 배울수 있다.(CONV가 0이면됨으로). 또한 gradient flow를 향상시켰다. backprob시에 add gate의 gradient가 상위 레이어에 그대로 복사가 되어 vanishing problem이 줄어든다.
- 여러 stage구성과 GAP를 사용한 점은 VGG와 GoogleNet과 같다.

- Residual Networks: Bottleneck Block 일반적인 CONV레이어 앞뒤로 1x1 CONV레이어를 채널수를 늘리는 과정과 줄이는 과정을 구성함으로, 레이어수는 많아졌지만 연산량이 줄어들었다. more non-linearity & sequential computaion으로 복잡한 계산을 더 잘한다는 직관이 작용했다.
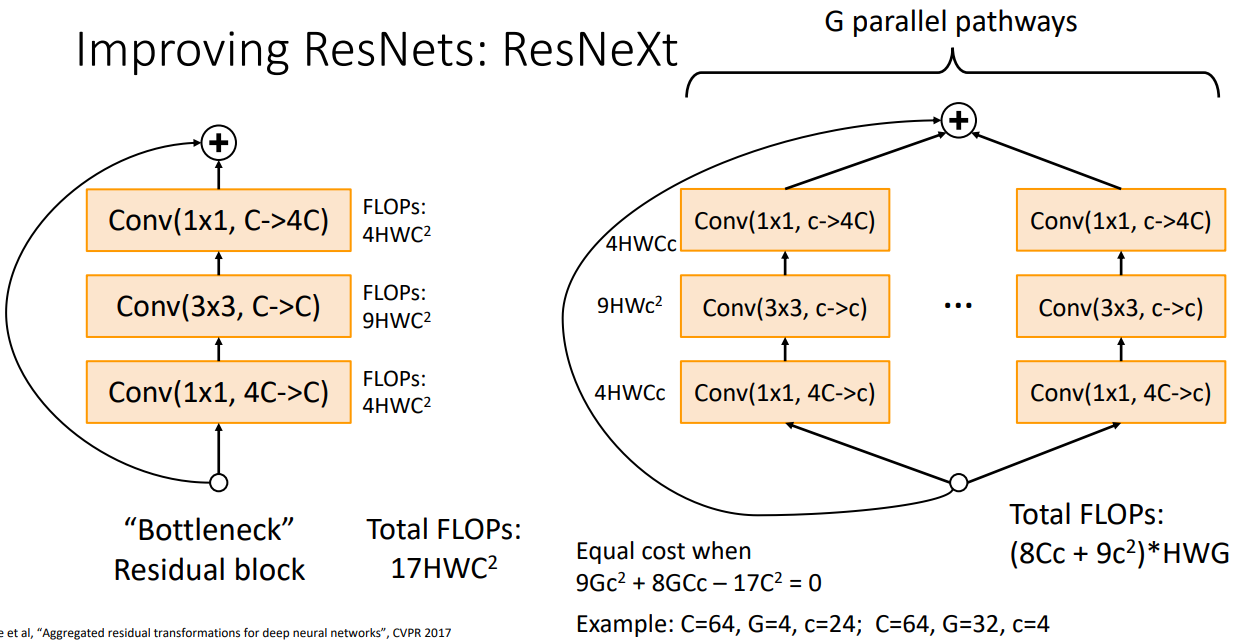
- Improving Resnets:ResNeXt Bottleneck Block을 병렬적으로 구성한 방법으로 G개의 보틀넥을 구성한다. 내부 채널인 c를 조정하여 기존 Bottleneck 구성과 연산량을 비슷하게 구성하였다.

- Grouped Convolution: 입력 채널과 출력채널을 G개의 그룹으로 나누어 각 그룹마다 CONV연산을 수행하고 그 결과를 종합하여 구성한다.
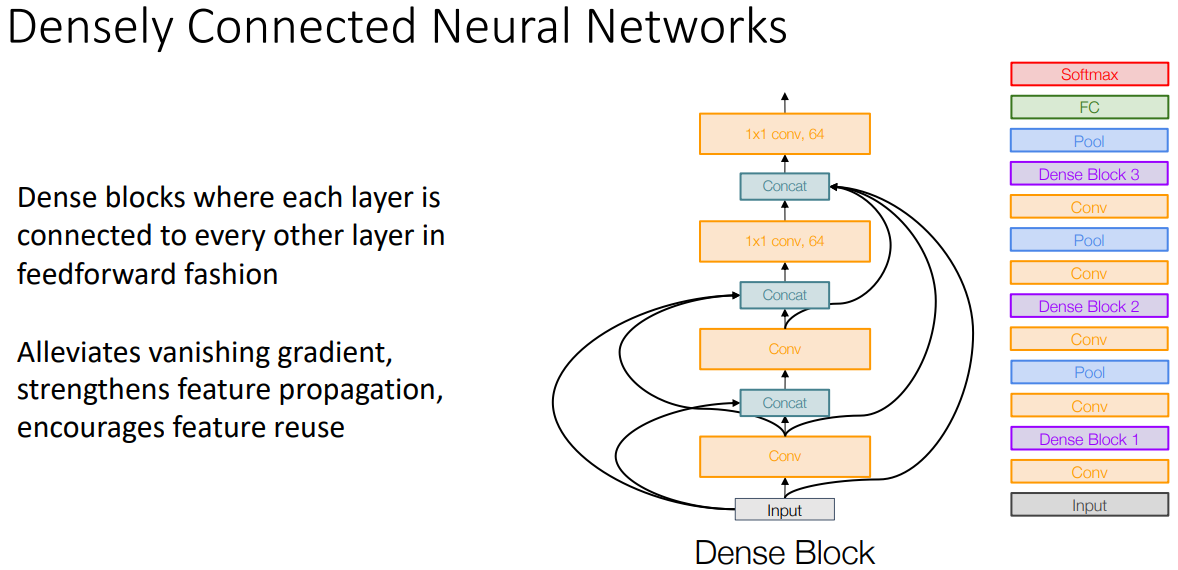
- 이전 레이어의 feature를 다음 feature에 더하는 대신 concat 시키며 바로다음 이외에도 여러곳에서 concat 과정을 반복하여 수행했다.

- 정확도 대신 연산량을 최대한 줄인 모델으로 Repeated Block과정을 수행하는데 왼쪽의 과정을 오른쪽으로 변환하였다.


- 모델을 만든다는 삽질?을 하지 말고 정확도를 원할경우 ResNet을 효율성을 원하다면 MobileNets과 ShuffleNets을 사용하길 권한다.
참고자료
cs231n 강의 자료
cs231n 한글 강의 자료
EECS 498-007 / 598-005 2019 강의 자료
