CS231N, EECS 498-007 / 598-005에서 나타나는 개념을 정리하기 위하여 복기용도로 작성하였습니다.
간단히 정리한 내용을 살펴보며 모르는 부분이 있을 때 찾아보는 용도로 보시면 좋을 것 같습니다.
학습 후기
이번 강의에서는 다양한 하드웨어적인 내용들과 더불어 여려가지의 내용들이 있지만 제가 생각하기에 중요한 내용들만 추려서 정리했습니다.
PyTorch
PyTorch: Fundamental Concepts
- Tensor: 다차원의 배열형태로 GPU에서 동작합니다.
- Autograd: 자동으로 computational graph를 build up하고 backpropagate과정을 수행합여 gradient를 구합니다.
- Module: object-oriented Neural Network Layer으로 내부에 자신의 State를 저장하며 composing하여 큰 모델만들기가 쉬워집니다.
Tensor
- Running example: Train a two-layer ReLU network on random data with L2 loss

- 위의 예제로 통해 텐서가 어떻게 작동하는지 단계별로 확인해보자.

- Create random tensors for data and weights
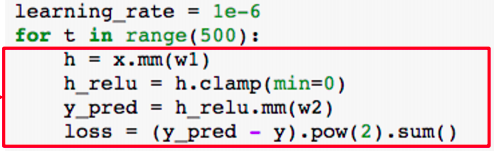
- Forward pass: compute predictions and loss

- Backward pass: manually compute gradients

- Gradient descent step on weights

- To run on GPU, just use a different device!
Autograd
- 텐서를 선언할 때, 파라미터 옵션을 requires_grad=True으로 한다면 computational graph를 build해야 한다.
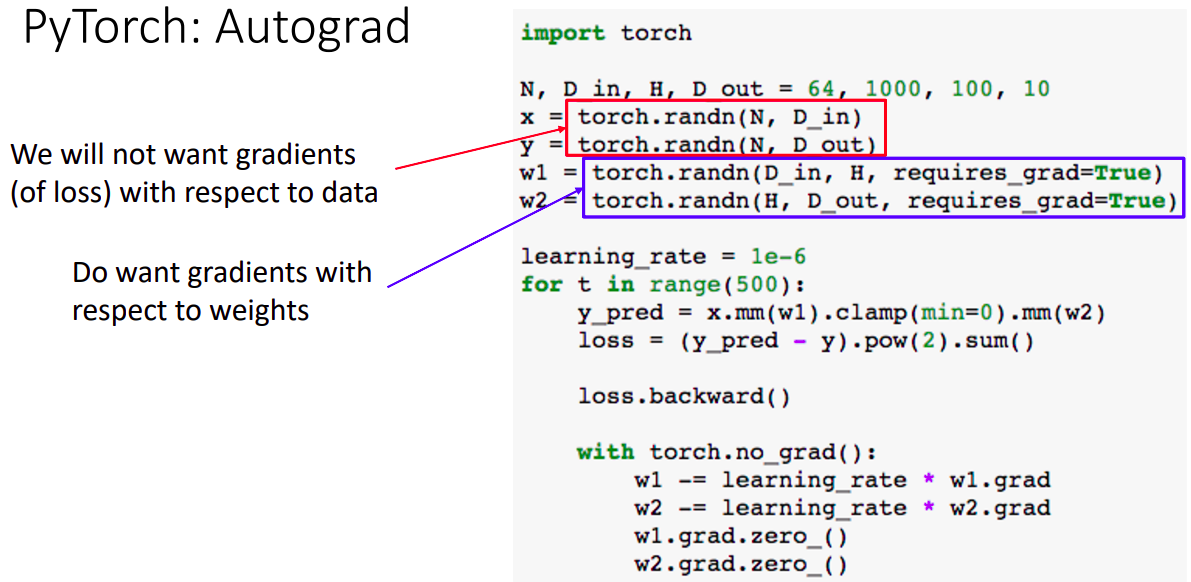
- 빨간 박스의 경우 gradient를 원하지 않는 텐서이며, 파란색 박스는 gradient 계산이 필요한 텐서이다.
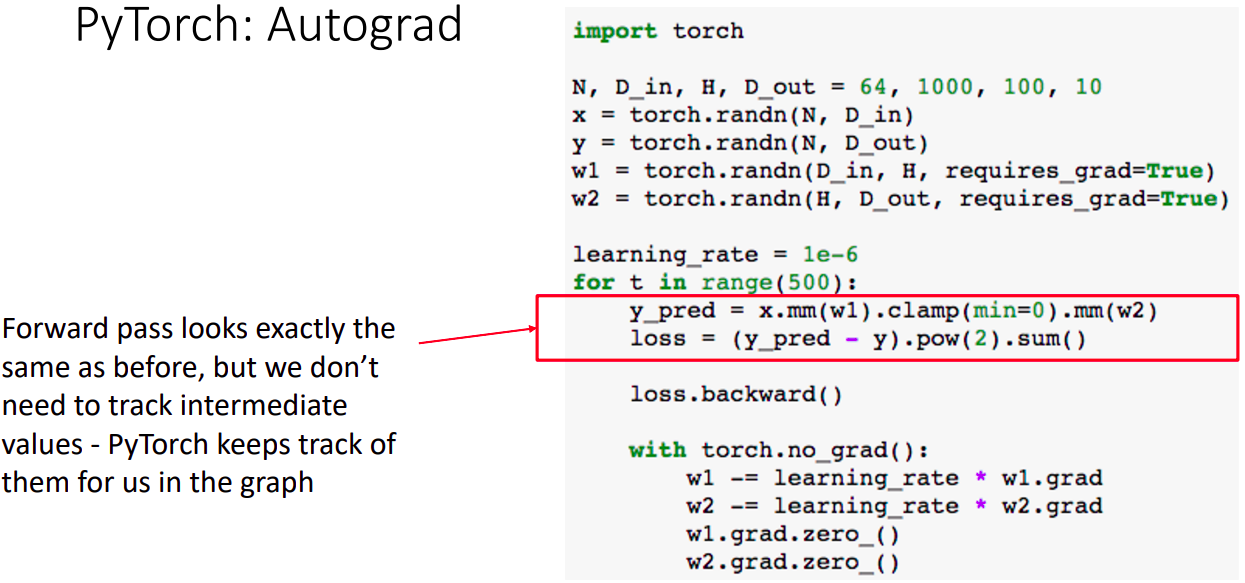
- Forward pass는 이전 예제와 같음을 알 수 있는데, 중간값들을 따로 체크하지 않음을 알 수 있다. (파이토치가 내부적으로 추적하고 있기 때문)

- 단 한줄의 문장이 그래프를 탐색하면서 "requires_grad=True" 인 모든 weight값의 gradient를 계산한다.
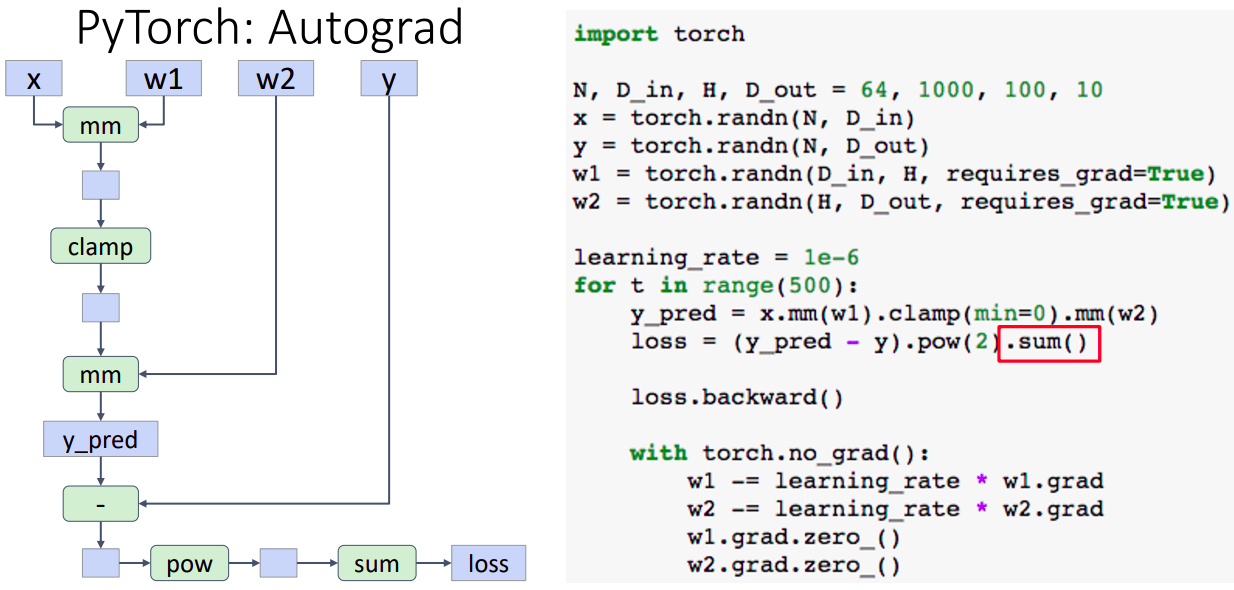
- requires_grad=True인 텐서가 연산작업이 생길때마다 자동적으로 computational graph에 추가하며 resulting tensors도 requires_grad=True인 텐서가 된다.
- 왼쪽의 그림: 연산작업이 추가 될때마다 그래프에 추가된 모습
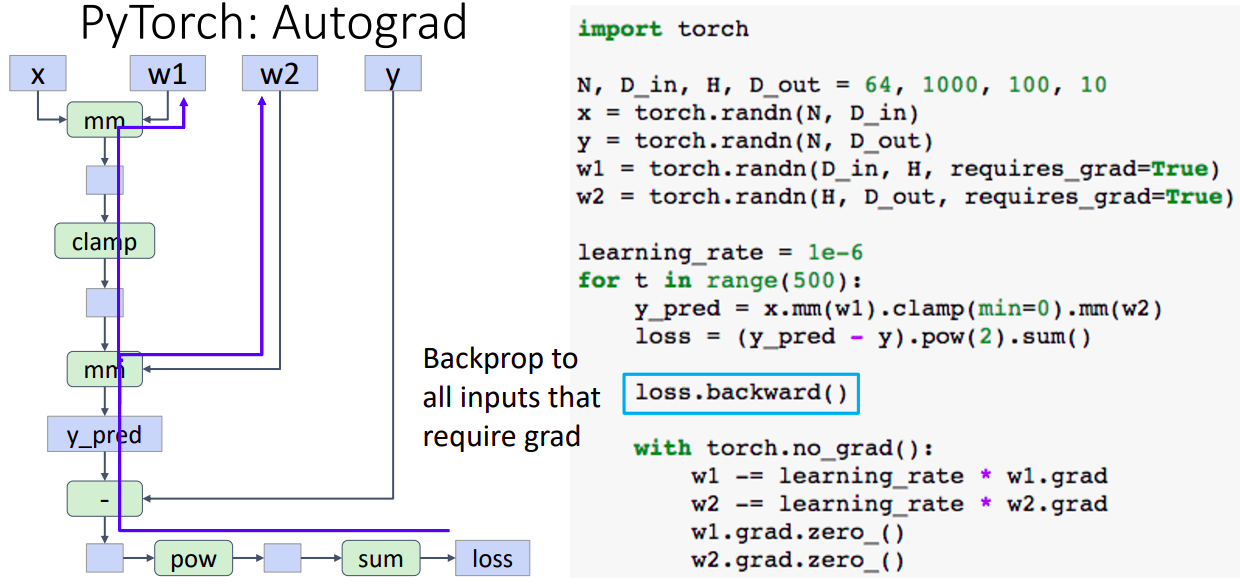
- loss는 그래프의 말단 노드이며 이 작업이 수행될 때, 그래프의 모든 requires_grad=True인 텐서를 탐색하고 backprop과정을 수행한다.
- backward과정이 끝나면, gradient가 weight인 w1.grad와 w2.grad에 축적되며 그래프는 destroyed 된다.

- weights에 대해 gradient step을 진행한다.
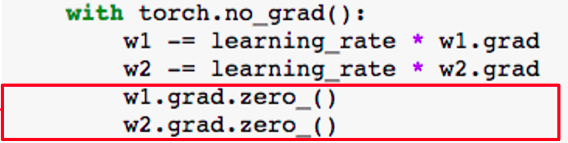
- gradient step을 진행한 이후 명시적으로 0으로 설정해야 한다. 잊어버리면 버그 발생의 원인이라고 합니다. (grad가 축적되기 때문)
- with torch.no_grad() 구문아래에서 gradient update과정이 진행됨이 이상해보이는데, 파이토치에게 이 구문 아래에서는 computational graph 생성을 하지말라는 의미이다.
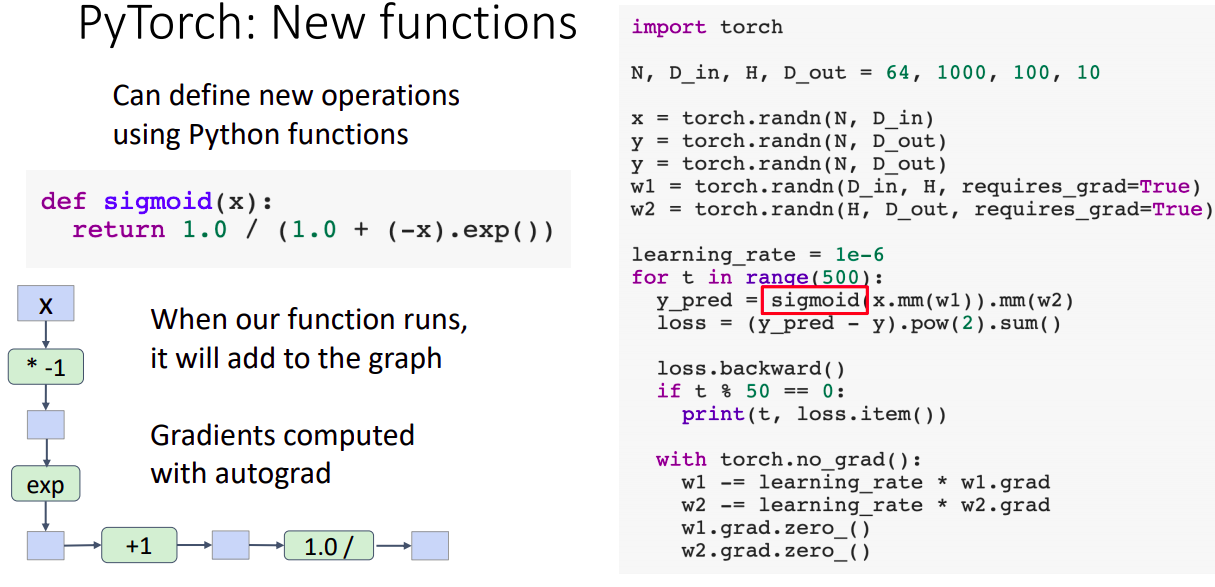
- 파이선 function으로 새로운 연산을 추가 할 수 있다. 입력값과 출력값을 tensor형식으로 구성하고 이를 modular computaion이라고 표현한다.
- 주의 할 점은 내부적 연산이 primitive한 연산단위로 computational graph 구성되어 각 단계마다 gradient를 구해야한다. 따라서 일부 연산의 경우 backprob 도중 overflow 혹은 무한대 등의 불안정한 결과가 나타날 수 있다.

- 이를 대신하여 autograd.Function을 subclassing하여 구성한다면 (backward 과정 연산이 한번에 표현됨을 알고 있으니) 이를 사용하여 computational node가 단일하게 하나로 구성됨을 알 수 있다.
- 이럼에도 불구하고 이렇게 구현하는 것은 굉장히 드문 케이스?이며 차라리 파이선 함수로 구현하는 것이 충분히 괜찮다고?한다.
PyTorch: nn

- Higher-level wrapper으로 네트워크 구성이 간단해짐을 알 수 있다.

- Object-oriented API으로 모델 object가 layer object의 sequence으로 구성되며 각 layer는 weight tensor을 가지고 있다.
- torch.nn.Sequential 은 Container Object으로 layer object를 sequence 형태로 구성할 수 있다. 그리고 내부의 layer들은 learnable weight와 bias를 attribute 형태로 가지고 있다.

- Forward Pass: 데이터를 넣어주고 결과를 받아서 로스를 torch.nn에서 지원하는 api로 계산한다.

- Backward Pass: 정의한 모델 object내에 learnable weigth들이 들어있고, Backpropagation으로 해당 weight값들의 gradient를 구해준다.
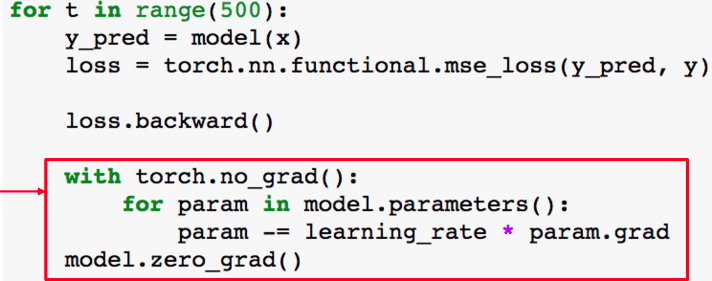
- 모델의 각 Parameter들의 gradient값을 업데이트 한다. 이후 초기화 수행한다.
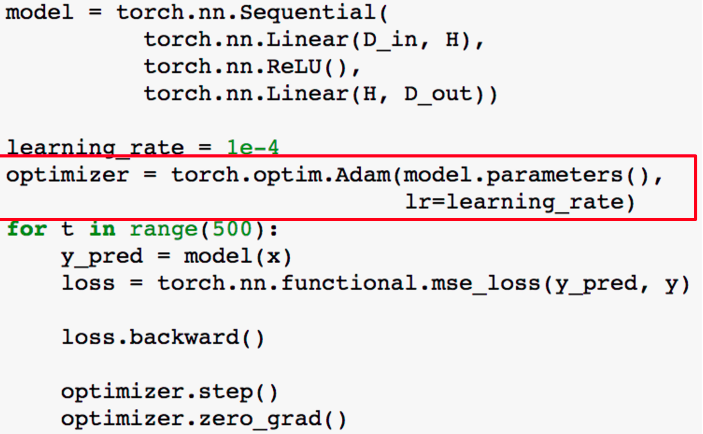
- gradient descent과정을 구현하는것이 귀찮기 때문에 제공되는 optimizer object를 사용한다.
PyTorch: Module
- PyTorch Module은 neural net layer으로 입력이나 출력 텐서 모듈은 weight나 다른 모듈을 포함할 수 있다. 나만의 모델이나 레이어를 정의 할 때는 custom Module로 만드는 것이 가장 일반적인 방법이다.
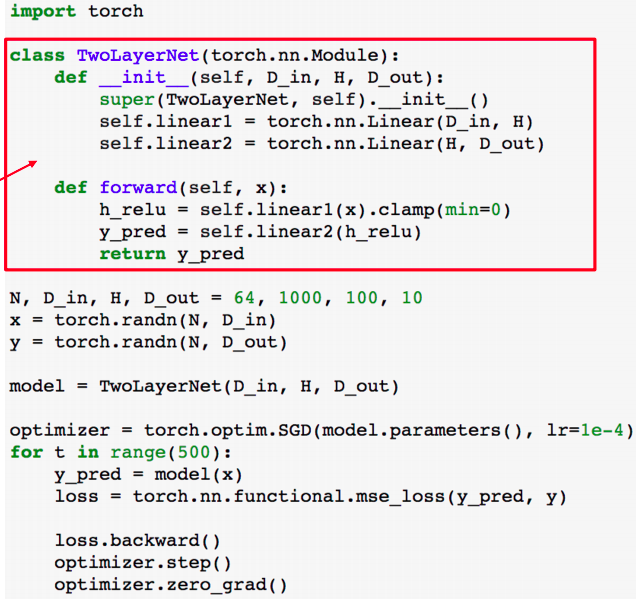
- 나만의 전체 모델을 단일한 module으로 구성하는데 torch.nn.module을 상속 받아 사용한다.
- 초기화 부분에서 레이어의 입,출력값의 크기를 설정해준다. 예제에는 레이어지만 다른 모듈도 이곳에서 사용할 수 있다.
- forward부분에서 선언한 모듈이나 텐서 연산을 사용하여 구성할 수 있다. backward는 autograd가 자동적으로 구성한다.

- 이러한 방식은 residual network처럼 반복적으로 사용되는 구성을 모듈화하여 다른 모듈이나 sequence에 재 사용할 수 있다.
PyTorch: DataLoaders
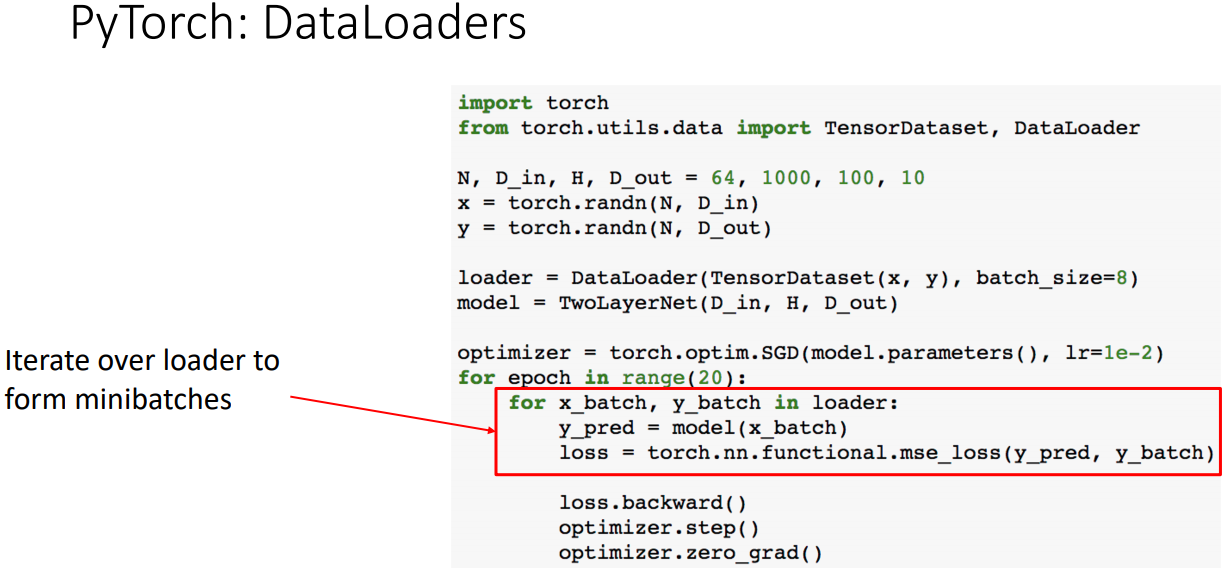
- DataLoader는 Dataset을 미니배치구성, 셔플, 멀티스레드구성 등을 수행한다. 나만의 data를 load할 경우 Dataset클래스를 만들어 사용한다.
PyTorch: Pretrained Models

- pretrained model을 로드하여 사용할 수 있다.
PyTorch: Dynamic Computation Graphs

- every iteration 마다 그래프(Computation Graphs)를 build하고(Dynamic) 버리고, 다시 rebuild하는 과정이 굉장히 비효율적으로 보인다.
- 그러나 장점은 regular python control flow을 사용하여 뉴럴넷을 구성할 수 있다는 것이다. 권장하지는 않지만 every iteration 마다 그래프 구성을 다르게 할 수도 있다.
Static Computation Graphs
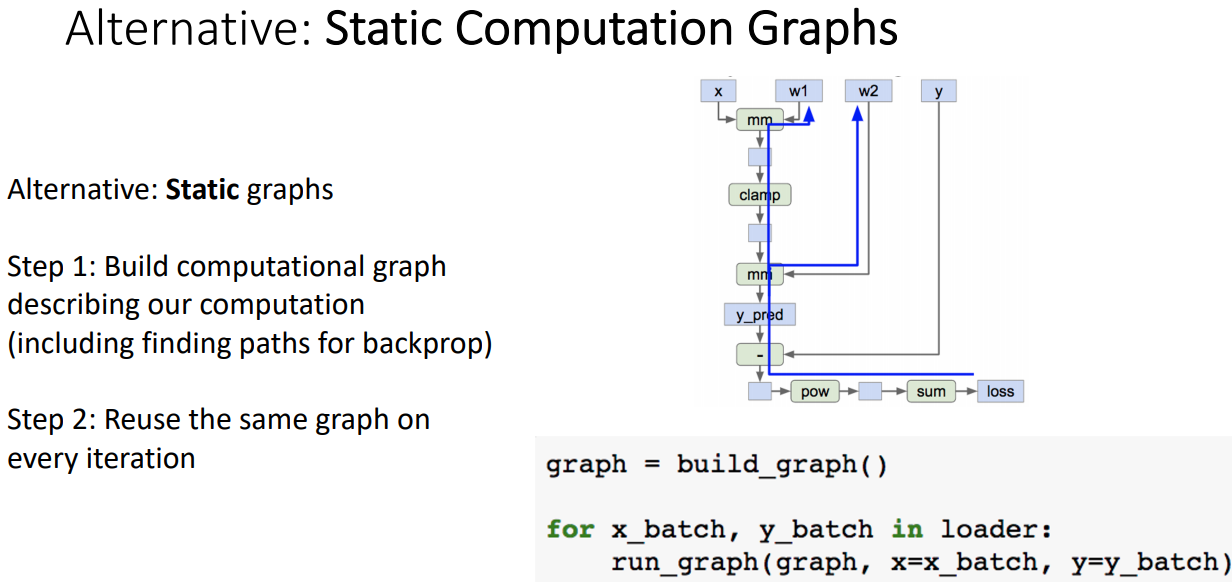
- Computation Graphs를 미리 구성하고(backprop과정도 함께), 이 그래프를 every iteration 마다 재사용 할 수 있다.
PyTorch: Static Graphs with JIT
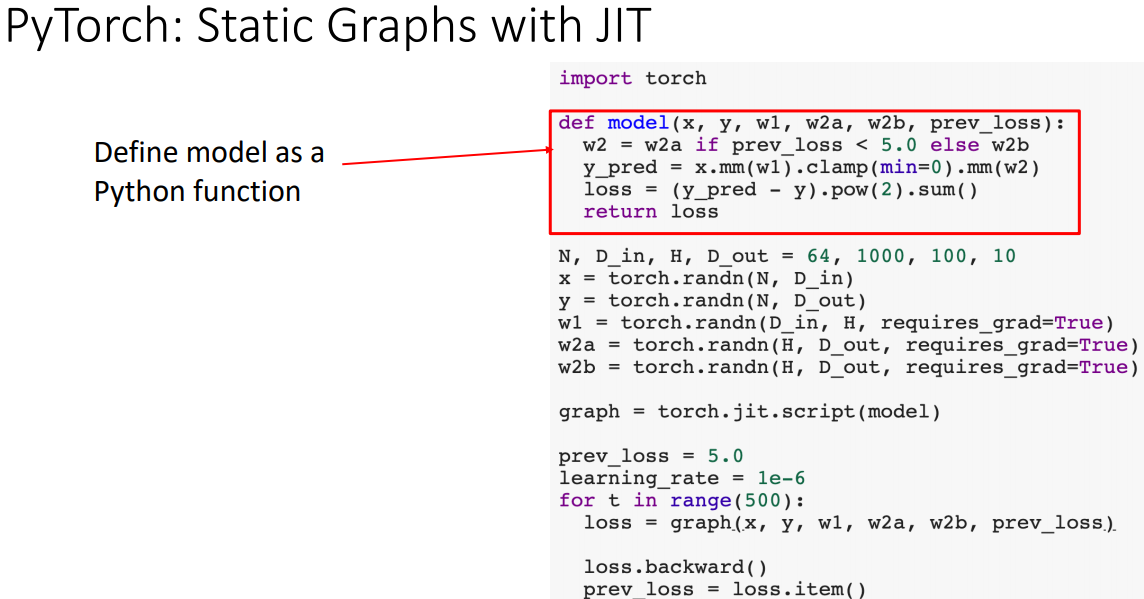
- Static 구성과 같이 파이선 함수로 모델을 정의 한다.

- 마법같은 라인?이 파이선 소스 코드를 Introspect하며, 자동적으로 탐색한 뒤에 Computation Graphs를 build한다. 이 후 graph object를 리턴해준다. 재미있는 점은 그래프내부에 조건절이 있는데 이를 하나의 노드로 구성됨을 볼 수 있다.
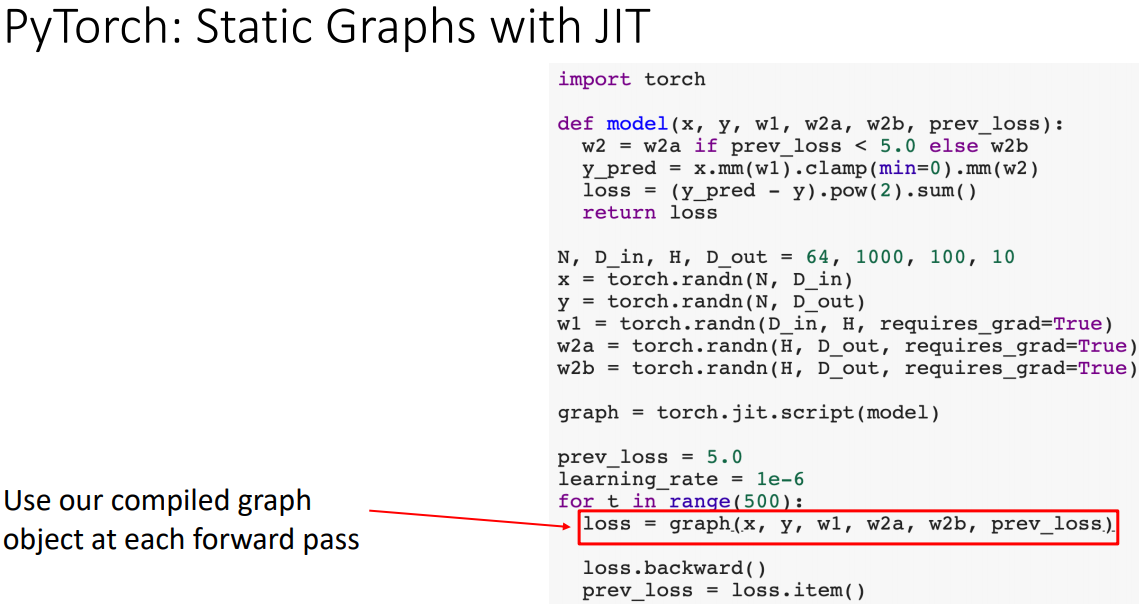
- 반복문 아래에서 그래프를 재사용한다.

- 명시적으로 코드를 컴파일하는 대신, 모델함수에 annotation과 torch.jit.script를 붙이면 그 함수가 정의 될 때 컴파일 해준다.
Static vs Dynamic Graphs: Optimization
Static 장점1
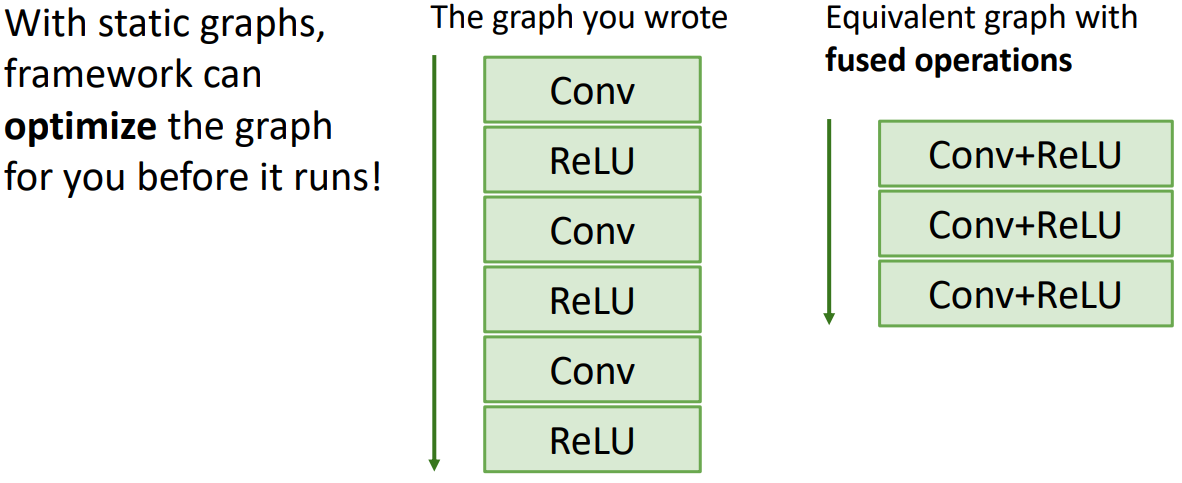
- 정적 구성의 장점은 최적화의 잠재력(potential for optimization)이 있다는것이다.
- 그래프가 굉장히 길게 구성될 경우, compiler technique 사용하면 그래프를 재사용하여 효율적인 계산이 가능하다. 예를 들면 몇가지 연산들을 fuse하여 연산이 빠르게 되도록 구성 할 수 있다.
Static 장점2

- Static 그래프는 학습을 다 한뒤에 deploy 할 때, deploy 환경이 파이선에 의존적이지 않아도 된다.
Static 단점1

- 디버깅이 상대적으로 불편하다. 작성한 코드와 실제 돌아가는 코드의 indirection이 크다.
Dynamic 특징
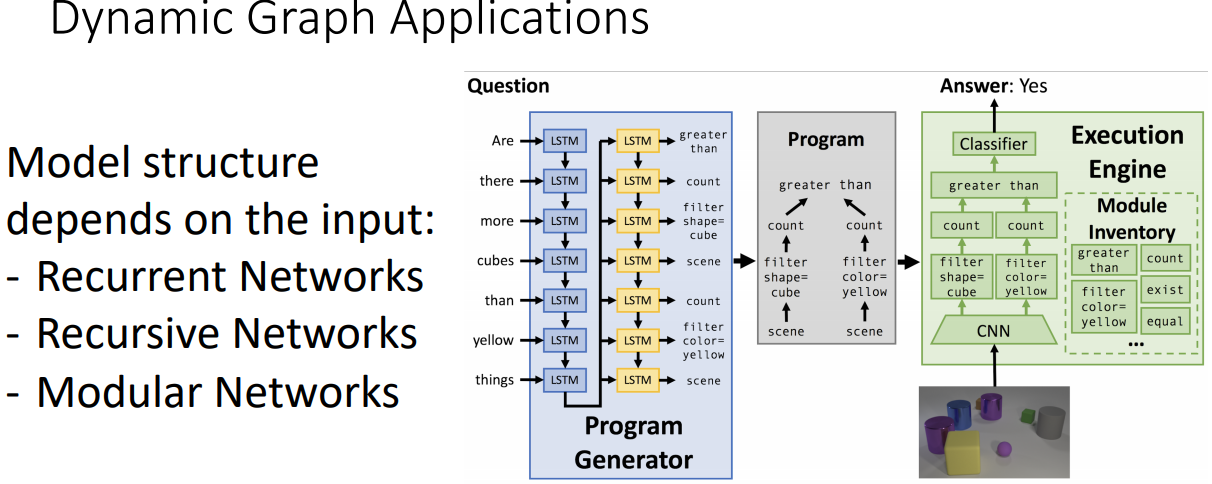
- Dynamic은 입력값에 의존적이다. Recurrent Networks의 sequnce길이나 Recursive Networks에서 parse tree구성, Modular Networks에서 입력값에 따른 모델 선택이 달라진다.
TensorFlow
TensorFlow: History

- 1버전에서는 static이 기본이였지만 2로 넘어와서는 Dynamic으로 바뀌었다. TF와 Torch 모두 상호보완하는? 모습.
TensorFlow: Dynamic Graph
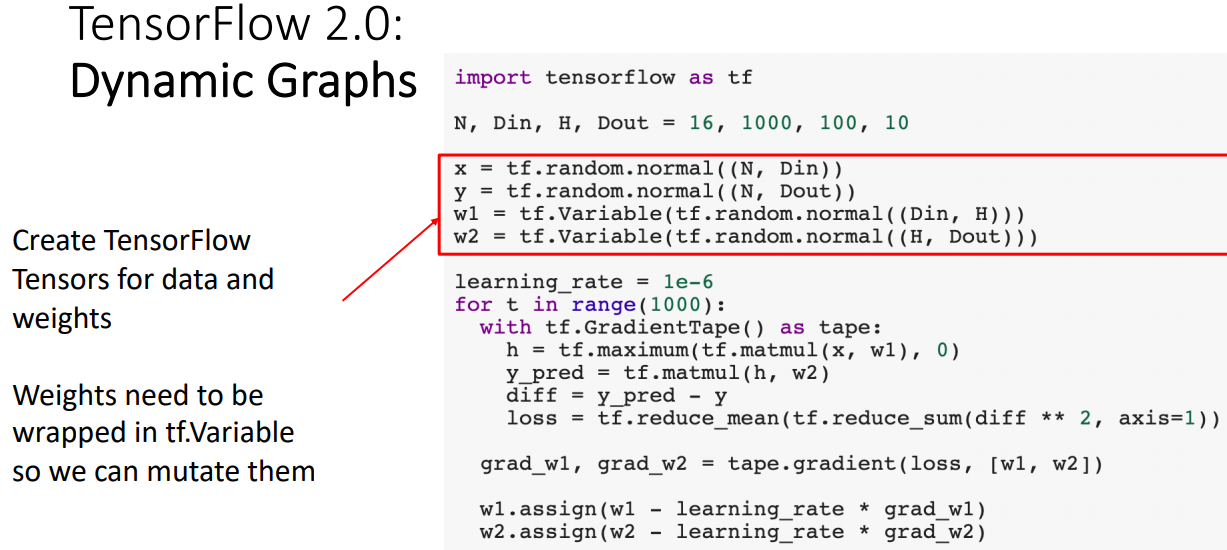
- 토치 코드 구성과 동일하며 weight가 필요한 경우 tf.Variable으로 wrap하여 사용한다.
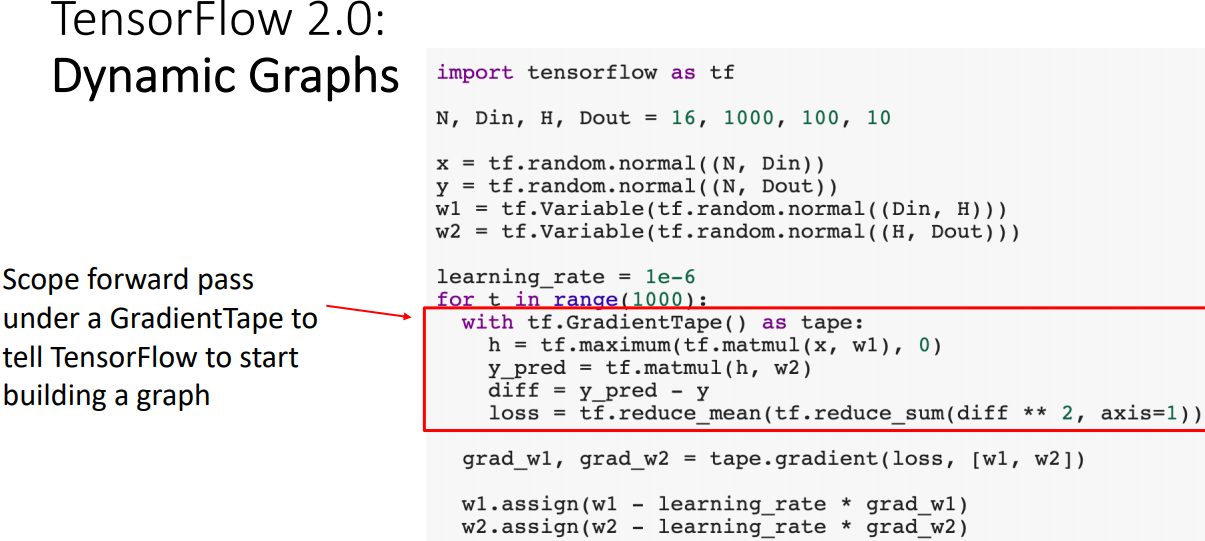
- gradient를 추적하기 위해 with구문을 사용하여 with내의 연산은 Computation Graphs를 구성하는 것이다.

- tape scope이후 tape.gradient에서 gradients를 계산한다.
- 이후 weight update를 수행한다.
TensorFlow: Static Graph
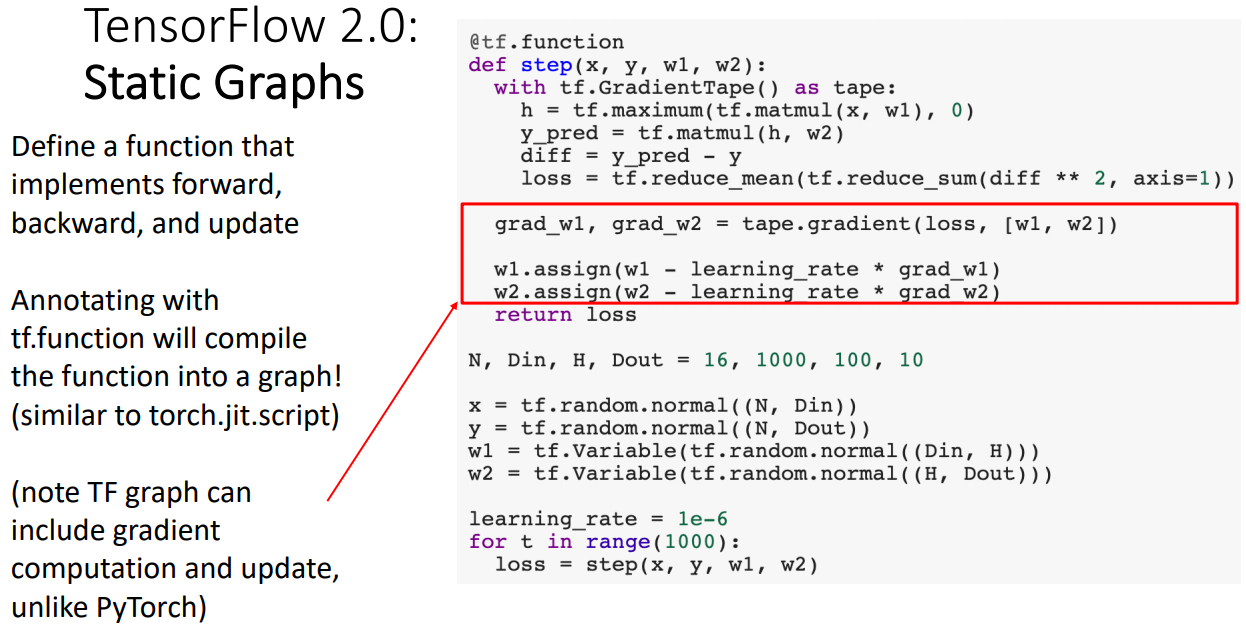
- static 구성시 함수와 annotation을 함께 정의 해주고, forward/backward/update과정을 구현한다.
- TF에서는 파이토치와는 달리 gradient 계산과정과 update과정이 static graph구성에 포함되어야 한다.
- 마지막 라인에서 보듯이 단순히 컴파일된 step함수만 호출하면 된다.
TensorFlow: Keras(High-level API)
Version: 1
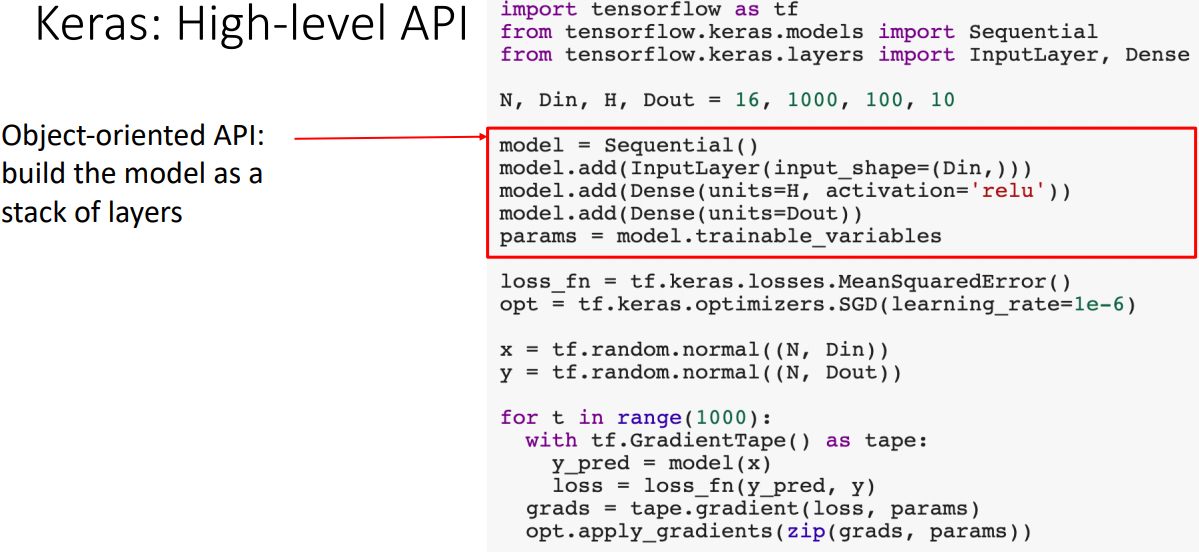
- torch.nn과 비슷하게 모델을 레이어를 쌓아서 구성한다.
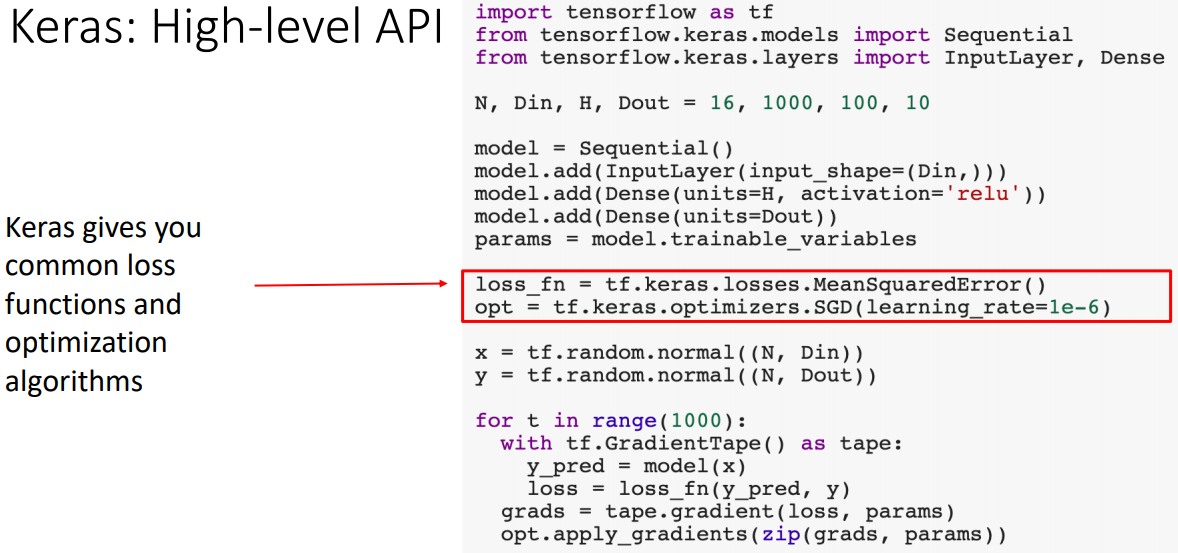
- optimizer와 loss를 정의한다.
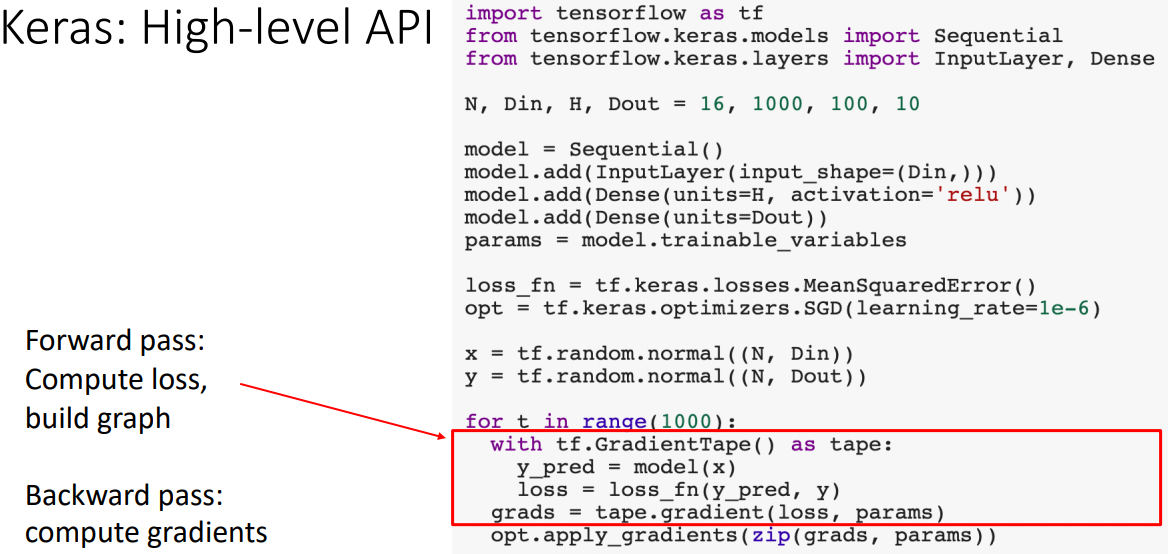
- forward/backward/update과정을 수행한다.
Version: 2

- loss를 리턴하는 함수를 정의하여 optimizer가 gradient를 계산하고 파라미터 update를 수행하도록 구성 할 수도 있다.
TensorFlow: TensorBoard
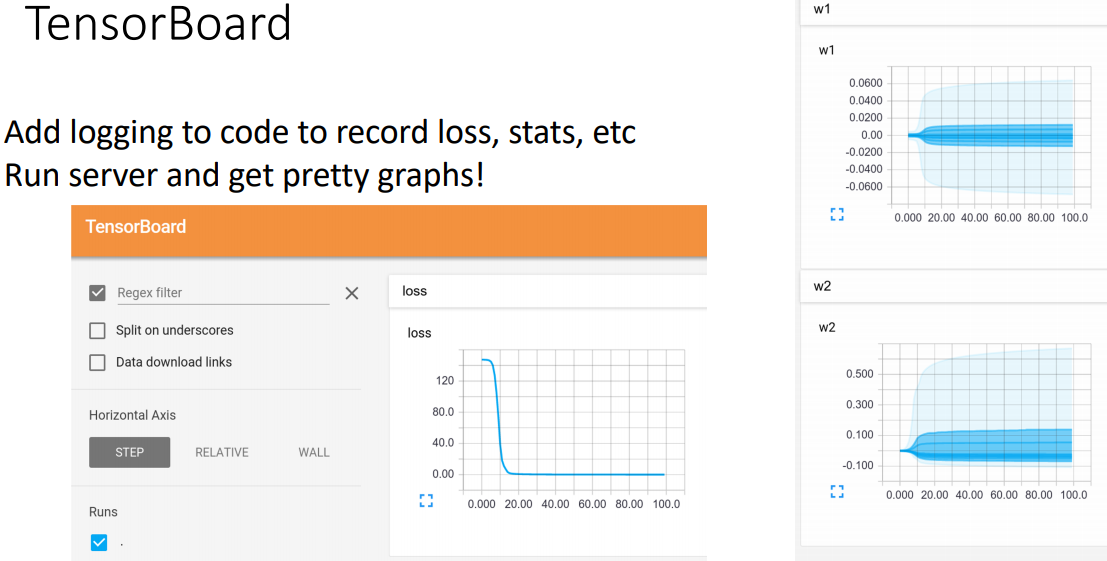
- 모델의 통계 및 수치를 추적하는 웹서버이다.
- 소스 코드 내부에 logging code를 추가하여 다양한 값을 기록할 수 있다.
- PyTorch에서도 torch.utils.tensorboard를 이용하여 사용할 수 있다.
PyTorch VS TensorFlow

- PyTorch는 JIT이 모바일 환경이 아닌곳에서 deploy가 가능하지만 아이폰환경에서는 사용이 어렵다고 한다.
- 연구의 대부분은 PyTorch를, 일부 프로덕션용 기업에서는 TF를 사용하는 것으로 보인다.
참고자료
cs231n 강의 자료
cs231n 한글 강의 자료
EECS 498-007 / 598-005 2019 강의 자료
