Augmentation
우리가 현실의 문제를 해결하기 위해 맞닥뜨려야 하는 데이터들은 충분히 모으기도 쉽지 않지만 고품질로 정제하는 과정도 만만치 않다.
제한된 데이터셋을 최대한 활용하기 위해서 augmentation방법을 사용할 수 있다.
Data augmentation은 갖고 있는 데이터셋을 여러 가지 방법으로 증강시켜(augment) 실질적인 학습 데이터셋의 규모를 키울 수 있는 방법이다.
데이터가 많아진다 -> 과적합(overfitting)을 줄일 수 있다는 의미
또한 가지고 있는 데이터셋이 실제 상황에서의 입력값과 다를 경우, augmentation을 통해서 실제 입력값과 비슷한 데이터 분포를 만들어 낼 수 있다.
예를 들어, 학습한 데이터는 노이즈가 많이 없는 사진 but 테스트 이미지는 다양한 노이즈가 있는 경우, 테스트에서 좋은 성능을 내기 위해서 노이즈의 분포를 예측하고 학습 데이터에 노이즈를 삽입해 모델이 이런 노이즈에 잘 대응할 수 있도록 해야 함.
이렇게 data augmentation은 데이터를 늘릴 뿐만 아니라 모델이 실제 테스트 환경에서 잘 동작할 수 있도록 도와주기도 한다.
이미지 데이터의 augmentation은 포토샵, SNS의 사진 필터, 각종 카메라 앱에서 흔히 발견할 수 있는 기능들과 비슷. 인스타의 필터 or 좌우 대칭, 상하 반전 같은 이미지 공간적 배치 조작도 포함.
다양한 Image Augmentation 방법
Flipping

이미지를 대칭.
분류 문제에서는 문제가 없을 수 있음 but 물체 탐지(detection), 세그멘테이션(segmentation) 문제 등 정확한 정답이 존재하는 문제에는 라벨도 같이 좌우 반전을 해주어야 함.
Gray scale
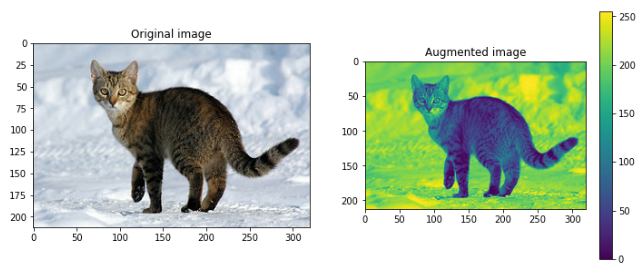
그레이 스케일은 3가지 채널(channel)을 가진 RGB 이미지를 하나의 채널을 가지도록 해줌.
(예제는 흑백 대신 다른 색상으로 이미지를 표현)
Saturation
RGB 이미지를 HSV(Hue(색조), Saturation(채도), Value(명도)의 3가지 성분으로 색을 표현) 이미지로 변경하고 S(saturation) 채널에 오프셋(offset)을 적용, 조금 더 이미지를 선명하게 만들어 준다. 이후 다시 우리가 사용하는 RGB 색상 모델로 변경해준다.
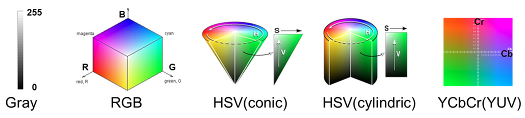
-
Gray 모델 - 색(Color) 정보를 사용X, 밝기 정보만으로 영상을 표현. 검정(0)부터 흰색(255)까지 총 256단계의 밝기 값(Intensity)으로 영상 픽셀 값을 표현.
-
RGB 모델 - 가장 기본 색상 모델. 색(Color)을 Red, Green, Blue의 3가지 성분의 조합으로 생각.
검은색: R,G,B=0,
흰색: R,G,B=255,
빨간색: R=255, G,B=0,
노란색: R=G=255, B=0.
R=G=B인 경우, 무채색인 Gray 색상.
R, G, B 각각은 0 ~ 255 사이의 값을 가질 수 있으므로, RGB 색상 모델을 사용하면 총 256 256 256 = 16,777,216 가지의 색을 표현할 수 있음. -
HSV 모델 - Hue(색조), Saturation(채도), Value(명도)의 3가지 성분으로 색을 표현.
Hue는 색조 (붉은색 계열인지 푸른색 계열인지)를 나타내고, Saturation은 그 색이 얼마나 선명한(순수한) 색인지, Value 는 밝기(Intensity).
HSV 모델은 우리가 색을 가장 직관적으로 표현할 수 있는 모델. 머리속에서 상상하는 색을 가장 쉽게 만들어낼 수 있음.영상/이미지 처리 에서 HSV 모델을 사용시 H, S, V 각각은 0 ~ 255 사이의 값으로 표현. H 값은 색의 종류를 나타내기에 크기는 의미X, 단순한 인덱스(Index)임.
S 값은 0이면 무채색 (gray 색), 255면 가장 선명한(순수한) 색임을 나타냅니다.
V 값은 작을수록 어둡고, 클수록 밝은 색.
HSV 색상 모델은 그림과 같이 원뿔(conic) 형태, 원기둥(cylindric) 형태가 있습니다.

Brightness
밝기조절
Rotation
회전, 90도 단위로 돌리지 않는 경우 직사각형 형태에서 기존 이미지로 채우지 못하는 영역을 어떻게 처리해야 할지 유의해야 한다.

Center Crop
이미지의 중앙을 기준으로 확대

Augmentation 심화
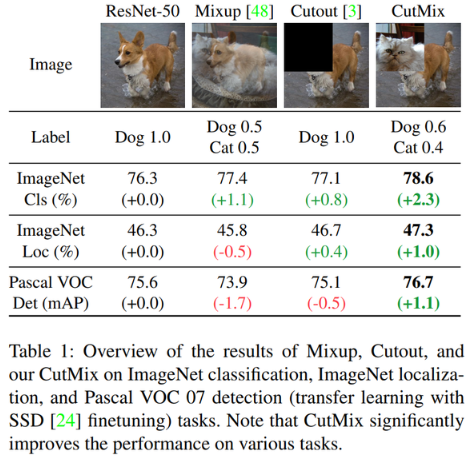
Cutmix Augmentation
네이버 클로바(CLOVA)에서 발표한 CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features 에서 제안된 방법.
Mixup은 특정 비율로 픽셀별 값을 섞는 방식이고, Cutout은 이미지를 잘라내는 방식
CutMix는 Mixup과 비슷하지만 일정 영역을 잘라서 붙여주는 방법