모델 최적화하기 (1) Neural Architecture Search
지금까지 봤던 방법은 사람이 고안한 방식을 네트워크 구조에 적용하여 효과를 봤던 방법.
모델의 훈련은 컴퓨터가 시켜줄 수 있어도, 어떤 모델 구조가 좋을지는 사람이 직접 고민하고 실험해 보아야 했음.
새로운 모델 구조를 고안하고 이해하는 과정을 반복하다 보면, "우리가 딥러닝으로 이미지 분류 문제를 풀기 위해 딥러닝 모델의 파라미터(parameter)를 최적화해 왔듯이 모델의 구조 자체도 최적화할 수는 없을지" 생각하게 됨.
이렇게 여러 가지 네트워크 구조를 탐색하는 것을 아키텍쳐 탐색(architecture search)라고 함.
그중 신경망을 사용해 모델의 구조를 탐색하는 접근 방법을 NAS(neural architecture search) 라고 함.
1. NASNet
NASNet: NAS에 강화학습을 적용하여 500개의 GPU로 최적화한 CNN 모델들
꼭 NASNet이 아니더라도 일반적으로 머신 러닝에서는 그리드 탐색(grid search) 등으로 실험과 모델 셋팅(config)를 비교하기 위한 자동화된 방법을 사용하곤 함.
그리드 탐색은 간단히 말하면 모든 조합을 실험해보는 것. 그러나 그리드 탐색은 모델에서 바꿔볼 수 있는 구성의 종류가 매우 많아 머신 러닝 중에서도 학습이 오래 걸리는 딥러닝에서는 적합하지 않다.
딥러닝에서 모델을 탐색하기 위해 강화학습 모델이 대상 신경망의 구성(하이퍼파라미터)을 조정하면서 최적의 성능을 내도록 하는 방법이 제안되었으며, NASNet은 그중 하나임.
아키텍쳐 탐색을 하는 동안 강화학습 모델은 대상 신경망의 구성을 일종의 변수로 조정하면서 최적의 성능을 내도록 한다.
(레이어의 세부 구성, CNN의 필터 크기, 채널의 개수, connection 등이 조정할 수 있는 변수)
이렇게 네트워크 구성에 대한 요소들을 조합할 수 있는 범위를 탐색 공간(search space)이라고 함.
이 공간에서 최고의 성능을 낼 수 있는 요소의 조합을 찾는 것
NASNet이 NAS를 처음 적용한 것은 아님.
이전의 방식 중에 MNIST에 최적화하는데 800개의 GPU를 사용해서 28일이 걸린게 있음(밑의 사진이 그 구조).
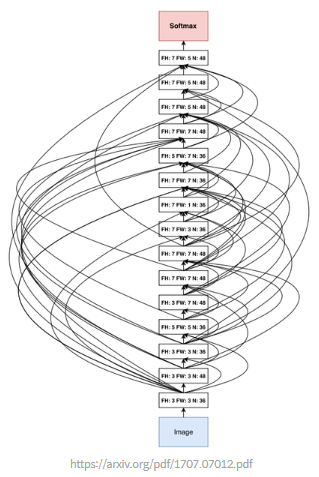
NASNet 논문은 이미지넷 데이터에 대해 이보다 짧은 시간 안에 최적화를 함.
Convolution cell
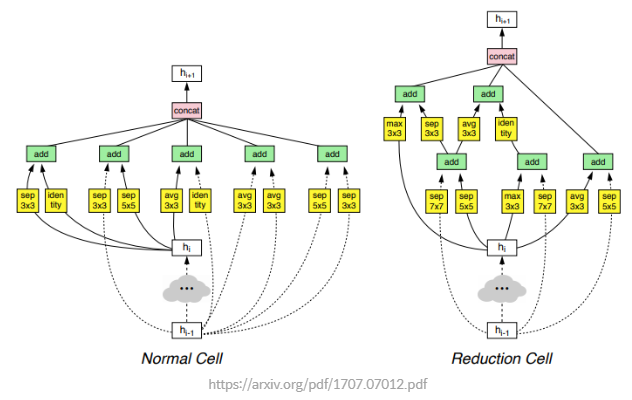
레이어 하나마다의 하이퍼 파라미터를 조절하면 탐색 공간이 너무 방대해져 찾아야 될 공간이 넓어진다. 따라서 오랜 시간이 걸린다.
NASNet 논문에서는 이러한 탐색 공간을 줄이기 위해서 모듈(cell) 단위의 최적화를 하고 그 모듈을 조합하는 방식을 채택.
ResNet에는 Residual Block, DenseNet에는 Dense Block이라는 모듈이 사용되는데, 논문에서는 이와 유사한 개념을 convolution cell이라고 부름.
Convolution cell은 normal cell과 reduction cell로 구분.
Normal cell: 특성 맵의 가로, 세로가 유지되도록 stride를 1로 고정.
Reduction cell: stride를 1 또는 2로 가져가서 특성 맵의 크기가 줄어들 수 있도록 함.
논문의 모델은 normal cell과 reduction cell 내부만을 최적화하며, 이렇게 만들어진 convolution cell이 위 그림의 두 가지임.
두 가지 cell을 조합해 최종 결과 네트워크(NASNet)를 만들었으며, 좀 더 적은 연산과 가중치로 SOTA(state-of-the-art) 성능을 기록했다고 함.
모델 최적화하기 (2) EfficientNet
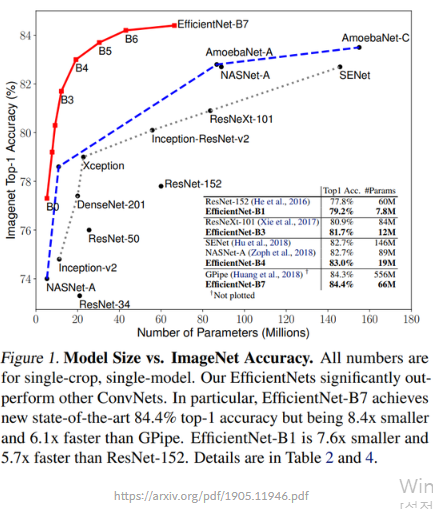
EfficientNet은 기존 모델들의 오류율을 뛰어넘을 뿐만 아니라 모델의 크기인 "Number of Parameters" 또한 최적화된 것을 볼 수 있음.
빨간색 선: EfficientNet의 모델
정확도를 얻는 데 다른 네트워크들은 무지막지한 파라미터의 수를 사용한 반면 EfficientNet은 작고 효율적인 네트워크를 사용함.
EfficientNet은 우리가 이미지에 주로 사용하는 CNN을 효율적으로 사용할 수 있도록 네트워크의 형태를 조정할 수 있는 width, depth, resolution 세 가지 요소에 집중
width는 CNN의 채널에 해당. 채널을 늘려줄수록 CNN의 파라미터와 특성을 표현하는 차원의 크기를 키울 수 있다.
depth는 네트워크의 깊이. ResNet은 대표적으로 네트워크를 더 깊게 만들 수 있도록 설계해 성능을 올린 예시.
resolution은 입력값의 너비(w)와 높이(h) 크기입니다. 입력이 클수록 정보가 많아져 성능이 올라갈 여지가 생기지만 레이어 사이의 특성 맵이 커지는 단점이 있다.
Compound scaling
EfficientNet은 resolution, depth, width를 최적으로 조정하기 위해서 앞선 NAS와 유사한 방법을 사용해 기본 모델(baseline network)의 구조를 미리 찾고 고정해둔다.
모델의 구조가 고정이 되면 효율적인 모델을 찾는다는 커다란 문제가, 개별 레이어의 resolution, depth, width 를 조절해 기본 모델을 적절히 확장시키는 문제로 단순화된다.

그리고 EfficientNet 논문에서는 resolution, depth, width라는 세 가지 "scaling factor"를 동시에 고려하는 compound scaling을 제안한다.
compound coefficient ϕ(phi): 모델의 크기를 조정하기 위한 계수.
-> 위 식을 통해 레이어의 resolution, depth, width를 각각 조정하는 것이 아니라 고정된 계수 ϕ에 따라서 변하도록 한다.
보다 일정한 규칙에 따라(in a principled way) 모델의 구조가 조절되도록 할 수 있음.
논문에서는 우선 ϕ를 1로 고정, 그 후 resolution과 depth, width을 정하는 α,β,γ의 최적값을 찾는다.
논문에서는 앞서 설명했던 그리드 탐색으로 α,β,γ을 찾을 수 있었다고 설명함.
이후 α,β,γ, 즉 resolution과 depth, width의 기본 배율을 고정한 뒤 compound coefficient ϕ를 조정하여 모델의 크기를 조정한다.
