Going Deeper
1.ResNet: 딥러닝 논문을 이해하자 I
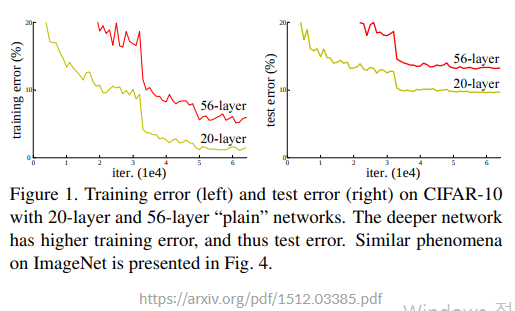
2015년 발표된 ResNet의 원본 논문은 Deep Residual Learning for Image Recognition 이라는 제목으로 Kaiming He, Xiangyu Zhang 등이 작성함.ResNet 논문은 Residual Block이라는 아주 간단하면서도
2.DenseNet과 SENet: 딥러닝 논문을 이해하자 II
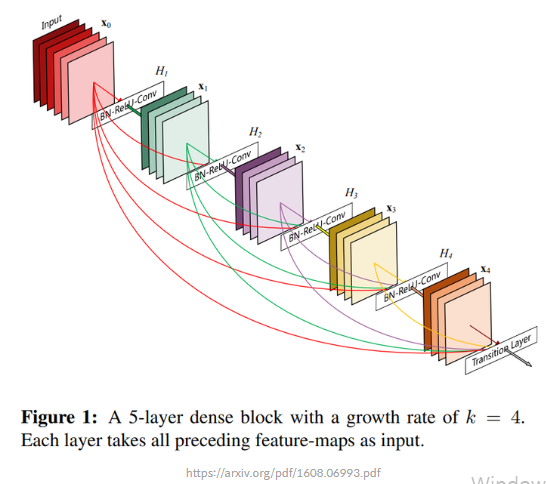
Densely Connected Convolutional Networks의 저자들은 DenseNet이 ResNet의 shortcut connection을 Fully Connected Layer처럼 촘촘히 가지도록 한다면 더욱 성능 개선 효과가 클 것이라고 생각하고 이를
3.NASNet과 EfficientNet: 딥러닝 논문을 이해하자 III
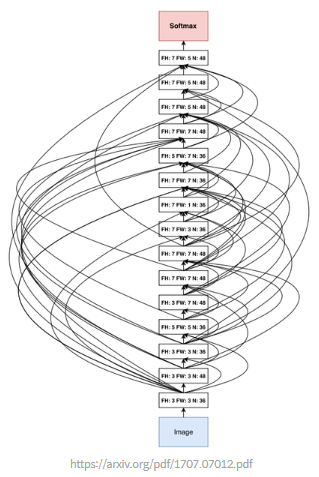
지금까지 봤던 방법은 사람이 고안한 방식을 네트워크 구조에 적용하여 효과를 봤던 방법.모델의 훈련은 컴퓨터가 시켜줄 수 있어도, 어떤 모델 구조가 좋을지는 사람이 직접 고민하고 실험해 보아야 했음.새로운 모델 구조를 고안하고 이해하는 과정을 반복하다 보면, "우리가 딥
4.Image Augmentation
우리가 현실의 문제를 해결하기 위해 맞닥뜨려야 하는 데이터들은 충분히 모으기도 쉽지 않지만 고품질로 정제하는 과정도 만만치 않다.제한된 데이터셋을 최대한 활용하기 위해서 augmentation방법을 사용할 수 있다.Data augmentation은 갖고 있는 데이터셋을
5.Object Detection

Object detection 이미지 내에서 물체의 위치와 그 종류를 찾아내는 것. 이미지 기반의 문제를 풀기 위해서 다양한 곳에서 필수적으로 사용됨. (자율 주행에서 차량, 사람 탐지, 얼굴 인식 등) 1. Object detection의 용어 정리 Classif
6.7. 물체를 분리하자! - 세그멘테이션 살펴보기

세그멘테이션(segmentation): 픽셀 수준에서 이미지의 각 부분이 어떤 의미를 갖는 영역인지 분리해 내는 방법. 이미지 분할 기술