
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 시작하며
이번 16번째 미니 프로젝트에서는 이전 미니 프로젝트에서 실습했던 지도학습이 아닌 비지도학습, 즉 클러스터링 기법을 사용하여 진행했습니다.
이번 프로젝트에서 해결하고자 했던 문제는 가전제품 센서들에서 수집된 데이터를 통해 가전제품 사용 패턴을 군집화였습니다.

가전제품의 경우 사용자만의 사용 특정 패턴이 있을 것입니다. 예를 들어, 냉장고를 여는 횟수, 세탁기 사용 cycle 횟수 등등 여러가지 패턴들이 존재할 것입니다. 이것을 Life Stage라고 부르는데, B2C 기업에서는 해당 패턴을 분석하는 것이 중요합니다.
개인화 혹은 초개인화 마케팅을 위해서는 현재 고객의 상황에 맞는 제품들을 추천하는 것이 중요할 것입니다. 그래야 마케팅 반응률을 높일 수 있기 때문입니다. 모든 사람들에게 mass marketing을 하기에는 비용도 많이 들기 때문에, 가전 사용 패턴을 파악하여 사용자의 현 life stage에 맞게 마케팅을 하는 것이 효율적이고 효과적일 것입니다.
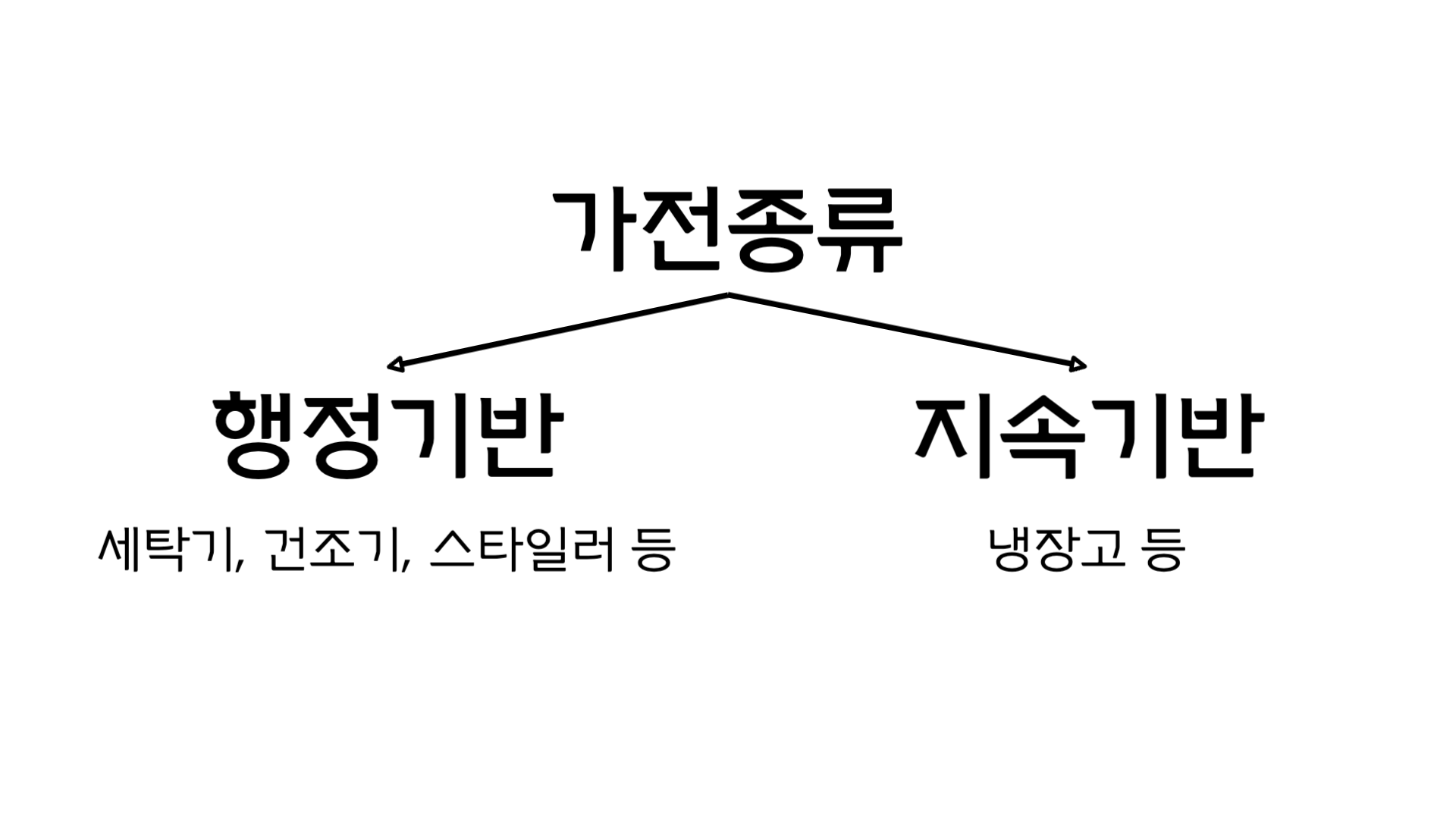
가전에는 두가지 종류가 있습니다. 첫번째로는 행정기반의 가전인데, 1번의 행정으로 수행이 끝나는 가전제품들이 해당됩니다. 예시로는 세탁기, 건조기, 스타일러 등이 있습니다.
이와 반대로 수행이 1번의 사이클로 끝나는 것이 아닌 선이 뽑히기 전까지 지속적으로 작동이 수행되는 가전이 있습니다. 예시로 냉장고, 에어컨 등이 있습니다.
이번 미니 프로젝트에서는 여러 대의 냉장고에서 수집된 데이터로 분석을 했습니다. 한 대의 냉장고에는 여러 개의 센서가 존재합니다. 그렇다면 매일 시간당 혹은 분당으로 수집되는 데이터는 어떻게 분석해야할까요?
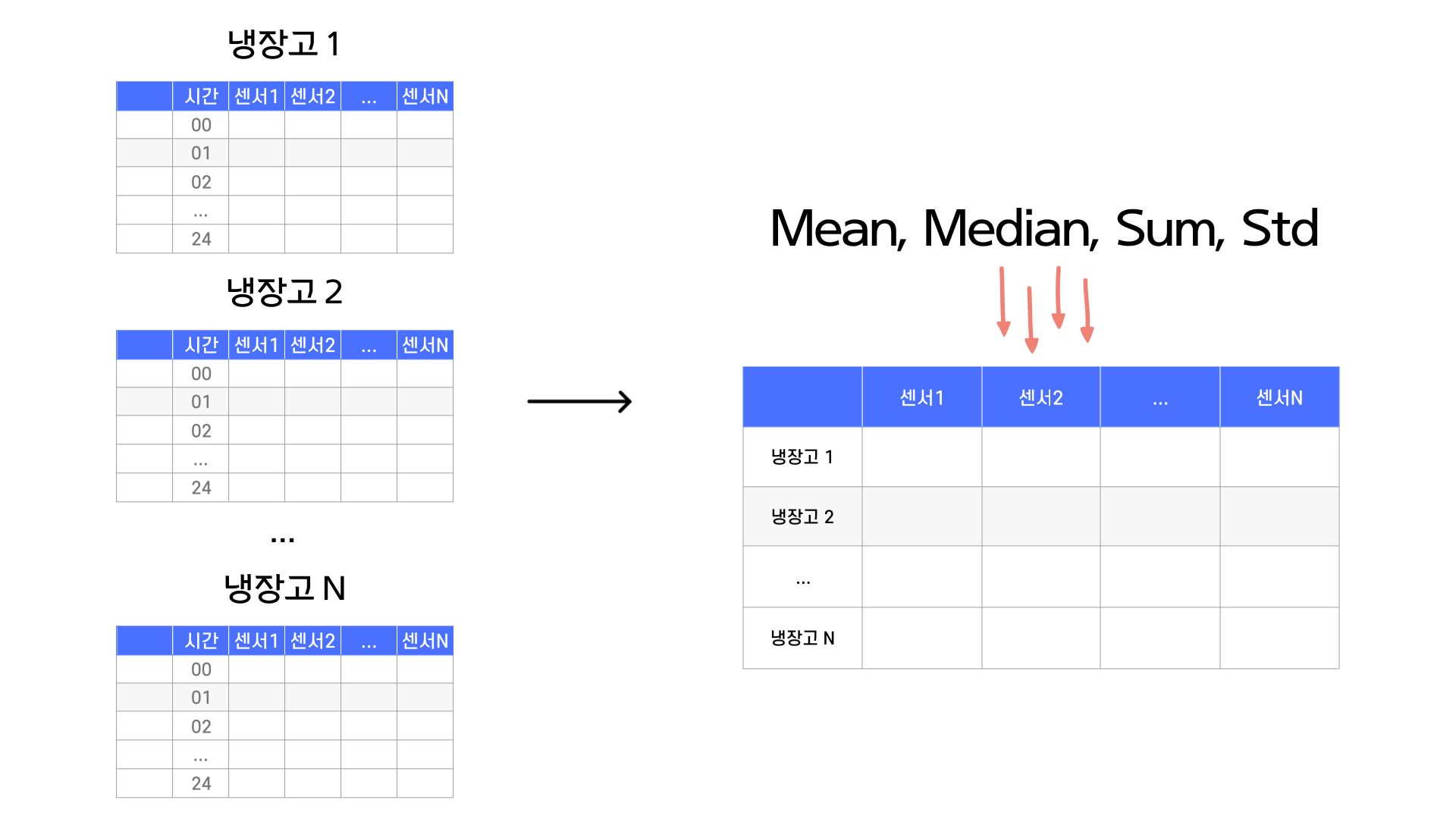
여러 냉장고에 있는 여러 센서들에서 수집된 일일 데이터를 대표값으로 feature extraction하여 분석을 수행했습니다. 예를 들어, 일일 데이터를 가져온다고 했을 때 만약 센서 1에서는 냉장고를 열고 닫는 횟수를 수집한다면 평균, 중간값이 아닌 총합을 가져와 한개의 데이터로 압축을 할 수 있습니다. 만약 온도 데이터를 수집하는 센서데이터의 데이터를 압축한다면 분산을 대표값으로 사용하여 압축할 수 있을 것입니다.
이렇게 데이터를 사용할 수 있는 상태로 변경했다면 이제 클러스터링 분석을 할 준비가 마무리 되었습니다.
02. 군집화 진행과정
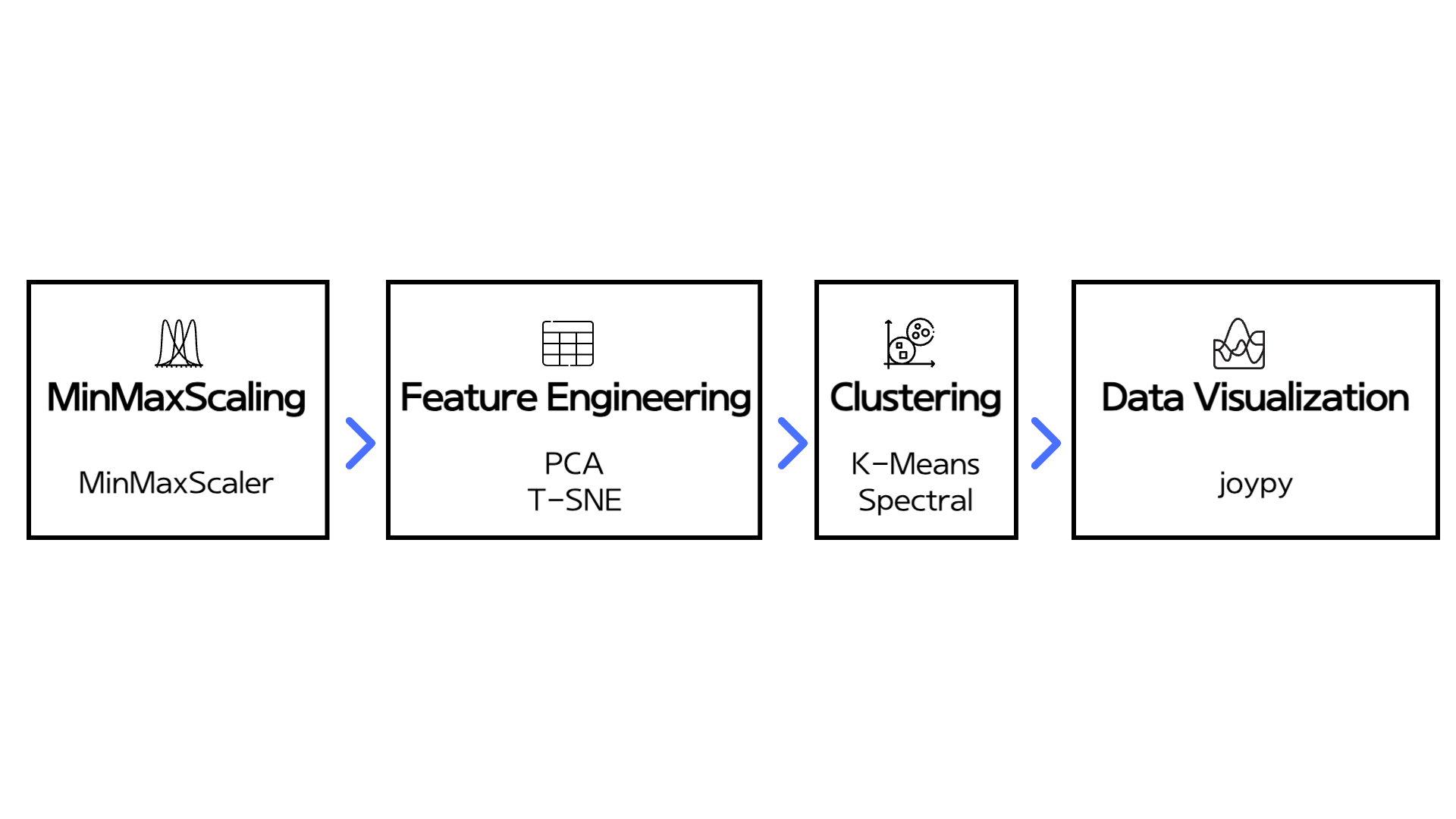
먼저 MinMaxScaling을 해주었습니다. 데이터 분포를 확인했을 때 outlier가 없었기 때문에 Normalization 대신 MinMaxScaling을 사용하여 최대한 data의 분포를 살릴 수 있도록 스케일링을 진행해주었습니다.
다음으로는 PCA와 T-SNE를 활용하여 Engineering 과정을 수행했습니다. 이번 미니 프로젝트에서 13개의 센서 feature를 사용했는데, 이렇게 되면 데이터는 13차원으로 표현이 됩니다. 하지만 이를 시각화하기는 어려기 때문에 2차원으로 차원을 축소하여 군집화를 시각화하고 해당 engieering 단계를 진행했습니다.
다음으로는 K-Means와 Spectral Clustering 두 모델을 사용하여 모델링을 했습니다. 모델링을 한 후 나온 레이블링 결과값으로 이전 engineering 단계에서 추출한 값들을 통해 시각화를 하여 클러스터 별로 군집이 어떻게 변하는지를 확인했습니다.
마지막으로는 joypy 라이브러리를 활용하여 클러스터별로 전체 13개의 센서데이터 어떻게 분포하고 있는지 시각화를 했습니다.
02-01. Feature Engineering
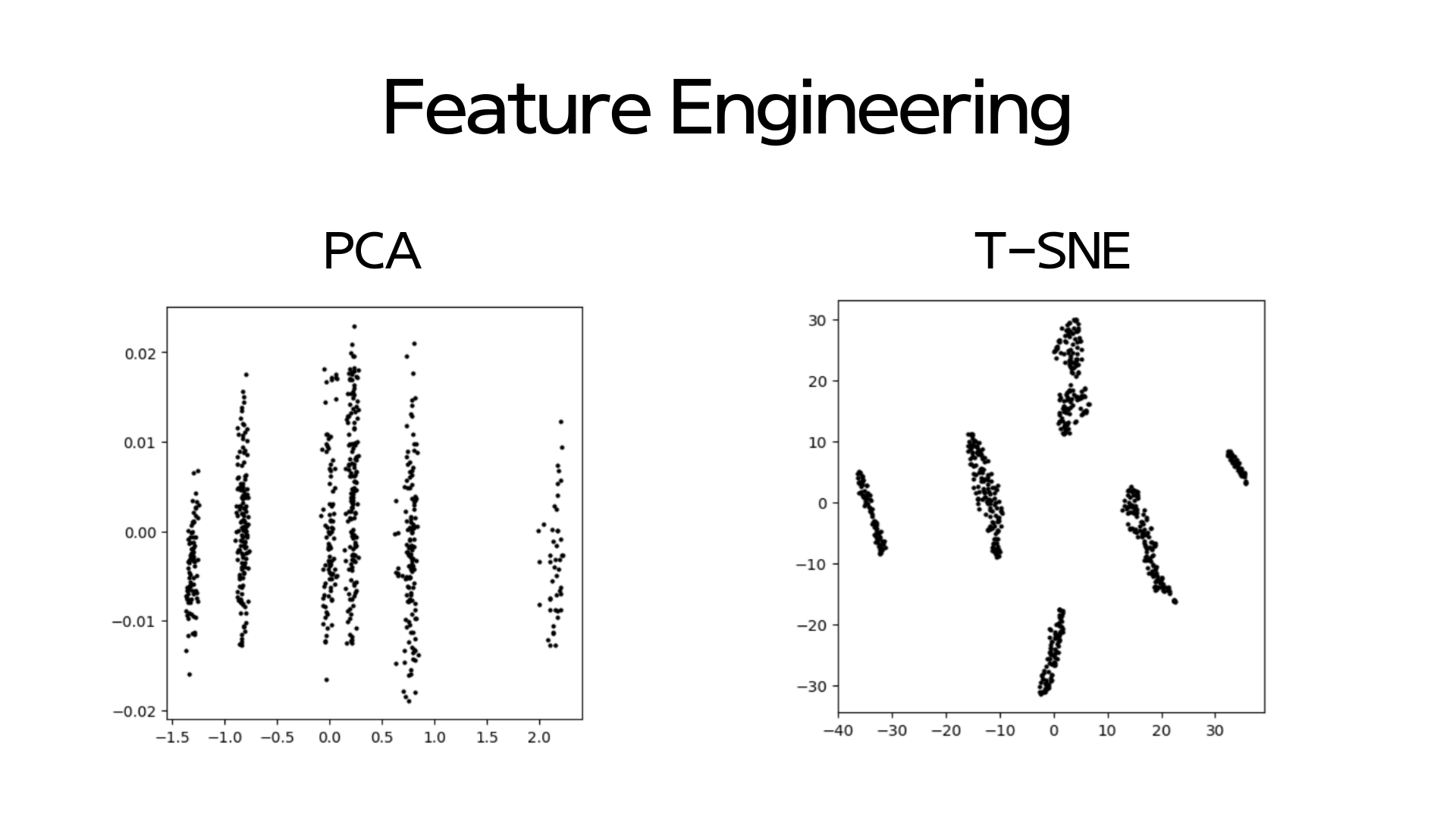
먼저 PCA를 통해 engineering을 했습니다. pca.fit_transform()을 한 후 변형된 데이터 중 첫번째 2개의 컬럼 값, 즉 데이터의 분포를 제일 잘 설명하는 축의 값 2개를 가져왔 데이터 프레임을 만들었습니다. 그 두개의 값을 시각화하면 위 이미지의 왼쪽 그래프가 나옵니다. 6개의 군집이 잘 분리된 것을 확인할 수 있습니다!
두번째로 T-SNE를 통해 engineering을 진행했습니다. PCA의 경우 고차원에서의 데이터 분산을 저차원에서의 데이터 분산과 거의 동일하게 만듭니다. T-SNE의 경우는 고차원에서의 점 i, j가 이웃할 확률이 저차원에서도 i,j가 이웃일 확률이 보장되도록 만듭니다. 다른 말로는 고차원에서의 확률분포와 저차원에서의 확률분포가 같아지도록 만듭니다. 그 결과는 오른쪽 그래프와 같습니다. PCA에 비해서 군집간의 거리가 더 잘 벌어진 것을 확인할 수 있습니다.
그래서 T-SNE을 통해 나온 값을 활용해 다음에 나올 모델링 결과 시각화를 했습니다.
02-02. Clustering (Modeling)
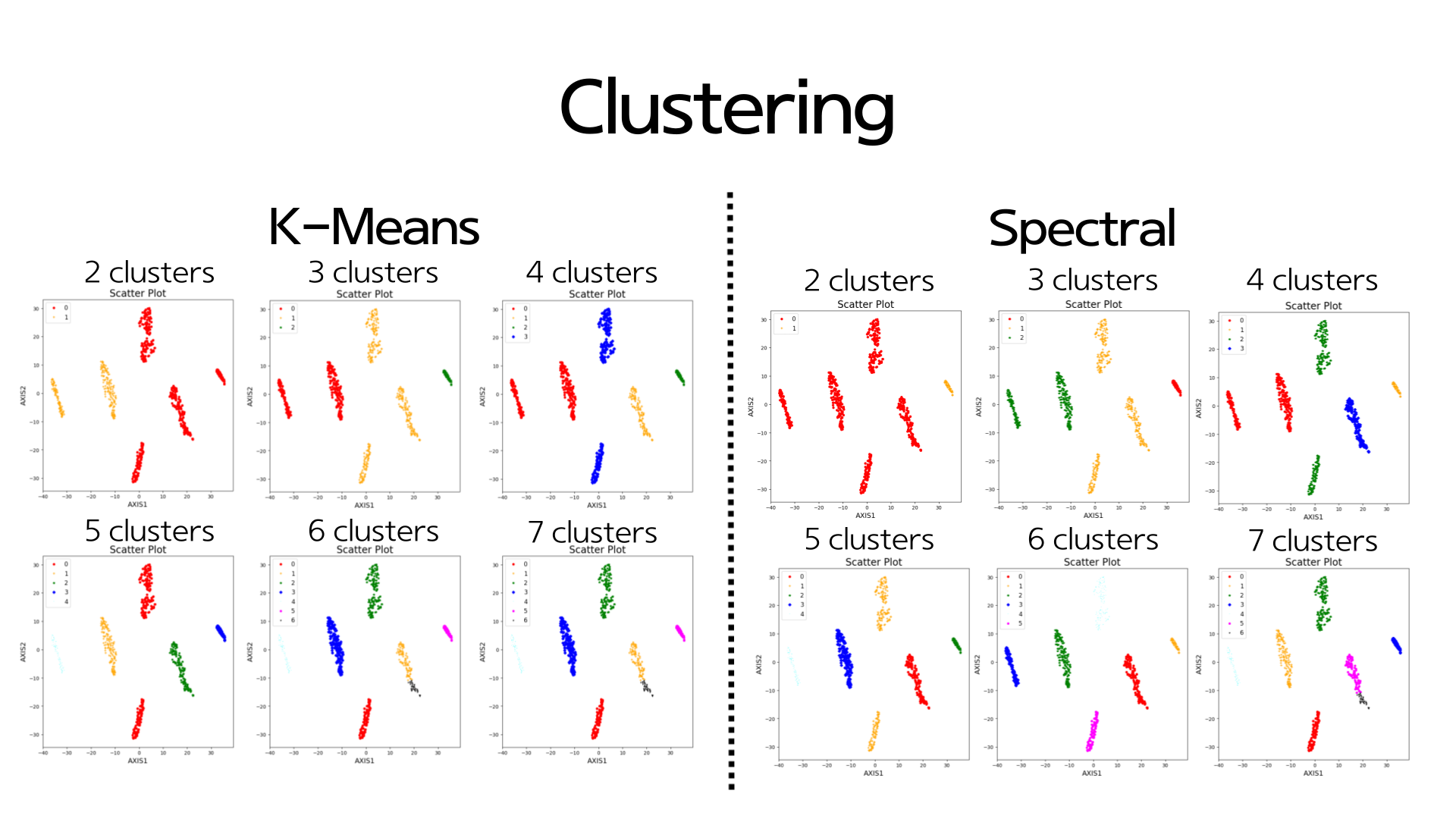
K-Means와 Spectral의 클러스터를 2,3,4,5,6,7개로 바꿔가며 모델링한 결과는 다음과 같습니다.
클러스터를 2개로 설정했을 때는 두 모델의 시각화 결과가 달랐습니다. 하지만 클러스터 개수를 늘릴 수록 두 모델에서 나오는 군집화 결과가 같아지는 것을 확인할 수 있었습니다. 클러스터가 5개 이하일 때는 서로 멀리 떨어진 것 같아도 하나의 군집으로 묶이는 데이터들을 확인할 수 있었습니다. 이를 통해 그 데이터들은 2차원으로 봤을 때는 멀리 떨어져보이지만, 원래 고차원일때는 서로 가까이 있다는 것을 알 수 있었습니다.
02-03. Data Visualization
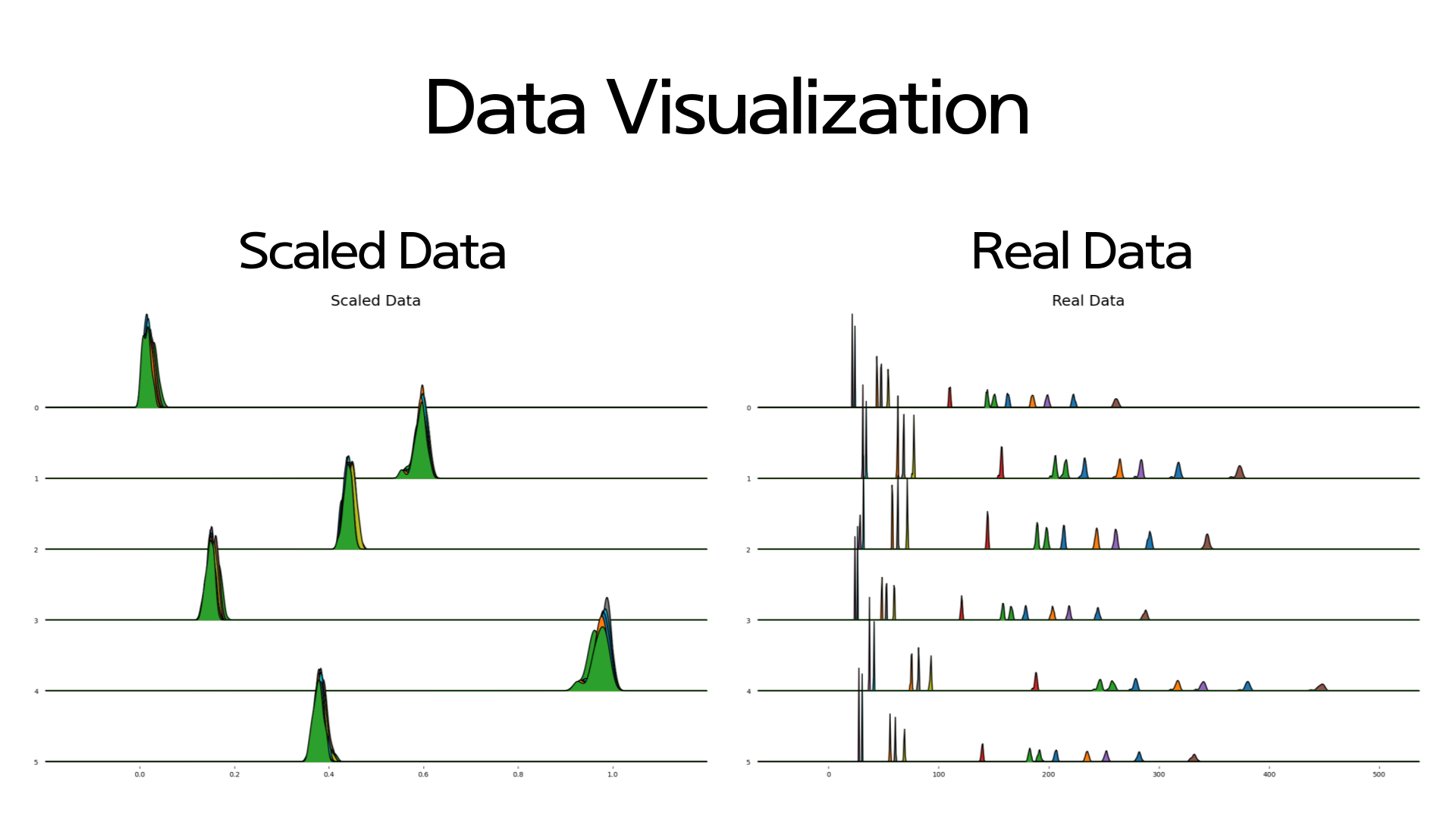
마지막으로 클러스터 별로 센서데이터들의 분포를 확인하기 위해 시각화를 했습니다. joypy 라이브러리를 사용하여 전체 센서데이터의 분포를 한번에 시각화를 했습니다. 왼쪽은 MinMaxScaling이 된 데이터입니다. 스케일링이 되어 분포가 겹쳐 알아보기 힘듭니다. 그래서 스케일링이 되기 전 원래 데이터를 사용하여 시각화를 했습니다.
그 결과 센서데이터 별로 분포를 더 명확하게 볼 수 있었습니다. 클러스터 별로 (위에서 부터 2) 어떤 센서 데이터들이 같은 군집에 속하는지를 확인하며 센서 데이터들의 상관관계도 어느정도 짐작해볼 수 있었습니다.
03. 마무리하며
이번 글에서는 클러스터링을 하여 사용자들의 가전제품(냉장고) 사용 패턴을 군집화하는 과정을 다루었습니다.
제가 마케팅을 전공했었기에 유저 데이터를 다루는 것에 관심이 많았었는데, 이번 미니 프로젝트를 통해 직접 다루어보고 분석까지 할 수 있어서 많은 도움이 되는 시간이었습니다.
하지만 마지막에 joypy 라이브러리를 활용하여 해석을 하는 부분은 어떻게하는지 불분명하여 이 글에서 다루지는 않았습니다. joypy 라이브러리 사용법을 더 공부하고 클러스터링 해석법을 더 알아보는 것이 필요할 것을 느끼는 시간이었습니다.
부족하지만 읽어주셔서 감사합니다:) 피드백은 언제나 환영입니다:)
