
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 시작하며
이번 20번째 미니 프로젝트에서는 8번째 미니 프로젝트와 많이 유사한 주제인 생산설비 고장 예측 문제에 관해 다루었습니다. 하지만 이전 8번째 미니 프로젝트와 다르게 feature들의 이름이 명시되어있었습니다.
이전 8번째 프로젝트에서는 feature 이름에 마스킹 처리 및 데이터 스케일링이 되어있어 feature를 기반으로 모델링 결과에 대해 해석을 하기 어려웠습니다. 이와 반대로 이번 미니 프로젝트에서는 모델링 후 shap 등을 활용하여 모델링 결과에 대하여 feature들을 활용해 해석 실습을 할 수 있었습니다.
그렇다면 이번 실습은 어떻게 진행했는지 전체 과정부터 소개해드리겠습니다.
02. mini 프로젝트 전체과정
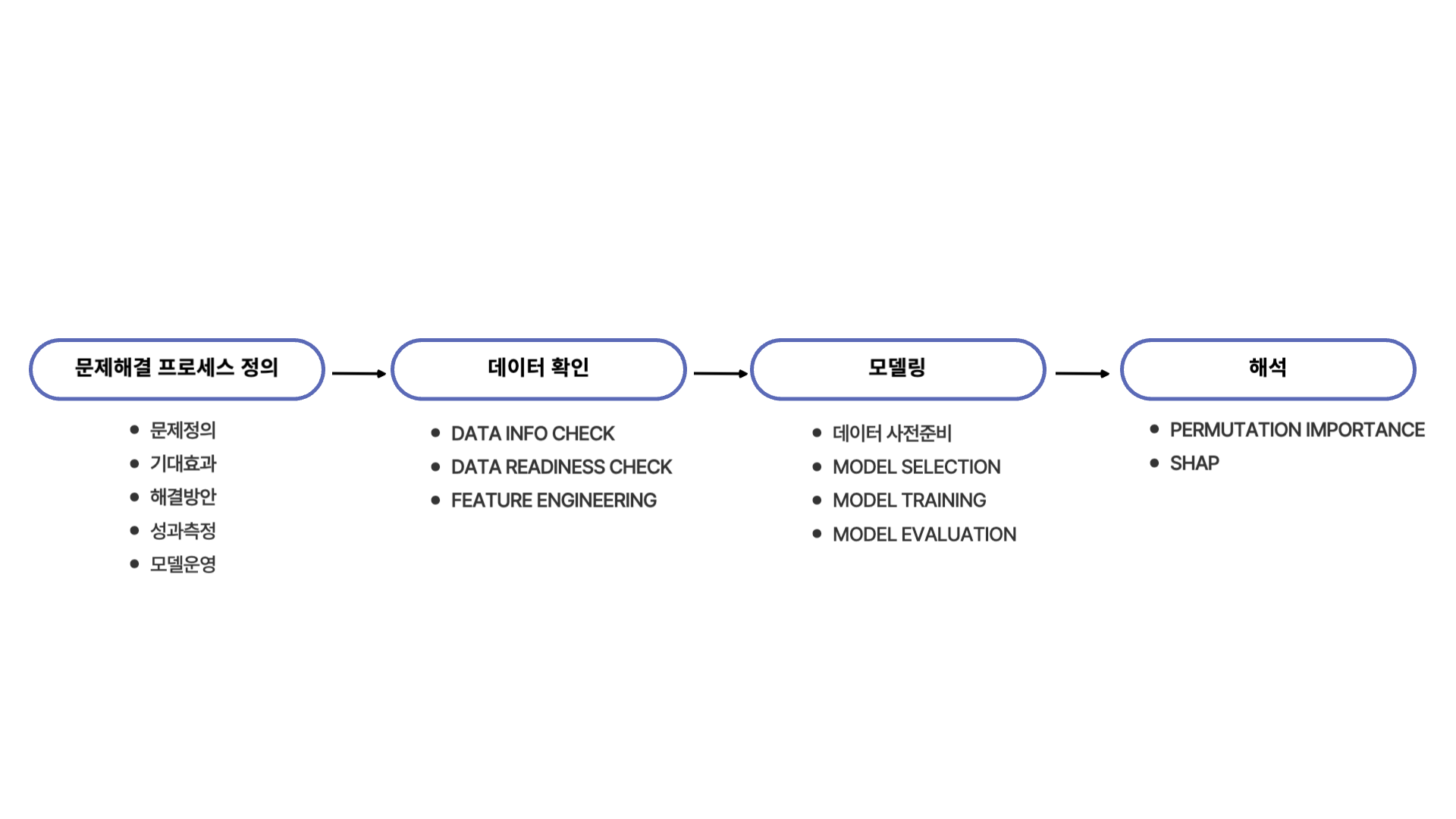
이전 미니 프로젝트들과 동일하게 문제해결 프로세스 "정의 → 데이터 확인 → 모델링 → 해석" 단계를 거쳤습니다. 이전 미니 프로젝트들과 달랐던 점은 Feature Engineering 과정에 IV (Information Value)를 계산하는 과정을 포함시켜 Binary Classification에 있어 어떤 feature들이 중요한 역할을 할지 확인한 것이었습니다. 이 부분은 데이터 확인 단계에서 더 자세히 다루어보겠습니다.
모델링 파트에서 달랐던 점은 크게 없었습니다. 달랐던 점이라면 서로 계열인 3가지 모델 (Logistic Regression, Random Forest, LightGBM)을 활용하여 모델링을 진행할 때 Bayesian Optimization을 사용하여 하이퍼 파라미터 튜닝을 통해 베이스 모델을 만들어 각각의 모델을 평가했습니다.
해석 부분에서는 shap에 더해 eli5 라이브러리에 있는 Permutation Importance를 사용하여 최종 선택된 모델에서 어떤 feature가 분류문제에서 중요한 역할을 했는지 확인했습니다. shap와 결과가 조금 다르게 나와었는데 해석 부분에서 어떻게 다르게 나왔는지 알려드리겠습니다.
그럼 먼저 문제해결 프로세스 정의부터 시작하겠습니다.
03. 문제해결 프로세스 정의
해당 프로젝트에서의 문제점은 서두에서 소개했던 것처럼 생산 설비에 문제가 생겨 생산이 정지되는 과정을 방지하는 것이 해결하고자 하는 문제입니다. 생산설비 정지로 인해 생산 스케줄에 차질이 생긴다면 결과적으로 납품이 지연되고 이는 지연에 대한 손해배상액을 내야하는 결과로 이어집니다.
때문에 생산설비가 문제가 생기는 것을 미리 예방할 수 있다면 이에 대한 기대효과로 생산설비 정비 횟수를 절감하고 납품지연 횟수를 감소시켜 전체적인 비용을 감소시킬 수 있습니다.
해당 문제를 해결하기 위해서는 Machine Failure을 발생시키는 오류들의 원인을 캄지 및 개선하는 활동을 전개해야합니다. 분석을 할 데이터에는 1과 0으로 되어있는 Machine Failure 컬럼이 있습니다. 하지만 저희가 모델링을 하여 예측하고자 하는 값은 Machine Failure 값이 아닙니다.
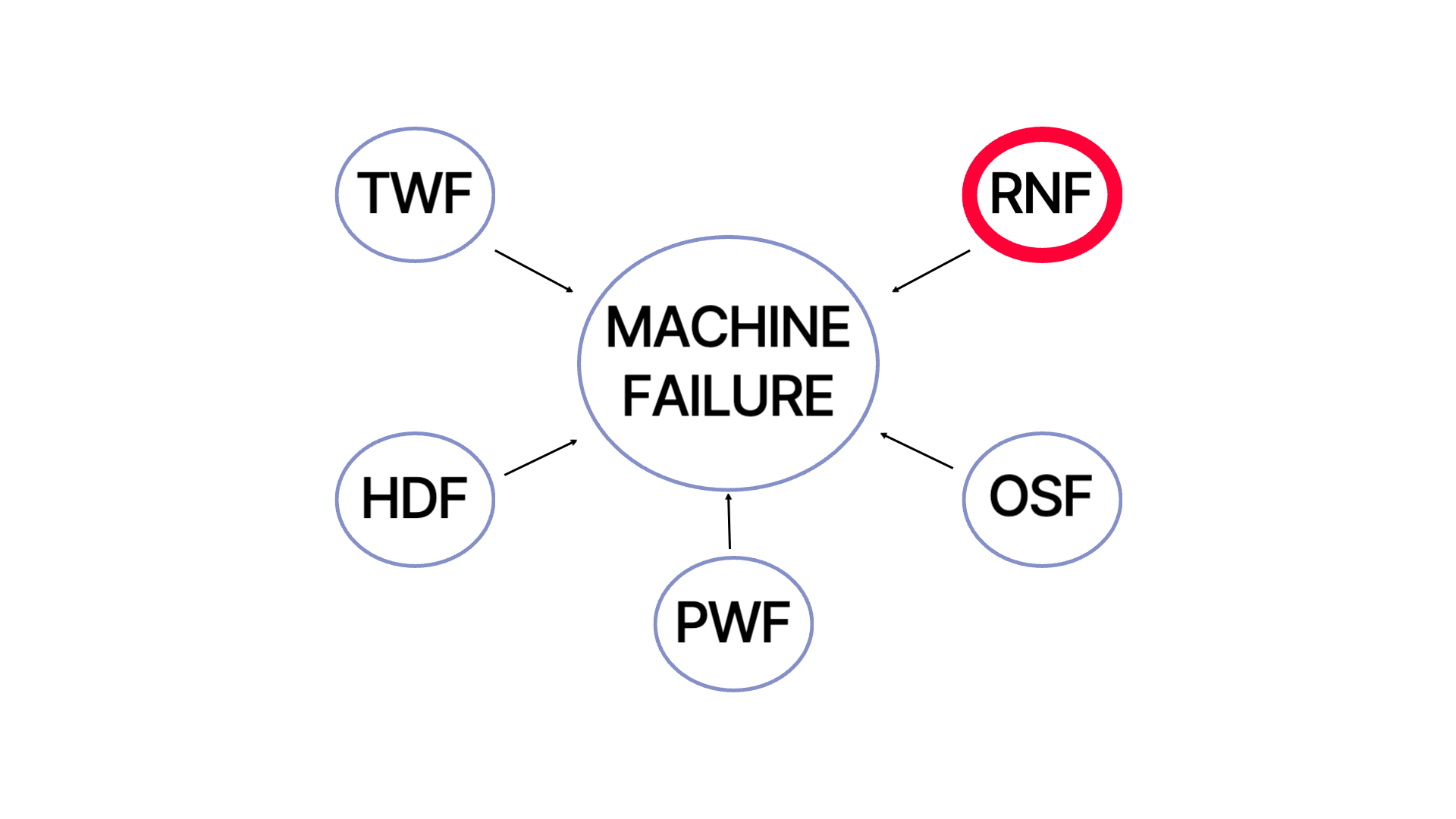
생산설비 고장을 일으키는 원인에는 (해당 미니 프로젝트에서는) 5가지가 있는데 이를 하나하나 알아보면 다음와 같습니다.
- TWF: 툴 마모로 인한 알람, 200~240분 사이일시 고장발생
- HDF: 공기온도와 프로세스온도 차이가 8.6k 미만이고, 회전속도가 1380rpm미만일시 고장발생
- PWF: 동력이 3500W 미만이거나 9000W 이상일 시 고장발생
- OSF: 공구마모와 토크의 곱이 11,000minNM을 초과할시 고장발생
- RNF: 공정 모수에 관계없이 0.1%의 실패 확률로 고장발생
해당 오류들이 하나 혹은 복수로 발생하면 생산설비 고장이 납니다. 원인들을 자세히 보면 TWF, HDF, PWF, OSF은 고장발생시 명확한 Rule이 있습니다. 하지만 RNF의 경우에는 명확한 원인이 없습니다. 그래서 여기서 예측하고자 하는 것은 Rule이 명확하지 않은 RNF를 예측하여 생산설비 고장을 예방 및 미리 예측하는데 있습니다.
04. 데이터 확인
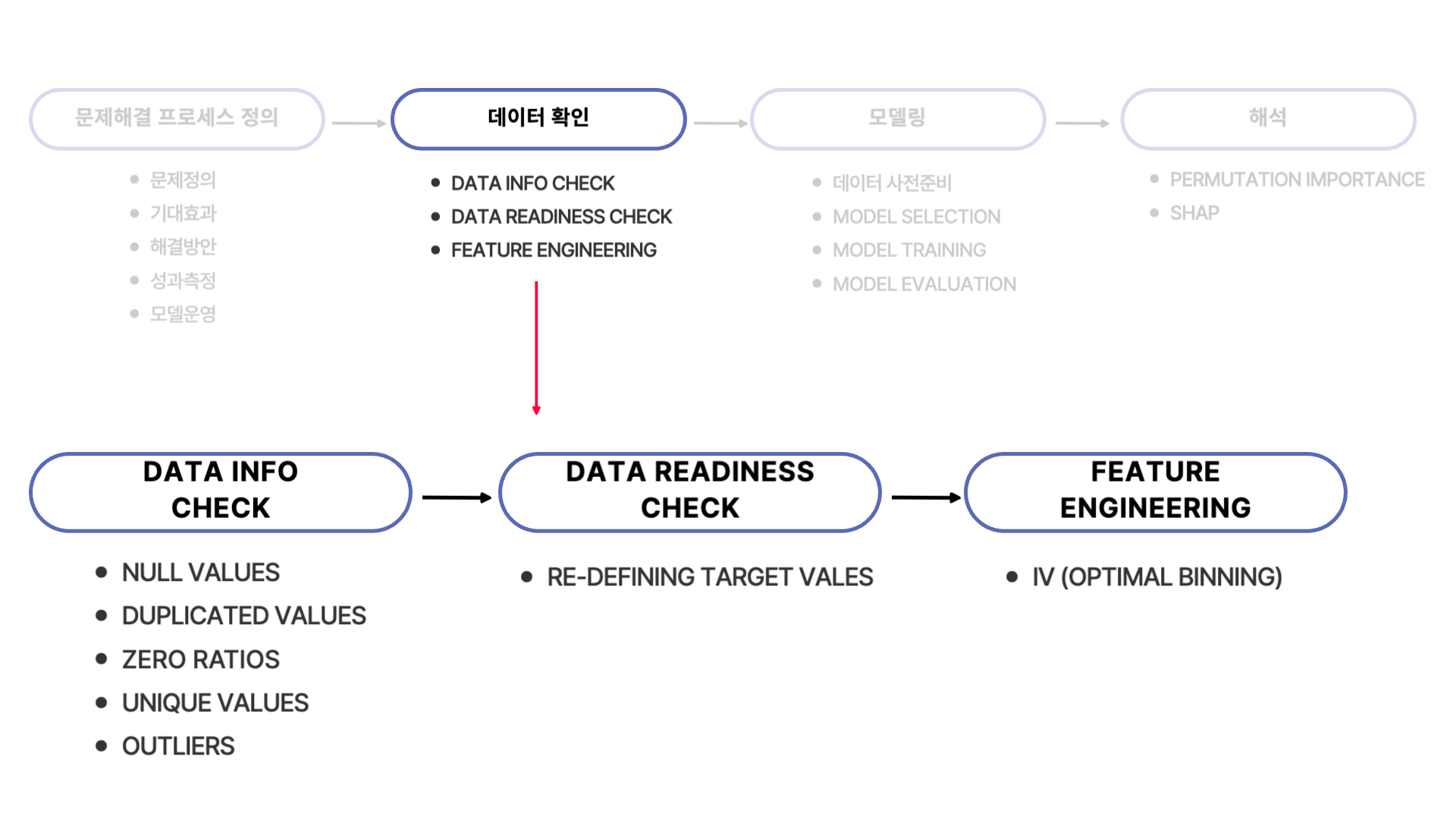
데이터 확인 단계는 이전 미니 프로젝트들과 동일하게 Data Info Check → Data Readiness Check → Feature Engineering 단계를 거쳤습니다.
Data Info Check에서 데이터의 기본적인 5가지를 확인 후 Data Readiness Check 단계에서 타겟 데이터를 변경했습니다.
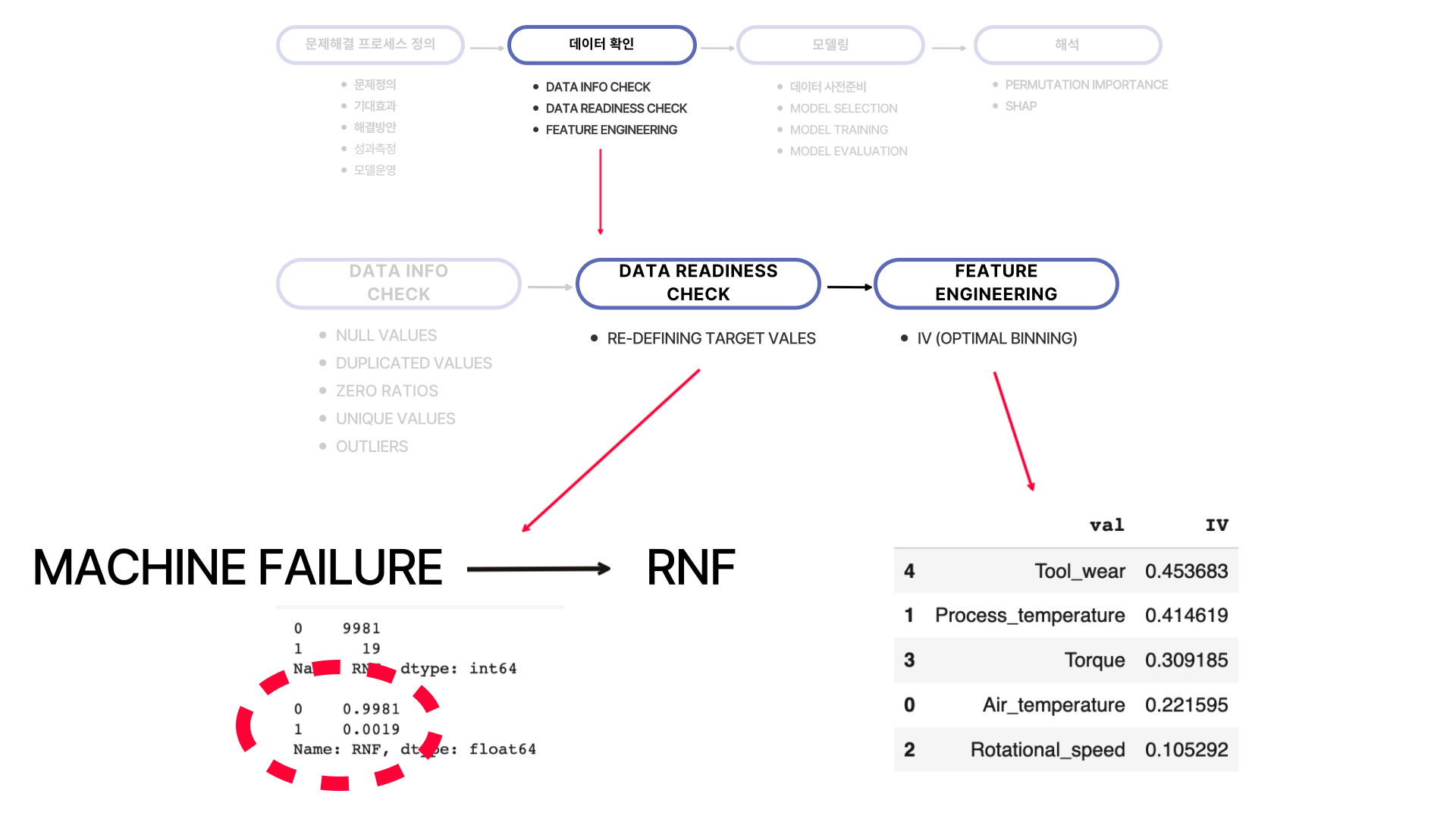
문제정의에서 다루었듯 Machine Failure를 일으키는 원인 중 RNF만 원인을 알기 어려워 타겟 레이블로 설정하여 예측을 하고자 했습니다. 하지만 1 (positive) 값의 비율이 0.19% 정도로 매우 낮았습니다. 때문에 모델이 1값을 예측하는데 어려움이 있을 것으로 예상되어 모델링 과정에서 over-sampling을 통해 레이블값의 비율을 맞추었습니다.
다음으로 Feature Engineering 단계에서는 feature selection을 위해 IV (optimal binning을 통해) 을 구해 어떤 feature들이 타겟값 구분을 할 때 정보량이 많은지를 구했습니다.
여기서 눈여겨 볼 점은 오른쪽아래 IV 점수를 통해 'Tool_wear' 컬럼과 'Process_Importance' 컬럼이 중요 변수임을 짐작할 수 있습니다. 하지만 이후 shap을 통해 feature importance를 확인했을 때 'Process_Importance' 중요성이 많이 떨어졌음을 확인할 수 있었습니다. 이 부분은 해석 부분에서 더 자세히 다루어보겠습니다.
05. 모델링

다음으로 모델링을 진행했습니다. 학습을 위해 데이터를 train/test로 분리를 하고 category 값은 (원핫)인코딩을 해주어 모델링에 사용될 수 있도록 데이터를 변형했습니다.
그 다음 서로 다른 계열인 Logistic Regression, Random Forest, LightGBM을 사용하여 모델링을 진행했습니다.
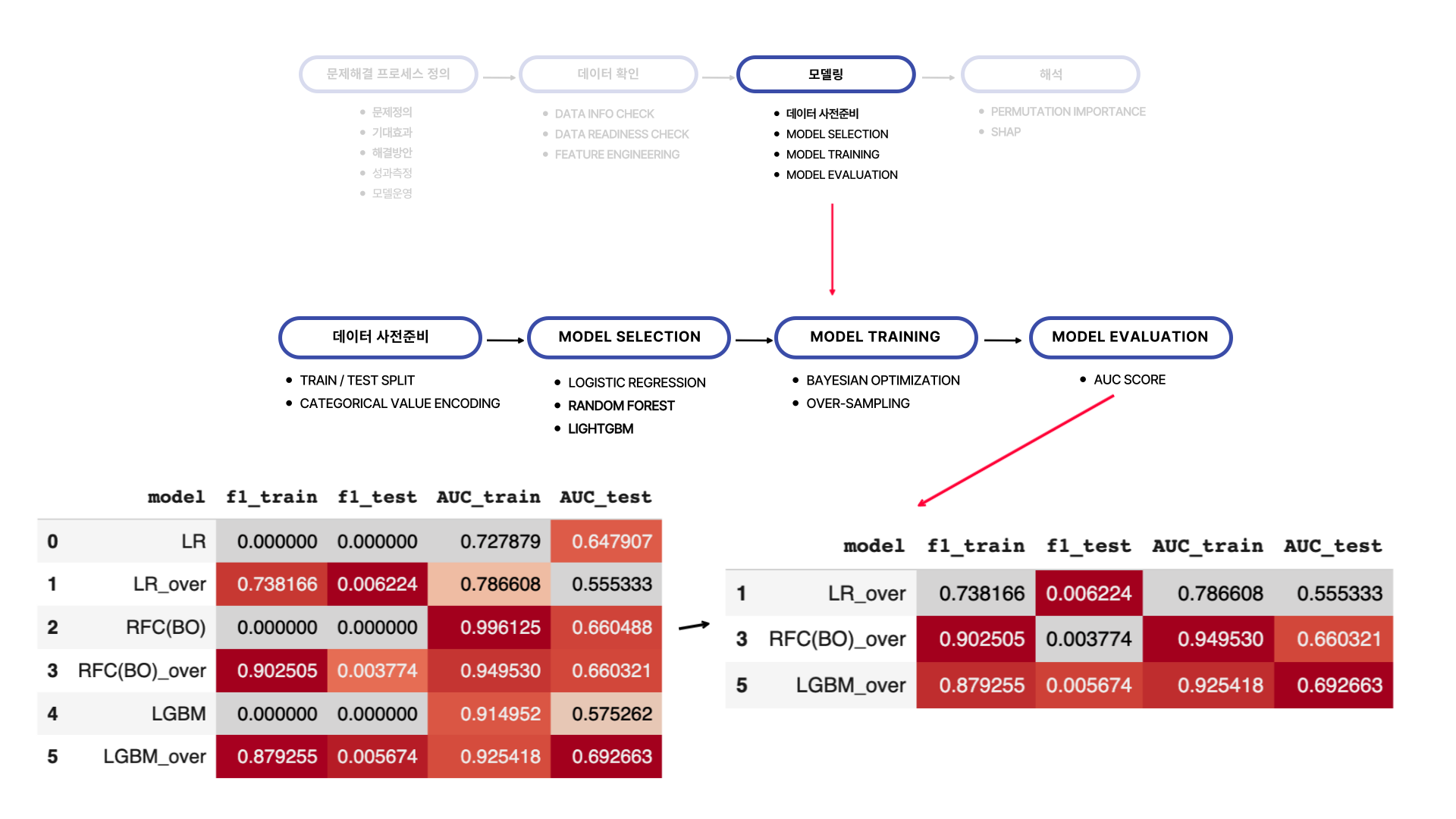
오버 샘플링을 하지 않았을 때의 모델링 결과는 왼쪽 아래에 model 이름에 '_over'가 붙지 않았을 때 입니다.
각각의 결과를 보면 f1-score에 대한 결과를 얻을 수가 없습니다. 이는 1 (positive)의 개수가 너무 적어 모델이 잘 예측하지 못했기 때문입니다. 그래서 SMOTE를 사용하여 클래스 밸런스를 맞추어 모델학습을 진행했습니다.
그 결과 테스트셋에대하여 f1-score의 값이 가장 높은 것은 over-sampling된 데이터를 사용한 Logistic Regression 모델입니다. 하지만 이 모델의 roc_auc score를 보면 0.55로 낮은 것을 확인할 수 있습니다. 이 수치는 0.5와 너무 가까워 맞출 확률이 거의 반반입니다.
이와 비교하여 over-sampling된 데이터를 사용하여 모델링한 lightGBM의 경우 f1-score는 Logistic Regression 모델에 비해 낮지만, roc_auc 점수에 경우 0.19가 높습니다. 그래서 맞출 확률을 어느 정도 보장하면서 f1-score 점수가 어느 정도 나오는 lightGBM의 최종 모델로 선택했습니다.
06. 해석
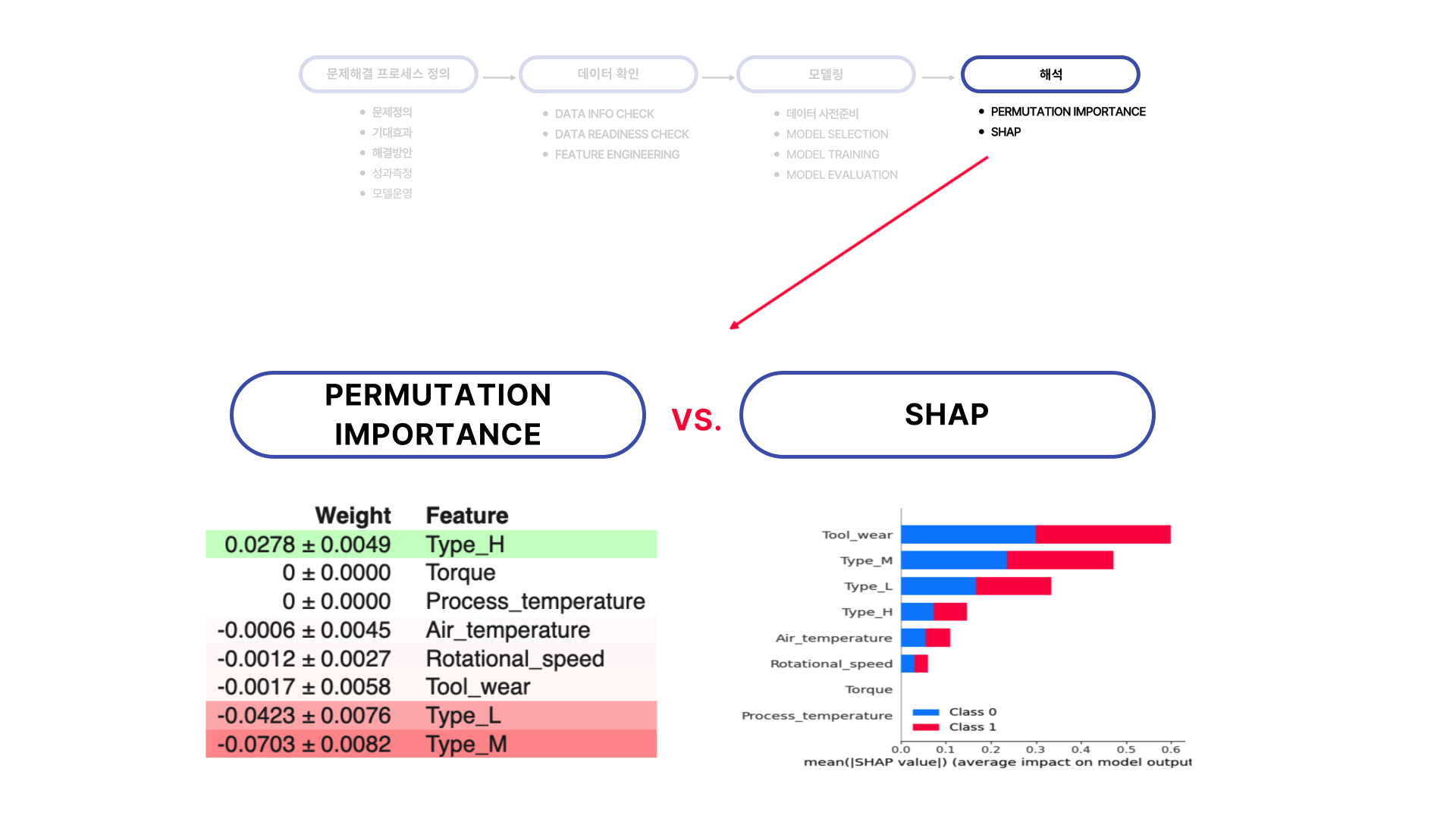
이전 미니 프로젝트들에서는 SHAP만을 사용하여 중요변수를 봤다면, 이번에는 Permutation Importance도 같이 확인해보았습니다. Permutation Importance의 경우 SHAP처럼 변수에 대한 해석을 가능하게 해주지는 않지만, 어떤 변수가 모델에 영향을 끼치는지 알 수 있도록 해줍니다.
확인결과 두개의 결과가 다른 것을 확인할 수 있었습니다. Permutation Importance의 결과로는 원핫인코딩을 통해 만들어준 Type_H에 해당하는 컬럼이 가장 중요한 변수이지만, SHAP의 경우는 Feature Engineering 과정에서 보았던 Tool_wear가 여전히 가장 중요한 변수였습니다.
하지만 IV에서 두번째로 중요했던 Process_temperature 변수가 중요도에서 많이 떨어졌음을 확인할 수 있었습니다. 이는 변수들의 상호작용을 포함한 변수의 중요도를 계산했을 때 Process_temperature의 중요도가 많이 떨어짐을 알 수 있었습니다.
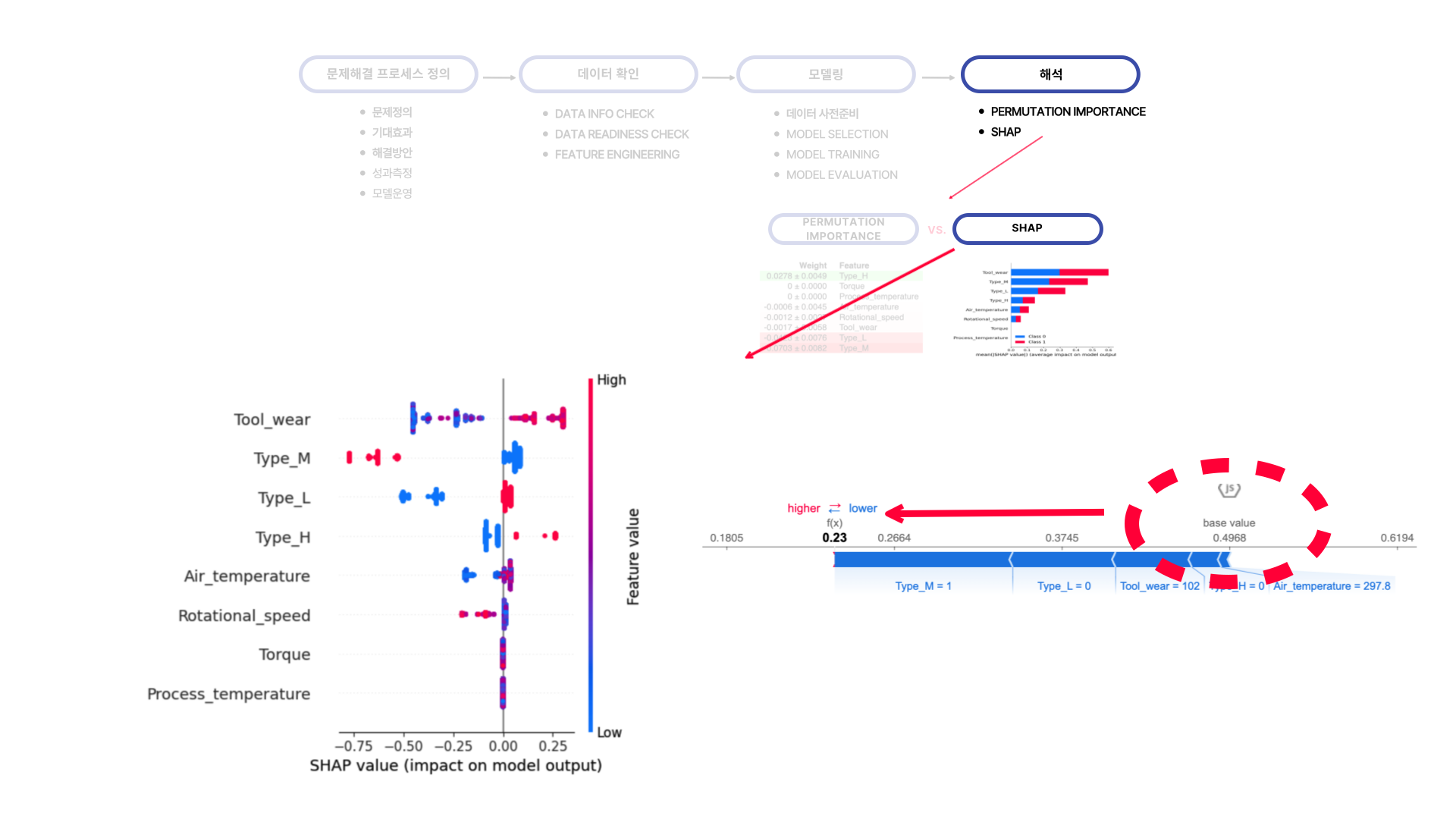
SHAP을 통해 변수들이 모델에 끼친 영향을 더 자세히 본 결과, Tool_wear은 값이 낮을수록, Type_M은 값이 높을수록, Type_L은 값이 낮을수록 낮은 예측값에 영향을 준다는 것을 알 수 있었습니다.
이에 대한 결과는 force_plot을 통해 하나의 값에 대한 변수들의 영향도를 보며 더 자세히 확인할 수 있었습니다.
07. 마무리하며
이번 미니 프로젝트에서 진행했던 내용들은 이전 19개 정도의 미니 프로젝트들을 하면서 많이 익숙해진 부분들이 많았습니다. 하지만 이제 분석과정을 완벽히 이해했어!가 아닌 이제 슬슬 익숙해졌으니 더 알아야하고 더 완벽히 숙지해야하는 부분은 어떤 부분인지 자가진단할 수 있는 시간이었습니다.
앞으로 30개 정도의 미니 프로젝트를 더 진행할텐데 더 꼼꼼히 분석 실습을 하며 실전에서도 해당 분석 기술 및 과정 등을 잘 적용할 수 있도록 연습해야겠습니다!
부족하지만 읽어주셔서 감사합니다:) 피드백은 언제나 웰컴입니다!
