
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 각색하여 복습을 위해 작성하였습니다.
개요
이번 3번째 미니 프로젝트를 진행하며 크게 3가지 내용을 다뤘습니다.
첫번째로 데이터 분석 프로세스 중 가장 첫번째 순서에 해당하는 '문제 정의'에 대한 부분을,
두번째는 '데이터 관점'의 사고에 대한 중요성을,
마지막으로는 이번 미니 프로젝트에서 가장 중요했던 Cross Validation의 중요성과 어떻게 활용할 수 있는지 배웠습니다.
이후로 다음의 순서대로 배운 내용을 소개해드리고자 합니다.
1. 전체적인 프로세스
2. '문제 정의'란?
3. 직접 눈으로 데이터를 확인해보자
4. Cross Validation
01. 전체적인 프로세스
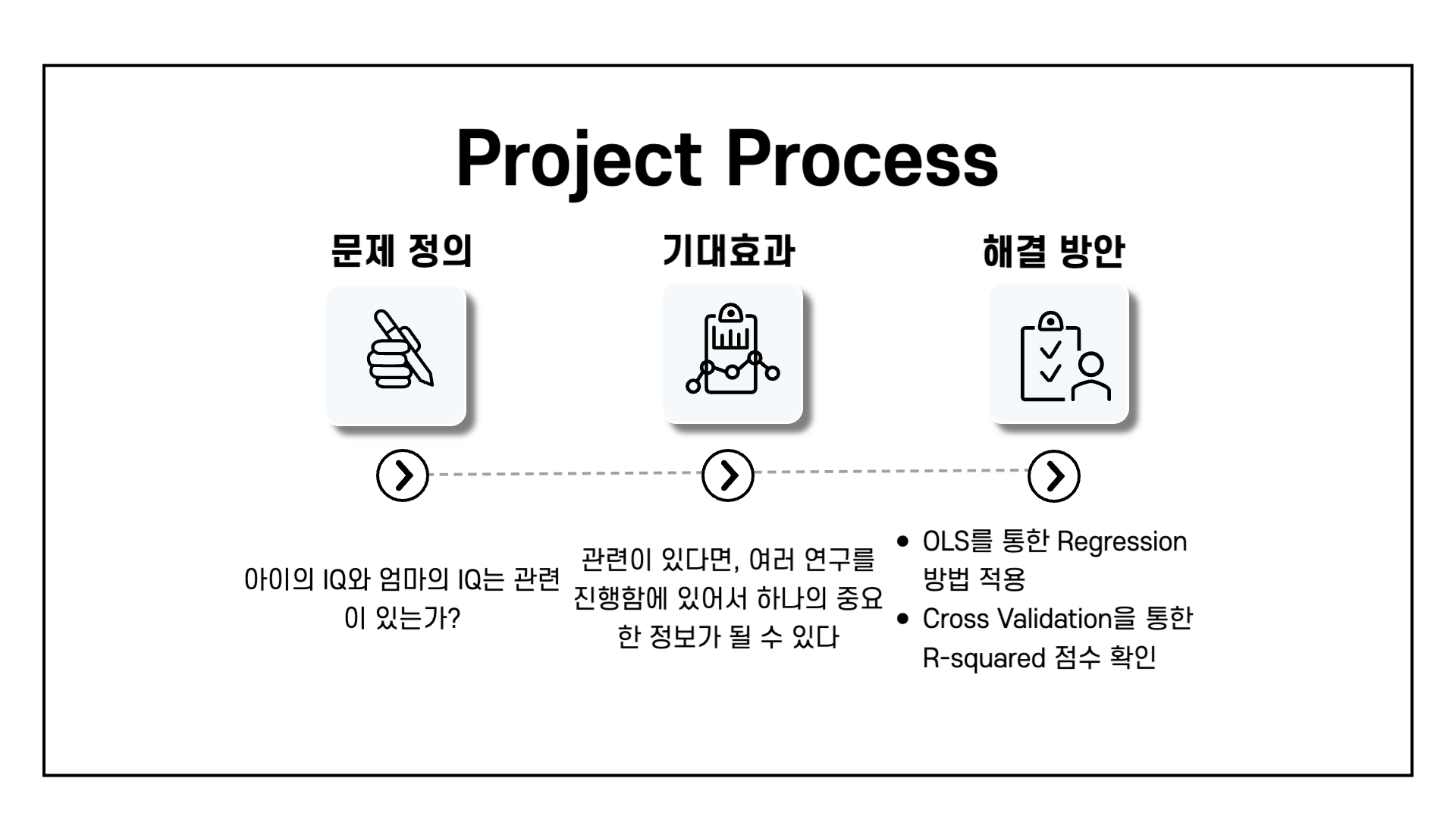
이번 미니 프로젝트의 목표는 아이의 IQ가 엄마의 IQ와 관련성이 있는지 알아보는 것입니다.
하지만 이번 프로젝트에서는 프로젝트 전체 진행상황에 집중하기보다는, 문제를 정의하거나 해결함에 있어 어떻게 해야 하는지 세세한 부분에 더 집중했습니다.
그렇다면 먼저 문제 정의에 관한 부분을 다루어보겠습니다.
02. '문제 정의'란?
이번 미니 프로젝트에서는 문제 해결 프로세스를 정의하는 것의 중요성이 강조되었습니다.
많은 신입들의 경우 문제가 주어지면 정말 잘 해결하지만, 상황을 주고 문제를 만들어오는 것에는 익숙하지 않는 경우가 많다는 것이 발견되었다고 합니다.
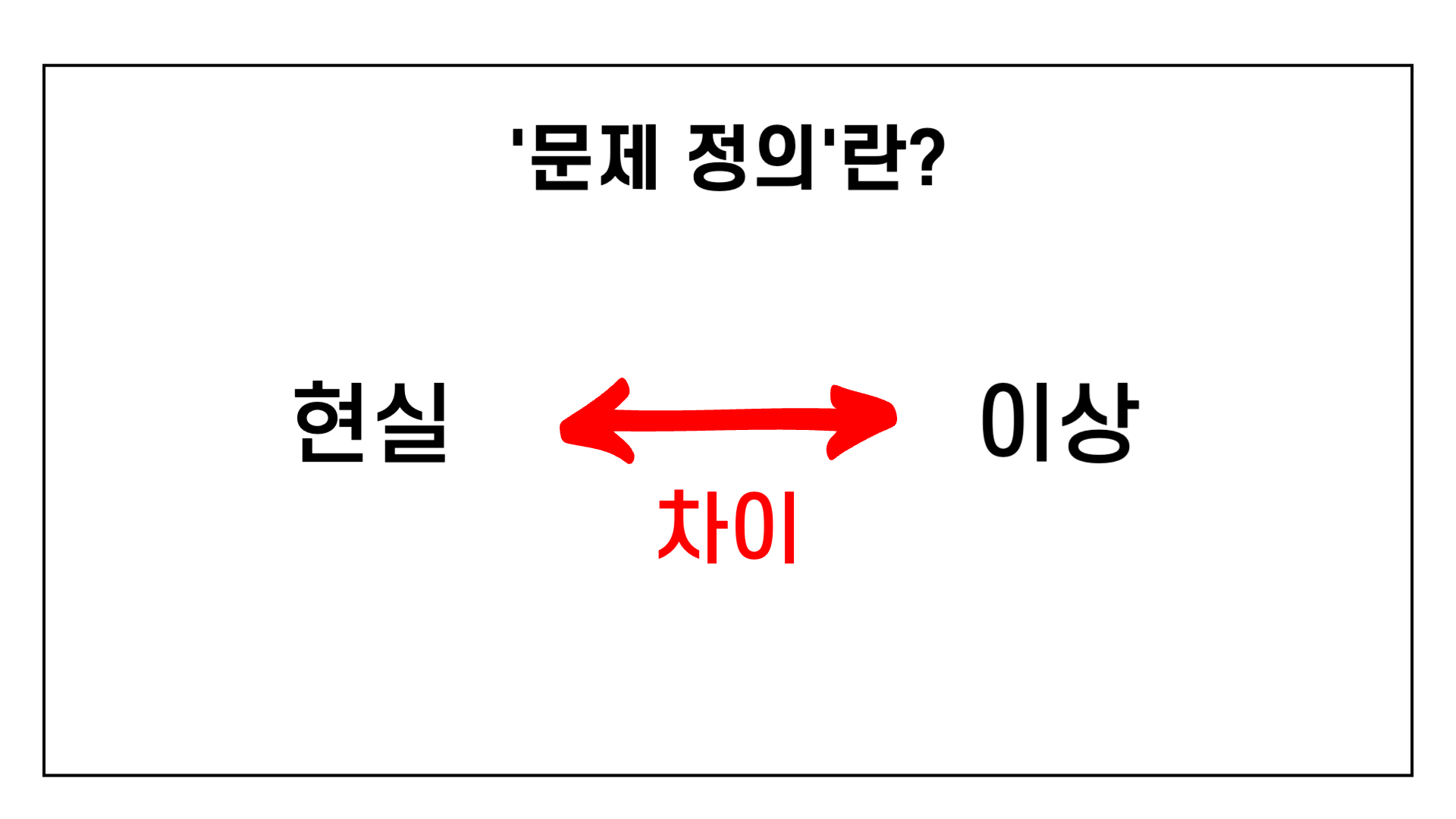
그렇다면 문제 정의란 무엇인가?
'현실과 이상의 차이'라고 합니다!
예를 들어, 전기세 사용량을 예측하고자 할 때, 만약 5일 동안 10000원의 전기를 썼다고 했을 때 우리는 다음 2일의 전기사용량을 대략 (10000 / 5) * 2 = 4000원이라고 예상을 할 수 있습니다.
하지만, 현실은 4000원이 아닌 경우가 있을 수 있습니다. 현실과 이상의 갭이 발생하는 것입니다.
때문에 우리는 현실과 이상의 차이가 이만큼 있는데 어떻게 줄일 수 있는지, 어떤 데이터를 사용하여 줄일 수 있는지에 대한 부분을 풀고자 하는 문제로 정의 할 수 있습니다.
혹은 다른 예시로, 한 클라이언트가 앱의 유저를 3000명에서 5000명으로 늘리고 싶다고 했을 때 (현실과 이상의 차이), 우리는 해당 부분을 문제 정의로 볼 수 있습니다.
이 후 분석을 통하여 어떤 feature들이 유저 트래픽에 영향을 끼치는지 확인하여 (ex. 프로모션 시간대) 클라이언트에게 ~ 하셔야 합니다 라고 action item까지 제안할 수도 있습니다.
이렇게 문제 정의부터 분석, 이후 취해야 할 action item까지, 문제 정의부터 문제 해결 의전체적인 프로세스를 정의하는 것은 분석가에게 요구되는 역량이라는 것을 이번 미니 프로젝트에서 배울 수 있었습니다. 데이터 분석 기법만 배워서는 오래 살아남는 데이터 분석가가 될 수 없다는 것 또한 (당연한 말이겠지만) 배웠습니다. (물론 다른 역량들도 많을 것입니다!)
03. 직접 눈으로 데이터를 확인해보자
최근 데이터 분석가 면접 질문이 많이 바뀌었다고 합니다. 예를 들어, 데이터를 어디까지 나누어봤는지, 샘플링은 어떻게 했는지 등등 데이터를 어떻게 다루었는지에 관해 면접관들이 더 자세히 물어본다고 합니다.
실제 현업에서는 정말 더러운(?) 데이터를 많이 만나게 될텐데, 알고리즘에 많은 관심을 두는 분석가는 데이터의 모양이 이상하면 데이터에 불만을 가지게 된다고 합니다. 하지만 현업에서의 이런 태도는 매우 위험한 사고일 것입니다.
때문에 모델링은 매우 deep하게 하지 않더라도, 데이터를 가져와서 cross validation으로 검증을 하면서
- 각 fold별 모델링을 한 결과가 어떻게 되는지
- random 값은 어떻게 주었는데 결과가 어떻게 변하는지
- 샘플링 기법을 어떤 것을 사용했을 때 성능이 어떻게 달라지는지
등을 확인하면 data-centric한 사고가 필요하다는 것을 배웠습니다.
또한, 데이터 분포를 여러가지 plot들로 그려보고 눈으로 확인하며 실제 내가 생각하는 분포와 매치되는지 등등을 확인하기 위해 시각화를 하는 습관도 매우 중요하다고 합니다!
그럼 마지막으로 Cross Validation의 중요성 및 활용방안에 대해 소개해드리겠습니다.
04. Cross Validation
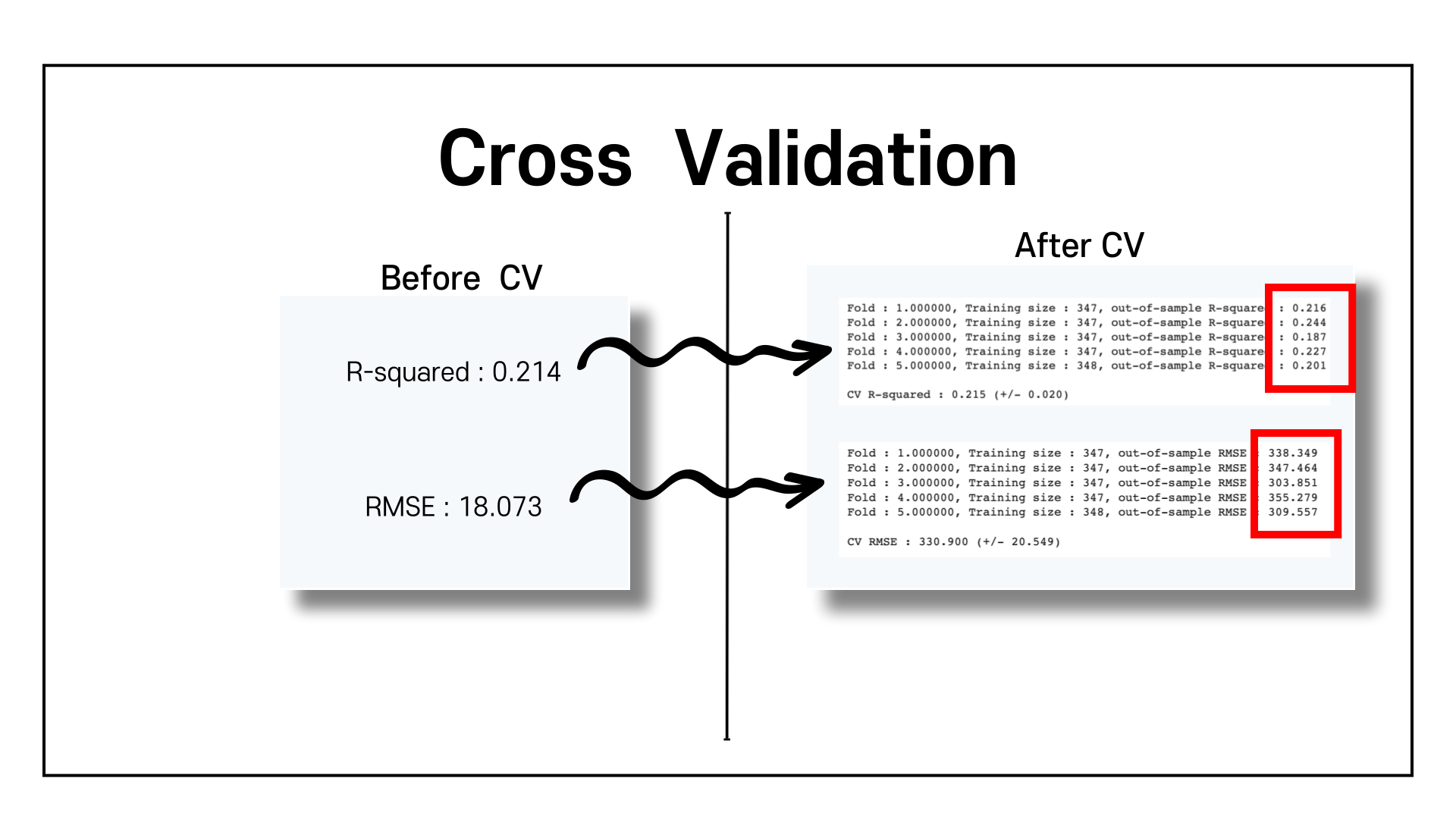
scikit-learn의 LinearRegression 모델을 사용하여 모델을 훈련시켰습니다.
Cross Validation 이전에 R-squared와 RMSE는 각각 0.214, 18.073 입니다.
그런데 Cross Validation을 한 이후에는, 각 Fold마다 R-squared 점수가 다른 것을 확인할 수 있었습니다. 이는 RMSE도 동일하게 각 Fold마다 점수가 다른 것을 확인할 수 있었습니다.
그렇다면 이를 어떻게 활용할 수 있을까?
모델 훈련 후 배포를 한다고 했을 때, 보통의 경우에 결과는 모든 fold에 대해서 정리하고 가장 결과가 좋았던 데이터를 활용한 모델의 weight를 활용하여 최종 모델을 생성한다고 합니다.
그 다음 결과가 좋지 않았던 fold의 데이터를 별개로 분석하여 해당 데이터셋에서 결과가 낮게 나오는 이유를 분석하여 모델링 특성에 반영한다고 합니다.
하지만, 전체 데이터의 특성을 모두 반영한 모델을 찾는 것은 매우 어렵다는 것을 배웠습니다.
때문에 trade-off 관계를 분석하여 타협점을 찾는 것이 중요하다는 것 또한 배울 수 있었습니다.
이는 만약 결과가 좋지 않았던 Fold의 결과를 높게 만들고자 한다면, 결과가 좋았던 Fold의 결과는 좋지 않아지기 때문입니다.
05. 정리하며
지금까지 3가지 내용 (문제 정의란 무엇인지?, 데이터 중심 사고, Cross Validation 활용하기)을 다루었습니다. 이전에 머신러닝 공부를 했지만 Cross Validation을 왜 해야하는지 다시 한번 깨닫는 중요한 시간이 되었습니다.
마지막으로, Cross Validation을 유용하게 사용할 수 있는 2가지 상황을 정리하고 마무리하겠습니다.
- 데이터의 크기가 너무 커서 나눠지는 데이터의 분포를 담보할 수 없을 때
데이터가 너무 많으면 (2억개 이상 row일 때) 40 folds, 50 folds까지 나눌 수도 있음 - 모델의 복잡도가 너무 높아서 데이터의 특성에 따라 결과가 바뀔 때
폴드 별로 나누어서 값이 많이 바뀌는지 바뀌지 않는지를 확인할 수 있음 - 대부분의 경우 숨쉬듯이 하기..! 그냥 무조건!!
어떨 땐 쓰고 어떨 땐 안쓰고가 아님
여기까지 읽어주신 분이 계시다면 부족하지만 감사드립니다:)
