
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 각색하여 복습을 위해 작성하였습니다.
01. 개요
이번 4번째 미니 프로젝트에서는 중요하게 배운 내용이 1가지 있습니다.

해당 미니 프로젝트에서는 공기질 데이터를 분석할 때 Regression 모델링이 필요하다는 것을 발견했습니다.
그런데 모델링을 할 때, 최근 많이 쓰이는 Ensemble - Boosting 모델인 lightGBM만 써서 모델링을 해도 될까요? (어감을 보면 아니라고 이미 말하는 것 같네요..)
이번 미니 프로젝트에서 배운 내용을 토대로 말해보고자 합니다!
02. 미니 프로젝트 진행과정
모델링 접근 방식에 관해 이야기해보기 전 해당 미니 프로젝트 진행과정에 대해 먼저 소개해드리겠습니다.
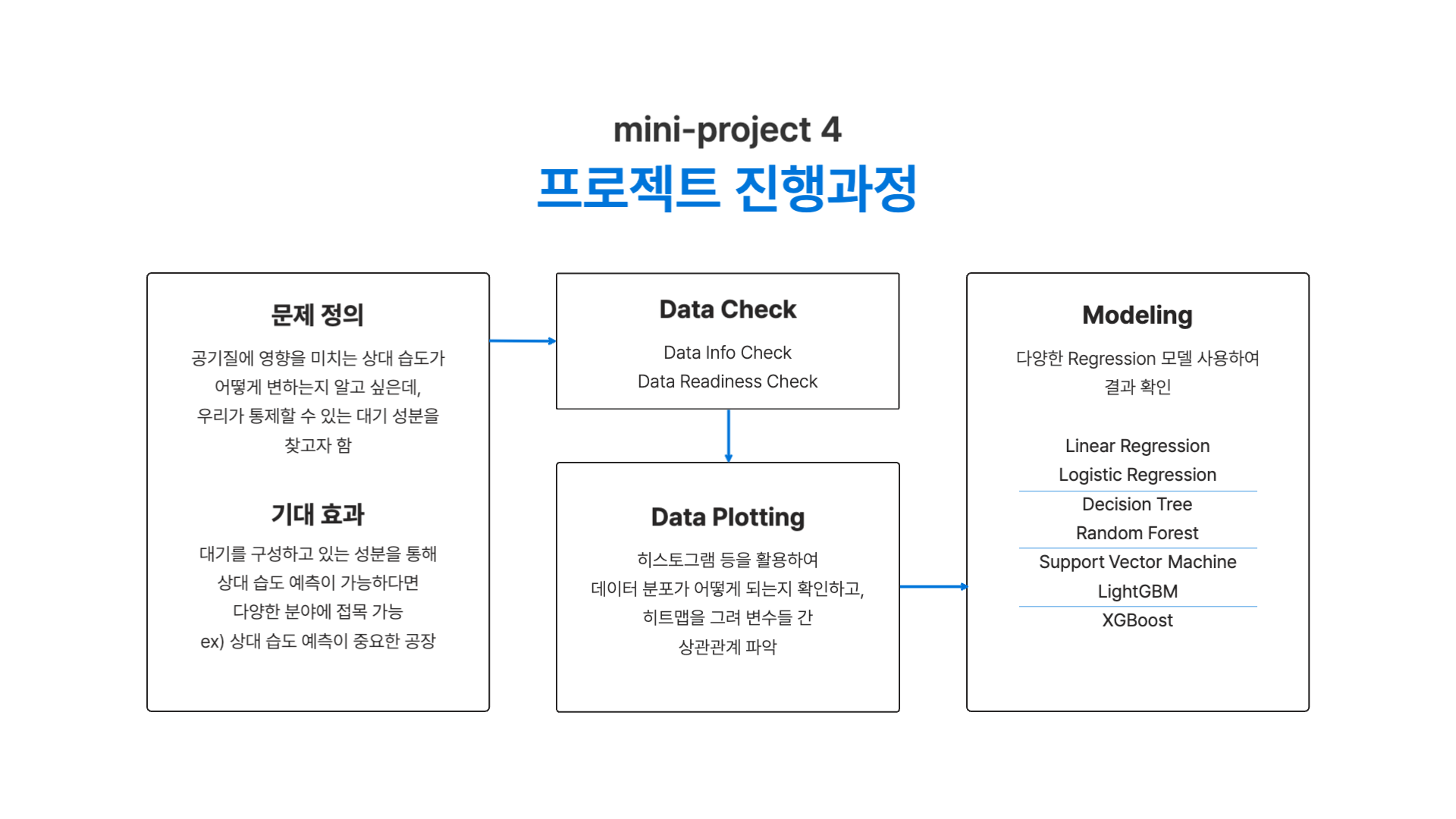
먼저 이번 미니 프로젝트의 현실은 공기질에 영향을 미치는 상대 습도에 영향을 끼치는 대기 성분은 어떤게 있을지 몇개의 가설만 있는 상황입니다. 이와 반대되는 이상은(현실과 이상에 관한 이야기는 이전 프로젝트에서 다루었습니다!) 상대 습도에 영향을 끼치는 대기 성분을 예측하여 우리가 통제할 수 있는 것은 어떤 것이 있는지 알아내는 것입니다 (문제 정의). 이로 인한 기대효과는 상대 습도 예측이 중요한 공장 등 다양한 분야에 접목하여 사용 가능한 모델이 될 수 있을 것입니다.
다음으로 Data Check에서는 데이터의 shape, dtypes, null values 등을 확인하여 feature들의 특성을 파악했습니다. 그리고 날짜 컬럼에서 월, 시간 정보 등의 추가 컬럼을 생성했습니다.
이후 Data Plotting에서 히스토그램과 히트맵을 그려 feature들이 분포 및 상관관계를 파악할 수 있었습니다.
마지막으로 Modeling에서는 다양한 Regression 모델을 사용하여 모델링을 했습니다. 한가지가 아닌 여러 알고리즘을 사용하며 이번 미니 프로젝트에서 사용되는 데이터는 어떤 알고리즘에 가장 적합한 지 확인할 수 있었습니다.
그러면 다음으로 Modeling을 진행하며 배웠던 내용을 더 자세히 소개해드리겠습니다.
03. 모델링 접근 방법
이번 미니 프로젝트의 중점은 다양한 모델들을 많이 다뤄보고, 해당 모델들에서 이번 미니 프로젝트가 추구하는 방향과 맞는 모델을 찾는 것입니다.

처음으로는 선형 계열의 Linear Regression과 Logistic Regression을 활용하여 모델링을 했습니다. 각각의 RMSE (root mean squared error)는 6.97, 344.73로 에러가 큰 것 같아서 다음으로 트리 계열의 모델인 Decision Tree와 Random Forest (Bagging 모델)를 사용했습니다.
각각의 RMSE는 1.42와 0.72로 에러가 많이 줄어든 것을 확인했습니다. 이를 통해 해당 데이터는 Tree 계열 모델에 적합한 데이터라는 것을 알 수 있었습니다.
다음으로 SVM 모델을 활용하여 모델링을 했습니다. 하지만 RMSE는 33.32로 해당 데이터에는 적합하지 않다는 것을 알 수 있었습니다.
마지막으로, (해당 미니 프로젝트에서는 다루지 않았지만) Boosting 모델인 lightGBM과 XGBoost 모델을 사용하여 모델링을 했습니다. 그 결과는 각각 0.89, 1.12의 RMSE를 산출했습니다. 이를 통해 해당 데이터는 Boosting 기반의 모델보다 Bagging 기반의 모델에 더 적합하다는 것을 알 수 있었습니다!
비록 lightGBM과 XGBoost가 더 최신의 모델이기는 하나, 여러 다양한 모델로 모델링을 한 결과 사용하는 데이터에 따라 이전의 모델이 더 좋은 결과를 나타낼 수도 있다는 것을 발견했습니다.
04. 정리하며
이번 미니 프로젝트에서 배운 내용을 정리하면 데이터에 따라 모델링의 결과가 달라질 수 있다는 것이었습니다.
물론 하이퍼파라미터 튜닝에 따라 결과는 달라질 수 있지만, 모델링을 할 때 단순히 최신 모델 만을 사용하는 것이 항상 더 좋은 결과를 나타내는 것은 아니라는 것을 배울 수 있었습니다.
저도 머신러닝 알고리즘을 배우며 lightGBM이 가볍고 성능이 좋으니까 이것만 쓰면 되겠네 라는 태도를 가지고 있었지만, 이번 미니 프로젝트를 하며 생각을 바꿀 수 있었습니다. 요즘에 이게 유행이니까 이걸 하자~ 라는 태도가 아니라, 여러 알고리즘의 특성을 다 알고 다 해봤더니 이게 좋아~ 이런 데이터에서는 이게 좋더라~ 라는 충분히 납득가능한 수준, 상식적인 수준에서 움직이는 데이터 분석가가 되도록 해야할 것 같습니다.
마지막으로 어떤 알고리즘이 어떤 데이터에서 잘 작동하는지를 정리하고 마무리 짓겠습니다.
- 모델에 사용되는 데이터들은 연속형인데, 결과는 Binary일 경우 --> Logistic Regression
- 데이터들이 연속형과 범주형이 섞여있을 때 --> Random Forest
- 데이터들이 대부분 범주형일 때 --> CatBoost
부족하지만 여기까지 읽어주셔서 감사합니다:)
