
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 개요
이번 미니 프로젝트에서는 은행 데이터 분석을 통해 파산 가능성을 예측하는 모델링을 하는 실습을 진행했습니다. 데이터는 약 6800개의 row와 96개의 컬럼으로 이루어진 데이터로서, 은행을 판단하는 것으로 보이는 컬럼들이 보였습니다. 이렇게 애매하게 말씀드린 이유는 그 변수들을 잘 이해하지 못했기 때문입니다. 예시로 컬럼 중에 'Total Asset Return Growth Rate Ratio'라는 컬럼이 있었는데.. 음.. 제가 도메인 지식을 잘 알지 않는 이상 이해하기 어려운 컬럼이었습니다. 이러한 컬럼들이 90개가 넘다보니, 하나하나를 이해하는 것보다는 해당 컬럼들을 Data EDA 등을 통해 타겟 변수와의 유의미성을 판단하는 것이 실습 시간으로 봤을때 더 나을 것(?)으로 보였습니다. 만약 실제 데이터 분석가로 해당 분야를 분석하게 된다면 도메인 지식을 바탕으로 해당 컬럼들을 하나하나 볼 수 있는 기회가 있었으면 좋을 것 같습니다..!
이번 글에서 중점적으로 다룰 부분은 Imbalanced Data에 대한 내용입니다. 이전에 많은 미니 프로젝트들에서 데이터의 클래스가 불균형이었던적이 많았습니다. 그때 sampling 혹은 모델에서 class_weight를 조절하여 문제를 해결했었는데, 이번엔 Anomaly Detection 모델을 추가하여 분석을 진행했습니다.

여러가지 이상탐지 모델이 있지만, 이번 실습에서는 Isolation Forest를 사용했습니다. 기본적인 원리는 RandomForest와 비슷하게 여러 개의 의사결정 나무를 사용한 앙상블 기반의 모델입니다. 이때 이상값을 탐지하는 방법은 비정상 데이터라면 가까운 깊이에서 고립이 되는 값을 찾는 것입니다. 루트 노드까지의 평균 거리가 짧을수록 outlier score가 높아지고, outlier score가 높은 값을 찾는 원리로 작동합니다 (참고 블로그 링크).
그렇다면 해당 모델을 사용하여 어떻게 분석을 진행했는지 Data Processing 부분과 Model Analysis 부분에 중점을 두어 다루어보겠습니다.
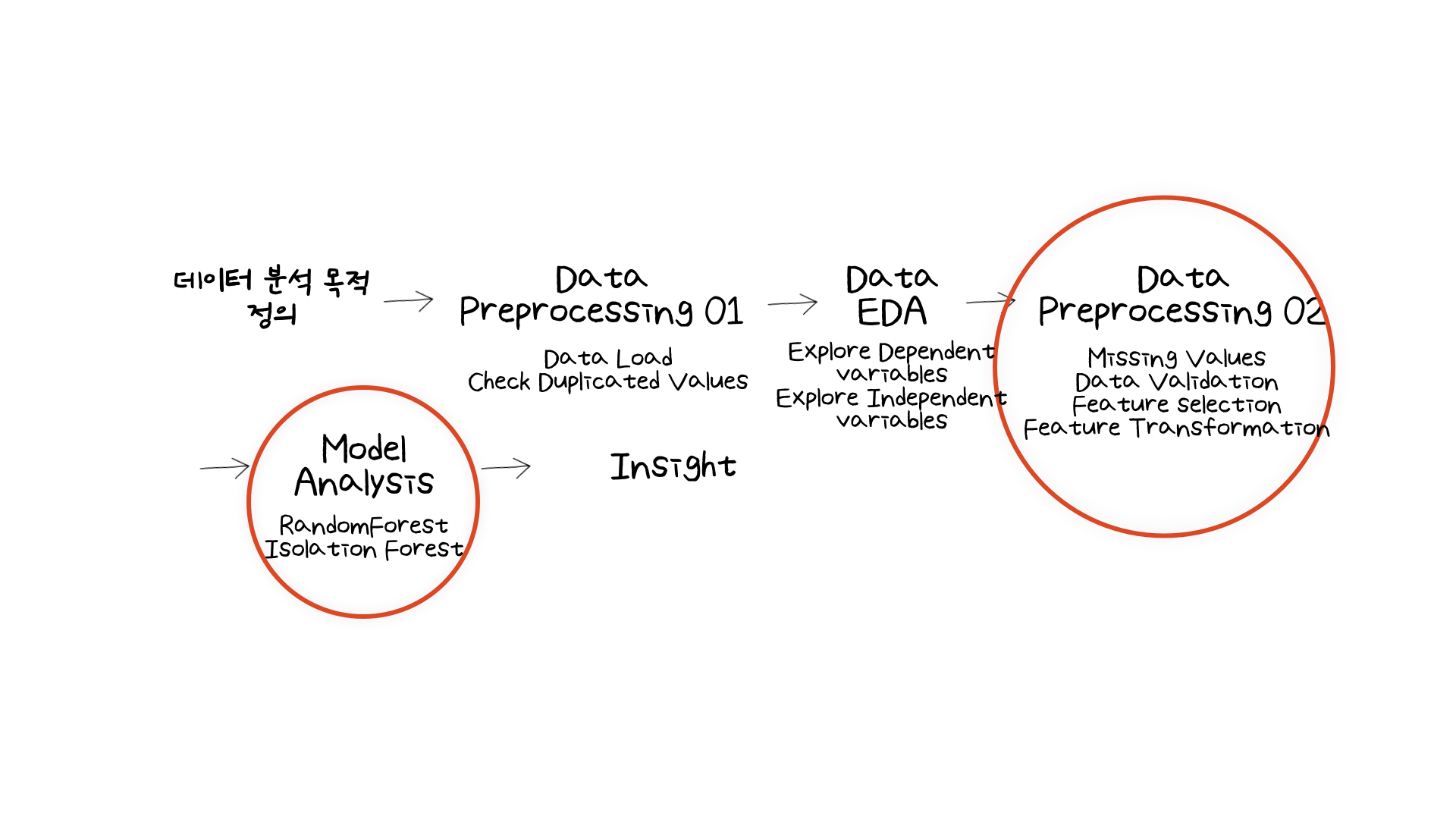
02. What Have I Learned?
첫번째로 모델링을 하기 전 데이터 스케일링과 인코딩 작업을 해주었습니다.
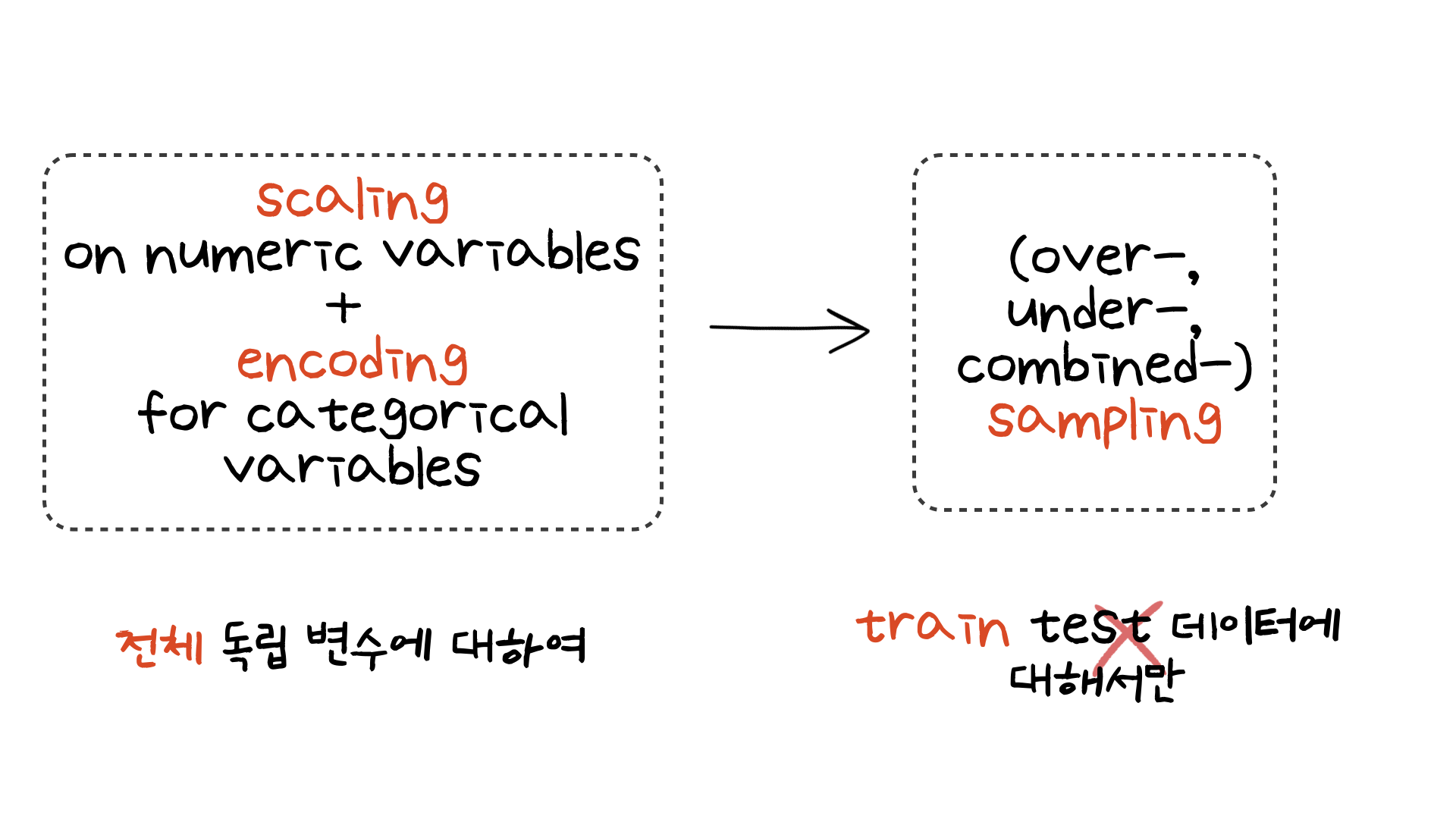
이 때 유의해야 할 점이 두가지가 있습니다. 첫번째는 샘플링 전에 카테고리 변수는 one-hot encoding을 해주어야 한다는 점입니다. 사실 이 부분은 정확히 이해는 하지 못했습니다. 이전 미니 프로젝트에서 샘플링 전에 원핫 인코딩이 필요하다는 것을 강조했었는데.. 이 부분은 다시 복습을 하여 이후에 다시 다루어보도록 하겠습니다. 두번째는 sampling은 학습을 할 데이터에만 적용하는 것입니다. 어떤 샘플링 기법이든 학습할 데이터에만 적용한 후, 이후 모델을 테스트 데이터는 샘플링을 적용하지 않은 이미 학습이 된 데이터로 예측을 해야합니다.
이번 실습에서는 imblearn 라이브러리의 오버샘플링 함수인 SMOTE와 combined 샘플링 기법인 SMOTEENN을 사용하여 변수를 변형시켜주었습니다. 그렇게 해서 모델링에 활용된 데이터는
- sampling이 되지 않은 imbalance 한 데이터
- over-sampling이 적용된 데이터
- combined-sampling이 적용된 데이터
이렇게 세가지입니다.
위 세가지 데이터를 사용하여 모델링을 한 방법은 아래와 같이 5가지입니다.
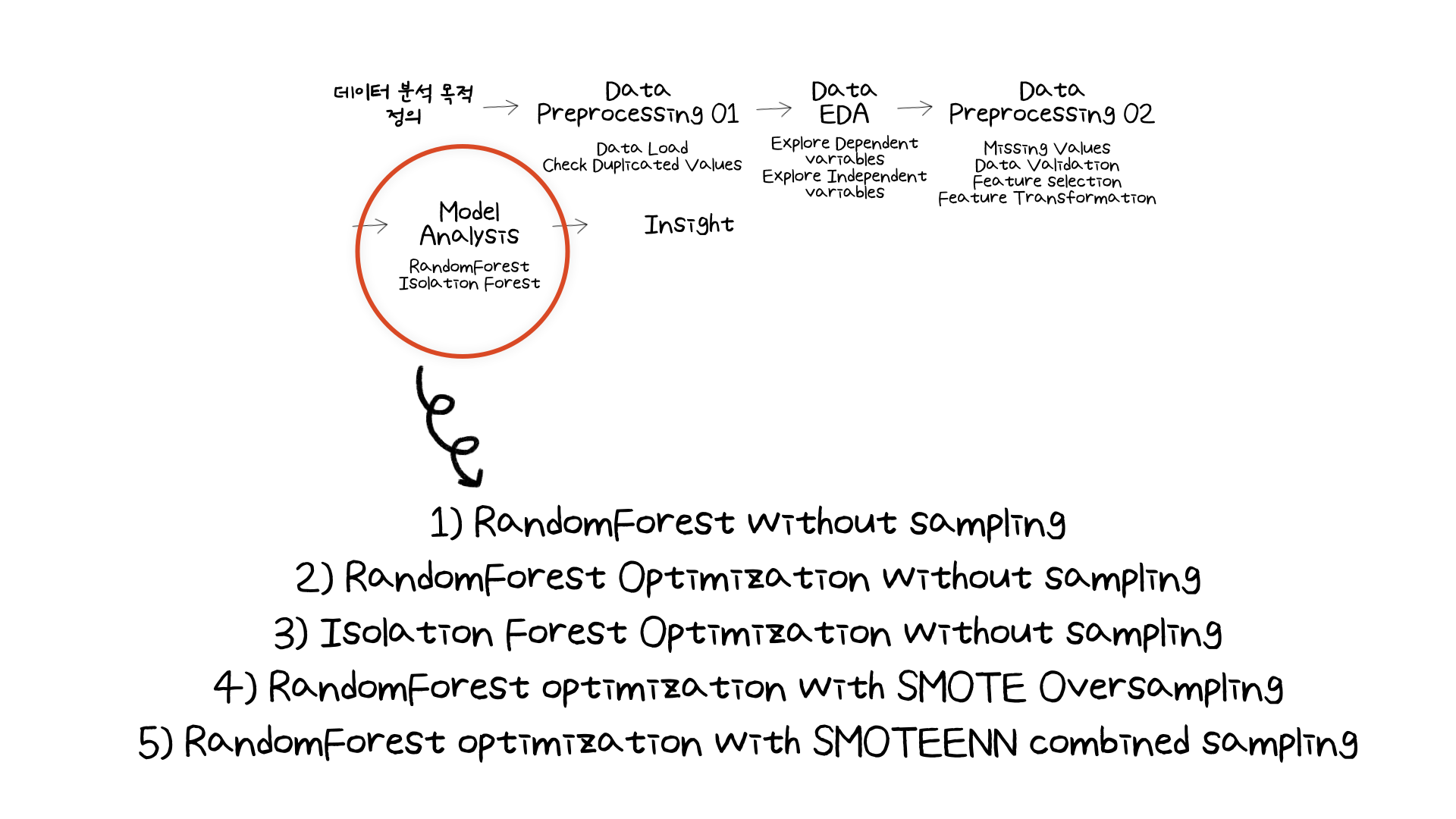
분류 모델에는 랜덤포레스트를 사용했습니다. 랜덤 포레스트 모델로
- 샘플링없이 모델링
- 샘플링없이 하이퍼 파라미터 튜닝 (class_weight 포함)을 통한 모델링 4. 오버샘플링한 데이터를 기반으로 하이퍼 파라미터 튜닝을 통한 모델링
5, combined-sampling한 데이터를 기반으로 하이퍼 파라미터 튜닝을 통한 모델링
4가지와
- 샘플링되지 않은 데이터를 기반으로 Isolation Forest 모델을 통한 모델링을
1가지 방법으로 통해 모델링을 진행했습니다. 모델링 결과는 아래와 같습니다.
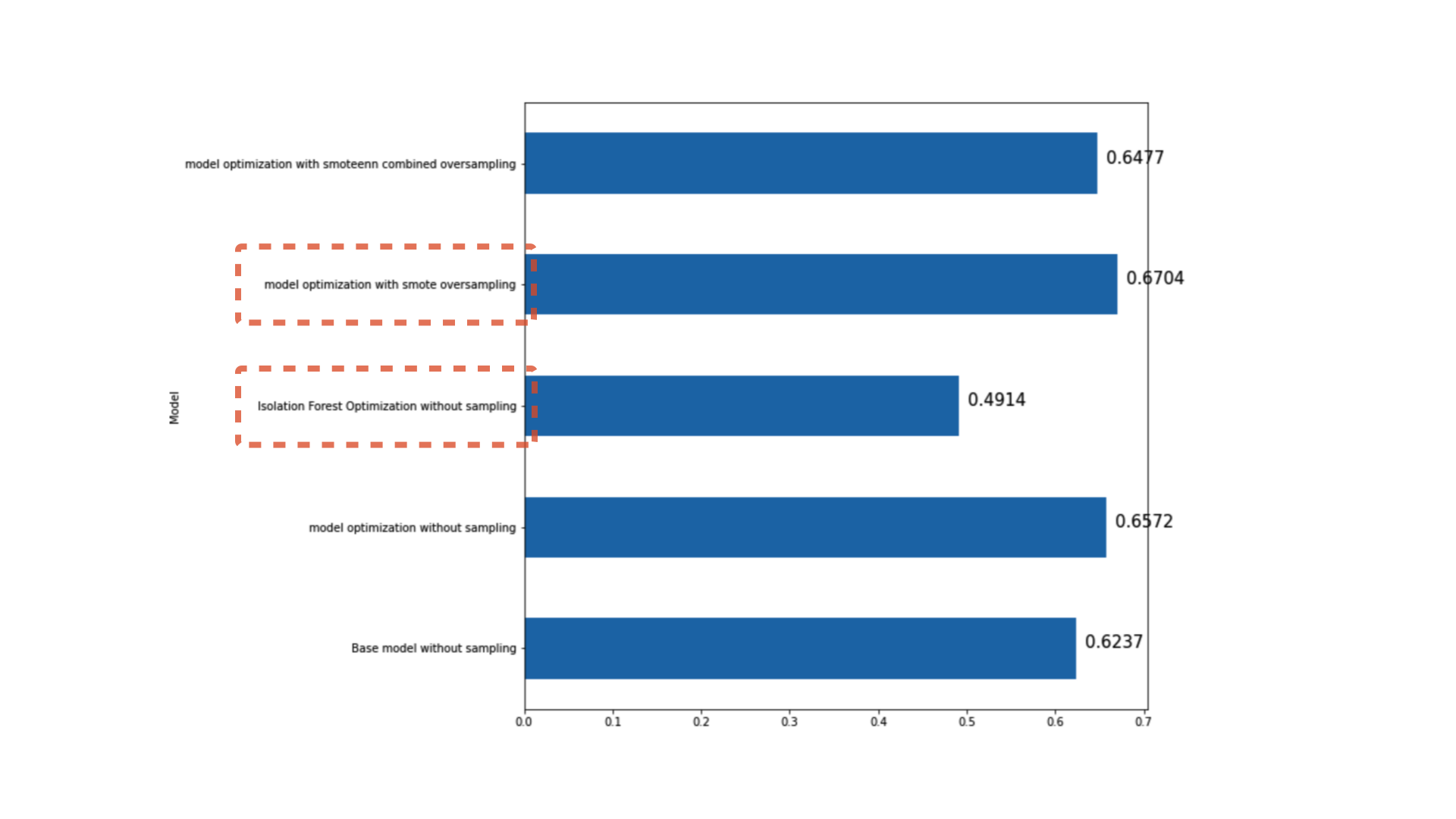
f1_score를 기반으로 모델링 성능을 측정한 결과 오버샘플링된 데이터를 기반으로한 튜닝된 랜덤포레스트의 성능이 가장 좋았습니다. 사실 이전 미니 프로젝트들에서 오버샘플링된 데이터를 기반으로 모델링을 했었을 때 성능이 좋지 않았었습니다. 하지만 이번 데이터에서는 오버샘플링을 했을때 성능이 제일 좋게 나타났습니다. 물론 랜덤포레스트가 아닌 부스팅 기반의 XGBoost 혹은 LightGBM에서의 결과는 다를 수도 있지만, 여기서 얻은 교훈은 'There is no one best model'이었습니다.
하지만 아쉽게도 이상탐지 기법 모델 중 하나인 Isolation Forest를 통한 모델링은 좋은 성능을 나타내지 못했습니다. 심지어 성능이 다른 모델링에 비해 너무 떨어졌습니다. 내심 좋은 성능을 나타내어 이번 글에서 다룰 때 나중에 이 기법도 쓸 것이다! 라고 말하고 싶었지만 이번엔 그 기대감은 살짝 넣어두었습니다. 하지만 나중에 비슷한 문제가 있을때 Isolation Forest 혹은 다른 이상탐지 기법을 사용할 수 있다는 또다른 선택지를 배울 수 있는 시간이었습니다.
03. 마무리하며
이번 실습을 진행하며 고객 데이터에서는 어떻게 사용할 수 있을까라는 생각이 들기도 했습니다. 고객이 상품 구매 퍼널로 들어와 상품을 실제 구매하는 비율은 매우 적을 것입니다. 이 때 구매를 한 손님을 1, 구매를 하지 않은 손님을 0으로 해서 Isolation Forest 등의 이상탐지 기법 모델을 사용하면 어떤 결과가 나올지 궁금해졌습니다. 나중에 실제 현업에서 일을 하게 된다면 해당 모델들을 꼭 적용해보고 싶습니다.
부족한 글 읽어주셔서 감사합니다:)
