
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 각색하여 복습을 위해 작성하였습니다.
01. 개요
이번 5번째 미니 프로젝트에서는 배운내용을 크게 2가지로 정리하면 아래와 같습니다.
이번 미니 프로젝트에서 유방암 환자를 예측할 때 binary classification 방법으로 접근을 했습니다. 이때, 클래스가 negative인 경우와 positive인 경우 두가지가 있을텐데 각 Feature마다 해당 클래스가 어떻게 분포하고 있는지 확인하며 발견한 사실을 소개하고자 합니다.
다음으로는, 데이터에 대하여 여러 모델을 적용하여 모델링을 한 방법을 소개하고자 합니다. 이전 프로젝트에서 여러 Regression 모델들을 활용하여 모델링을 한 것처럼, 이번엔 Classification 모델들을 활용하여 모델링을 진행한 방법을 소개하고자 합니다.
02. 미니 프로젝트 진행과정
배운 내용을 자세하게 소개하기 전, 이번 미니 프로젝트 전체 진행과정을 간단하게 소개해드리겠습니다.
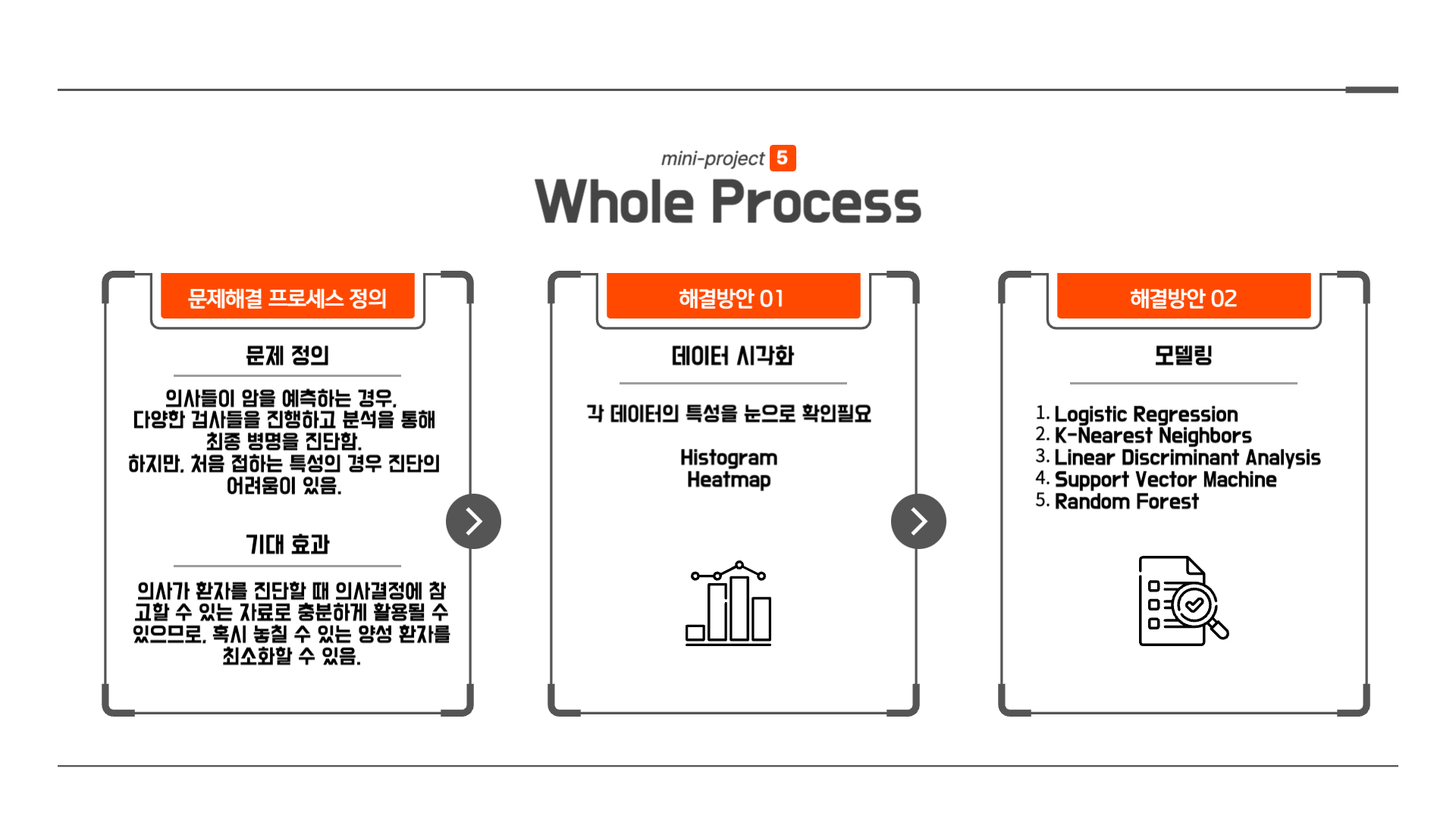
먼저 문제정의, 기대효과의 정의로 시작했고 다음으로는 제가 크게 배운 내용으로 언급했던 데이터 시각화와 모델링 부분을 해결방안으로서 활용했습니다.
그렇다면 제가 이번 미니 프로젝트를 진행하면서 첫번째로 데이터가 시각화가 왜 중요하다는 것을 배웠는지 소개하고자 합니다.
03. 데이터 시각화 (히스토그램)
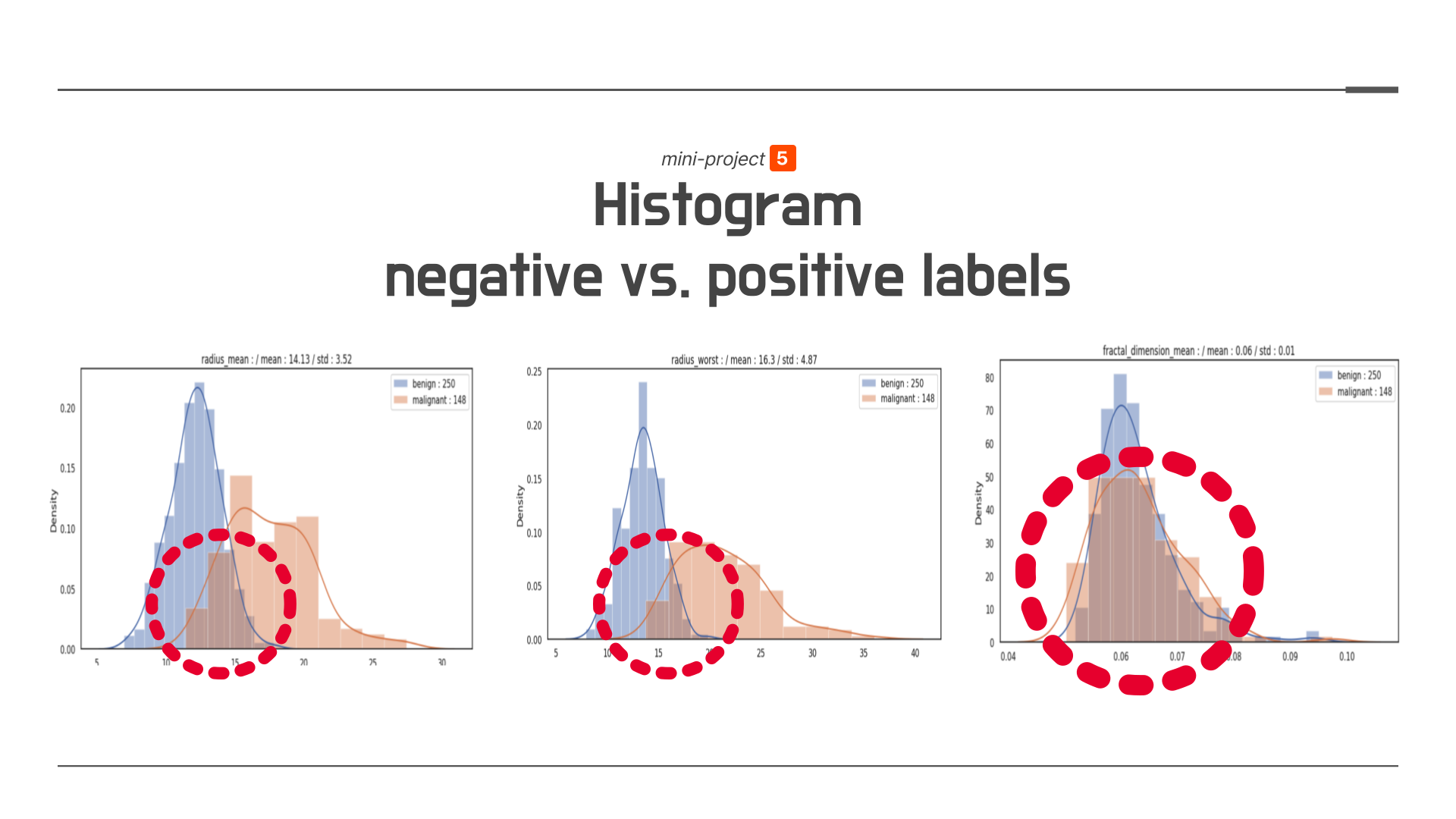
해당 미니 프로젝트에서 사용했던 데이터의 feature는 30개였습니다. 그중 3개의 feature의 레이블 별로 구분된 히스토그램을 예시로 보여드리겠습니다.
첫번째 히스토그램을 보면 두 히스토그램이 (파란색은 0 (negative) 빨간색이 1 (positive)) 겹치는 부분이 다소 있는 것을 알 수 있습니다. 하지만 전체적으로 봤을 때 두 히스토그램의 구분이 잘 되어있는것으로 보아, 우리는 해당 feature가 유방암 환자를 잘 구분하는 feature가 될 것임을 예상할 수 있습니다.
다음으로 두번째 히스토그램을 보면, 첫번째 히스토그램보다도 겹치는 부분이 더 작은 것을 확인할 수 있습니다. 이를 통해 해당 feature가 두 레이블을 더 잘 구분할 수 있는 feature가 될 수 있음을 예상할 수 있습니다.
이와 반대로, 마지막 두개의 히스토그램 분포는 거의 겹쳐있는 것을 볼 수 있습니다. 이를 통해 우리는 마지막 feature는 두 레이블을 구분하는 것이 어려울 것임을 예상할 수 있습니다.
하지만, 해당 히스토그램들은 feature들간의 상관관계를 고려하지 않고 독립적으로 본 결과입니다. 때문에, 서로 간의 상관관계를 확인하기 위해 heatmap도 같이 보는 것이 좋을 것입니다!
그래서, 히스토그램을 보며 '아 이 feature는 중요할 거야!'라고 확정지는 것이 아니라 나중에 모델링할 때 '히스토그램을 그렸을 때 몇 개의 feature가 레이블을 잘 구분짓는 feature들이 있었는데 실제 모델링을 할 때는 어떨가?'하는 참고자료로 충분히 활용할 수 있는 것을 배울 수 있었습니다.
04. 모델링
5개의 모델링 결과를 알려드리기 전에, 간단하게 전체 모델에 똑같이 적용시킨 모델링 과정에 대해 소개해드리겠습니다.
- 먼저 GridSearchCV를 사용하여 각 모델의 hyperparameter를 rough하게 조정해주었습니다.
- 그 다음 cross_val_score를 통해 5-fold로 cross validation을 해주었습니다. (그 결과 1-fold로 train, test set을 나눈 것보다 f1 score과 조정이 되었습니다)
- 이후, confusion matrix를 그려 모델들을 비교하며 tn, fp, fn, tp 부분을 확인했습니다.
- 마지막으로 scikit-learn의 metrics에 있는 classification_report를 통해 precision, recall, f1 등등의 점수를 확인했습니다.
이 과정을 거친 모델들의 결과는 아래와 같습니다.
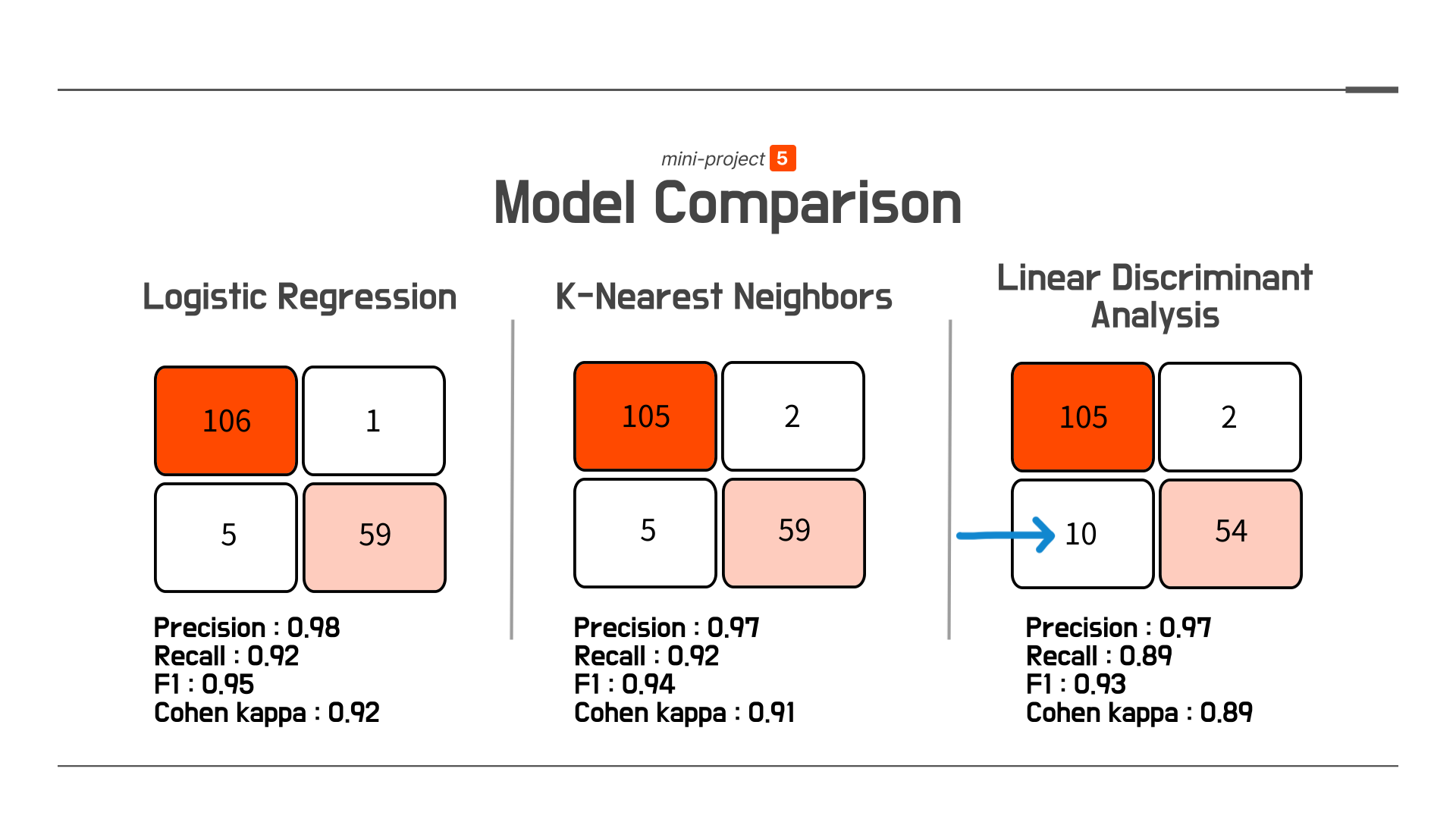
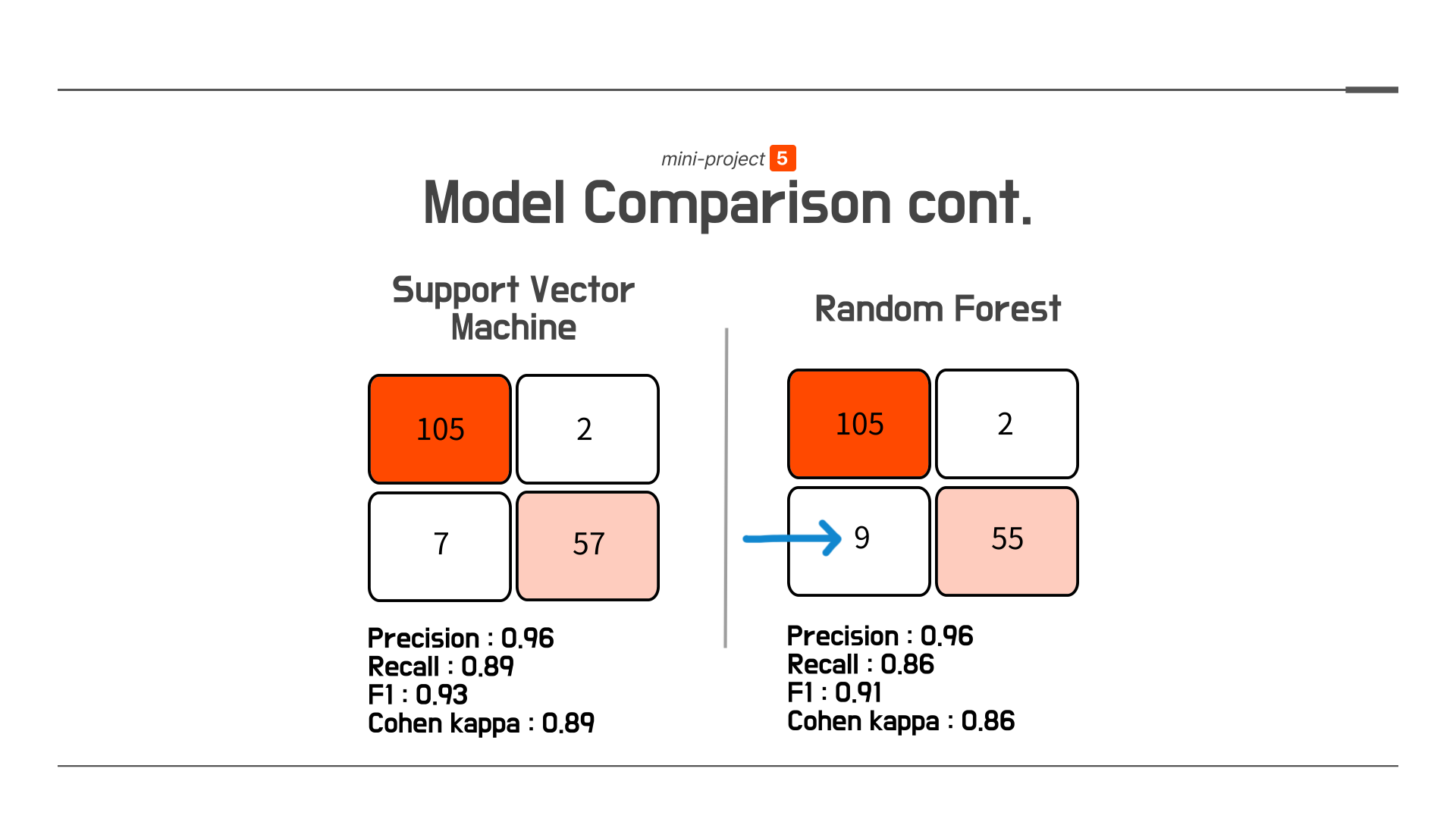
그 결과, Logistic Regression의 결과가 가장 좋은 것을 확인할 수 있었습니다. fp, fn의 숫자도 가장적고 precision, f1 점수도 가장 높은 것을 확인할 수 있었습니다.
하지만 무슨 이유에서인지, Random Forest의 점수는 생각보다 좋지는 않았습니다. 이를 통해 알 수 있던 사실은 해당 데이터가 트리계열의 ensemble-bagging 모델에는 적합하지 않다는 것 또한 짐작할 수 있었습니다.
05. 정리하며
제가 배운 내용을 다시 정리하자면 아래와 같습니다.
1. 데이터 시각화를 왜 할까? → 시각화를 통해 feature들의 레이블에 따른 데이터 분포를 확인하여 feature들과 레이블 간의 관계를 모델링 전에 어느 정도 파악할 수 있다
2. 데이터에 맞는 모델을 선택하는 과정을 간단하게 정리하면,
- GridSearchCV로 rough하게 하이퍼파라미터 조정
- Cross Validation로 모델의 서로다른 fold에 대한 성능 측정
- Confusion Matrix 그리기
- Classification Report 나타내기
마지막으로 미니 프로젝트 진행과정에서 배운 내용이 아닌, 그 외에 배운 내용을 정리하며 마무리 짓도록 하겠습니다!
Summary
- 문제해결 프로세스 정의는 정말 중요함
- 회사에서는 '상식'이 있는 사람이 필요
- 데이터 분석은 어떻게 보면 '도구'이자 '과정'임. 모델링만 하는 것은 의미가 없음
- 직접 문제를 정의하고 해결할 줄 아는 능력이 필요.
- 모델의 학습시간이 얼마나 걸렸는지도 확인 필요 (엔지니어링 관점)
- why? 만약 학습시간이 너무 길면 사용할 수가 없음
- 예를 들어, 공장에서는 검사 lead time이 0.5초라고 한다면,
학습을 0.5초 이내로 끝내고 결과를 뱉어내는 모델 선정 필요 - 때문에 모델을 학습할 때, 모델 시간도 같이 기록해둔다면
현업에서 의사결정 때 유용하게 사용할 수 있음
- Domain Knowledge 꼭 알아야 하는가?
- Domain Knowledge를 공부하고 알아가는 것은 정말 중요하지만
전혀 모르는 상태에서 분석에 투입되는 경우도 존재! - 이때는 데이터의 변형을 최소한으로 가져가면서 다양한 방법으로 모델링을 시도하는 것이
최선일 수 있음 - 모델의 성능이 충분히 우수하게 나온다면?
그렇다면 모델의 결과를 통해서 데이터를 분석할 수도 있음
- Domain Knowledge를 공부하고 알아가는 것은 정말 중요하지만
- 이번 챕터에서는 feature들이 가지고 있는 정보의 양이 충분하였기에
전체적으로 모델의 성능이 높게 나타남.
부족하지만 읽어주셔서 감사합니다. 피드백 매우 환영합니다!
